moving to a data-centric architecture: toronto data unconference 2015
TRANSCRIPT

Moving to a data-centric architecture!
Toronto Data Unconference!June 19th, 2015
Adam Muise!Chief Architect!Paytm [email protected]!

Who am I?!• Chief Architect at Paytm Labs!
• Paytm Labs is a data-driven lab founded to take on the really hard problems of scaling up Fraud, Recommendation, Rating, and Platform at Paytm!
• Paytm is an Indian Payments/Wallet company, has 50 Million wallets already, adds almost 1 Million wallets a day, and will be greater than 100 Million customers by the end of the year. Alibaba recently invested in us, perhaps you heard. !
• I’ve also worked with Data Science teams at IBM, Cloudera, and Hortonworks!

Paytm = Biggest Digital Wallet in India &
Marketplace!

I have nothing to sell you.!

This is an unconference. !

That means you should speak. !

Try it out now. Let’s introduce ourselves. !

What I suggest we discuss:!
Why a Datalake?!&!
How to Datalake in 2015!

Why Datalake?!

In most cases, more data is better.!Work with the population, not just a
sample.

Your view of a client today.
Male!
Female!
Age: 25-30!
Town/City!
Middle Income Band!
Product Category Preferences!

Your view with more data.
Male!
Female!
Age: 27 but feels old!
GPS coordinates!
$65-68k per year!
Product recommendations!
Tea Party!Hippie!
Looking to start a business !
Walking into Starbucks right now…!
A depressed Toronto Maple Leaf’s Fan!
Products left in basket indicate drunk
amazon shopper!
Gene Expression for
Risk Taker!
Thinking about a new house!
Unhappy with his cell phone plan!
Pregnant!
Spent 25 minutes looking at tea cozies!

New types of data don’t quite fit into your pristine view of the world.
My Little Data Empire!Data!Data!Data!
Data!Data!
Data!Data! Data!
Data!
Logs!Data!
Data!Data!Data!
Data!Data!Data!
Machine Data!Data!
Data!Data!Data!
Data!Data!Data!
?!?!?! ?!

To resolve this, some people make Data Warehouses with fixed
schemas EDW!Data!Data!Data!
Data!Data!
Data!Data! Data!
Data!Schema!

…but that has its problems too.
EDW!Data!Data!Data!
Data!Data!
Data!Data! Data!
Data!Schema!Data!Data!Data!
ETL! ETL!
ETL! ETL!
EDW!Data!Data!Data!
Data!Data!
Data!Data! Data!
Data!Schema!Data!Data!Data!
ETL! ETL!
ETL! ETL!

What if the data was processed and stored centrally? What if you didn’t need to force it into a single schema? !
Data Lake.
EDW!Data!Data!
Data!
Data!Data!Data!
Data!Schem
a!
BI & Analytics! Schema! Schema!
Data!Data!Data!
Data Lake!Data!
Data!Data!Data!
Data!Data!Data!Data!Data! Data!
Data!Data!Schema!Schema!Data!
Data!Data!Process! Process!
Data!Data!Data!
Data!Data!Data!
Data!Data!Data! Data!
Data!Data!Data Sources!
Data Sources!

A Data Lake Architecture enables:!- Landing data without forcing a single schema!- Landing a variety and large volume of data efficiently!- Retaining data for a long period of time with a very low $/TB!
- A platform to feed other Analytical DBs!- A platform to execute next gen data analytics and processing applications (Graph Analytics, Machine
Learning, SAP, etc…)

How to Datalake in 2015…!

What is Lambda Architecture?!

Batch Processing!+!
Stream Processing!= Lambda Architecture!

Batch Layer!- Handles ETL!- Traditional Integration!- Often System of Record!- Archive!- Large-scale analytics!

Speed Layer!- Handles Event streams!- Near-Realtime predictive analytics!- Alerting/Trending!- Processing/Parsing for Micro-Batch ETL!- Often an ingest layer for NoSQL DB data or Search indexes (Solr, ES, etc)!

Lambda Architecture!
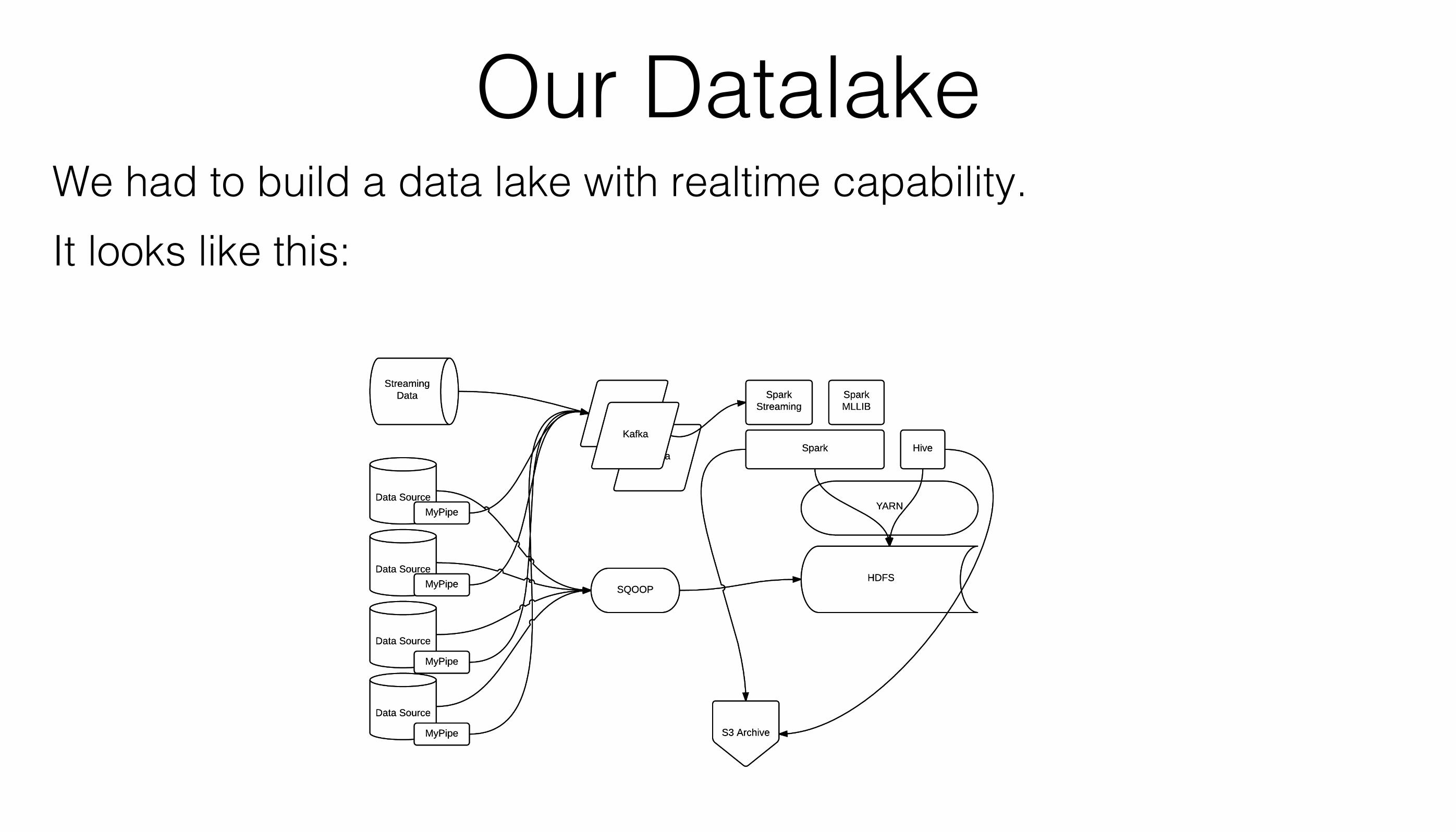
Our Datalake!We had to build a data lake with realtime capability. !It looks like this:!!

Our Datalake!Lambda Architecture!Batch Ingest:!
• SQOOP from MySQL instances!
• Keep as much in HDFS as you can, offload to S3 for DR/Archive and when you have colder data!
• Spark and other Hadoop processing tools can run natively over S3 data so it’s never really gone (don’t use Glacier in a processing workflow)!
Realtime Ingest:!
• Mypipe to get events from binary log data and push into Kafka topics (under construction)!
• Applications push critical events to Kafka !
• Kafka acts as a buffered ingest, can be archived to HDFS with Camus!
• All Realtime data processed with Spark Streaming (Micro Batch) or Camus (archive to Avro)!

Variations…!
Realtime Fraud Rule Engine!

Discussion:!What are the options to
handle realtime updates in Hadoop?!
!

28
Fin