mongodb evenings dallas: what's the scoop on mongodb & hadoop
TRANSCRIPT

Tweet tonight using #MongoDB to be entered to win a t-shirt!

Welcome to MongoDB Evenings Dallas! Agenda
5:30pm: Pizza, Beer & Soft Drinks
6:00pm: Welcome William Kent, Enterprise Account Executive, MongoDB
6:10pm: What’s the Scoop on MongoDB & Hadoop? Jake Angerman, Senior Solutions Architect, MongoDB
7:00pm: Acxiom's Journey with MongoDB John Riewerts, Director of Engineering - Marketing Services, Acxiom
7:45pm: Announcements
Q&A

MongoDB + Hadoop
{ Name: ‘Jake Angerman’, Title: ‘Sr. Solutions Architect’}

MongoDB + Hadoop

Documents Support Modern Requirements
Relational Document Data Structure { customer_id : 123,
first_name : "Mark",last_name : "Smith",city : "San Francisco",location : [37.7576792,-122.5078112],image : <binary data>,phones: [ {
number : “1-212-555-1212”, dnc : true,
type : “home”},{
number : “1-212-555-1213”, type : “cell”
} ] }

6
MongoDB Technical Capabilities
Applica'on
Driver
Mongos
Primary
Secondary
Secondary
Shard1
Primary
Secondary
Secondary
Shard2
… Primary
Secondary
Secondary
ShardN
1. DynamicDocumentSchema { name: “John Smith”, date: “2013-08-01”, address: “10 3rd St.”, phone: {
home: 1234567890, mobile: 1234568138 } }
db.customer.insert({…})db.customer.find({ name: ”John Smith”})
2.Na3velanguagedrivers
4.Highperformance- Datalocality- Indexes- RAM
3.Highavailability- Replicasets
5.Horizontalscalability- Sharding

7
Hadoop
A framework for distributed processing of large data sets • Terabyte and petabyte datasets • Data warehousing • Advanced analytics • Not a database • No indexes • Batch processing

8
Data Management

9
Data Management
Hadoop Fault tolerance Batch processing Coarse-grained operations Unstructured Data WORM
MongoDB High availability Mutable data Fine-grained operations Flexible Schemas CRUD

10
Data Management
Hadoop Offline Processing Analytics Data Warehousing
MongoDB Online Operations Application Operational

11
Commerce Use Case
Applications powered by
Analysis powered by
• Products & Inventory • Recommended products • Customer profile • Session management
• Elastic pricing • Recommendation models • Predictive analytics • Clickstream history
MongoDB Connector for
Hadoop

12
Insurance Use Case
Applications powered by
Analysis powered by
• Customer profiles • Insurance policies • Session data • Call center data
• Customer action analysis • Churn analysis • Churn prediction • Policy rates
MongoDB Connector for
Hadoop

13
Fraud Detection Use Case
Payments
Fraud modeling
Nightly Analysis
MongoDB Connector for Hadoop
Results Cache
Online payments processing
3rd Party Data
Sources
Fraud Detection
query only
query only

Where MongoDB Fits in the Hadoop Ecosystem

15
HDFS
YARN
MapReduce
Pig Hive
Spark

Spark Streaming
Hive
Spark Shell
Mesos Hadoop
Pig
Spark SQL
Spark
Stand Alone
YARN

17
MongoDB Connector for Hadoop
• Low latency • Rich fast querying • Flexible indexing • Aggregations in database • Known data relationships • Great for any subset of data
• Longer jobs • Batch analytics • Highly parallel processing • Unknown data relationships • Great for looking at all data or
large subsets
Applications Distributed Analytics
MongoDB Connector for
Hadoop

db.tweets.aggregate([{$group:{_id:{hour:{$hour:"$date"},minute:{$minute:"$date"}},total:{$sum:"$sentiment.score"},average:{$avg:"$sentiment.score"},count:{$sum:1},happyTalk:{$push:"$sentiment.positive"}}},{$unwind:"$happyTalk"},{$unwind:"$happyTalk"},{$group:{_id:"$_id",total:{$first:"$total"},average:{$first:"$average"},count:{$first:"$count"},happyTalk:{$addToSet:"$happyTalk"}}},{$sort:{_id:-1}}])
But doesn't MongoDB have…? • aggregation framework
– machine learning libraries
• map reduce – Javascript – competing workloads

19
MongoDB Data Operations Spectrum • Document Retrieval – 1ms if in cache, ~10ms from
spinning disk • .find() – per-document cost similar to single document
– _id range – any secondary index range, can be composite key – intersect two indexes – covered indexes even faster
• .count(), .distinct(), .group() – fast, may be covered • .aggregate() – retrieval cost like find, plus pipeline
operations – $match, $group – $project, $redact
• .mapReduce() – in-database Javascript • Hadoop Connector
– mongo.input.query for indexed partial scan – full scan
Faster……………
.....Slow
er

20

21
Analytics Landscape
Batch / Predictive / Ad Hoc (mins – hours)
Real-Time Dashboards / Scoring (<30 ms)
Planned Reporting (secs – mins )
Modern
Legacy

Use Cases

MetLife – Single View
…
SingleCSRApplica3onUnifiedCustomerPortalOpera3onalRepor3ng
Cards … CardsSilo1
…
Opera'onalDataLayer• Insurancepolicies• Demographicdata• Customerwebdata• Callcenterdata DW/DataLake
• Churnpredic3onalgorithms
MongoDBConnectorforHadoop
CardsCardsSilo2 CardsCardsSiloN
Pub-sub/ETL
CustomerClustering
ChurnAnalysis
Predic3veanaly3cs
…

25
Foursquare
• k-nearest neighbor problems – similarity of venues, people, or brands
• MongoDB data has advantages when used with MapReduce – log files can be stale – log files may not contain as much information – you can scan much less data
BSON dump
MongoDBConnectorforHadoop

MongoDB Connector for Hadoop

28
https://github.com/mongodb/mongo-hadoop

29
Connector Overview
Data
Read/WriteMongoDB
Read/WriteBSON
Tools
MapReduce
Pig
Hive
Spark
PlaUorms
ApacheHadoop
ClouderaCDH
HortonworksHDP
AmazonEMR

30
MapReduce Configuration
• MongoDB input – mongo.job.input.format=com.mongodb.hadoop.MongoInputFormat– mongo.input.uri=mongodb://mydb:27017/db1.collection1
• MongoDB output – mongo.job.output.format=com.mongodb.hadoop.MongoOutputFormat– mongo.output.uri=mongodb://mydb:27017/db1.collection2
• BSON input/output – mongo.job.input.format=com.hadoop.BSONFileInputFormat– mapred.input.dir=hdfs:///tmp/database.bson– mongo.job.output.format=com.hadoop.BSONFileOutputFormat– mapred.output.dir=hdfs:///tmp/output.bson

33
MongoDB Cluster
MONGOS
SHARD A
SHARD B
SHARD C
SHARD D
MONGOS Client

34

35
extends MongoSplitter class
List<InputSplit> calculateSplits()

36
• High-level platform for creating MapReduce • Pig Latin abstracts Java into easier-to-use notation • Executed as a series of MapReduce applications • Supports user-defined functions (UDFs)
Pig

37
samples = LOAD 'mongodb://127.0.0.1:27017/sensor.logs' USING com.mongodb.hadoop.pig.MongoLoader(’deviceId:int,value:double');
grouped = GROUP samples by deviceId;
sample_stats = FOREACH grouped { mean = AVG(samples.value); GENERATE group as deviceId, mean as mean;}
STORE sample_stats INTO 'mongodb://127.0.0.1:27017/sensor.stats' USING com.mongodb.hadoop.pig.MongoStorage;

38
• Data warehouse infrastructure built on top of Hadoop • Provides data summarization, query, and analysis • HiveQL is a subset of SQL • Support for user-defined functions (UDFs)

39
Hive Support
CREATETABLEmongo_users(idint,namestring,ageint)STOREDBY"com.mongodb.hadoop.hive.MongoStorageHandler"WITHSERDEPROPERTIES("mongo.columns.mapping”="_id,name,age”)TBLPROPERTIES("mongo.uri"="mongodb://host:27017/test.users”)
• Access collections as Hive tables • Use with MongoStorageHandler or BSONStorageHandler

Spark

41 Image source: dzone.com

42
• Powerful built-in transformations and actions – map, reduceByKey, union, distinct, sample, intersection, and more
– foreach, count, collect, take, and many more
An engine for processing Hadoop data. Can perform MapReduce in addition to streaming, interactive queries, and machine learning.

Create the Resilient Distributed Dataset (RDD)
rdd = sc.newAPIHadoopRDD(
config, MongoInputFormat.class, Object.class, BSONObject.class)
config.set(
"mongo.input.uri", "mongodb://127.0.0.1:27017/marketdata.minbars")
config.set(
"mongo.input.query", '{"_id":{"$gt":{"$date":1182470400000}}}')
config.set(
"mongo.output.uri", "mongodb://127.0.0.1:27017/marketdata.fiveminutebars")
val minBarRawRDD = sc.newAPIHadoopRDD(
config,
classOf[com.mongodb.hadoop.MongoInputFormat],
classOf[Object],
classOf[BSONObject])

Spark Demo

K-means Clustering

>>> mongo_rdd = sc.mongoRDD('mongodb://localhost:27017/adsb.tincan') >>> parsed_rdd = mongo_rdd.map(parseData) >>> clusters = KMeans.train(parsed_rdd, 10, maxIterations=10, runs=1, initializationMode="random") >>> cluster_sizes = parsed_rdd.map(lambda e: clusters.predict(e)).countByValue() >>> cluster_sizes defaultdict(<type 'int'>, {0: 70122, 1: 350890, 2: 118596, 3: 104609, 4: 254759, 5: 175840, 6: 166789, 7: 68309, 8: 147826, 9: 495102})
K-means Clustering

K-means Clustering

K-means Clustering

Summary

52
Data Flows
Hadoop Connector
BSON Files
MapReduce & HDFS
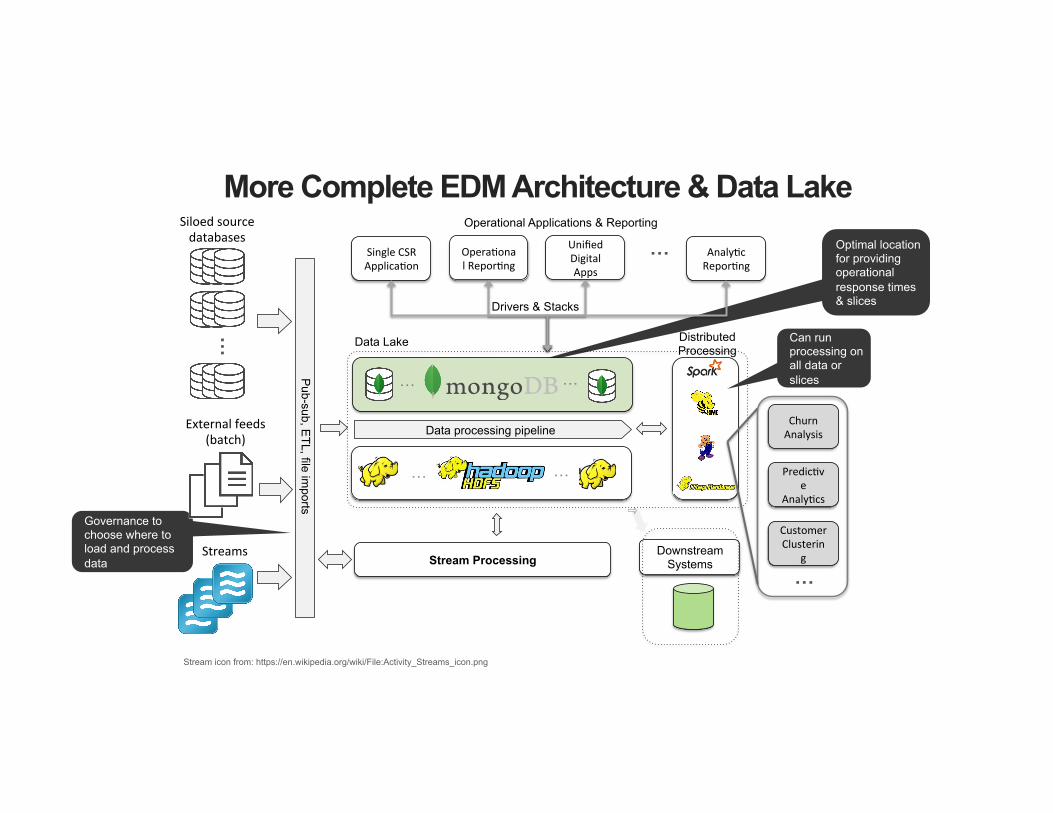
Optimal location for providing operational response times & slices
Governance to choose where to load and process data
More Complete EDM Architecture & Data Lake
…
Siloedsourcedatabases
Externalfeeds(batch)
Streams
Stream icon from: https://en.wikipedia.org/wiki/File:Activity_Streams_icon.png
Data processing pipeline
Pub-sub, E
TL, file imports
Stream Processing Downstream
Systems
… …
SingleCSRApplica3on
UnifiedDigitalApps
Opera3onalRepor3ng
…
… …
Analy3cRepor3ng
Drivers & Stacks
CustomerClusterin
g
ChurnAnalysis
Predic3ve
Analy3cs
…
Distributed Processing
Operational Applications & Reporting
Can run processing on all data or slices
Data Lake

Code “JakeAngerman” gets 25% off Super Early Bird Registration Ends March 25, 2016
June 28 - 29, 2016 New York, NY www.mongodbworld.com