model-free monte carlo-like policy evaluation
TRANSCRIPT

University of Liège – University of Michigan
Modelfree Monte Carlolike Policy Evaluation
Raphaël Fonteneau, Susan Murphy, Louis Wehenkel, Damien Ernst
Journées MAS, Bordeaux, France
(August 31st – September 3rd 2010)
The material of this talk is based on a presentationgiven by Raphael Fonteneau at Cap 2010.

Time
Patients
1
n
0 1 TEvaluation
?Therapy to evaluate

3
Introduction
● Discretetime stochastic optimal control problems arise in many fields (finance, medecine, engineering,...)
● Many techniques for solving such problems use an oracle that evaluates the performance of any given policy in order to determine a (near)optimal control policy
● When the system is accessible to experimentation, such an oracle can be based on a Monte Carlo (MC) approach
● In this paper, the only information is contained in a sample of onestep transitions of the system
● In this context, we propose a ModelFree Monte Carlo (MFMC) estimator of the performance of a given policy that mimics in some way the Monte Carlo estimator.

4
Problem statement
● We consider a discretetime system whose dynamics over T stages is given by
● All xt lie in a normed state space X, all u
t lie in a normed action
space U, wt are i.i.d. according to a probability distribution pW(.)
● An instantaneous reward is associated with the action u
t while being in state x
t
● A policy h: {0,...,T1} × X U is given, and we want to evaluate its performance.

Problem statement
● The expected return of the policy h when starting from an initial state x0 is given by
where
with
x0 xT
w0
w1 wT−2wT−1
x1
x2 xT−2 xT−1r0
r1 rT−2rT−1

6
Problem statement
● Problem: the functions f, ρ and pW(.) are unknown
● They are replaced by a sample of system transitions
where the pairs are arbitrary chosen and the pairs are determined by , where wl is drawn according to pW(.)
How to evaluate Jh(x0) in this context?

7
The Monte Carlo estimator
● We define the Monte Carlo estimator of the expected return of h when starting from the initial state x0:
with

8
The Monte Carlo estimator
x11
x0
x1p
xT−11
xT1
xTp
xT−1px2
p xT−2p
x21 xT−2
1
w01
w0p
wT−21
wT−11
xT2
MC Estimator
∑t=0
T−1
r t1
∑t=0
T−1
r t2
∑t=0
T−1
r tp
1p∑i=1
p
∑t=0
T−1
rti
w11
w02 w1
2 wT−22 wT−1
2
wT−2p
wT−1p
w ti~pW .
w1p
x12 x2
2 xT−22
xT−12
r01
r11 rT−2
1
rT−11
r02
r0p
r12
r1p
rT−22
rT−2p
rT−12
rT−1p

9
The Monte Carlo estimator
● We assume that the random variable Rh(x0) admits a finite variance
● The bias and variance of the Monte Carlo estimator are

10
● Here, the MC approach is not feasible, since the system is unknown
● We introduce the ModelFree Monte Carlo estimator
● From the sample of transitions, we build p sequences of different transitions of length T called ``broken trajectories''
● These broken trajectories are built so as to minimize the discrepancy (using a distance metric ∆) with a classical MC sample that could be obtained by simulating the system with the policy h
● We average the cumulated returns over the p broken trajectories to compute an estimate of the expected return of h
● The algorithm has complexity O(npT) .
The Modelfree Monte Carlo estimator

11
The Modelfree Monte Carlo estimator

12
Example with T=3, p=2, n=8
The Modelfree Monte Carlo estimator

13
The Modelfree Monte Carlo estimator

14
The Modelfree Monte Carlo estimator

15
The Modelfree Monte Carlo estimator

The Modelfree Monte Carlo estimator

17
The Modelfree Monte Carlo estimator

18
The Modelfree Monte Carlo estimator

The Modelfree Monte Carlo estimator

20
The Modelfree Monte Carlo estimator

21
The Modelfree Monte Carlo estimator

The Modelfree Monte Carlo estimator

23
The Modelfree Monte Carlo estimator
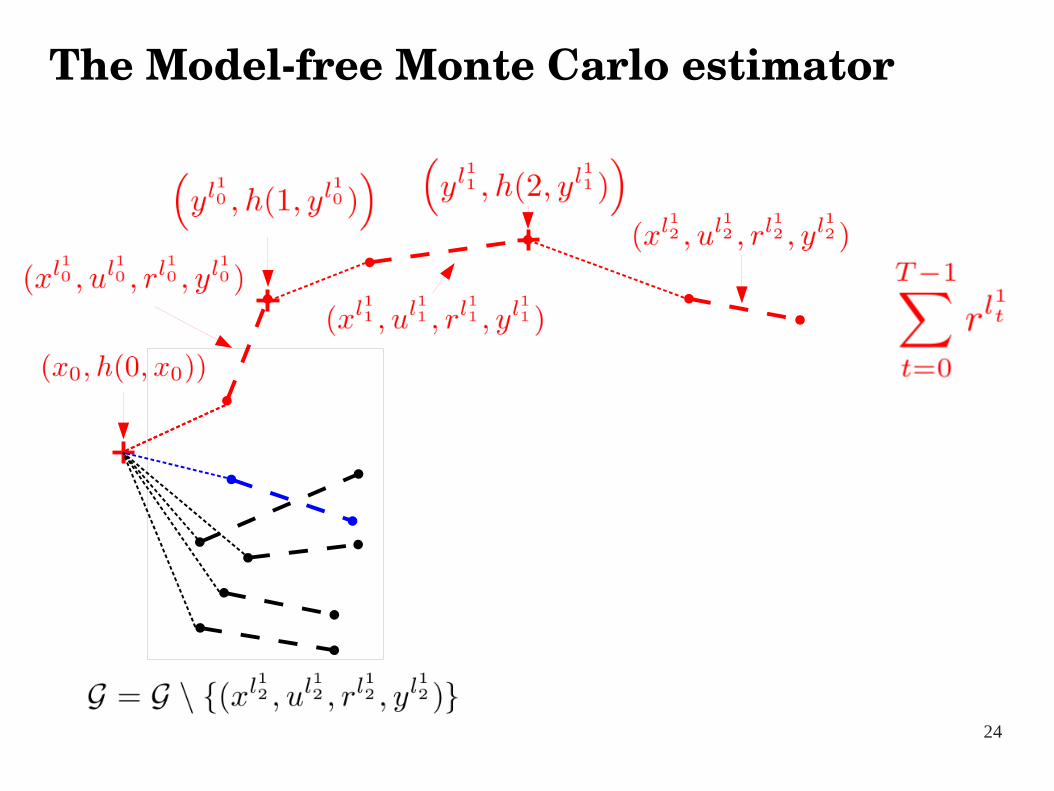
24
The Modelfree Monte Carlo estimator

The Modelfree Monte Carlo estimator

26
The Modelfree Monte Carlo estimator

27
The Modelfree Monte Carlo estimator

The Modelfree Monte Carlo estimator

29
The Modelfree Monte Carlo estimator

30
The Modelfree Monte Carlo estimator
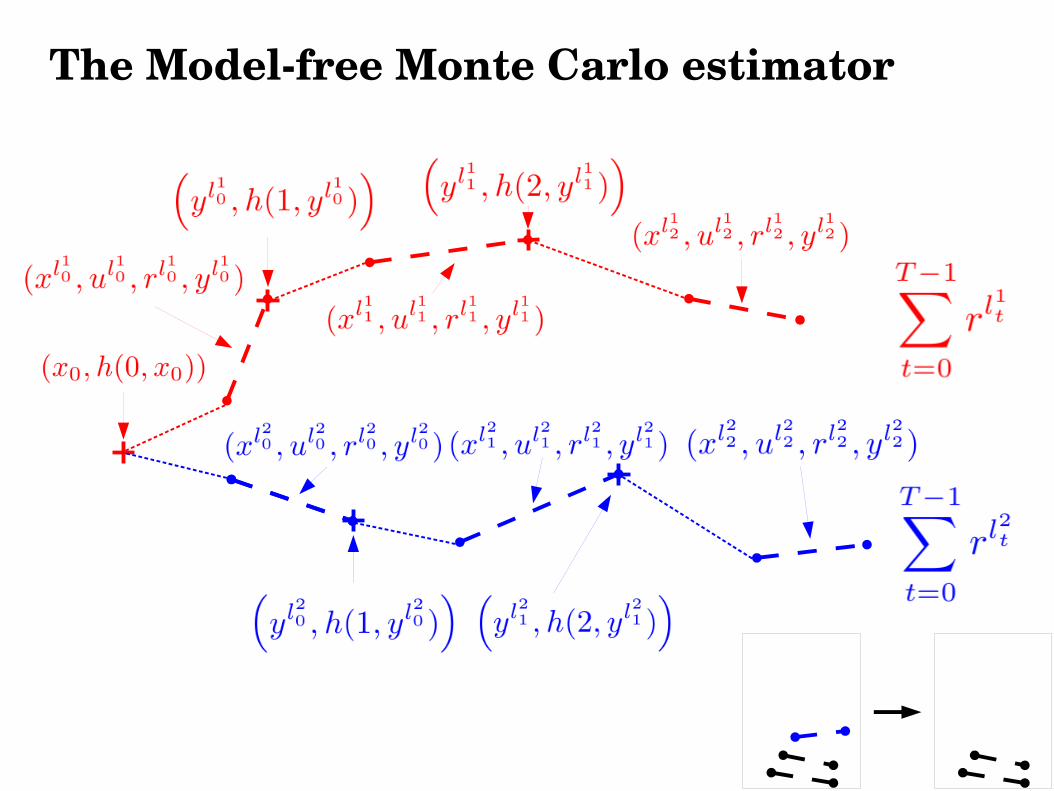
The Modelfree Monte Carlo estimator

32
● Assumption: the functions f, ρ and h are Lipschitz continuous
MFMC estimator: analysis

33
● The only information available on the system is gathered in a sample of n onestep transitions
● We define the random variable as follows:a
The set of pairs is arbitrary chosen,a
whereas the pairs are determined by where wl is drawn according to pW(.)
● is a realization of the random set .
MFMC estimator: analysis

34
● Distance metric ∆
● ksparsity
● denotes the distance of (x,u) to its kth nearest neighbor (using the distance ∆) in the sample
MFMC estimator: analysis

35
X
U
(x,u)
(x',u')The ksparsity can beseen as the smallest radius γ such that all∆balls in X×U of radius γ contain at least kelements from
MFMC estimator: analysis

36
● Expected value of the MFMC estimator
● Theorem
MFMC estimator: analysis

37
● Variance of the MFMC estimator
● Theorem
MFMC estimator: analysis

38
Illustration
● System
● pW(.) is uniform over W, T = 15, x0 = 0.5 .

39
Illustration
● Simulations for p = 10, n = 100 … 10 000, uniform grid
n
Monte Carlo estimatorModelfree Monte Carlo estimator

40
Illustration
● Simulations for p = 1 … 100, n = 10 000, uniform grid
Monte Carlo estimator
p p
Modelfree Monte Carlo estimator

41
Conclusions and Future work
Conclusions
● We have proposed in this paper an estimator of the expected return of a policy in a modelfree setting, the MFMC estimator
● We have provided bounds on the bias and variance of the MFMC estimator
● The bias and variance of the MFMC estimator converge to the bias and variance of the MC estimator
Future work
● MFMC estimator in a direct policy search framework
● One could extend this approach to evaluate return distributions (and not only expected values). This could allow to develop ''safe'' policy search techniques based on Value at Risk (VaR) criteria.