mixture modelling of continuous variables. mixture modelling so far we have dealt with mixture...
TRANSCRIPT

Mixture modelling of continuous variables

Mixture modelling
• So far we have dealt with mixture modelling for a selection of binary or ordinal variables collected at a single time point (c/s) or longitudinally across time
• The simplest example of a mixture model consists of a single continuous manifest variable
• The multivariate extension to this simple model is known as Latent Profile Analysis
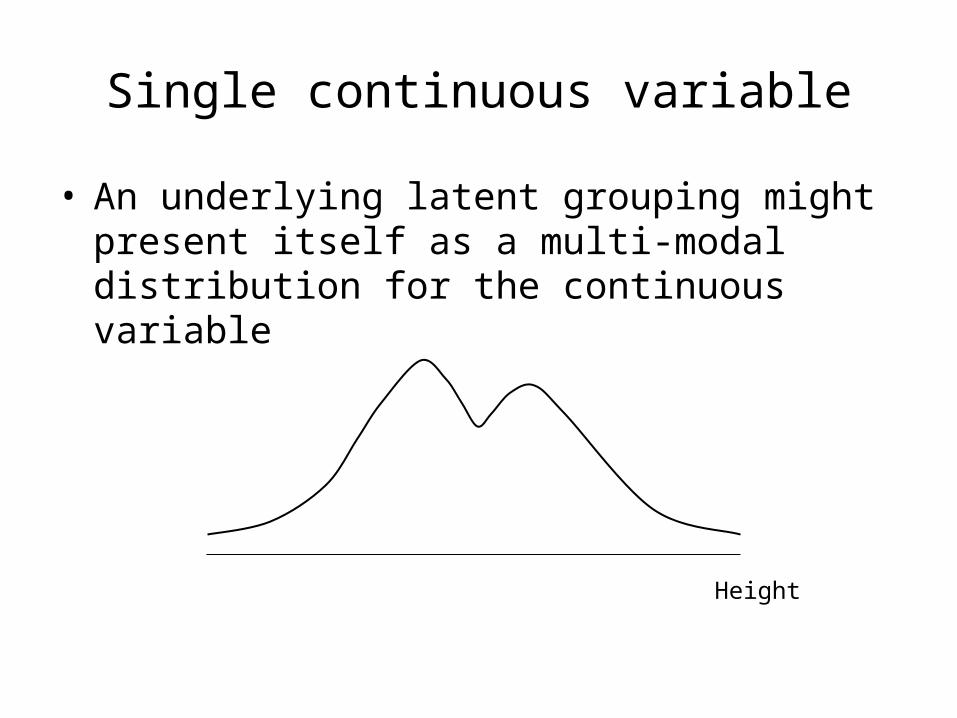
Single continuous variable
• An underlying latent grouping might present itself as a multi-modal distribution for the continuous variable
Height

Single continuous variable
• An underlying latent grouping might present itself as a multi-modal distribution for the continuous variable
Height
Females

Single continuous variable
• An underlying latent grouping might present itself as a multi-modal distribution for the continuous variable
Height
Males

Single continuous variable
• But the distance between modes may be small or even non-existent
• Depends on the variation in the item being measured and also the sample in which the measurement is taken (e.g. clinical or general population)

Single continuous variable
Figure taken from: Muthén, B. (2001). Latent variable mixture modeling. In G. A. Marcoulides & R. E. Schumacker (eds.), New Developments and Techniques in Structural Equation Modeling (pp. 1-33). Lawrence Erlbaum Associates.
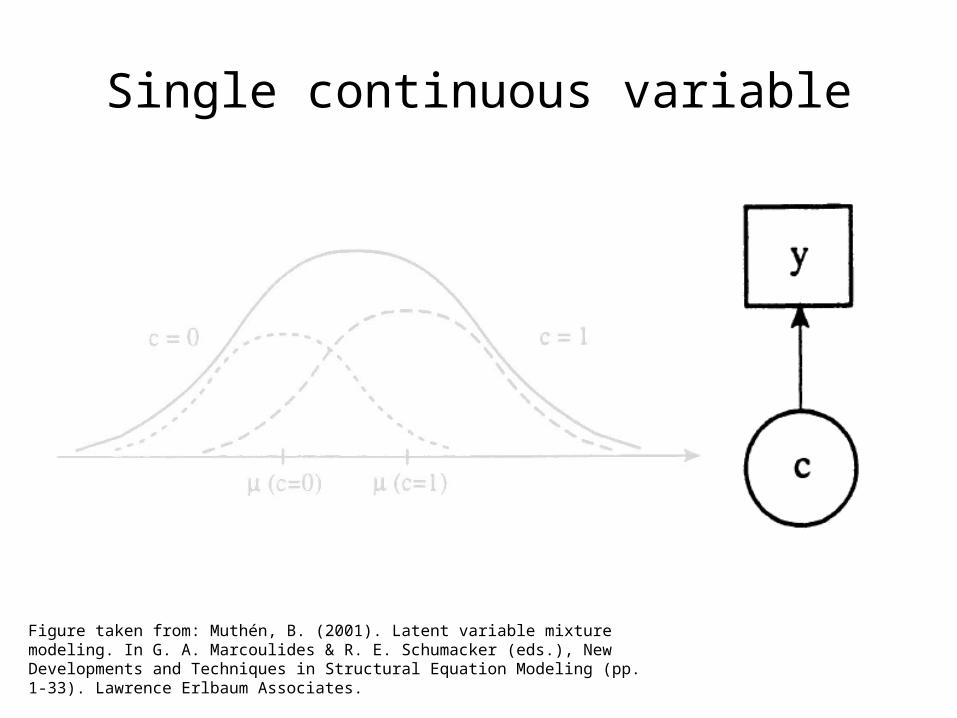
Single continuous variable
Figure taken from: Muthén, B. (2001). Latent variable mixture modeling. In G. A. Marcoulides & R. E. Schumacker (eds.), New Developments and Techniques in Structural Equation Modeling (pp. 1-33). Lawrence Erlbaum Associates.

Single continuous variable
• We assume that the manifest variable is normally distributed within each latent class

GHQ Example
Data: File is "ego_ghq12_id.dta.dat" ;
Define: sumodd = ghq01 +ghq03 +ghq05 +ghq07 +ghq09 +ghq11; sumeven = ghq02 +ghq04 +ghq06 +ghq08 +ghq10 +ghq12; ghq_sum = sumodd + sumeven;
Variable: Names are ghq01 ghq02 ghq03 ghq04 ghq05 ghq06 ghq07 ghq08 ghq09 ghq10 ghq11 ghq12 f1 id; Missing are all (-9999) ; usevariables = ghq_sum;
Analysis: Type = basic ;
plot: type is plot3;
Here we derive a single sum-score from the 12 ordinal GHQ items
The syntax shows that variables can be created in the define statement which are not then used in the final model
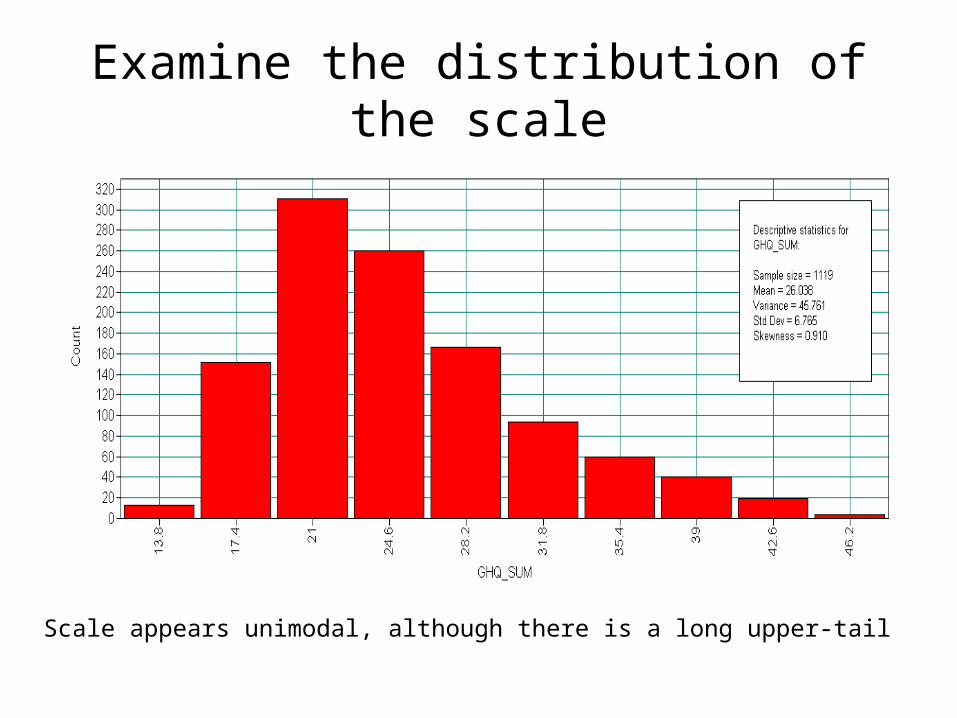
Examine the distribution of the scale
Scale appears unimodal, although there is a long upper-tail
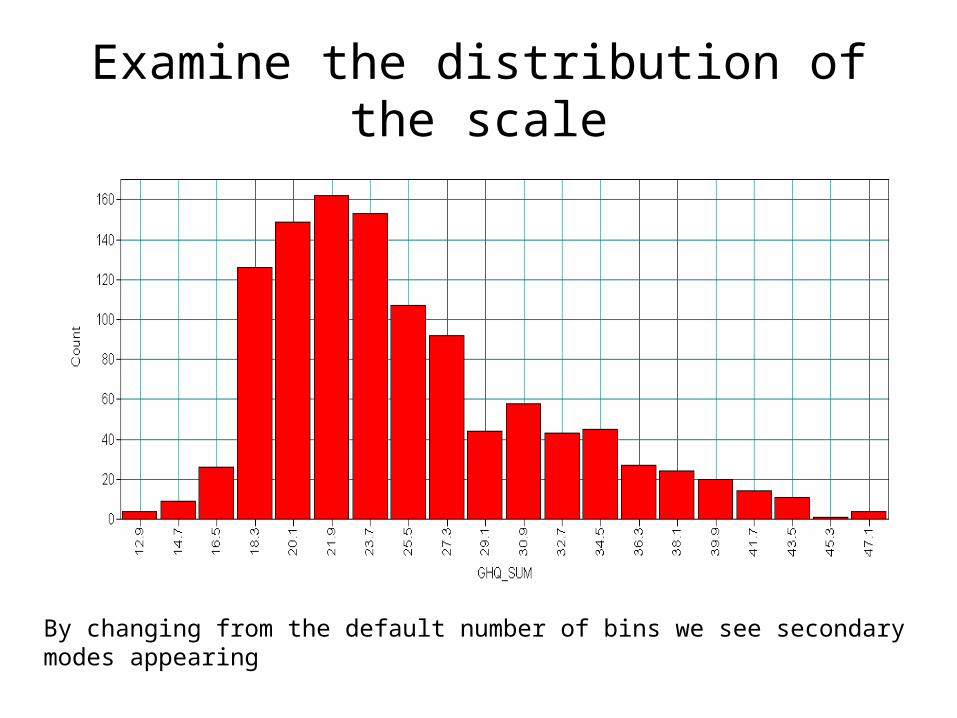
Examine the distribution of the scale
By changing from the default number of bins we see secondary modes appearing

Fit a 2-class mixture
Variable: <snip> classes = c(2);
Analysis: type = mixture ; proc = 2 (starts); starts = 100 20; stiterations = 20; stscale = 15;
model: %overall%
%c#1% [ghq_sum]; ghq_sum (equal_var);
%c#2% [ghq_sum]; ghq_sum (equal_var);

Fit a 2-class mixture
Variable: <snip> classes = c(2);
Analysis: type = mixture ; proc = 2 (starts); starts = 100 20; stiterations = 20; stscale = 15;
model: %overall%
%c#1% [ghq_sum]; ghq_sum (equal_var);
%c#2% [ghq_sum]; ghq_sum (equal_var);
This funny set of symbols refers to the first class
Means are referred to using square brackets.
Variances are bracket-less.
Here we have constrained the variances to be equal between classes by having the same bit of text in brackets at the end of the two variance lines
Means will be freely estimated.

Model results
TESTS OF MODEL FIT
Loglikelihood
H0 Value -3624.960 H0 Scaling Correction Factor 1.078 for MLR
Information Criteria
Number of Free Parameters 4 Akaike (AIC) 7257.921 Bayesian (BIC) 7278.002 Sample-Size Adjusted BIC 7265.297 (n* = (n + 2) / 24)

Model results
FINAL CLASS COUNTS AND PROPORTIONS FOR THE LATENT CLASSESBASED ON THE ESTIMATED MODEL
Latent classes 1 200.36980 0.17906 2 918.63020 0.82094
CLASSIFICATION QUALITY Entropy 0.829
CLASSIFICATION OF INDIVIDUALS BASED ON THEIR MOST LIKELY LATENT CLASS MEMBERSHIP
Latent classes 1 189 0.16890 2 930 0.83110
Average Latent Class Probabilities for Most Likely Latent Class Membership (Row)by Latent Class (Column)
1 2 1 0.889 0.111 2 0.035 0.965
Entropy is high
A smaller class of 18% has emerged, consistent with the expected behaviour of the GHQ in this sample from primary care
Class-specific entropies are both good

Model results Two-Tailed Estimate S.E. Est./S.E. P-Value
Latent Class 1
Means GHQ_SUM 37.131 0.574 64.737 0.000
Variances GHQ_SUM 18.876 1.016 18.581 0.000
Latent Class 2
Means GHQ_SUM 23.618 0.202 117.046 0.000
Variances GHQ_SUM 18.876 1.016 18.581 0.000
Categorical Latent Variables
Means C#1 -1.523 0.118 -12.947 0.000
Huge separation in means since SD = 4.3 (i.e. sqrt(18.88))

Examine within-class distributions

Examine within-class distributions

What have we done?
• We have effectively done a t-test backwards.• Rather than obtaining a manifest binary variable,
assuming equality of variances and testing for equality of means
• we have derived a latent binary variable based on the assumption of a difference in means (still with equal variance)

What next?
• The bulk of the sample now falls into a class with a GHQ distribution which is more symmetric than the sample as a whole
• There appear to be additional modes within the smaller class
• The ‘optimal’ number of classes can be assessed in the usual way using aBIC, entropy and the bootstrap LRT.
• In the univariate case, residual correlations are not an issue, but when moving to a multivariate example, these too will need to be assessed.

What next?
• As before, posterior probabilities can be exported and modelled in a weighted regression analysis
• A logistic regression analysis using a latent binary variable derived from the data is likely to be far more informative than a linear-regression analysis using the manifest continuous variable

What if we had not constrained the variances?
Variable: <snip> classes = c(2);
Analysis: type = mixture ; proc = 2 (starts); starts = 100 20; stiterations = 20; stscale = 15;
model: %overall%
%c#1% [ghq_sum]; ghq_sum ; ! (equal_var);
%c#2% [ghq_sum]; ghq_sum ; ! (equal_var);
Commented out

TESTS OF MODEL FIT
Loglikelihood H0 Value -3610.586 H0 Scaling Correction Factor 0.932 for MLR
Information Criteria Number of Free Parameters 5 Akaike (AIC) 7231.172 Bayesian (BIC) 7256.273 Sample-Size Adjusted BIC 7240.392
FINAL CLASS COUNTS AND PROPORTIONS FOR THE LATENT CLASSESBASED ON THE ESTIMATED MODEL
Latent Classes
1 456.72641 0.40816 2 662.27359 0.59184
CLASSIFICATION QUALITY
Entropy 0.479
Entropy is poor
Classes are more equal
BIC is lower!

Means are closer, variances differ greatly
MODEL RESULTS
Two-Tailed Estimate S.E. Est./S.E. P-Value
Latent Class 1
Means GHQ_SUM 31.493 0.816 38.616 0.000
Variances GHQ_SUM 45.570 2.439 18.686 0.000
Latent Class 2
Means GHQ_SUM 22.275 0.328 67.823 0.000
Variances GHQ_SUM 11.144 1.605 6.943 0.000

Distribution far from symmetric

Distribution far from symmetric