TRANSCRIPT

Fingerprint Synthesis: Search with 100 Million Prints
Vishesh MistryMichigan State University
East Lansing, MI, [email protected]
Joshua J. EngelsmaMichigan State University
East Lansing, MI, [email protected]
Anil K. JainMichigan State University
East Lansing, MI, [email protected]
(a)
(b)
Figure 1: Comparison of real fingerprints with synthesized fingerprints. Images in (a) are rolled fingerprint images from a law enforcement operationaldatabase [12] and fingerprints in (b) are synthesized using the proposed approach. One example for each of the four major fingerprint types is shown (fromleft to right: arch, left loop, right loop, whorl). All the fingerprints have dimensions of 512 × 512 pixels and a resolution of 500 dpi. A COTS minutiaeextractor was used to extract the minutiae points overlaid on the fingerprint images. Fingerprints in (a), from left to right, have NFIQ 2.0 quality scores of(47, 64, 77, 73), respectively, while those in (b), from left to right, have quality scores of (78, 40, 61, 42), respectively.
Abstract
Evaluation of large-scale fingerprint search algorithmshas been limited due to lack of publicly available datasets.A solution to this problem is to synthesize a dataset of fin-gerprints with characteristics similar to those of real fin-gerprints. We propose a Generative Adversarial Network(GAN) to synthesize a fingerprint dataset consisting of 100million fingerprint images. In comparison to publishedmethods, our approach incorporates an identity loss whichguides the generator to synthesize a diverse set of finger-prints corresponding to more distinct identities. To demon-strate that the characteristics of our synthesized fingerprints
are similar to those of real fingerprints, we show that (i)the NFIQ quality value distribution of the synthetic finger-prints follows the corresponding distribution of real finger-prints and (ii) the synthetic fingerprints are more distinctthan existing synthetic fingerprints (and more closely alignwith the distinctiveness of real fingerprints). We use oursynthesis algorithm to generate 100 million fingerprint im-ages in 17.5 hours on 100 Tesla K80 GPUs when executedin parallel. Finally, we report for the first time in openliterature, search accuracy (DeepPrint rank-1 accuracy of91.4%) against a gallery of 100 million fingerprint images(using 2,000 NIST SD4 rolled prints as the queries).
arX
iv:1
912.
0719
5v1
[cs
.CV
] 1
6 D
ec 2
019

Algorithm Orientationmodel
Ridgestructure
model
Minutiaemodel Analysis
Cappelli etal. [15]
Zero-pole[34]
Gaborfiltering
[19]
Gaborfiltering
[19]
◦ Minutiae and ridge structure models are implemented independently.◦ Synthesized and real fingerprints have very different characteristics.◦ Generated 10,000 plain fingerprints (240× 336).
SFinGe[6]
Zero-pole[34]
Gaborfiltering
[19]
Gaborfiltering
[19]
◦ Minutiae and ridge structure models are implemented independently.◦ Cannot control number and location of minutiae points.◦ A large portion of the synthetic fingerprint have parallel ridges without
any minutiae points, which is uncommon in real fingerprints.◦ Can generate 100,000 (416× 560) plain fingerprint images in 24 hours.
Johnson atal. [25]
Zero-pole[34]
Gaborfiltering
[19]
Spatialdistributionmodel [17]
◦ Minutiae and ridge structure models are implemented independently.◦ Synthesized and real fingerprints have very different characteristics.◦ Synthesized 2,400 plain fingerprints.
Zhao at al.[38]
Zero-pole[34]
AM-FMmodel[27]
Spatialdistributionmodel [17]
◦ Minutiae and ridge structure models are implemented independently.◦ Synthesized and real fingerprints have very different characteristics.◦ Generated 5,000 rolled fingerprints.
Bontrageret al. [11]
Wasserstein GAN (WGAN) [8]◦ 128x128 partial fingerprint patches are generated.◦ Synthesized fingerprints have unrealistic ridge orientation fields.
Cao et al.[13]
Improved WGAN [24] with weightinitialization from Convolutional
Autoencoder (CAE) [28]
◦ No fingerprint distinctiveness measure is included in the loss function.◦ Synthesized 10 million rolled fingerprint images of size 512× 512.◦ Evaluated quality, distinctiveness and minutiae count on 2,000 generated
fingerprints only.
Attia et al.[9]
Variational Autoencoder (VAE) [26, 32]◦ No evaluation on fingerprint quality and distinctiveness.◦ Since only 800 unique fingerprints were used for training, VAE was not
able to learn the complete distribution of real fingerprints.
Proposedapproach
Improved WGAN [24] with weightinitialization from Convolutional
Autoencoder (CAE) [28]. Identity lossfor generating more distinct fingerprints.
◦ Implemented identity loss to generate more distinct fingerprints.◦ Synthesized 100 million rolled fingerprint images of size 512 × 512, ap-
proaching the size of operational datasets.◦ Synthesized and real fingerprints have similar characteristics with respect
to fingerprint quality (NFIQ).
Table 1: A summary of fingerprint synthesis approaches reported in the literature.
1. Introduction
Nehemiah Grew published the first scientific paper onridge-valley patterns in the year 1684 [23]. Since then, fin-gerprints have become the most widely accepted humantrait for biometric recognition systems. A large part ofthis wide-spread adoption is likely due to the studies whichdemonstrate the uniqueness and persistence of friction ridgepatterns interwoven on our fingerprints (as well as on thepalms and bottom of our feet) [37, 30]. Leveraging theseproperties, large scale Automated Fingerprint IdentificationSystems (AFIS) have been deployed in law enforcementand forensics agencies, international border crossings, andnational ID systems. A few notable applications, wherelarge-scale AFIS is being used include:
(i) India’s Aadhaar Project [7] which, as of November2019, has an enrollment database of ∼1.25 billion ten-prints (as well as face and irides) of Indian residentsand receives around 30 million authentication search
requests everyday1. While Aadhaar uses ten finger-prints, 2 irides and a face image for de-duplication (i.e.,to ensure that an individual is not trying to enroll morethan once), virtually all of the authentication requestsare based on a single fingerprint, typically the right in-dex finger, to receive benefits and services.
(ii) The FBI’s Next Generation Identification (NGI) [1]which has about 67.7 million non-criminal ten-prints(as well as other biometric modalities) and 77.6 mil-lion criminal ten-prints from 140 million subjects. Itreceived over 3 million non-criminal search requestsand approximately 1 million criminal search requestsin the month of October 2019 alone.2. Most of thesesearches were based on fingerprints (either tenprints orlatents).
(iii) The Department of Homeland Security’s OBIM [5]system (Office of Biometric Identity Management),
1https://bit.ly/2YCCdKB2https://bit.ly/36n7ROP

(a)
(e)
(b)
(f)
(c)
(g)
(d)
(h)
Figure 2: Comparison of the synthetic fingerprints generated by various approaches. Fingerprints (a), (b), (c), (e), (f), and (g) were synthesized usingapproaches [15], [38], [13], [25], [11], and [9] respectively. Fingerprints (d) and (h) were synthesized using the proposed approach. Fingerprints synthesizedusing our approach have characteristics closer to that of real fingerprints in terms of fingerprint quality (NFIQ) and are more distinct than previous approaches.
which has been in operation since March 2013, collect-ing fingerprints and face images of all non-US citizensat any port of entry into the United States.
Two major requirements of large-scale fingerprint searchare: (i) high search accuracy, typically measured as rank-1retrieval and, (ii) the search must be computationally effi-cient. A number of fingerprint search algorithms have beenproposed [35, 12, 14, 20, 10], but nearly all of them wereevaluated on a gallery of at most 2,700 distinct rolled fin-gerprints from NIST SD14 [2]3. A few exceptions are: onemillion rolled fingerprints in [35], and a dataset of 250,000rolled fingerprints in [12].
Collecting a large-scale fingerprint dataset is both timeconsuming and expensive. Additionally, it requires ap-proval from the Institutional Review Board and the user’sconsent. The privacy regulations4 prohibit sharing of fin-gerprint databases from those who have already collecteda large fingerprint database. Indeed, NIST has taken downsome of their previously public fingerprint datasets (NISTSD27 [3], NIST SD14 [2], and NIST SD4 [4]) from its web-site due to privacy regulations.
Therefore, to adequately evaluate large-scale fingerprintsearch algorithms, we propose to synthesize 100 million fin-gerprints with characteristics close to those of real finger-print images.
3NIST SD14 dataset is no longer available on the NIST website.4https://bit.ly/2YD4e4A
2. Related WorkMany approaches have been proposed for the task of
synthetic fingerprint generation which are detailed in ta-ble 1. Figure 2 shows a comparison between the syn-thetic fingerprint images generated using the approaches in[9, 11, 38, 15, 13, 25] and our proposed approach. Priorapproaches suffer from various limitations which are enu-merated below:
(i) Because of the assumption of independence of minu-tiae model and the ridge structure model [15, 25, 38,6], minutiae distributions could be generated with novalid ridge orientation field.
(ii) The assumption of a fixed ridge spacing in the synthe-sis algorithms [15, 25, 6] resulted in the characteris-tics of real and synthesized prints being very different.In fact, Chen at al. [16] reported a 98% accuracy indiscriminating the real fingerprints from the syntheticfingerprints using two ridge spacing features alone.
(iii) The ridge structure model in [15, 25, 38, 6] uses a mas-terprint. Due to Gabor filtering and the AF/FM mod-els, the generated masterprints have non-consistentridge flow patterns which leads to unrealistic finger-print images.
(iv) The approaches [15, 25, 38, 6] are susceptible to gen-erating unreal minutiae configurations as the minu-

Figure 3: The architecture of the proposed fingerprint synthesis approach. Step 1 shows the training flow of the CAE, whichincludes the encoder Genc and the decoder Gdec. Step 2 illustrates the training flow of the I-WGAN (G and D) along withthe introduced identity loss. The weights of G were initialized using the trained weights of Gdec. The solid black arrowsshow the forward pass of the networks while the dotted black lines show the propagation of the losses.
tiae models do not consider local minutiae configura-tions. Gottschlich and Huckemann [22] showed thatthey achieved a classification accuracy of 100% be-tween the real and synthetic [15] fingerprints on thebasis of minutiae configurations.
(v) None of the approaches generated a fingerprint datasetof size comparable to large-scale operational datasets.
More recent approaches to fingerprint synthesis have uti-lized generative adversarial networks (GANs) [21]. Bon-trager et al. [11] used Wasserstein GAN (WGAN) [8] togenerate fake masterprint images (note here, masterprintrefers to a single fingerprint patch which can match to manyother fingerprint patches). However, the generated finger-print image size was just 128 × 128 pixels, much smallerthan the typical size of a 500 dpi fingerprint. Cao and Jain[13] used Improved-WGAN [24] to synthesize 512 × 512rolled fingerprint images. However, their approach wasshown to synthesize fingerprints that were not as distinctas real fingerprints.
To rectify the limitations of existing fingerprint synthe-sis approaches, the proposed algorithm makes the followingcontributions:
(i) Improve the fingerprint distinctiveness via the additionof an identity loss in GAN.
(ii) Synthesize a fingerprint dataset of 100 million finger-print images, the largest synthetic fingerprint datasetgenerated to date.
(iii) Extensive experimental analysis demonstrating - (a)fingerprint quality of our synthetic fingerprints isclosely aligned with that of real fingerprints and (b)our synthetic fingerprints are more “distinct” than ex-isting synthetic fingerprints.
(iv) Benchmark evaluations using the state-of-the-artDeepPrint [18] search algorithm against our 100 mil-lion synthetic fingerprint dataset. To the best of ourknowledge, this is the largest search experiment to beconducted in the open literature.
3. Proposed ApproachWe use Improved WGAN [24], also known as I-WGAN,
as the backbone of the proposed fingerprint synthesis algo-rithm. Instead of training the I-WGAN from scratch, we ini-tialize the weights of the generator using the trained weightsof the decoder of a convolutional autoencoder (CAE) in amanner similar to [12]. Our main contribution to the syn-thesis process is the introduction of an identity loss whichforces the generator to produce fingerprint images withmore distinct characteristics during training.
The architecture of the proposed approach is shown inFigure 3. The following sub-sections explain the majorcomponents of the architecture in detail.
3.1. Convolutional Autoencoder
The first step of our proposed approach involves traininga convolutional autoencoder (CAE) [28] in an unsupervised

(a)
(b)
Figure 4: Fingerprint images in (a) were generated by Gwithout weights initialization and fingerprints images in (b)were generated by G with weights initialization from Gdec.
fashion. The encoder (Genc) takes a 512 × 512 grayscaleinput image (x) and transforms it into a 512-dimensionallatent vector (z’). The decoder (Gdec) takes the latent vec-tor (z’) as input and attempts to reconstruct back the inputimage (x’). More formally, the autoencoder minimizes thereconstruction loss between x’ and x, which is shown inequation 1.
LCAE = ||x− x′||22 (1)
After training the CAE, we use the trained weights ofGdec to initialize the Generator G of the I-WGAN. Themain motive behind this is to enable G to infuse domainknowledge in it when it starts training, thus enabling it toproduce fingerprint images which are better in quality (aswas shown in [12]). Figure 4 shows a comparison betweentwo fingerprint images generated using G without and withweights initialized by Gdec.
3.2. Improved-WGAN
The architecture of I-WGAN [24] used in our approachfollows the guidelines in [31]. Both the generatorG and thediscriminatorD consist of seven convolutional layers with akernel size of 4×4 and a stride of 2×2 (Table 2). G takes a512-dimensional latent vector z∼Pz as input, where Pz is amultivariate Gaussian distribution, and outputs a 512× 512dimensional grayscale image. All the convolutional layersin G have ReLU as their activation function, except the last
Generator G/Gdec architectureType Output size Filter sizeInput 512× 1
Fully Connected 16384× 1
Reshape 4× 4× 1024
Deconvolution 8× 8× 512 4× 4
Deconvolution 16× 16× 256 4× 4
Deconvolution 32× 32× 128 4× 4
Deconvolution 64× 64× 64 4× 4
Deconvolution 128× 128× 32 4× 4
Deconvolution 256× 256× 16 4× 4
Deconvolution 512× 512× 1 4× 4
Table 2: Network architecture of the generator G/Gdec in I-WGAN. The discriminator D has an architecture which isan inverse of the architecture of G.
layer which uses tanh. The discriminator D has the inversearchitecture of the generatorG. All the convolutional layersin D use LeakyReLU as the activation function. Moreover,batch normalization is applied to all the layers of G and Dto allow for stable and faster training.
3.3. Identity Loss
In [12], the search accuracy on NIST SD4 [4] (2,000rolled fingerprint pairs) against 250K synthesized rolledfingerprints is significantly higher than that against 250Kreal rolled fingerprints. One explanation for this differ-ence in search accuracies is that no distinctiveness measurewas used during training of the synthesis generator, lead-ing to lower “diversity among the synthesized fingerprintsthan among real fingerprints. To rectify this, we introducean identity loss to encourage synthesis of more distinct orunique fingerprint images.
A recent work [18] proposed a deep network, calledDeepPrint, to extract a fixed-length representations froma fingerprint image, encoding the minutiae as well as thetexture information (i.e. the identity) of the fingerprintinto a 192-dimensional vector. Building on the same con-cept, we train MobileNetV2 [33] (F (x)) to extract a 512-dimensional feature vector from a fingerprint image (x). Wethen use this trained MobileNetV2 during the training pro-cess of the I-WGAN. For each mini-batch, we use the Mo-bileNetV2 network to extract the fixed-length representa-tions of all the fingerprint images synthesized by the gener-ator G. The similarity between each pair of representationsin the mini-batch is minimized in order to guide G to pro-duce fingerprints with different identities, i.e. more distinctfingerprints.
Formally, for each pair of fixed-length representations(x, y) in a mini-batch, the identity loss, which is given byEq. 2, is minimized.
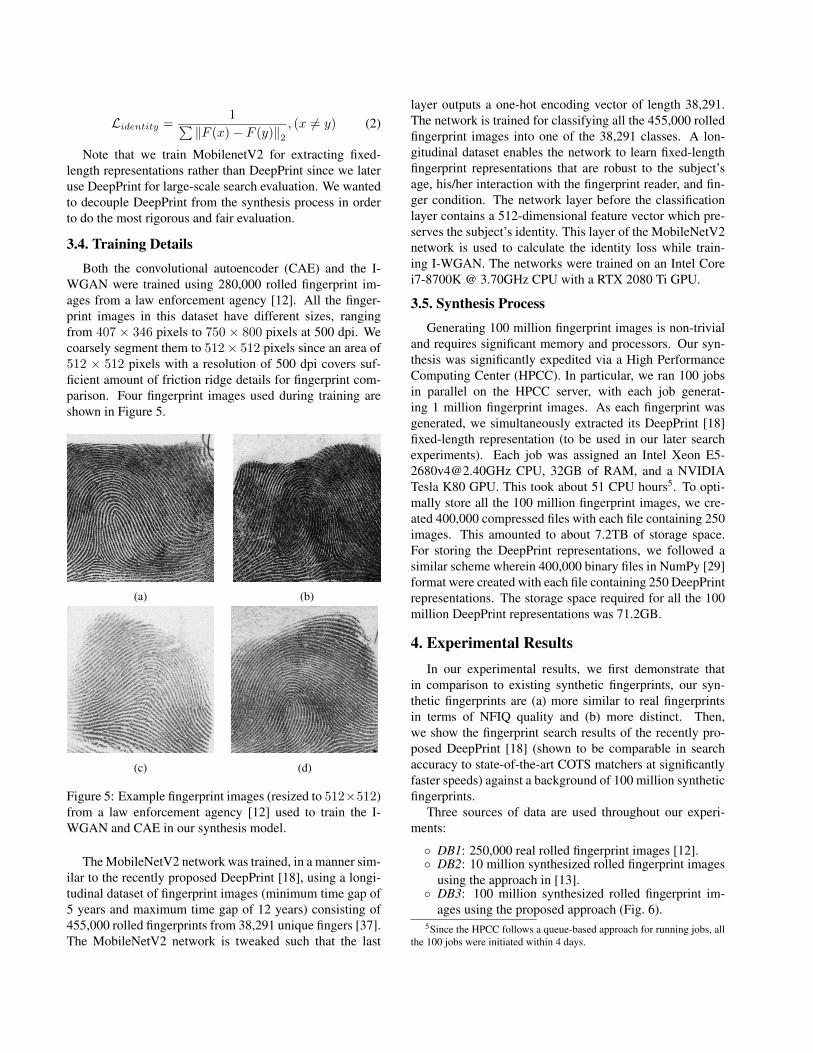
Lidentity =1∑
‖F (x)− F (y)‖2, (x 6= y) (2)
Note that we train MobilenetV2 for extracting fixed-length representations rather than DeepPrint since we lateruse DeepPrint for large-scale search evaluation. We wantedto decouple DeepPrint from the synthesis process in orderto do the most rigorous and fair evaluation.
3.4. Training Details
Both the convolutional autoencoder (CAE) and the I-WGAN were trained using 280,000 rolled fingerprint im-ages from a law enforcement agency [12]. All the finger-print images in this dataset have different sizes, rangingfrom 407 × 346 pixels to 750 × 800 pixels at 500 dpi. Wecoarsely segment them to 512× 512 pixels since an area of512 × 512 pixels with a resolution of 500 dpi covers suf-ficient amount of friction ridge details for fingerprint com-parison. Four fingerprint images used during training areshown in Figure 5.
(a) (b)
(c) (d)
Figure 5: Example fingerprint images (resized to 512×512)from a law enforcement agency [12] used to train the I-WGAN and CAE in our synthesis model.
The MobileNetV2 network was trained, in a manner sim-ilar to the recently proposed DeepPrint [18], using a longi-tudinal dataset of fingerprint images (minimum time gap of5 years and maximum time gap of 12 years) consisting of455,000 rolled fingerprints from 38,291 unique fingers [37].The MobileNetV2 network is tweaked such that the last
layer outputs a one-hot encoding vector of length 38,291.The network is trained for classifying all the 455,000 rolledfingerprint images into one of the 38,291 classes. A lon-gitudinal dataset enables the network to learn fixed-lengthfingerprint representations that are robust to the subject’sage, his/her interaction with the fingerprint reader, and fin-ger condition. The network layer before the classificationlayer contains a 512-dimensional feature vector which pre-serves the subject’s identity. This layer of the MobileNetV2network is used to calculate the identity loss while train-ing I-WGAN. The networks were trained on an Intel Corei7-8700K @ 3.70GHz CPU with a RTX 2080 Ti GPU.
3.5. Synthesis Process
Generating 100 million fingerprint images is non-trivialand requires significant memory and processors. Our syn-thesis was significantly expedited via a High PerformanceComputing Center (HPCC). In particular, we ran 100 jobsin parallel on the HPCC server, with each job generat-ing 1 million fingerprint images. As each fingerprint wasgenerated, we simultaneously extracted its DeepPrint [18]fixed-length representation (to be used in our later searchexperiments). Each job was assigned an Intel Xeon [email protected] CPU, 32GB of RAM, and a NVIDIATesla K80 GPU. This took about 51 CPU hours5. To opti-mally store all the 100 million fingerprint images, we cre-ated 400,000 compressed files with each file containing 250images. This amounted to about 7.2TB of storage space.For storing the DeepPrint representations, we followed asimilar scheme wherein 400,000 binary files in NumPy [29]format were created with each file containing 250 DeepPrintrepresentations. The storage space required for all the 100million DeepPrint representations was 71.2GB.
4. Experimental ResultsIn our experimental results, we first demonstrate that
in comparison to existing synthetic fingerprints, our syn-thetic fingerprints are (a) more similar to real fingerprintsin terms of NFIQ quality and (b) more distinct. Then,we show the fingerprint search results of the recently pro-posed DeepPrint [18] (shown to be comparable in searchaccuracy to state-of-the-art COTS matchers at significantlyfaster speeds) against a background of 100 million syntheticfingerprints.
Three sources of data are used throughout our experi-ments:
◦ DB1: 250,000 real rolled fingerprint images [12].◦ DB2: 10 million synthesized rolled fingerprint images
using the approach in [13].◦ DB3: 100 million synthesized rolled fingerprint im-
ages using the proposed approach (Fig. 6).5Since the HPCC follows a queue-based approach for running jobs, all
the 100 jobs were initiated within 4 days.

Figure 6: Examples of rolled fingerprint images (512× 512 @ 500 dpi) synthesized by our approach.
0 20 40 60 80 100NFIQ 2.0 Scores
0.000
0.005
0.010
0.015
0.020
0.025
0.030
Prob
abilit
y of
occ
uren
ce
DB1DB2DB3
Figure 7: Plots of the NFIQ 2.0 values for DB1, DB2and DB3. NFIQ 2.0 ranges from [0,100], with 0 being thelowest score (poor quality) and 100 being the highest score(good quality).
4.1. Fingerprint Quality
NFIQ 2.0 [36] is an open source fingerprint quality soft-ware. For a fingerprint image, NFIQ 2.0 outputs a qualityscore between [0,100], with 0 being the lowest score and100 being the highest score. For evaluating the fingerprintquality of real fingerprint images inDB1, and synthetic im-ages by [13] in DB2 and the proposed approach in DB3,we sampled 10,000 random fingerprint images from each ofthe three databases and computed their NFIQ 2.0 scores.
Figure 7 shows the plot of the NFIQ 2.0 values forDB1,DB2 and DB3. The mean and standard deviation (µ, σ) of
the NFIQ 2.0 scores for DB1, DB2 and DB3 are (53.9,23.4), (62.8, 14.8), and (46.0, 21.3), respectively. Fig. 7shows that the synthetic images based on the proposed ap-proach (DB3) have quality scores closer to that of the realfingerprints (DB1) than synthetic fingerprints in DB2.
4.2. Fingerprint Uniqueness
Our first fingerprint search experiment is aimed at mea-suring the diversity of fingerprints in our synthetic dataset(and also to compare that diversity to real fingerprints andprevious approaches to synthetic fingerprints generation).To evaluate the distinctiveness of our synthetic fingerprints,we perform fingerprint search using 2,000 probes fromNIST SD4 [4] against galleries of different sizes. We aug-ment the 2,000 NIST SD4 gallery with subsets of DB1,DB2 and DB3 each in increasing gallery sizes of 10K,50K, 100K and 250K fingerprints. DeepPrint [18], a state-of-the-art fingerprint matcher was used to match the NISTSD4 probes to the augmented gallery. Fig. 8 comparesthe rank-1 search accuracy of DeepPrint on datasets DB1,DB2 and DB3 at varying gallery sizes.
It can be observed from Fig. 8 that, as expected, thereis a decrease in rank-1 search accuracy as the gallery sizeincreases (both for real fingerprints and synthetic finger-prints). We note that real fingerprints are more unique thanboth synthetic fingerprint datasets since the rank-1 accu-racy is the lowest when using real fingerprints in the gallery.However, we also note that the synthetic fingerprints fromour approach (DB3) result in lower DeepPrint search accu-racy than DB2. This implies that the synthetic fingerprintsin DB3 (our proposed approach) are more diverse than thesynthetic fingerprints in DB2. In other words, adding the

Figure 8: Rank-1 fingerprint search accuracy of DeepPrint[18] on datasets DB1, DB2 and DB3 with gallery sizes of10K, 50K, 100K, and 250K.
identity loss helped us close some of the gap between realfingerprint distinctiveness and synthetic fingerprint distinc-tiveness.
4.3. Fingerprint Search Against 100 Million
Existing literature on fingerprint synthesis, apparently,did not have the necessary resources to search against large-scale fingerprint datasets. One of the main limiting fac-tors is the search speed of existing fingerprint search algo-rithms. However, the fixed-length matcher, DeepPrint [18],now enables us to measure the fingerprint matching accu-racy against galleries as large as 100 million without an in-ordinate amount of computational resources (search against100 million takes ≈ 11 seconds [18]). Therefore, in thispaper, we not only synthesize fingerprints (like others in theliterature), but we also scale the synthesis to 100 millionand we actually show the search performance against thelarge-scale synthesized gallery.
Figure 9 shows the plot of rank-N search accuracies for arange of values of N ∈ [1, 500]. The rank-1, rank-100, andrank-500 search accuracies on a gallery of 100 million fin-gerprints are 91.4%, 97.2%, and 97.85%, respectively. Asexpected, the rank-1 search accuracy decreases by 8% as thegallery size increases from 250K to 100M. The rank-1 ac-curacy of 91.4% is promising, but leaves room for improve-ment. Since DeepPrint performed similarly to top-COTSmatchers on a gallery of 1 million real fingerprints in [18],we posit that DeepPrint and by extension COTS matchershave room for improvement with galleries of hundreds ofmillions or even billions of fingerprints (e.g. Aadhaar). Thiswill be an active research direction for us in the future. Notethat we could not evaluate COTS against 100 million due tothe inadequate speed of the matchers (about 210 CPU hours
1 100 200 300 400 500N
92
93
94
95
96
97
98
Rank
-N S
earc
h Ac
cura
cy (%
)
Figure 9: Rank-N fingerprint search accuracies for the aug-mented gallery of 100 million fingerprints using DeepPrint[18] as the fingerprint matcher.
for a rank-1 search on a gallery size of 100 million imagesas compared to 11s for DeepPrint)
5. Conclusions
There are no large-scale fingerprint datasets in the pub-lic domain due to stringent privacy laws and regulations.This necessitates the development of synthetic fingerprintswhose characteristics are similar to real fingerprints. Wepropose an I-WGAN modeled with an identity loss to gen-erate diverse and realistic 512 × 512 rolled fingerprint im-ages. The properties of the synthetic fingerprint images byour method closely mimics the properties of the real finger-prints in terms of fingerprint quality. The synthetic finger-prints are also more diverse than existing synthetic finger-prints. To the best of our knowledge, we show for the firsttime in the literature that a synthetic fingerprint dataset of100 million prints is generated for conducting large scalesearch. Our fingerprint synthesis approach takes approx-imately 17.5 CPU hours to synthesize 100 million finger-print images. We further show that by using state-of-the-art DeepPrint matcher, the rank-1 search accuracy decreasesfrom 97.4% to 91.4% as the gallery size is increased from250K to 100M images. Our ongoing work addresses: (i)pushing the size of the synthetic fingerprint dataset to 1 bil-lion or even more, and (ii) to further enhance the individu-ality of synthesized fingerprints.
References
[1] Next Generation Identification (NGI). https://www.fbi.gov/services/cjis/fingerprints-and-other-biometrics/ngi.

[2] NIST Special Database 14. https://www.nist.gov/srd/nist-special-database-14.
[3] NIST Special Database 27. https://www.nist.gov/itl/iad/image-group/nist-special-database-2727a.
[4] NIST Special Database 4. https://www.nist.gov/srd/nist-special-database-4.
[5] Office of Biometric Identity Management. https://www.dhs.gov/obim.
[6] SFinGe (Synthetic Fingerprint Generator). http://biolab.csr.unibo.it/research.asp?organize=Activities&select=&selObj=12&pathSubj=111%7C%7C12&.
[7] Unique Identification Authority of India. https://uidai.gov.in.
[8] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein GAN.CoRR, 2017.
[9] M. Attia, M. H. Attia, J. Iskander, K. Saleh, D. Nahavandi,A. Abobakr, M. Hossny, and S. Nahavandi. Fingerprint Syn-thesis Via Latent Space Representation. In 2019 IEEE In-ternational Conference on Systems, Man and Cybernetics(SMC).
[10] B. Bhanu and X. Tan. Fingerprint Indexing Based on NovelFeatures of Minutiae Triplets. IEEE Transactions on PatternAnalysis and Machine Intelligence, 2003.
[11] P. Bontrager, A. Roy, J. Togelius, N. D. Memon, and A. Ross.DeepMasterPrints: Generating MasterPrints for DictionaryAttacks via Latent Variable Evolution. In 9th IEEE BTAS2018.
[12] K. Cao and A. K. Jain. Fingerprint indexing and matching:An integrated approach. In IEEE International Joint Confer-ence on Biometrics, IJCB, 2017.
[13] K. Cao and A. K. Jain. Fingerprint Synthesis: EvaluatingFingerprint Search at Scale. In International Conference onBiometrics, ICB, 2018.
[14] R. Cappelli, M. Ferrara, and D. Maltoni. Fingerprint Index-ing Based on Minutia Cylinder-Code. IEEE Transactions onPattern Analysis and Machine Intelligence, 2011.
[15] R. Cappelli, D. Maio, and D. Maltoni. Synthetic Fingerprint-Database Generation. In 16th International Conference onPattern Recognition, ICPR, 2002.
[16] S. Chen, S. Chang, Q. Huang, J. He, H. Wang, andQ. Huang. SVM-Based Synthetic Fingerprint DiscriminationAlgorithm and Quantitative Optimization Strategy. PLOSONE, 2014.
[17] Y. Chen and A. K. Jain. Beyond Minutiae: A FingerprintIndividuality Model with Pattern, Ridge and Pore Features.In Advances in Biometrics, 2009.
[18] J. J. Engelsma, K. Cao, and A. K. Jain. Learning a Fixed-Length Fingerprint Representation. to appear in IEEE Trans-actions on Pattern Analysis and Machine Intelligence, 2019.
[19] I. Fogel and D. Sagi. Gabor filters as texture discriminator.Biological Cybernetics, 1989.
[20] R. S. Germain, A. Califano, and S. Colville. Fingerprintmatching using transformation parameter clustering. IEEEComputational Science and Engineering, 1997.
[21] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu,D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Gen-erative Adversarial Nets. In Z. Ghahramani, M. Welling,C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors,Advances in NeurIPS 27, 2014.
[22] C. Gottschlich and S. Huckemann. Separating the real fromthe synthetic: minutiae histograms as fingerprints of finger-prints. IET Biometrics, 2014.
[23] N. Grew. The description and use of the pores in the skin ofthe bands and feet. Philosophical Transactions of the RoyalSociety of London, 1684.
[24] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. C.Courville. Improved Training of Wasserstein GANs. CoRR,abs/1704.00028, 2017.
[25] P. A. Johnson, F. Hua, and S. A. C. Schuckers. Texture Mod-eling for Synthetic Fingerprint Generation. In CVPR Work-shops, 2013.
[26] D. P. Kingma and M. Welling. Auto-Encoding VariationalBayes. CoRR, 2013.
[27] K. Larkin and P. Fletcher. A coherent framework for finger-print analysis: are fingerprints holograms? Optics express,2007.
[28] J. Masci, U. Meier, D. Ciresan, and J. Schmidhuber. StackedConvolutional Auto-encoders for Hierarchical Feature Ex-traction. In Proceedings of the 21th International Conferenceon Artificial Neural Networks, 2011.
[29] T. E. Oliphant. A Guide to NumPy. Trelgol Publishing USA,2006.
[30] S. Pankanti, S. Prabhakar, and A. K. Jain. On the individu-ality of fingerprints. IEEE Transactions on Pattern Analysisand Machine Intelligence, 2002.
[31] A. Radford, L. Metz, and S. Chintala. Unsupervised Rep-resentation Learning with Deep Convolutional GenerativeAdversarial Networks. In 4th International Conference onLearning Representations, ICLR, 2016.
[32] D. J. Rezende, S. Mohamed, and D. Wierstra. StochasticBackpropagation and Approximate Inference in Deep Gener-ative Models. In Proceedings of the 31st International Con-ference on Machine Learning, 2014.
[33] M. Sandler, A. G. Howard, M. Zhu, A. Zhmoginov, andL. Chen. MobileNetV2: Inverted Residuals and Linear Bot-tlenecks. In CVPR 2018.
[34] B. Sherlock and D. Monro. A model for interpreting finger-print topology. Pattern Recognition, 1993.
[35] Y. Su, J. Feng, and J. Zhou. Fingerprint indexing with poseconstraint. Pattern Recognition, 2016.
[36] E. Tabassi. NFIQ 2.0: NIST Fingerprint image quality. NIS-TIR 8034, 2016.
[37] S. Yoon and A. K. Jain. Longitudinal study of fingerprintrecognition. Proceedings of the National Academy of Sci-ences, 2015.
[38] Q. Zhao, A. K. Jain, N. G. Paulter Jr., and M. Taylor. Finger-print image synthesis based on statistical feature models. InIEEE BTAS 2012.