message passing interface (mpi) 3
DESCRIPTION
Amit Majumdar Scientific Computing Applications Group San Diego Supercomputer Center Tim Kaiser (now at Colorado School of Mines). Message Passing Interface (MPI) 3. MPI 3 Lecture Overview. Collective Communications Advanced Topics “V” Operations Derived Data Types Communicators. - PowerPoint PPT PresentationTRANSCRIPT

Message Passing Interface (MPI) 3
Amit MajumdarScientific Computing Applications Group
San Diego Supercomputer CenterTim Kaiser (now at Colorado School of Mines)

2
MPI 3 Lecture Overview
• Collective Communications
• Advanced Topics– “V” Operations
– Derived Data Types
– Communicators
3
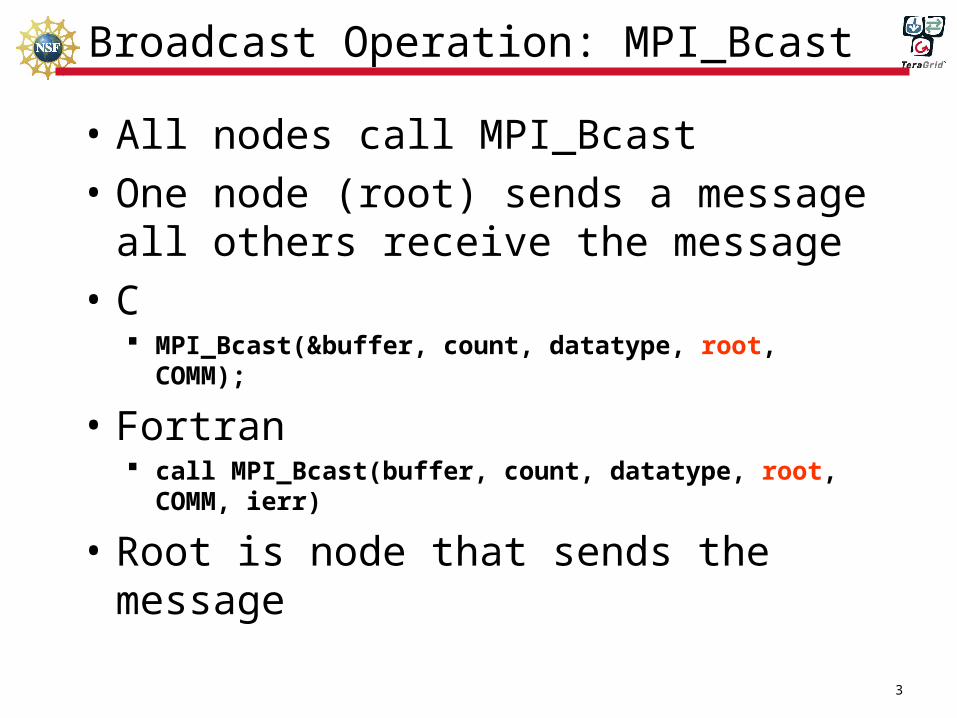
Broadcast Operation: MPI_Bcast
• All nodes call MPI_Bcast
• One node (root) sends a message all others receive the message
• C MPI_Bcast(&buffer, count, datatype, root, COMM);
• Fortran call MPI_Bcast(buffer, count, datatype, root, COMM, ierr)
• Root is node that sends the message

4
Broadcast Example
• Write a parallel program to broadcast data using MPI_Bcast– Initialize MPI – Have processor 0 broadcast an integer – Have all processors print the data – Quit MPI
5
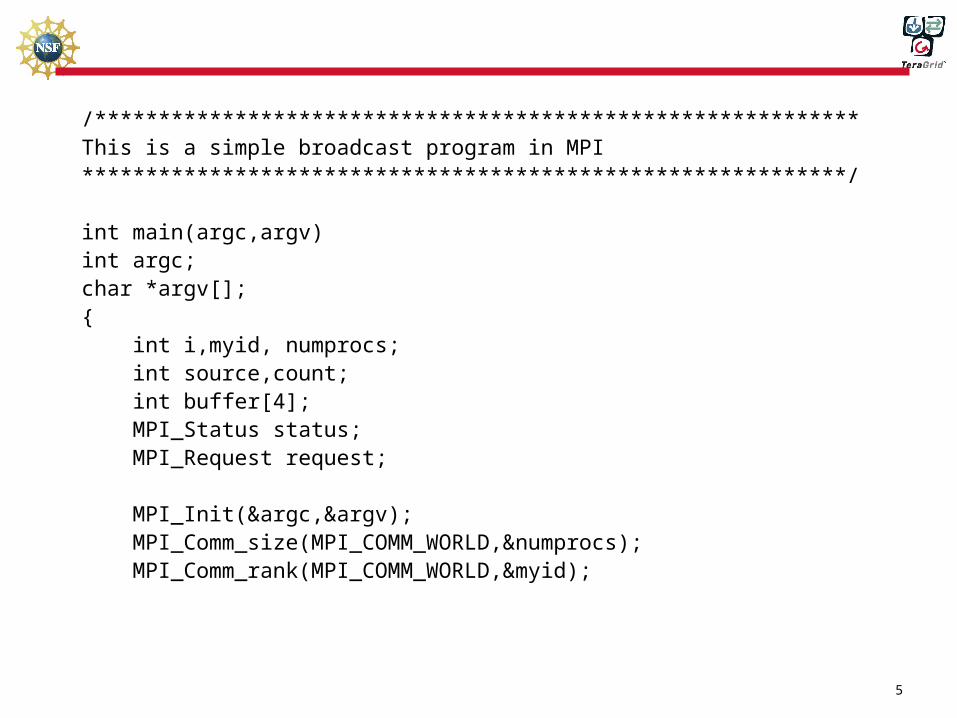
/************************************************************This is a simple broadcast program in MPI************************************************************/
int main(argc,argv)int argc;char *argv[];{ int i,myid, numprocs; int source,count; int buffer[4]; MPI_Status status; MPI_Request request; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid);

6
source=0;
count=8;
if(myid == source){
for(i=0;i<count;i++)
buffer[i]=i;
}
MPI_Bcast(buffer,count,MPI_INT,source,MPI_COMM_WORLD);
for(i=0;i<count;i++)
printf("%d ",buffer[i]);
printf("\n");
MPI_Finalize();
}
7
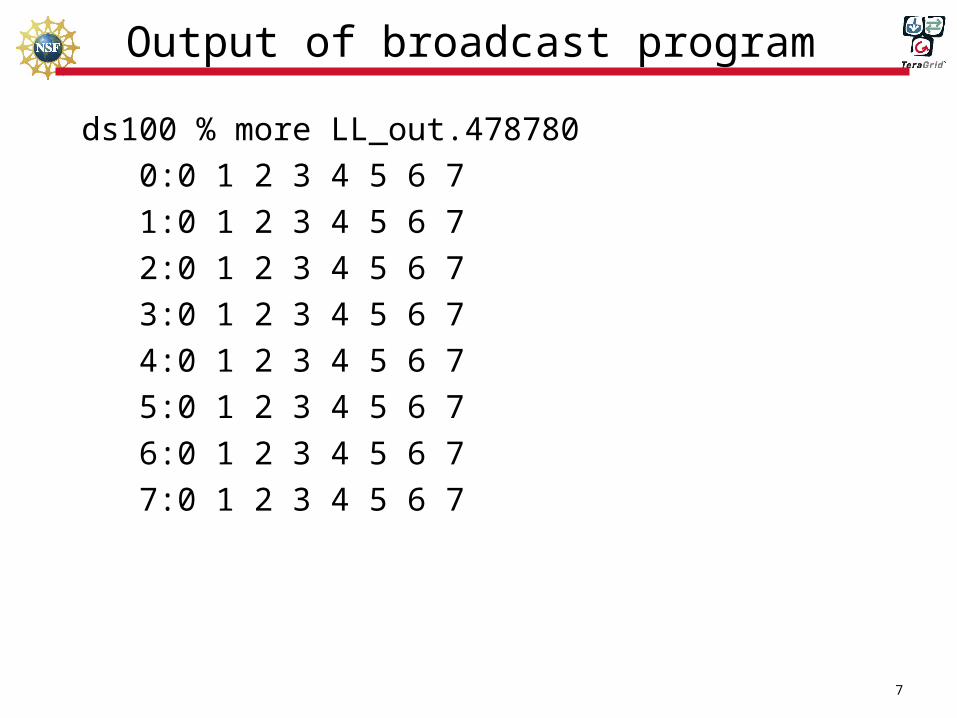
Output of broadcast program
ds100 % more LL_out.478780
0:0 1 2 3 4 5 6 7
1:0 1 2 3 4 5 6 7
2:0 1 2 3 4 5 6 7
3:0 1 2 3 4 5 6 7
4:0 1 2 3 4 5 6 7
5:0 1 2 3 4 5 6 7
6:0 1 2 3 4 5 6 7
7:0 1 2 3 4 5 6 7

8
Reduction Operations
• Used to combine partial results from all processors
• Result returned to root processor
• Several types of operations available
• Works on single elements and arrays

9
MPI_Reduce
• C – int MPI_Reduce(&sendbuf, &recvbuf, count, datatype, operation,root, communicator)
• Fortran – call MPI_Reduce(sendbuf, recvbuf, count, datatype, operation,root, communicator, ierr)
• Parameters– Like MPI_Bcast, a root is specified. – Operation is a type of mathematical operation

10
Operations for MPI_Reduce
MPI_MAX Maximum MPI_MIN Minimum MPI_PROD Product MPI_SUM Sum MPI_LAND Logical and MPI_LOR Logical or MPI_LXOR Logical exclusive or MPI_BAND Bitwise and MPI_BOR Bitwise or MPI_BXOR Bitwise exclusive or MPI_MAXLOC Maximum value and location MPI_MINLOC Minimum value and location

11
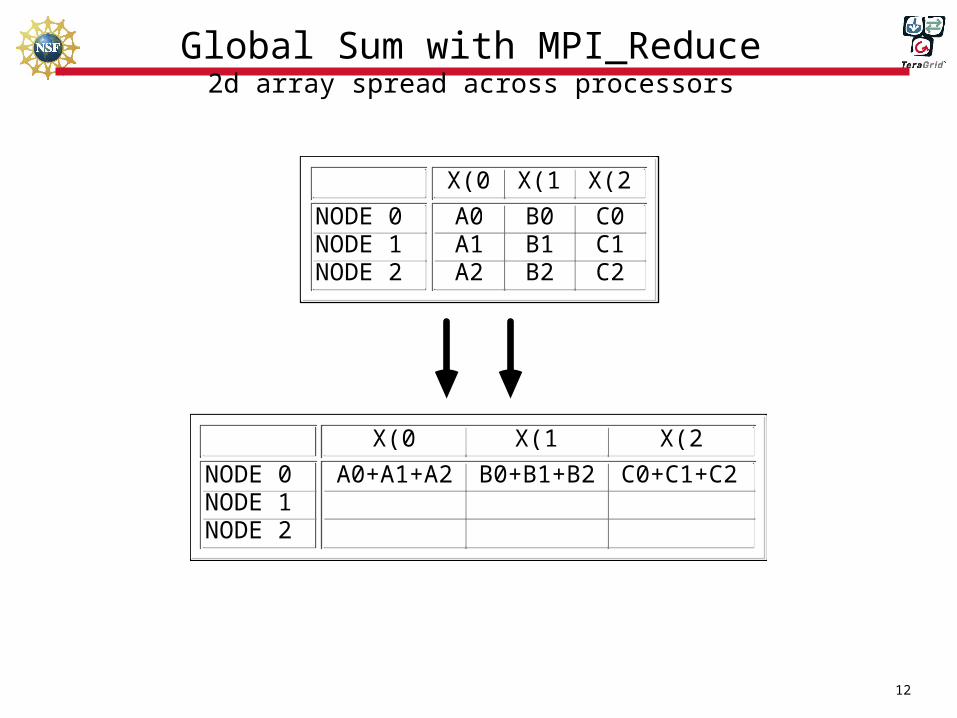
Global Sum with MPI_Reduce
C double sum_partial, sum_global;sum_partial = ...;
ierr = MPI_Reduce(&sum_partial, &sum_global, 1, MPI_DOUBLE, MPI_SUM,root, MPI_COMM_WORLD);Fortran
double precision sum_partial, sum_global sum_partial = ... call MPI_Reduce(sum_partial, sum_global, 1, MPI_DOUBLE_PRECISION, MPI_SUM,root, MPI_COMM_WORLD, ierr)
12
Global Sum with MPI_Reduce2d array spread across processors
A0+A1+A2 B0+B1+B2 C0+C1+C2NODE 0NODE 1NODE 2
X(0) X(1) X(2)
A0 B0 C0A1 B1 C1A2 B2 C2
NODE 0NODE 1NODE 2
X(0) X(1) X(2)
13
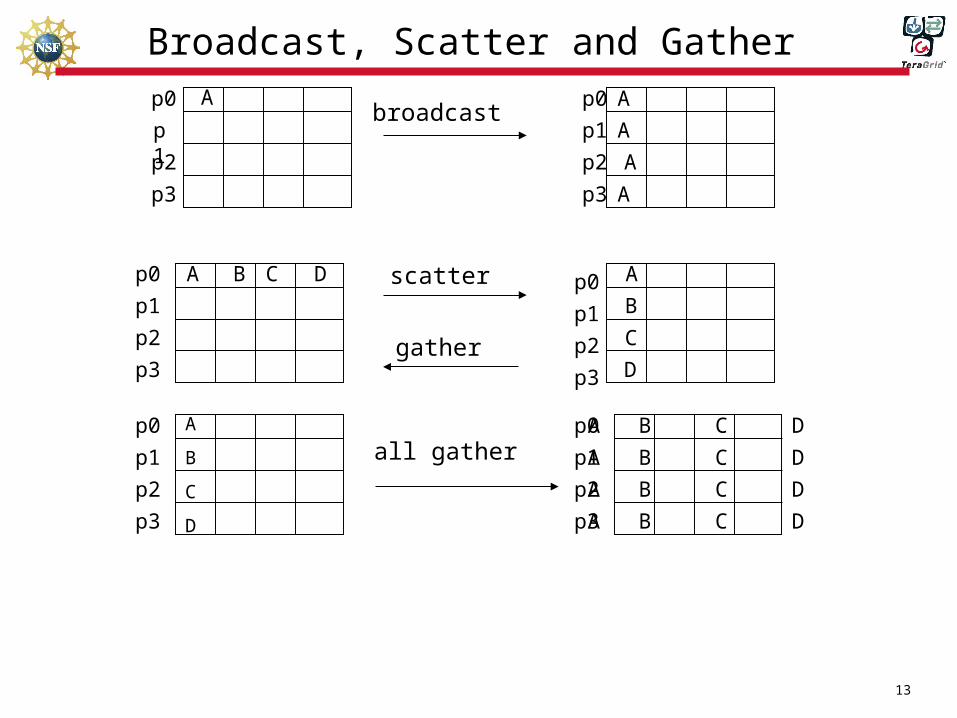
Broadcast, Scatter and Gather A Ap0
p1
p2
p3
p0
p1
p2
p3
A
A
A
broadcast
scatterA B C D A
B
C
Dgather
A
B
C
D
A B C D
A B C D
A B C D
A B C D
all gather
p0
p1
p2
p3
p0
p1
p2
p3
p0
p1
p2
p3
p0
p1
p2
p3

14
Scatter Operation using MPI_Scatter
• Similar to Broadcast but sends a section of an array to each processors
A(0) A(1) A(2) . . ………. A(N-1)
P0 P1 P2 . . . Pn-1
Goes to processors:
Data in an array on root node:

15
MPI_Scatter
• C – int MPI_Scatter(&sendbuf, sendcnts, sendtype, &recvbuf,
recvcnts, recvtype, root, comm );
• Fortran – MPI_Scatter(sendbuf,sendcnts,sendtype,
recvbuf,recvcnts,recvtype,root,comm,ierror)
• Parameters– sendbuf is an array of size (number processors*sendcnts)
– sendcnts number of elements sent to each processor
– recvcnts number of element(s) obtained from the root processor
– recvbuf contains element(s) obtained from the root processor, may be an array

16
Scatter Operation using MPI_Scatter
• Scatter with Sendcnts = 2
A(0) A(2) A(4) . . . A(2N-2) A(1) A(3) A(5) . . . A(2N-1)
P0 P1 P2 . . . Pn-1
B(0) B(0) B(0) B(0)B(1) B(1) B(1) B(1)
Goes to processors:
Data in an array on root node:

17
Global Sum Example with MPI_Reduce
• Example program to sum data from all processors

18
#include <mpi.h>#include <stdio.h>#include <stdlib.h>/*! This program shows how to use MPI_Scatter and
MPI_Reduce! Each processor gets different data from the root
processor by way of MPI_Scatter. ! The data is summed and then sent back! to the root processor using MPI_Reduce. The root
processor then prints the global sum. *//* globals */int numnodes,myid,mpi_err;#define mpi_root 0/* end globals */

19
void init_it(int *argc, char ***argv);
void init_it(int *argc, char ***argv) { mpi_err = MPI_Init(argc,argv); mpi_err = MPI_Comm_size( MPI_COMM_WORLD, &numnodes ); mpi_err = MPI_Comm_rank(MPI_COMM_WORLD, &myid);}
int main(int argc,char *argv[]){ int *myray,*send_ray,*back_ray; int count; int size,mysize,i,k,j,total,gtotal; init_it(&argc,&argv);/* each processor will get count elements from the root */ count=4; myray=(int*)malloc(count*sizeof(int));

20
/* create the data to be sent on the root */ if(myid == mpi_root){ size=count*numnodes; send_ray=(int*)malloc(size*sizeof(int)); for(i=0;i<size;i++) send_ray[i]=i; }/* send different data to each processor */ mpi_err = MPI_Scatter(send_ray, count, MPI_INT, myray,
count, MPI_INT, mpi_root, MPI_COMM_WORLD);
/* each processor does a local sum */ total=0; for(i=0;i<count;i++) total=total+myray[i]; printf("myid= %d total= %d\n ",myid,total);
21
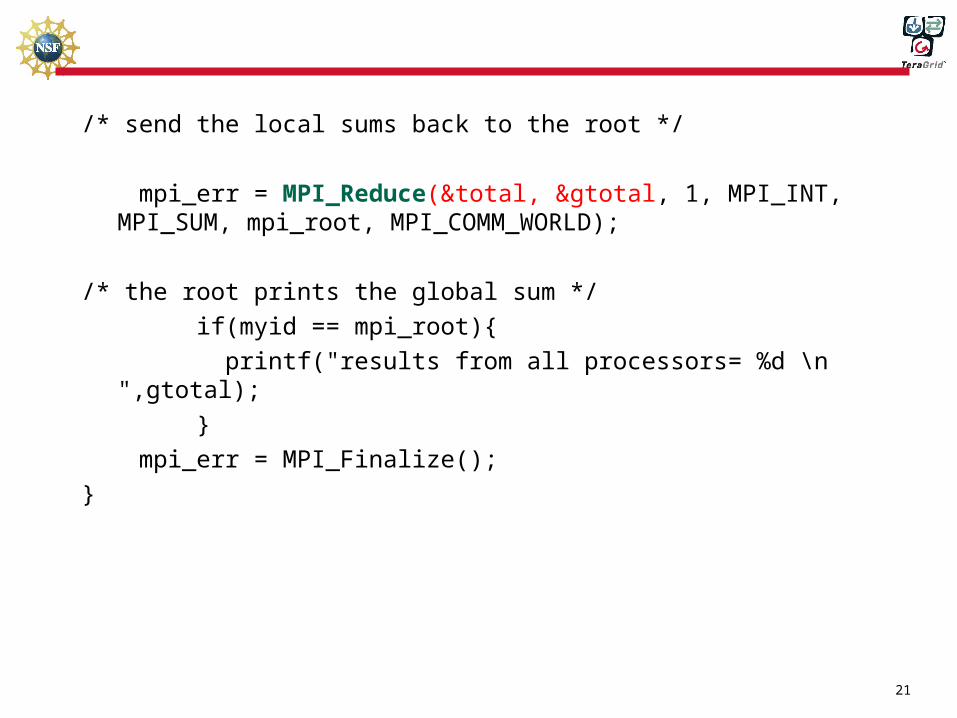
/* send the local sums back to the root */
mpi_err = MPI_Reduce(&total, >otal, 1, MPI_INT, MPI_SUM, mpi_root, MPI_COMM_WORLD);
/* the root prints the global sum */
if(myid == mpi_root){
printf("results from all processors= %d \n ",gtotal);
}
mpi_err = MPI_Finalize();
}

22
Gather Operation using MPI_Gather
• Used to collect data from all processors to the root, inverse of scatter
• Data is collected into an array on root processor
A(0) A(1) A(2) . . . A(N-1)
P0 P1 P2 . . . Pn-1
A0 A1 A2 . . . An-1
Data from variousProcessors:
Goes to an array on root node:

23
MPI_Gather
• C – int MPI_Gather(&sendbuf,sendcnts, sendtype, &recvbuf,
recvcnts,recvtype,root, comm );
• Fortran – MPI_Gather(sendbuf,sendcnts,sendtype,
recvbuf,recvcnts,recvtype,root,comm,ierror)
• Parameters– sendcnts number of elements sent from each processor
– sendbuf is an array of size sendcnts
– recvcnts number of elements obtained from each processor
– recvbuf of size recvcnts*number of processors

24
Code for Scatter and Gather
• A parallel program to scatter data using MPI_Scatter
• Each processor sums the data
• Use MPI_Gather to get the data back to the root processor
• Root processor prints the global data
• See attached Fortran and C code
25
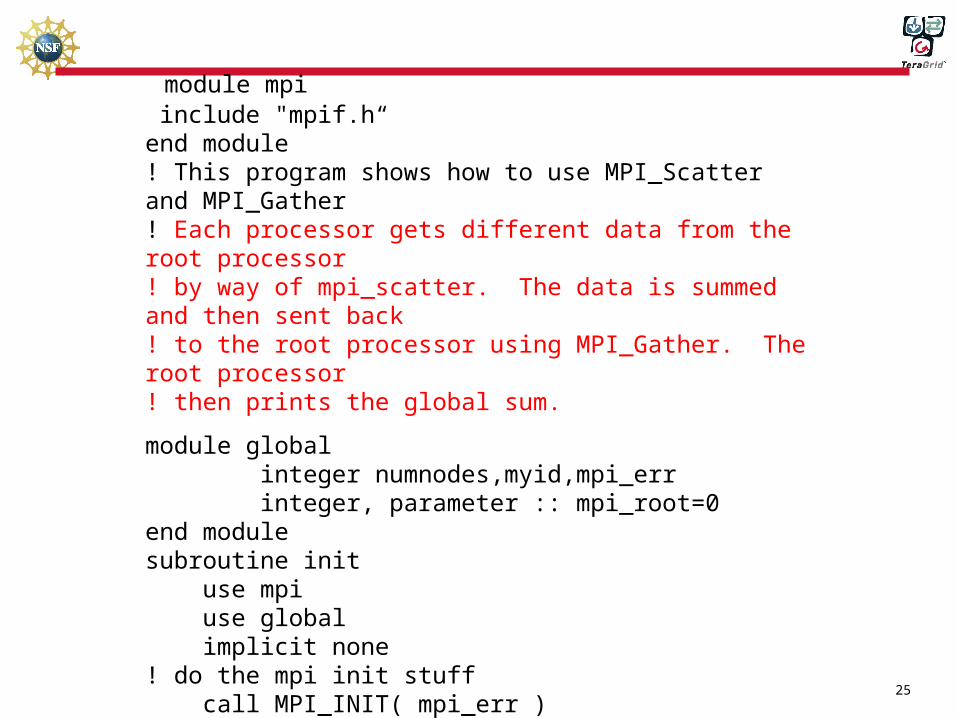
module mpi include "mpif.h“end module! This program shows how to use MPI_Scatter and MPI_Gather! Each processor gets different data from the root processor! by way of mpi_scatter. The data is summed and then sent back! to the root processor using MPI_Gather. The root processor! then prints the global sum.
module global integer numnodes,myid,mpi_err integer, parameter :: mpi_root=0end modulesubroutine init use mpi use global implicit none! do the mpi init stuff call MPI_INIT( mpi_err ) call MPI_COMM_SIZE( MPI_COMM_WORLD, numnodes, mpi_err ) call MPI_Comm_rank(MPI_COMM_WORLD, myid, mpi_err)

26
end subroutine initprogram test1 use mpi use global implicit none integer, allocatable :: myray(:),send_ray(:),back_ray(:) integer count integer size,mysize,i,k,j,total call init! each processor will get count elements from the root count=4 allocate(myray(count))! create the data to be sent on the root if(myid == mpi_root)then size=count*numnodes allocate(send_ray(0:size-1)) allocate(back_ray(0:numnodes-1)) do i=0,size-1 send_ray(i)= i enddo endif

27
call MPI_Scatter (send_ray, count, MPI_INTEGER, & myray, count, MPI_INTEGER, & mpi_root, MPI_COMM_WORLD,mpi_err)! each processor does a local sum total=sum(myray) write(*,*)"myid= ",myid," total= ",total! send the local sums back to the root call MPI_Gather ( total, 1, MPI_INTEGER, & back_ray, 1, MPI_INTEGER, & mpi_root, MPI_COMM_WORLD,mpi_err)! the root prints the global sum if(myid == mpi_root)then write(*,*)"results from all processors= ",sum(back_ray) endif call mpi_finalize(mpi_err)
end program
28
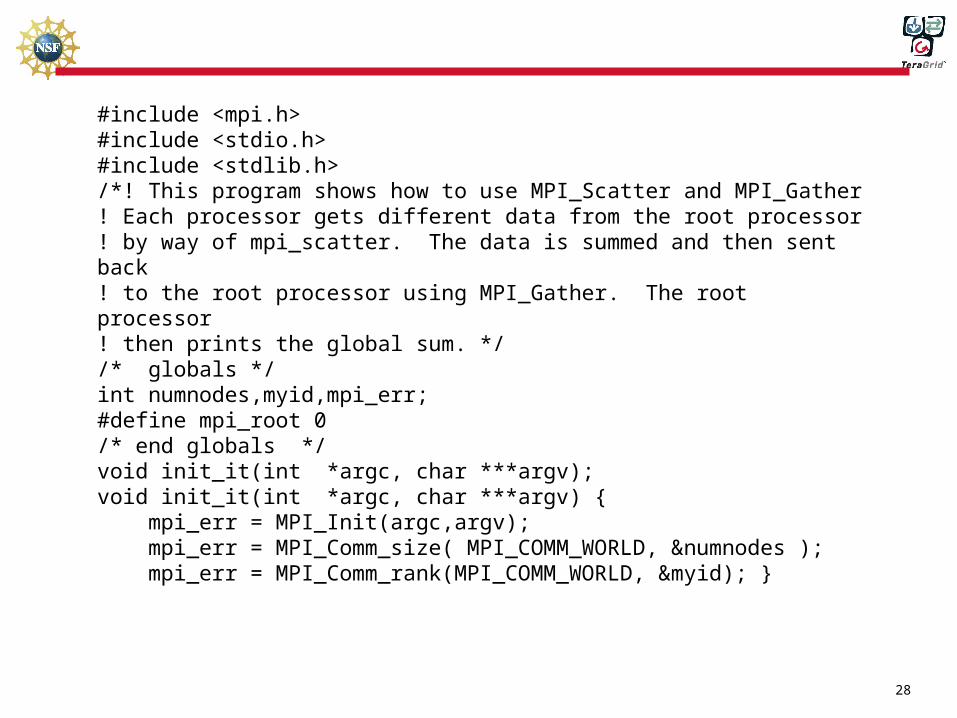
#include <mpi.h>#include <stdio.h>#include <stdlib.h>/*! This program shows how to use MPI_Scatter and MPI_Gather! Each processor gets different data from the root processor! by way of mpi_scatter. The data is summed and then sent back! to the root processor using MPI_Gather. The root processor! then prints the global sum. *//* globals */int numnodes,myid,mpi_err;#define mpi_root 0/* end globals */void init_it(int *argc, char ***argv);void init_it(int *argc, char ***argv) { mpi_err = MPI_Init(argc,argv); mpi_err = MPI_Comm_size( MPI_COMM_WORLD, &numnodes ); mpi_err = MPI_Comm_rank(MPI_COMM_WORLD, &myid); }

29
int main(int argc,char *argv[]){ int *myray,*send_ray,*back_ray; int count; int size,mysize,i,k,j,total; init_it(&argc,&argv);/* each processor will get count elements from the root */ count=4; myray=(int*)malloc(count*sizeof(int));/* create the data to be sent on the root */ if(myid == mpi_root){ size=count*numnodes; send_ray=(int*)malloc(size*sizeof(int)); back_ray=(int*)malloc(numnodes*sizeof(int)); for(i=0;i<size;i++) send_ray[i]=i; }
/* send different data to each processor */

30
mpi_err = MPI_Scatter( send_ray, count, MPI_INT, myray, count, MPI_INT, mpi_root, MPI_COMM_WORLD);/* each processor does a local sum */ total=0; for(i=0;i<count;i++) total=total+myray[i]; printf("myid= %d total= %d\n ",myid,total);/* send the local sums back to the root */ mpi_err = MPI_Gather(&total, 1, MPI_INT, back_ray, 1, MPI_INT, mpi_root, MPI_COMM_WORLD);/* the root prints the global sum */ if(myid == mpi_root){ total=0; for(i=0;i<numnodes;i++) total=total+back_ray[i]; printf("results from all processors= %d \n ",total); } mpi_err = MPI_Finalize();}
31
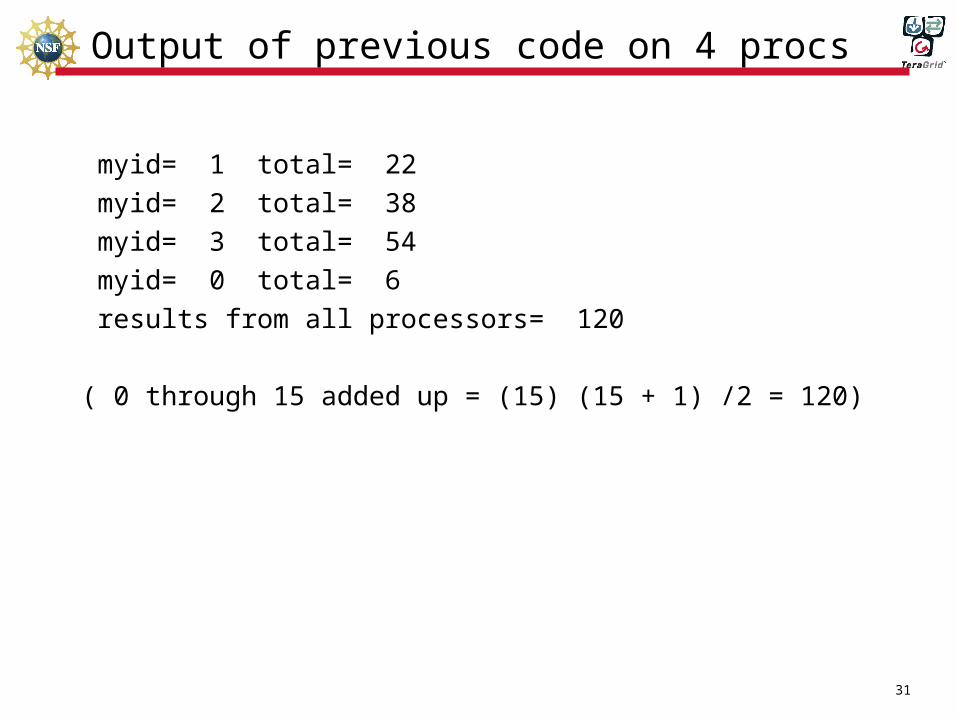
Output of previous code on 4 procs
myid= 1 total= 22
myid= 2 total= 38
myid= 3 total= 54
myid= 0 total= 6
results from all processors= 120
( 0 through 15 added up = (15) (15 + 1) /2 = 120)

32
MPI_Allgather and MPI_Allreduce
• Gather and Reduce come in an "ALL" variation• Results are returned to all processors• The root parameter is missing from the call• Similar to a gather or reduce followed by a
broadcast

33
All to All communication with MPI_Alltoall
• Each processor sends and receives data to/from all others
• C – int MPI_Alltoall(&sendbuf,sendcnts, sendtype, &recvbuf,
recvcnts, recvtype, MPI_Comm);
• Fortran – call MPI_Alltoall(sendbuf,sendcnts,sendtype,
recvbuf,recvcnts,recvtype,comm,ierror)

34
b0 b1 b2 b3c0 c1 c2 c3d0 d1 d2 d3
a0 a1 a2 a3a1 b1 c1 d1a2 b2 c2 d2a3 b3 c3 d3
a0 b0 c0 d0MPI_AlltoallP0P1P2P3
P0P1P2P3

35
All to All with MPI_Alltoall
• Parameters– sendcnts number of elements sent to each processor
– sendbuf is an array of size sendcnts
– recvcnts number of elements obtained from each processor
– recvbuf is an array of size recvcnts
• Note that both send buffer and receive buffer must be an array of size of the number of processors
• See attached Fortran and C codes

36
module mpi include "mpif.h“ end module! This program shows how to use MPI_Alltoall. Each processor! send/rec a different random number to/from other processors. module global integer numnodes,myid,mpi_err integer, parameter :: mpi_root=0end modulesubroutine init use mpi use global implicit none! do the mpi init stuff call MPI_INIT( mpi_err ) call MPI_COMM_SIZE( MPI_COMM_WORLD, numnodes, mpi_err ) call MPI_Comm_rank(MPI_COMM_WORLD, myid, mpi_err)end subroutine init

37
program test1 use mpi use global implicit none integer, allocatable :: scounts(:),rcounts(:) integer ssize,rsize,i,k,j real z call init ! counts and displacement arrays allocate(scounts(0:numnodes-1)) allocate(rcounts(0:numnodes-1)) call seed_random! find data to send do i=0,numnodes-1 call random_number(z) scounts(i)=nint(10.0*z)+1 Enddo write(*,*)"myid= ",myid," scounts= ",scounts
38
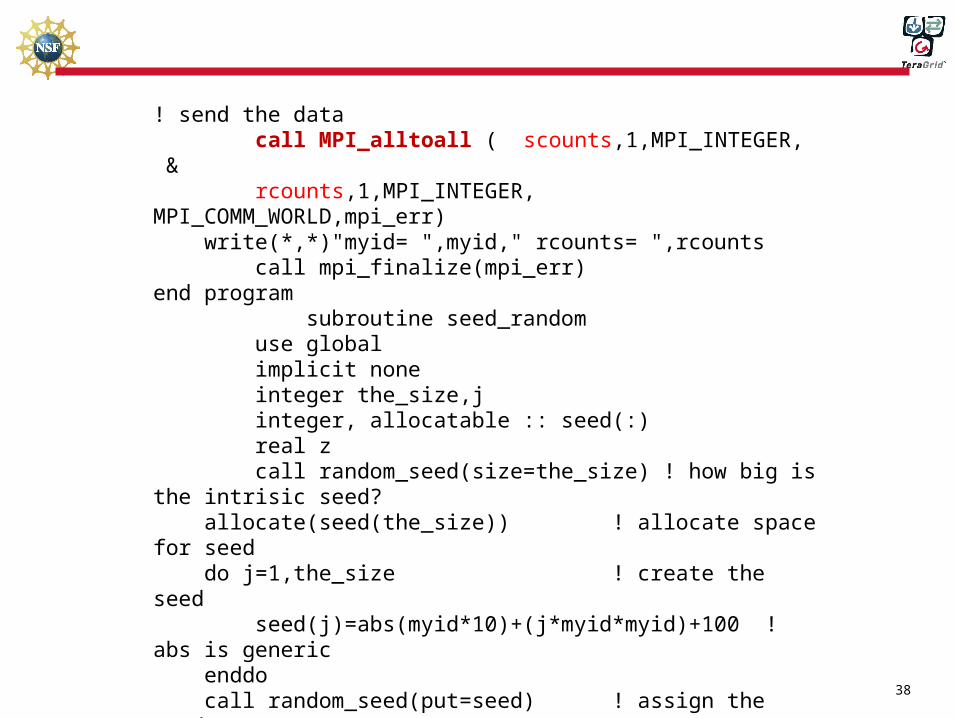
! send the data call MPI_alltoall ( scounts,1,MPI_INTEGER, & rcounts,1,MPI_INTEGER, MPI_COMM_WORLD,mpi_err) write(*,*)"myid= ",myid," rcounts= ",rcounts call mpi_finalize(mpi_err)end program subroutine seed_random use global implicit none integer the_size,j integer, allocatable :: seed(:) real z call random_seed(size=the_size) ! how big is the intrisic seed? allocate(seed(the_size)) ! allocate space for seed do j=1,the_size ! create the seed seed(j)=abs(myid*10)+(j*myid*myid)+100 ! abs is generic enddo call random_seed(put=seed) ! assign the seed deallocate(seed)end subroutine

39
#include <mpi.h>#include <stdio.h>|#include <stdlib.h>/*! This program shows how to use MPI_Alltoall. Each processor! send/rec a different random number to/from other processors. *//* globals */int numnodes,myid,mpi_err;#define mpi_root 0/* end module */void init_it(int *argc, char ***argv);void seed_random(int id);void random_number(float *z);void init_it(int *argc, char ***argv) { mpi_err = MPI_Init(argc,argv); mpi_err = MPI_Comm_size( MPI_COMM_WORLD, &numnodes ); mpi_err = MPI_Comm_rank(MPI_COMM_WORLD, &myid);}

40
int main(int argc,char *argv[]){ int *sray,*rray; int *scounts,*rcounts; int ssize,rsize,i,k,j; float z; init_it(&argc,&argv); scounts=(int*)malloc(sizeof(int)*numnodes); rcounts=(int*)malloc(sizeof(int)*numnodes); /*! seed the random number generator with a! different number on each processor*/ seed_random(myid);/* find data to send */ for(i=0;i<numnodes;i++){ random_number(&z); scounts[i]=(int)(10.0*z)+1; } printf("myid= %d scounts=",myid); for(i=0;i<numnodes;i++)
printf("%d ",scounts[i]);
printf("\n");

41
/* send the data */ mpi_err = MPI_Alltoall( scounts,1,MPI_INT, rcounts,1,MPI_INT, MPI_COMM_WORLD); printf("myid= %d rcounts=",myid); for(i=0;i<numnodes;i++) printf("%d ",rcounts[i]); printf("\n"); mpi_err = MPI_Finalize();}
void seed_random(int id){ srand((unsigned int)id);}
void random_number(float *z){ int i; i=rand(); *z=(float)i/32767;
}
42
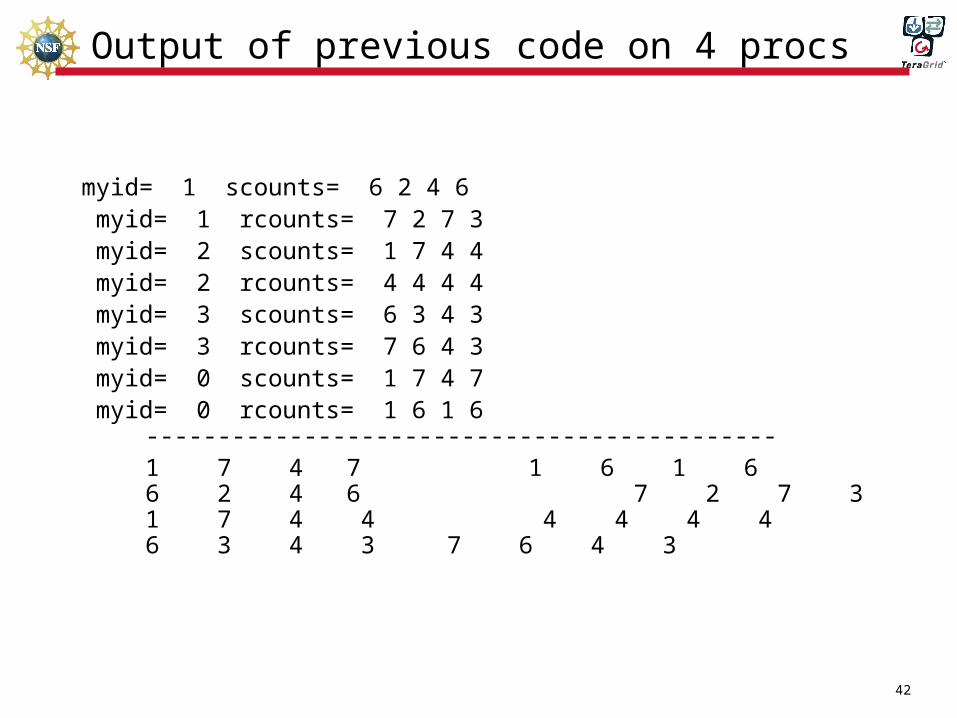
Output of previous code on 4 procs
myid= 1 scounts= 6 2 4 6 myid= 1 rcounts= 7 2 7 3 myid= 2 scounts= 1 7 4 4 myid= 2 rcounts= 4 4 4 4 myid= 3 scounts= 6 3 4 3 myid= 3 rcounts= 7 6 4 3 myid= 0 scounts= 1 7 4 7 myid= 0 rcounts= 1 6 1 6
--------------------------------------------1 7 4 7 1 6 1 66 2 4 6 7 2 7 31 7 4 4 4 4 4 46 3 4 3 7 6 4 3

43
The variable or “V” operators
• A collection of very powerful but difficult to setup global communication routines
• MPI_Gatherv: Gather different amounts of data from each processor to the root processor
• MPI_Alltoallv: Send and receive different amounts of data form all processors
• MPI_Allgatherv: Gather different amounts of data from each processor and send all data to each
• MPI_Scatterv: Send different amounts of data to each processor from the root processor
• We discuss MPI_Gatherv and MPI_Alltoallv

44
MPI_Gatherv
• C– int MPI_Gatherv (&sendbuf, sendcnts, sendtype,
&recvbuf, &recvcnts, &rdispls,recvtype, comm);
• Fortran– MPI_Gatherv (sendbuf, sendcnts, sendtype, recvbuf,
recvcnts, rdispls, recvtype, comm, ierror)
• Parameters:– Recvcnts is now an array
– Rdispls is a displacement
· See attached codes
45
MPI_Gatherv
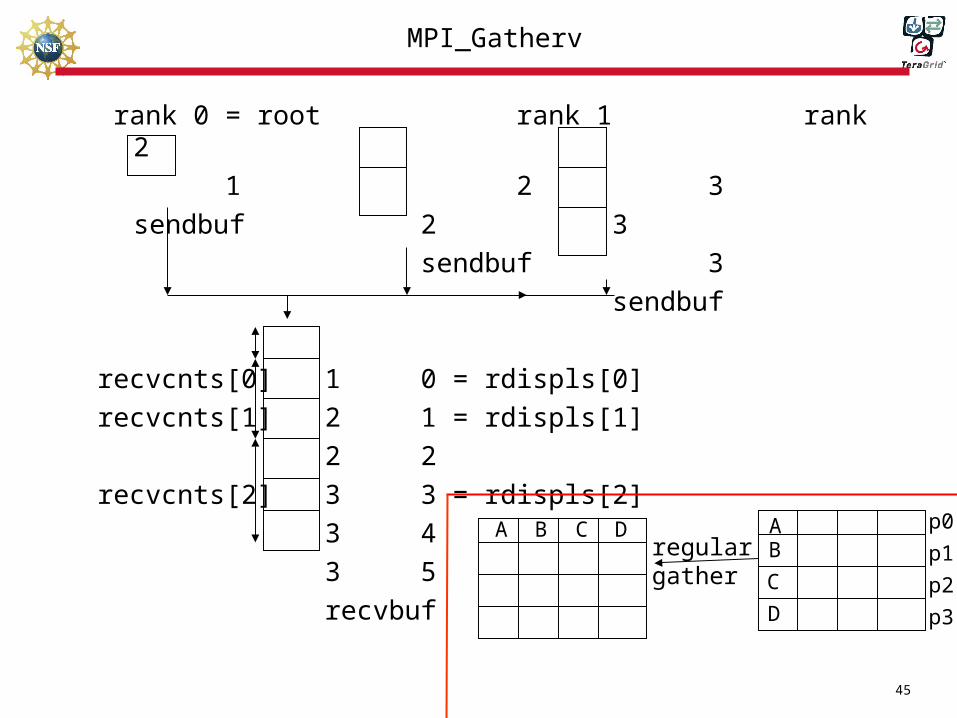
rank 0 = root rank 1 rank 2
1 2 3
sendbuf 2 3
sendbuf 3
sendbuf
recvcnts[0] 1 0 = rdispls[0]
recvcnts[1] 2 1 = rdispls[1]
2 2
recvcnts[2] 3 3 = rdispls[2]
3 4
3 5
recvbuf
B C D AB
C
D
regular gather
p0
p1
p2
p3
A

46
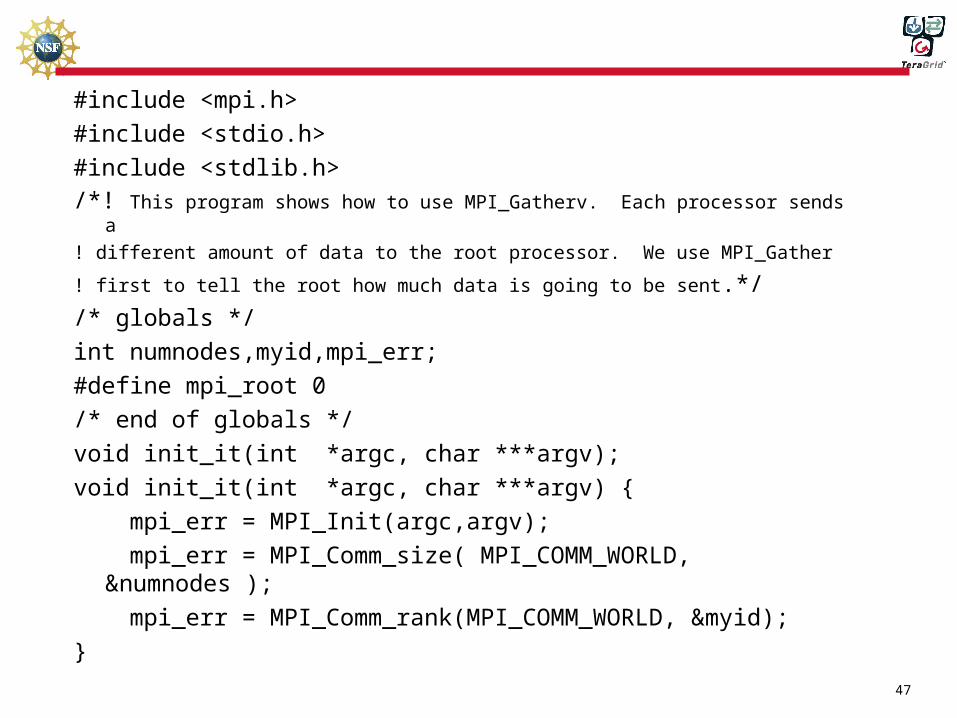
MPI_Gatherv code
Sample program:include ‘mpif.h’integer isend(3), irecv(6)integer ircnt(0:2), idisp(0:2)data ircnt/1,2,3/ idisp/0,1,3/call mpi_init(ierr)call mpi_comm_size(MPI_COMM_WORLD, nprocs,ierr)call mpi_comm_rank(MPI_COMM_WORLD,myrank,ierr)do I = 1,myrank+1
isend(I) = myrank+1enddoiscnt = myrank + 1call MPI_GATHERV(isend,iscnt,MPI_INTEGER,irecv,ircnt,idisp,MPI_INTEGER
& 0,MPI_COMM_WORLD, ierr)if (myrank .eq. 0) then
print *, ‘irecv =‘, irecvendifcall MPI_FINALIZE(ierr)end
Sample execution:% bsub –q hpc –m ultra –I –n 3 ./a.out% 0: irecv = 1 2 2 3 3 3
47
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
/*! This program shows how to use MPI_Gatherv. Each processor sends a
! different amount of data to the root processor. We use MPI_Gather
! first to tell the root how much data is going to be sent.*/
/* globals */
int numnodes,myid,mpi_err;
#define mpi_root 0
/* end of globals */
void init_it(int *argc, char ***argv);
void init_it(int *argc, char ***argv) {
mpi_err = MPI_Init(argc,argv);
mpi_err = MPI_Comm_size( MPI_COMM_WORLD, &numnodes );
mpi_err = MPI_Comm_rank(MPI_COMM_WORLD, &myid);
}

48
int main(int argc,char *argv[]){
int *will_use;
int *myray,*displacements,*counts,*allray;
int size,mysize,i;
init_it(&argc,&argv);
mysize=myid+1;
myray=(int*)malloc(mysize*sizeof(int));
for(i=0;i<mysize;i++)
myray[i]=myid+1;
/* counts and displacement arrays are only required on the root */
if(myid == mpi_root){
counts=(int*)malloc(numnodes*sizeof(int));
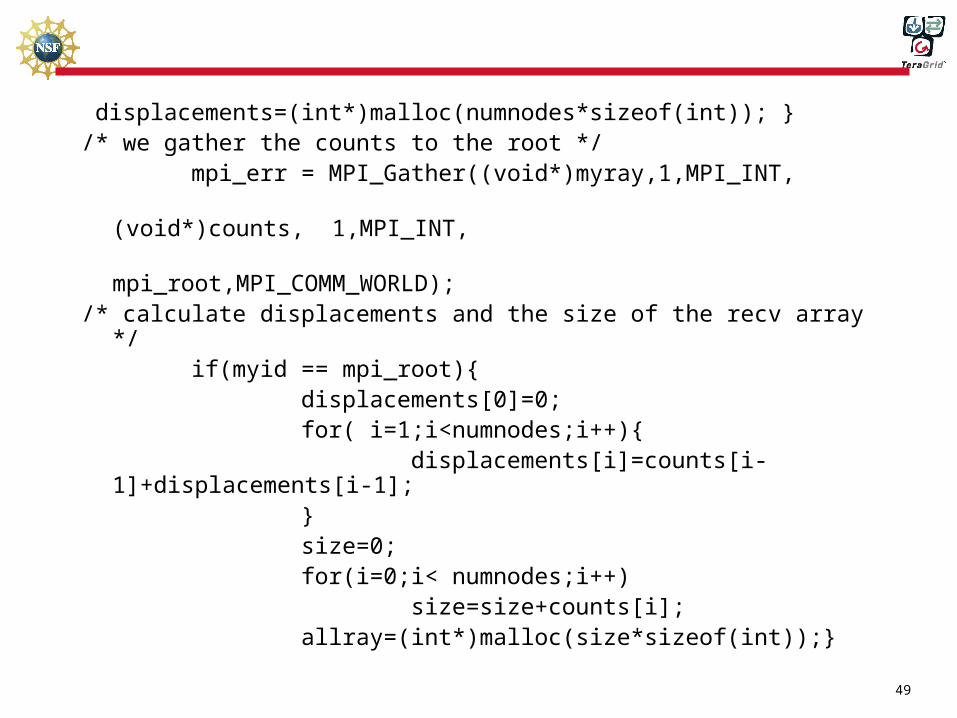
49
displacements=(int*)malloc(numnodes*sizeof(int)); } /* we gather the counts to the root */ mpi_err = MPI_Gather((void*)myray,1,MPI_INT, (void*)counts, 1,MPI_INT, mpi_root,MPI_COMM_WORLD);/* calculate displacements and the size of the recv array */ if(myid == mpi_root){ displacements[0]=0; for( i=1;i<numnodes;i++){ displacements[i]=counts[i-1]+displacements[i-1]; } size=0; for(i=0;i< numnodes;i++) size=size+counts[i]; allray=(int*)malloc(size*sizeof(int));}
50
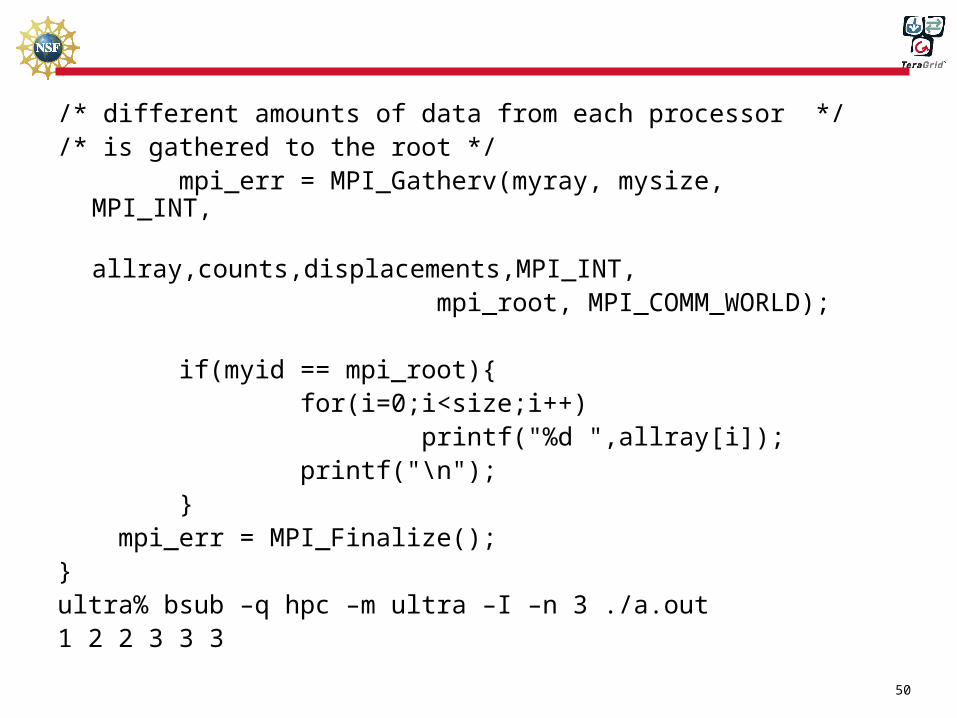
/* different amounts of data from each processor *//* is gathered to the root */ mpi_err = MPI_Gatherv(myray, mysize, MPI_INT, allray,counts,displacements,MPI_INT, mpi_root, MPI_COMM_WORLD);
if(myid == mpi_root){ for(i=0;i<size;i++) printf("%d ",allray[i]); printf("\n"); } mpi_err = MPI_Finalize();}ultra% bsub –q hpc –m ultra –I –n 3 ./a.out1 2 2 3 3 3

51
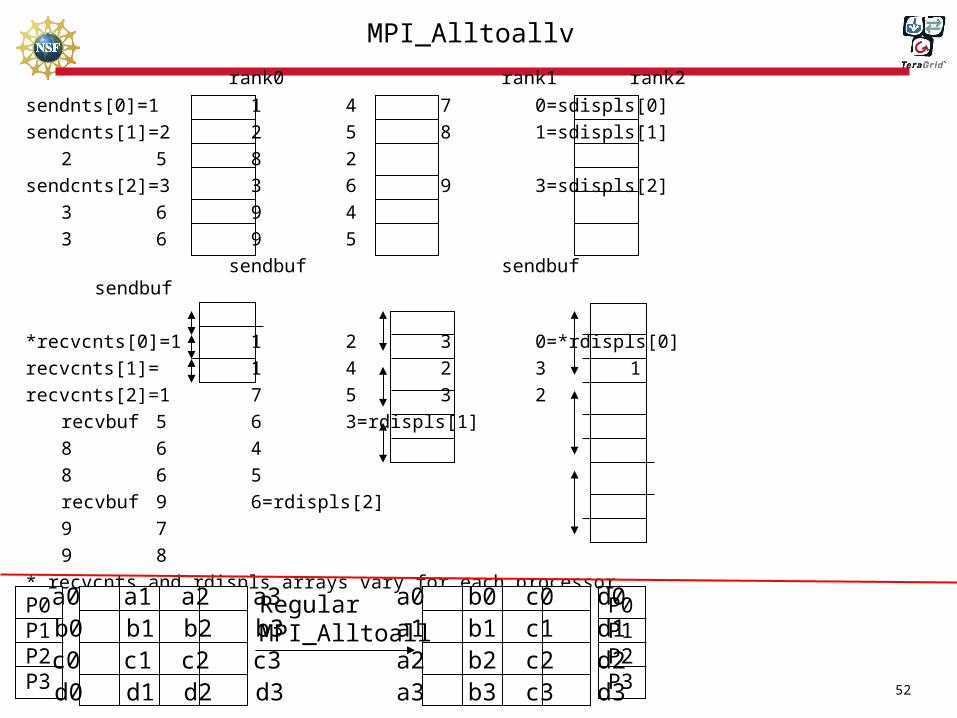
MPI_Alltoallv
• Send and receive different amounts of data form all processors
• C– int MPI_Alltoallv (&sendbuf, &sendcnts, &sdispls,
sendtype, &recvbuf, &recvcnts, &rdispls, recvtype, comm );
• Fortran– Call MPI_Alltoallv(sendbuf, sendcnts, sdispls,
sendtype, recvbuf, recvcnts, rdispls,recvtype, comm,ierror);
• See attached code
52
MPI_Alltoallv
rank0 rank1 rank2
sendnts[0]=1 1 4 7 0=sdispls[0]
sendcnts[1]=2 2 5 8 1=sdispls[1]
2 5 8 2
sendcnts[2]=3 3 6 9 3=sdispls[2]
3 6 9 4
3 6 9 5
sendbuf sendbuf sendbuf
*recvcnts[0]=1 1 2 3 0=*rdispls[0]
recvcnts[1]= 1 4 2 3 1
recvcnts[2]=1 7 5 3 2
recvbuf 5 6 3=rdispls[1]
8 6 4
8 6 5
recvbuf 9 6=rdispls[2]
9 7
9 8
* recvcnts and rdispls arrays vary for each processor
b0 b1 b2 b3c0 c1 c2 c3d0 d1 d2 d3
a0 a1 a2 a3a1 b1 c1 d1a2 b2 c2 d2a3 b3 c3 d3
a0 b0 c0 d0RegularMPI_Alltoall
P0P1P2P3
P0P1P2P3

53
MPI_Alltoallv
proc#
recvcnts 0 1 2
0 1 2 3
1 1 2 3
2 1 2 3
proc#
rdispls 0 1 2
0 0 0 0
1 1 2 3
2 2 4 6
On all procs
sendcnts[0] = 1sendcnts[1] = 2sendcnts[2] = 3
On all procs
sdispls[0] = 0sdispls[1] = 1sdispls[2] = 3

54
MPI_Alltoallv
program alltoallv
include ‘mpif.h’
integer sendbuf(6), recvbuf(9)
integer sendcnts(0:2), sdispls(0:2), recvcnts(0), rdispls0:2)
data sendbuf/1,2,2,3,3,3/
data sendcnts/1,2,3/ sdispls/0,1,3/
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs, ierr)call MPI_COMM_RANK(MIP_COMM_WORLD,myrank, ierr)do i = 1,6
sendbuf(i) = sendbuf(i) + nprocs*myrankenddo
do i = 0, nprocs – 1recvcnts(i) = myrank + 1rdispls(i) = i* (myrank + 1)
enddo
print*, ‘sendbuf=‘, sendbufcall MP_FLUSH(1)call MPI_ALLTOALLV(sendbuf,sendcnts,sdispls,MPI_INTEGER,recvbuf, recvcnts, rdispls,MPI_INTEGER, MPI_COMM_WORLD, ierr)print*, ‘recvbuf=‘,recvbufcall MPI_FINALIZE(ierr)end

55
MPI_Alltoallv
% 0: sendbuf = 1 2 2 3 3 3
1: sendbuf = 4 5 5 6 6 6
2: sendbuf = 7 8 8 9 9 9
0: sendbuf = 1 4 7 0 0 0 0 0 0
1: sendbuf = 2 2 5 5 8 8 0 0 0
2: sendbuf = 3 3 3 6 6 6 9 9 9

56
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
/*
! This program shows how to use MPI_Alltoallv. Each processor
! send/rec a different and random amount of data to/from other
! processors.
! We use MPI_Alltoall to tell how much data is going to be sent.
*/
/* globals */
int numnodes,myid,mpi_err;
#define mpi_root 0
/* end module */

57
void seed_random(int id);void random_number(float *z);
void init_it(int *argc, char ***argv) { mpi_err = MPI_Init(argc,argv); mpi_err = MPI_Comm_size( MPI_COMM_WORLD, &numnodes ); mpi_err = MPI_Comm_rank(MPI_COMM_WORLD, &myid);}int main(int argc,char *argv[]){ int *sray,*rray; int *sdisp,*scounts,*rdisp,*rcounts; int ssize,rsize,i,k,j; float z; init_it(&argc,&argv); scounts=(int*)malloc(sizeof(int)*numnodes); rcounts=(int*)malloc(sizeof(int)*numnodes); sdisp=(int*)malloc(sizeof(int)*numnodes); rdisp=(int*)malloc(sizeof(int)*numnodes);/*

58
! seed the random number generator with a! different number on each processor*/ seed_random(myid);/* find out how much data to send */ for(i=0;i<numnodes;i++){ random_number(&z); scounts[i]=(int)(10.0*z)+1; } printf("myid= %d scounts=",myid); for(i=0;i<numnodes;i++) printf("%d ",scounts[i]); printf("\n");/* tell the other processors how much data is coming */ mpi_err = MPI_Alltoall( scounts,1,MPI_INT,
rcounts,1,MPI_INT, MPI_COMM_WORLD);

59
/* write(*,*)"myid= ",myid," rcounts= ",rcounts */
/* calculate displacements and the size of the arrays */
sdisp[0]=0;
for(i=1;i<numnodes;i++){
sdisp[i]=scounts[i-1]+sdisp[i-1];
}
rdisp[0]=0;
for(i=1;i<numnodes;i++){
rdisp[i]=rcounts[i-1]+rdisp[i-1];
}
ssize=0;
rsize=0;
for(i=0;i<numnodes;i++){
ssize=ssize+scounts[i];
rsize=rsize+rcounts[i];
}

60
/* allocate send and rec arrays */
sray=(int*)malloc(sizeof(int)*ssize);
rray=(int*)malloc(sizeof(int)*rsize);
for(i=0;i<ssize;i++)
sray[i]=myid;
/* send/rec different amounts of data to/from each processor */
mpi_err = MPI_Alltoallv( sray,scounts,sdisp,MPI_INT,
rray,rcounts,rdisp,MPI_INT,
MPI_COMM_WORLD);
printf("myid= %d rray=",myid);
for(i=0;i<rsize;i++)
printf("%d ",rray[i]);
printf("\n");
mpi_err = MPI_Finalize();}
61
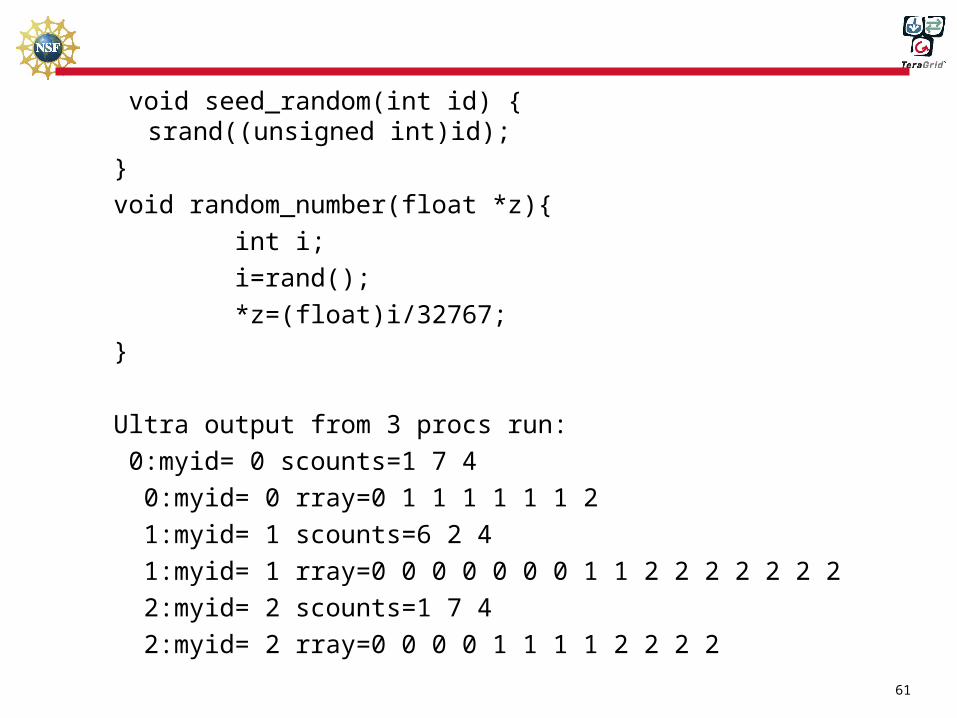
void seed_random(int id) {
srand((unsigned int)id);
}
void random_number(float *z){
int i;
i=rand();
*z=(float)i/32767;
}
Ultra output from 3 procs run:
0:myid= 0 scounts=1 7 4
0:myid= 0 rray=0 1 1 1 1 1 1 2
1:myid= 1 scounts=6 2 4
1:myid= 1 rray=0 0 0 0 0 0 0 1 1 2 2 2 2 2 2 2
2:myid= 2 scounts=1 7 4
2:myid= 2 rray=0 0 0 0 1 1 1 1 2 2 2 2

62
Derived types
• C and Fortran 90 have the ability to define arbitrary data types that encapsulate reals, integers, and characters.
• MPI allows you to define message data types corresponding to your data types
• Can use these data types just as default types

63
Derived types, Three main classifications:
• Contiguous Vectors: enable you to send contiguous blocks of the same type of data lumped together
• Noncontiguous Vectors: enable you to send noncontiguous blocks of the same type of data lumped together
• Abstract types: enable you to (carefully) send C or Fortran 90 structures, don't send pointers

64
Derived types, how to use them
• Three step process– Define the type using
• MPI_Type_contiguous for contiguous vectors
• MPI_Type_vector for noncontiguous vectors
• MPI_Type_struct for structures
– Commit the type using• MPI_Type_commit
– Use in normal communication calls• MPI_Send(buffer, count, MY_TYPE,
destination,tag, MPI_COMM_WORLD, ierr)

65
MPI_Type_contiguous
• Defines a new data type of length count elements from your old data type
• C– MPI_Type_contiguous(int count, old_type, &new_type)
• Fortran– Call MPI_TYPE_CONTIGUOUS(count, old_type,
new_type, ierror)
• Parameters– Old_type: your base type
– New_type: a type count elements of Old_type
• See attached codes
66
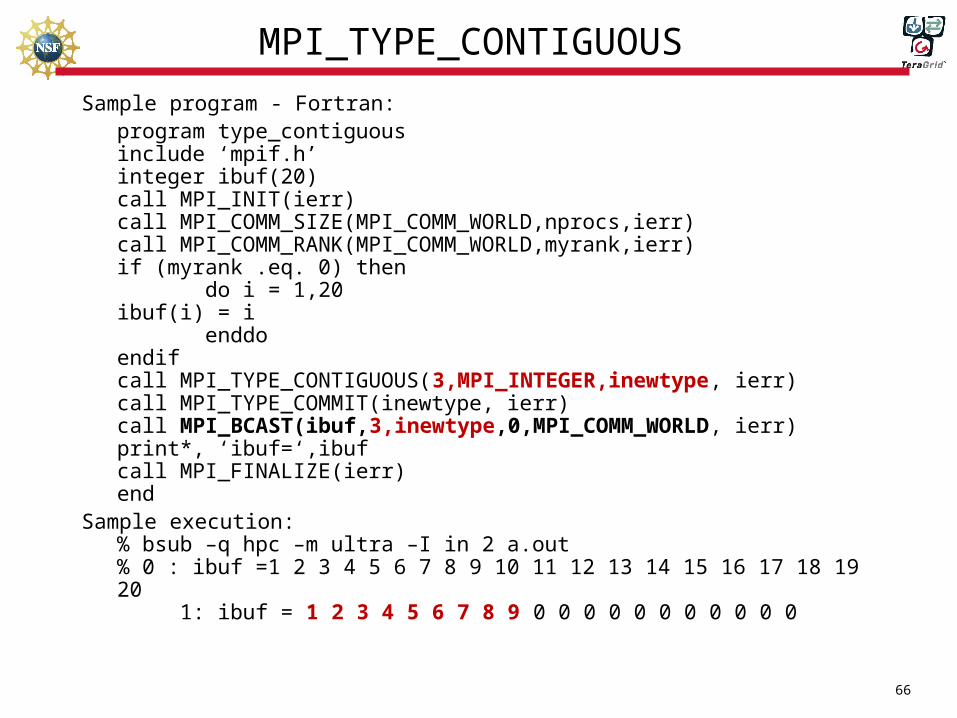
MPI_TYPE_CONTIGUOUS
Sample program - Fortran:program type_contiguousinclude ‘mpif.h’integer ibuf(20)call MPI_INIT(ierr)call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,ierr)call MPI_COMM_RANK(MPI_COMM_WORLD,myrank,ierr)if (myrank .eq. 0) then do i = 1,20
ibuf(i) = i enddoendifcall MPI_TYPE_CONTIGUOUS(3,MPI_INTEGER,inewtype, ierr)call MPI_TYPE_COMMIT(inewtype, ierr)call MPI_BCAST(ibuf,3,inewtype,0,MPI_COMM_WORLD, ierr)print*, ‘ibuf=‘,ibufcall MPI_FINALIZE(ierr)end
Sample execution:% bsub –q hpc –m ultra –I in 2 a.out% 0 : ibuf =1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1: ibuf = 1 2 3 4 5 6 7 8 9 0 0 0 0 0 0 0 0 0 0 0

67
MPI_Type_contiguous#include <stdio.h>#include "mpi.h“#include <math.h>int main(argc,argv)
int argc;char *argv[];{
int myid, numprocs, i , buffer[20]; MPI_Status status; MPI_Datatype inewtype ; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid); if (myid == 0) { for (i=0; i<20; i++) buffer[i]=i ;} if (myid == 1) { for (i=0; i<20; i++) buffer[i]=0 ;} MPI_Type_contiguous(3,MPI_INT,&inewtype); MPI_Type_commit(&inewtype) ; MPI_Bcast(buffer,3,inewtype,0,MPI_COMM_WORLD); for(i=0;i<20;i++) printf("%d ",buffer[i]); printf("\n"); MPI_Finalize(); }Output on two processors :
0 1 2 3 4 5 6 7 8 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19

68
MPI_Type_vector
• Defines a datatype which consists of count blocks each of length blocklength and stride displacement between blocks
• C– MPI_Type_vector(count, blocklength, stride, old_type,
*new_type)
• Fortran– Call MPI_TYPE_VECTOR(count, blocklength, stride,
old_type, new_type, ierror)
• See attached codes

69
MPI_Type_vector
29 30 31 32 33 34 35
22 23 24 25 26 27 28
15 16 17 18 19 20 21
8 9 10 11 12 13 14
1 2 3 4 5 6 7
To specify this row (in C order), we can use MPI_Type_vector( count, blocklen, stride, oldtype, &newtype ); MPI_Type_commit( &newtype );
The exact code for this is MPI_Type_vector( 5, 1, 7, MPI_DOUBLE, &newtype ); MPI_Type_commit( &newtype );

70
module mpi
!DEC$ NOFREEFORM
include "mpif.h"
!DEC$ FREEFORM
end module
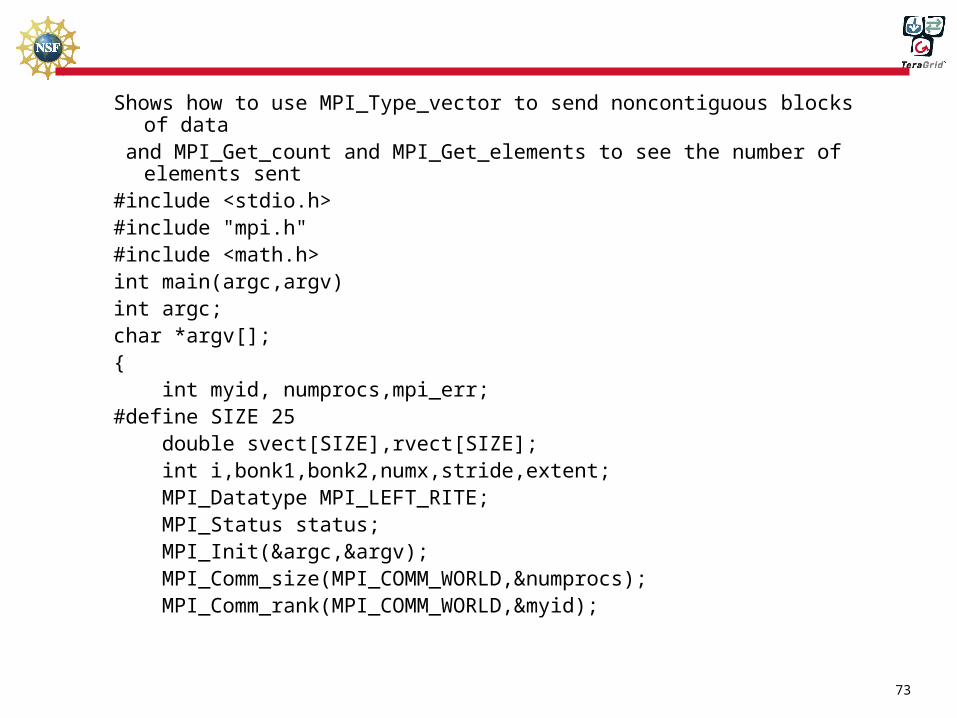
!Shows how to use MPI_Type_vector to send noncontiguous blocks of data
!and MPI_Get_count and MPI_Get_elements to see the number of elements sent
program do_vect
use mpi
! include "mpif.h"
integer , parameter :: size=24
integer myid, ierr,numprocs
real*8 svect(0:size),rvect(0:size)
integer i,bonk1,bonk2,numx,stride,extent
integer MY_TYPE
integer status(MPI_STATUS_SIZE)
call MPI_INIT( ierr )
call MPI_COMM_RANK( MPI_COMM_WORLD, myid, ierr )
call MPI_COMM_SIZE( MPI_COMM_WORLD, numprocs, ierr )
stride=5
numx=(size+1)/stride

71
extent = 1
if(myid == 1)write(*,*)"numx=",numx," extent=",extent," stride=",stride
call MPI_Type_vector(numx,extent,stride,MPI_DOUBLE_PRECISION,MY_TYPE,ier
r)
call MPI_Type_commit(MY_TYPE, ierr )
if(myid == 0)then
do i=0,size
svect(i)=i
enddo
call MPI_Send(svect,1,MY_TYPE,1,100,MPI_COMM_WORLD,ierr)
endif
if(myid == 1)then
do i=0,size
rvect(i)=-1
enddo
call MPI_Recv(rvect,1,MY_TYPE,0,100,MPI_COMM_WORLD,status,ierr)
endif
if(myid == 1)then
call MPI_Get_count(status,MY_TYPE,bonk1, ierr )
call MPI_Get_elements(status,MPI_DOUBLE_PRECISION,bonk2,ierr)

72
write(*,*)"got ", bonk1," elements of type MY_TYPE"
write(*,*)"which contained ", bonk2," elements of type MPI_DOUBLE_PREC
ISION"
do i=0,size
if(rvect(i) /= -1)write(*,'(i2,f4.0)')i,rvect(i)
enddo
endif
call MPI_Finalize(ierr )
end program
! output
! numx= 5 extent= 1 stride= 5
! got 1 elements of type MY_TYPE
! which contained 5 elements of type MPI_DOUBLE_PRECISION
! 0 0.
! 5 5.
! 10 10.
! 15 15.
! 20 20.
73
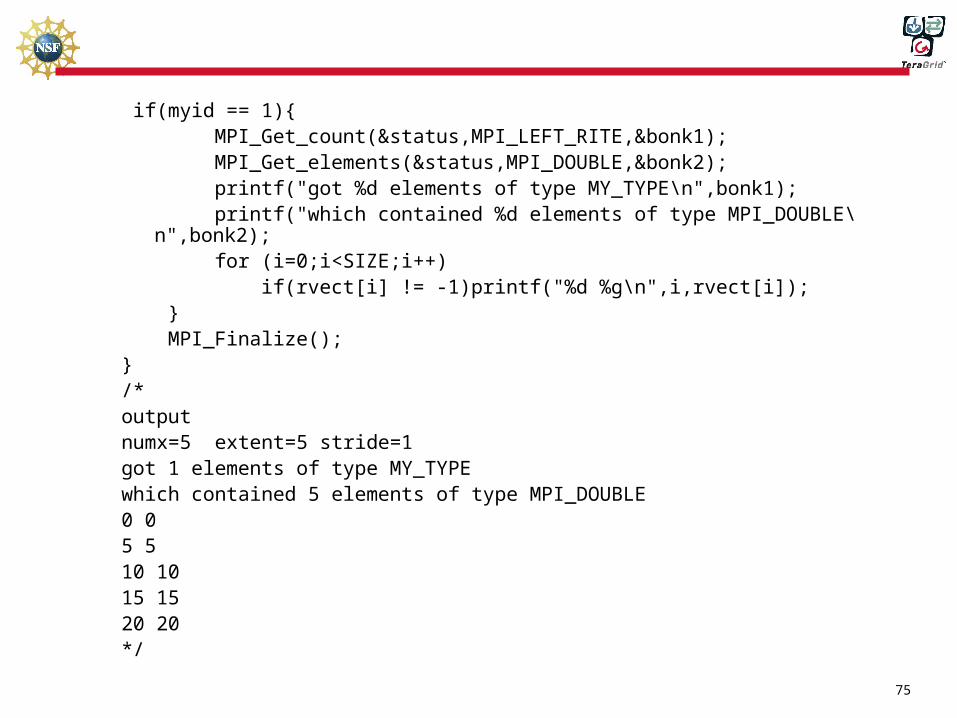
Shows how to use MPI_Type_vector to send noncontiguous blocks of data and MPI_Get_count and MPI_Get_elements to see the number of elements sent#include <stdio.h>#include "mpi.h"#include <math.h>int main(argc,argv)int argc;char *argv[];{ int myid, numprocs,mpi_err;#define SIZE 25 double svect[SIZE],rvect[SIZE]; int i,bonk1,bonk2,numx,stride,extent; MPI_Datatype MPI_LEFT_RITE; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid);

74
stride=5; numx=(SIZE+1)/stride; extent=1; if(myid == 1){ printf("numx=%d extent=%d stride=%d\n",stride,numx,extent,stride); }
mpi_err=MPI_Type_vector(numx,extent,stride,MPI_DOUBLE,&MPI_LEFT_RITE);
mpi_err=MPI_Type_commit(&MPI_LEFT_RITE); if(myid == 0){ for (i=0;i<SIZE;i++) svect[i]=i; MPI_Send(svect,1,MPI_LEFT_RITE,1,100,MPI_COMM_WORLD); } if(myid == 1){ for (i=0;i<SIZE;i++) rvect[i]=-1;
MPI_Recv(rvect,1,MPI_LEFT_RITE,0,100,MPI_COMM_WORLD,&status);}
75
if(myid == 1){ MPI_Get_count(&status,MPI_LEFT_RITE,&bonk1); MPI_Get_elements(&status,MPI_DOUBLE,&bonk2); printf("got %d elements of type MY_TYPE\n",bonk1); printf("which contained %d elements of type MPI_DOUBLE\n",bonk2); for (i=0;i<SIZE;i++) if(rvect[i] != -1)printf("%d %g\n",i,rvect[i]); } MPI_Finalize();}/*outputnumx=5 extent=5 stride=1got 1 elements of type MY_TYPEwhich contained 5 elements of type MPI_DOUBLE0 05 510 1015 1520 20*/

76
MPI_Type_struct
• Defines a MPI datatype which maps to a user defined derived datatype
• C– int MPI_Type_struct(count, &array_of_blocklengths,
&array_of_displacement, &array_of_types, &newtype);
• Fortran– Call MPI_TYPE_STRUCT(count, array_of_blocklengths,
array_of_displacement, array_of_types, newtype,ierror)

77
MPI_Type_struct
• Parameters: – [IN count] # of old types in the new type (integer)
– [IN array_of_blocklengths] how many of each type in new structure (integer)
– [IN array_of_types] types in new structure (integer)
– [IN array_of_displacement] offset in bytes for the beginning of each group of types (integer)
– [OUT newtype] new datatype (handle) – Call MPI_TYPE_STRUCT(count, array_of_blocklengths,
array_of_displacement,array_of_types, newtype,ierror)– Ierr = MPI_Type_struct(count, &array_of_blocklengths,
&array_of_displacement, &array_of_types, &newtype);

78
Derived Data type Example
Consider the data type or structure consisting of 3 mpi double 10 mpi integer 2 mpi characterCreating the MPI data structure matching this C/Fortran structure is a three step process • Fill the descriptor arrays: B - blocklengths T - types D - displacements • Use MPI_Type_struct to create the MPI data structure • Commit the new data type using MPI_Type_commit

79
Derived Data type Example
• To create the MPI data structure matching this C/Fortran structure– Fill the descriptor arrays:
• B - blocklengths
• T - types
• D - displacements
• Then use MPI_Type_struct
80
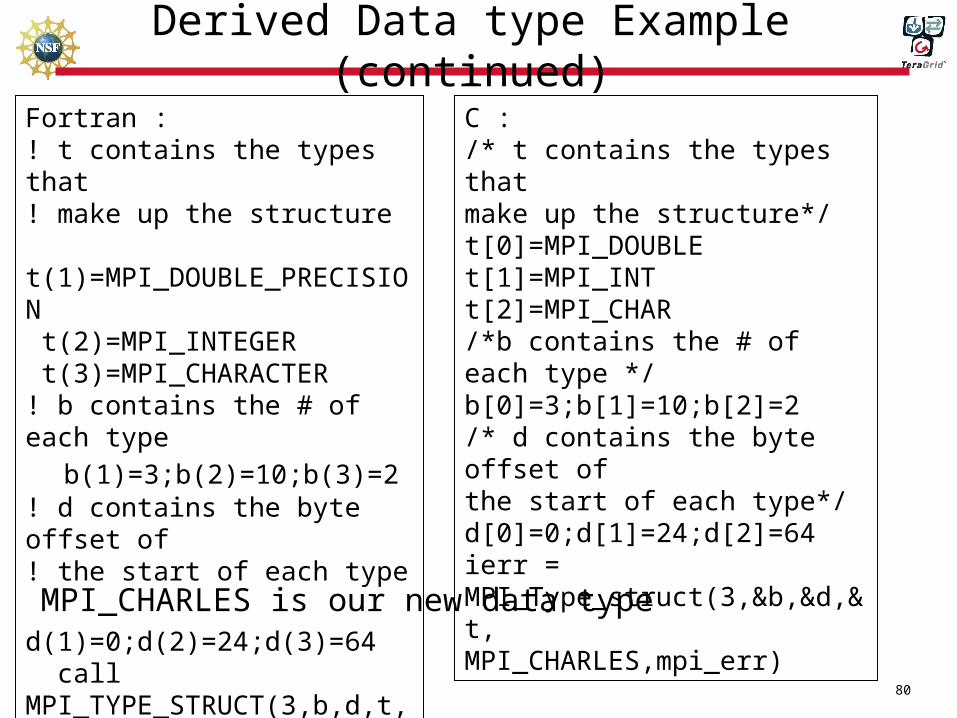
Derived Data type Example (continued)
Fortran :! t contains the types that! make up the structure t(1)=MPI_DOUBLE_PRECISION t(2)=MPI_INTEGER t(3)=MPI_CHARACTER! b contains the # of each type
b(1)=3;b(2)=10;b(3)=2! d contains the byte offset of! the start of each type
d(1)=0;d(2)=24;d(3)=64 call MPI_TYPE_STRUCT(3,b,d,t, MPI_CHARLES,mpi_err)
MPI_CHARLES is our new data type
C :/* t contains the types thatmake up the structure*/t[0]=MPI_DOUBLE t[1]=MPI_INTt[2]=MPI_CHAR/*b contains the # of each type */b[0]=3;b[1]=10;b[2]=2/* d contains the byte offset ofthe start of each type*/d[0]=0;d[1]=24;d[2]=64ierr = MPI_Type_struct(3,&b,&d,&t,MPI_CHARLES,mpi_err)
81
MPI_Type_commit
• Before we use the new data type we call MPI_Type_commit
• C– MPI_Type_commit(&MPI_CHARLES)
• Fortran– Call MPI_Type_commit(MPI_CHARLES,ierr)

82
Communicators
• A communicator is a parameter in all MPI message passing routines
• A communicator is a collection of processors that can engage in communication
• MPI_COMM_WORLD is the default communicator that consists of all processors
• MPI allows you to create subsets of communicators

83
Why Communicators?
• Isolate communication to a small number of processors
• Useful for creating libraries
• Different processors can work on different parts of the problem
• Useful for communicating with "nearest neighbors"

84
MPI_Comm_split
• Provides a short cut method to create a collection of communicators
• All processors with the "same color" will be in the same communicator
• Index gives rank in new communicator
• Fortran– call MPI_COMM_SPLIT(OLD_COMM, color, index,
NEW_COMM, mpi_err)
• C– MPI_Comm_split(OLD_COMM, color, index, &NEW_COMM)

85
MPI_Comm_split
• Split odd and even processors into 2 communicatorsProgram comm_splitinclude "mpif.h"Integer color,zero_onecall MPI_INIT( mpi_err )call MPI_COMM_SIZE( MPI_COMM_WORLD, numnodes, mpi_err )call MPI_COMM_RANK( MPI_COMM_WORLD, myid, mpi_err )color=mod(myid,2) !color is either 1 or 0call MPI_COMM_SPLIT(MPI_COMM_WORLD,color,myid,NEW_COMM,mpi_err)call MPI_COMM_RANK( NEW_COMM, new_id, mpi_err )call MPI_COMM_SIZE( NEW_COMM, new_nodes, mpi_err )Zero_one = -1If(new_id==0)Zero_one = colorCall MPI_Bcast(Zero_one,1,MPI_INTEGER,0, NEW_COMM,mpi_err)If(zero_one==0)write(*,*)"part of even processor communicator"If(zero_one==1)write(*,*)"part of odd processor communicator"Write(*,*)"old_id=", myid, "new_id=", new_idCall MPI_FINALIZE(mpi_error)End program

86
MPI_Comm_split
• Split odd and even processors into 2 communicators0: part of even processor communicator0: old_id= 0 new_id= 0
2: part of even processor communicator2: old_id= 2 new_id= 1
1: part of odd processor communicator1: old_id= 1 new_id= 0
3: part of odd processor communicator3: old_id= 3 new_id= 1

87
#include "mpi.h"#include <math.h>int main(argc,argv)int argc;char *argv[];{ int myid, numprocs; int color,Zero_one,new_id,new_nodes; MPI_Comm NEW_COMM; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid); color=myid % 2; MPI_Comm_split(MPI_COMM_WORLD,color,myid,&NEW_COMM); MPI_Comm_rank( NEW_COMM, &new_id); MPI_Comm_size( NEW_COMM, &new_nodes); Zero_one = -1; if(new_id==0)Zero_one = color; MPI_Bcast(&Zero_one,1,MPI_INT,0, NEW_COMM); if(Zero_one==0)printf("part of even processor communicator \n"); if(Zero_one==1)printf("part of odd processor communicator \n"); printf("old_id= %d new_id= %d\n", myid, new_id); MPI_Finalize();}