mendelian randomisation
TRANSCRIPT

Mendelian Randomisation
James McMurray
PhD StudentDepartment of Empirical Inference
29/07/2014

What is Mendelian Randomisation?
I Approach to test for a causal effect from observational data inthe presence of certain confounding factors.
I Uses the measured variation of genes of known function, tobound the causal effect of a modifiable exposure(environment) on a phenotype (disease).
I Fundamental idea is that the genotypes are randomly assigned(due to meiosis).
I This allows them to be used as an instrumental variable.

What is Mendelian Randomisation?
I Approach to test for a causal effect from observational data inthe presence of certain confounding factors.
I Uses the measured variation of genes of known function, tobound the causal effect of a modifiable exposure(environment) on a phenotype (disease).
I Fundamental idea is that the genotypes are randomly assigned(due to meiosis).
I This allows them to be used as an instrumental variable.

What is Mendelian Randomisation?
I Approach to test for a causal effect from observational data inthe presence of certain confounding factors.
I Uses the measured variation of genes of known function, tobound the causal effect of a modifiable exposure(environment) on a phenotype (disease).
I Fundamental idea is that the genotypes are randomly assigned(due to meiosis).
I This allows them to be used as an instrumental variable.

What is Mendelian Randomisation?
I Approach to test for a causal effect from observational data inthe presence of certain confounding factors.
I Uses the measured variation of genes of known function, tobound the causal effect of a modifiable exposure(environment) on a phenotype (disease).
I Fundamental idea is that the genotypes are randomly assigned(due to meiosis).
I This allows them to be used as an instrumental variable.

What is Mendelian Randomisation?
I Approach to test for a causal effect from observational data inthe presence of certain confounding factors.
I Uses the measured variation of genes of known function, tobound the causal effect of a modifiable exposure(environment) on a phenotype (disease).
I Fundamental idea is that the genotypes are randomly assigned(due to meiosis).
I This allows them to be used as an instrumental variable.

What is Mendelian Randomisation?: DAG

Motivation: Why Observational Data?
I Randomised Control Trials (RCTs) are the gold standard forcausal inference.
I However, it is often not ethical or possible to carry out RCTs.
I E.g. we cannot randomly assign a lifetime of heavy smokingand no smoking to groups of individuals.
I This leads to a need to use observational data.
I But this requires many assumptions.

Motivation: Why Observational Data?
I Randomised Control Trials (RCTs) are the gold standard forcausal inference.
I However, it is often not ethical or possible to carry out RCTs.
I E.g. we cannot randomly assign a lifetime of heavy smokingand no smoking to groups of individuals.
I This leads to a need to use observational data.
I But this requires many assumptions.

Motivation: Why Observational Data?
I Randomised Control Trials (RCTs) are the gold standard forcausal inference.
I However, it is often not ethical or possible to carry out RCTs.
I E.g. we cannot randomly assign a lifetime of heavy smokingand no smoking to groups of individuals.
I This leads to a need to use observational data.
I But this requires many assumptions.

Motivation: Why Observational Data?
I Randomised Control Trials (RCTs) are the gold standard forcausal inference.
I However, it is often not ethical or possible to carry out RCTs.
I E.g. we cannot randomly assign a lifetime of heavy smokingand no smoking to groups of individuals.
I This leads to a need to use observational data.
I But this requires many assumptions.

Motivation: Why Observational Data?
I Randomised Control Trials (RCTs) are the gold standard forcausal inference.
I However, it is often not ethical or possible to carry out RCTs.
I E.g. we cannot randomly assign a lifetime of heavy smokingand no smoking to groups of individuals.
I This leads to a need to use observational data.
I But this requires many assumptions.

Motivation: Why Observational Data?
I Randomised Control Trials (RCTs) are the gold standard forcausal inference.
I However, it is often not ethical or possible to carry out RCTs.
I E.g. we cannot randomly assign a lifetime of heavy smokingand no smoking to groups of individuals.
I This leads to a need to use observational data.
I But this requires many assumptions.

Instrumental Variables (IV)
I In the previous DAG, G is the instrumental variable(instrument).
I Because it affects Y only through X (exclusively)
I Therefore, under certain assumptions, if G is correlated with Ythen we can infer the edge X → Y
I First we will consider an example

Instrumental Variables (IV)
I In the previous DAG, G is the instrumental variable(instrument).
I Because it affects Y only through X (exclusively)
I Therefore, under certain assumptions, if G is correlated with Ythen we can infer the edge X → Y
I First we will consider an example

Instrumental Variables (IV)
I In the previous DAG, G is the instrumental variable(instrument).
I Because it affects Y only through X (exclusively)
I Therefore, under certain assumptions, if G is correlated with Ythen we can infer the edge X → Y
I First we will consider an example

Instrumental Variables (IV)
I In the previous DAG, G is the instrumental variable(instrument).
I Because it affects Y only through X (exclusively)
I Therefore, under certain assumptions, if G is correlated with Ythen we can infer the edge X → Y
I First we will consider an example

Instrumental Variables (IV)
I In the previous DAG, G is the instrumental variable(instrument).
I Because it affects Y only through X (exclusively)
I Therefore, under certain assumptions, if G is correlated with Ythen we can infer the edge X → Y
I First we will consider an example

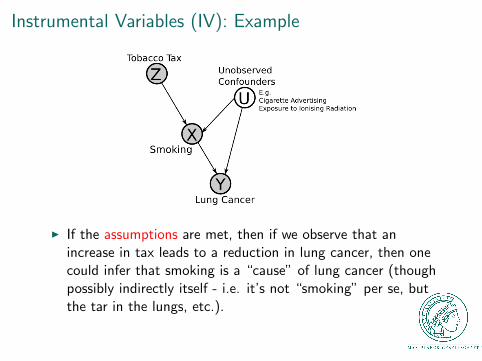
Instrumental Variables (IV): Example
I If the assumptions are met, then if we observe that anincrease in tax leads to a reduction in lung cancer, then onecould infer that smoking is a “cause” of lung cancer (thoughpossibly indirectly itself - i.e. it’s not “smoking” per se, butthe tar in the lungs, etc.).
Instrumental Variables (IV): Example
I If the assumptions are met, then if we observe that anincrease in tax leads to a reduction in lung cancer, then onecould infer that smoking is a “cause” of lung cancer (thoughpossibly indirectly itself - i.e. it’s not “smoking” per se, butthe tar in the lungs, etc.).

Instrumental Variables (IV): Assumptions: Z → X
I We must know (a priori) that the causal direction is Z → Xand not X → Z .
I This is what makes the causal structure unique andidentifiable.
I Note this does not mean that the Z we choose has to be the“true” cause of X. For example, if Z is a SNP, we can choosea SNP in linkage disequilibrium with Z, so long as it isindependent of all the other variables but still correlated withX.
I The more correlated Z is with X, the better.

Instrumental Variables (IV): Assumptions: Z → X
I We must know (a priori) that the causal direction is Z → Xand not X → Z .
I This is what makes the causal structure unique andidentifiable.
I Note this does not mean that the Z we choose has to be the“true” cause of X. For example, if Z is a SNP, we can choosea SNP in linkage disequilibrium with Z, so long as it isindependent of all the other variables but still correlated withX.
I The more correlated Z is with X, the better.

Instrumental Variables (IV): Assumptions: Z → X
I We must know (a priori) that the causal direction is Z → Xand not X → Z .
I This is what makes the causal structure unique andidentifiable.
I Note this does not mean that the Z we choose has to be the“true” cause of X. For example, if Z is a SNP, we can choosea SNP in linkage disequilibrium with Z, so long as it isindependent of all the other variables but still correlated withX.
I The more correlated Z is with X, the better.

Instrumental Variables (IV): Assumptions: Z → X
I We must know (a priori) that the causal direction is Z → Xand not X → Z .
I This is what makes the causal structure unique andidentifiable.
I Note this does not mean that the Z we choose has to be the“true” cause of X. For example, if Z is a SNP, we can choosea SNP in linkage disequilibrium with Z, so long as it isindependent of all the other variables but still correlated withX.
I The more correlated Z is with X, the better.

Instrumental Variables (IV): Assumptions: Z → X
I We must know (a priori) that the causal direction is Z → Xand not X → Z .
I This is what makes the causal structure unique andidentifiable.
I Note this does not mean that the Z we choose has to be the“true” cause of X. For example, if Z is a SNP, we can choosea SNP in linkage disequilibrium with Z, so long as it isindependent of all the other variables but still correlated withX.
I The more correlated Z is with X, the better.

Example: Can use associated SNP as instrument

Instrumental Variables (IV): Assumptions: Z ⊥⊥ U
I No factor can affect both the instrument and the effects. Forexample, there cannot be a factor that causes both highertaxes and less cancer (e.g. differences in health awareness indifferent countries).

Instrumental Variables (IV): Assumptions: Z ⊥⊥ U
I No factor can affect both the instrument and the effects. Forexample, there cannot be a factor that causes both highertaxes and less cancer (e.g. differences in health awareness indifferent countries).

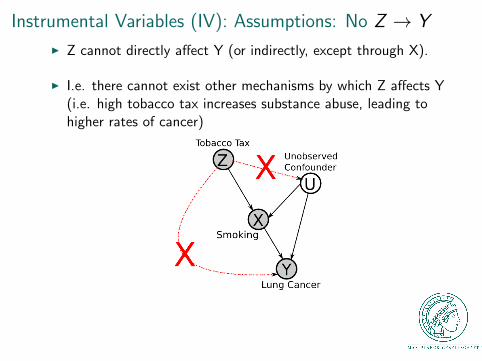
Instrumental Variables (IV): Assumptions: No Z → Y
I Z cannot directly affect Y (or indirectly, except through X).
I I.e. there cannot exist other mechanisms by which Z affects Y(i.e. high tobacco tax increases substance abuse, leading tohigher rates of cancer)

Instrumental Variables (IV): Assumptions: No Z → Y
I Z cannot directly affect Y (or indirectly, except through X).
I I.e. there cannot exist other mechanisms by which Z affects Y(i.e. high tobacco tax increases substance abuse, leading tohigher rates of cancer)
Instrumental Variables (IV): Assumptions: No Z → Y
I Z cannot directly affect Y (or indirectly, except through X).
I I.e. there cannot exist other mechanisms by which Z affects Y(i.e. high tobacco tax increases substance abuse, leading tohigher rates of cancer)

Instrumental Variables (IV): Assumptions: Faithfulness
I Assume that the true underlying DAG manifests itself in theobserved data
I I.e. causal effects do not cancel out
I Reasonable assumption, because the contrary would requirevery specific parameters
I But note that if relations are deterministic, impliedConditional Independencies do not hold and faithfulness isviolated
I Note that, in practice, the sample size is important in testingthe independencies in the data.

Instrumental Variables (IV): Assumptions: Faithfulness
I Assume that the true underlying DAG manifests itself in theobserved data
I I.e. causal effects do not cancel out
I Reasonable assumption, because the contrary would requirevery specific parameters
I But note that if relations are deterministic, impliedConditional Independencies do not hold and faithfulness isviolated
I Note that, in practice, the sample size is important in testingthe independencies in the data.

Instrumental Variables (IV): Assumptions: Faithfulness
I Assume that the true underlying DAG manifests itself in theobserved data
I I.e. causal effects do not cancel out
I Reasonable assumption, because the contrary would requirevery specific parameters
I But note that if relations are deterministic, impliedConditional Independencies do not hold and faithfulness isviolated
I Note that, in practice, the sample size is important in testingthe independencies in the data.

Instrumental Variables (IV): Assumptions: Faithfulness
I Assume that the true underlying DAG manifests itself in theobserved data
I I.e. causal effects do not cancel out
I Reasonable assumption, because the contrary would requirevery specific parameters
I But note that if relations are deterministic, impliedConditional Independencies do not hold and faithfulness isviolated
I Note that, in practice, the sample size is important in testingthe independencies in the data.

Instrumental Variables (IV): Assumptions: Faithfulness
I Assume that the true underlying DAG manifests itself in theobserved data
I I.e. causal effects do not cancel out
I Reasonable assumption, because the contrary would requirevery specific parameters
I But note that if relations are deterministic, impliedConditional Independencies do not hold and faithfulness isviolated
I Note that, in practice, the sample size is important in testingthe independencies in the data.

Instrumental Variables (IV): Assumptions: Faithfulness
I Assume that the true underlying DAG manifests itself in theobserved data
I I.e. causal effects do not cancel out
I Reasonable assumption, because the contrary would requirevery specific parameters
I But note that if relations are deterministic, impliedConditional Independencies do not hold and faithfulness isviolated
I Note that, in practice, the sample size is important in testingthe independencies in the data.
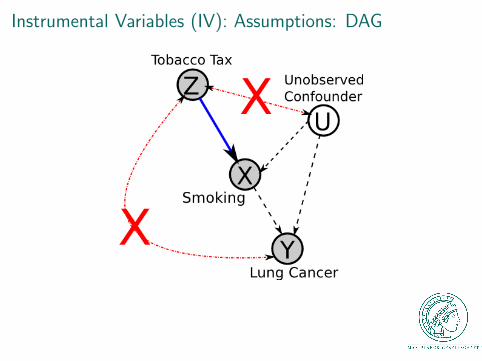
Instrumental Variables (IV): Assumptions: DAG

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Katan MB (1986): Apolipoprotein E isoforms, serumcholesterol, and cancer.
I Do low serum cholesterol levels increase cancer risk?
I But maybe both cancer risk and cholesterol levels are affectedby diet (confounders)
I Or latent tumours cause the lower cholesterol level (reversecausation)
I But patients with Abetalipoproteinemia (inability to absorbcholesterol) - did not appear predisposed to cancer
I Led Katan to idea of finding a large group geneticallypredisposed to lower cholesterol levels
I This is Mendelian Randomisation.
I Note this does not require that the genetic variants are directdeterminants of health. But, uses the association to improveinferences of the effects of modifiable environmental risks onhealth.

What is Mendelian Randomisation?: Original example
I Apolipoprotein E (ApoE) gene was known to affect serumcholesterol, with the ApoE2 variant being associated withlower levels.
I Many individuals carry ApoE2 variant and so have lowercholesterol levels from birth
I Since genes are randomly assigned during meiosis (due torecombination), ApoE2 carriers should not be different fromApoE carriers in any other way (diet, etc.), so there is noconfounding via the genome - note these assumptions.
I Therefore if low serum cholesterol is really causal for cancer,the cancer patients should have more ApoE2 alleles than thecontrols - if not then the levels would be similar in bothgroups.

What is Mendelian Randomisation?: Original example
I Apolipoprotein E (ApoE) gene was known to affect serumcholesterol, with the ApoE2 variant being associated withlower levels.
I Many individuals carry ApoE2 variant and so have lowercholesterol levels from birth
I Since genes are randomly assigned during meiosis (due torecombination), ApoE2 carriers should not be different fromApoE carriers in any other way (diet, etc.), so there is noconfounding via the genome - note these assumptions.
I Therefore if low serum cholesterol is really causal for cancer,the cancer patients should have more ApoE2 alleles than thecontrols - if not then the levels would be similar in bothgroups.

What is Mendelian Randomisation?: Original example
I Apolipoprotein E (ApoE) gene was known to affect serumcholesterol, with the ApoE2 variant being associated withlower levels.
I Many individuals carry ApoE2 variant and so have lowercholesterol levels from birth
I Since genes are randomly assigned during meiosis (due torecombination), ApoE2 carriers should not be different fromApoE carriers in any other way (diet, etc.), so there is noconfounding via the genome - note these assumptions.
I Therefore if low serum cholesterol is really causal for cancer,the cancer patients should have more ApoE2 alleles than thecontrols - if not then the levels would be similar in bothgroups.

What is Mendelian Randomisation?: Original example
I Apolipoprotein E (ApoE) gene was known to affect serumcholesterol, with the ApoE2 variant being associated withlower levels.
I Many individuals carry ApoE2 variant and so have lowercholesterol levels from birth
I Since genes are randomly assigned during meiosis (due torecombination), ApoE2 carriers should not be different fromApoE carriers in any other way (diet, etc.), so there is noconfounding via the genome - note these assumptions.
I Therefore if low serum cholesterol is really causal for cancer,the cancer patients should have more ApoE2 alleles than thecontrols - if not then the levels would be similar in bothgroups.

What is Mendelian Randomisation?: Original example
I Apolipoprotein E (ApoE) gene was known to affect serumcholesterol, with the ApoE2 variant being associated withlower levels.
I Many individuals carry ApoE2 variant and so have lowercholesterol levels from birth
I Since genes are randomly assigned during meiosis (due torecombination), ApoE2 carriers should not be different fromApoE carriers in any other way (diet, etc.), so there is noconfounding via the genome - note these assumptions.
I Therefore if low serum cholesterol is really causal for cancer,the cancer patients should have more ApoE2 alleles than thecontrols - if not then the levels would be similar in bothgroups.

What is Mendelian Randomisation?: Original example
I Katan only provided the suggestion, but the method has sincebeen used for many different analyses with some success, suchas the link between blood pressure and stroke risk.
I However, some conclusions have later been disproved byRandomised Control Trials. To understand why, we mustconsider the biological assumptions.

What is Mendelian Randomisation?: Original example
I Katan only provided the suggestion, but the method has sincebeen used for many different analyses with some success, suchas the link between blood pressure and stroke risk.
I However, some conclusions have later been disproved byRandomised Control Trials. To understand why, we mustconsider the biological assumptions.

What is Mendelian Randomisation?: Original example
I Katan only provided the suggestion, but the method has sincebeen used for many different analyses with some success, suchas the link between blood pressure and stroke risk.
I However, some conclusions have later been disproved byRandomised Control Trials. To understand why, we mustconsider the biological assumptions.

Panmixia
I Recall the assumption that the genotype is randomly assigned- this implies panmixia
I That is, there is no selective breeding (so random mating)
I Implies that all recombination is possible
I In our DAG, this means that G is not influences by Y (or othervariables)
I Not entirely accurate, as demonstrated by PopulationStratification

Panmixia
I Recall the assumption that the genotype is randomly assigned- this implies panmixia
I That is, there is no selective breeding (so random mating)
I Implies that all recombination is possible
I In our DAG, this means that G is not influences by Y (or othervariables)
I Not entirely accurate, as demonstrated by PopulationStratification

Panmixia
I Recall the assumption that the genotype is randomly assigned- this implies panmixia
I That is, there is no selective breeding (so random mating)
I Implies that all recombination is possible
I In our DAG, this means that G is not influences by Y (or othervariables)
I Not entirely accurate, as demonstrated by PopulationStratification

Panmixia
I Recall the assumption that the genotype is randomly assigned- this implies panmixia
I That is, there is no selective breeding (so random mating)
I Implies that all recombination is possible
I In our DAG, this means that G is not influences by Y (or othervariables)
I Not entirely accurate, as demonstrated by PopulationStratification

Panmixia
I Recall the assumption that the genotype is randomly assigned- this implies panmixia
I That is, there is no selective breeding (so random mating)
I Implies that all recombination is possible
I In our DAG, this means that G is not influences by Y (or othervariables)
I Not entirely accurate, as demonstrated by PopulationStratification

Panmixia
I Recall the assumption that the genotype is randomly assigned- this implies panmixia
I That is, there is no selective breeding (so random mating)
I Implies that all recombination is possible
I In our DAG, this means that G is not influences by Y (or othervariables)
I Not entirely accurate, as demonstrated by PopulationStratification

Population Stratification
I Systematic difference in allele frequencies betweensubpopulations, due to ancestry
I For example, physical separation leads to non-random mating
I Leads to different genetic drift in different subpopulations (i.e.changes in allele frequency over time due to random sampling)
I Means that the genotype is not randomly assigned whenconsidered across sub-populations
I E.g. Lactose intolerance

Population Stratification
I Systematic difference in allele frequencies betweensubpopulations, due to ancestry
I For example, physical separation leads to non-random mating
I Leads to different genetic drift in different subpopulations (i.e.changes in allele frequency over time due to random sampling)
I Means that the genotype is not randomly assigned whenconsidered across sub-populations
I E.g. Lactose intolerance

Population Stratification
I Systematic difference in allele frequencies betweensubpopulations, due to ancestry
I For example, physical separation leads to non-random mating
I Leads to different genetic drift in different subpopulations (i.e.changes in allele frequency over time due to random sampling)
I Means that the genotype is not randomly assigned whenconsidered across sub-populations
I E.g. Lactose intolerance

Population Stratification
I Systematic difference in allele frequencies betweensubpopulations, due to ancestry
I For example, physical separation leads to non-random mating
I Leads to different genetic drift in different subpopulations (i.e.changes in allele frequency over time due to random sampling)
I Means that the genotype is not randomly assigned whenconsidered across sub-populations
I E.g. Lactose intolerance

Population Stratification
I Systematic difference in allele frequencies betweensubpopulations, due to ancestry
I For example, physical separation leads to non-random mating
I Leads to different genetic drift in different subpopulations (i.e.changes in allele frequency over time due to random sampling)
I Means that the genotype is not randomly assigned whenconsidered across sub-populations
I E.g. Lactose intolerance

Population Stratification
I Systematic difference in allele frequencies betweensubpopulations, due to ancestry
I For example, physical separation leads to non-random mating
I Leads to different genetic drift in different subpopulations (i.e.changes in allele frequency over time due to random sampling)
I Means that the genotype is not randomly assigned whenconsidered across sub-populations
I E.g. Lactose intolerance

Canalization
I Variation in robustness of phenotypes to genotype andenvironments
I Waddington Drosophilia experiment:I Exposed Drosophilia pupae to heat shockI Developed Cross-veinless phenotype (no cross-veins in wings)I By selecting for this phenotype, eventually appears without
heat shockI Led to theory of organisms rolling downhill in to “canals” of
the epigenetic landscape with development, becoming morerobust to variation
I Think of it like an optimisation problem
I Exact mechanisms unknown
I Acts as confounder between genotype, environment andphenotype

Canalization
I Variation in robustness of phenotypes to genotype andenvironments
I Waddington Drosophilia experiment:I Exposed Drosophilia pupae to heat shockI Developed Cross-veinless phenotype (no cross-veins in wings)I By selecting for this phenotype, eventually appears without
heat shockI Led to theory of organisms rolling downhill in to “canals” of
the epigenetic landscape with development, becoming morerobust to variation
I Think of it like an optimisation problem
I Exact mechanisms unknown
I Acts as confounder between genotype, environment andphenotype

Canalization
I Variation in robustness of phenotypes to genotype andenvironments
I Waddington Drosophilia experiment:I Exposed Drosophilia pupae to heat shockI Developed Cross-veinless phenotype (no cross-veins in wings)I By selecting for this phenotype, eventually appears without
heat shockI Led to theory of organisms rolling downhill in to “canals” of
the epigenetic landscape with development, becoming morerobust to variation
I Think of it like an optimisation problem
I Exact mechanisms unknown
I Acts as confounder between genotype, environment andphenotype

Canalization
I Variation in robustness of phenotypes to genotype andenvironments
I Waddington Drosophilia experiment:I Exposed Drosophilia pupae to heat shockI Developed Cross-veinless phenotype (no cross-veins in wings)I By selecting for this phenotype, eventually appears without
heat shockI Led to theory of organisms rolling downhill in to “canals” of
the epigenetic landscape with development, becoming morerobust to variation
I Think of it like an optimisation problem
I Exact mechanisms unknown
I Acts as confounder between genotype, environment andphenotype

Canalization
I Variation in robustness of phenotypes to genotype andenvironments
I Waddington Drosophilia experiment:I Exposed Drosophilia pupae to heat shockI Developed Cross-veinless phenotype (no cross-veins in wings)I By selecting for this phenotype, eventually appears without
heat shockI Led to theory of organisms rolling downhill in to “canals” of
the epigenetic landscape with development, becoming morerobust to variation
I Think of it like an optimisation problem
I Exact mechanisms unknown
I Acts as confounder between genotype, environment andphenotype

Pleiotropy
I One gene can affect many (even seemingly unrelated)phenotypes
I Mendelian Randomisation makes the assumption of nopleiotropy
I In this case, this means that we know the genotype is onlyinfluencing the phenotype via the considered exposure
I I.e. ApoE2 only affects serum cholesterol levels, and cannotaffect cancer risk by other, unobserved means.
I This is a big assumption, prior knowledge is necessary.
I If possible, using multiple, independent SNPs (instruments)helps to alleviate this issue (as if they are all consistent then itis unlikely that they all have other pathways causing the samechange) - but note they must not be in LinkageDisequilibrium!

Pleiotropy
I One gene can affect many (even seemingly unrelated)phenotypes
I Mendelian Randomisation makes the assumption of nopleiotropy
I In this case, this means that we know the genotype is onlyinfluencing the phenotype via the considered exposure
I I.e. ApoE2 only affects serum cholesterol levels, and cannotaffect cancer risk by other, unobserved means.
I This is a big assumption, prior knowledge is necessary.
I If possible, using multiple, independent SNPs (instruments)helps to alleviate this issue (as if they are all consistent then itis unlikely that they all have other pathways causing the samechange) - but note they must not be in LinkageDisequilibrium!

Pleiotropy
I One gene can affect many (even seemingly unrelated)phenotypes
I Mendelian Randomisation makes the assumption of nopleiotropy
I In this case, this means that we know the genotype is onlyinfluencing the phenotype via the considered exposure
I I.e. ApoE2 only affects serum cholesterol levels, and cannotaffect cancer risk by other, unobserved means.
I This is a big assumption, prior knowledge is necessary.
I If possible, using multiple, independent SNPs (instruments)helps to alleviate this issue (as if they are all consistent then itis unlikely that they all have other pathways causing the samechange) - but note they must not be in LinkageDisequilibrium!

Pleiotropy
I One gene can affect many (even seemingly unrelated)phenotypes
I Mendelian Randomisation makes the assumption of nopleiotropy
I In this case, this means that we know the genotype is onlyinfluencing the phenotype via the considered exposure
I I.e. ApoE2 only affects serum cholesterol levels, and cannotaffect cancer risk by other, unobserved means.
I This is a big assumption, prior knowledge is necessary.
I If possible, using multiple, independent SNPs (instruments)helps to alleviate this issue (as if they are all consistent then itis unlikely that they all have other pathways causing the samechange) - but note they must not be in LinkageDisequilibrium!

Pleiotropy
I One gene can affect many (even seemingly unrelated)phenotypes
I Mendelian Randomisation makes the assumption of nopleiotropy
I In this case, this means that we know the genotype is onlyinfluencing the phenotype via the considered exposure
I I.e. ApoE2 only affects serum cholesterol levels, and cannotaffect cancer risk by other, unobserved means.
I This is a big assumption, prior knowledge is necessary.
I If possible, using multiple, independent SNPs (instruments)helps to alleviate this issue (as if they are all consistent then itis unlikely that they all have other pathways causing the samechange) - but note they must not be in LinkageDisequilibrium!

Pleiotropy
I One gene can affect many (even seemingly unrelated)phenotypes
I Mendelian Randomisation makes the assumption of nopleiotropy
I In this case, this means that we know the genotype is onlyinfluencing the phenotype via the considered exposure
I I.e. ApoE2 only affects serum cholesterol levels, and cannotaffect cancer risk by other, unobserved means.
I This is a big assumption, prior knowledge is necessary.
I If possible, using multiple, independent SNPs (instruments)helps to alleviate this issue (as if they are all consistent then itis unlikely that they all have other pathways causing the samechange) - but note they must not be in LinkageDisequilibrium!

Pleiotropy
I One gene can affect many (even seemingly unrelated)phenotypes
I Mendelian Randomisation makes the assumption of nopleiotropy
I In this case, this means that we know the genotype is onlyinfluencing the phenotype via the considered exposure
I I.e. ApoE2 only affects serum cholesterol levels, and cannotaffect cancer risk by other, unobserved means.
I This is a big assumption, prior knowledge is necessary.
I If possible, using multiple, independent SNPs (instruments)helps to alleviate this issue (as if they are all consistent then itis unlikely that they all have other pathways causing the samechange) - but note they must not be in LinkageDisequilibrium!
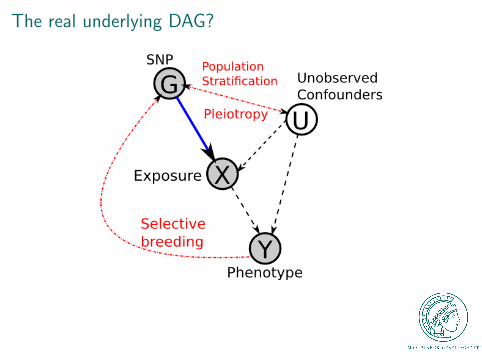
The real underlying DAG?

Conclusion
I Instrumental variables are a method to infer causal relationsfrom observational data, given certain assumptions.
I Applied in Genetic Epidemiology with MendelianRandomisation.
I Has had some success, but underlying biology poses problems.
I Can we improve robustness with more measurements ofintermediate phenotypes? (gene methylation, RNAseq,proteomics) - multi-step Mendelian Randomisation
I Can we improve identification of appropriate instruments?(e.g. whole genome sequencing makes it easier to identifypopulation stratification)
Thanks for your time
Questions?