memories and the memory subsystem; the memory hierarchy; caching; rom
TRANSCRIPT

Memories and the Memory Subsystem;The Memory Hierarchy;
Caching;ROM

Memory:Some embedded systems require large amounts; others have small memory requirements
Often must use a hierarchy of memory devices
Memory allocation may be static or dynamic
Main concerns [in embedded systems]:make sure allocation is safeminimize overhead
Main points to remember:--choose the appropriate memory for the task at hand--make appropriate use of dynamic memory management
caching—can be multiple levelvirtual storage (paging)
--if building hardware, choose appropriate busing strategy, including bus width--may need to add extra bits for error detection, error correction--may need to add extra bits for security--may need to use compression of data or of code

Memory types:
RAMDRAM—asynchronous; needs refreshingSRAM—asynchronous; no refreshingSemistatic RAMSDRAM—synchronous DRAM
ROM—read only memoryPROM—one timeEPROM—reprogram (uv light)EEPROM—electrical reprogrammingFLASH—reprogram without removing from circuit
Altera chips: http://www.altera.com/literature/hb/cyc/cyc_c51007.pdfmemory blocks with parity bit (supports error checking)synchronous, can emulate asynchronouscan be used as:
single port—nonsimultaneous read/writesimple dual-port—simultaneous read/write“true” dual-port (bidirectional)—2 read; 2 write; one read,
one write at different frequenciesshift registerROMFIFO
flash memory

fig_04_01
Standard memory configuration:
Memory a “virtual array”
Address decoder
Signals: address, data, control
fig_04_02
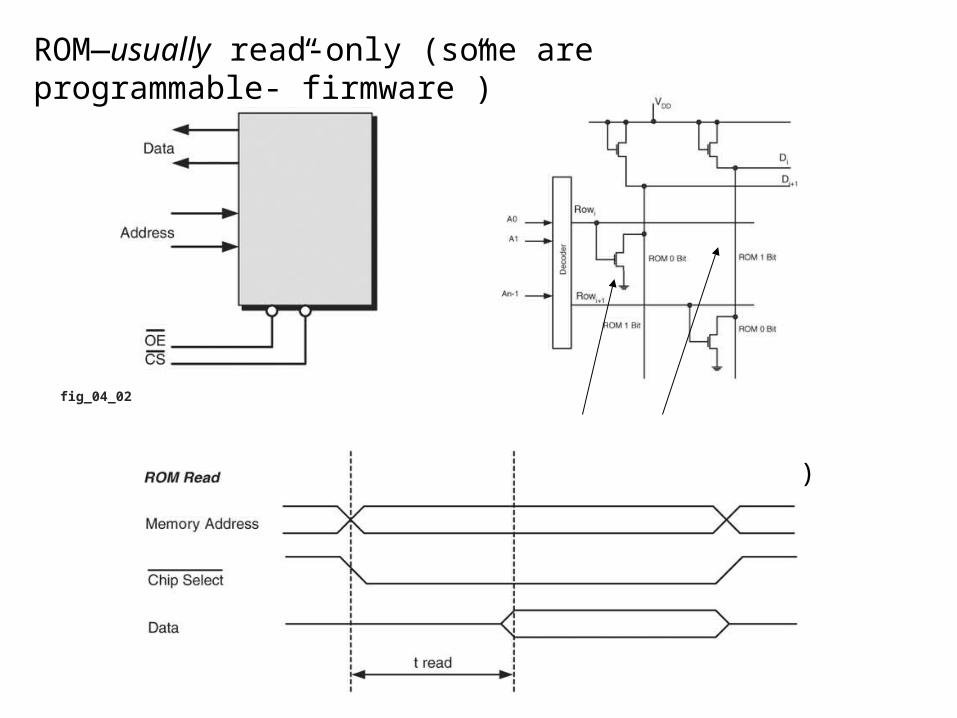
ROM—usually read-only (some are programmable-”firmware”)
transistor (0 or 1)

fig_04_04
SRAM—similar to ROMIn this example—6 transistors per cell (compare to flipflop?)

fig_04_06
Dynamic RAM: only 1 transistor per cellREAD causes transistor to discharge; it must be restored each timerefresh cycle time determined by part specification

fig_04_08
Comparison—SRAM / DRAM

fig_04_11
Two important time intervals: access time and cycle time

fig_04_12
Terminology for memory systems:
Block: logical unit of transfer
Block size
Page—logical unit; a collection of blocks
Bandwidth—word transition rate on the I/O bus (memory can be organized in bits, bytes, words)
Latency—time to access first word in a sequence
Block access time—time to access entire block
“virtual” storage

Memory interface:
Restrictions which must be dealt with:
Size of RAM or ROM
width of address and data I/O lines

fig_04_14
Memory example:
4K x 16 SRAM
Uses 2 8-bit SRAMs (to achieve desired word size)
Uses 4 1K blocks (to achieve desired number of words)
Address:10 bits within a block2 bits to specify block— CS (chip select)

If insufficient I/O lines: must multiplex signals and store in registers until data is accumulated (common in embedded system applications)
Requires MAR / MDR configuration typically

DRAM:
Variations available: EDO, SDRAM, FPM—basically DRAMs trying to accommodate ever faster processors
Techniques:--synchronize DRAM to system clock--improve block accessing--allow pipelining
As with SRAM, typically there are insufficient I/O pins and multiplexing must be used
fig_04_30
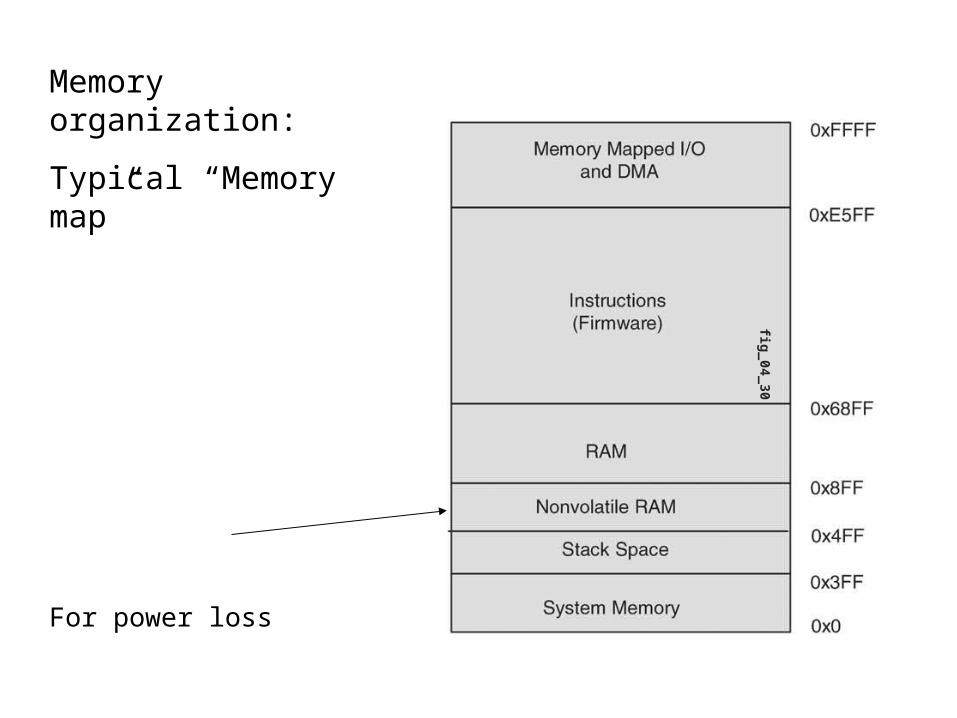
Memory organization:
Typical “Memory map”
For power loss

Issue in embedded systems design: stack overflow
Example: should recursion be used?
Control structures: “sequential” +:
“Primitive” “Structured programming”GOTO choice (if-else, case)Cond GOTO iteration (pre, post-test)
?recursion?
[functions, macros: how do these fit into the list of control structures?]
fig_04_31
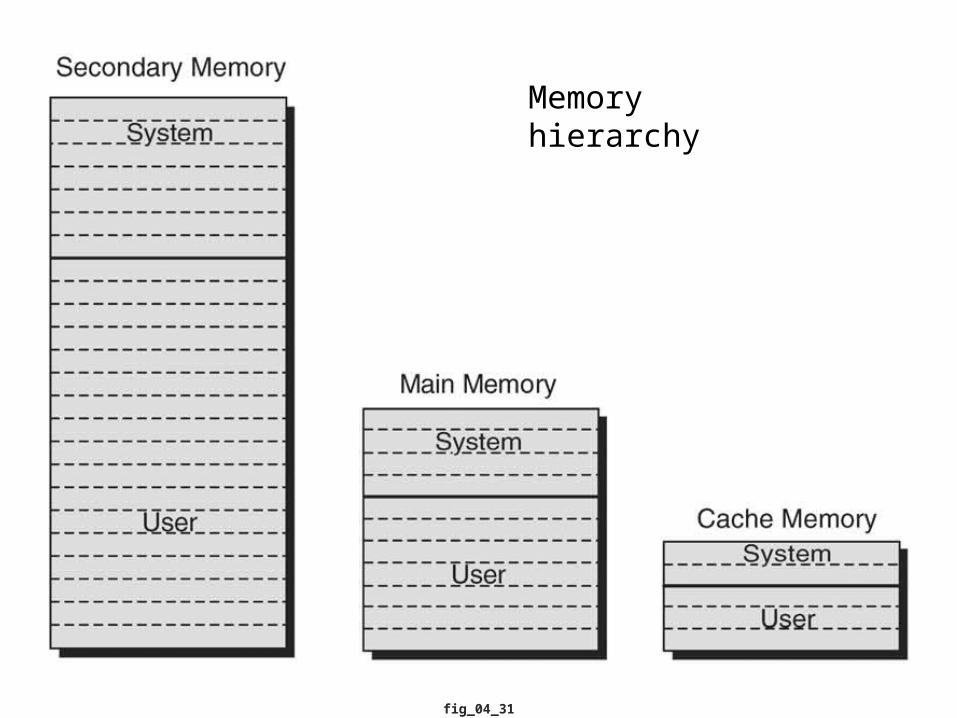
Memory hierarchy

fig_04_32
Paging / Caching
Why it typically works:
locality of reference
(spatial/temporal)
“working set”
Notes:
1. in real-time embedded systems, behavior may be atypical; but caching may still be a useful technique: how do you decide if behavior is “typical” / “atypical”?
2. In all cases must be careful to prevent thrashing

fig_04_33
Typical memory system with cache: hit rate (miss rate) important

Basic caching strategies:
Direct-mapped Associative
Block-set associative questions:
what is “associative memory”?
what is overhead?
what is efficiency (hit rate)?
is bigger cache better?

Associative memory: storage location related to data storedExample—hashing:--When software program is compiled or assembled, a symbol table must be created to link addresses with symbolic names--table may be large; even binary search of names may be too slow--convert each name to a number associated with the name, this number will be the symbol table indexFor example, let a = 1, b = 2, c = 3,…Then “cab” has value 1 + 2 + 3 = 6 “ababab” has value 3 *(1 + 2) = 9And “vvvvv” has value 5*22 = 110Address will be modulo a prime p, if we expect about 50 unique identifiers, can take p = 101 (make storage about twice as large as number of items to be stored, reduce collisions)Now array of names in symbol table will look like:0—>1—>2--->…6--->cab…9--->ababab--->vvvvv…Here there is one collision, at address 9; the two items are stored in a linked listAccess time for an identifier <= (time to compute address) + 1 + length of longest linked list ~ constant

Caching: the basic process—note OVERHEAD for each task--program needs information M that is not in the CPU--cache is checked for M how do we know if M is in the cache?--hit: M is in cache and can be retrieved and used by CPU--miss: M is not in cache (M in RAM or in secondary memory) where is M?
* M must be brought into cache* if there is room, M is copied into cache how do we know if there is room?* if there is no room, must overwrite some info M’ how do we select M’?
++ if M’ has not been modified, overwrite it how do we know if M’ has been modified?++ if M’ has been modified, must save changeshow do we save changes to M’?

fig_04_34
Example: direct mapping32-bit words, cache holds 64K words, in 128 0.5K blocksMemory addresses 32 bitsMain memory 128M words; 2K pages, each holds 128 blocks (~ cache)
fig_04_35
fig_04_36
2 bits--byte; 9 bits--word address;7 bits—block address (index); 11 (of 15)—tag (page block is from)
Tag table: 128 entries (one for each block in the cache). Contains:Tag: page block came fromValid bit: does this block contain data write-through: any change propagated immediately to main memorydelayed write: since this data may change again soon, do not propagate change to main memory immediately—this saves overhead; instead, set the dirty bitIntermediate: use queue, update periodicallyWhen a new block is brought in, if the valid bit is true and the dirty bit is true, the old block must first be copied into main memoryReplacement algorithm: none; each block only has one valid cache location
fig_04_37
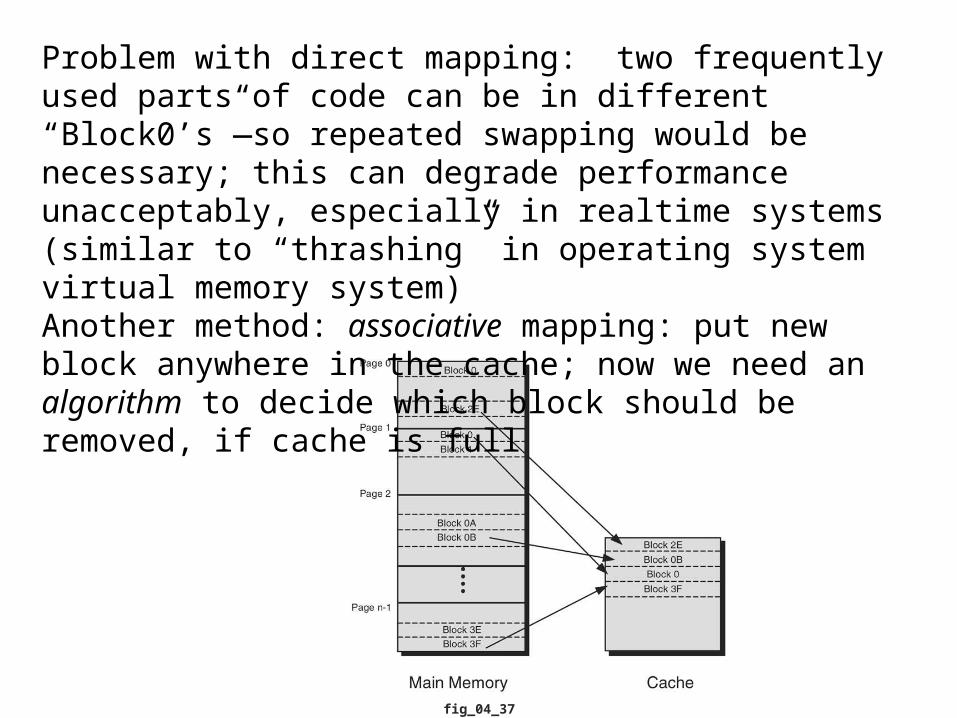
Problem with direct mapping: two frequently used parts of code can be in different “Block0’s”—so repeated swapping would be necessary; this can degrade performance unacceptably, especially in realtime systems (similar to “thrashing” in operating system virtual memory system)Another method: associative mapping: put new block anywhere in the cache; now we need an algorithm to decide which block should be removed, if cache is full

fig_04_38
Step 1: locate the desired block within the cache; must search tag table, linear search may be too slow; search all entries in parallel or use hashingStep 2: if miss, decide which block to replace.a.Add time accessed to tag table info, use temporal locality:Least recently used (LRU)—a FIFO-type algorithmMost recently used (MRU)—a LIFO-type algorithmb. Choose a block at random
Drawbacks: long search timesComplexity and cost of supporting logicAdvantages: more flexibility in managing cache contents

fig_04_39
Intermediate method: block-set associative cacheEach index now specifies a set of blocksMain memory: divided into m blocks organized into n groupsGroup number = m mod n Cache set number ~ main memory group numberBlock from main memory group j can go into cache set jSearch time is less, since search space is smallerHow many blocks: simulation answer (one rule of thumb: doubling associativity ~ doubling cache size, > 4-way probably not efficient)
Two-way set-associative scheme

Example: 256K memory-64 groups, 512 blocks Block Group (m mod
64)0 64 128 . . . 384 448 01 65 129 . . . 385 449 12 66 130 . . . 386 450 2. . .63 127 192 . . . 447 511 63

fig_04_40
Dynamic memory allocation (“virtual storage”):--for programs larger than main memory--for multiple processes in main memory--for multiple programs in main memory
General strategies may not work well because of hard deadlines for real-time systems in embedded applications—general strategies are nondeterministic
Simple setup:Can swap processes/programsAnd their contexts--Need storage (may be infirmware)--Need small swap time comparedto run time--Need determinismEx: chemical processing, thermal control

fig_04_41
Overlays (“pre-virtual storage”):Seqment program into one main section and a set of overlays (kept in ROM?)Swap overlaysChoose segmentation carefully to prevent thrashing

fig_04_42
Multiprogramming: similar to paging
Fixed partition size: Can get memory fragmentationExample:If each partition is 2K and we have 3 jobs: J1 = 1.5K, J2 = 0.5K, J3 = 2.1KAllocate to successive partitions (4)J2 is using only 0.5 K J3 is using 2 partitions, one of size 0.1KIf a new job of size 1K enters system, there is no place for it, even though there is actually enough unused memory for it
Variable size:Use a scheme like pagingInclude compactionChoose parameters carefully to prevent thrashing

Error checking: simple examples1.Detect one bit error: add a parity bit2.Correct a 1-bit error: Hamming codeExample: send m message bits + r parity bitsThe number of possible error positions ism + r + 1, we need 2r >= m + r + 1If m = 8, need r = 4; ri checks parity of bits with i in binary representationPattern:Bit #: 1 2 3 4 5 6 7 8 9 10 11 12Info: r0 r1 m1 r2 m2 m3 m4 r3 m5 m6 m7 m8
--- --- 1 --- 1 0 0 --- 0 1 1 1Set parity = 0 for each groupr0: bits 1 + 3 + 5 + 7 + 9 + 11 = r0 + 1 + 1 + 0 + 0 + 1 r0 = 1r1: bits 2 + 3 + 6 + 7 + 10 + 11 = r1 + 1 + 0 + 0 + 1 + 1 r1 = 1r2: bits 4 + 5 + 6 + 7 + 12 = r2 + 1 + 0 + 1 r2 = 0r3: bits 8 + 9 + 10 + 11 + 12 = r3 + 0 + 1 + 1 + 1 r3 = 1Exercise: suppose message is sent and 1 bit is flipped in received messageCompute the parity bits to see which bit is incorrect
Addition: add an overall parity bit to end of message to also detect two errors
Note: a.this is just one example, a more general formulation of Hamming codes using the finite field arithmetic can also be given b. this is one example of how error correcting codes can be obtained, there are many more complex examples, e.g., Reed-Solomon codes used in CD players

In an embedded system may need to COMPRESS data and/or code. To do this, make more frequent symbols have shorter encodings (e.g., Morse code)
Simple example—Huffman codingAssign frequency to characters based on data to be compressed, use frequency to build a binary tree to determine encoding ex: in typical English text, the most frequent letters (in order) are ETAOINSHRDLU ….. so we should give shorter encodings to E and T, for example, and longer encodings to letters like X,Y,Z
Huffman coding does this by using the character frequencies to build a tree; the more frequent the character, the closer to the root and the shorter its code will be

Lets look at this example fromhttp://mitpress.mit.edu/sicp/full-text/sicp/book/node41.html
For symbols A, B, C, D, E, F, G, and H, we can choose a code with three bits per character. With such a code, the message BACADAEAFABBAAAGAH needs 54 bits
But Suppose we know that the relative frequencies in our data are 8 for A, 3 for B, and 1 each for C-HThen we can build a tree representing these differences. We get the code for a symbol by tracing itsposition starting from the root and assigning 0 if we go left, 1 if rightFrom this tree we compute the codes:
A 0 C 1010 E 1100 G 1110
B 100 D 1011 F 1101 H 1111
And we can encode the abovemessage in only 42 bits