meeting performance goals in multi-tenant hadoop clusters
TRANSCRIPT

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Meeting Performance Goals in Multi-tenant Hadoop Clusters
Shivnath Babu and Brian Majeska

Who we are
• Manages Operations for YP’s Hadoop and HBase clusters
• Worked with Hadoop ecosystem for 5 years
• System Admin for 13 years
• Previously at eHarmony, CalTech, EarthLink
Brian MajeskaDirector Engineering OperationsPlatform Data ServicesYP.com
Glendale, CA 91203
Shivnath BabuAssociate Professor,Duke UniversityCo-founder/CTO,Unravel Data Systems
Menlo Park, CA 94025
• R&D on Hadoop, Spark, NoSQL, streaming, & MPP to simplify ongoing app/system management
• Led work on first self-tuning Hadoop platform
• Awards from NSF, IBM, HP
• PhD, Stanford University

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Lifecycle of a Multi-tenant Hadoop Cluster
Growth, Diversity, Challenges

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Growth• Pilot: Migrated ETL to Hadoop 5 years ago• Growth in applications• ETL: from 3 to 100+ unique workflows in 5 years• Ad-hoc: 7K jobs a day - 24/7
• Growth in users: 100+ active users• Growth in systems: HDFS, MapReduce, Hive, Oozie, HBase,
Spark, Kafka

Hadoop Growth Over Time
Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Production Cluster300 servers8 cores8 x 1T data drives (2PB)18G RAM1G NIC
Multi-tenant Production Cluster220 servers16 cores12 x 4T data drives (7PB)256G RAM10G NIC
5 Years Ago… 1PB data Today… 5PB data

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Daily Processing on Multi-tenant Cluster
• 1.3 Billion events
• 300TB HDFS Reads
• 35TB HDFS Writes

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
With Great Power Comes Great Diversity!
• Diversity in application types• Diversity in application resource needs• Diversity in users and their skill-sets• Diversity in business criticality of workloads

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Lifecycle of a Multi-tenant Hadoop Cluster
Growth & Diversity Challenges

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Growth + Diversity Big Challenges
• More problems• Harder to diagnose Cascading
failures
Application slowdowns
Rogue applications
Missed SLAs
Stuck jobsFailed queries

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Growth + Diversity Big Challenges
• More problems• Harder to diagnose• Harder to track who is doing what• Harder to control
CPU/IO/Network usageFiles/Tables/partitions createdBest practices on application performance and cluster usage

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Growth + Diversity Big Challenges
• More problems• Harder to diagnose• Harder to track who is doing what• Harder to control• Harder to optimize• Harder to plan
Server configurationScheduler parametersJustifying resource demandsForecasting capacity needs

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
For Easier Ongoing Management of Multi-tenant Hadoop Clusters
Understand, Improve, Control

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
UnderstandWhat is Going On

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Real-life Example: Unpredictable Workflow Performance

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
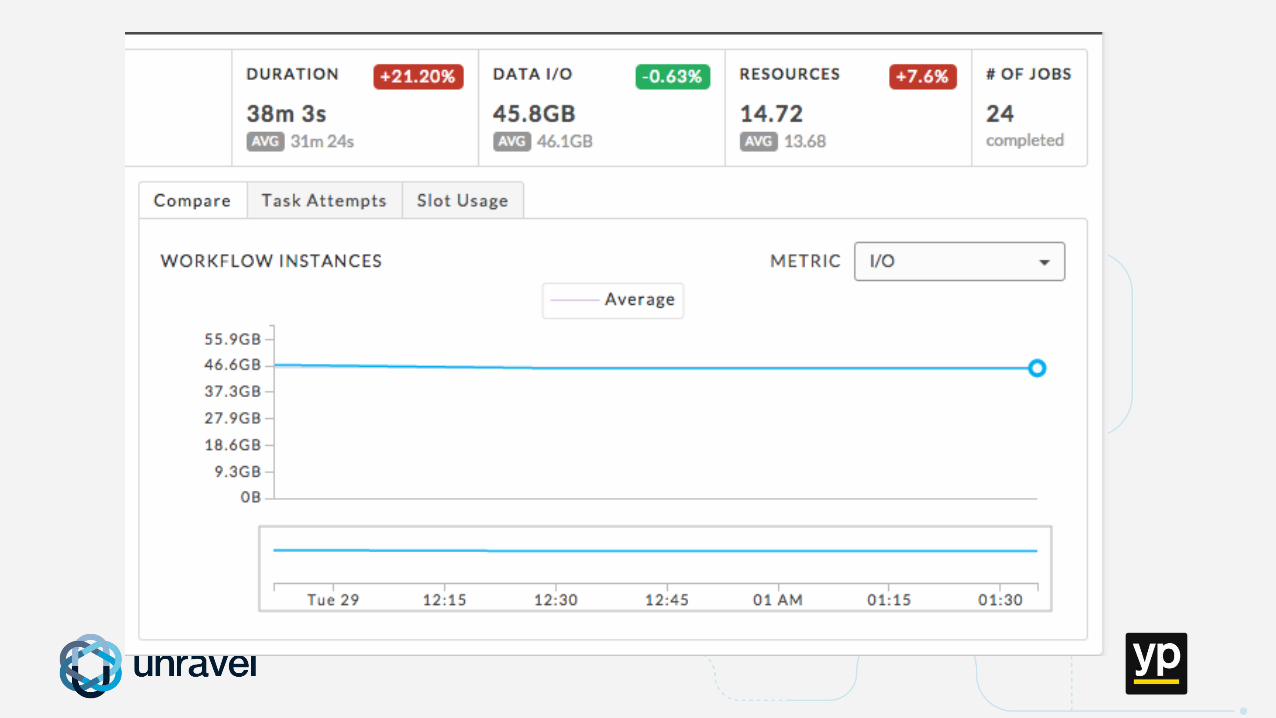
Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
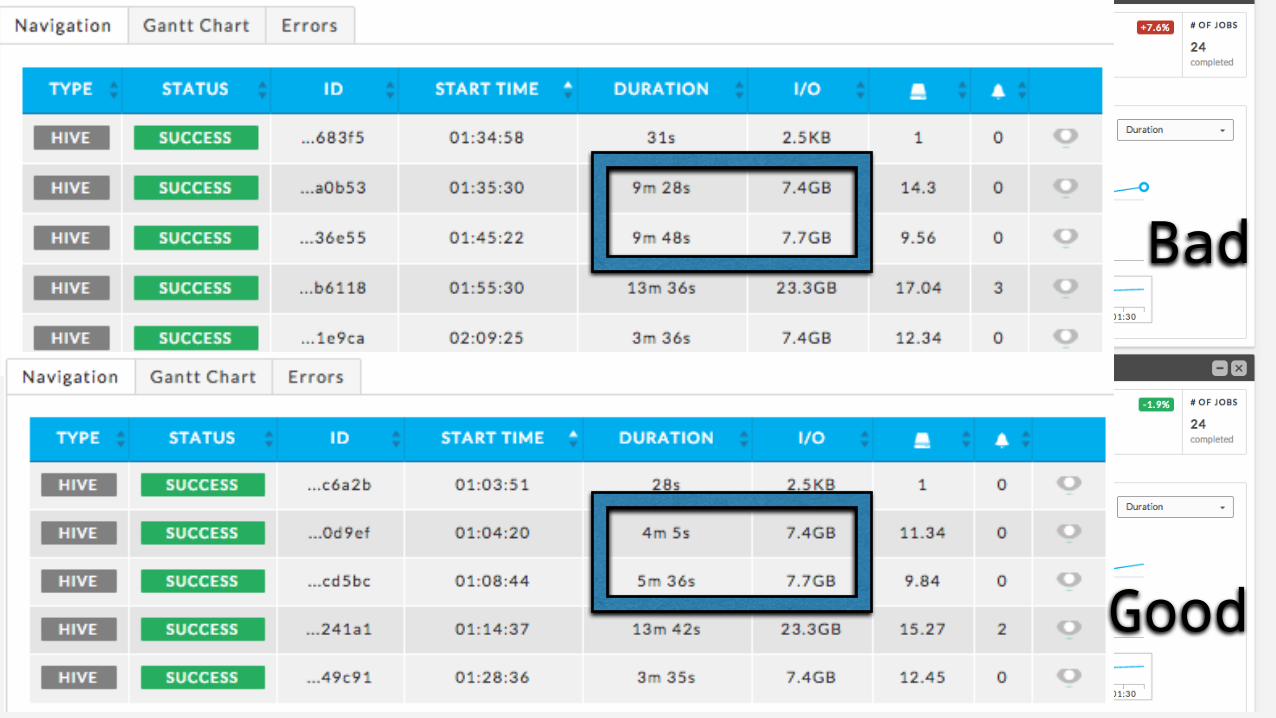
Bad
Good

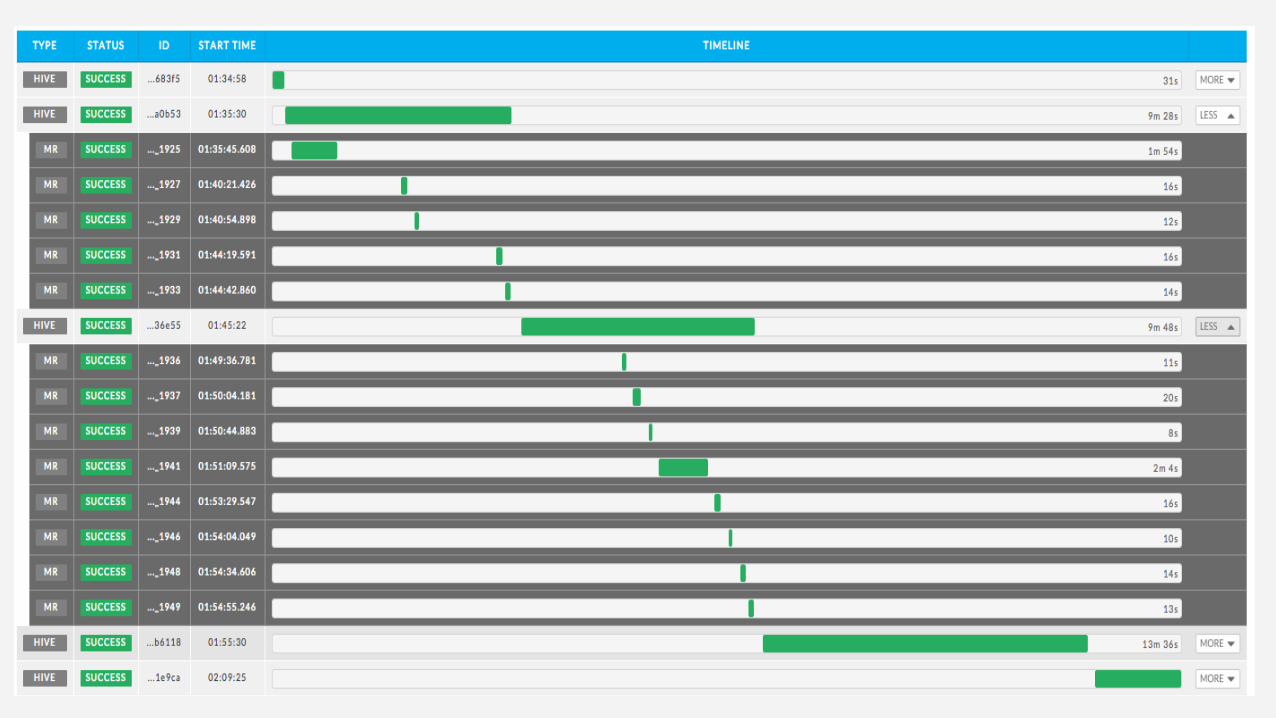

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Root Cause of this Resource Contention

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
But, This is Just One Type of Contention
• At Resource Manager Level• App admission time• Container allocation for App
Master• Container allocation for tasks• Container allocation for
Executor• At Application Level
• Workflow Scheduler, e.g., Oozie• Query Engine, e.g., HiveServer2
• At Master Daemon Level• NameNode• Hive MetaStore
Bad
Good

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Key Takeaways
Resource contention at different levels affects app performance• Different apps (Oozie workflows, MapReduce, Spark, Tez) are affected
differently• Manual diagnosis can be hard and time-consuming
Unravel’s approach to diagnose such problems automatically• Analyzes full-stack monitoring data• Carefully combines system knowledge with statistical analysis

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
For Easier Ongoing Management of Multi-tenant Hadoop Clusters
Understand, Improve, Control

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
ImprovePerformance &
Efficiency

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Quick Primer on YARN Resource Manager
Image from: http://doc.mapr.com/display/MapR/YARN

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Two Ways to Improve Performance & Efficiency 1. At the level of individual application’s interaction with
the Resource Manager2. At the level of the Resource Manager’s Configuration
that affects all applications

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Application’s Interaction with the Resource Manager1. Number of containers • MapReduce, Spark, & Tez use different techniques to determine this
number
2. Container size• CPU• Memory
Image from: http://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Application Spawns Too Many Containers

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Poorly-sized Containers

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Massive Inefficiencies Diagnosed and Eliminated with Intelligent Container Sizing!

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Two Ways to Improve Performance & Efficiency 1. At the level of individual application’s interaction with
the Resource Manager2. At the level of the Resource Manager’s Configuration
that affects all applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
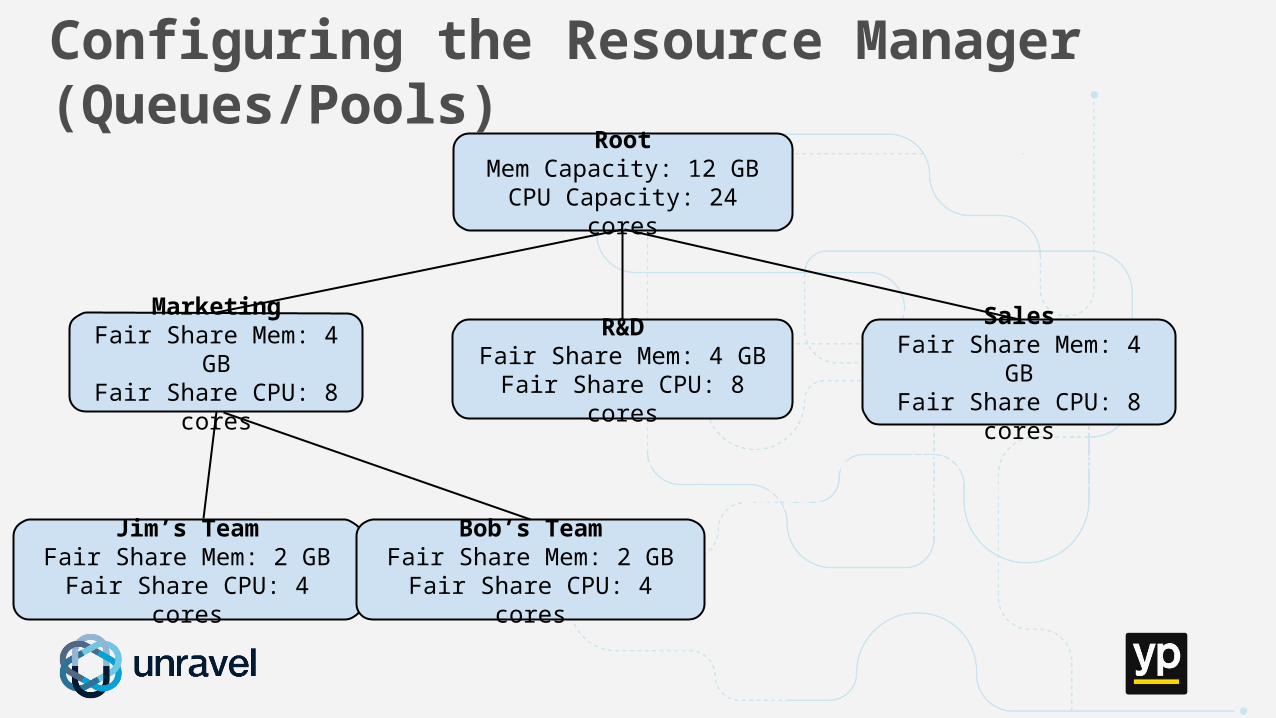
Configuring the Resource Manager (Queues/Pools)
RootMem Capacity: 12 GB
CPU Capacity: 24 cores
MarketingFair Share Mem: 4 GB
Fair Share CPU: 8 cores
R&DFair Share Mem: 4 GB
Fair Share CPU: 8 cores
SalesFair Share Mem: 4 GB
Fair Share CPU: 8 cores
Missed SLAsPoor performanceFailed applications
Jim’s TeamFair Share Mem: 2 GB
Fair Share CPU: 4 cores
Bob’s TeamFair Share Mem: 2 GB
Fair Share CPU: 4 cores

Configuring the Resource Manager (Parameters)
Image from: http://www.slideshare.net/SumeetSingh1/hadoop-summit-san-jose-2015-towards-slabased-scheduling-on-yarn-clusters

Performance Goals that Need to be Met
• Deadline: ETL workflow should finish by 6.00 AM• Latency: Average query latency should be under 3
minutes• Utilization: Cluster utilization should be above 70%• Predictability: SLA satisfaction rate should be above
95%

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Very complex to configure manually for good performance and
efficiency!1. YARN does not understand performance
goals 2. Too many low-level parameters to be set3. Need a deep understanding of application
workload & performance requirements4. Diverse types of application behaviors5. Workloads change with time

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
A New Interface to YARN’s Resource Manager
Simple abstraction to specify key performance goals• Based on past/current performance• Helps pose operational what-if questions
Powerful functionality • Learning engine for automated answers to operational what-if
questions• Recommender system to automatically find parameter settings that
meet performance goals
Nonintrusive & No changes needed to YARN YARN
Inside
!

Ask operational what-if questions based on past/current performance: 1. What is the impact of decreasing capacity of ADVERTISING queue by 30%?2. How to reduce average workflow latency in FINANCIAL queue to 30 minutes?
Resource allocation & app performance in different queues

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Tempo: Robust and Self-Tuning Resource Management in Multi-
tenant Parallel Databases
To appear in VLDB in Sept 2016

Key Types of Performance
Goals
ApplicationWorkload
in the Cluster
Models of Fair/Capacity Schedulers
Learning and Optimization Algorithms
Automated Answers to Operational Questions

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Key Takeaways
YARN is powerful to meet key multi-tenant resource allocation needs
But, an easy interface to specify & satisfy performance goals is lacking
Our work aims to fill this gap in the ecosystem

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
For Easier Ongoing Management of Multi-tenant Hadoop Clusters
Understand, Improve, Control

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
ControlMulti-tenant Usage
by Enforcing Policies

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
AutoActions for Policy-based ControlOps specifies a policy: If resources used by ad-hoc apps in FINANCIAL queue are slowing down the CEO-Report workflow by more than 20%, then move the ad-hoc apps to the QUARANTINE queue
Unravel continuously monitors for policy violations
If a policy violation is detected, then Unravel acts via YARN REST APIs • Helps Ops automate operational processes & get peace of
mind• Unravel maintains complete audit trail for post-mortem
investigation

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Examples of AutoActionsBeginner• Enforcing best practices on number of tasks and container sizes
Intermediate• Detecting Rogue Apps and moving them to a capped queue/pool• Making workflow execution fault-tolerant under YARN kills & OOMs
Expert• Guaranteeing SLAs by dynamic adjustment of YARN Resource
Manager parameters• Enabling workload-aware cluster selection to lower Cloud usage costs

Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
Lifecycle of a Multi-tenant Hadoop Cluster
Growth, Diversity, Challenges
Missed SLAsPoor performanceFailed applications
Underutilized clustersLow throughput
Unused datasetsPoor data layout
For Easier Ongoing Management of Multi-tenant Hadoop Clusters
Understand, Improve, Control

Get Unravel Trial Edition:
bit.ly/getunravel
UNCOVER ISSUESUNLEASH RESOURCESUNRAVEL PERFORMANCE