medical persona classification in social media
TRANSCRIPT

Medical Persona Classification in Social Media
Nikhil Pattisapu1, Manish Gupta1,2, Ponnurangam Kumaraguru3, Vasudeva Varma1
1IIIT Hyderabad
2Microsoft India
3IIIT Delhi
Advances in Social Network Analysis and Mining 2017
ASONAM 2017 1 / 30

Overview
Motivation
Problem Definition
Related Work
Dataset
Approach
Evaluation Metrics
Experiments
Results
Analysis and Conclusion
Future Work
ASONAM 2017 2 / 30

MotivationWhat is Medical Persona?
User groups and content providers of Web 2.0 applications inhealthcare. Some examples -
Patient
Caretaker
Consultant
Journalist
Pharmacist
Researcher
Other
ASONAM 2017 3 / 30

Motivation
Pharmaceutical firms use Medical social media for Drugmarketing and pharmacovigilance.
Figure: Sample post from drugs.com describing a patient’s experienceswith the drug Keppra.
ASONAM 2017 4 / 30

MotivationUse cases
Few use cases for identifying medical persona are mentioned below.
To gather information about drug usage, adverse events,benefits and side effects from patients.
To find out the kind of informational assistance sought bycaretakers and put such information readily available.
To identify key opinion leaders in a drug or disease area.
To find out if a doctor has patients who can take part in aclinical trial.
ASONAM 2017 5 / 30

MotivationUse cases
To gather information on conversations between pharmacistsand others to identify drug dosage, interactions andtherapeutic effects.
To acquire or collaborate on technologies invented byresearchers that can be a part of the drug pipeline.
To gather information about journalists’ survey on quality oflife of patients.
ASONAM 2017 6 / 30

Problem Definition
Given a social media post, identify the medical personae associatedwith it.
We pose this as multi-label text classification problem, where ourlabel set is {Patient, Caretaker, Consultant, Journalist, Pharmacist,Researcher, Other}
There are two primary reasons for setting this as a multi-labelclassification task (as opposed to single-label)
There might be posts involving conversations betweenmultiple personae. For example, a blog describingpatient-consultant conversation.
A post might be of ambiguous nature and hence canpotentially be mapped to more than one label by a humanannotator.
ASONAM 2017 7 / 30

Related Work
This problem is primarily related to two problems, which arethoroughly studied in literature
Authorship Attribution - The task of determining the authorof a particular document
Automatic Genre Identification (AGI) - The task of classifyingdocuments based on genres (which includes their form,structure, functional trait, communicative purpose, targetedaudience and narrative style) rather than the content, topicsor subjects that the documents span.
ASONAM 2017 8 / 30

Related WorkState-of-the-art Methods
For both, authorship attribution and AGI, supervised algorithmsbased on extensive feature engineering have been proposed. Thetop features include
Word n-grams
Character n-grams
Common words
Function words
Part-of-speech tags
Document statistics (e.g. document length)
HTML tags.
Stylistic features
Acronyms
Hashtag and reply mentions.
ASONAM 2017 9 / 30

Related WorkWhy can’t existing methods be trivially adapted?
Different features need to be explored for medical domain.
As opposed to most methods proposed in literature, our taskis of closed-set multi-label type.
Each persona has several users and will itself containheterogeneity.
ASONAM 2017 10 / 30

Dataset
Blog / Tweet Search APINoise Filtering &
Deduplication
Human
AnnotationQuery
Blogs / Tweets Labeled
Blogs / Tweets
Figure: Dataset Collection
Our dataset consists of both blogs as well as tweets.
Examples of queries include drug names - minocycline, qvar,gilenya
Whenever using only drugs as queries resulted in a lot ofirrelevant content, drug-disease pairs (e.g. acne minocycline)were used as queries.
We used 50 queries and retrieved 50 blogs and 30 tweets perquery.
Noisy posts, retweets were removed.
ASONAM 2017 11 / 30

Dataset
Figure: Dataset Statistics
1581 blogs and 1025 tweets were annotated
The inter-annotator agreement between 4 annotators wasfound to be 0.708 for blogs and 0.70 for tweets.
The label cardinality of blogs and tweets was 1.18 and 1.24respectively.
The maximum label cardinality of a blog was 2 and that of atweet was 3.
ASONAM 2017 12 / 30

ApproachOverview
We first transform the multi-label task into one or more singlelabel-task using
Binary label transformationLabel powerset transformation
We then use the following approaches to solve this task
N-gram approachFeature EngineeringAveraged Word VectorsCNN-LSTM
ASONAM 2017 13 / 30

ApproachLabel transformation method
Binary Relevance Method
We train an individual classifier for each label.
Given an unseen sample, the combined model then predicts alllabels for this sample for which the respective classifierspredict a positive result.
Label Powerset Method
We train one binary classifier for every label combinationattested in the training set
For an unseen example, prediction is done using a votingscheme.
ASONAM 2017 14 / 30

Approach
N-gram approach (Baseline)
Each document is represented as a TF-IDF vector over theentire vocabulary.
An SVM is trained to classify the document into one or moreof the pre-defined personae.
Both Word n-grams and character n-grams are used.
Averaged word Vectors
document vector(di ) =∑w ij
word embedding(w ij )
len(pi )(1)
ASONAM 2017 15 / 30
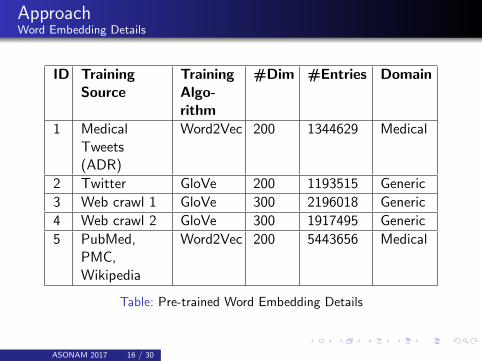
ApproachWord Embedding Details
ID TrainingSource
TrainingAlgo-rithm
#Dim #Entries Domain
1 MedicalTweets(ADR)
Word2Vec 200 1344629 Medical
2 Twitter GloVe 200 1193515 Generic
3 Web crawl 1 GloVe 300 2196018 Generic
4 Web crawl 2 GloVe 300 1917495 Generic
5 PubMed,PMC,Wikipedia
Word2Vec 200 5443656 Medical
Table: Pre-trained Word Embedding Details
ASONAM 2017 16 / 30

ApproachFeature Engineering
For this task, we manually engineered a total of 89 features,distributed in 6 feature types.
Document Level features (4)
Captures generic features of a postExamples - Number of sentences, average sentence length,average word lengthPharmacist blogs are lengthier than Patient blogs.
POS features (33)
Capture the distribution of different Parts-of-Speech in thedocument.Example - Number of AdjectivesA Consultant is 1.6 times more likely to use adjectives than ajournalist.
ASONAM 2017 17 / 30

ApproachFeature Engineering
List lookup features (7)
Include the average frequency of terms which occur in thedocument as well as in a particular list.Example - List of abusive words.The terms MD, Dr., MBBS, FRCS, consultation fee, werefound to be more frequent in consultant blogs than others.
Syntactic features (7)
Capture the presence or absence of various classes of terms.Example - date, person, location, organization, time, money,and percentage amounts.Researcher blogs contain more percentage mentions thanothers.
ASONAM 2017 18 / 30

ApproachFeature Engineering
Semantic features (35)
Consist of a lot of medical domain specific featuresExamples - number of disease mentions, drug mentions,chemical mentions, organ mentionsThe distribution across these features gives significant cluesabout the persona.These features were extracted using MetaMap.
Tweet specific features
Consist features specific to tweets onlyExamples - number of hashtags
ASONAM 2017 19 / 30

ApproachCNN Architecture
For experiments related to tweets, we use the following CNNarchitecture
Softmax / Sigmoid
Convolution
Layer
Max-pooling
Layer
Pre-trained Word
Embedding Layer
I am suffering pneumonia
Figure: CNN
ASONAM 2017 20 / 30

ApproachCNN-LSTM Architecture
For experiments related to blogs, we use the following CNN-LSTMarchitecture
LSTM LSTM LSTM
Softmax / Sigmoid
Layer
Convolution
Layer
Max-pooling
Layer
Pre-trained Word
Embedding Layer
Sequential
Layer
I treated a patient He was suffering fever Hygiene highly impacts dengue
Figure: CNN-LSTMASONAM 2017 21 / 30

Evaluation Metrics
Each evaluation metric is described on a per instance basis whichis subsequently averaged over all instances to obtain the aggregatevalue.
Let l and pr be the true label set and predicted label set fordocument d
Exact Match =
{1 if l = pr
0 otherwise(2)
Jaccard Similarity = |l ∩ pr |/|l ∪ pr | (3)
Precision = |l ∩ pr |/|pr | (4)
Recall = |l ∩ pr |/|l | (5)
F − Score = 2 ∗ Precision ∗ Recall/(Precision + Recall) (6)
ASONAM 2017 22 / 30

Evaluation Metrics
Hamming Loss =
∑|L|j=1 xor(l j , pr j)
|L|(7)
Hamming Score = 1 − Hamming Loss (8)
where l j , pr j denote j th element of l and pr respectively.
ASONAM 2017 23 / 30

Experimental Details
Throughout this work, we conduct 10 fold cross validationexperiments.
For extracting semantic features we use MetaMap.
For tuning hyperparameters in CNN and CNN-LSTM models,we used a grid search over the entire hyper-parameter spacewhich includes
Number of convolution filtersFilter sizesActivation Functions (ReLU and sigmoid)Size of hidden layerNumber of epochs
We select the configuration which maximizes the F-Score on ahold-out validation set.
ASONAM 2017 24 / 30

ResultsBlogs
Approach LTMethod
EmbId
JS EM HS F-Score
Wordunigrams
BR-
0.446 0.393 0.870 0.520LP 0.566 0.511 0.865 0.570
Charactern-grams
BR-
0.460 0.401 0.871 0.530LP 0.577 0.523 0.868 0.580
FeatureEngineering
BR-
0.461 0.409 0.872 0.530LP 0.574 0.518 0.867 0.580
AveragedWord2Vec
BR 3 0.608 0.521 0.880 0.600LP 4 0.627 0.568 0.886 0.640
CNN-LSTM
BR 3 0.496 0.421 0.846 0.460LP 3 0.586 0.514 0.869 0.600
Table: Results of all Approaches for Blogs
ASONAM 2017 25 / 30
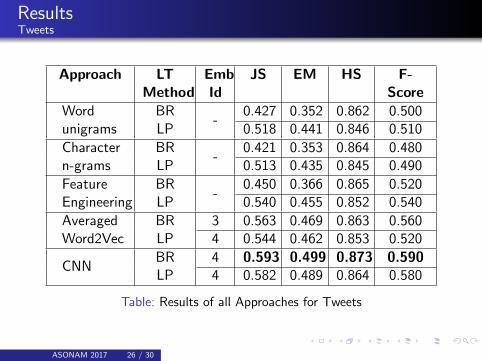
ResultsTweets
Approach LTMethod
EmbId
JS EM HS F-Score
Wordunigrams
BR-
0.427 0.352 0.862 0.500LP 0.518 0.441 0.846 0.510
Charactern-grams
BR-
0.421 0.353 0.864 0.480LP 0.513 0.435 0.845 0.490
FeatureEngineering
BR-
0.450 0.366 0.865 0.520LP 0.540 0.455 0.852 0.540
AveragedWord2Vec
BR 3 0.563 0.469 0.863 0.560LP 4 0.544 0.462 0.853 0.520
CNNBR 4 0.593 0.499 0.873 0.590LP 4 0.582 0.489 0.864 0.580
Table: Results of all Approaches for Tweets
ASONAM 2017 26 / 30

AnalysisFeature Analysis
FeatureGroup
Best Feature (Blogs) Best Feature (Tweets)
Document # characters (3) # characters (8)
Syntactic # Money mentions (2) # Money mentions (6)
List lookup # matching words withconsultant list (1)
# matching words withpatient word list (29)
Semantic # Inorganic chemical (38) # research activity (34)
POS # Foreign word (163) # Personal Pronoun(116)
Tweetspecific
- # hashtags (9)
Table: Feature Analysis for Blogs and Tweets based on χ2 metric.Number in the parenthesis indicates feature rank (lesser the better)
ASONAM 2017 27 / 30

Analysis and Conclusion
Averaged word2vec (for blogs), CNN model (for tweets)outperforms other approaches.
CNN-LSTM model fails to outperform averaged word2vecmethod, mainly due to the high number of trainable modelparameters
Word embeddings with superior medical concept coverage donot perform well against others. [May be coverage is not verycrucial for this task.]
Word embeddings trained purely on medical text (likePubMed articles) do not outperform others.
Lack of diversity of persona in training dataMost of the data is generated by few personae (like researchersfor PubMed)
ASONAM 2017 28 / 30

Future Work
The current features are limited to a posts content, we wouldlike to explore other featureslike social features, for example, number of followers on Twitter
We wish to experiment with distant supervision basedmethods to get automatically labeled examples for datahungry models like CNN-LSTM.
ASONAM 2017 29 / 30
