measuring individual learning performance in group work from a knowledge integration perspective
TRANSCRIPT

Information Sciences 179 (2009) 339–354
Contents lists available at ScienceDirect
Information Sciences
journal homepage: www.elsevier .com/locate / ins
Measuring individual learning performance in group workfrom a knowledge integration perspective
Jesualdo Tomás Fernández-Breis *, Dagoberto Castellanos-Nieves, Rafael Valencia-Garcı́aDepartamento de Informática y Sistemas, Facultad de Informática, Campus de Espinardo, Universidad de Murcia, CP 30100, Murcia, Spain
a r t i c l e i n f o
Article history:Received 29 July 2007Received in revised form 6 October 2008Accepted 8 October 2008
Keywords:Ontologye-LearningAssessmentKnowledge integrationCooperative work
0020-0255/$ - see front matter � 2008 Elsevier Incdoi:10.1016/j.ins.2008.10.014
* Corresponding author. Tel.: +34 968364613; faxE-mail addresses: [email protected] (J.T. Fernández
a b s t r a c t
Evaluation is an important part of the teaching–learning process, and it becomes more dif-ficult when individuals are developing a joint project and individual marks have to beassigned to the group members. Different strategies can be used to perform this task. Inthis work, an approach that combines the global group results and the individual perfor-mance is presented. This approach makes use of a semantic framework to rank the individ-ual participation of each group member and to compare their results with those theyshould have obtained to achieve the final mark. An experiment performed in real settingsis also reported in this paper.
� 2008 Elsevier Inc. All rights reserved.
1. Introduction
Learning is a social behavior; it only happens during group interactions [9]. Group work is a fact of life in the corporateworkforce [2], and group work learning is considered crucial nowadays. As a result, some academic institutions make explicitmention of it in their assessment policies, e.g. the University of Wollongong in Australia. Many companies also use sociallearning groups to promote organizational effectiveness and the formation of knowledge communities [9]. In [26], threegood reasons for group learning are presented. First, individuals can learn from each other and benefit from activities thatrequire them to articulate and test their knowledge. Group work provides an opportunity for individuals to clarify and refinetheir understanding of concepts through discussion with peers. Second, group work can help to develop skills sought byemployers. At this point, it should be noted that employers hire individuals and not groups, so individual performance mustbe taken into account when working in group. Third, group work may reduce the workload for assessing, grading and pro-viding feedback to individuals if groups are globally evaluated. In [45], the author states that evaluation is an integral part ofthe learning process, so special attention must be paid to it. The essence of evaluation is to obtain useful data for the indi-viduals, the teacher and the institution. In this sense, evaluation should be continuous, and individuals should get quickfeedback.
Different strategies for group assessment have been proposed [43]. One option is shared group marking, in which all thegroup members receive the same mark, but other strategies for individual marking can be found: allocated task, individualreport, examination, average and individual mark, distribution of pool marks, individual weightings, peer evaluation, etc.Grading individuals in group work has controversial aspects. First, individuals are concerned about the possibility thatthe mark does not reflect their own effort. Second, individual work should be evaluated, since students get individual de-grees. Third, grading group performance requires the teacher to be clear about how groups satisfy the course objectives.
. All rights reserved.
: +34 968364151.-Breis), [email protected] (D. Castellanos-Nieves), [email protected] (R. Valencia-Garcı́a).

340 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
In this work, we are interested in providing individual marks to each member of the group. Our approach is based on twopedagogical criteria: (1) teacher feedback should consist of reinforcing points of agreement but it should also include incon-sistencies and differences [40]; and (2) assessment of group work should be done several times during the assignment [45]. Acombination of group and individual performance can be used. The advantage of this approach is that it is perceived as fair,although it might require additional work for staff.
This study follows two cooperative learning principles: positive interdependency, and individual exigibility. This firstestablishes that the success of each individual is directly related to the success of the group. The goals and tasks are common,so all the members learn together. Each member is then fundamental in the cooperative learning process. On the other hand,individual exigibility means that the work of an individual is helpful for the other members. Each member is therefore able tolearn about all topics included in the group assignment. Our cooperative learning evaluation framework will assume theseprinciples, so good group members will have acquired all the knowledge possessed in the group.
On the technological side, the Semantic Web aims at adding semantic information to web contents in order to create anenvironment in which software agents will be capable of doing tasks efficiently [4]. The basic properties of the Semantic Weballow for meeting learning requirements: quickness, just-in-time and pertinent learning [35]. Semantic Web technologiesare commonly accepted for different purposes in the e-Learning community [11,29]. However, the assessment of individualperformance in cooperative work has not been addressed to date by using such technologies. One of the basic technologiesfor the Semantic Web is ontology. An ontology can be defined as a formal, and explicit specification of a shared conceptu-alization [23]. In this work, ontologies will be the knowledge representation technology, and performance measurementswill be based on ontology-related activities.
Our approach is based on the assumption that students are assigned a task to be solved in group, and that an ontology,representing the knowledge acquired by each individual along the assignment, can be obtained. Hence, the group result isobtained by merging the ontologies of the group members. An automatic ontology merging approach, which has been proveduseful for different problems (see Section 2) is used. This merging approach is capable of detecting and solving similaritiesand inconsistencies, so that some feedback might also be generated for the learners.
The structure of this paper is as follows. Section 2 contains the description of the technical foundations of this work. Theframework for evaluating individual performance will be presented in Section 3. Finally, some conclusions will be put for-ward in Section 4.
2. Technical foundations
In this section, the technical foundations and previous works are introduced to facilitate understanding.
2.1. Ontologies
In recent years, there has been a great interest in ontologies for representing knowledge, and it has become basic forKnowledge Management [27], the Semantic Web, Bioinformatics, e-Learning, Business to Business Applications, and so on[6]. Ontologies have also been used in medicine to represent medical models [36] and knowledge in diagnostic systems[38]. Ontologies present two main advantages for practitioners: the knowledge contained in an ontology is shareable andreusable, so the same ontological content can be used in different tasks and applications. In this work, ontologies are repre-sented by sets of concepts holding that: (1) every concept is defined through a set of attributes, so the presence of axiomsbetween these attributes is not considered; (2) concepts can be inter-related through different semantic relations. Repre-senting ontologies as sets of interrelated concepts is widely accepted (see for instance [3,6]). The ontological model usedin this work can be summarized as comprising: (1) concepts, which are the entities of the application domain; (2) the con-cepts’ attributes; (3) relationships that can be established among concepts; and (4) structural axioms that can be establishedaccording to the particular application domain.
One of the main problems is the construction of ontologies. There are several methodologies [7,12,15,21,28,31,32,34],although none can be considered standard. In this work, we assume that students are capable of building their own ontology,and any methodology can be used for it. On the other hand, a cooperative methodology is used for combining the ontologiesof the students in order to get the group ontology. The integrative methodology proposed in [19] is used. This methodologyhas already successfully been applied in different domains: (a) Intensive Care Units [37], to develop an ontology-based sys-tem for monitoring patients; (b) biological application domains [20]; (c) biomedical domains such as ‘‘diagnosis and plaguesin tomatoes” and ”diagnosis and diseases caused by protozoa” [17,18] with an academic purpose. The framework was usedfor integrating ontologies in the second and third domains and for managing intelligent alarms in the Intensive Care Unitapplication domain.
2.2. Cooperative learning and ontologies
In this work the group ontology is built by reusing students’ ontologies through integration processes. As stated in [5],cooperative modeling processes tend to reach stability, so after a series of iterations, the group knowledge would becomestable. The result of the cooperative learning process will depend on various parameters [19]:

J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354 341
� Consistency between the individual ontologies;� Redundancy between the individual ontologies;� The knowledge contained in the ontology, which is evaluated according to the following maximum information criterion:
the resulting ontology must be the one that provides the maximum information content.
Obviously, inconsistencies should be avoided. An ontology can be internally or externally inconsistent. In this work, anontology is internally inconsistent when some parts of it are inconsistent with others. External inconsistency appears whentwo (or more) ontologies are inconsistent. Hence, external inconsistencies may arise during cooperative ontology construc-tion processes, whereas internal ones can be avoided by following an appropriate methodology for building the ontology.
In this work, integration processes are performed as described in [19]. In this methodology, two ontologies can be inte-grated together if and only if they are neither inconsistent nor equivalent. Inconsistent ontologies cannot be directly inte-grated together because they would incorporate contradictory knowledge into the integration-derived ontology. On theother hand, new knowledge cannot be obtained by integrating equivalent ontologies. It should be noted that we are talkingabout completely equivalent ontologies, so degrees of similarity are not used. This methodology needs a reference ontologyfor the process, that is, the ontology that contains the best and correct knowledge when decisions have to be made. For thispurpose, different criteria can be used, e.g. the largest ontology, the most similar to a particular ontology, and so on.
Finally, this integration process comprises three main steps:
� Initialization: Capture of the individual ontologies to be integrated.� Integration: Selection of the largest subset of ontologies compatible for integration, i.e., without inconsistent or equivalent
ontologies. It also generates terminological unification.� Transformation: Fusion of the selected ontologies into a single, global ontology. This is carried out by merging those con-
cepts that are detected as synonyms and those having the same term associated and are not inconsistent.
In this work, the evaluation of the learning process will therefore be based on a series of metrics defined on top of thisintegration framework. These metrics would measure the similarity between the ontological knowledge of the group mem-bers and the correct one, which is defined by the teacher ontology. Fig. 1 describes the structure of this cooperative learningprocess. The students build their own ontologies, which are integrated to generate the group ontology. For this integration,the teacher ontology is used as the reference. Then, different metrics are applied to compare these ontologies, and the resultsfor each individual are finally obtained. Such metrics are further explained in Section 3.
2.3. Inconsistency management
As previously stated, consistency is a problem and the most relevant ontology mapping/merging methodologies [28] donot propose automatic solutions. Some detect inconsistencies and it is the user who must make the final decision. However,since our approach attempts to be automatic, such inconsistencies need to be treated automatically.
Some efforts have recently been made regarding inconsistency and conflict detection. In [24], conflicts are considered interms of dependencies between concepts and locking policies. Unfortunately, this approach is oriented to collaborative
Fig. 1. A sketch of the evaluation process based on integration processes.

342 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
development, so this approach cannot be applied to automatic merging processes. In [33], a systematic method for automat-ically detecting and solving various semantic conflicts in heterogeneous databases is proposed. Schemas at data and schemalevel are detected. At knowledge level, these conflicts might also be found in ontologies, such as the existence of homonymsand synonyms, concepts defined by dissimilar sets of attributes, or different abstraction levels. However, this approachmakes use of manual contextual mapping to a common ontology, so this problem is different to ours.
Over the last years, the integration framework described in Section 2.2 has been used in different domains. One of itsmain drawbacks is that it discards all the knowledge belonging to an ontology when this is classified as inconsistent. Thisinconsistency may be due to one single concept or relation, so the loss of potentially useful knowledge should be avoided.From the pedagogical side, detecting inconsistencies between the knowledge acquired by group members can be useful todetect potential problems. This might lead to a bad group performance, since a lot of knowledge might potentially get lost.The integration framework extension capable of managing some inconsistencies is now described.
2.3.1. Managing individual inconsistenciesAccording to the different reasoning elements taken into account in this approach, three types of inconsistencies can be
detected:Type I (Attribute-based inconsistency): Two concepts have an equal term associated, equivalent parent and children con-
cepts, but no common attributes. Given the automatic nature of this integration process, and due to the inexistence of anycommon internal property (i.e., attribute), both concepts cannot be supposed to refer to the same entity. An example isshown in Fig. 2, where the two PRINTER concepts have equivalent parents but no common attributes. This inconsistencyis managed by renaming the concepts. This action allows all the information contained the ontologies to be kept. Fig. 3 showsthe integrated ontology after this change.
Type II (Relations-based inconsistency): Two concepts from different ontologies have the same term assigned and com-mon parents of different nature, that is, one through taxonomy and one through mereology. This type of inconsistency can befound in Fig. 4. In the second ontology, the relations peripheral is a class of hardware and internal hardware is a class of hard-ware are inconsistent with the relations defined in the first ontology peripheral is part of hardware and internal hardware ispart of hardware.
Fig. 2. Example of Type I inconsistency.
Fig. 3. Integrated ontology after solving the Type I inconsistency.

Fig. 4. Example of Type II inconsistency.
J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354 343
The solution implies the removal of one in-conflict relation, followed by the analysis of the ontology after such removal.When the inconsistent relation is removed, the participants of such relations are also removed if they do not have other (tax-onomic or mereological) parent concepts in the ontology. In this case, their child concepts are recursively removed if they donot have other parent concepts either.
The integration of the two ontologies shown in Fig. 4 triggers a Type II inconsistency due to these incompatible relations:peripheral is a type of hardware and peripheral is a part of hardware. In this case the first ontology is the reference for the pro-cess because it has more concepts and relations, so the inconsistent relation is peripheral is part of hardware. Given thatperipheral does not have any child, this concept would be removed from the first ontology and now, both ontologies wouldbe consistent and, therefore, compatible for integration. The result of this integration process is shown in Fig. 5.
Type III inconsistency (Structural inconsistency): Two concepts have equivalent sets of attributes, but they do not haveany common parent. This is the case of the concepts hard disk in Fig. 6. There are internal and external hard disks. However,different ontology builders might assign the same term hard disk to both concepts, thus producing a Type III inconsistency.The concept hard disk of the left ontology has one taxonomic parent, Internal, and the set of attributes of hard disk is {vendor,
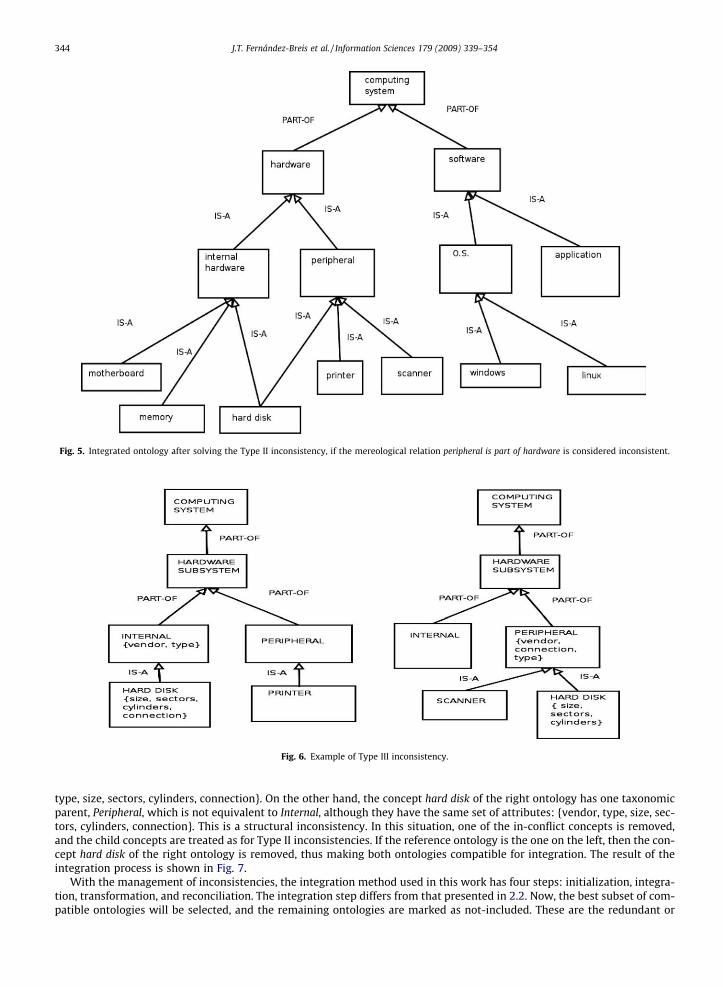
Fig. 5. Integrated ontology after solving the Type II inconsistency, if the mereological relation peripheral is part of hardware is considered inconsistent.
Fig. 6. Example of Type III inconsistency.
344 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
type, size, sectors, cylinders, connection}. On the other hand, the concept hard disk of the right ontology has one taxonomicparent, Peripheral, which is not equivalent to Internal, although they have the same set of attributes: {vendor, type, size, sec-tors, cylinders, connection}. This is a structural inconsistency. In this situation, one of the in-conflict concepts is removed,and the child concepts are treated as for Type II inconsistencies. If the reference ontology is the one on the left, then the con-cept hard disk of the right ontology is removed, thus making both ontologies compatible for integration. The result of theintegration process is shown in Fig. 7.
With the management of inconsistencies, the integration method used in this work has four steps: initialization, integra-tion, transformation, and reconciliation. The integration step differs from that presented in 2.2. Now, the best subset of com-patible ontologies will be selected, and the remaining ontologies are marked as not-included. These are the redundant or

Fig. 7. Integrated ontology after solving the Type III inconsistency.
J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354 345
inconsistent ontologies. The original transformation is applied to the selected ontologies. As a result of this process, a globalontology is obtained. Finally, the inconsistent ontologies are processed to be included into the global ontology on a one-by-one basis. The inconsistencies are solved by applying the aforementioned actions.
In summary, the ontological model and the integration framework that will serve as the kernel for defining the frame-work for measuring individual performance in group work have been described in this section. This integration frameworkis capable of managing inconsistencies, so that incompatible visions of the group members can be reconciled.
3. The individual performance measurement framework
When students do a group project, they usually distribute the workload and tasks, they interact and discuss the work.They acquire knowledge through such processes. After submitting the assignment, students are assessed and they obtaineither an individual or group mark. In this section, a framework for monitoring their progress and measuring individual per-formance is presented.
In the framework, each student is asked to represent ontologically the knowledge acquired at different stages of theassignment. The knowledge from all the group members is then integrated and feedback is provided in both quantitativeand qualitative terms. Some basic elements have to be defined before introducing the functions used for ranking and mark-ing students.
Definition 1 (Teacher ontology). The teacher ontology, written TO, is the ontology created by the teacher; it contains thecorrect solution for the students’ assignment.
Definition 2 (Personal ontology). A personal ontology, written PO, is the ontology submitted by the student.
Definition 3 (Group ontology). A group ontology, written GO, is the ontology resulting from the integration of all the groupmembers ontologies. In order to make this integration, the teacher ontology is used as the reference.
The different functions for ranking and marking students are defined in the next subsections.
3.1. Ranking individuals
In this subsection, the functions for ranking the individual work of the group members are presented. Such functions at-tempt to measure the consistency, the novelty and the quality of the knowledge acquired by any student in the context of thegroup.
Definition 4 (Degree of overlapping). The degree of overlapping, written DoO, is the ratio of common knowledge itemsbetween two ontologies. The application of this definition to PO and GO stands for the amount of personal knowledgeincluded in the group knowledge. The degree of overlapping is calculated as follows:
DoOðPO;GOÞ ¼ jPO \ GOjjGOj :
Definition 5 (Degree of innovation of a student). The degree of innovation of a student, written DoI, is the ratio of knowledgeitems included in the global one that were identified by only that particular student. The degree of innovation is calculated asfollows:

346 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
DoIðPO;GOÞ ¼ jPO� ðPO \Sn�1
i¼1 ZiÞjjPOj ;
where Zi is a personal ontology except for PO.
Definition 6 (Degree of support received by a student). The degree of support received by a student, written DoS, is theratio of students that identified the same knowledge items. The degree of support for an ontology is then calculated
as follows:DosðPOÞ ¼PX
i¼1DoSEðKiÞX , where X is the number of knowledge entities in PO, and Ki is the ith knowledge entity
in PO.
The degree of support for a particular knowledge entity, written DoSE, is calculated as the ratio of personal ontologies inwhich it appears:
DoSEðKiÞ ¼Pn
j¼1inðKi ;POjÞn ; where Ki is the ith knowledge entity of PO, POj is the jth personal ontology, n is the size of the
group, and in returns 1 if Ki has been defined in POj.Now the ranking functions used in this work are defined.
Definition 7 (Student ranking). The ranking of a student, written RANK, is determined by the weighted average of the threeprevious degrees: overlapping, innovation and support. This ranking would be calculated as follows:
RANKi ¼ b�1DoOðPOi;GOÞ þ b�2DoIðPOi;GOÞ þ b�3DoSðPOiÞ; where GO is the group ontology, POi is the personal ontology ofthe ith student, 0 6 b1 6 1 and
P3i¼1bi ¼ 1.
Three factors affect the ranking of the student within the group. First, the overlapping factor accounts for the proportionof common, consistent knowledge. Second, the degree of innovation accounts for the knowledge exclusively provided by aparticular member. Third, the degree of support accounts for the average number of members that identified the sameknowledge entities.
The values given to the three bi parameters would allow the teacher to give more importance to different aspects. A highvalue in b1 would mean that it is important to generate consistent knowledge. A high value in b2 would mean that it isimportant to be specialist in some topics, i.e. the only one that knows it. Finally, a high value in b3 would mean that it isimportant to have acquired common knowledge.
In order to obtain the ranking value for each student, the previous three functions have been normalized to avoid signif-icant differences due to high or low values for a particular parameter.
Definition 8 (Normalized overlapping). The normalized overlapping of a student, written nDoO, is the result of dividing thedegree of overlapping for such student and the highest degree of overlapping. It is then calculated as follows:nDoOi ¼ DoOi
maxfDoOjg ; j ¼ 1 . . . n; where n is the number of students in the group, and DoOk stands for DoO(POk, GO).
Definition 9 (Normalized innovation). The normalized innovation of a student, written nDoI, is the result of dividing thedegree of innovation for such student and the highest degree of innovation. It is then calculated as follows:nDoIi ¼ DoIi
maxfDoIjg; j ¼ 1 . . . n; where n is the number of students in the group, and DoIk stands for DoI(POk, GO).
Definition 10 (Normalized support). The normalized support of a student, written nDoS, is the result of dividing the degree ofsupport for such student and the highest degree of support. It is then calculated as follows:nDoSi ¼ DoSi
maxfDoSjg; j ¼ 1 . . . n; where n is the number of students in the group, and DoSk stands for DoS(POk).
Definition 11 (Normalized student ranking). The normalized ranking of a student, written nRANK, is the weighted average ofthe three previous normalized degrees. This ranking would be calculated as follows:nRANKi ¼ b�1nDoOi þ b�2nDoIi þ b�3nDoSi, where 0 6 b1 6 1and
P3i¼1bi ¼ 1:
The values given to the three bi parameters have the same meaning as in Definition 7.
3.2. Marking individuals
The previous functions are useful for ranking students, but they are not enough for marking. For this purpose, additionalmechanisms have to be considered. In this work they will be based on the semantic similarity of the ontologies. Conceptualsimilarity methods have been used in several applications, such as supporting the ontology engineer in reusing existingontologies [22] and to get better and closer results in semantic queries [13]. In our methodology, the teacher ontology ac-counts for the correct or ideal solution to the students’ assignment. Hence, this ontology will be used to obtain the seman-tic similarity of such ontology with the student and group ontologies. The functions for marking the students are definedbelow.
Definition 12 (Similarity between two ontologies). The similarity between the two ontologies, written SIM, is the amount ofontological entities that appear in both ontologies. The similarity is defined as follows:

J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354 347
� Two concepts are similar if they have the same name and are compatible for integration.� Two relations are similar if both participants are compatible for integration and the relation belongs to the same type, that
is, taxonomy or mereology.� Two attributes are similar if they belong to the same concept and they have the same name, since this framework does not
manage attribute data types.
Hence, the similarity function is defined as follows:
SIMðO1;O2Þ ¼PjO1 j
i¼1 similarity entityðEi;O2ÞjO2j
;
�
where similarity entityðE;OÞ ¼ 1 if there is a similar entity to E in O;0 otherwise:
Definition 13 (Group score). The group score, written GS, is the score obtained by the group as the result of the assessmentof their assignment. It has the same value for any member of the group. It is calculated as follows:
GS ¼ similarityðGO; TOÞ:
Definition 14 (Individual score). The individual score of a student, written IND, is the similarity of the student ontology andthe teacher one. It is calculated as follows:
INDi ¼ similarityðPOi; TOÞ:
Definition 15 (Normalized individual score). The normalized individual score of a student, written nIND, is the result of divid-ing the individual score for such student and the highest individual score. It is then calculated as follows:
nINDi ¼ INDimaxfINDjg ; j ¼ 1::n; where n is the number of students in the group.
Definition 16 (Ranked marking score). The ranked marking score of a student, written RMS, is the weighted average of theindividual score and its ranking score. In this case, each student would get the following score:
RMSi ¼ a�1INDi þ a�2RANKi, where 0 6 a1 6 1 andP2
i¼1ai ¼ 1.
The values given to the ai parameters would allow the teacher to give more importance to the individual score or to theranking one. A higher value for a1 would give more importance to the individual performance, whereas a higher value for a2
would give more importance to the relative performance of the student in the group.
Definition 17 (Normalized ranked marking score). The normalized ranking score, written nRMS, is the result of applying theformula for ranked score using their normalized factors. Hence, it is calculated as follows:
nRMSi ¼ a�1nINDi þ a�2nRANKi, where 0 6 a1 6 1 andP2
i¼1ai ¼ 1.
The values given to the two ai parameters have the same meaning as in Definition 16.
Definition 18 (Final ranked marking score). The final ranked marking score of a student, written fRS, is the result ofweighting the group score and the normalized ranking score for a student, thus providing the mark for the student. It iscalculated as follows:
fRSi ¼ c�1GSþ c�2nRMSi, where 0 6 c1 6 1 andP2
i¼1ci ¼ 1.
The values given to the ci parameters would allow the teacher to give more importance to the marking score or to theranking one. A higher value for c1 would give more importance to marking, whereas a higher value for c2 would give moreimportance to ranking.
Given that both GS and nRMSi are values between 0 and 1, the value of fRSi will also be in this range.
3.3. Applying the evaluation framework
This framework has recently been applied in a course with eight non computer science students, with similar backgroundand computing skills. They were asked to do a joint task on computers. Before the assignment, they were trained for 8 h overtwo weeks in the construction of ontologies using an ontology editor developed in our group. The group was given fourweeks to complete this assignment. In this experiment, only concepts and relations were considered, so the students werenot asked to define attributes. The students were asked to build the ontology twice during this period; after week two (seeTable 1), and at the end of the assignment, week four (see Table 2). The number of concepts, taxonomies and mereologies ofthe individual ontologies are shown in these tables. The column Entities accounts for the sum of the concepts, taxonomiesand mereologies.
Let us discuss the results obtained by each student Ei at weeks two and four. Table 3 shows the results at week two, andTable 4 for week four. In this experiment the parameters b1 = b2 = b3 = 0.33 have been used to calculate each student’s rank-ing. Note that the highest ranking value is shown in bold in each column.
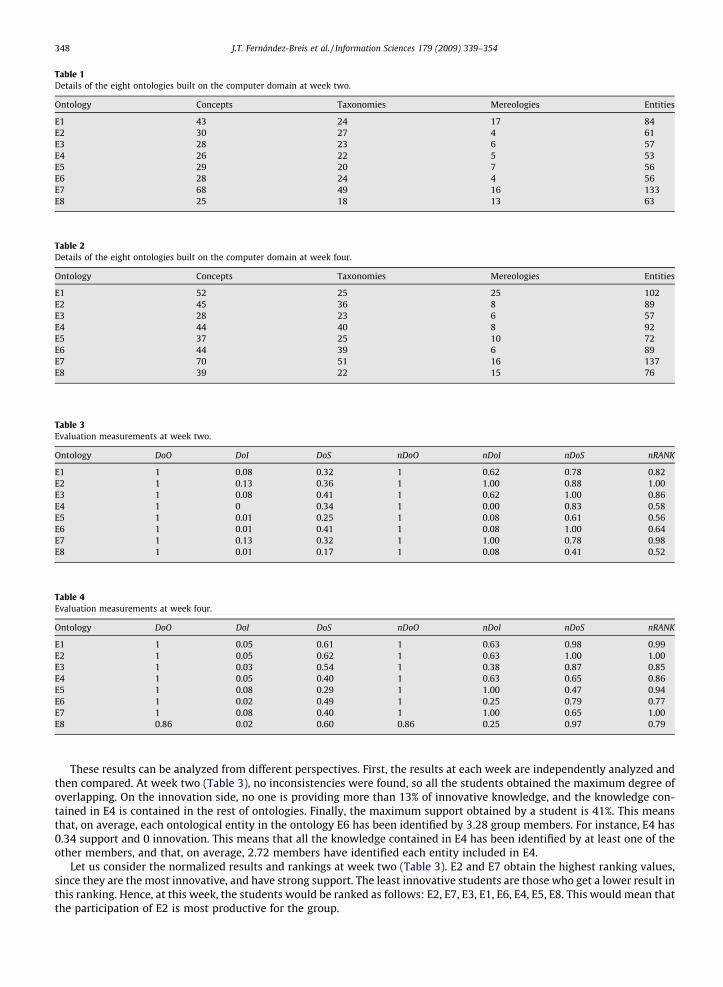
Table 1Details of the eight ontologies built on the computer domain at week two.
Ontology Concepts Taxonomies Mereologies Entities
E1 43 24 17 84E2 30 27 4 61E3 28 23 6 57E4 26 22 5 53E5 29 20 7 56E6 28 24 4 56E7 68 49 16 133E8 25 18 13 63
Table 2Details of the eight ontologies built on the computer domain at week four.
Ontology Concepts Taxonomies Mereologies Entities
E1 52 25 25 102E2 45 36 8 89E3 28 23 6 57E4 44 40 8 92E5 37 25 10 72E6 44 39 6 89E7 70 51 16 137E8 39 22 15 76
Table 3Evaluation measurements at week two.
Ontology DoO DoI DoS nDoO nDoI nDoS nRANK
E1 1 0.08 0.32 1 0.62 0.78 0.82E2 1 0.13 0.36 1 1.00 0.88 1.00E3 1 0.08 0.41 1 0.62 1.00 0.86E4 1 0 0.34 1 0.00 0.83 0.58E5 1 0.01 0.25 1 0.08 0.61 0.56E6 1 0.01 0.41 1 0.08 1.00 0.64E7 1 0.13 0.32 1 1.00 0.78 0.98E8 1 0.01 0.17 1 0.08 0.41 0.52
Table 4Evaluation measurements at week four.
Ontology DoO DoI DoS nDoO nDoI nDoS nRANK
E1 1 0.05 0.61 1 0.63 0.98 0.99E2 1 0.05 0.62 1 0.63 1.00 1.00E3 1 0.03 0.54 1 0.38 0.87 0.85E4 1 0.05 0.40 1 0.63 0.65 0.86E5 1 0.08 0.29 1 1.00 0.47 0.94E6 1 0.02 0.49 1 0.25 0.79 0.77E7 1 0.08 0.40 1 1.00 0.65 1.00E8 0.86 0.02 0.60 0.86 0.25 0.97 0.79
348 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
These results can be analyzed from different perspectives. First, the results at each week are independently analyzed andthen compared. At week two (Table 3), no inconsistencies were found, so all the students obtained the maximum degree ofoverlapping. On the innovation side, no one is providing more than 13% of innovative knowledge, and the knowledge con-tained in E4 is contained in the rest of ontologies. Finally, the maximum support obtained by a student is 41%. This meansthat, on average, each ontological entity in the ontology E6 has been identified by 3.28 group members. For instance, E4 has0.34 support and 0 innovation. This means that all the knowledge contained in E4 has been identified by at least one of theother members, and that, on average, 2.72 members have identified each entity included in E4.
Let us consider the normalized results and rankings at week two (Table 3). E2 and E7 obtain the highest ranking values,since they are the most innovative, and have strong support. The least innovative students are those who get a lower result inthis ranking. Hence, at this week, the students would be ranked as follows: E2, E7, E3, E1, E6, E4, E5, E8. This would mean thatthe participation of E2 is most productive for the group.
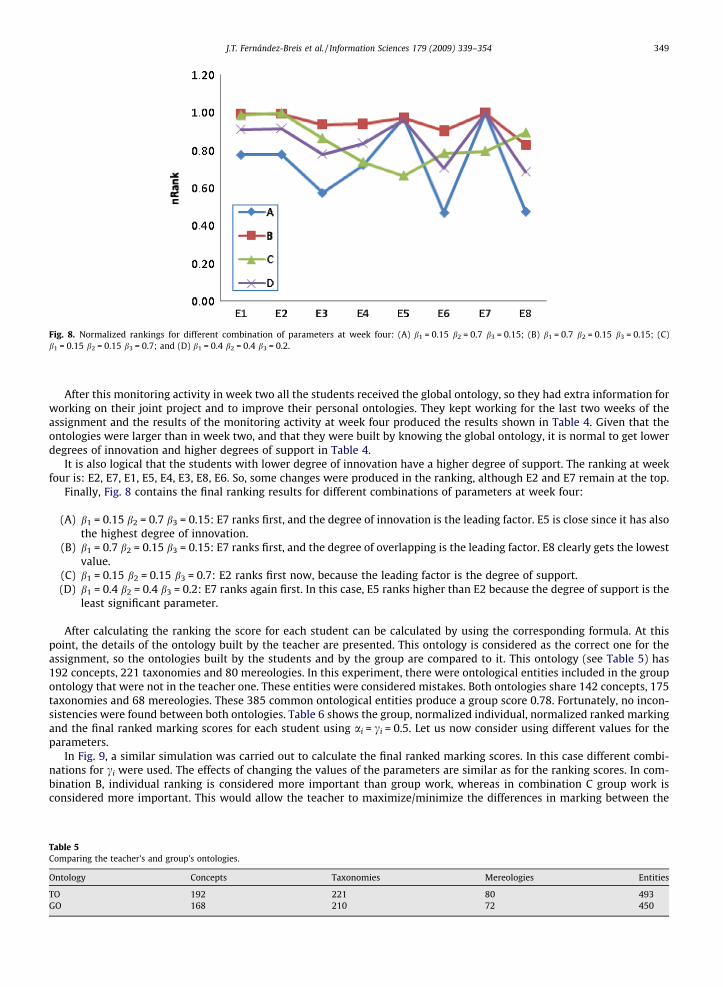
Fig. 8. Normalized rankings for different combination of parameters at week four: (A) b1 = 0.15 b2 = 0.7 b3 = 0.15; (B) b1 = 0.7 b2 = 0.15 b3 = 0.15; (C)b1 = 0.15 b2 = 0.15 b3 = 0.7; and (D) b1 = 0.4 b2 = 0.4 b3 = 0.2.
J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354 349
After this monitoring activity in week two all the students received the global ontology, so they had extra information forworking on their joint project and to improve their personal ontologies. They kept working for the last two weeks of theassignment and the results of the monitoring activity at week four produced the results shown in Table 4. Given that theontologies were larger than in week two, and that they were built by knowing the global ontology, it is normal to get lowerdegrees of innovation and higher degrees of support in Table 4.
It is also logical that the students with lower degree of innovation have a higher degree of support. The ranking at weekfour is: E2, E7, E1, E5, E4, E3, E8, E6. So, some changes were produced in the ranking, although E2 and E7 remain at the top.
Finally, Fig. 8 contains the final ranking results for different combinations of parameters at week four:
(A) b1 = 0.15 b2 = 0.7 b3 = 0.15: E7 ranks first, and the degree of innovation is the leading factor. E5 is close since it has alsothe highest degree of innovation.
(B) b1 = 0.7 b2 = 0.15 b3 = 0.15: E7 ranks first, and the degree of overlapping is the leading factor. E8 clearly gets the lowestvalue.
(C) b1 = 0.15 b2 = 0.15 b3 = 0.7: E2 ranks first now, because the leading factor is the degree of support.(D) b1 = 0.4 b2 = 0.4 b3 = 0.2: E7 ranks again first. In this case, E5 ranks higher than E2 because the degree of support is the
least significant parameter.
After calculating the ranking the score for each student can be calculated by using the corresponding formula. At thispoint, the details of the ontology built by the teacher are presented. This ontology is considered as the correct one for theassignment, so the ontologies built by the students and by the group are compared to it. This ontology (see Table 5) has192 concepts, 221 taxonomies and 80 mereologies. In this experiment, there were ontological entities included in the groupontology that were not in the teacher one. These entities were considered mistakes. Both ontologies share 142 concepts, 175taxonomies and 68 mereologies. These 385 common ontological entities produce a group score 0.78. Fortunately, no incon-sistencies were found between both ontologies. Table 6 shows the group, normalized individual, normalized ranked markingand the final ranked marking scores for each student using ai = ci = 0.5. Let us now consider using different values for theparameters.
In Fig. 9, a similar simulation was carried out to calculate the final ranked marking scores. In this case different combi-nations for ci were used. The effects of changing the values of the parameters are similar as for the ranking scores. In com-bination B, individual ranking is considered more important than group work, whereas in combination C group work isconsidered more important. This would allow the teacher to maximize/minimize the differences in marking between the
Table 5Comparing the teacher’s and group’s ontologies.
Ontology Concepts Taxonomies Mereologies Entities
TO 192 221 80 493GO 168 210 72 450
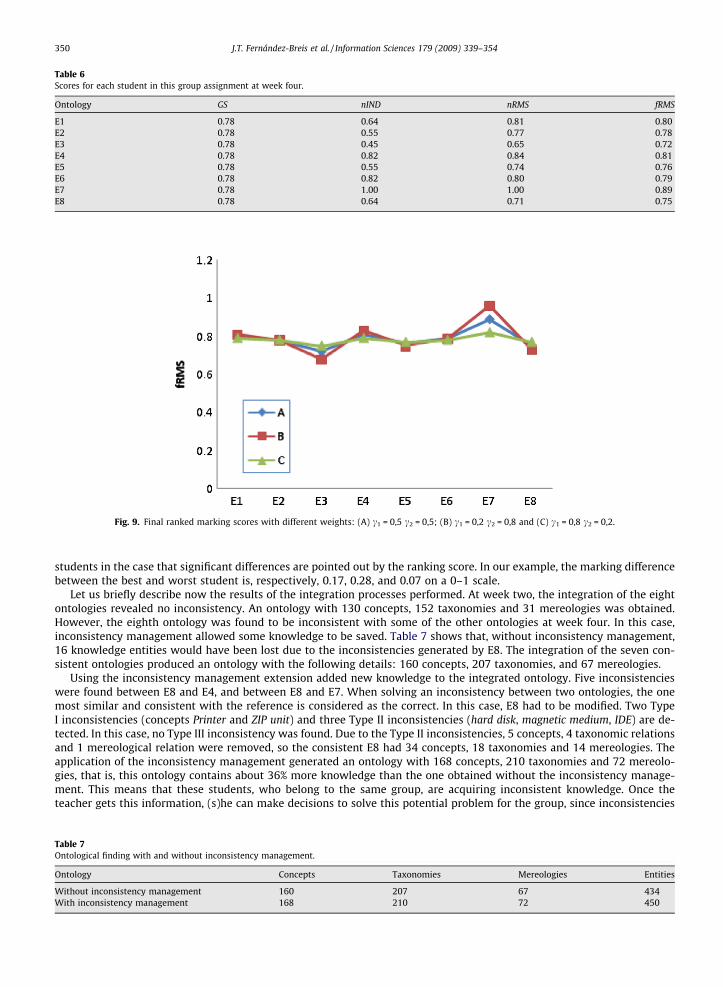
Fig. 9. Final ranked marking scores with different weights: (A) c1 = 0,5 c2 = 0,5; (B) c1 = 0,2 c2 = 0,8 and (C) c1 = 0,8 c2 = 0,2.
Table 6Scores for each student in this group assignment at week four.
Ontology GS nIND nRMS fRMS
E1 0.78 0.64 0.81 0.80E2 0.78 0.55 0.77 0.78E3 0.78 0.45 0.65 0.72E4 0.78 0.82 0.84 0.81E5 0.78 0.55 0.74 0.76E6 0.78 0.82 0.80 0.79E7 0.78 1.00 1.00 0.89E8 0.78 0.64 0.71 0.75
350 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
students in the case that significant differences are pointed out by the ranking score. In our example, the marking differencebetween the best and worst student is, respectively, 0.17, 0.28, and 0.07 on a 0–1 scale.
Let us briefly describe now the results of the integration processes performed. At week two, the integration of the eightontologies revealed no inconsistency. An ontology with 130 concepts, 152 taxonomies and 31 mereologies was obtained.However, the eighth ontology was found to be inconsistent with some of the other ontologies at week four. In this case,inconsistency management allowed some knowledge to be saved. Table 7 shows that, without inconsistency management,16 knowledge entities would have been lost due to the inconsistencies generated by E8. The integration of the seven con-sistent ontologies produced an ontology with the following details: 160 concepts, 207 taxonomies, and 67 mereologies.
Using the inconsistency management extension added new knowledge to the integrated ontology. Five inconsistencieswere found between E8 and E4, and between E8 and E7. When solving an inconsistency between two ontologies, the onemost similar and consistent with the reference is considered as the correct. In this case, E8 had to be modified. Two TypeI inconsistencies (concepts Printer and ZIP unit) and three Type II inconsistencies (hard disk, magnetic medium, IDE) are de-tected. In this case, no Type III inconsistency was found. Due to the Type II inconsistencies, 5 concepts, 4 taxonomic relationsand 1 mereological relation were removed, so the consistent E8 had 34 concepts, 18 taxonomies and 14 mereologies. Theapplication of the inconsistency management generated an ontology with 168 concepts, 210 taxonomies and 72 mereolo-gies, that is, this ontology contains about 36% more knowledge than the one obtained without the inconsistency manage-ment. This means that these students, who belong to the same group, are acquiring inconsistent knowledge. Once theteacher gets this information, (s)he can make decisions to solve this potential problem for the group, since inconsistencies
Table 7Ontological finding with and without inconsistency management.
Ontology Concepts Taxonomies Mereologies Entities
Without inconsistency management 160 207 67 434With inconsistency management 168 210 72 450

J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354 351
are a source of problems in cooperative work. With this inconsistency management, we are able to detect possible flaws inthe group, which is also an important task of the teacher monitoring the group.
3.4. Summary and remarks
This framework provides mechanisms for evaluating individuals in group work by detecting the most important and rele-vant contributions for the final group results. This framework assumes that an ontology can be obtained for each student. It doesnot actually impose that the students build the ontology, since the ontology may be obtained through different processes. Thegroup ontology is then built by applying integration processes. The framework also requires one teacher ontology, which cor-responds to the correct solution of the assignment. Hence, comparisons between pairs of ontologies are performed to obtain thequality of the group and the individual performance. In this way, students are marked by combining three factors:
(1) Quality of the group work: This factor accounts for the correctness of the work. It is measured by comparing theknowledge contained in the group ontology and the correct knowledge, which is contained in the teacher ontology.
(2) Quality of the individual work: This factor accounts for the correctness of knowledge acquired by each student. It ismeasured by comparing the knowledge contained in the individual ontology and the expected knowledge, containedin the teacher ontology.
(3) Relevance of the student in the group: This factor accounts for the role played by the student in the group. It attemptsto measure the student’s influence and contribution in the group work. It is measured by comparing the knowledge ofthe student with the group knowledge and the knowledge of the rest of group members.
Factor 1 is more oriented to marking. Obviously, each group member would get the same score for factor 1. However, thisfactor is necessary to obtain the mark of the assignment since it accounts for the correctness of the group work. On the otherhand, factors 2 and 3 allow grading of the group members, so they are oriented to ranking students. Both factors are com-bined to obtain the normalized ranked marking score (Definition 17). The marking and ranking components are then com-bined (Definition 18) to obtain the score of each group member.
Hence, individual marks can be graded by the normalized ranked marking score, and the mark of each group member hastwo components: the group work and the ranked marking score. In our approach, the teacher is currently responsible fordefining the importance of both components, as shown in the example in the previous subsection. Each teacher may havea different policy and each assignment may even have its own properties, requirements and difficulty. All this informationcan be used by the teacher for weighting group and individual performance. There might be assignments in which the tea-cher is only interested in the group result. In this case, ranking factor nRMS would not be considered in Definition 18. On theother hand, there might be group assignments in which the teacher is more interested in the individual performance of stu-dents, so assigning a higher weight to the ranking factor nRMS in Definition 18.
Furthermore, the possibilities the framework gives to teachers for defining the marking style is not just to weight groupand individual performance. Let us focus now on the RANK factor. It combines different aspects of individual performance fora given student: knowledge overlap with other group members, knowledge that only such student has, and how many groupmembers support the knowledge such student has. Teachers can also decide which factor is more important in a particularassignment. One decision might be, for instance, to consider innovation the most important factor.
In summary, this framework provides teachers with a flexible series of elements that can be combined according to theobjectives of each particular group assignment. The application of the framework in a real course revealed interesting results,since we were capable of providing individual marks to each group member. The students were shown the results, and weasked them to give their opinion anonymously about the mark and rank they were given. They were asked about their mark,and chose one of three possible answers: better than deserved, fair, worse than deserved. They were also asked for the otherstudents’ rank. They were asked which they considered the most unfair, if any. Only one student considered his mark worsethan deserved. However, the other students did not consider that mark unfair.
Finally, the teacher’s ontology acts as the correct knowledge for the group work in this framework. The marks are thengiven to the group and the individuals by making automatic comparisons and calculations. Nevertheless, provided that weknow what knowledge has been acquired by the student and what has not, extensions to this framework dealing with thegeneration of semantic feedback to students are feasible.
4. Discussion and conclusions
Group work is an important learning process, which requires specific attention due to its characteristics and the problemsderived from its assessments. In this work, an approach that combines the overall group result and the individual ones isused to assess individual performance in group works, ranking and marking.
The literature provides different approaches for ranking groups and individuals in different contexts. As stated in [44],ranking groups is different from ranking individuals. For these authors, groups should not be ranked by using mean values,but according to other indices less sensitive to manipulation. However, such indices tend to be less sensitive to individualperformance. Ranking is approached there by the average number of hits scored by group members. This is similar to our

352 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
approach, although we consider semantic hits. Our approach would also allow for a better interpretation of the results, sincethe ontology provides a semantic context that might be used for different academic purposes, such as generating feedback orself-assessment.
In [25], statistical methods are used to rank individuals by group comparisons. Different teams compete, and the individ-ual results are obtained by combining the team results. In this way, if an individual is part of winning teams, this individualwould get a good ranking. For instance, given three players P1, P2, and P3, if the team (P1,P2) has better results than the team(P2,P3), P1 ranks better than P3. Individuals are then ranked by group results. This approach makes use of inter-group resultsto infer relative individual performance, whereas our approach proposes the measurement of individual performance byusing intra-group explicit metrics.
On the other hand, approaches such as [1] use semantic-related factors to rank. This approach does not consider cooper-ative processes, because it assumes the existence of a group of users who are not performing cooperative tasks. Our approachtakes semantic cooperation-related artifacts into account by considering support, overlapping and innovation metrics, whichcan be exploited in different ways such as ranking, marking, feedback generation, etc.
Genetic algorithms use problem-oriented ranking functions, whereas our approach tends to use a general function. Ge-netic algorithms rank individuals according to population properties for selection purposes. Our goal is clearly different sincethe members of the population are the group members, and there is no need for selection but for marking and ranking. Forthis purpose, semantics-based approaches are more appropriate due to the context they provide for supporting the decisionsmade.
Fuzzy sets have also been used to evaluate performance. An example in the e-Learning field can be found in [41,42]. There,vague marks are given to each student. However, this work does not address the assessment of group work but individualstudent answers. An advantage of our approach is that it can be applied either to groups or individuals; these can be seen asgroups of size one. In such case, the weight of the ranking-related factors should be zero.
The approaches presented in [8,14] are applicable to individual assessment. The OeLE system [8], developed in our re-search group, makes use of semantic web and natural language technologies to support the assessment of open ques-tions-based exams by employing semantic similarity measurements. We are interested in including this group evaluationframework in OeLE to extend its assessment capabilities. [14] presents a learning and assessment system based on the writ-ing of course hyperbooks and the comparison of domain ontologies. There, each student makes his own hyperbook from acourse ontology and the individual hyperbooks are compared and discussed manually and collaboratively, whereas our ap-proach is fully automatic.
Most related works are interested in providing individual marks to individual assessment tests, and most do not make useof semantic components. We are not providing just a quantitative result of the individual performance, but also a qualitativeand quantitative semantic interpretation of the learning process, which can be used by teachers to adjust such process, andthis is likely to be the most important advantage of our approach. Given the inability of such related approaches to providethe type of output needed by teachers and students, we did not carry out a comparative performance analysis of such ap-proaches, something which might be interesting to detect potential improvement to our metrics.
The framework presented in this paper ranks and mark students according to the knowledge they acquire during thegroup work. For this purpose, the knowledge generated by the group is audited and classified into common, private andinconsistent knowledge. Common knowledge is acquired by most group members. Private knowledge is only acquired byone student. Students having private knowledge can be considered the group experts in such area. Finally, inconsistentknowledge represents learning flaws in the group, since the different members are learning incompatible knowledge. So, thisframework is providing teachers with different evaluation instruments, not just a mark or a rank. Once the framework isapplied, the teacher knows the group and individual performance, the group and individual strengths and weaknesses,the role played by each individual, and the group learning flaws. All these aspects are qualitatively and quantitatively pro-vided by the combination of the integration and evaluation frameworks, whereas other previously commented approachesonly focus on getting a quantitative ranking or marking of students and group members.
Using ontologies as the kernel technology for ranking and marking students, as is done here, allows more effective eval-uation of groups and students than non ontology-based methods. Through the application of this framework in differentassignments, semantic learning models of the students and groups can be acquired. The analysis of such models might allowlearning profiles and flaws to be obtained and this information might be used by the teacher to change or adapt the learningobjects according to student needs. Since different assignments might be focused on the same conceptual entities, althoughhaving a different perspective, our approach would also allow to measure how the shared conceptual entities are acquired bythe students from the different perspectives. Each perspective might correspond to particular learning methodology, so ourframework might also be used to semantically compare the different results obtained by the students using different learn-ing methodologies.
In each group, the members play different roles, and some members collaborate more than others. In this framework, thisissue is measured from a semantic perspective. Members are more relevant if they present a good balance between their degreeof innovation, degree of support and degree of overlapping. That is, the most relevant members should not produce inconsis-tencies, should add new, innovative knowledge, and most of their knowledge should be supported by the rest of the group.
An extension to an existing framework for automatic ontology integration has been made, which allows for the manage-ment of inconsistencies. The original framework discards all the knowledge contained in an inconsistent ontology. Theextension allows for only the inconsistent parts to be discarded.

J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354 353
Finally, there are open research issues to improve this framework. First, the integration framework only considers taxo-nomic and mereological relations. This might be improved to be made applicable in more realistic problems. From the anal-ysis of the integration framework, different improvements have been proposed to increase the flexibility of the integrationprocess, such as the use of Wordnet synsets to detect synonymy or the use of isolated concept regions analysis [39] to im-prove inconsistency management processes. With respect to the evaluation framework, improvements can be made in dif-ferent directions. First, the framework is very flexible since it has an interesting set of parameters. It would be interesting tobe able to obtain the best combination of parameters for a particular evaluation policy. Moreover, we are considering theinclusion of a new factor in the scoring function accounting for the evolution of the student along the assignment. Ap-proaches such as those presented in [10,16,30] provide interesting mechanisms to address these issues.
Acknowledgements
This work has been possible thanks to the Seneca Foundation, through Project 05738/PI/07, and the Regional Governmentof Murcia, through project TIC-INF 07/01-0001.
References
[1] H. Alani, C. Brewster, Ontology ranking based on the analysis of concept structures, in: Proceedings of the 3rd International Conference on KnowledgeCapture, Banff, Canada, 2005, pp. 51–58.
[2] T.A. Angelo, K.P. Cross, Classroom Assessment Techniques, second ed., Jossey-Bass, San Francisco, 1993, pp. 349–351.[3] V.R. Benjamins, D. Fensel, S. Decker, A. Gómez-Pérez, (KA)2: building ontologies for the internet. A mid-term report, International Journal of Human–
Computer Studies 51 (3) (1999) 687–712.[4] T. Berners-Lee, J. Hendler, O. Lassila, The semantic web, The Scientific American (2001).[5] G. Beydoun, A. Hoffmann, J.T. Fernández-Breis, R. Martı́nez-Béjar, R. Valencia-Garcı́a, A. Aurum, Cooperative modeling evaluated, International Journal
of Cooperative Information Systems 14 (1) (2005) 45–71.[6] C. Brewster, K. O’Hara, S. Fuller, Y. Wilks, E. Franconi, M.A. Musen, J. Ellman, S. Buckinham Shum, Knowledge representation with ontologies: the
present and future, IEEE Intelligent Systems 19 (1) (2004) 72–81.[7] D. Calvanese, G. Giacomo, M. Lenzerini, Ontology of integration and integration of ontologies, in: Working Notes of the 2001 International Description
Logics Workshop, Stanford, CA, USA, 2001.[8] D. Castellanos-Nieves, J.T. Fernández-Breis, R. Valencia-Garcı́a, R. Martı́nez-Béjar, A semantic web technologies-based system for students assessment,
in: e-Learning Environments, IADIS e-Learning Conference, Lisbon, Portugal, 2007, pp. 451–458.[9] R.S. Chen, C.H. Hsiang, A study on the critical success factors for corporations embarking on knowledge community-based e-learning, Information
Sciences 177 (2007) 570–586.[10] Y. Chen, W. Su, New robust stability of cellular neural networks with time-varying discrete and distributed delays, International Journal of Innovative
Computing, Information and Control 3 (6B) (2007) 1549–1556.[11] V. Devedzic, Semantic Web and Education, Springer, 2006.[12] J. Domingue, Tadzebao and WebOnto: discussing, browsing, and editing ontologies on the web, in: Proceedings of the 11th Workshop on Knowledge
Acquisition, Modelling and Management, Banff, Canada, 1998.[13] G. Erozel, N.K. Cicekli, I. Cicekli, Natural language querying for video databases, Information Sciences 178 (2008) 2534–2552.[14] G. Falquet, L. Nerima, J.C. Ziswiler, Ontologies and ontology mapping for supporting student assessment in an advanced learning system, in: P.
Kommers, G. Richards (Eds.), Proceedings of World Conference on Educational Multimedia, Hypermedia and Telecommunications, Montreal, Canada,2005, pp. 3858–3864.
[15] A. Farquhar, R. Fikes, J. Rice, The ontolingua server: a tool for collaborative ontology construction, International Journal of Human–Computer Studies 46(1997) 707–727.
[16] A. Fekih, H. Xu, F. Chowdhury, Neural networks based system identification techniques for model based fault detection of nonlinear systems,International Journal of Innovative Computing, Information and Control 3 (5) (2007) 1073–1085.
[17] J.T. Fernández-Breis, R. Martínez-Béjar, A web-based framework for integrating knowledge, Industrial Knowledge Management – A Micro LevelApproach (2000) 123–138.
[18] J.T. Fernández-Breis, R. Martínez-Béjar, A cooperative tool for facilitating knowledge management, Expert Systems with Applications 18 (4) (2000)315–330.
[19] J.T. Fernández-Breis, R. Martínez-Béjar, A cooperative framework for integrating ontologies, International Journal of Human–Computer Studies 56 (6)(2002) 662–717.
[20] J.T. Fernández-Breis, R. Martínez-Béjar, R. Valencia-García, P.J. Vivancos-Vicente, F. García-Sánchez, Towards cooperative frameworks for modeling andintegrating biological processes knowledge, IEEE Transactions on NanoBioscience 3 (3) (2004) 164–171.
[21] M. Fernández-López, A. Gómez-Pérez, A. Pazos-Sierra, J. Pazos-Sierra, Building a chemical ontology using METHONTOLOGY and the ontology designenvironment, IEEE Intelligent Systems and Their Applications (January/February) (1999) 37–46.
[22] A. Formica, Ontology-based concept similarity in formal concept analysis, Information Sciences 176 (2006) 2624–2641.[23] T.R. Gruber, A translation approach to portable ontology specifications, Knowledge Acquisition 5 (2) (1993) 199–220.[24] Z. Hellman, A. Gal, Structural conflict avoidance in collaborative ontology engineering, in: Proceedings of the 5th International Conference on
Enterprise Information Systems, Angers, France, pp. 67–76.[25] T.K. Huang, C.J. Lin, R. Weng, Ranking individuals by group comparisons, in: Proceedings of the 23rd International Conference on Machine Learning,
Pittsburgh, Pennsylvania, 2006, pp. 425–432.[26] R. James, C. McInnis, M. Devlin, Assessing learning in Australian universities, 2002. http://www.cshe.unimelb.edu.au/assessinglearning/.[27] L.F. Lai, A knowledge engineering approach to knowledge management, Information Sciences 177 (2007) 4072–4094.[28] D.B. Lenat, R.V. Guha, Building Large Knowledge-based Systems, Addison-Wesley, 1990.[29] M.D. Lytras, A. Pouloudi, N. Korfiatis, An ontological oriented approach on e-learning: integrating semantics for adaptive e-learning systems, in: C.
Ciborra et al. (Eds.), New Paradigms in Organizations, Markets and Society, Proceedings of the 11th European Conference on Information Systems,2003.
[30] L. Mi, F. Takeda, Analysis on the robustness of the pressure-based individual identification system based on neural networks, International Journal ofInnovative Computing, Information and Control 3 (1) (2007) 97–110.
[31] N. Noy, M.A. Musen, The PROMPT suite: interactive tools for ontology mapping and merging, International Journal of Human–Computer Studies 59(2003) 983–1024.
[32] S. Ram, J. Park, Semantic conflict resolution ontology (SCROL): an ontology for detecting and resolving data and schema-level semantic conflicts, IEEETransactions on Knowledge and Data Engineering 16 (2) (2004) 189–202.

354 J.T. Fernández-Breis et al. / Information Sciences 179 (2009) 339–354
[33] S. Pinto, S. Staab, C. Tempich, DILIGENT: towards a fine-grained methodology for distributed loosely-controlled and evolving engineering of ontologies,in: Proceedings of the 16th European Conference on Artificial Intelligence, Valencia, Spain, 2004, pp. 393–397.
[34] S. Staab, H.P. Schnurr, R. Studer, Y. Sure, Knowledge processes and ontologies, IEEE Intelligent Systems 16 (1) (2001) 26–34.[35] L. Stojanovic, S. Staab, R. Studer, e-Learning based on the semantic web, in: Proceedings of World Conference on the WWW and Internet, Orlando,
Florida, 2001, pp. 1174–1183.[36] A.R. Tawil, M. Montebello, R. Bahsoon, W.A. Gray, N.J. Fiddian, Interschema correspondence establishment in a cooperative OWL-based multi-
information server grid environment, Information Sciences 178 (2008) 1011–1031.[37] F.J. Torralba-Rodríguez, J.T. Fernández-Breis, R. Valencia-García, J.M. Ruíz-Sánchez, R. Martínez-Béjar, J.A. Gómez-Rubí, An ontological framework for
representing and exploiting medical knowledge, Expert Systems with Applications 25 (2) (2003) 211–230.[38] M. Ulieru, M. Hadzic, E. Chang, Soft computing agents for e-health in application to the research and control of unknown diseases, Information Sciences
176 (2006) 1190–1214.[39] R. Valencia-García, J.T. Fernández-Breis, J.M. Ruiz-Martínez, F. García-Sánchez, R. Martínez-Béjar, An incremental ontology-centred methodology for
information retrieval from medical documents, Expert Systems: The Knowledge Engineering Journal 25 (3) (2008) 314–334.[40] C.J. Walker, Assessing group process: using classroom assessment to build autonomous learning teams, Assessment Update 7 (6) (1995) 4–5.[41] H.Y. Wang, S.M. Chen, Evaluating students’ answer scripts using vague values, Applied Intelligence 28 (2008) 83–193.[42] H.Y. Wang, S.M. Chen, Evaluating students’ answer scripts based on extended fuzzy grade sheets, International Journal of Innovative Computing
Information and Control 4 (4) (2008) 961–970.[43] T. Winchester-Seeto, Assessment of collaborative work – collaboration versus assessment, in: Invited Paper Presented at the Annual Universe Science
Symposium, The University of Sydney, April 2002.[44] S. Yitzhaki, M. Eisenstaedt, Ranking individuals versus groups, 2002. Available at SSRN: http://ssrn.com/abstract = 351041.[45] H.G. Zamora, La evaluación, parte fundamental e integral del proceso de aprendizaje, Eduteka 6 (2002) 14. (in Spanish).