material: dr barend erasmus bcb 341: principles of conservation biology
TRANSCRIPT

Material: Dr Barend Erasmus
BCB 341: Principles of Conservation Biology

• Why model species ranges?
• What is a niche? – fundamental and realised
• Correlative range modelling – background and assumptions
• Distribution datasets• Variables and their
selection• Models and their selection• Model calibration and
evaluation

We need to know where species occur and why they occur where they do:
We want to predict where a particular species occurs.
We want to know more about organism-environment relationships

increasing rates of habitat, and species loss, incomplete (spatial and temporal) distribution
info for a large number of taxa, existing distribution data collected in an ad hoc
fashion.
Given the rate of species loss, it is unlikely that we will get the distribution data that we need in time if we rely on conventional survey techniques.
Atlases are an invaluable data source and cover very few taxa but they are very important for model development and calibration.

species richness (Jetz & Rahbeck 2002) centres of endemism (Johnson, Hay & Rogers 1998), the occurrence of particular species assemblages
(Neave, Norton & Nix 1996), the occurrence of individual species (Gibson et al.
2004), the location of unknown populations (Raxworthy et
al. 2004) the location of suitable breeding habitat (Osborne,
Alonso & Bryant 2001), breeding success (Paradis et al. 2000), abundance (Jarvis & Robertson 1999), genetic variability of species (Scribner et al. 2001)

help target field surveys (Engler, Guisan & Rechsteiner 2004), aid in the design of reserves (Li et al.1999), inform wildlife management outside protected areas (Milsom et al.
2000) guide mediatory actions in human–wildlife conflicts (Sitati et al.
2003). monitor declining species (Osborne, Alonso & Bryant 2001), predict range expansions of recovering species (Corsi, Dupre &
Boitani 1999), estimate the likelihood of species’ long-term persistence in areas
considered for protection (Cabeza et al. 2004) identify locations suitable for introduction (Debeljak et al., 2001) identify locations suitable for reintroductions (Glenz et al., 2001). identify sites vulnerable to local extinction (Gates & Donald 2000) identify sites vulnerable to species invasion (Kriticos et al. 2003), explore the potential consequences of climate change (Erasmus et
al. 2002).

Definition: n-dimensional hypervolume described by n environmental and resource constraints within which a species can maintain a viable population.
The combination of conditions and resources required by an individual species defines the area in which it is able to live.
(from Begon, Harper & Townsend 1990)

Fundamental niche never completely occupied due to competitive interactions
Actual occupied niche space that maintains viable population is a subset of the fundamental niche = realised niche

What determines the edge of geographic ranges? There are changes in local population dynamics at the edge
of a distribution, and more net losses than net gainsThese population level changes are brought about by: Changes in abiotic factors (physical barriers, climate
factors, absence of essential resources) and biotic factors (impact of competitors, predators or parasites)
Genetic mechanisms that prevent species from becoming more widespread.
Abiotic/biotic factors are only limiting because a species has not evolved the morphological / physiological / ecological means to overcome them.

Plot of species presence with variation in some environmental variable.
Most models assume a Gaussian response, but in fact it is seldom Gaussian, and may take on a variety of shapes. Especially in complex communities, response curves may exhibit truncated forms due to biotic interactions.
The ability of the chosen model to represent this response curve is critical to model performance.

Source: Guisan and Zimmerman, 2000
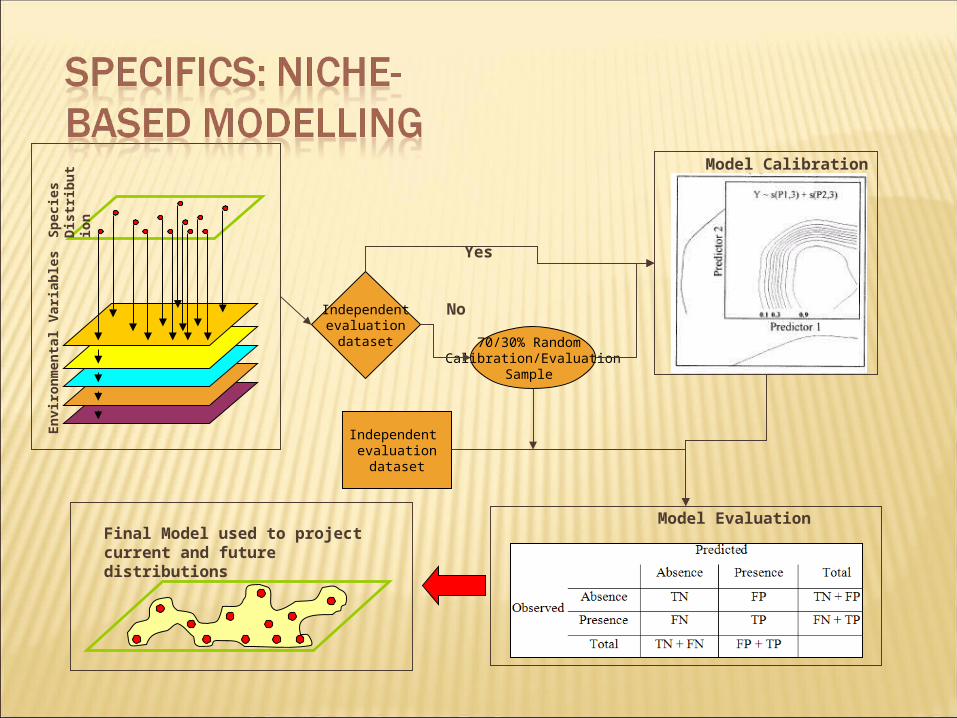
Model Calibration
En
viro
nm
enta
l Var
iab
les
Sp
ecie
s D
istr
ibu
tio
n
Independentevaluation
dataset 70/30% Random Calibration/Evaluation
Sample
Yes
Independent evaluation
dataset
No
Model EvaluationFinal Model used to project current and future distributions

Assumptions:
Environmental factors drive species distribution Species are in equilibrium with their environment Limiting variables – are they really limiting? Coincidence with climate or climate shift Evidence for species dying/not reproducing due to climate Collinearity of variables Assumption of assembly rules: niche assembly vs dispersal
assembly Static vs dynamic approaches: data snapshot or time series
response?

Risk of all models: GIGO- Garbage in, garbage out
Need to understand assumptions, explicit and implicit
Models are an abstraction of reality, meant to improve our understanding of core processes.

Direct IndirectVariables with biological relationship with study species
Variables that correlate with study species because of correlation with series of intermediate direct factors rather than direct relationship
Definition
Climate, nesting sites, soil nutrients (plants), interacting species, site isolation
Elevation, soil, topography, geology, soil nutrients (animals)Example
Model structure easily interpreted in biological meaningful terms.
Direct biological relationship should generalize better to new areas, and be more effective for climate change modeling than indirect predictors.
Provides more info for conservation management
Data sets widely available in GISLow cost, ease of collectionCan be effective predictors, ie elevation in
mountainous areasEncompasses a range of correlated
variables so should: result in parsimonious models if variable selection applied, recording fewer variables
Strength
Variables require greater effort to record
Data sets may need to be estimated for large spatial extents (using indirect variables reducing overall accuracy
Correlation with direct variables tend to be location specific
Limited interpretation – biological meaning inferred, resulting in increased uncertainty
Weakness

Click to enlarge

• Species only select their habitats in the broadest sense (Heglund 2002), and distribution patterns are the cumulative result of a large number of fine scale decisions made to maximize resource acquisition.
• The more accurately these fine-scale resources can be approximated and access quantified, the better the model should perform if all models were equal.
• Predictions at broad scales can use broader environmental variables, often associated with the fundamental niche,
• Finer scale predictions need to concern themselves more with those variables that determine the realized niche.
(Pearson & Dawson 2003)
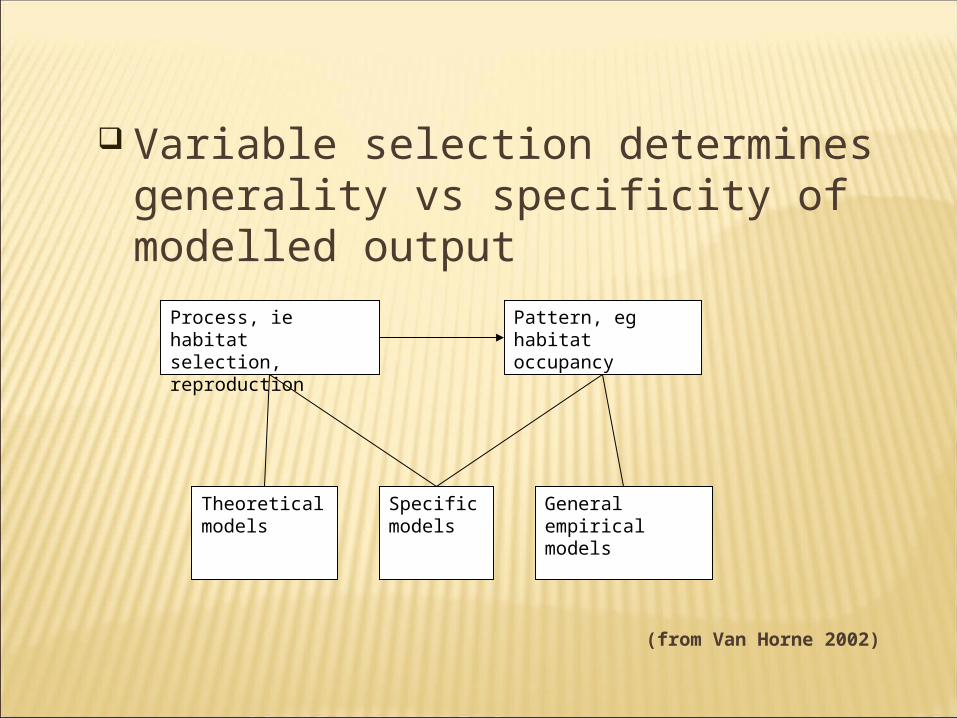
Variable selection determines generality vs specificity of modelled output
Process, ie habitat selection, reproduction
Pattern, eg habitat occupancy
Theoretical models
Specific models
General empirical models
(from Van Horne 2002)

MAP, Psummer, Pwinter MAT, Tmin, Tmax, Tmin06 Soil (pH, texture, organic C, fertility) Avoid indirect measures of a variable
which is a challenge project into the future e.g. slope,
aspect, altitude Difficult variables – Solar radiation,
wind

Growing degree days (e.g. base 5°C)
PET – Thornthwaite, Priestly-Taylor, Linacre
Water Balance – Crudely defined as MAP – PET
Favourable soil moisture days– Modelled using e.g. ACRU, WATBUG
Palmer Drought Stress Index – PDSI Program

Recommendation Potential advantagesUse variables that show direct relationship with organism
Improved predictive ability, especially over large geographical extents or predicting responses to environmental change
Consideration of interacting species Improved predictive ability, greater biological validity (modeling of realized niche), greater explanatory power and ease of interpretation
ID complete geographical region of interest prior to sampling (Thuiller et al 2004)
Improved predictive ability with new data because model does not need to extrapolate beyond conditions under which model was constructed; explanatory conclusions more widely applicable
Environmental stratification, with equal samples between strata
Improved predictive ability, more accurate explanatory analysis
Multiscale approach to sampling Improved predictive ability, greater explanatory understanding, more relevant to cons planning
Aim to sample at least 10 sites for every environmental variable considered
More reliable model development and explanatory analysis, improved predictive ability
Aim to model spatial autocorrelation, where present; test to ensure adequate stats power for autocorrelation analyses in design of sampling scheme (Keitt et al 2002, Dungan et al 2002. More background Legendre 2002, Perry et al 2002)
Facilitated detection, characterization and subsequent modeling of autocorrelation, improved understanding of mechanisms generating distribution pattern, greater predictive accuracy
Collect independent evaluation data; environmental stratification used in process.
Essential to test models, increase scientific rigour and observational analyses. Idea of model generality and predictive ability.

•Museum/Herbarium data e.g. Precis (Sabonet)•Survey Atlas data e.g. Protea Atlas•Expert Atlas e.g. Birds of Africa•Field data e.g. Ackdat or TSP databases•Presence / Absence data•Georeference accuracy e.g. GPS / QDS•Taxonomy affects numbers•Taxonomic updates of older museum data
Fieldwork
Survey Atlas
Expert Atlas
Herbaria Specimens
Museum Specimens
Data sources and their typical scales
Presence/Absence
Presence/Absence
Presence/Absence
Presence
Presence
Locality Type 1-5 degree
0.25- 1 degree
1-15 minutes
1-5km
1-1000m

Using existing data Ad hoc museum data – presence only
(Brotons et al 2004) Atlases – may be presence/absence.
Scaling down of atlas data: not a good idea to attempt without due caution and model validation (Araujo et al 2005)
Flagship/Indicator species: depends on objective of model – ecosystem function vs biodiversity vs change detection
Adaptation response depends on selected flagship species, ie Proteas in CFR

Collecting new data to model Gradsect sampling – maximizing samples
across gradients (Wessels et al 1998) Focussed vs random (Hirzel & Guisan
2002): ‘Regular’ and ‘equal-stratified’ sampling strategies is more accurate and more robust. Improve sample design: (1) increase sample size, (2) prefer systematic to random sampling and (3) include environmental information in the
design


BioClimatic envelope e.g. Bioclim Ordinary Regression e.g. incl. in Arc-SDM Generalised additive models (GAM) e.g.
GRASP Generalised linear models (GLM) e.g. incl.
in Biomod Ordination (e.g. CCA) e.g. ENFA Classification and regression trees (CART)
e.g. incl. in Biomod Genetic Algorithm e.g. GARP Artificial neural networks e.g. SPECIES Bayesian e.g. WinBUGS

What question do you want to answer? Data considerations
What environmental data do you have access to? What is the resolution and extent of this data? Categorical or continuous data?
Scale considerations. (Thuiller et al 2003 – GAMs better at performing consistent across scales because of ability model to complex response curves)
Different variables important at different scales (Pearson& Dawson 2003)
Good example of an informed modeled solution: Gibson et al 2004
Different models compared: summary of such studies in Segurado & Araujo 2005, Thuiller et al 2003.

Click to enlarge.(Guisan and Zimmerman, 2000)

Type of model Potential application1.Empirical behaviour of species presence/absence to environmental variables prioritized (e.g non-parametric models such as GAM, classification trees and neural networks)
Complex distribution patterns, i.e. where occurrences do not respond to environmental variables according to a predefined ‘shape’, ie widespread species
2.Focuses on general trend of presence/absence response (e.g. parametric models such as GLM)
Expected to provide reasonable models for species responding to environmentalgradients as predicted by simple response curves.
3. Use presence-only data to seek relationships with environmental predictor (DOMAIN and ENFA)
Expected to provide models with high sensitivity (low misclassification of true presences) but low overall performance because it ignores the response of absence data to environmental variables.Useful if no reliable species absence data is available.
4. Use presence-only data and their geographic positions to develop predictions (spatial interpolators)
Complex distribution patterns, i.e. where occurrences do not respond to environmental variables according to a predefined ‘shape’, ie widespread species.Expected to provide models with high sensitivity (low misclassification of true presences) ) but low overall performance because it ignores the response of absence data to environmental variables(Segurado & Araujo 2005)

In general, neural networks and GAM (possibly with an autocorrelation coefficient) are the most robust.
Neural networks are black boxes: biological interpretation is hard to do
Two options: Choose an expert system (e.g. BIOMOD) that
compares models automatically, and selects the best one, or choose a model that is generally robust.
Choose a method particularly suited to the questions asked, i.e. ENFA when presence-only data is available.
However, GAM with pseudo-absence may outperform presence-only techniques (Brotons et al 2004).

Click magnifying glass to enlarge table.(from Johnson & Omland 2004, Rushton et al 2004).
Once you have decided on a model type, then you need an methodology to select the best model from a suite of potential models, all with different combinations of the selected environmental variables.
Stepwise selection of variables: order doesn’t matter in GAM, does with GLM

Fre
qu
en
cy
Value classes
IF Tann =[23,29] °C AND Tmin06=[5,12] °C ANDRann=[609,1420] AND Soils=[1,4,5,8]THEN SP=PRESENT
En
vir
on
me
nta
l V
ari
ab
les
Sp
ec
ies
Dis
trib
uti
on

For linear regression there is a dependent variable Y and predictor variables X1 … Xp such that
1j
jjY
Additive models replace the linear function Bj with a smoothed non-linear function fj
1
)(j
jfjY
e BX a p)]-ln[p/(1
Owing to the binomial nature of the dependent variable we need to use the “Logit” family (non-linear transformation)

• Output data = probability values
• Observed data = presence – absence dataHow to compare?
Need a probability threshold to derive a misclassification matrix (MM)
+ - + True
positive (a)
False positive (b)
- False positive (c)
True negative (d)
ActualActual
PredictedPredicted
(Fielding & Bell 1997, Guisan and Zimmerman, 2000)

Based on the MM Take into account chance agreement Estimation of Kappa for a range of threshold and
keep the best Ke = [(TN+FN)x(TN+FP) + (FP+TP)x(FN+TP)]/n² Ko = (TN + TP)/n K = [Ko – Ke] / [1 – Ke] Scales between 0 and 1; >0.7 good, 0.4 – 0.7 fair,
<0.4 poor
(Thuiller 2004, pers comm.)

Sensitivity TP/(FN+TP) (true positive fraction)
Specificity TN/(FP+TN) (true negative fraction)
Plot sensitivity and specificity for a range of thresholds
Calculate Area-under-curve (AUC):
0.8 good, 0.6 – 0.8 fair, 0.5 random, <0.6 poor
0
0.2
0.4
0.6
0.8
1
0.0 0.2 0.4 0.6 0.8 1.0
1 - specificity

Testing and training data sets (30:70) Comparison across models, or across var’s with
same model. Number of explanatory variables. Model development and improvement is iterative
process Delineating the predictive ability of predictor
variables (Lobo et al 2002) Evaluate model output against historical data
(Hilbert et al 2004) Use of modelled data in conservation planning
(Hannah et al; Cabeza at al, 2004; Loiselle et al 2003)