map reduce along with amazon emr
TRANSCRIPT

Map Reduce along with Amazon EMR
Sampath Rachakonda & Siva Krishna BattuBigdata Analytics on Cloud Meetup
14th March 2015
http://www.meetup.com/abctalks

Agenda
http://www.meetup.com/abctalks
Introduction to BigData and Hadoop
MapReduce
Core Hadoop and its Ecosystem
Use Cases
Hadoop Installation on Windows/Ubuntu
Work flow on Map Reduce
M-R on EMR
Real-time examples on EMR
What's Next ? Hadoop 2.0!

Introduction to BigData
http://www.meetup.com/abctalks
It is the latest buzz but on the other hand data is an opportunity


Contd..
http://www.meetup.com/abctalks
Extremely large datasets that are hard to deal with using
relational databases
Storage/Cost
Search/Performance
Analytics and Visualization
Need for parallel processing on hundreds of machines
ETL cannot complete within a reasonable amount of time
Beyond 24 hours never catch up


Solution to handle BigData
http://www.meetup.com/abctalks
Distributed File System
System shall manage and heal itself
Automatically route around failure
Speculatively execute redundant tasks based on
performance
Performance Scale Linearly
Proportional change in capacity with resource change
Compute should move to data
Lower Latency, Lower Bandwidth

Introduction Apache Hadoop
http://www.meetup.com/abctalks
What is Hadoop ?
A scalable fault tolerant grid operating system for data storage and
processing.
Open Source, Apache License
Works with Structured and Unstructured Data
HDFS: Fault-Tolerant high-bandwidth clustered storage
Commodity Hardware
Master (name-node) – Slave Architecture
MapReduce : Distributed Data Processing

Hadoop Cluster
http://www.meetup.com/abctalks
A set of “cheap” commodity hardware
Networked together
Resides in same location in set of
racks in a data centre
No super computers, use commodity
unreliable hardware

Hadoop System Principles
http://www.meetup.com/abctalks
Scale-Out rather than Scale-Up
Bring Code to data rather than Data to Code
Deal with failures - they are common
Abstract complexity of distributed and concurrent applications

RDBMS Vs Hadoop
http://www.meetup.com/abctalks
Before hadoop many applications
used RDBMS for batch processing
like Oracle, MySQL, Sybase, etc..
Hadoop doesn't fully replace RDBMS
the architecture
RDBMS products Scale-up rather
than Scale-Out with limitations of
100s of terabytes
Structured Vs Unstructured
Offline Batch Vs Online Transactions

Hadoop + RDBMS Complements each other
http://www.meetup.com/abctalks
For example a small website with small number of users
generating large amount of audit logs :
WebServer (1)--> RDBMS --> (2)&(4) --> Hadoop(3)
Use RDBMS for rich user interface and enforce data
integrity
RDBMS generates lots of audit logs; the logs are moved
periodically to hadoop cluster
All logs are kept & processed in Hadoop for various
analytics
Results from hadoop cluster are stored back onto RDBMS
to be used by web server. Ex: Suggestions based on audit
history

Hadoop Eco System
http://www.meetup.com/abctalks
Hadoop mainly comprised of two
core components :
HDFS(Hadoop Distributed File
System) to store data & process
data
MapReduce(Distributed data
processing framework)

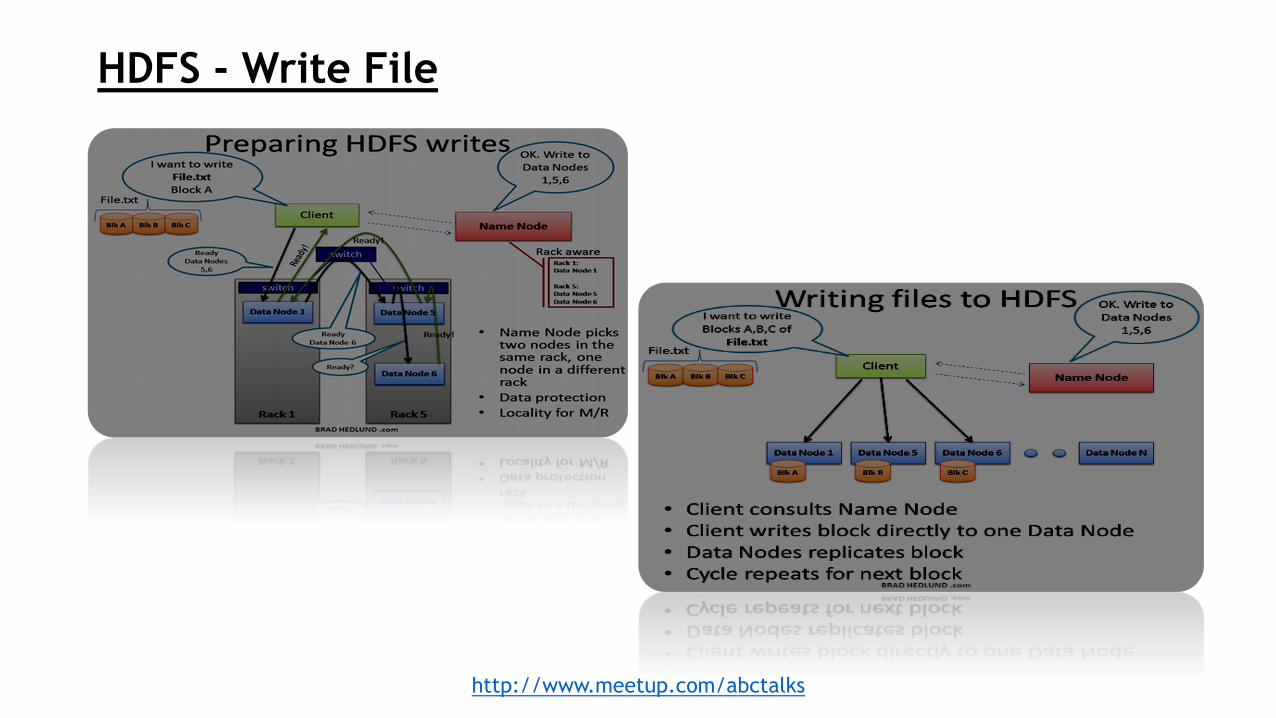
HDFS(Hadoop Distributed File System)
http://www.meetup.com/abctalks
A scalable, fault-tolerant, High Performance distributed file
system
Asynchronous Replication
Write-Once Read Many (WORM)
Hadoop cluster with 3 data nodes minimum
Data divided into 64 MB(default) or 128 MB blocks, each
block replicated 3 times by default
No RAID required for DataNode
Interfaces: Java, Thrift, C Library, FUSE, WebDAV, HTTP, FTP
NameNode holds the file system metadata
Files are broken up and spread over DataNodes

MapReduce(Distributed data processing framework)
http://www.meetup.com/abctalks
Software Framework for distributed Computation
Input | map () | CopySort | Reduce {} | Output
Jobtracker schedules and manages jobs
Tasktracker executes individual map() and reduce() tasks on
each cluster node


MapReduce - Executing File
http://www.meetup.com/abctalks
Client program is copied on each node
JobTracker determines number of splits from input path & then select
some task trackers based on their network proximity to the data sources
Now JobTracker sends task request to the selected TaskTrackers
Each TaskTracker starts the map phase processing by extracting the
input data from the splits
Once Map task completes, TaskTracker notifies the JobTracker.
When all TaskTrackers complete mapper phase, TaskTracker will notify
the selected TaskTrackers for reducer phase.
Each TaskTracker reads region files remotely & invokes the reverse
function, which collects the key/aggregated value into the output file
(one per reducer node).
After both mapper & reducer phases are completed, the JobTracker
unblocks the client program.

Java MapReduce Example
http://www.meetup.com/abctalks
Let us go with the basic word count example which helps us
to understand the workflow easily
Let us now dive into the demo of word count and understand
how does mapper, reducer functions and more..

Introduction to Amazon AWS & EMR
http://www.meetup.com/abctalks
AWS is an cloud infrastructure which
provides
Elastic Capacity
Quick and Easy Deployment
No CapEx, No initial investment
Pay as you go, for what you use
Automation & Reusable components

Amazon EMR : Hadoop in Cloud
http://www.meetup.com/abctalks
Scalable and fault tolerant
Flexibility for multiple languages
and data formats
Open Source
Ecosystem of tools
Batch and real-time analytics
Amazon EMR is the easiest way to
run hadoop in the cloud
Now let us look at the same example
we did on single node cluster on EMR
and look at the feasibility of doing it

Thank You !!
http://www.meetup.com/abctalks
https://www.facebook.com/abctalks