managing energy and server resources in hosting centers chase, anderson, thakar, vahdat, doyle, sosp...
TRANSCRIPT

Managing Energy and Server Resources in Hosting Centers
Chase, Anderson, Thakar, Vahdat, Doyle,
SOSP 2001

1. Introduction
• “Pre-virtualization” paper
• “Shared hosting centers” = clouds
• Proposes policy for resource allocation, which is “energy conscious”
• “Muse”: operating system for a hosting center
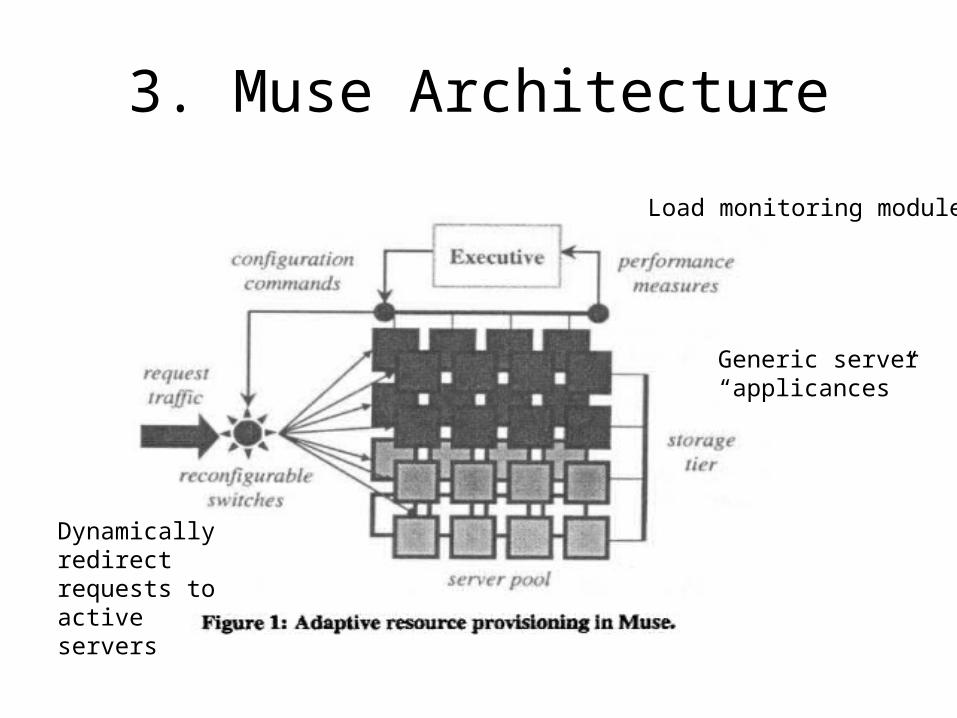
3. Muse Architecture
Generic server “applicances”
Load monitoring modules
Dynamically redirect requests to active servers

3.1 Services and Servers
• Request can be handled by several servers
• Servers are “stateless” – Shared network storage
• “Resource containers” framework used to allocate share of resources
*Paper does not talk about migration of applicationsMy guess: all services are “running” on all servers – they maybe used or not used

3.2 Redirecting switches
• Reconfigurable server switches – “a mechanism to support resource assignments planned by the
executive. Muse switches maintain an active set of servers selected to serve requests for each network-addressable service. The switches are dynamically reconfigurable to change the active set for each service. Since servers may be shared, the active sets of different services may overlap. “
– Details not clear in the paper• My guess: since there is no migration, the only way to
change the number of servers (physical machines) involved in serving requests, is by changing the active set of a request director – this impicitly changes the number of servers ready to handle requests. Some servers will become idle, and power saving mechanisms will “kick-in”

3.3 Adaptive Resource Provisioning
• Executive accepts load information, determines resource allocation and directs servers and switches to change accordingly– Details of which resource is taken from which
server not clear from the paper.

3.4 Energy-conscious provisioning
• “Energy-conscious provisioning configures switches to concentrate request load on a minimal active set of servers for the current aggregate load level. Active servers always run near a configured utilization threshold, while the excess servers transition to low-power idle states to reduce the energy cost of maintaining surplus capacity during periods of light load. “

3.4 Energy-conscious provisioning
• Section argues about benefit of shutting down vs micro-power management – Servers not power-efficient at low utilizations due to need of
power supply to keep charging
One more server powering on
Request throughput same, but power draw higher

3.4…Energy conscious provisioning
• Interesting table!
Need to study how this behaviour is in modern processorsRelates to Suparna’s discussion on “energy proportionality”

Resource economy
• Mu_max – total number of resources available at time (t)– Cost (t) – cost per resource– Mu_max may also change
• Utility function U_i(t, mu_i) – revenue from of mu_i resources given to service I to at time t– Base on “delivered performance” (e.g. throughput)
• Cost and utility are in $’s

…Bids
• Bid_i (lambda_i) – per unit time dollar amount customer wants to pay – lambda_i = throughput received by service i
• Lambda_i depends on time and mu_i (allocated resource)– Bid_i( lambda_i(t, mu_i) )
• May allocate more resources, because it will improve throughput– But only upto a point, no use after that.

and penalties
• Center may allocate unneeded resources to another service, especially if no throughput improvement by allocating more– It will still collect the bid money, esp if it is
fixed penalty needed

…penalties
• Define max target utilization rho_target• If rho_i (fraction) of mu_i is being used
– If mu_i < r_i (which is the fixed amount customer i is paying for) and rho_i > rho_target
• Customer is underprovisioned (delays etc will be longer). Note: if mu_i is less, rho_i will be more
• Penalty can be r_i/mu_i (degree of short fall, e.g. 1.5, 2, etc)
• Center will have to trade off penalty vs revenue due to overbooking

MSRP resource allocation
• Maximize Service Revenue and Profit• Divided into epochs
– Intervals, or some change in state
• At each epoch– Determine mu_i for N services (i) so that profit
is maximized• Sum_i (U_i(t,mu_i) – mu_i*cost(t))• U_i(t,mu_i) = bid_i(lambda_i(t,mu_i)) –
penalty_i(t,mu_i)• Constraint: sum mu_i <= mu_max

…MSRP
• Assumptions: U_i is concave– Price_i (mu_i) = U_i(t, mu_i+1) - U_i(t, mu_i)
• Incremental price for one additional resource
– It’s like a partial derivative or gradient• Should be positive and monotonically
nonincreasing• Shows that utility of additional resources decrease
as amount of allocated resources increase

…MSRP
• Grow (i,target), shrink(i, target)– Reduce allocations until price(mu_i) = target
• Algorithm phases1. If price_i(mu_i) <= cost(t)
1. shrink(i,cost(t))– Incremental unit price can’t be more than unit
cost, shrink until it is equal (which means price being paid for allocated resources is more than cost)

…MSRP
• Algorithm phases– If mu (sum of allocated resources) < mu_max, idle
resources are there.• Grow(i,price_j(mu_j)) – i is highest price_i(mu_i), j is next
highest. Repeat until mu=mu_max or price_i(mu_i) < cost (t) for highest bidder i.– (better to let resource idle than allocate)
– If mu > mu_max (opposite of above)– Now mu <=mu_max
• If price_i(mu_i) < price_j(mu_j) shift resources until equal
• At equilibrium price_i(mu_i) is equivalent for all i.

Estimating performance effects
• In MSRP algo, “price” defined in terms of U_i, which is defined in terms of bid_i which is a function of lambda_i, which is a function of u_i!– Need to calculate lambda as a fn of u_i, so
that price_i can be compute.

Estimating lambda
• Current values measured:– Lambda_i, rho_i, mu_i (is known)
• If rho_i < rho_target– Changing mu_i will not affect lambda_i (?)– So lambda_i is same– Can reclaim of mu_i*(rho_target- rho_i)
• If rho_i > rho_target – Assume tput will increase linearly with mean per-
request service demand (rho_i mu_i/lambda_i)• (My guess) : Lambda_i(mu_i, t+1) = lambda_i(mu_i,t)
mu_i(t+1)/mu_i(t)

4.4 Feedback and Stability
• Smoothing of performance measures• Flop-flip: “holds a stable estimate E(t) = E(t-1) until that estimate
falls outside some tolerance of a moving average of recent observations, then it switches the estimate to the current value of the moving average.”

4.5 Pricing
• Limitation: customers do not change bids

4.6 Multiple resources
• Focus only on bottleneck resource – resolve that, then move on to next bottlenexk…

5. Prototype
• 5.1: Monitoring and Estimation– Considers only CPU – Measures TCP queue length (q_i)– And FIN-ACK rate (lambda_i)
• If rho_i < rho_target (i.e. CPU allocation is enough) but q_i is greater than a threshold– Assume I/O is the bottleneck– Reduce rho_target for that service, so that more of
the CPU will get allocated to that, so that it will get larger share of the node, and I/O contention will also drop

5.2: Executive
• Determines allocation etc commands• “actuator”: Separate program that passes commands to
servers/switches• “The actuator uses Advanced Power Management
(APM) tools for Intel-based systems to retire excess servers by remotely transitioning them to a low power state. The current prototype recruits and retires servers by rank; we have not investigated policies to select target servers to spread thermal load or evenly distribute the start/stop cycles.”
• Algorithm is O(N + mu*N)

5.3 Request Redirector
• Intercepts TCP packets, redirects them
• Active set membership is controlled by executive and actuator
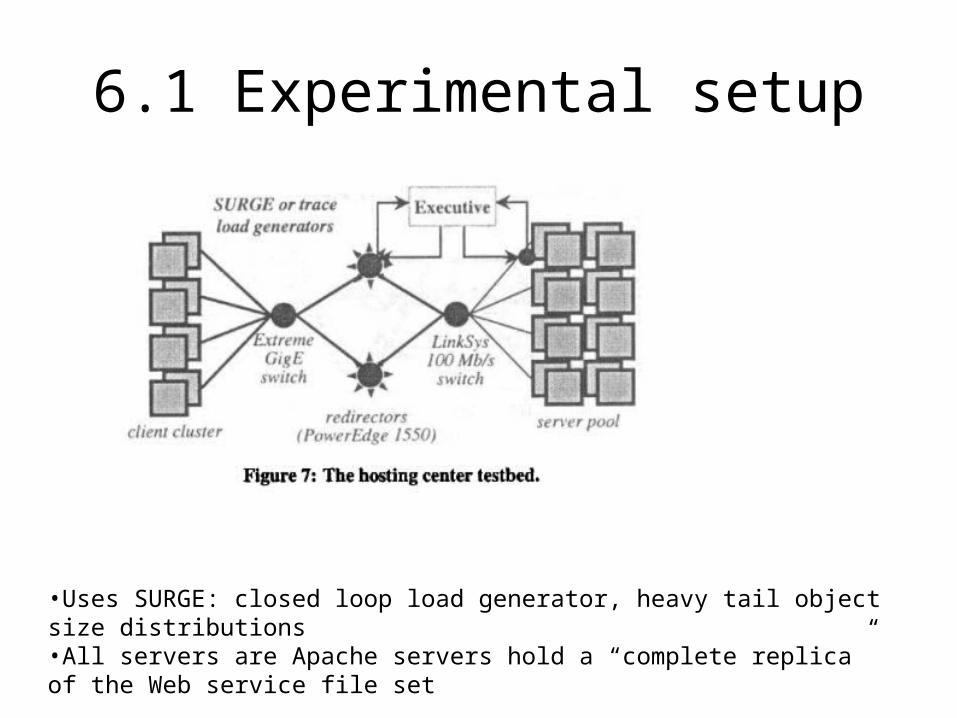
6.1 Experimental setup
•Uses SURGE: closed loop load generator, heavy tail object size distributions•All servers are Apache servers hold a “complete replica” of the Web service file set

6.2 Allocation Under Constraint
S1 bids higher

6.2 Allocation Under Constraint
S0 bids higher

6.3 Browndown
S0 bids high
Server failsS1 allotment goes down
“However, shortly after the failure, at t = 170, the request load for sl exceeds sO. Although sO bids higher per request, the executive shifts resources away from sO because the same resources will satisfy more hits for the badly saturated sl, earning higher overall utility. “

6.4 Varying Load and Power

6.4 Varying Load and Power