"machine translation 101" and the challenge of patents
TRANSCRIPT

“Machine Translation 101” And The Challenge of Patents
John TinsleyDirector / Co-Founder
EPOPIC. 5th Nov 2014, Warsaw

The need for translation
50% of all PCT applications in 2013 came from Asia

BSc in Computational Linguistics PhD in Machine Translation Language Technology consultant Founder of Iconic Translation Machines
Why listen to me?
Machine Translation is what I do!
The world’s first and only patent specific machine translation system

§ The use of computers to translate from one language into another § The use of computers to automate some, or all, of the translation
process
§ An approach to Machine Translation, where translations for an input are
estimated based on previous seen translation examples and associated (inferred) probabilities.
§ e.g. IPTranslator, Google Translate
§ Rule-based (or transfer-based): based on linguistic rules
• e.g. Systran; Altavista’s Babelfish
§ Example-based: based on translation examples and inferred linguistic patterns
Machine Translation: The Basics Machine Translation = automatic translation
Statistical Machine Translation (SMT)
Other approaches
SMT is now by far the predominant approach

A corpus (pl. corpora) is a collection of texts, in electronic format, in a single language § document(s) § book(s)
Bilingual Corpora
a bilingual corpus
Note source language = original language or language we’re translating from target language = language we’re translating into
A bilingual corpus is a collection of corresponding texts, in multiple languages § a document & its translation § a book in multiple languages § European Parliament proceedings

Aligned Bilingual Corpora A document-aligned bilingual corpus corresponds on a document level For translation, we required sentence-aligned bilingual corpora
§ The sentence on line 1 in the source language text corresponds to (i.e. is a translation of) the sentence on line 1 in the target language text etc.
§ Often referred to as parallel aligned corpora
Sentence aligned bilingual parallel corpora are essential for statistical machine translation

Learning from Previous Translations Suppose we already know (from a sentence-aligned bilingual corpus) that:
§ “dog” is translated as “perro” § “I have a cat” is translated as
“Tengo un gato”
We can theoretically translate: § “I have a dog” à “Tengo un perro” § Even though we have never seen “I
have a dog” before
Statistical machine translation induces information about unseen input, based on previously known translations:
§ Primarily co-occurrence statistics § Takes contextual information into account

Statistical Machine Translation
§ Example of a small sentence-aligned bilingual corpus for English-French

Statistical Machine Translation
§ We take some new sentence to translate

Statistical Machine Translation
§ From the corpus we can infer possible target (French) translations for various source (English) words
§ We can then select the most probable translations based on simple frequencies (co-occurrence statistics)

Statistical Machine Translation
Given a previously unseen input sentence, and our collated statistics, we can estimate translation

Advanced MT All modern approaches are based on building translations for complete
sentences by putting together smaller pieces of translation Previous example is very simplistic
§ In reality SMT systems calculate much more complex statistical models over millions of sentence pairs for a pair of languages
§ Upwards of 2M sentence pairs on average for large-scale systems
§ Word-to-word translation probabilities § Phrase-to-phrase translation probabilities § Word order probabilities § Linguistic information (are the words nouns, verbs?) § Fluency of the final output
Previous example is very simplistic
Other statistics calculated include

Data is Key For SMT data is key
§ Information (word/phrase correspondences and associated statistics) is only based on what we have seen before in the data
Important that data used to train SMT systems is: § Of sufficient size
§ avoid sparseness/skewed statistics
§ Representative and relevant § contains the right type of language
§ High-quality § absence of misspellings, incorrect alignments etc. § Proofed by human translators
training data

Why is MT Difficult? A word or a phrase can have more than one meaning (ambiguity – lexical or structural)
§ e.g. “bank”, “dive”, “I saw the man with the telescope”
People use language creatively § New words are cropping up all the time
Linguistic differences between languages § e.g. structure of Irish sentences vs. structure of English sentences: § “Tá (Is) ocras (hunger) orm (on me)” <-> “I am hungry”
There can be more than one way to express the same meaning. § “New York”, “The Big Apple”, “NYC”

Why is MT Difficult?
§ Israeli officials are responsible for airport security. § Israel is in charge of the security at this airport. § The security work for this airport is the responsibility of the Israel government. § Israeli side was in charge of the security of this airport. § Israel is responsible for the airport’s security. § Israel is responsible for safety work at this airport. § Israel presides over the security of the airport. § Israel took charge of the airport security. § The safety of this airport is taken charge of by Israel.
§ This airport’s security is the responsibility of the Israeli security officials.
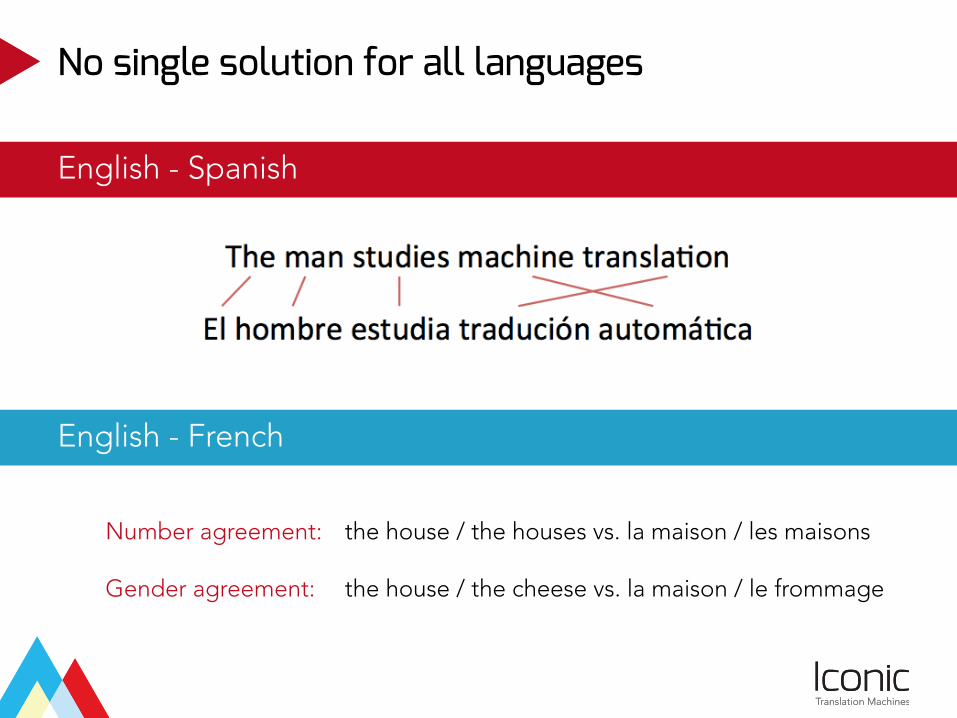
No single solution for all languages
Number agreement: the house / the houses vs. la maison / les maisons
Gender agreement: the house / the cheese vs. la maison / le frommage
English - Spanish
English - French

No single solution for all languages
English - German
English - Chinese
种水果的农民
The farmer who grows fruit[Lit: “grow fruit (particle) farmer”]

The Challenge of Patents
L is an organic group selected from -CH2-(OCH2CH2)n-, -CO-NR'-, with R'=H or C1-C4 alkyl group; n=0-8; Y=F, CF3 …
maximum stress of 1.2 to 3.5 N/mm<2> and a maximum elongation of 700 to 1,300% at 0[deg.] C.
Long Sentences
Technical constructions
Largest single document: 249,322 words
Longest Sentence: 1,417 words

The Challenge of Patents
Very long sentences as standard Gramma1cally incomplete using nominal and telegraphic style (!) Passive forms are frequent Frequent use of subordinate clauses, par1ciples, implicit constructs Inconsistent and incorrect spelling High use of neologisms Instances of synonymy and polysemy Spurious use of punctua1on
Authoring guide for “to be translated” text
Patents break almost all of the rules!

Judge the quality of an MT system by comparing its output against a human-produced “reference” translation § Pros: Quick, cheap, consistent § Cons: Inflexible, cannot be used on ‘new’ input
§ Pros: Reliable, flexible, multi-faceted (fluency, error analyses,
benchmarking) § Cons: Slow, expensive, subjective
§ Fluency vs. Adequacy
Evaluating Machine Translation Quality
Automatic Evaluation
Human Evaluation
Task-Based Evaluation

Evaluating Machine Translation Quality Task Based Evaluation § Standalone evaluation of MT systems is necessary to get a sense of the
overall quality of a system § To determine the ultimate usability of an MT system, intrinsic task-based
evaluation is required § Why? Fluency vs. Adequacy
Fluency how fluent and grammatically correct the translation output is
Adequacy how accurately the translation conveys the meaning of the source
Output 1 The big blue house Output 2 The big house red Source La gran casa roja
Task-Based Evaluation

Practical uses of Machine Translation
Understand its limitations and you’ll understand its capabilities!
No
§ Translate a patent for filing
§ Translate literature for publication
§ Translate marketing materials
§ Anything mission critical without review
Yes
§ Productivity tool for professional translation
§ Understand foreign patents
§ Localisation processes and “controlled’ content
§ High volume, e.g. eDiscovery

We provide Machine Translation solutions with Subject Matter Expertise

We do this using Linguistic Engineering

An “ensemble” MT architecture
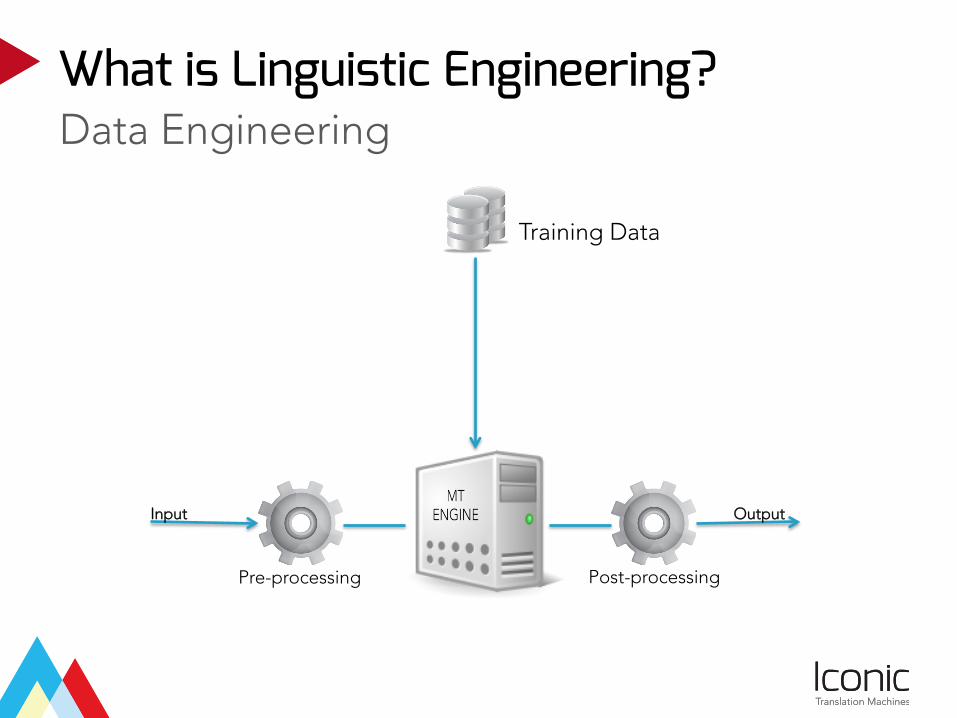
Data EngineeringWhat is Linguistic Engineering?
Pre-processing Post-processing
Input Output
Training Data

Data Engineering + Linguistic EngineeringAn “ensemble” architecture
Chinese pre-ordering rules
StatisticalPost-editing
Input
Output
Training Data
Spanish med-deviceentity recognizer Multi-output
Combination
Korean pharmatokenizer
Patent inputclassifier
Client TM/terminology (optional)
Japanese scriptnormalisation
GermanCompounding rules
Moses
RBMT
Moses
Moses

What is the value for users?
Specialist solutions deliver more useable outcomes for the user
Post-editing
For information purposes
Multilingual search
Increased productivity
Extract more meaning
Retrieve more relevant results
=
=
=

How this impacts translation quality
0
5
10
15
20
25
30
35
40
45
50
Iconic
Systran
Portuguese to English
