lucene and solr document classification
TRANSCRIPT

Lucene And Solr Document Classification
Alessandro Benedetti, Software Engineer, Sease Ltd.

Alessandro Benedetti
● Search Consultant● R&D Software Engineer● Master in Computer Science● Apache Lucene/Solr Enthusiast● Semantic, NLP, Machine Learning Technologies passionate● Beach Volleyball Player & Snowboarder
Who I am

● Classification● Lucene Approach● Solr Integration● Demo● Extensions● Future Work
Agenda

“Classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known. “ Wikipedia
Classification

● E-mail spam filter● Document categorization● Sexually explicit content detection● Medical diagnosis● E-commerce● Language identification
Real World Use Cases
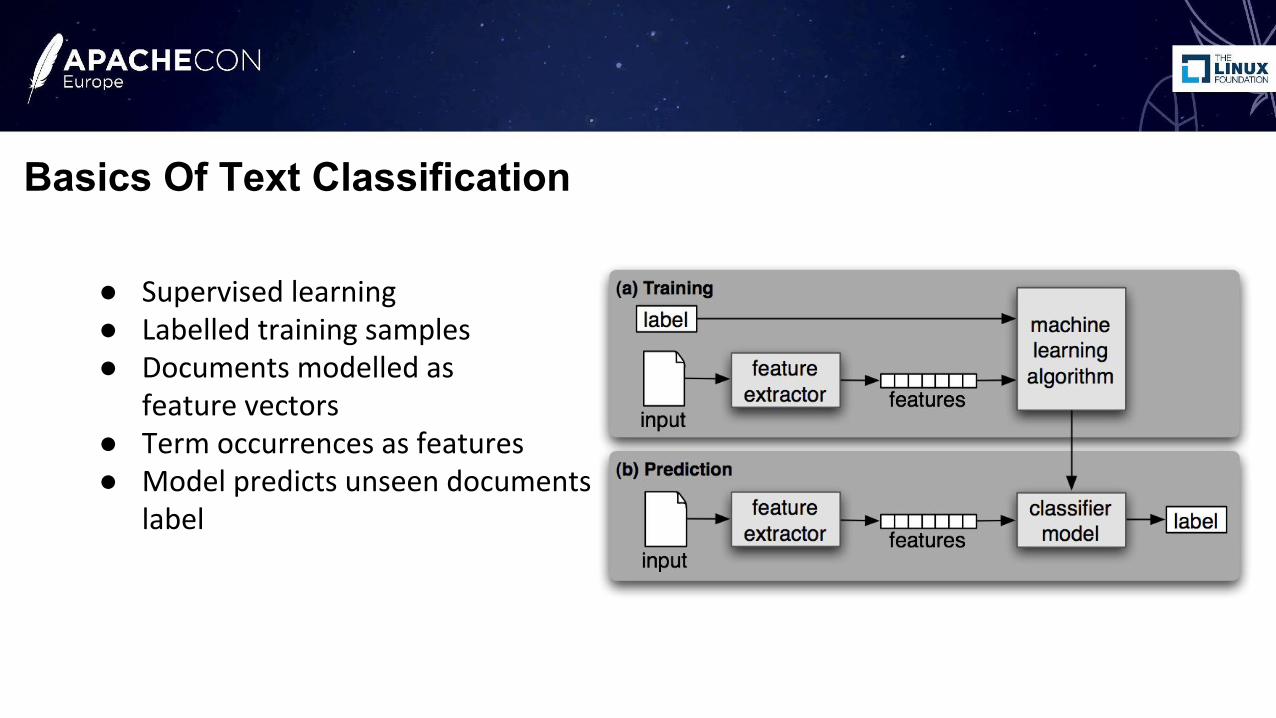
● Supervised learning● Labelled training samples● Documents modelled as
feature vectors● Term occurrences as features● Model predicts unseen documents
label
Basics Of Text Classification

Apache Lucene
Apache LuceneTM is a high-performance, full-featured text search engine library written entirely in Java.
It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
Apache Lucene is an open source project available for free download.

● Lucene index has complex data structures● Lot of organizations have already indexes in place● Pre existent data can be used to classify● No need to train a model from a separate training set● From training set to Inverted index
Apache Lucene For Classification

● Advanced configurable text analysis● Term frequencies● Term positions● Document frequencies● Norms● Part of speech tags and custom payload
Apache Lucene For Classification

● Given an index with labelled documents● Each document has a class field
● Given an unknown document in input● Given a set of relevant fields
● Search the top K most similar documents● Fetch the classes from the retrieved documents● Return most occurring class(es)● Class ranking in retrieved documents is important !
K Nearest Neighbours

● KNN uses Lucene More Like This● Lucene query component● Extract interesting terms* from the input document fields● Build a Lucene query● Run the query against the search index● Resulting documents are “the similar documents”
* an interesting term is a term :- occurring frequently in the seed document (high term frequency)- but quite rare in the corpus (high inverted document frequency)
More Like This

Assumptions● Term occurrences are probabilistic independent features● Terms positions are irrelevant ( bag of words )
Calculate the probability score of each available class C● Prior ( #DocsInClassC / #Docs )● Likelihood ( P(d|c) = P(t1, t2,..., tn|c) == P(t1|c) * P(t2|c) * … * P(tn|c))
Where given term t P(t|c) = TF(t) in documents of class c +1 / #terms in all documents of class c + #docs of class c
Assign top scoring class
Naive Bayes Classifier

● Documents are the Lucene unit of information● Documents are a map field -> value● Each field may be analysed differently
(different tokenization and token filtering)● Each field may have a different weight for the classification
(affecting differently the similarity score)
Document Classification

Solr is the popular, blazing fast, open source NoSQL search platform from the Apache Lucene project.
Its major features include powerful full-text search, hit highlighting, faceted search and analytics, rich document parsing, geospatial search, extensive REST APIs as well as parallel SQL.
Apache Solr

Index Time Integration - SOLR-7739● Ingest the document● Assign the class ● Set the class as a field value● Index the document
Request Handler Integration (TO DO) - SOLR-7738Return an assigned class :● Given a text and a field● Given an input document● Given an indexed document id
Solr Integration

● Pipeline of processors● Each single document flows
through the chain● Each processor is executed once● Last processor triggers the
update command
Update Request Processor Chain

● Update Component● Configurable Singleton Factory● Single instance per request thread● Process a single Document● SolrCloud compatible*
* Pre processor / Post processor
Update Request Processor

● Access the Index Reader● A Lucene Document Classifier is instantiated ● A class is assigned by the classifier ● A new field is added to the original Document, with the class● The document goes through the next processing steps
Classification Update Request Processor

...<initParams path="/update/**,/query,/select,/tvrh,/elevate,/spell,/browse"> <lst name="defaults"> <str name="df">text</str> <str name="update.chain">classification</str> </lst> </initParams>...
Solrconfig.xml - Update Handler

...<updateRequestProcessorChain name="classification"> <processor class="solr.ClassificationUpdateProcessorFactory"> ... </processor> <processor class="solr.RunUpdateProcessorFactory"/> </updateRequestProcessorChain>...
Solrconfig.xml - Chain configuration

<processor class="solr.ClassificationUpdateProcessorFactory"> <str name="inputFields">title^1.5,content,author</str> <str name="classField">cat</str> <str name="algorithm">knn</str> <str name="knn.k">20</str> <str name="knn.minTf">1</str> <str name="knn.minDf">5</str> </processor>
N.B. classField must be stored
Solrconfig.xml - K nearest neighbour classifier config

<processor class="solr.ClassificationUpdateProcessorFactory"> <str name="inputFields">title^1.5,content,author</str> <str name="classField">cat</str> <str name="algorithm">bayes</str> </processor>
N.B. classField must be Indexed (take care of analysis)
Solrconfig.xml - Naive Bayes classifier config

● Lucene >= 6.0● Solr >= 6.1
● Classification needs a training set ->An index with initially human assigned classes is required
Solr Classification - Important Notes

● Sci-Fi StackExchange dataset● Roughly 18.000 questions and answers● Roughly 6.000 tagged● 70 % Training Set + 30% test set
Solr Classification - Demo

● Index the training set documents(this is our ground truth)
● Index the test set (classification will happen automatically at indexing time)
● Evaluate the test set(a simple java app to verify that the automatically assigned classesare consistent with what expected)
Solr Classification - Demo

● True Positive : Predicted class == actual class● False Positive : Predicted class != actual class● True Negative : Not predicted class != actual class● False Negative : Not predicted class == actual class
Precision = TP / TP+FPRecall = TP / TP+FN
Solr Classification - System Evaluation Metrics

● Index the training set documents(this is our ground truth)
● Index the test set (classification will happen automatically at indexing time)
● Evaluate the test set(a simple java app to verify that the automatically assigned classesare consistent with what expected)
Solr Classification - Demo

MaxOutputClasses 1[System Global Accuracy]0.5095676824946846[System Globel Recall]0.2686846038863976TP{star-wars}59FP{star-wars}75FN{star-wars}7[Precision (of predicted)]{star-wars}0.44029850746268656[Recall for class)]{star-wars}0.8939393939393939TP{harry-potter}147FP{harry-potter}137FN{harry-potter}3[Precision (of predicted)]{harry-potter}0.5176056338028169[Recall for class]{harry-potter}0.98
Solr Classification - Demo - Full Dataset

MaxOutputClasses 5[System Global Accuracy]0.20481927710843373[System Globel Recall]0.5399850523168909TP{star-wars}66FP{star-wars}400FN{star-wars}0[Precision (of predicted)]{star-wars}0.14163090128755365[Recall for class)]{star-wars}1.0TP{harry-potter}150FP{harry-potter}584FN{harry-potter}0[Precision (of predicted)]{harry-potter}0.20435967302452315[Recall for class]{harry-potter}1.0
Solr Classification - Demo - Full Dataset

MaxOutputClasses 1[System Global Accuracy]0.9907407407407407[System Globel Recall]0.6750788643533123TP{star-wars}64FP{star-wars}0FN{star-wars}2[Precision (of predicted)]{star-wars}1.0[Recall for class)]{star-wars}0.9696969696969697TP{harry-potter}150FP{harry-potter}2FN{harry-potter}0[Precision (of predicted)]{harry-potter}0.9868421052631579[Recall for class]{harry-potter}1.0
Solr Classification - Demo - Partial Dataset

MaxOutputClasses 5[System Global Accuracy]0.24259259259259258[System Globel Recall]0.8264984227129337TP{star-wars}66FP{star-wars}52FN{star-wars}0[Precision (of predicted)]{star-wars}0.559322033898305[Recall for class)]{star-wars}1.0TP{harry-potter}150FP{harry-potter}48FN{harry-potter}0[Precision (of predicted)]{harry-potter}0.7575757575757576[Recall for class]{harry-potter}1.0
Solr Classification - Demo - Partial Dataset

Multi classes support● Class field may be multi valued ● Assign multiple classes● Not only the top scoring but top N (parameter)
Split human/auto assigned classes● classTrainingField● classOutputField
Default : use the same field
Solr Classification - Extensions SOLR-8871

Classification Context Filtering
● Reduce the document space to consider ->reduce the training set
● Useful when only a subset of the index may be interesting for classification
● Consider only the human labelled documents as training data
Solr Classification - Extensions SOLR-8871

Individual Field Weighting
● When classifying, each field has a different importancee.g.title vs content
● Set a different boost per field● Knn compatible● Bayes compatible
Solr Classification - Extensions SOLR-8871

● Numeric Field Support (Knn) (Euclidean distance based)● Lat lon support (Knn)
(geo distance based)● SolrCloud support
(use the entire sharded index as training set)
Solr Classification - Future Work

Questions ?

● Special thanks to Tommaso Teofili,Apache committer who followed the developments and made possible the contributions.
● And to theAudience :)