live demo: introducing the spark connector for mongodb
TRANSCRIPT

MongoDB Europe 2016Old Billingsgate, London
15th November
Distributed Ledgers, Blockchain + MongoDBBryan Reinero

MongoDB Connector For Spark


HDFS
Distributed Data

Spark Stand Alone
YARN
Mesos
HDFS
Distributed Resources

YARN
Spark
Mesos
HDFS
Spark Stand Alone
Hadoop
Distributed Processing

YARN
SparkMesos
Hive
Pig
HDFS
Hadoop
Spark Stand Alone
Domain Specific Languages

YARN
SparkMesos
Hive
Pig
SparkSQL
Spark Shell
SparkStreaming
HDFS
Spark Stand Alone
Hadoop
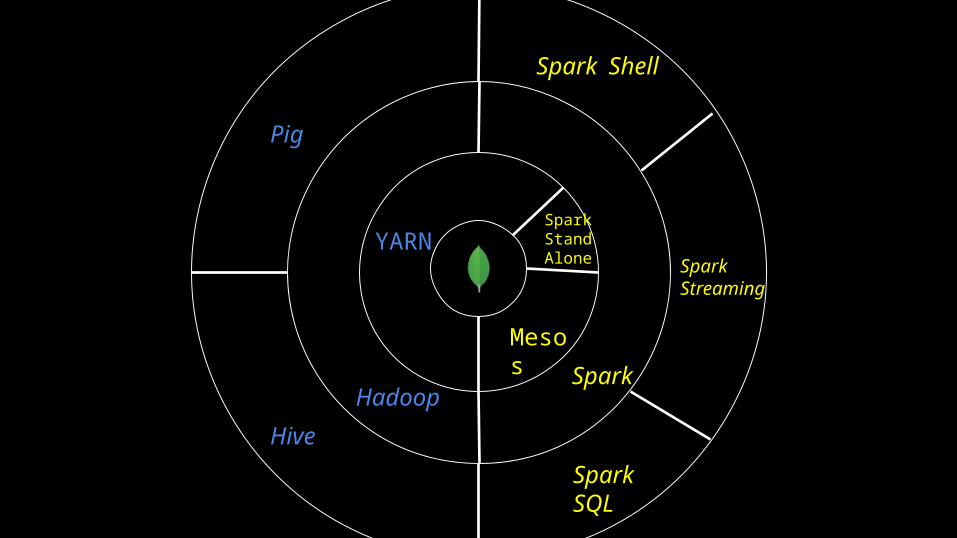
YARN
SparkMesos
Hive
Pig
SparkSQL
Spark Shell
SparkStreaming
Spark Stand Alone
Hadoop

Stand AloneYARN
SparkMesos
SparkSQL
SparkShell
SparkStreaming

Stand Alone
YARN
SparkMesos
SparkSQL
SparkShell
SparkStreaming

executor
Worker Node
executor
Worker Node
MasterSpark Connector
Driver Application
ParellelizeParellelizeParellelizeParellelize

ParellelizeParellelizeParellelizeParellelize
TransformTransformTransformTransform

Transformationsfilter( func )union( func )intersection( set )distinct( n )map( function )

ParellelizeParellelizeParellelizeParellelize
TransformTransformTransformTransform
TransformTransformTransformTransform

ParellelizeParellelizeParellelizeParellelize
Transform
TransformTransformTransform
Transform
Transform
Transform
Transform
Action
Action
Action
Action

Actionscollect()count()first()take( n )reduce( function )

ParellelizeParellelizeParellelizeParellelize
TransformTransformTransformTransform
TransformTransformTransformTransform
Action
Action
Action
Action
Result
Result
Result
Result

ParellelizeParellelizeParellelizeParellelize
TransformTransformTransformTransform
TransformTransformTransformTransform
Action
Action
Action
Action
Result
Result
Result
Result
Lineage

ParellelizeParellelizeParellelizeParellelize
TransformTransformTransformTransform
TransformTransformTransformTransform
Action
Action
Action
Action

ParellelizeParellelizeParellelizeParellelize
TransformTransformTransformTransform
TransformTransformTransformTransform
Action
Action
Action
Action

Parellelize
Parellelize
Parellelize
Parellelize
Transform
Transform
Transform
Transform
Transform
Transform
Transform
Transform
Action
Action
Action
Action
Result
Result
Result
Result

Using the Connector

https://github.com/mongodb/mongo-spark

http://spark.apache.org/docs/latest/



{ "_id" : ObjectId("578be1fe1fe699f2deb80807"), "user_id" : 196, "movie_id" : 242, "rating" : 3, "timestamp" : 881250949}

./bin/spark-shell \ --conf \
"spark.mongodb.input.uri=mongodb://127.0.0.1/movies.movie_ratings" \ --conf \
"spark.mongodb.output.uri=mongodb://127.0.0.1/movies.user_recommendations" \ --packages org.mongodb.spark:mongo-spark-connector_2.10:1.0.0

./bin/spark-shell \ --conf \
"spark.mongodb.input.uri=mongodb://127.0.0.1/movies.movie_ratings" \ --conf \
"spark.mongodb.output.uri=mongodb://127.0.0.1/movies.user_recommendations" \ --packages org.mongodb.spark:mongo-spark-connector_2.10:1.0.0

./bin/spark-shell \ --conf \
"spark.mongodb.input.uri=mongodb://127.0.0.1/movies.movie_ratings" \ --conf \
"spark.mongodb.output.uri=mongodb://127.0.0.1/movies.user_recommendations" \ --packages org.mongodb.spark:mongo-spark-connector_2.10:1.0.0

./bin/spark-shell \ --conf \
"spark.mongodb.input.uri=mongodb://127.0.0.1/movies.movie_ratings" \ --conf \
"spark.mongodb.output.uri=mongodb://127.0.0.1/movies.user_recommendations" \ --packages org.mongodb.spark:mongo-spark-connector_2.10:1.0.0

import com.mongodb.spark._import com.mongodb.spark.rdd.MongoRDDimport org.bson.Document
val rdd = sc.loadFromMongoDB()for( doc <- rdd.take( 10 ) ) println( doc )

Read Config Write Config

Aggregation Filters$match | $project | $group

JSONJSONJSONJSONJSONJSONJSONJSONJSONJSONJSON
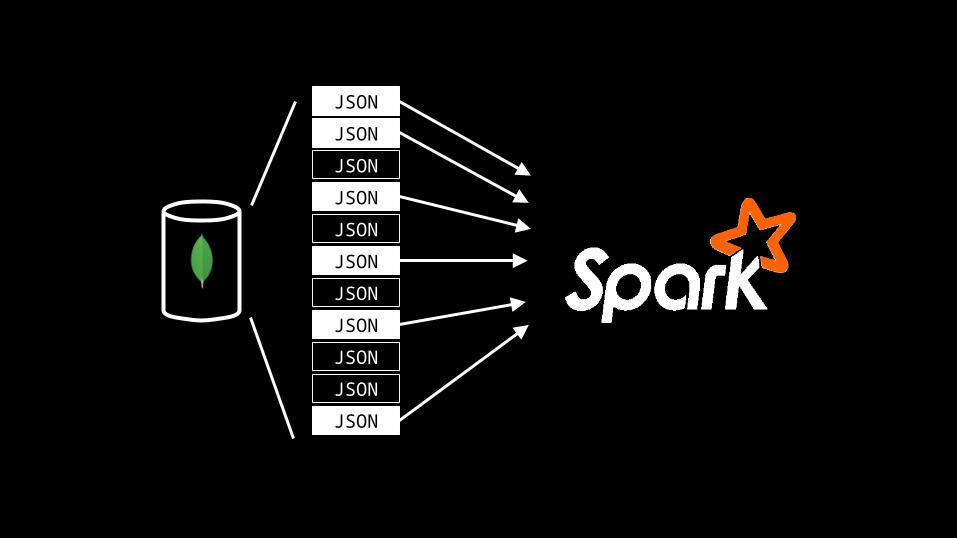
JSONJSONJSONJSONJSONJSONJSONJSONJSONJSONJSON

val aggRdd = rdd.withPipeline( Seq( Document.parse( "{ $match: { Country: \"USA\" } }" ) ) )

Spark SQL + Dataframes

RDD + Schema = Dataframe


JSONJSONJSONJSONJSONJSONJSONJSONJSONJSONJSON
$sample


Data Locality
mongos

Courses and Resources

https://university.mongodb.com/courses/M233/about
THANKS!@blimpyacht