liquid metal’s optimus: synthesis of efficient streaming hardware scott mahlke (university of...
Post on 21-Dec-2015
223 views
TRANSCRIPT

Liquid Metal’s OPTIMUS:Synthesis of Efficient Streaming Hardware
Scott Mahlke (University of Michigan) and Rodric Rabbah (IBM)DAC HLS Tutorial, San Francisco 2009
1

your apphere
JIT compilerconfigureslogic
Dynamic Application Specific Customization of HW
2
Inspired by ASIC paradigm:• High Performance• Low Power

Liquid Metal: “JIT the Hardware”
3
Single language for programming HW & SW Run in a standard JVM, or synthesize in HW Fluidly move computation between HW & SW Do for HW (viz. FPGAs) what FORTRAN did for
computing Address critical technology trendsPower address impractical growth of power and
cooling demands
Architecture enabling million way parallelism vs. small scale multicores
Versatility in the field & on the fly customization to end-user applications
Applications demand for pervasive streaming and mobile content (WWW, multimedia, gaming)
ASIC-like
Reconfigurable

Lime: the Liquid Metal Language
4
Design Principles: Object-oriented, Java-like, Java-compatible Raise level of abstraction Parallel constructs that simplify code Target synthesis while retaining generality

4 reasons not another *C to HDL approach
Emphasis on programmer productivity Leverage rich Java IDEs, libraries, and analysis
Not an auto-parallelization approach Lime is explicitly parallel and synthesizable
Fast fail-safe mechanism Lime may be refined into parallel SW implementation
Intrinsic opportunity for online optimizations Static optimizations with dynamic refinement

Lime Overview6
Computation is well encapsulated
Data-flow driven computation
Multiple “clock domains
Tasks, Value types
HW (FPGA): Lime:
Bit-level control and reasoning
Memory usage statically determined before layout
Abstract OO programming down to the bit-level!
Ordinal-indexed arrays, bounded loops
Streaming primitives
Template-like Generics
Rate “matching” operators

Streams: Exposing Computational Structure
7
Stream primitives are integral to the language
Tasks in streams are strongly isolated Only the endpoints may perform side-
effects Provide macro-level functional
programming abstraction… … While allowing traditional imperative
programming inside

A Brief Introduction to Stream Operations
8
int stream s1 = { 1, 1, 2, 3, 5, 8 };
A finite stream literal:
int stream s2 = task 3;
An infinite stream of 3’s:
int stream s3 = s2 * 17;double stream s4 = Math.sin(s1);double stream s5 = s3 + s4;
Stream expressions:
These operations create and connect tasks. Execution occurs later: lazy computation, functional.

Simple Audio Processing9
value int[] squareWave(int freq, int rate, int amplitude) { int wavelength = rate / freq; int[] samples = new int[wavelength];
for (int s: 1::wavelength) samples[s] = (s <= wavelength/2) ? 0 : amplitude;
return (value int[]) samples;}
int stream sqwaves = task squareWave(1000, 44100, 80));
task AudioSink(44100).play(sqwaves);

Liquid Metal Tool Chain10 Lime
QuicklimeFront-EndCompiler
StreamingIR
LM VMVirtex5 FPGA
LM VM
Xilinxbitfile
XilinxVHDL
Compiler
HDL
Cell BE
LM VM
Cell binary
Cell SDK
C
CrucibleBack-EndCompiler
OptimusBack-EndCompiler
FPGAModel

Streaming Intermediate Representation (SIR)
11
splitter joiner
joiner splitter
Task:
SplitJoin:
Feedback Loop:
switch joiner
Switch:
Pipeline:
• Task may be stateless or have state• Task mapped to “module” with FIFO I/O• Task graphs are hierarchical & structured

SIR Compiler Optimizations12
Address FPGA compilation challenges Finite, non-virtualizable device Complex optimization space
Throughput, latency, power, area Very long synthesis times (minutes-hours)
Task fusion and fission load balancing, scalability
Stream buffer allocation locality enhancing, manage cache footprint or SRAM and control logic complexity
Data access fusion reduce critical path length, improve communication-to-computation balance

Preliminary Liquid Metal Results on Energy Consumption: FPGA vs PPC 405
13
FFT
Pa
ralle
l A
...
Bu
bb
le S
ort
Me
rge
So
rt
Dis
cre
te .
..
DE
S
Ma
trix
Mu
lt..
.
Ma
trix
Blo
c...
Ave
rag
e
0
0.2
0.4
0.6
0.8
Fract
ion o
f Pow
erP
C E
nerg
y
~1.4~1.4~1.4 2.25
• Liquid Metal on Virtex 4 FPGA, 1.6W• C reference implementation on PPC 405, 0.5W
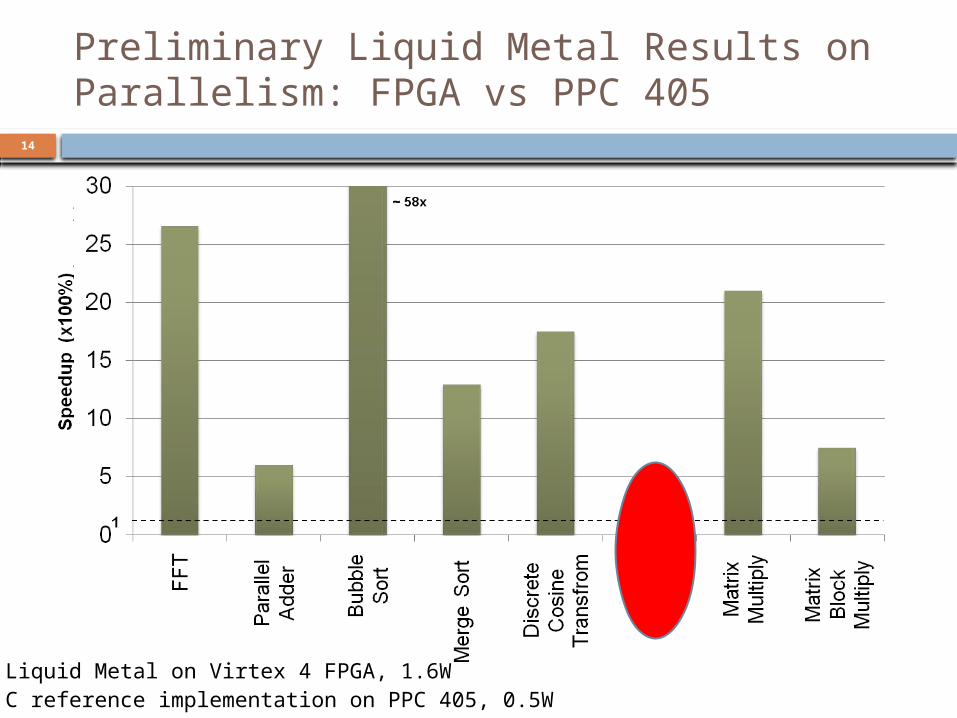
Preliminary Liquid Metal Results on Parallelism: FPGA vs PPC 405
14
• Liquid Metal on Virtex 4 FPGA, 1.6W• C reference implementation on PPC 405, 0.5W

Handel-C Comparison
Compared DES and DCT with hand-optimized Handel-C implementation
Performance 5% faster before optimizations 12x faster after optimizations
Area 66% larger before optimizations 90% larger after optimizations
15

Overview
Compilation Flow
Scheduling
Optimizations
Results
16

Top Level Compilation
Filter
Controller
M0
Init
M1
…
. . .
i0 i1 ix
OmO0O0
…
Mn
Work Source
Filter Filter
Round-Robin Splitter(8,8,8,8)
FilterFilter
Round-Robin Joiner(1,1,1,1)
Sink
a[ ]
i
Init
Controller
Controller
Controller
Controller
Controller
Controller
Controller
Controller
A
B EC
HGF I
J
D
Work
Work
WorkWorkWork
Work
Work
Work
Source
Filter Filter
Round-Robin Splitter(8,8,8,8)
FilterFilter
Round-Robin Joiner(1,1,1,1)
Sink
B DC
F
E
A
J
IHG
17

Filter Compilation
sum = 0i = 0
temp = pop( )
sum = sum + tempi = i + 1Branch bb2 if i < 8
push(sum)
1
2
3
4
Basic Block
Register
Control in
Control outs
Mem
ory/Queue ports
Ack
Live data outsLive data ins
bb1
bb2
bb3
bb4
Live out Data
Live
ou
t Da
ta
Register
mux mux
Register
Register
Register
FIFO Read
FIFO Write
Control
Token
Control Token
Control Token
Ack
Ack
Ack
18

Operation Compilation
FU
…
…
i0 im
o0 on
predicate
ADDADD
CMP
Register
i 1 temp sum
8
Control out 3
11
1
temp
Control out 4
Control in
…
sum = sum + tempi = i + 1Branch bb2 if i < 8
19

Static Stream Scheduling
20
Filter 1
Filter 2
Push 2
Pop 3
Each queue has to be deep enough to hold values generated from a single execution of the connected filter
Double buffering is needed
Buffer access is non-blocking
A controller module is needed to orchestrate the schedule
Controller uses finite state machine to execute the steady state schedule
20

Greedy Stream Scheduling
Filter 1
Filter 2
Filters fire eagerly. Blocking channel access.
Allows for potentially smaller channels
Controller is not needed
Results produced with lower latency.
21

Latency Comparison
FF
T
Pa
ralle
l Ad
de
r
Bu
bb
le S
ort
Me
rge
So
rt
Dis
cre
te C
os.
..
DE
S
Ma
trix
Mu
ltip
ly
Ma
trix
Blo
ck M
...
Ave
rag
e
0
2
4
6
8
10
12
14
16
18
La
ten
cy o
f Sta
tic R
ela
tive
to G
ree
dy
22

Area Comparison
FF
T
Pa
ralle
l Ad
de
r
Bu
bb
le S
ort
Me
rge
So
rt
Dis
cre
te C
os.
..
DE
S
Ma
trix
Mu
ltip
ly
Ma
trix
Blo
ck M
...
Ave
rag
e
0
10
20
30
40
50
60
70
80
90
100Circuits with static schedulerCircuits with greedy scheduler
%
of
FP
GA
A
rea
23

Optimizations
Streaming optimizations (macro functional) Channel allocations, Channel access fusion, Critical Path
Balancing, Filter fission and fusion, etc. Doing these optimization needs global information about the
stream graph Typically performed manually using existing tools
Classic optimizations (micro functional) Flip-flop elimination, Common subexpression elimination,
Constant folding, Loop unrolling, etc. Typically included in existing compilers and tools
24

Channel Allocation
Larger channels: More SRAM More control logic Less stalls
Interlocking makes sure that each filter gets the
right data or blocks.
What is the right channel size?
25

Channel Allocation Algorithm
Set the size of the channels to infinity.
Warm-up the queues.
Record the steady state instruction schedules for each pair.
Unroll the schedules to have the same number of pushes and pops.
Find the maximum number of overlapping lifetimes.
26

Channel Allocation Example
----
----
push
----
push
----
push
push
push
----
----
push
----
----
pop
----
----
----
pop
----
pop
pop
pop
pop
Max overlap = 3
Producer Consumer
Source
Filter 1
Filter 2
Sink
27
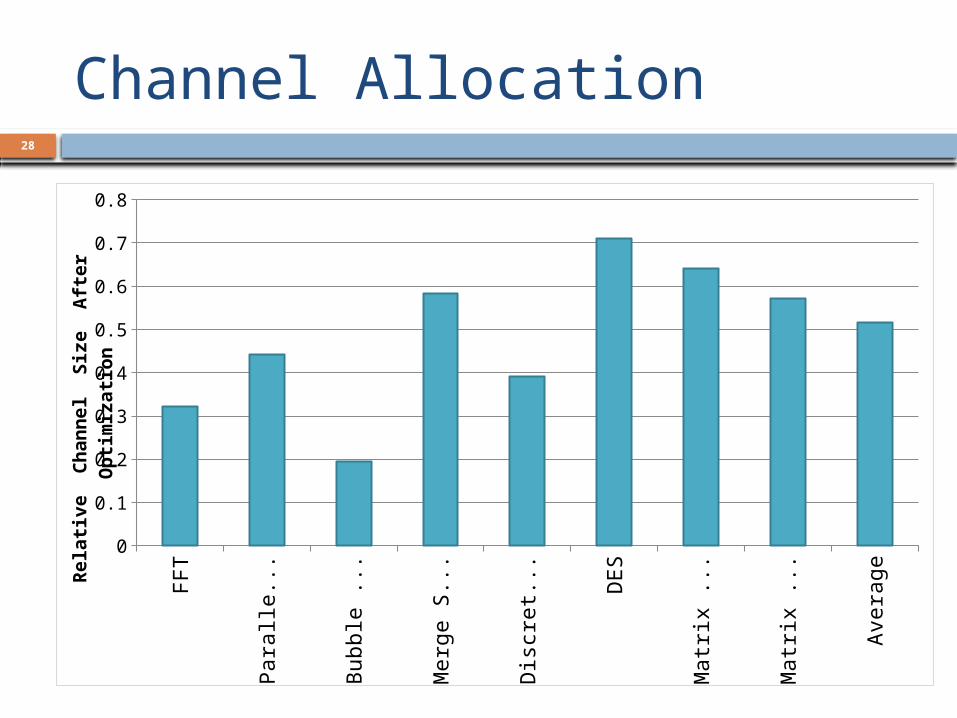
Channel Allocation28
FFT
Para
llel A
...
Bubble
Sort
Merg
e S
ort
Dis
crete
...
DES
Matr
ix M
ul...
Matr
ix B
lo..
.
Ave
rage
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Re
lati
ve
C
ha
nn
el
Siz
e
Aft
er
O
pti
miz
ati
on

Channel Access Fusion
Each channel access (push or pop) takes one cycle.
Communication to computation ratio
Longer critical path latency
Limit task-level parallelism
29

Channel Access Fusion Algorithm
Clustering channel access operations Loop Unrolling Code Motion Balancing the groups
Similar to vectorization Wide channels
30
rrrrrrrr
w
w
w
w
r
w
w
r
Write Mult. = 1
Read Mult. = 8
Write Mult. = 8
Read Mult. = 8
Write Mult. = 4
Read Mult. = 1
30

Access Fusion Example
Some caveats
int sum = 0; for (int i = 0; i < 32; i++) sum+ = pop(); push(sum);
int sum = 0; int t1, t2, t3, t4; for (int i = 0; i < 8; i++) { (t1, t2, t3, t4) = pop4(); sum+ = t1 + t2 + t3 + t4; } push(sum); }}
int sum = 0; for (int i = 0; i < 32; i++) sum+ = pop(); pop(); pop(); push(sum);
int sum = 0; for (int i = 0; i < 8; i++) { sum+ = pop(); sum+ = pop(); sum+ = pop(); sum+ = pop(); } pop(); pop(); push(sum);
31

FFT
Pa
ralle
l A
...
Bu
bb
le S
ort
Me
rge
So
rt
Dis
cre
te .
..
DE
S
Ma
trix
Mu
lt..
.
Ma
trix
Blo
c...
Ave
rag
e
0
1
2
3
4
5
6
7
8
Sp
eed
up
(x1
00
%)
Access Fusion32

Critical Path Balancing
Critical path is set by the longest combinational path in the filters
Optimus uses its internal FPGA model to estimate how this impacts throughput and latency
Balancing Algorithm: Optimus take target clock as input Start with least number of basic blocks Form USE/DEF chains for the filter Use the internal FPGA model to measure critical path
latency Break the paths whose latency exceeds the target
33

Critical Path Balancing Example
Mul
Add
MulMul
Sub
Add
MulMul
Sub
Mul
Sub
Add Sub Add Sub
Add Sub
Mul Mul
Add Add
Shift
Shift
Add
AddSub
Add
MulMul
Sub
Mul
Add
Add SubAdd Sub
Add
Shift
1
1
1
2
2
1
3
34
Operation
Delay
Add/Sub 4
Shift 2
Multiply 10
34

Liquid Metal 35
Interdisciplinary effort addressing the entire stack One language for programming HW (FPGAs) and
SW Liquid Metal VM: JIT the hardware!
GPU MulticoreCPU ???FPGA
LiquidMetal VM
Program all withLime

Streaming IR
Expose structure: computation and communication
Uniform framework for pipeline and data parallelism
Canonical representation for stream-aware optimizations

Streaming Optimizations
Macro-functional Fold streaming IR
graphs into FPGA… Fusion, fission,
replication …subject to
latency, area, and throughput constraints
Micro-functional Micro-pipelining Channel
allocation Access fusion Flip-flop
elimination

Ongoing Effort
Application development Streaming for enterprise and consumer Real-time applications
Compiler and JIT Pre-provisioning profitable HW implementations Runtime opportunities to “JIT” the HW
Advanced dynamic reconfiguration support in VM Predictive, hides latency
New platforms Tightly coupled, higher bandwidth, lower
latency communication Heterogeneous MPSoC systems – FPGA +
processors
38