linked (open) data - unige.it...(data-warehousing) virtually materialized approaches federated...
TRANSCRIPT

LINKED (OPEN) DATA
1
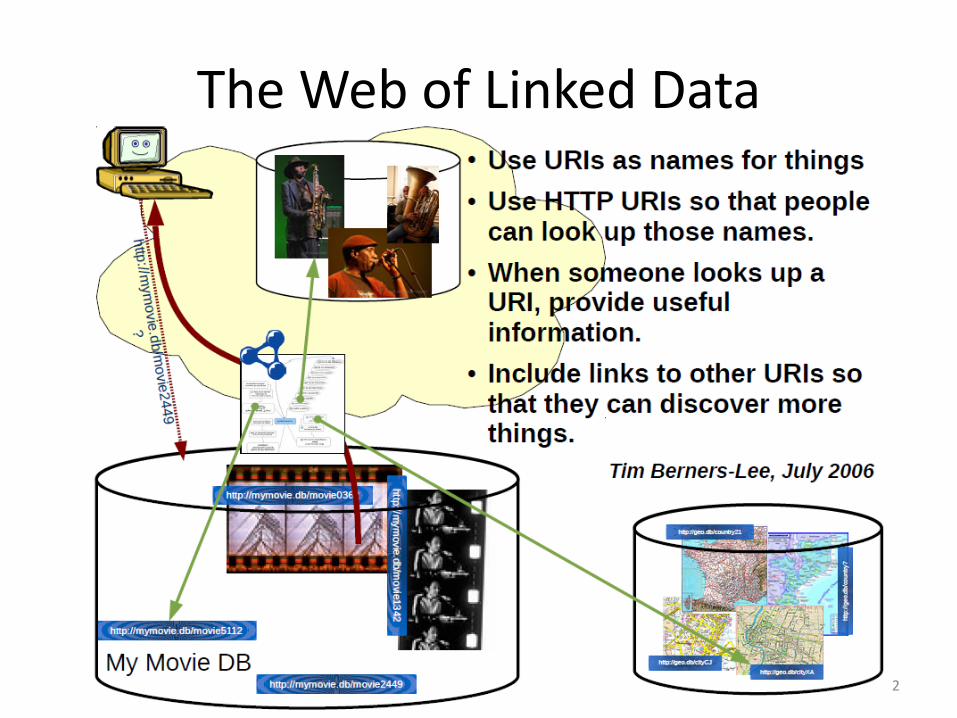
The Web of Linked Data
2
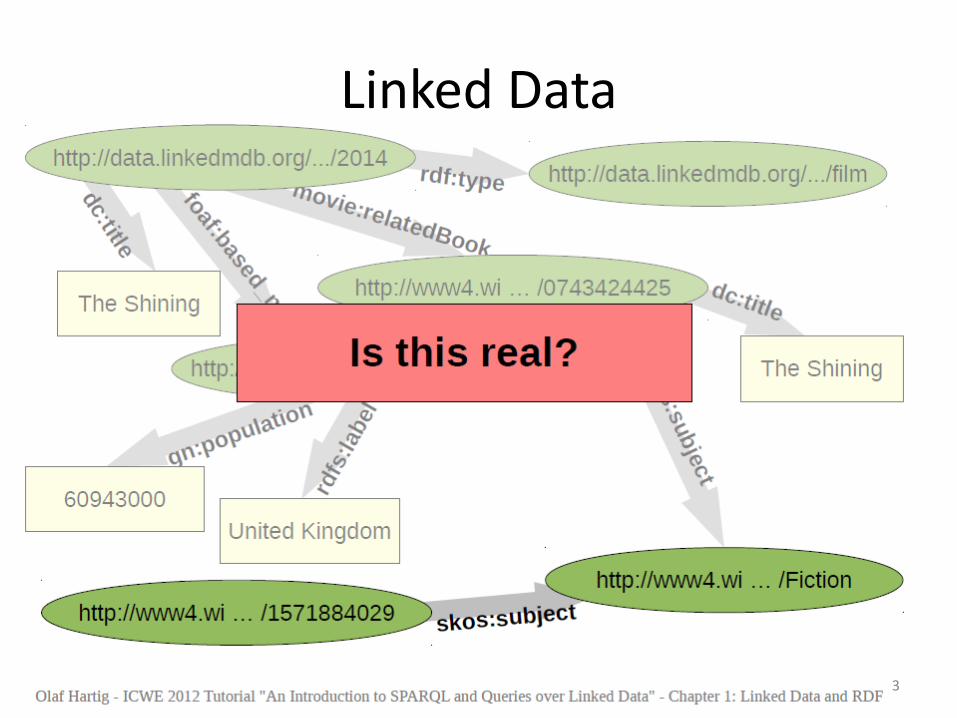
Linked Data
3

W3C Linked Open Data Project
4

Linked (Open) Data
• Linked data is just RDF data, typically– Just the instances, not schema
• Linked open data is just linked data freely accessible on the Web along with any required ontologies
5

W3C Linked Open Data Project
6

W3C Linked Open Data Project
7

W3C Linked Open Data Project
8

W3C Linked Open Data Project
9

W3C Linked Open Data Project
10

W3C Linked Open Data Project
More than 30 billion triples in more than 200 sources across the LOD cloud DBPedia: 3.4 million entities, 1 billion triples
Sources:linkeddata.orgwikipedia.org
11

Issue
• Huge and growing fast linked data set• Huge volumes è Towards Big Data
• In the following– Principles for storing and querying RDF data,
giving up volume issues
13

RDF USE CASES
14

Standards for knowledge representation and processing
Semantic Web Stack
unambiguous namesfor resources:URIs
a common datamodel to access,connect, describethe resources: RDF
access to data:SPARQL
define commonvocabularies:RDFS, OWL
reasoning logics:OWL, Rules
15

Use Cases
• Here, focus on RDF data processing– No reasoning
• Three main scenarios:– Processing a single RDF dataset– RDF as a view of relational data– RDF in distributed settings
16

Processing a single RDF dataset: SPARQL Protocol, Endpoints
• SPROT = SPARQL Protocol for RDF• SPARQL endpoint– A service, conformant to SPROT, that accepts SPARQL
queries and returns results via HTTP, in one or more machine-processable formats
– Either generic (fetching data as needed) or specific (querying an associated triple store)
– Issuing a SPARQL query is an HTTP GET request with parameter query
• A SPARQL endpoint is mostly conceived as a machine-friendly interface towards a knowledge base
17

Processing a single RDF dataset
18
List of SPARQL endpoints: http://www.w3.org/wiki/SparqlEndpoints

Processing a single RDF dataset: SPARQL Client Libraries
19

Processing a single RDF dataset: setting up your own collection
20

Processing a single RDF dataset: populating your own collection
21

Relational Databases to RDF: RDB2RDF
23

RDF in Distributed Settings
• Querying integrated RDF datasets– Controlled Integration solutions– Link traversal based query execution
24

Controlled Integration Solutions
• Ship and integrate data from different sources to the client.
• Three common approaches:– Query-driven (single mediator)
– Database federations (exported schemas)
– Materialization-based approached(fully integrated & centrally managed warehouse)
RDFSource
RDFSource
?
25

Controlled Integration Solutions
Approaches for querying
distributed and potentially heterogeneous (RDF) data sources
Materialization-based approaches(data-warehousing)
Virtually materialized
approaches
Federated Systems
(Exported schema)
MapReduce/
Hadoop
Shared-memory
architectures
(Message-Passing, RMI, etc.)
Non-MR
Shared-nothing
architectures
Query-driven(Mediator-based
Systems)Shard, Jena-HBase
[Abadi et al. PVLDB’11]
Trinity (MSR)
DARQFedEx
YARS2
Partout
4Store
Eagre
TOWARDS BIG DATA 26

Query-Driven Approach
SPARQL Client
Wrapper
RDFSource
RDFSource
RDFSource
query result query resultquery result
Mediator
Wrapper Wrapper
SPARQL Client
27

Advantages of Query-Driven Integration
• No need to copy data– no or little own storage costs– no need to purchase data
• Potentially more up-to-date data• Mediator holds catalog (statistics, etc.) and may
optimize queries• Only generic query interface needed at sources
(SPARQL endpoints)• May be less draining on sources• Sources often even unaware of participation
28

resultquery
Federation-based ApproachSPARQL Client
RDFSource
Federated Schema
Exported Schema
SPARQL Client
Local Schema
resultquery
RDFSource
Exported Schema
Local Schema
resultquery
RDFSource
Exported Schema
Local Schema
Source 1 Source 2 … Source n 29

Advantages of Federation-Based Integration
• Very similar to query-driven integration, except – that the sources know that they are part of a
federation– and they export their local schemas into a
federated schema• Intermediate step toward full integration of
the data in a single “warehouse”
30

Warehousing Architecture
SPARQL Client
Warehouse
RDFSource
RDFSource
RDFSource
Query & Analysis
Integration
Metadata
SPARQL Client
31

Advantages of Warehousing• Perform Extract-Transform-Load (ETL) processes with
periodic updates over the source• High query performance• Local processing at sources unaffected• Can operate even when sources are offline• Can query data that is no longer stored at sources• More detailed statistics and metadata available at
warehouse– Modify, summarize (store aggregates), analyse– Add historical information, provenance, timestamps, etc.
32

SPARQL 1.1 Federation Extension
33

Controlled Integration Solutions: Summary
• Pros:– Queried data is up to date
• Cons:– All relevant datasets must be exposed via a
SPARQL endpoint– Effort to set up mediator/federated/warehouse
schema
34

Controlled Integration Solutions: Summary
35

Link traversal-based query execution
36

Main Idea
37

Main Idea
38

Main Idea
39

Main Idea
40

Main Idea
41
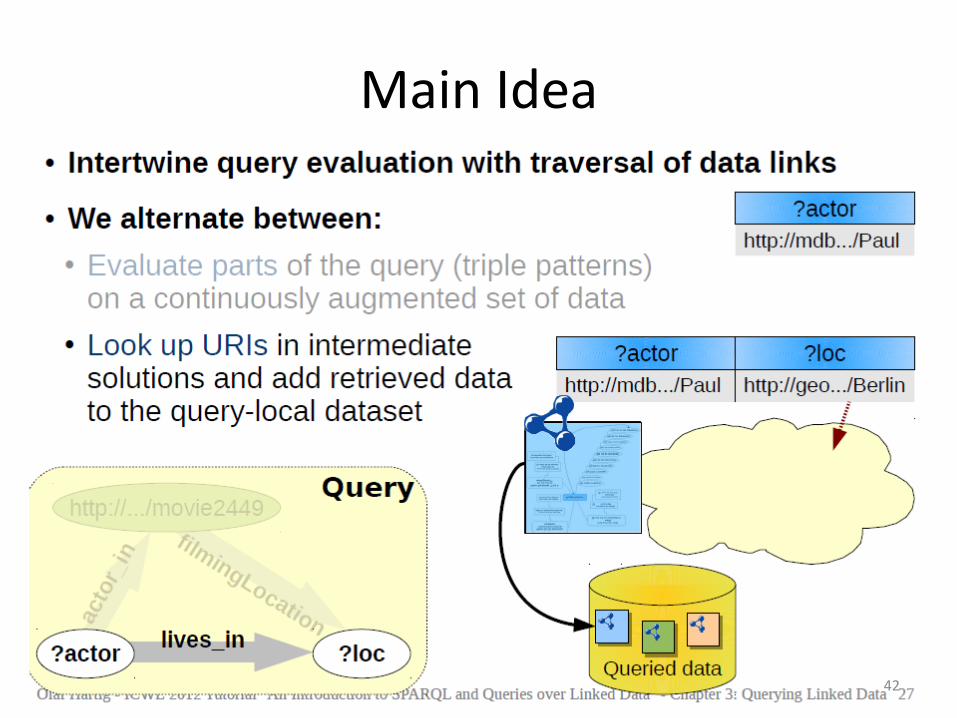
Main Idea
42
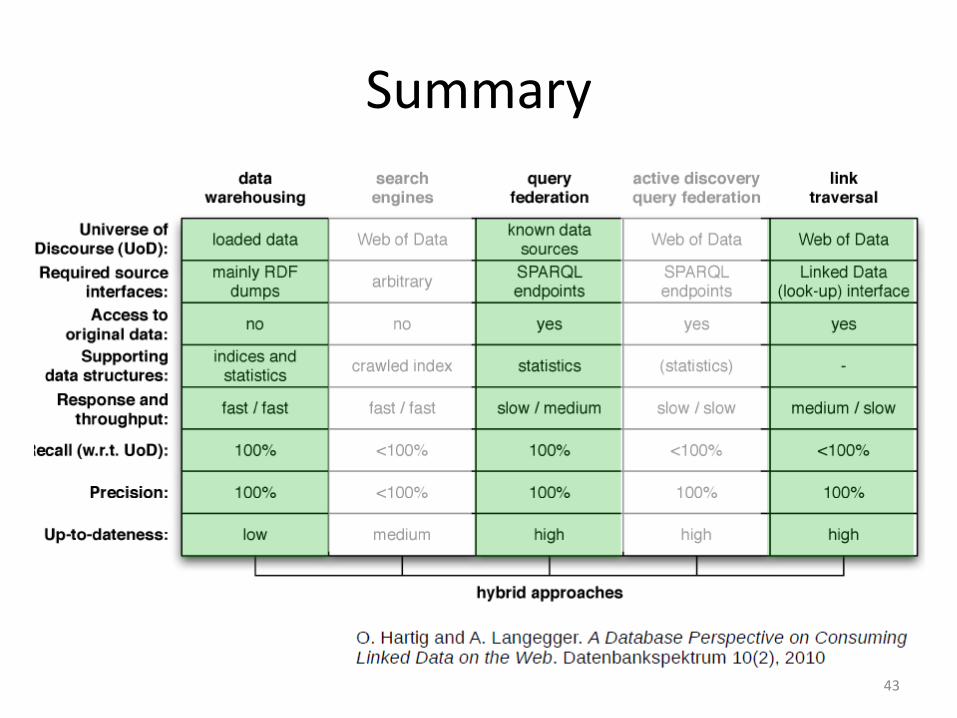
Summary
43

RDF AND DATABASES
44

RDF and Databases
• Two alternative approaches
RDF as an interface format
RDF Enabled SolutionsRDF is not visible inside the DBMS
RDF Native SolutionsRDF (triples, graphs) as data model
RDF as astoring format
45

Back-end
Native vs Non-Native Systems
46
Native systems
Non Native systems

Classification of RDF Systems
In Memory
RDF Graph is stored as triples in
main –memory
In memory is fastest, but load time has to be
factored in
Native store
Persistent storage systems with their
own implementation of databases
Native stores are fast, scalable, and popular
now
Jena TDB, Sesame Native, Virtuoso,
AllegroGraph, Oracle 11g
Non-Native store
Persistent storage systems set-up to run on third party DBs
Non-native stores may be better if you want to rely on
the overall set of DBMS functionalities
Jena SDB using Postgres or Oracle
47

Native RDF Systems
• Storing RDF as set of triples– Triple stores
• Storing RDF as a graph– Graph databases
48

Some examples of Native systems
Solution name StorageNative
SPARQLSupport
Native APIs
AllegroGraph Graph √For most modern
programming languages
Dydra Graph database in the cloud √ REST API
Jena Tuple store √ JavaOracle (from 11g) Triplestore √ Java
Sesame 3rd party √ JavaStardog Triplestore √ Java, Groovy
Profium Sense In-memory triplestore √ Java
49

Triple Stores management issues
• At a high logical level– The data model corresponds to sets of triples– No need to create schemas– No need to link tables because you can have one
to many relationships directly• At a lower level– Triple stored in memory in a persistent back-end– Persistence provided by a relational DBMS or a
custom DB for efficiency
50

Relational backend
• General RDBMS (e.g., MySQL, PostgreSQL, Oracle, DB2, SQLServer, …)
• Basic principles:– store triples in one single giant three-attribute table
(subject, predicate, object)– convert SPARQL to equivalent SQL– The database will do the rest
• Used by many TripleStores, including 3Store, Jena, HexaStore, RDF-3X, …
51

Example: Single Triple Tableex:Katja ex:teaches ex:Databases;
ex:works_for ex:MPI_Informatics;ex:PhD_from ex:TU_Ilmenau.
ex:Martin ex:teaches ex:Databases;ex:works_for ex:MPI_Informatics;ex:PhD_from ex:Saarland_University.
ex:Ralf ex:teaches ex:Information_Retrieval;ex:PhD_from ex:Saarland_University;ex:works_for ex:Saarland_University,
ex:MPI_Informatics.
subject predicate objectex:Katja ex:teaches ex:Databasesex:Katja ex:works_for ex:MPI_Informaticsex:Katja ex:PhD_from ex:TU_Ilmenauex:Martin ex:teaches ex:Databasesex:Martin ex:works_for ex:MPI_Informaticsex:Martin ex:PhD_from ex:Saarland_Universityex:Ralf ex:teaches ex:Information_Retrievalex:Ralf ex:PhD_from ex:Saarland_Universityex:Ralf ex:works_for ex:Saarland_Universityex:Ralf ex:works_for ex:MPI_Informatics 52

Conversion of SPARQL to SQLGeneral approach to translate SPARQL into SQL:
(1) Each triple pattern is translated into a (self-) JOINover the triple table
(2) Shared variables create JOIN conditions(3) Constants create WHERE conditions(4) FILTER conditions create WHERE conditions(5) OPTIONAL clauses create OUTER JOINS(6) UNION clauses create UNION expressions
53

SELECT
FROM Triples P1, Triples P2, Triples P3
Example: Conversion to SQL Query
SELECT ?a ?b ?t WHERE
{?a works_for ?u. ?b works_for ?u. ?a phd_from ?u. }
OPTIONAL {?a teaches ?t}
FILTER (regex(?u, “Saar”))
SELECT
FROM Triples P1, Triples P2, Triples P3
WHERE P1.predicate=“works_for” AND P2.predicate=“works_for”
AND P3.predicate=“phd_from”
SELECT
FROM Triples P1, Triples P2, Triples P3
WHERE P1.predicate=“works_for” AND P2.predicate=“works_for”
AND P3.predicate=“phd_from”
AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object
SELECT
FROM Triples P1, Triples P2, Triples P3
WHERE P1.predicate=“works_for” AND P2.predicate=“works_for”
AND P3.predicate=“phd_from”
AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object
AND REGEXP_LIKE(P1.object, “Saar”)
SELECT P1.subject as A, P2.subject as B
FROM Triples P1, Triples P2, Triples P3
WHERE P1.predicate=“works_for” AND P2.predicate=“works_for”
AND P3.predicate=“phd_from”
AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object
AND REGEXP_LIKE(P1.object, “Saar”)
SELECT R1.A, R1.B, R2.T FROM
( SELECT P1.subject as A, P2.subject as B
FROM Triples P1, Triples P2, Triples P3
WHERE P1.predicate=“works_for” AND P2.predicate=“works_for”
AND P3.predicate=“phd_from”
AND P1.object=P2.object AND P1.subject=P3.subject AND P1.object=P3.object
AND REGEXP_LIKE(P1.object, “Saar”)
) R1 LEFT OUTER JOIN
( SELECT P4.subject as A, P4.object as T
FROM Triples P4
WHERE P4.predicate=“teaches”) AS R2
) ON (R1.A=R2.A)
´
P1
P2
P3
P4´
´
Filter
regex(?u,“Saar“)
Projection
?u
?a,?u
?a
54

Is that all?Well, no.• Which indexes should be built?
(to support efficient evaluation of triple patterns)• How can we reduce storage space?• How can we find the best execution plan?
Existing databases need modifications:• flexible, extensible, generic storage not needed here• cannot deal with multiple self-joins of a single table• often generate bad execution plans
55

Fragmentation-based solutionsObservations and assumptions:• Not too many different predicates• Triple patterns usually have fixed predicate• Need to access all triples with one predicate
Design consequence:• Use one two-attribute table for each predicate
57

Exampleex:Katja ex:teaches ex:Databases;
ex:works_for ex:MPI_Informatics;ex:PhD_from ex:TU_Ilmenau.
ex:Martin ex:teaches ex:Databases;ex:works_for ex:MPI_Informatics;ex:PhD_from ex:Saarland_University.
ex:Ralf ex:teaches ex:Information_Retrieval;ex:PhD_from ex:Saarland_University;ex:works_for ex:Saarland_University,
ex:MPI_Informatics.
subject objectex:Katja ex:TU_Ilmenauex:Martin ex:Saarland_Universityex:Ralf ex:Saarland_University
PhD_from
subject objectex:Katja ex:MPI_Informaticsex:Martin ex:MPI_Informtaticsex:Ralf ex:Saarland_Universityex:Ralf ex:MPI_Informatics
works_for
subject objectex:Katja ex:Databasesex:Martin ex:Databasesex:Ralf ex:Information_Retrieval
teaches
58

Simplified Example: Query Conversion
SELECT ?a ?b ?t WHERE
{?a works_for ?u. ?b works_for ?u. ?a phd_from ?u. }
SELECT W1.subject as A, W2.subject as B
FROM works_for W1, works_for W2, phd_from P3
WHERE W1.object=W2.object
AND W1.subject=P3.subject
AND W1.object=P3.object
59

Fragmentation-based solutions andcolumnstores
Columnstores store each column (or group of columns) of a table separately
subject objectex:Katja ex:TU_Ilmenauex:Martin ex:Saarland_Universityex:Ralf ex:Saarland_University
PhD_from
PhD_from:subjectex:Katjaex:Martinex:Ralf
PhD_from:objectex:TU_Ilmenauex:Saarland_Universityex:Saarland_University
Advantages:• Fast if only subject or object are accessed, not both• Allows for a very compact representation
Problems:• Need to recombine columns if subject and object are accessed• Inefficient for triple patterns with predicate variable • Space overhead in case the same subject is replicated among triples several times60
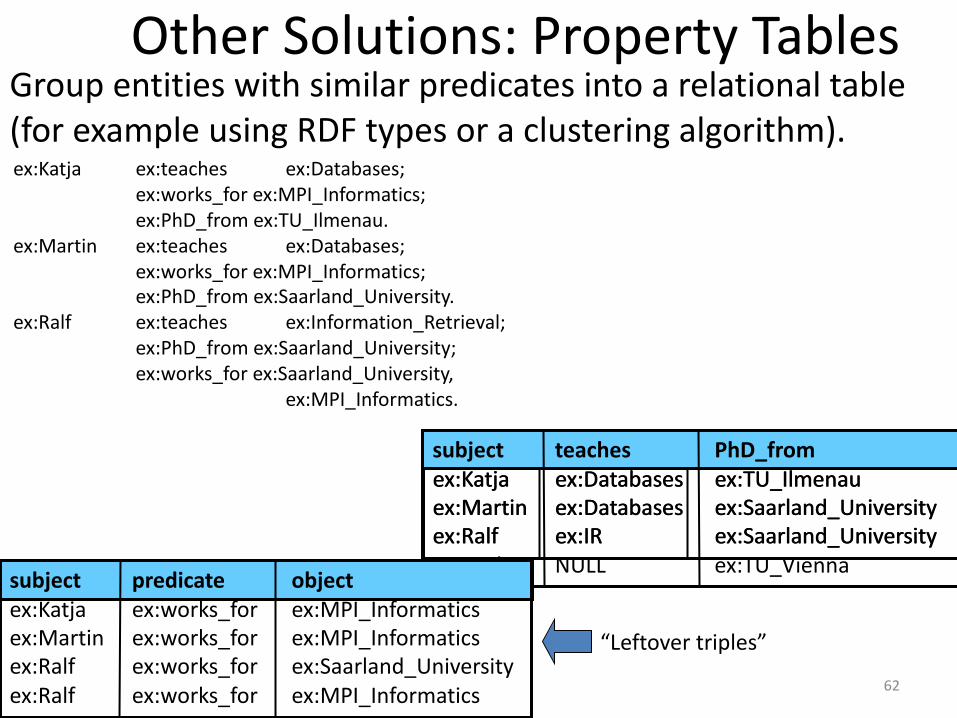
Other Solutions: Property TablesGroup entities with similar predicates into a relational table(for example using RDF types or a clustering algorithm).ex:Katja ex:teaches ex:Databases;
ex:works_for ex:MPI_Informatics;ex:PhD_from ex:TU_Ilmenau.
ex:Martin ex:teaches ex:Databases;ex:works_for ex:MPI_Informatics;ex:PhD_from ex:Saarland_University.
ex:Ralf ex:teaches ex:Information_Retrieval;ex:PhD_from ex:Saarland_University;ex:works_for ex:Saarland_University,
ex:MPI_Informatics.
subject teaches PhD_fromex:Katja ex:Databases ex:TU_Ilmenauex:Martin ex:Databases ex:Saarland_Universityex:Ralf ex:IR ex:Saarland_University
subject teaches PhD_fromex:Katja ex:Databases ex:TU_Ilmenauex:Martin ex:Databases ex:Saarland_Universityex:Ralf ex:IR ex:Saarland_Universityex:Axel NULL ex:TU_Viennasubject predicate object
ex:Katja ex:works_for ex:MPI_Informaticsex:Martin ex:works_for ex:MPI_Informaticsex:Ralf ex:works_for ex:Saarland_Universityex:Ralf ex:works_for ex:MPI_Informatics
“Leftover triples”
62

Property Tables: Pros and Cons
Advantages:• More in the spirit of existing relational
systems• Saves many self-joins over triple tables etc.Disadvantages:• Potentially many NULL values• Query mapping depends on schema• Schema changes very expensive
63

Even More Systems…• Store RDF data as sparse matrix with bit-vector
compression • Convert RDF into XML and use XML methods
(XPath, XQuery, …)• Store RDF data in graph databases and perform
bi-simulation or employ specialized graph index structures
• And many more …
64