link prediction
TRANSCRIPT

Link Prediction
Class Data Mining Technology for Business and SocietyProgram M. Sc. Data ScienceUniversity Sapienza University of RomeSemester Spring 2016Lecturer Carlos Castillo http://chato.cl/
Sources:● Chapter 10 of Zafarani, Abbasi, and Liu's book on Social Media
Mining [slides] ● Sarkar, Chakrabarti, Moore: [slides] [slides]

Problem definition
● Given a graph G=(V,E) at time t– Or a series of snapshots of the graph at times ti<=t
● Describe the state of the graph at time t'>t● Sometimes, assume V stays the same and E
changes

Applications
Accelerating formation of connections in professional social networks

Applications
● Helping find your offline friends online

Applications
● Increase server efficiency through pre-fetching● Determining which links are missing in Wikipedia
pages (or other educational resources) ● Monitor/control propagation of computer viruses● Fixing corrupted data
– You bought five books, one of the titles is lost, can we infer it?
● ...

Basic method
1)Assign a score to every possible link (u,v)
2)Sort links by descending score
3)Predict the top-k links
Or the links with scores above a threshold
4)Profit!

Common neighbors
● Newman 2001: The probability of scientists collaborating increases with the number of other collaborators they have in common.
● Tendency to close triangles, more on this later ...

Jaccard similarity
● Correct common neighbors by reducing the influence of nodes with many neighbors

Adamic/Adar
● Count common neighbors but weight down nodes with too many neighbors
The idea is to avoid this
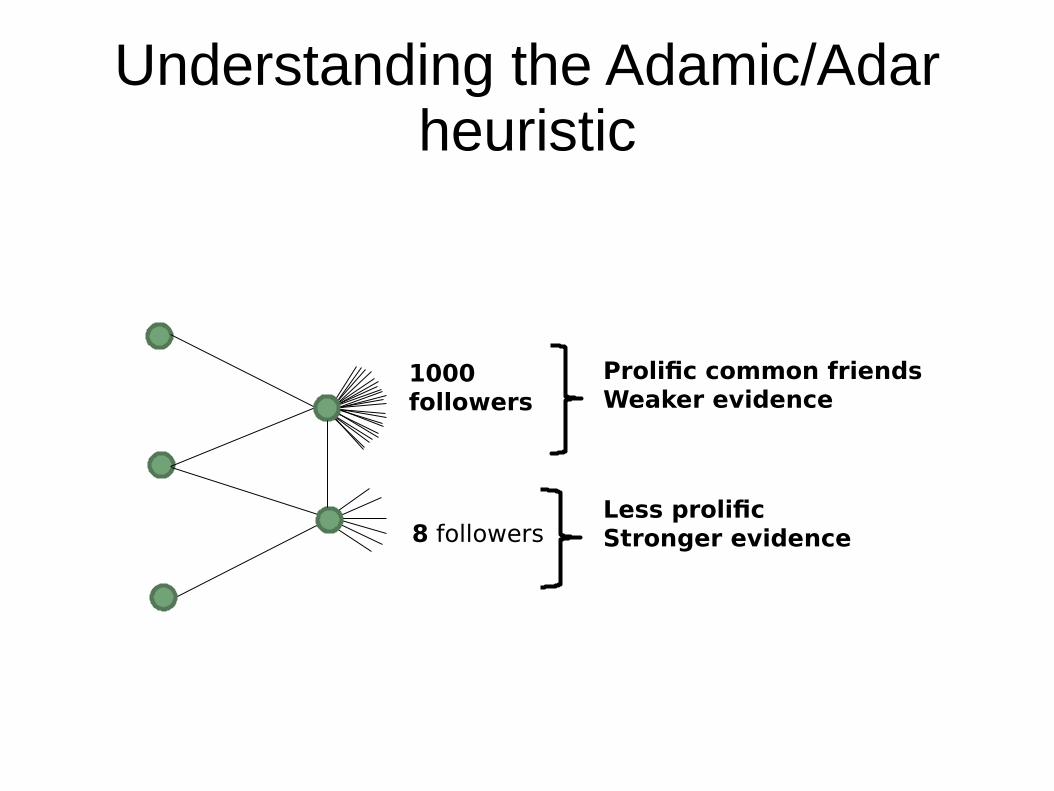
Understanding the Adamic/Adar heuristic
8 followers
1000followers
Prolific common friendsWeaker evidence
Less prolific Stronger evidence
Alice
Bob
Charlie

Preferential attachment
● “Rich-get-richer”● Newman 2001: the probability of two authors
collaborating is proportional to the product of their number of collaborators

Example: score(v5,v
7)
Exercise, compute:
● Number of common neighbors● Jaccard coefficient● Adamic and Adar's● Preferential attachment

Geodesic/shortest path distance
● Assumption: social connections are formed by following edges, then finding a new person, then connecting directly
score(u,v) := -(length of shortest path from u to v)
● Limit case: triadic closure

Katz 1953 or “rooted PageRank”
● Score based on weighted counts of paths, with exponential decay on path length. For α < 1
● A small α yields predictions which are similar to common neighbors

More on random walks
● Hitting time● Hu,v = expected steps of random walk from u to v
● To reduce the influence of well-connected nodes, we can multiply by the probability of a node in stationary state

Symmetric hitting time(commute time)
● Hitting time is not symmetric, we can symmetrize easily

Graph projections

SimRank [Jeh 2002]
● For directed graphs; follows inlinks
u
v
w
p
q s
r
Exercise, compute:
● simrank(u,v)● simrank(v,w)● simrank(u,w)

Meta-method / prunning
● Compute score(u,v) for all existing edges assuming they do not exist
● Remove k% with lower score● Compute score(u,v) in the reduced graph

Evaluating link prediction methods
● After one of the aforementioned measures is selected, a list of the top most similar pairs of nodes are selected.
● These pairs of nodes denote edges predicted to be the most likely to soon appear in the network.
● Performance (precision, recall, or accuracy) can be evaluated using the testing graph and by comparing the number of the testing graph’s edges that the link prediction algorithm successfully reveals.
● Performance is usually very low, since many edges are created due to reasons not solely available in a social network graph.
● So, a common baseline is to compare the performance with random edge predictors and report the factor improvements over random prediction.
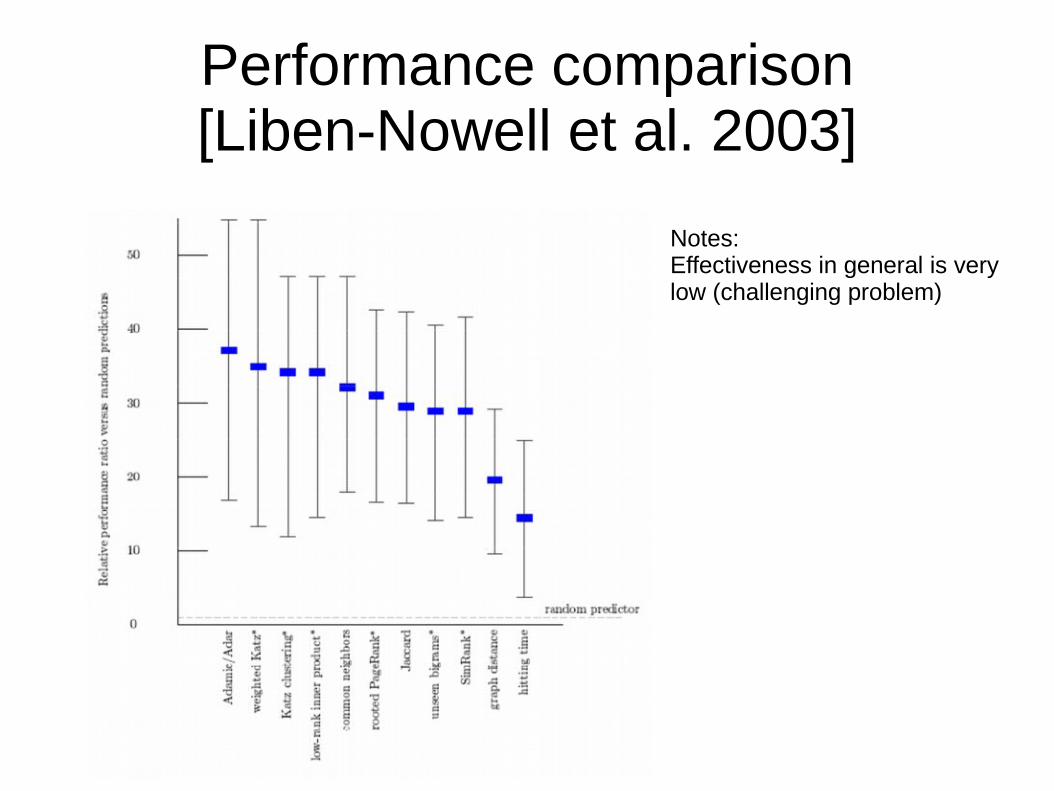
Performance comparison[Liben-Nowell et al. 2003]
Notes:Effectiveness in general is very low (challenging problem)

Adamic/Adar + content

Supervised learning[Hassan et al. 2006]
● Input features are all attributes, possibly including node-links as attribute
● Predict connected/not-connected learning on a sub-set of the data

Example experimental results with supervised learning
● Data: co-authorship network in DBLP and BIOBASE
● Split into two disjoint ranges of publication years (Ra, Rb)– Example: DBLP, Ra = [1999,2000] Rb=[2001,2004]
● Training item is a pair of authors (u,v), both with a paper in Ra, and all their attributes computed in Ra
● Ground truth is whether (u,v) co-author during Rb– Positive=yes, Negative=no

Example features
● Content similarity– Keywords in common, conferences in common, ...
● Aggregation features– Sum of papers, Sum of neighbors, ...
● Topological distance– Shortest-path length, ...

Performance results under various learning schemes (same feature set)

Community prediction

Community membership prediction
● Why do users join communities? – What factors affect the community-joining behavior of individuals?
● We can observe users who join communities and determine the factors that are common among them
● We require a population of users, a community C, and community membership information (i.e., users who are members of C).– To distinguish between users who have already joined the community
and those who are now joining it, we need community memberships at two different times t1 and t2, with t2 > t1.
– At t2, we determine users such as u who are currently members of the community, but were not members at t1. These new users form the subpopulation that is analyzed for community-joining behavior.

Peer influence
Hypothesis: individuals are inclined toward an activity when their friends are engaged in the same activity.
A factor that plays a role in users joining a community is the number of their friends who are already members of the community.

Supervised learning

Example regression tree

Beyond community membership
● Communities can be implicit: One can think of individuals buying a product as a community, and people buying the product for the first time as individuals joining the community
● Collective Behavior: A group of individuals behaving in a similar way (first defined by sociologist Robert Park)
● It can be planned and coordinated, but often is spontaneous and unplanned
● Examples:
– Individuals standing in line for a new product release
– Posting messages online to support a cause or to show support for an individual
● Approach can be similar to community membership prediction