linear methods, cont’d; svms intro. straw poll which would you rather do first? unsupervised...
Post on 21-Dec-2015
214 views
TRANSCRIPT

Linear Methods,cont’d; SVMs intro

Straw poll•Which would you rather do first?
•Unsupervised learning
•Clustering
•Structure of data
•Scientific discovery (genomics, taxonomy, etc.)
•Reinforcement learning
•Control
•Robot navigation
•Learning behavior

Reminder...•Finally, can write:
•Want the “best” set of w: the weights that minimize the above
•Q: how do you find the minimum of a function w.r.t. some parameter?

Reminder...•Derive the vector derivative expressions:
•Find an expression for the minimum squared error weight vector, w, in the loss function:

Solution to LSE regression•Differentiating the loss function...

LSE followup•The quantity is called a Gram matrix
and is positive semidefinite and symmetric
•The quantity is the pseudoinverse of X
•The complete “learning algorithm” is 2 whole lines of Matlab code
•So far, we have a regressor -- estimates a real valued y for each X
•Can convert to a classifier by assigning y=+1 or -1 to binary class training data
•Q: How do you handle non-binary data?

Handling non-binary data•DTs and k-NN can handle multi-class data
•Linear discriminants (& many other) learners only work on binary
•3 ways to “hack” binary classifiers to p-ary data:
•1 against many:
•Train p classifiers to recognize “class 1 vs anything else”; “class 2 vs everything else” ...
•Cheap, easy
•May drastically unbalance the classes for each classifier
•What if two classifiers make diff predictions?
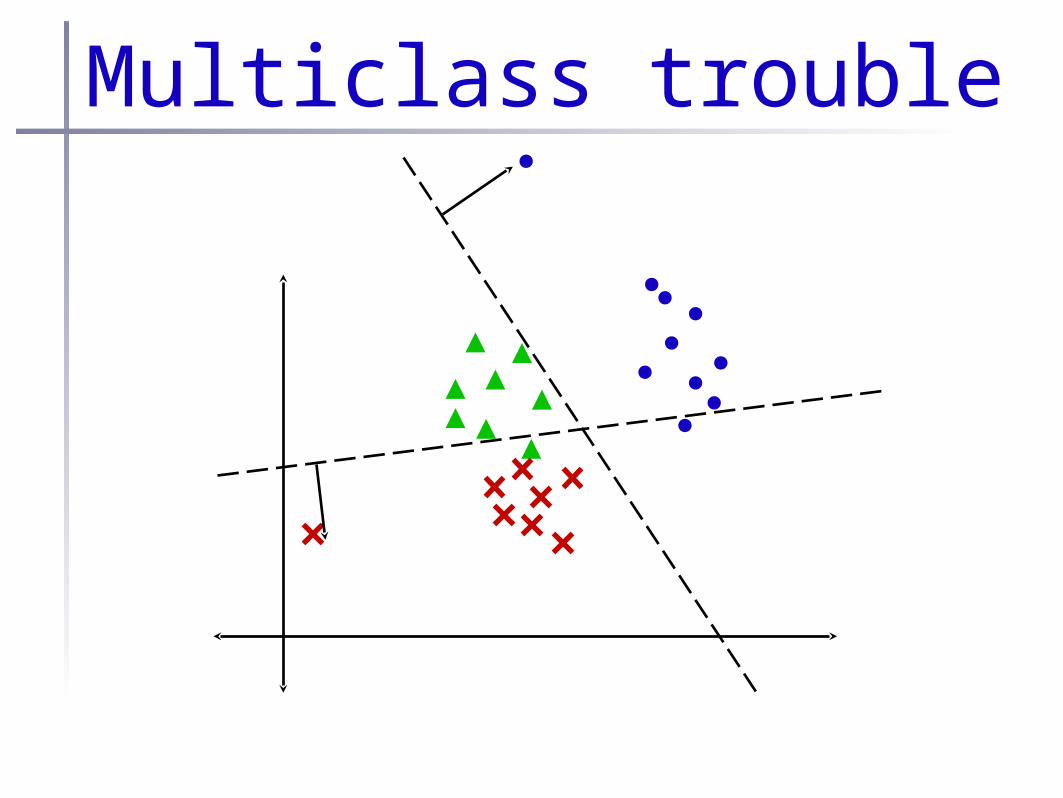
Multiclass trouble

Handling non-binary data•All against all:
•Train O(p^2) classifiers, one for each pair of classes
•Run every test point through all classifiers
•Majority vote for final classifier
•More stable than 1 vs many
•Lot more overhead, esp for large p
•Data may be more balanced
•Each classifier trained on very small part of data
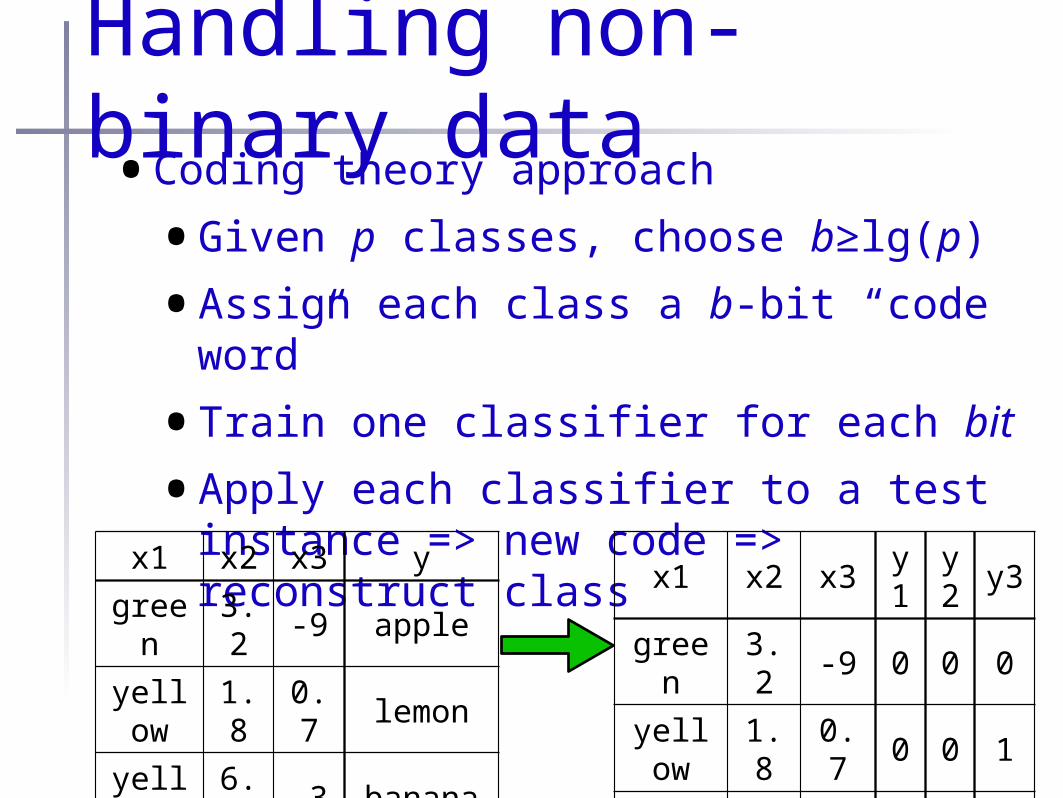
Handling non-binary data•Coding theory approach
•Given p classes, choose b≥lg(p)
•Assign each class a b-bit “code word”
•Train one classifier for each bit
•Apply each classifier to a test instance => new code => reconstruct class
x1 x2 x3 y
green
3.2 -9 apple
yellow
1.8 0.7 lemon
yellow
6.9 -3 banana
red 0.8 0.8 grape
green
3.4 0.9 pear
x1 x2 x3y1
y2
y3
green 3.2 -9 0 0 0
yellow
1.8 0.7 0 0 1
yellow
6.9 -3 0 1 0
red 0.8 0.8 0 1 1
green 3.4 0.9 1 0 0

Support Vector Machines

Linear separators are nice•... but what if your data looks like this:
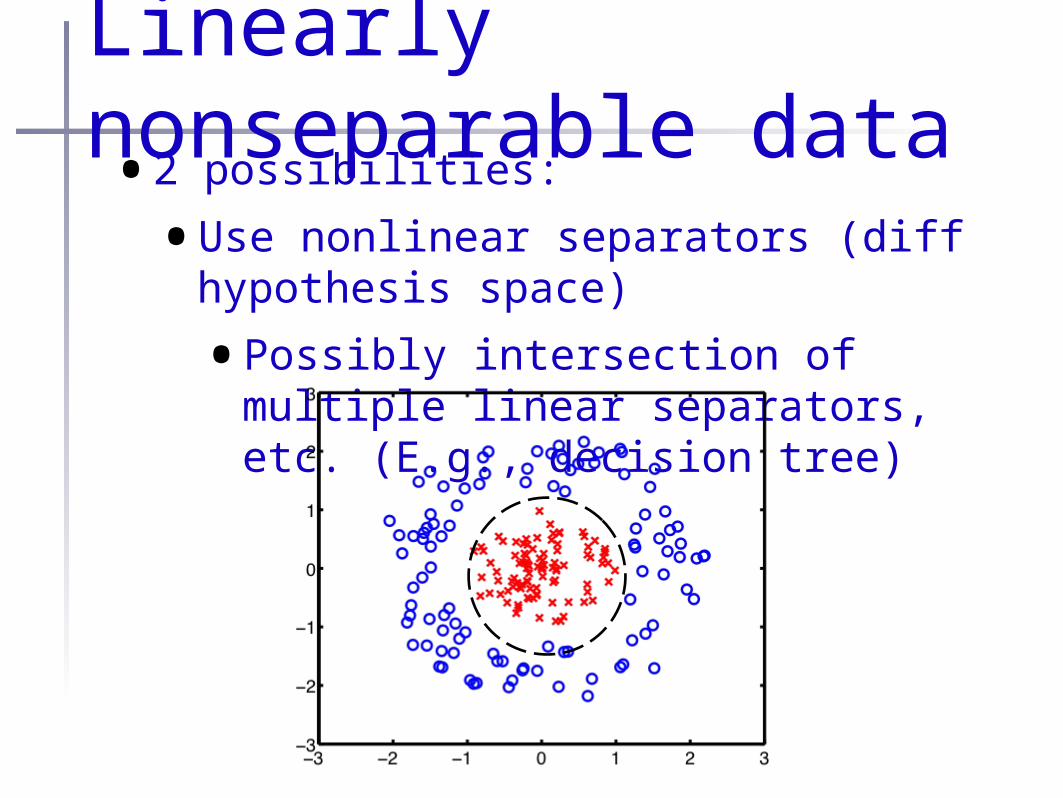
Linearly nonseparable data•2 possibilities:
•Use nonlinear separators (diff hypothesis space)
•Possibly intersection of multiple linear separators, etc. (E.g., decision tree)

Linearly nonseparable data•2 possibilities:
•Use nonlinear separators (diff hypothesis space)
•Possibly intersection of multiple linear separators, etc. (E.g., decision tree)
•Change the data
•Nonlinear projection of data
•These turn out to be flip sides of each other
•Easier to think about (do math for) 1st case
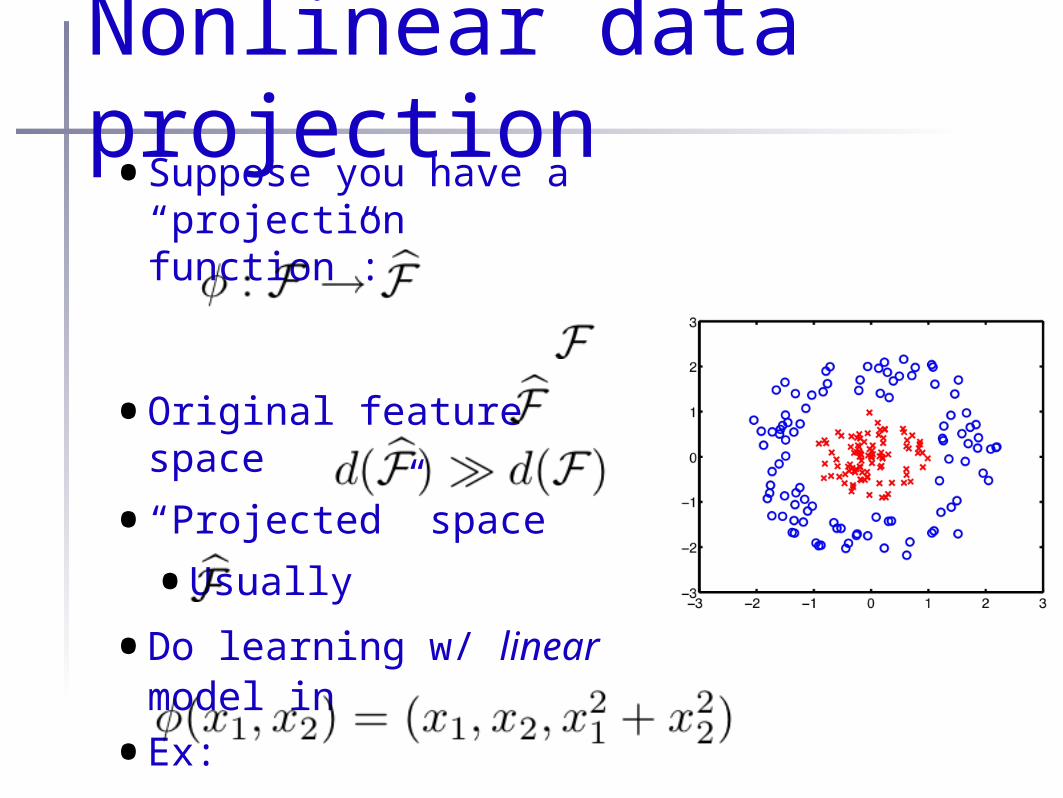
Nonlinear data projection•Suppose you have a
“projection function”:
•Original feature space
•“Projected” space
•Usually
•Do learning w/ linear model in
•Ex:

Common projections•Degree-k polynomials:
•Fourier expansions:
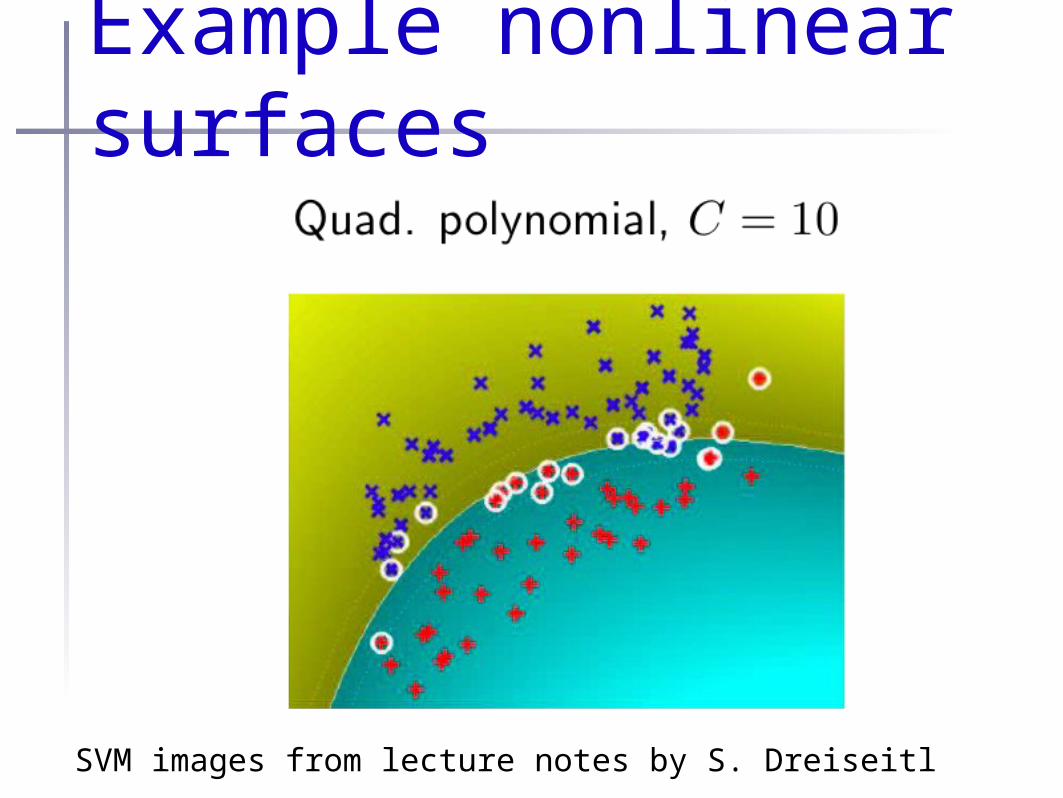
Example nonlinear surfaces
SVM images from lecture notes by S. Dreiseitl

Example nonlinear surfaces
SVM images from lecture notes by S. Dreiseitl

Example nonlinear surfaces
SVM images from lecture notes by S. Dreiseitl

Example nonlinear surfaces
Text
SVM images from lecture notes by S. Dreiseitl

The catch...•How many dimensions does have?
•For degree-k polynomial expansions:
•E.g., for k=4, d=256 (16x16 images),
•Yike!
•For “radial basis functions”,