lexical and syntax analysis chapter 4. compilation translating from high-level language to machine...
TRANSCRIPT

Lexical and Syntax Analysis
Chapter 4

Compilation
• Translating from high-level language to machine code is organized into several phases or passes.
• In the early days passes communicated through files, but this is no longer necessary.

Language Specification
• We must first describe the language in question by giving its specification.• Syntax:
• Defines symbols (vocabulary)• Defines programs (sentences)
• Semantics: • Gives meaning to sentences.
• The formal specifications are often the input to tools that build translators automatically.
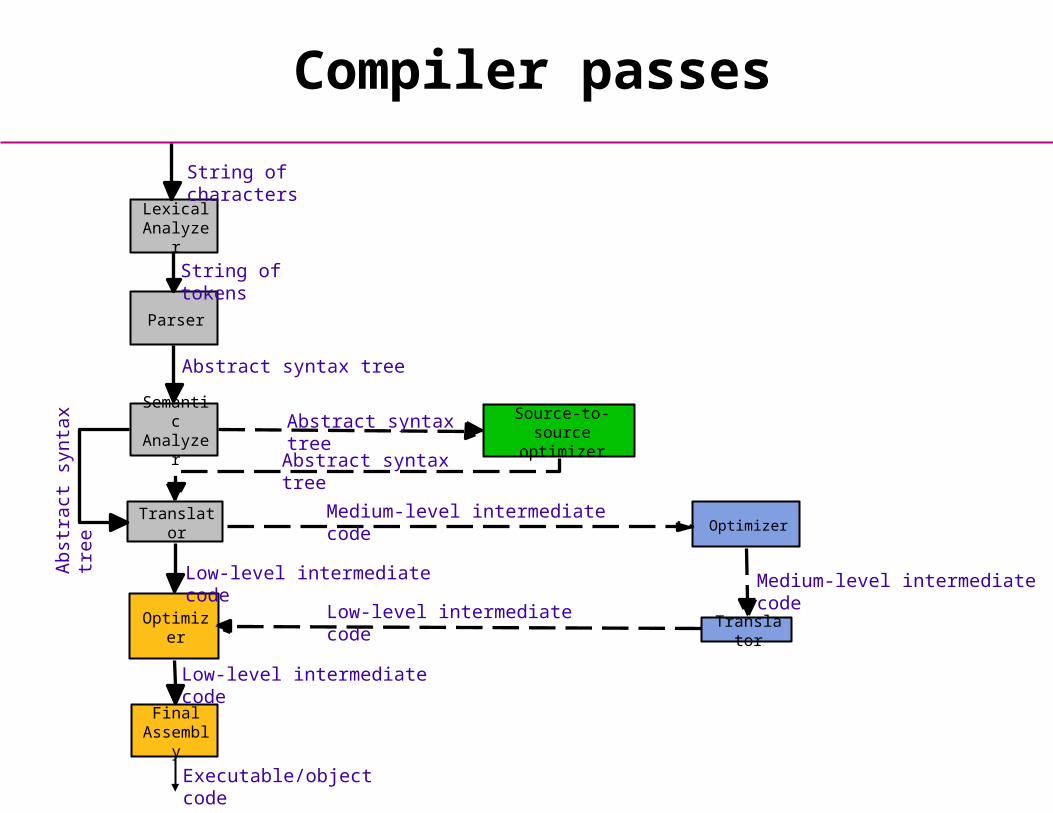
Compiler passes
Optimizer
Lexical Analyzer
Parser
Semantic Analyzer
Translator
Final Assembly
Optimizer
String of tokens
String of characters
Abstract syntax tree
Low-level intermediate code
Abstract syntax tree
Low-level intermediate code
Executable/object code
Translator
Medium-level intermediate code
Low-level intermediate code
Medium-level intermediate code
Source-to-sourceoptimizer
Abstract syntax tree
Abs
trac
t sy
ntax
tre
e
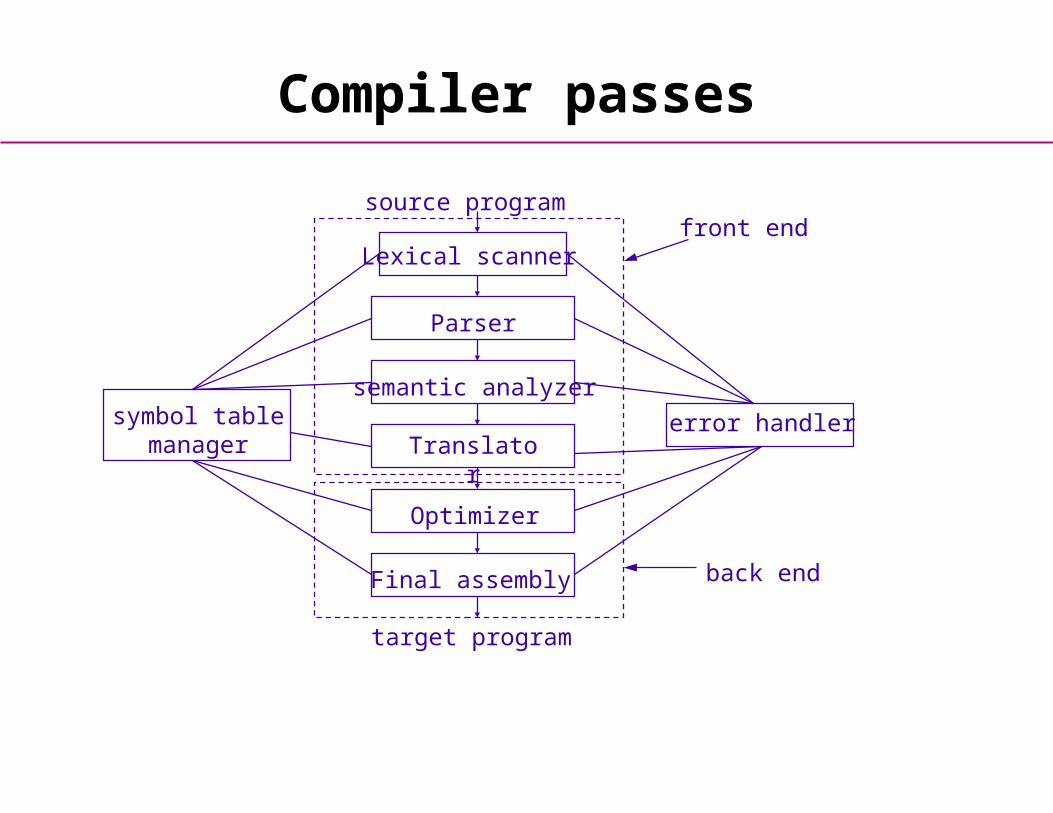
Compiler passes
Parser
semantic analyzer
Optimizer
Final assembly
Translatorsymbol table
managererror handler
target program
source programfront end
back end
Lexical scanner

Lexical analyzer
• Also called a scanner or tokenizer• Converts stream of characters into a stream of tokens
• Tokens are:• Keywords such as for, while, and class.• Special characters such as +, -, (, and <• Variable name occurrences• Constant occurrences such as 1, 0, true.

Comparison with Lexical Analysis
Phase Input Output
Lexer Sequence of characters
Sequence of tokens
Parser Sequence of tokens
Parse tree

Lexical analyzer
• The lexical analyzer is usually a subroutine of the parser.
• Each token is a single entity. A numerical code is usually assigned to each type of token.

• Lexical analyzers perform:• Line reconstruction
• delete comments• delete white spaces• perform text substitution
• Lexical translation: translation of lexemes -> tokens• Often additional information is affiliated with a
token.
Lexical analyzer

Parser
• Performs syntax analysis• Imposes syntactic structure on a sentence.• Parse trees are used to expose the structure.
• These trees are often not explicitly built• Simpler representations of them are often used
• Parsers, accepts a string of tokens and builds a parse tree representing the program

Parser
• The collection of all the programs in a given language is usually specified using a list of rules known as a context free grammar.

A grammar has four components: A set of tokens known as terminal symbols A set of variables or non-terminals A set of productions where each production
consists of a non-terminal, an arrow, and a sequence of tokens and/or non-terminals
A designation of one of the nonterminals as the start symbol.
Parser

Symbol Table Management
• The symbol table is a data structure used by all phases of the compiler to keep track of user defined symbols and keywords.
• During early phases (lexical and syntax analysis) symbols are discovered and put into the symbol table
• During later phases symbols are looked up to validate their usage.

Symbol Table Management
• Typical symbol table activities:
• add a new name• add information for a name• access information for a name• determine if a name is present in the table• remove a name• revert to a previous usage for a name (close a
scope).

Symbol Table Management
• Many possible Implementations:
• linear list• sorted list• hash table• tree structure

Symbol Table Management
• Typical information fields:• print value• kind (e.g. reserved, typeid, varid, funcid, etc.)• block number/level number• type• initial value• base address• etc.

Abstract Syntax Tree
• The parse tree is used to recognize the components of the program and to check that the syntax is correct.
• As the parser applies productions, it usually generates the component of a simpler tree (known as Abstract Syntax Tree).
• The meaning of the component is derived out of the way the statement is organized in a subtree.

Semantic Analyzer
• The semantic analyzer completes the symbol table with information on the characteristics of each identifier.
• The symbol table is usually initialized during parsing.
• One entry is created for each identifier and constant.• Scope is taken into account. Two different variables with
the same name will have different entries in the symbol table.
• The semantic analyzer completes the table using information from declarations.

Semantic Analyzer
• The semantic analyzer does• Type checking• Flow of control checks• Uniqueness checks (identifiers, case labels, etc.)
• One objective is to identify semantic errors statically. For example:
• Undeclared identifiers• Unreachable statements • Identifiers used in the wrong context.• Methods called with the wrong number of
parameters or with parameters of the wrong type.

Semantic Analyzer
• Some semantic errors have to be detected at run time. The reason is that the information may not be available at compile time.
• Array subscript is out of bonds.• Variables are not initialized.• Divide by zero.

Error Management
• Errors can occur at all phases in the compiler
• Invalid input characters, syntax errors, semantic errors, etc.
• Good compilers will attempt to recover from errors and continue.

Translator
• The lexical scanner, parser, and semantic analyzer are collectively known as the front end of the compiler.
• The second part, or back end starts by generating low level code from the (possibly optimized) AST.

• Rather than generate code for a specific architecture, most compilers generate intermediate language
• Three address code is popular.• Really a flattened tree representation.• Simple.• Flexible (captures the essence of many target
architectures).• Can be interpreted.
Translator

• One way of performing intermediate code generation:
• Attach meaning to each node of the AST.• The meaning of the sentence = the “meaning”
attached to the root of the tree.
Translator

XIL
• An example of Medium level intermediate language is XIL. XIL is used by IBM to compile FORTRAN, C, C++, and Pascal for RS/6000.
• Compilers for Fortran 90 and C++ have been developed using XIL for other machines such as Intel 386, Sparc, and S/370.

Optimizers
• Intermediate code is examined and improved.• Can be simple:
• changing “a:=a+1” to “increment a”• changing “3*5” to “15”
• Can be complicated:• reorganizing data and data accesses for cache
efficiency
• Optimization can improve running time by orders of magnitude, often also decreasing program size.

Code Generation
• Generation of “real executable code” for a particular target machine.
• It is completed by the Final Assembly phase
• Final output can either be • assembly language for the target machine• object code ready for linking
• The “target machine” can be a virtual machine (such as the Java Virtual Machine, JVM), and the “real executable code” is “virtual code” (such as Java Bytecode).
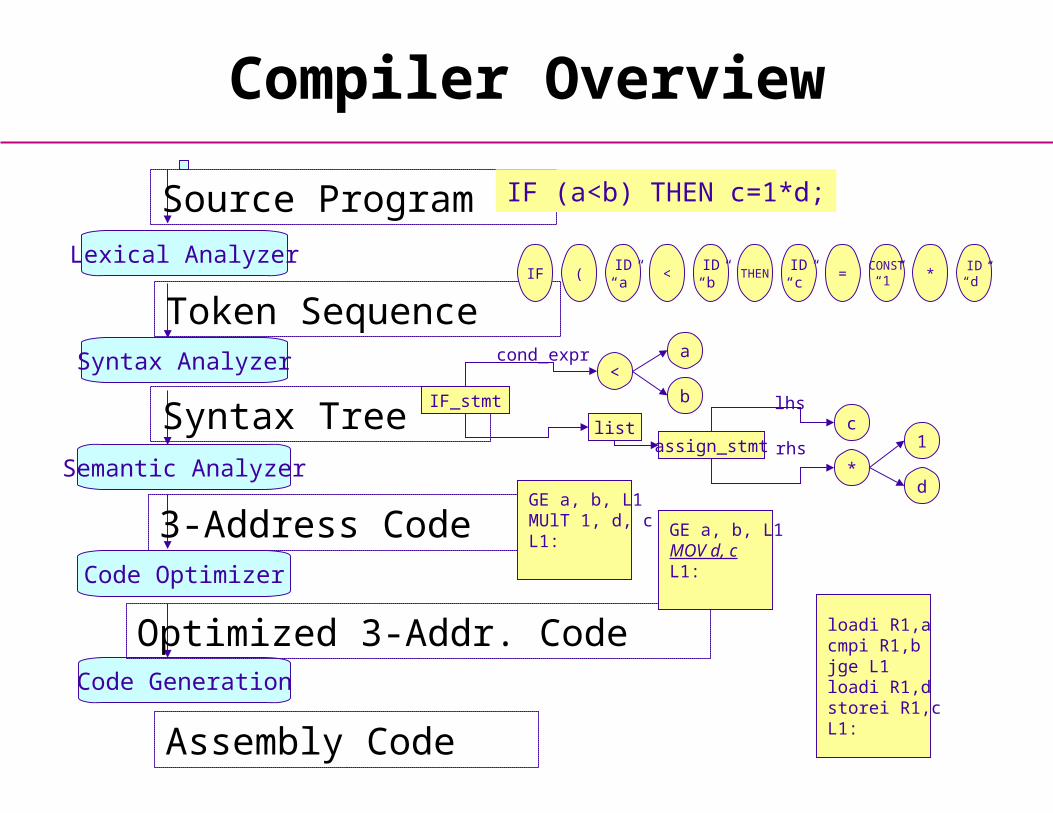
Compiler Overview
Lexical Analyzer
Syntax Analyzer
Semantic Analyzer
Code Optimizer
Code Generation
Source Program IF (a<b) THEN c=1*d;
Token Sequence
Syntax Tree
3-Address Code
Optimized 3-Addr. Code
Assembly Code
IF (ID“a”
<ID“b”
THENID“c”
=CONST
“1” *ID“d”
IF_stmt
<a
b
cond_expr
listassign_stmt
c
*
lhs
rhs 1
dGE a, b, L1MUlT 1, d, cL1:
GE a, b, L1MOV d, cL1:
loadi R1,acmpi R1,bjge L1loadi R1,dstorei R1,cL1:

Lexical Analysis

What is Lexical Analysis?
- The lexical analyzer deals with small-scale language constructs, such as names and numeric literals. The syntax analyzer deals with the large-scale constructs, such as expressions, statements, and program units.
- The syntax analysis portion consists of two parts:
1. A low-level part called a lexical analyzer (essentially a pattern matcher).
2. A high-level part called a syntax analyzer, or parser.
The lexical analyzer collects characters into logical groupings and assigns internal codes to the groupings according to their structure.
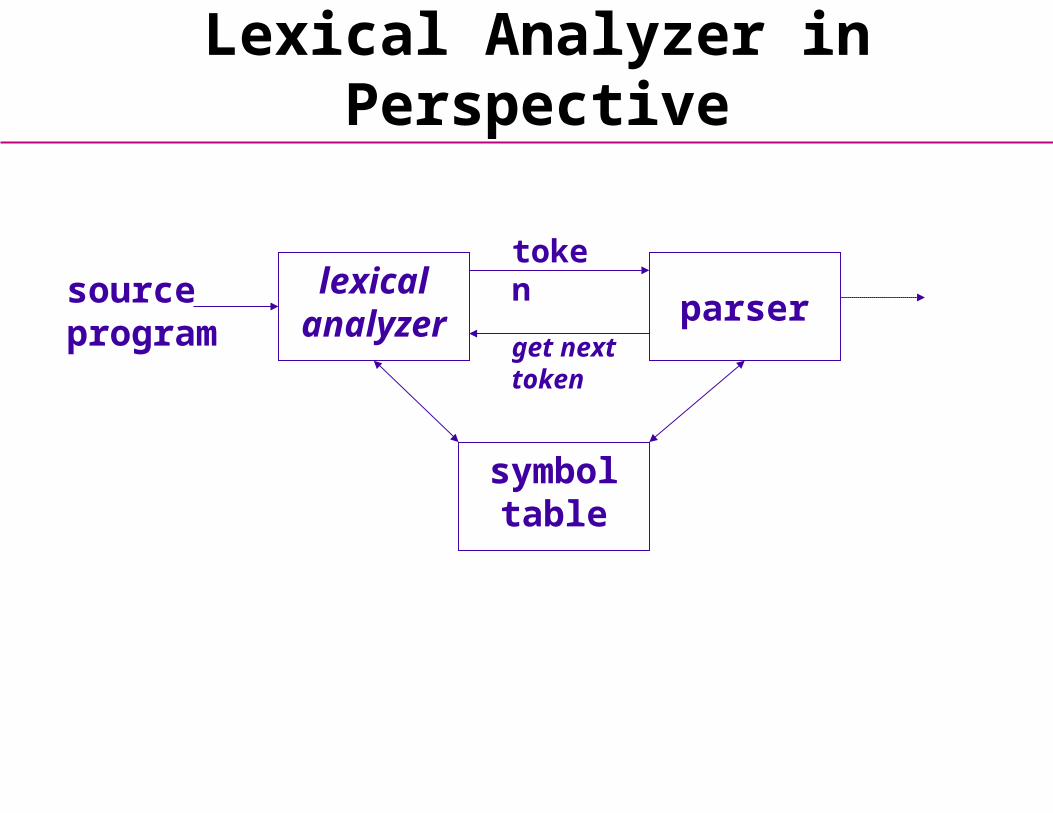
Lexical Analyzer in Perspective
lexical analyzer parser
symbol table
source program
token
get next token

Lexical Analyzer in Perspective
• LEXICAL ANALYZER
• Scan Input
• Remove white space, …
• Identify Tokens
• Create Symbol Table
• Insert Tokens into AST
• Generate Errors
• Send Tokens to Parser
• PARSER
• Perform Syntax Analysis
• Actions Dictated by Token Order
• Update Symbol Table Entries
• Create Abstract Rep. of Source
• Generate Errors

Lexical analyzers extract lexemes from a given input string and produce the corresponding tokens.
Sum = oldsum – value /100;
Token Lexeme
IDENT sum
ASSIGN_OP =
IDENT oldsum
SUBTRACT_OP -
IDENT value
DIVISION_OP /
INT_LIT 100
SEMICOLON ;

Basic Terminology
• What are Major Terms for Lexical Analysis?• TOKEN
• A classification for a common set of strings• Examples Include <Identifier>, <number>, etc.
• PATTERN• The rules which characterize the set of strings
for a token• LEXEME
• Actual sequence of characters that matches pattern and is classified by a token
• Identifiers: x, count, name, etc…

Basic Terminology
Token Sample Lexemes Informal Description of Pattern
const
if
relation
id
num
literal
const
if
<, <=, =, < >, >, >=
pi, count, D2
3.1416, 0, 6.02E23
“core dumped”
const
if
< or <= or = or < > or >= or >
letter followed by letters and digits
any numeric constant
any characters between “ and “ except “
Classifies Pattern
Actual values are critical. Info is :
1. Stored in symbol table2. Returned to parser

Token Definitions
Suppose: S ts the string banana
Prefix : ban, banana
Suffix : ana, banana
Substring : nan, ban, ana, banana
Subsequence: bnan, nn

letter A | B | C | … | Z | a | b | … | z
digit 0 | 1 | 2 | … | 9
id letter ( letter | digit )*
Shorthand Notation:
“+” : one or more r* = r+ | & r+ = r r*
“?” : zero or one r?=r | [range] : set range of characters (replaces “|” )
[A-Z] = A | B | C | … | Z
id [A-Za-z][A-Za-z0-9]*
Token Definitions

Token Recognition
Assume Following Tokens:
if, then, else, re-loop, id, num
What language construct are they used for ?
Given Tokens, What are Patterns ?
if if
then then
else else
Re-loop < | <= | > | >= | = | <>
id letter ( letter | digit )*
num digit + (. digit + ) ? ( E(+ | -) ? digit + ) ?
What does this represent ?
Grammar:stmt |if expr then stmt
|if expr then stmt else stmt|
expr term re-loop term | termterm id | num

What Else Does Lexical Analyzer Do?
Scan away b, nl, tabs
Can we Define Tokens For These?
blank b
tab ^T
newline ^M
delim blank | tab | newline
ws delim +

Symbol Tables
Regular Expression
Token Attribute-Value
ws
ifthenelse
idnum
<<==
< >>
>=
-
ifthenelseid
numreloprelop reloprelopreloprelop
-
---
pointer to table entrypointer to table entry
LTLEEQNEGTGE
Note: Each token has a unique token identifier to define category of lexemes

Building a Lexical Analyzer
There are three approaches to building a lexical analyzer:
1. Write a formal description of the token patterns of the language using a descriptive language. Tool on UNIX system called lex
2. Design a state transition diagram that describes the token patterns of the language and write a program that implements the diagram.
3. Design a state transition diagram and hand-construct a table-driven implementation of the state diagram.

Diagrams for Tokens
• Transition Diagrams (TD) are used to represent the tokens
• Each Transition Diagram has:
• States : Represented by Circles
• Actions : Represented by Arrows between states
• Start State : Beginning of a pattern (Arrowhead)
• Final State(s) : End of pattern (Concentric Circles)
• Deterministic - No need to choose between 2 different actions
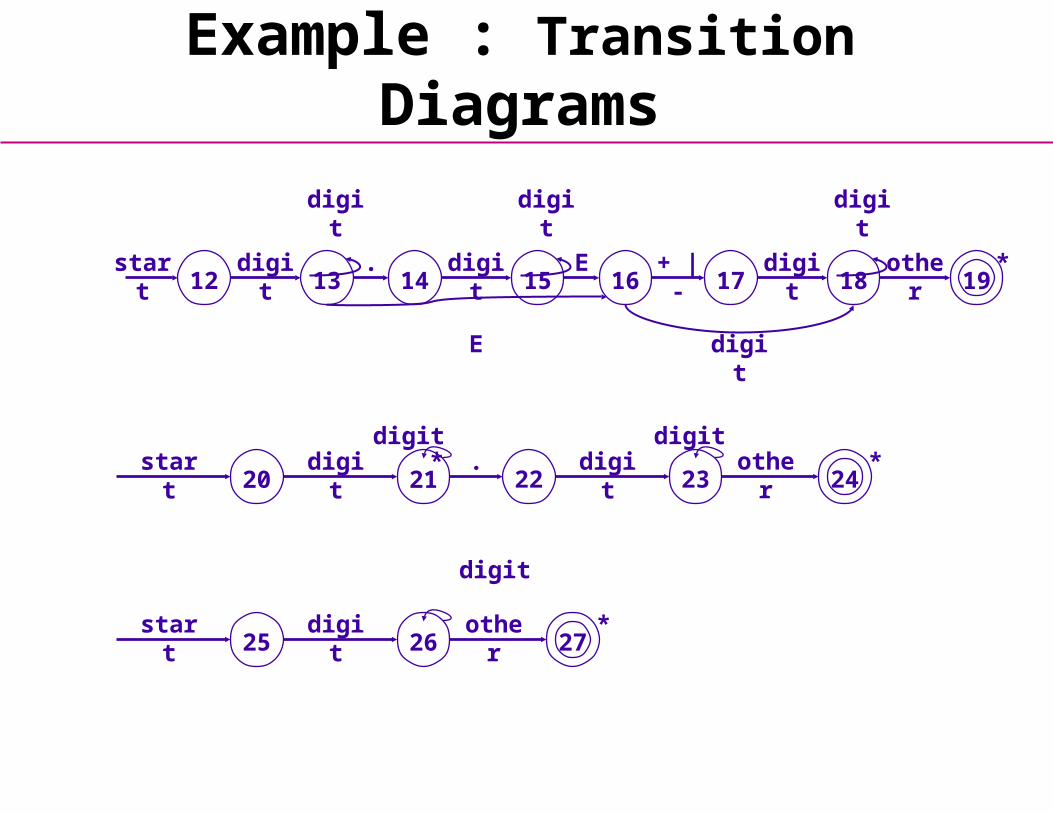
1912 1413 1615 1817start otherdigit . digit E + | - digit
digit
digit
digit
E
digit
*
start digit25
other2726
digit
*
start digit20
* .21
digit
24other
23
digit
digit22
*
Example : Transition Diagrams

State diagram to recognize names, reserved words, and integer literals

Reasons to use BNF to Describe Syntax
Provides a clear syntax description The parser can be based directly on the BNF
Parsers based on BNF are easy to maintain

Reasons to Separate Lexical and Syntax Analysis
Simplicity - less complex approaches can be used for lexical analysis; separating them simplifies the parser
Efficiency - separation allows optimization of the lexical analyzer
Portability - parts of the lexical analyzer may not be portable, but the parser always is portable

Summary of Lexical Analysis
• A lexical analyzer is a pattern matcher for character strings
• A lexical analyzer is a “front-end” for the parser
• Identifies substrings of the source program that belong together - lexemes
• Lexemes match a character pattern, which is associated with a lexical category called a token
- sum is a lexeme; its token may be IDENT

Semantic AnalysisIntro to Type Checking

The Compiler So Far
• Lexical analysis• Detects inputs with illegal tokens
• Parsing• Detects inputs with ill-formed parse trees
• Semantic analysis• The last “front end” phase• Catches more errors

What’s Wrong?
• Example 1
int in x;
• Example 2
int i = 12.34;

Why a Separate Semantic Analysis?
• Parsing cannot catch some errors
• Some language constructs are not context-free
• Example: All used variables must have been declared (i.e. scoping)
• Example: A method must be invoked with arguments of proper type (i.e. typing)

What Does Semantic Analysis Do?
• Checks of many kinds:
1. All identifiers are declared2. Types 3. Inheritance relationships4. Classes defined only once5. Methods in a class defined only once6. Reserved identifiers are not misusedAnd others . . .
• The requirements depend on the language

Scope
• Matching identifier declarations with uses
• Important semantic analysis step in most languages

Scope (Cont.)
• The scope of an identifier is the portion of a program in which that identifier is accessible
• The same identifier may refer to different things in different parts of the program• Different scopes for same name don’t overlap
• An identifier may have restricted scope

Static vs. Dynamic Scope
• Most languages have static scope• Scope depends only on the program text, not run-
time behavior• C has static scope
• A few languages are dynamically scoped• Lisp, COBOL• Current Lisp has changed to mostly static scoping• Scope depends on execution of the program

Class Definitions
• Class names can be used before being defined• We can’t check this property
• using a symbol table• or even in one pass
• Solution• Pass 1: Gather all class names• Pass 2: Do the checking
• Semantic analysis requires multiple passes• Probably more than two

Types
• What is a type?• The notion varies from language to language
• Consensus• A set of values• A set of operations on those values
• Classes are one instantiation of the modern notion of type

Why Do We Need Type Systems?
Consider the assembly language fragment
addi $r1, $r2, $r3
What are the types of $r1, $r2, $r3?

Types and Operations
• Certain operations are legal for values of each type
• It doesn’t make sense to add a function pointer and an integer in C
• It does make sense to add two integers
• But both have the same assembly language implementation!

Type Systems
• A language’s type system specifies which operations are valid for which types
• The goal of type checking is to ensure that operations are used with the correct types• Enforces intended interpretation of values, because
nothing else will!
• Type systems provide a concise formalization of the semantic checking rules

What Can Types do For Us?
• Can detect certain kinds of errors
• Memory errors:• Reading from an invalid pointer, etc.
• Violation of abstraction boundaries:
class FileSystem {
open(x : String) : File {
…
}
…
}
class Client { f(fs : FileSystem) { File fdesc <- fs.open(“foo”) … } -- f cannot see inside fdesc !}

Type Checking Overview
• Three kinds of languages:
• Statically typed: All or almost all checking of types is done as part of compilation (C and Java)
• Dynamically typed: Almost all checking of types is done as part of program execution (Scheme)
• Untyped: No type checking (machine code)

The Type Wars
• Competing views on static vs. dynamic typing• Static typing proponents say:
• Static checking catches many programming errors at compile time
• Avoids overhead of runtime type checks
• Dynamic typing proponents say:• Static type systems are restrictive• Rapid prototyping easier in a dynamic type system

The Type Wars (Cont.)
• In practice, most code is written in statically typed languages with an “escape” mechanism• Unsafe casts in C, Java
• It’s debatable whether this compromise represents the best or worst of both worlds

Type Checking and Type Inference
• Type Checking is the process of verifying fully typed programs
• Type Inference is the process of filling in missing type information
• The two are different, but are often used interchangeably

Rules of Inference
• We have seen two examples of formal notation specifying parts of a compiler
• Regular expressions (for the lexer)• Context-free grammars (for the parser)
• The appropriate formalism for type checking is logical rules of inference

Why Rules of Inference?
• Inference rules have the formIf Hypothesis is true, then Conclusion is true
• Type checking computes via reasoning
If E1 and E2 have certain types, then E3 has a certain type
• Rules of inference are a compact notation for “If-Then” statements

From English to an Inference Rule
• The notation is easy to read (with practice)
• Start with a simplified system and gradually add features
• Building blocks• Symbol is “and”• Symbol is “if-then”• x:T is “x has type T”

From English to an Inference Rule (2)
If e1 has type Int and e2 has type Int, then e1 + e2 has type Int
(e1 has type Int e2 has type Int) e1 + e2 has type Int
(e1: Int e2: Int) e1 + e2: Int

From English to an Inference Rule (3)
The statement
(e1: Int e2: Int) e1 + e2: Int
is a special case of
( Hypothesis1 . . . Hypothesisn ) Conclusion
This is an inference rule

Notation for Inference Rules
• By tradition inference rules are written
• Type rules can also have hypotheses and conclusions of the form:
` e : T• ` means “it is provable that . . .”
` Hypothesis1 … ` Hypothesisn
` Conclusion

Two Rules
i is an integer
` i : Int [Int]
` e1 : Int
` e2 : Int
` e1 + e2 : Int[Add]

Two Rules (Cont.)
• These rules give templates describing how to type integers and + expressions
• By filling in the templates, we can produce complete typings for expressions

Example: 1 + 2
1 is an integer 2 is an integer
` 1 : Int ` 2 : Int
` 1 + 2 : Int

Soundness
• A type system is sound if• Whenever ` e : T • Then e evaluates to a value of type T
• We only want sound rules• But some sound rules are better than others:
i is an integer
` i : Object

Type Checking Proofs
• Type checking proves facts e : T• Proof is on the structure of the AST• Proof has the shape of the AST• One type rule is used for each kind of AST node
• In the type rule used for a node e:• Hypotheses are the proofs of types of e’s sub-
expressions• Conclusion is the proof of type of e
• Types are computed in a bottom-up pass over the AST

Rules for Constants
` false : Bool [Bool]
s is a string constant
` s : String[String]

Two More Rules
` e : Bool
` not e : Bool [Not]
` e1 : Bool
` e2 : T
` while e1 loop e2 pool : Object
[Loop]

A Problem
• What is the type of a variable reference?
• The local, structural rule does not carry enough information to give x a type.
x is an identifier
` x : ? [Var]

Notes
• The type environment gives types to the free identifiers in the current scope
• The type environment is passed down the AST from the root towards the leaves
• Types are computed up the AST from the leaves towards the root

Expressiveness of Static Type Systems
• A static type system enables a compiler to detect many common programming errors
• The cost is that some correct programs are disallowed• Some argue for dynamic type checking instead• Others argue for more expressive static type
checking
• But more expressive type systems are also more complex

Dynamic And Static Types
• The dynamic type of an object is the class C that is used in the “new C” expression that creates the object• A run-time notion• Even languages that are not statically typed have the
notion of dynamic type
• The static type of an expression is a notation that captures all possible dynamic types the expression could take• A compile-time notion

• The typing rules use very concise notation• They are very carefully constructed• Virtually any change in a rule either:
• Makes the type system unsound (bad programs are accepted as well typed)
• Or, makes the type system less usable(perfectly good programs are rejected)
• But some good programs will be rejected anyway • The notion of a good program is undecidable
Dynamic And Static Types

Type Systems
• Type rules are defined on the structure of expressions
• Types of variables are modeled by an environment
• Types are a play between flexibility and safety

End of Lecture 6