legodb customizing relational storage for xml documents timothy sutherland sachin patidar
Post on 21-Dec-2015
227 views
TRANSCRIPT

LegoDB
Customizing Relational Storage for XML Documents
Timothy SutherlandSachin Patidar

Managing XML Data
XML has become widely used for exchange of data over the Web
XML is extensible and flexible: it can be used in applications
with widely different requirements There is no one-size-fits-all solution for all applications What are procedures to store, query and publish XML data?
Need adaptable and flexible solutions LegoDB is a component-based XML data management
systemThe database-anywhere paradigm: portable and adaptable to any data and any environment

Motivation & challenge’s
Motivation:
reuse of well developed features
concurrency control crash recovery query processors
wide variety of XML applications
Integrate with existing data stored in an RDBMS
Challenges:
mismatch between nested tree structure and flat tuples of the relational model
Inducing the flexibility to handle the wide domain of application
But storing and querying XML data in an RDBMS is a non-trivial task

Mapping XML schema to relationsQuestion ? Can different XML schemas validate the
exact same set of documents? Yes Different but equivalent regular expression
can describe the contents of a given element.(a(b|c*)) ((a,b) |(a,c*))
Sub-elements of an element can be referred to directly, or can be referred to by a type name

Sample XML Dataset:Internet Movie Database
<imdb><show type=“movie”><title>Fugitive, The</title><year>1993</year><review><suntimes><reviewer>Roger Ebert</reviewer><rating>Two thumbs up!</rating><comment> This is a fun action movie,Harrison Ford at his best.</comment></suntimes></review><review><nyt> The standard Hollywood summermovie strikes back.</nyt></review><box_office>183,752,965</box_office></show>
<show type=“TV series”><title>X Files,The</title><year>1994</year><seasons> 4 </seasons><episode><name>Fallen Angel</name><guest_director>Larry Shaw</guest_director></episode></show> </imdb>

DTD and XML Schema

Question ?
Can you find more storage mapping relations?
By performing a sequence of transformations (i.e. rewritings) which preserve the semantics of the schema.

Mapping XML Schema into tables
Inline as manyelements as possible
Partition reviews tableone for NYTimes, and one for rest
Split show table Into TV and Movies

Querying XML
Presence of schema for XML documents For applications to interpret data For issuing queries
Find the title, year and box office proceedsFor all 2001 movies
For $v in document (“imbdata”)/imbd/showWhere $v/year=2001Return $v/title, $v/year, $v/box_office

XML and Relational Databases
There is a mismatch between the relational model andthat of XML
Relational: Normalized, flat and fragmented XML: Un-normalized, nested and monolithic How to store XML data into relational tables?
– Need to map the nested and irregular XML data into flat andregular tables
How to evaluate XML queries over relational tables? – Need to map XQuery into SQL

Problem: Storing XML in RDMS
Taken from Juliana Freire’s presentation

Queries
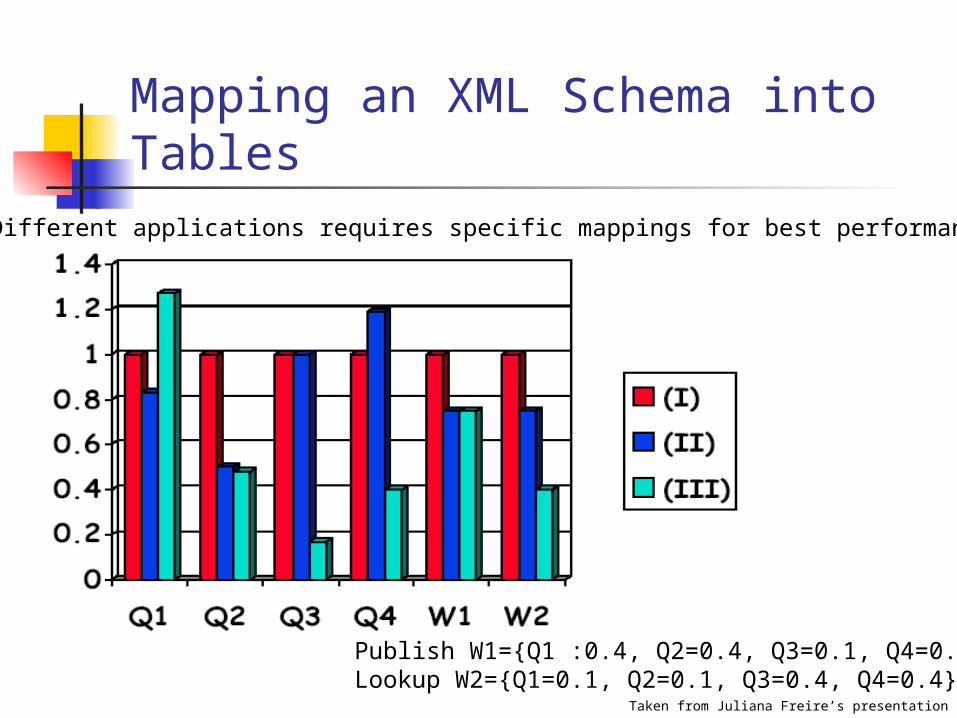
Mapping an XML Schema into Tables
Different applications requires specific mappings for best performance
Publish W1={Q1 :0.4, Q2=0.4, Q3=0.1, Q4=0.1}Lookup W2={Q1=0.1, Q2=0.1, Q3=0.4, Q4=0.4}
Taken from Juliana Freire’s presentation

The LegoDB Storage Mapping Engine
An optimization approach:
automatically explores a space of possible mappings selects the mapping which has the lowest cost for a given
application Basic Principles:
Application-driven: takes into account schema, data statistics and query workload
Logical/physical independence: interface is XML-based ( XMLSchema, XQuery, XML data statistics)
Leverage existing technology: XML standards; XML-specificoperations for generating space of mappings; relational optimizer for evaluating configurations

LegoDB
Create a p-schema for input XML schema Obtain cost estimates with input of data
statistics and XQuery workload. Search space of alternative storage
configurations to achieved an efficient mapping for a given application.

Architecture of the Mapping Engine
Cost (SQi)
RSi : Relational Schema/Queries/Stats
PSi: Physical Schema

XML Schema to Relations How to transform a XML schema to
a relation? P-Schema
Type Show = show [ @type [String<#8,#2>],
year [Integer<#4,#1800,#2100,#300>], title [String<#50,#34798.], Review*<#10>]
Type Review =review [ String<#800> ]

XML Schema to Relations For a type T and relation R R1- Create one relation R for each T. R2- Create a key for each T R3- Create a foreign key for all parents of
T R4- Create columns for R for every
physical type in T R5- Allow null values in R for every
optional type in T

XML Schema to Relations
Type Show = show [ @type [String<#8,#2>],
year [Integer<#4,#1800,#2100,#300>],
title [String<#50,#34798.],
Review*<#10>]
Type Review =review [ String<#800> ]
Show
Show_IDTypeYearTitle
ReviewReview_IDReviewTo_Show_Key (FK)

Types of XML Transformations Inlining/Outlining Union Factorization/Distribution Repetition Merge/Split Wildcard Rewritings

Inlining/Outlining Attributes can be “outlined” by removing
them from a relation and using a foreign key to relate them to a table.
Inlining is the exact opposite.
Type TV = seasons[Integer],Description,Episode*
Type Description = description[String]
Type TV = seasons[Integer]description[String]Episode*

Union Factorization/Distribution ((a,(b|c)) == (a,b|a,c)) (a[t1|t2] == a[t1]|a[t2])
Type Show = show [ @type [String],
title[String],year[Integer],(Movie|TV) ]
Type Movie = box_office[Integer],video_sales[Int],
Type TV = seasons[Integer],description[String],Episode*
Type Show = show[ (@type[String],
title[String],year[Integer],box_office[Integer],video_sales[Integer])
| (@type[String],title[String],year[Integer],seasons[Integer],description[String],Episode*) ]

Repetition Merge/Split (a+ == a,a* == a,a*,a*) …etc
Type Show = show [ @type [String],
title[String],year[Integer],Aka{1,*}]
Type Show = show [ @type [String],
title[String],year[Integer],Aka,Aka{0,*} ]

Wildcard Rewritings We might want to access specific
elements in a wildcard, such as NYTReview
Type Review =review[~[String]*]
Type Reviews = review[ (NYTReview | OtherReview)*]
Type NYTReview = nyt[String]
Type OtherReview =(~!nyt)[String]

Finding the best pSchema Use a Greedy Search Search until a “good” result is found
1. Get Initial/Current Schema 2. Get schema cost 3. Apply transformations to the schema 4. Select the best schema cost from the
transformations 5. If the cost is better than the current schema,
continue the search, mark this schema as the current schema. Otherwise stop searching.
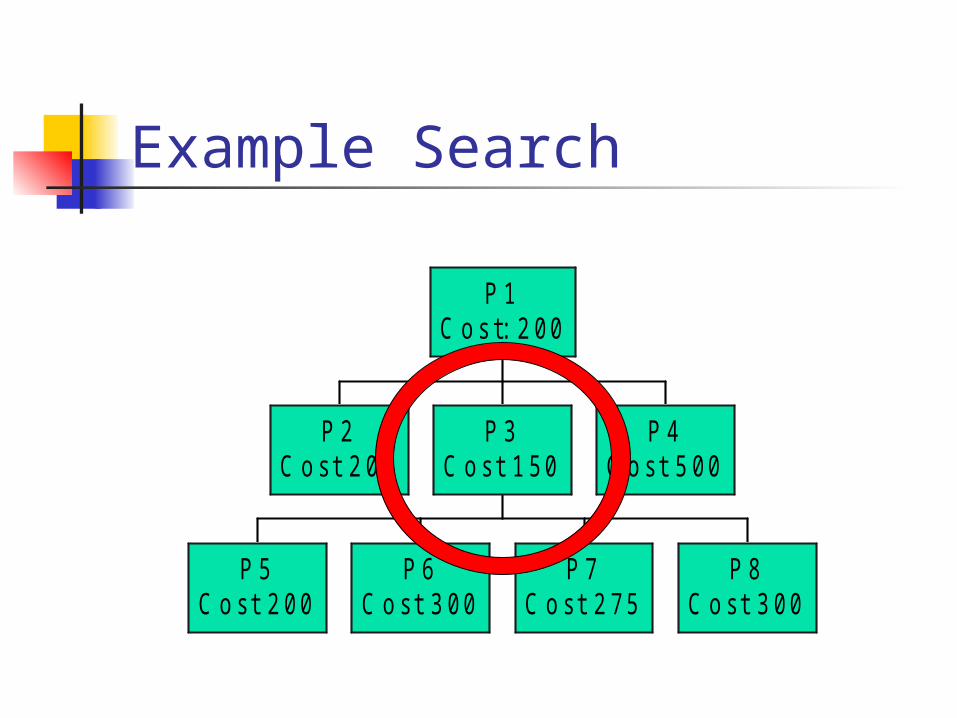
Example Search
P 2C o st 2 00
P 5C o st 2 00
P 6C o st 3 00
P 7C o st 2 75
P 8C o st 3 00
P 3C o st 1 50
P 4C o st 5 00
P 1C o s t: 2 00

Problem? With the way that this algorithm is
set up can you find a major oversight?
Remember how the relational data is created: Sample XML Data Sample XML Queries

Problem… A problem can be that the relative
number of each query type is not taken into consideration.
For example, what will happen if 90% of queries are to gather a review for a website, while that is only 1 of 25 queries in the system. Query distribution is not uniform!

Problem...Solved…Kind Of... If we take into account the frequency of a query…

Related Work STORED- Storing Semistructured
Data SilkRoute- Converting Relational
Data to XML StatiX- XML Schema statistics
framework

Conclusions LegoDB is an excellent way to take Cost
of a query into account when transforming an XML document to the relational model
Although LegoDB does an excellent job of transforming XML compared to static models, more work can be done on how to analyze how the frequency of queries affect the cost of the relational model.