lecture: parallel architecture –thread level … · lecture: parallel architecture –thread...
TRANSCRIPT

Lecture:ParallelArchitecture– ThreadLevelParallelismandDataLevelParallelism
1
CSCE569ParallelComputing
DepartmentofComputerScienceandEngineeringYonghong Yan
[email protected]://cse.sc.edu/~yanyh

Topics
• Introduction• Programmingonsharedmemorysystem(Chapter7)– OpenMP• Principlesofparallelalgorithmdesign(Chapter3)• Programmingonlargescalesystems(Chapter6)– MPI(pointtopointandcollectives)– IntroductiontoPGASlanguages,UPCandChapel• Analysisofparallelprogramexecutions(Chapter5)– PerformanceMetricsforParallelSystems• ExecutionTime,Overhead,Speedup,Efficiency,Cost
– ScalabilityofParallelSystems– Useofperformancetools
2

Topics
• Programmingonsharedmemorysystem(Chapter7)– Cilk/Cilkplus andOpenMP Tasking– PThread,mutualexclusion,locks,synchronizations• Parallelarchitecturesandmemory– Parallelcomputerarchitectures• ThreadLevelParallelism• DataLevelParallelism• Synchronization
– Memoryhierarchyandcachecoherency• Manycore GPUarchitecturesandprogramming– GPUsarchitectures– CUDAprogramming– IntroductiontooffloadingmodelinOpenMP
3

Lecture:ParallelArchitecture–ThreadLevelParallelism
4
Note:• Parallelisminhardware• Not(just)multi-/many-corearchitecture

BinaryCodeandInstructions
5
• Compileaprogramusing-save-tempsflagstoseethebinarycodeordisassemblyabinarycodeusingobjdump -D
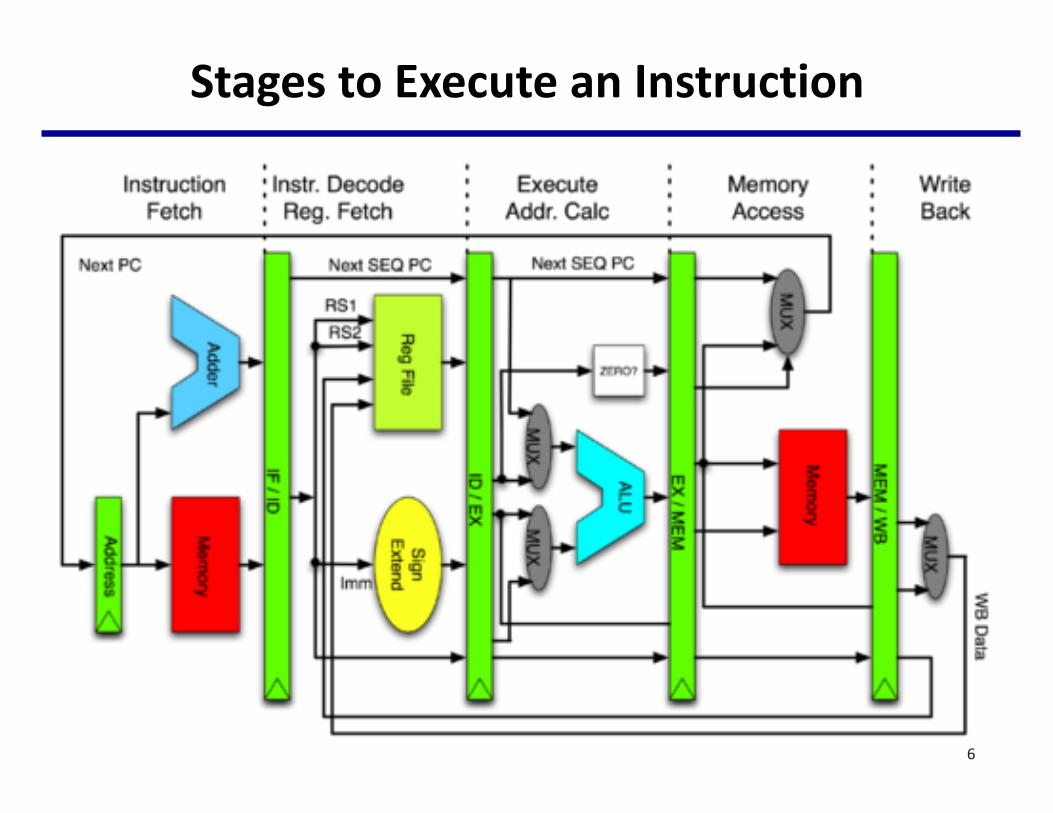
StagestoExecuteanInstruction
6
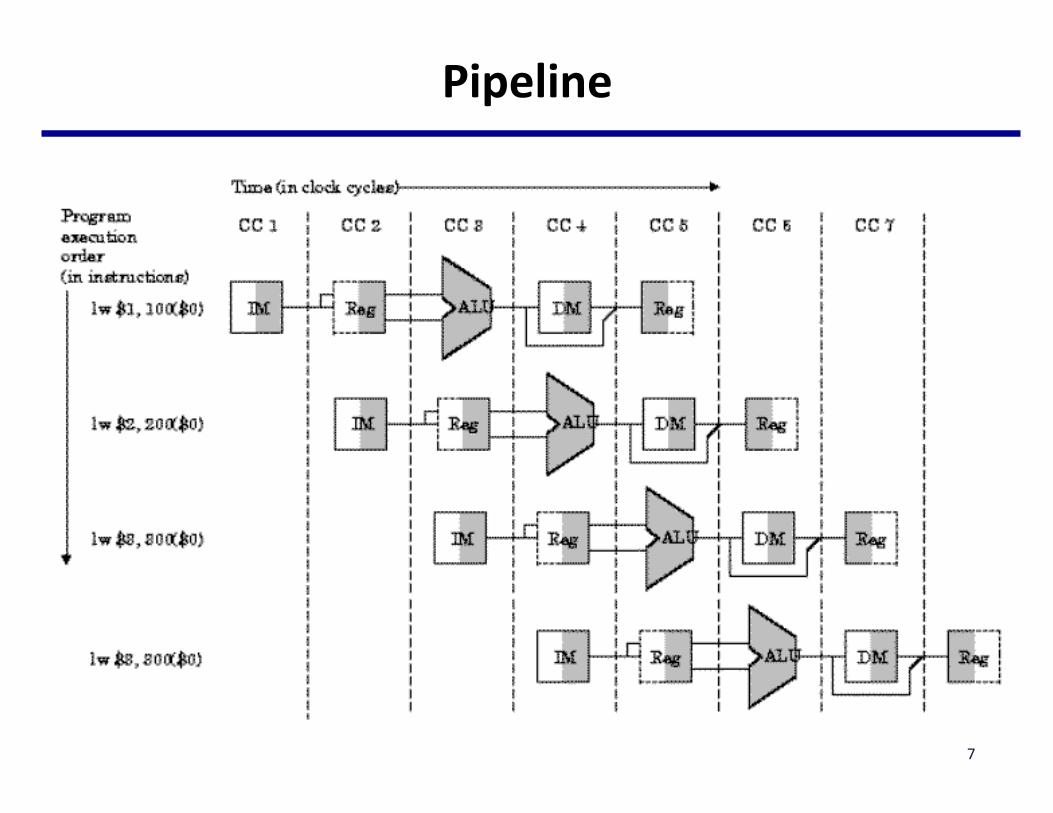
Pipeline
7
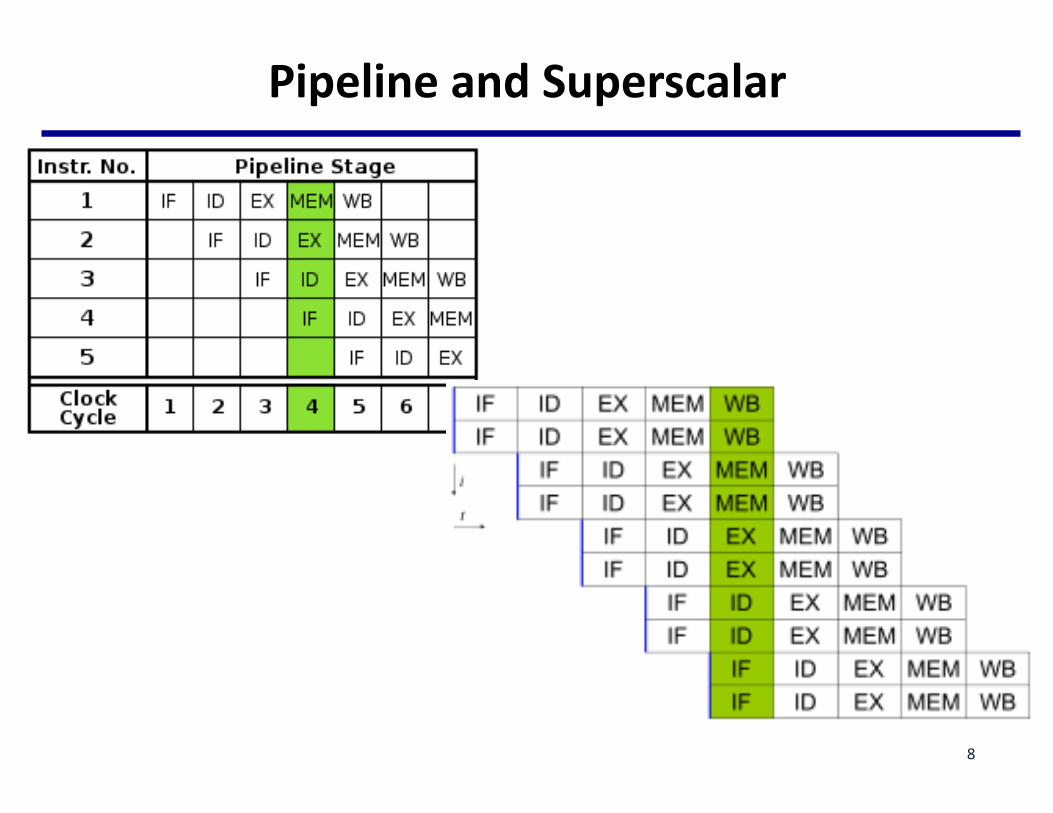
PipelineandSuperscalar
8

Whatdowedowiththatmanytransistors?
• Optimizingtheexecutionofasingleinstructionstreamthrough– Pipelining• Overlaptheexecutionofmultipleinstructions• Example:allRISCarchitectures;Intelx86underneaththehood
– Out-of-orderexecution:• Allowinstructionstoovertakeeachotherinaccordancewithcodedependencies(RAW,WAW,WAR)• Example:allcommercialprocessors(Intel,AMD,IBM,SUN)
– Branchpredictionandspeculativeexecution:• Reducethenumberofstallcyclesduetounresolvedbranches• Example:(nearly)allcommercialprocessors

Whatdowedowiththatmanytransistors?(II)
– Multi-issueprocessors:• Allowmultipleinstructionstostartexecutionperclockcycle• Superscalar(Intelx86,AMD,…)vs.VLIWarchitectures
– VLIW/EPICarchitectures:• Allowcompilerstoindicateindependentinstructionsperissuepacket• Example:IntelItanium
– Vectorunits:• Allowfortheefficientexpressionandexecutionofvectoroperations• Example:SSE- SSE4,AVXinstructions

Limitationsofoptimizingasingleinstructionstream(II)
• Problem:withinasingleinstructionstreamwedonotfindenoughindependentinstructionstoexecutesimultaneouslydueto– datadependencies– limitationsofspeculativeexecutionacrossmultiplebranches– difficultiestodetectmemorydependenciesamonginstruction
(aliasanalysis)• Consequence:significantnumberoffunctionalunitsareidlingat
anygiventime• Question:Canwemaybeexecuteinstructionsfromanother
instructionsstream– Anotherthread?– Anotherprocess?
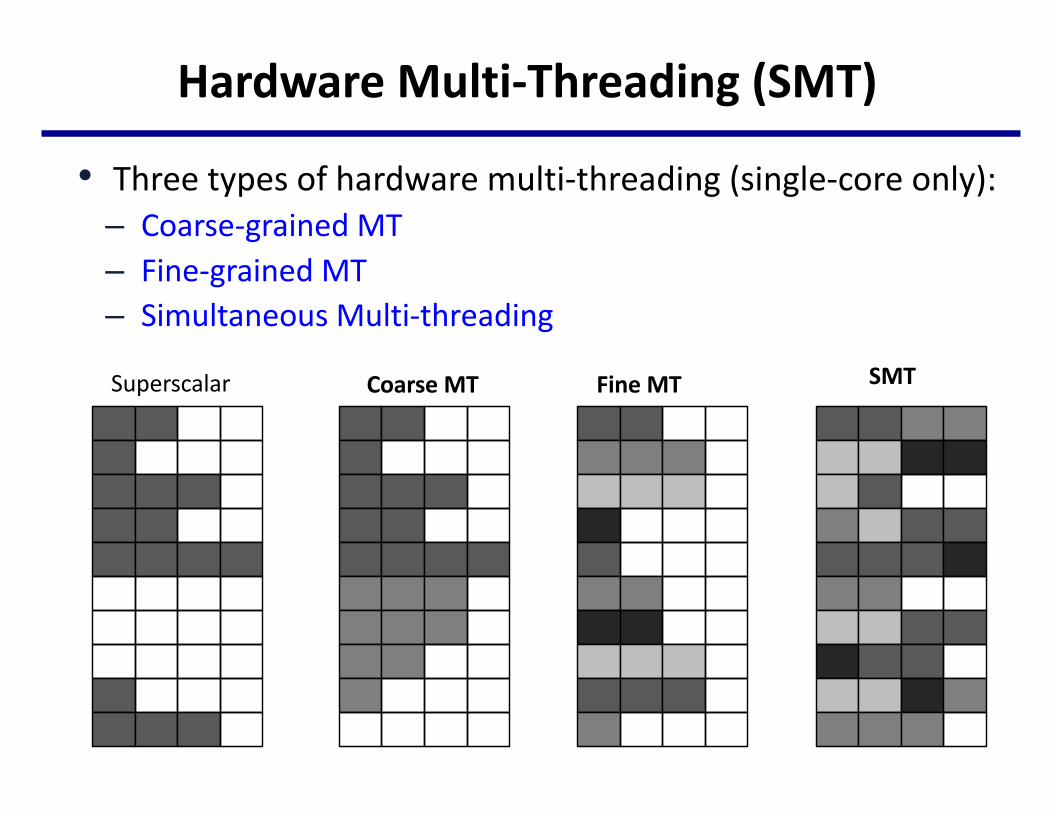
HardwareMulti-Threading(SMT)
• Threetypesofhardwaremulti-threading(single-coreonly):– Coarse-grainedMT– Fine-grainedMT– SimultaneousMulti-threading
Superscalar CoarseMT FineMT SMT

Thread-levelparallelism
• Problemsforexecutinginstructionsfrommultiplethreadsatthesametime– Theinstructionsineachthreadmightusethesameregister
names– Eachthreadhasitsownprogramcounter• Virtualmemorymanagementallowsfortheexecutionofmultiplethreadsandsharingofthemainmemory
• Whentoswitchbetweendifferentthreads:– Finegrainmultithreading:switchesbetweeneveryinstruction– Coursegrainmultithreading:switchesonlyoncostlystalls(e.g.
level2cachemisses)

SimultaneousMulti-threading
• ConvertThread-levelparallelismtoinstruction-levelparallelism
• DynamicallyscheduledprocessorsalreadyhavemosthardwaremechanismsinplacetosupportSMT(e.g.registerrenaming)
• Requiredadditionalhardware:– Registerfileperthread– Programcounterperthread• Operatingsystemview:– IfaCPUsupportsn simultaneousthreads,theOperating
Systemviewsthemasn processors– OSdistributesmosttimeconsumingthreads‘fairly’acrossthe
n processorsthatitsees.

ExampleforSMTarchitectures(I)
• IntelHyperthreading:– FirstreleasedforIntelXeonprocessorfamilyin2002– SupportstwoarchitecturalsetsperCPU,– Eacharchitecturalsethasitsown• Generalpurposeregisters• Controlregisters• Interruptcontrolregisters• Machinestateregisters
– Addslessthan5%totherelativechipsizeReference:D.T.Marret.al.“Hyper-ThreadingTechnologyArchitectureandMicroarchitecture”,IntelTechnologyJournal,6(1),2002,pp.4-15.ftp://download.intel.com/technology/itj/2002/volume06issue01/vol6iss1_hyper_threading_technology.pdf

ExampleforSMTarchitectures(II)
• IBMPower5– SamepipelineasIBMPower4processorbutwithSMTsupport– Furtherimprovements:• IncreaseassociativityoftheL1instructioncache• IncreasethesizeoftheL2andL3caches• Addseparateinstructionprefetch andbufferingunitsforeachSMT• Increasethesizeofissuequeues• Increasethenumberofvirtualregistersusedinternallybytheprocessor.

SimultaneousMulti-Threading
• Workswellif– Numberofcomputeintensivethreadsdoesnotexceedthenumberof
threadssupportedinSMT– Threadshavehighlydifferentcharacteristics(e.g.onethreaddoingmostly
integeroperations,anothermainlydoingfloatingpointoperations)• Doesnotworkwellif– Threadstrytoutilizethesamefunctionunits– Assignmentproblems:• e.g.adualprocessorsystem,eachprocessorsupporting2threadssimultaneously(OSthinksthereare4processors)
• 2computeintensiveapplicationprocessesmightenduponthesameprocessorinsteadofdifferentprocessors(OSdoesnotseethedifferencebetweenSMTandrealprocessors!)

Lecture:ParallelArchitecture--DataLevelParallelism
18

ClassificationofParallelArchitectures
Flynn’sTaxonomy• SISD:Singleinstructionsingledata– ClassicalvonNeumannarchitecture• SIMD:Singleinstructionmultipledata– Vector,GPU,etc• MISD:Multipleinstructionssingledata– Nonexistent,justlistedforcompleteness• MIMD:Multipleinstructionsmultipledata– Mostcommonandgeneralparallelmachine– Multi-/many- processors/cores/threads/computers
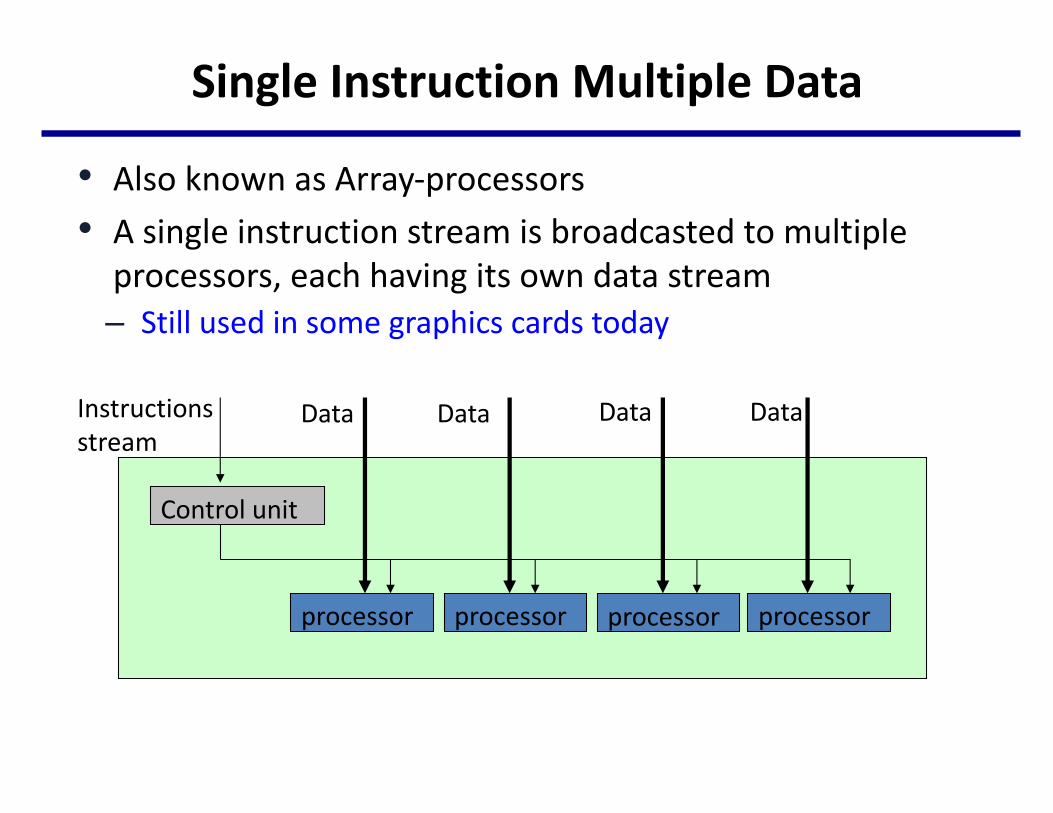
SingleInstructionMultipleData
• AlsoknownasArray-processors• Asingleinstructionstreamisbroadcastedtomultipleprocessors,eachhavingitsowndatastream– Stillusedinsomegraphicscardstoday
Instructionsstream
processor processor processor processor
Data Data Data Data
Controlunit

SIMDInReal
• Hardwarefordata-levelparallelism
• Threemajorimplementations– SIMDextensionstoconventionalCPU– Vectorarchitectures– GPUvariant
21
for (i=0; i<n; i++) {
a[i] = b[i] + c[i];
}

SIMDInstructions
• OriginallydevelopedforMultimediaapplications• Sameoperationexecutedformultipledataitems• Usesafixedlengthregisterandpartitionsthecarrychaintoallow
utilizingthesamefunctionalunitformultipleoperations– E.g.a64bitaddercanbeutilizedfortwo32-bitadd
operationssimultaneously• Instructionsoriginallynotintendedtobeusedbycompiler,butjustfor
handcraftingspecificoperationsindevicedrivers• Allelementsinaregisterhavetobeonthesamememorypageto
avoidpagefaultswithintheinstruction

IntelSIMDInstructions
• MMX(Mult-MediaExtension)- 1996– Existing64bitfloatingpointregistercouldbeusedforeight8-
bitoperationsorfour16-bitoperations• SSE(StreamingSIMDExtension)– 1999– SuccessortoMMXinstructions– Separate128-bitregistersaddedforsixteen8-bit,eight16-bit,
orfour32-bitoperations• SSE2– 2001,SSE3– 2004,SSE4- 2007– Addedsupportfordoubleprecisionoperations• AVX(AdvancedVectorExtensions)- 2010– 256-bitregistersadded

VectorProcessors
• Vectorprocessorsabstractoperationsonvectors,e.g.replacethefollowingloop
by
• Somelanguagesofferhigh-levelsupportfortheseoperations(e.g.Fortran90ornewer)
for (i=0; i<n; i++) {
a[i] = b[i] + c[i];
}
a = b + c; ADDV.D V10, V8, V6
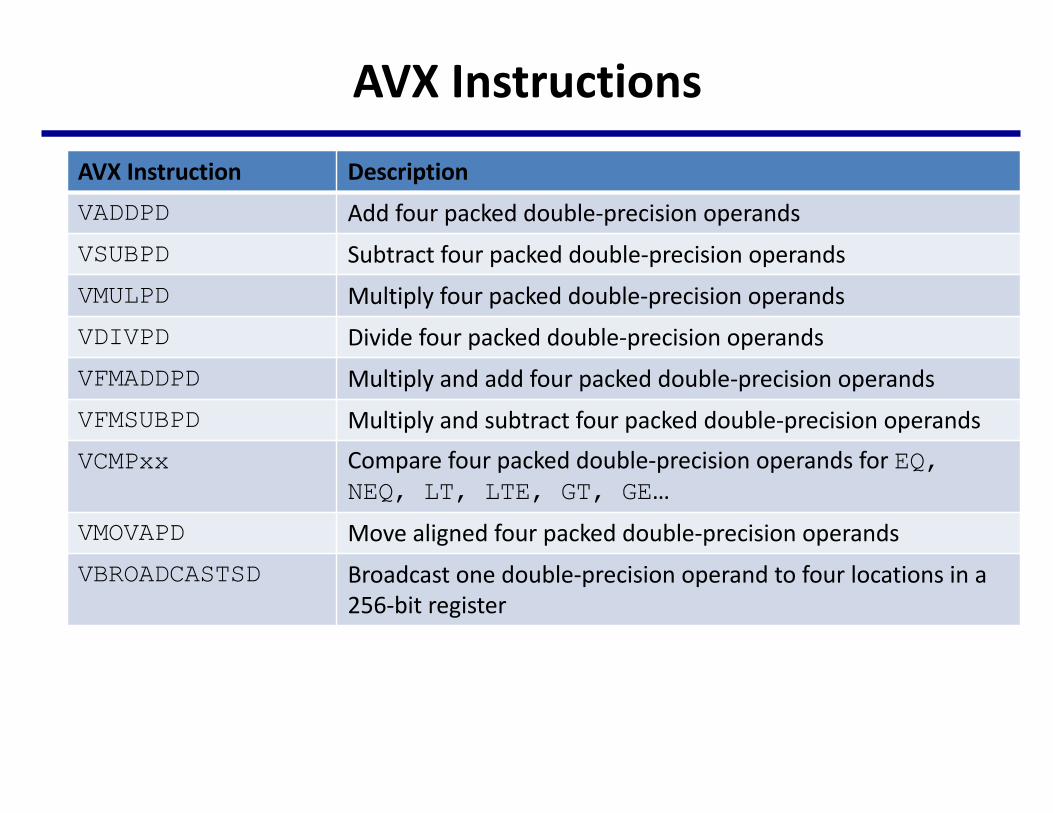
AVXInstructions
AVXInstruction DescriptionVADDPD Add fourpackeddouble-precisionoperandsVSUBPD Subtract fourpackeddouble-precisionoperandsVMULPD Multiplyfourpackeddouble-precisionoperandsVDIVPD Dividefourpackeddouble-precisionoperandsVFMADDPD Multiply andaddfourpackeddouble-precisionoperandsVFMSUBPD Multiplyandsubtractfourpackeddouble-precisionoperandsVCMPxx Compare fourpackeddouble-precisionoperandsforEQ,
NEQ, LT, LTE, GT, GE…VMOVAPD Movealigned fourpackeddouble-precisionoperandsVBROADCASTSD Broadcast onedouble-precisionoperandtofourlocationsina
256-bitregister

Mainconcepts
• Advantagesofvectorinstructions– Asingleinstructionspecifiesagreatdealofwork– Sinceeachloopiterationmustnotcontaindatadependenceto
otherloopiterations• Noneedtocheckfordatahazardsbetweenloopiterations• Onlyonecheckrequiredbetweentwovectorinstructions• Loopbrancheseliminated

Basicvectorarchitecture
• Amodernvectorprocessorcontains– Regular,pipelinedscalarunits– Regularscalarregisters– Vectorunits– (inventorsofpipelining!)– Vectorregister:canholdafixednumberofentries(e.g.64)– Vectorload-storeunits

ComparisonMIPScodevs.vectorcode
Example:Y=aX+Y for64elements
L.D F0, a /* load scalar a*/DADDIU R4, Rx, #512 /* last address */
L: L.D F2, 0(Rx) /* load X(i) */MUL.D F2, F2, F0 /* calc. a times X(i)*/L.D F4, 0(Ry) /* load Y(i) */ADD.D F4, F4, F2 /* aX(I) + Y(i) */S.D F4, 0(Ry) /* store Y(i) */DADDIU Rx, Rx, #8 /* increment X*/DADDIU Ry, Ry, #8 /* increment Y */DSUBU R20, R4, Rx /* compute bound */BNEZ R20, L

ComparisonMIPScodevs.vectorcode(II)
Example:Y=aX+Y for64elements
L.D F0, a /* load scalar a*/LV V1, 0(Rx) /* load vector X */MULVS.D V2, V1, F0 /* vector scalar mult*/LV V3, 0(Ry) /* load vector Y */ADDV.D V4, V2, V3 /* vector add */SV V4, 0(Ry) /* store vector Y */

Vectorlengthcontrol
• Whathappensifthelengthisnotmatchingthelengthofthevectorregisters?
• Avector-lengthregister(VLR)containsthenumberofelementsusedwithinavectorregister
• Stripmining:splitalargeloopintoloopslessorequalthemaximumvectorlength(MVL)

Vectorlengthcontrol(II)
low =0;
VL = (n mod MVL);
for (j=0; j < n/MVL; j++ ) {
for (i=low; i < low + VL; i++ ) {
Y(i) = a * X(i) + Y(i);
}
low += VL;
VL = MVL;
}

Vectorstride
• Memoryontypicallyorganizedinmultiplebanks– Allowforindependentmanagementofdifferentmemory
addresses– MemorybanktimeanorderofmagnitudelargerthanCPU
clockcycle• Example:assume8memorybanksand6cyclesofmemorybanktimetodeliveradataitem– Overlappingofmultipledatarequestsbythehardware

Vectorstride(II)
• Whathappensifthecodedoesnotaccesssubsequentelementsofthevector
– Vectorload‘compacts’thedataitemsinthevectorregister(gather)• Noaffectontheexecutionoftheloop• Youmighthoweveruseonlyasubsetofthememorybanks->longerloadtime• Worstcase:strideisamultipleofthenumberofmemorybanks
for (i=0; i<n; i+=2) {a[i] = b[i] + c[i];
}

Conditionalexecution
• Considerthefollowingloopfor (i=0; i< N; i++ ) {
if ( A(i) != 0 ) {
A(i) = A(i) – B(i);
}
}
• Loopcanusuallynotbeenvectorizedbecauseoftheconditionalstatement
• Vector-maskcontrol:booleanvectoroflengthMLVtocontrolwhetheraninstructionisexecutedornot– Perelementofthevector

Conditionalexecution(II)
LV V1, Ra /* load vector A into V1 */
LV V2, Rb /* load vector B into V2 */
L.D F0, #0 /* set F0 to zero */
SNEVS.D V1, F0 /* set VM(i)=1 if V1(i)!=F0 */
SUBV.D V1, V1, V2 /* sub using vector mask*/
CVM /* clear vector mask to 1 */
SV V1, Ra /* store V1 */

Supportforsparsematrices
• Accessofnon-zeroelementsinasparsematrixoftendescribedbyA(K(i)) = A(K(i)) + C (M(i))– K(i)andM(i)describewhichelementsofAandCarenon-zero– Numberofnon-zeroelementshavetomatch,locationnot
necessarily• Gather-operation:takeanindexvectorandfetchtheaccordingelementsusingabase-address– Mappingfromanon-contiguoustoacontiguous
representation• Scatter-operation:inverseofthegatheroperation

Supportforsparsematrices(II)LV Vk, Rk /* load index vector K into V1 */LVI Va, (Ra+Vk) /* Load vector indexed A(K(i)) */LV Vm, Rm /* load index vector M into V2 */LVI Vc, (Rc+Vm) /* Load vector indexed C(M(i)) */ADDV.D Va, Va, Vc /* set VM(i)=1 if V1(i)!=F0 */SVI Va, (Ra+Vk) /* store vector indexed A(K(i)) */
• Note:– Compilerneedstheexplicithint,thateachelementofKis
pointingtoadistinctelementofA– Hardwarealternative:ahashtablekeepingtrackofthe
addressacquired• Startofanewvectoriteration(convoy)assoonasanaddressappearsthesecondtime

Lecture:ParallelArchitecture–Synchronizationbetweenprocessors,coresandHWthreads
42

Synchronizationbetweenprocessors
• Requiredonalllevelsofmulti-threadedprogramming– Lock/unlock– Mutualexclusion– Barriersynchronization
• Keyhardwarecapability:*cp++– Uninterruptableinstructioncapableofautomaticallyretrieving
orchangingavalue
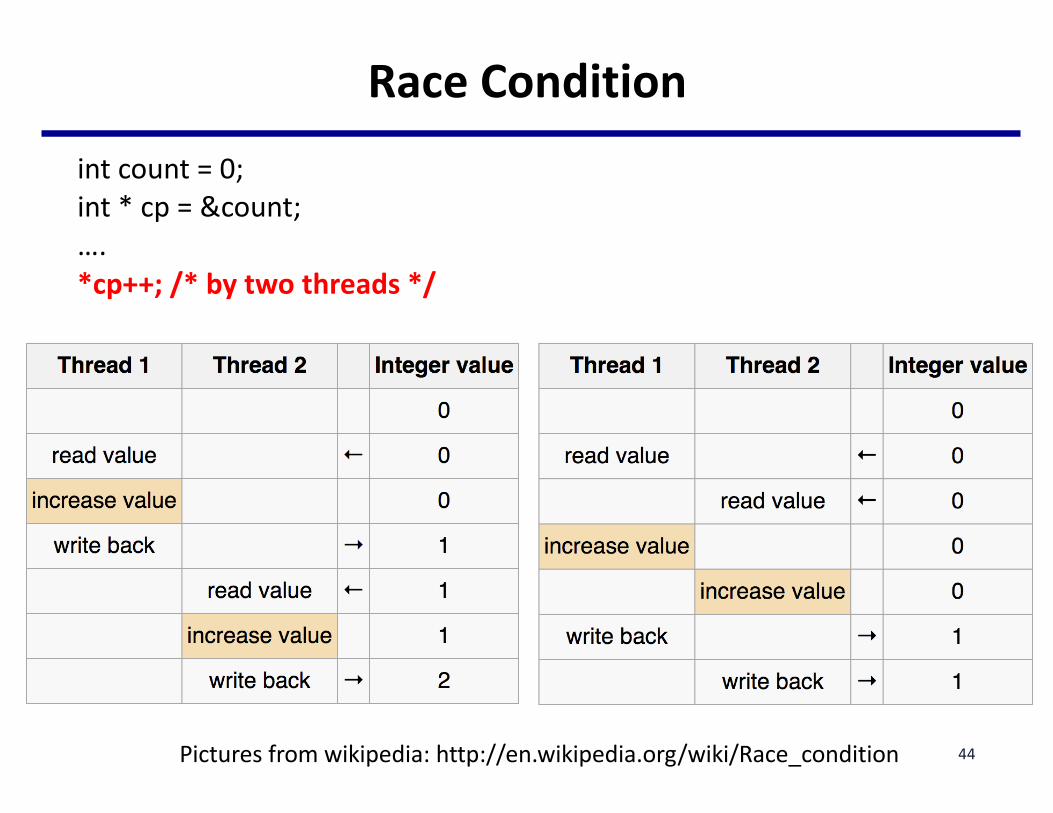
RaceConditionint count=0;int *cp =&count;….*cp++;/*bytwothreads*/
44Picturesfromwikipedia:http://en.wikipedia.org/wiki/Race_condition

SimpleExample(IIIb)
void *thread_func (void *arg){int * cp (int *) arg;
pthread_mutex_lock (&mymutex); *cp++; // read, increment and write shared variable
pthread_mutex_unlock (&mymutex);
return NULL;}

Synchronization
• Lock/unlockoperationsonthehardwarelevel,e.g.– Lockreturning1iflockisfree/available– Lockreturning0iflockisunavailable
• Implementationusingatomicexchange(compareandswap)– Processsetsthevalueofaregister/memorylocationtothe
requiredoperation– Settingthevaluemustnotbeinterruptedinordertoavoid
raceconditions– Accessbymultipleprocesses/threadswillberesolvedbywrite
serialization

Synchronization(II)
• Othersynchronizationprimitives:– Test-and-set– Fetch-and-increment
• Problemswithallthreealgorithms:– Requireareadandwriteoperationinasingle,uninterruptable
sequence– Hardwarecannotallowanyoperationsbetweenthereadand
thewriteoperation– Complicatescachecoherence– Mustnotdeadlock

Loadlinked/storeconditional
• Pairofinstructionswherethesecondinstructionreturnsavalueindicating,whetherthepairofinstructionswasexecutedasiftheinstructionswereatomic
• Specialpairofloadandstoreoperations– Loadlinked(LL)– Storeconditional(SC):returns1ifsuccessful,0otherwise• Storeconditionalreturnsanerrorif– ContentsofmemorylocationspecifiedbyLLchangedbefore
callingSC– Processorexecutesacontextswitch

Loadlinked/storeconditional(II)
• AssemblercodesequencetoatomicallyexchangethecontentsofregisterR4andthememorylocationspecifiedbyR1
try: MOV R3, R4
LL R2, 0(R1)
SC R3, 0(R1)
BEQZ R3, try
MOV R4, R2

Loadlinked/storeconditional(III)
• Implementingfetch-and-incrementusingloadlinkedandconditionalstore
try: LL R2, 0(R1)
DADDUI R3, R2, #1SC R3, 0(R1)
BEQZ R3, try
• ImplementationofLL/SCbyusingaspecialLinkRegister,whichcontainstheaddressoftheoperation

Spinlocks
• Alockthataprocessorcontinuouslytriestoacquire,spinningaroundinaloopuntilitsucceeds.
• Trivialimplementation
DADDUI R2, R0, #1
lockit: EXCH R2, 0(R1) !atomic exchange
BNEZ R2, lockit
• SincetheEXCHoperationincludesareadandamodifyoperation– Valuewillbeloadedintothecache• Goodifonlyoneprocessortriestoaccessthelock• BadifmultipleprocessorsinanSMPtrytogetthelock(cachecoherence)
– EXCHincludesawriteattempt,whichwillleadtoawrite-missforSMPs

Spinlocks(II)
• ForcachecoherentSMPs,slightmodificationofthelooprequired
lockit: LD R2, 0(R1) !load the lock
BNEZ R2, lockit !lock available?
DADDUI R2, R0, #1 !load locked value
EXCH R2, 0(R1) !atomic exchange
BNEZ R2, lockit !EXCH successful?

Spinlocks(III)
• …orusingLL/SClockit: LL R2, 0(R1) !load the lock
BNEZ R2, lockit !lock available?
DADDUI R2, R0, #1 !load locked value
SC R2, 0(R1) !atomic exchange
BNEZ R2, lockit !SC successful?

Lecture:ParallelArchitecture–Moore’sLaw
54

Moore’sLaw
Source:http://en.wikipedia.org/wki/Images:Moores_law.svg
• Long-termtrend onthenumberoftransistorperintegratedcircuit• Numberoftransistorsdoubleevery~18month

The“Future”ofMoore’sLaw
• ThechipsaredownforMoore’slaw– http://www.nature.com/news/the-chips-are-down-for-moore-
s-law-1.19338• SpecialReport:50YearsofMoore'sLaw– http://spectrum.ieee.org/static/special-report-50-years-of-
moores-law• Moore’slawreallyisdeadthistime– http://arstechnica.com/information-
technology/2016/02/moores-law-really-is-dead-this-time/• RebootingtheITRevolution:ACalltoAction(SIA/SRC,2015)– https://www.semiconductors.org/clientuploads/Resources/RIT
R%20WEB%20version%20FINAL.pdf
56