lecture 20 - duke university · 2017-11-08 · parallel dbms •parallelism is natural to dbms...
TRANSCRIPT

CompSci 516DatabaseSystems
Lecture20ParallelDBMS
Instructor:Sudeepa Roy
1DukeCS,Fall2017 CompSci516:DatabaseSystems

Announcements
• HW3dueonMonday,Nov20,11:55pm(in2weeks)– SeesomeclarificationsonPiazza
DukeCS,Fall2017 CompSci516:DatabaseSystems 2

ReadingMaterial• [RG]
– ParallelDBMS:Chapter22.1-22.5
• [GUW]– ParallelDBMSandmap-reduce:Chapter20.1-20.2
3
Acknowledgement:Thefollowingslideshavebeencreatedadaptingtheinstructormaterialofthe[RG]bookprovidedbytheauthorsDr.RamakrishnanandDr.Gehrke.
DukeCS,Fall2017 CompSci516:DatabaseSystems

ReadingMaterial• [RG]
– ParallelDBMS:Chapter22.1-22.5– DistributedDBMS:Chapter22.6– 22.14
• [GUW]– ParallelDBMSandmap-reduce:Chapter20.1-20.2– DistributedDBMS:Chapter20.3,20.4.1-20.4.2,20.5-20.6
• Recommendedreadings:– Chapter2(Sections1,2,3)ofMiningofMassiveDatasets,byRajaraman andUllman:
http://i.stanford.edu/~ullman/mmds.html– OriginalGoogleMRpaperbyJeffDeanandSanjayGhemawat,OSDI’04:
http://research.google.com/archive/mapreduce.html
4
Acknowledgement:Thefollowingslideshavebeencreatedadaptingtheinstructormaterialofthe[RG]bookprovidedbytheauthorsDr.RamakrishnanandDr.Gehrke.
DukeCS,Fall2017 CompSci516:DatabaseSystems

ParallelandDistributedDataProcessing
• RecallfromLecture18!• dataandoperationdistributionifwehavemultiple
machines
• Parallelism– performance
• Datadistribution– increasedavailability,e.g.whenasitegoesdown– distributedlocalaccesstodata(e.g.anorganizationmayhave
branchesinseveralcities)– analysisofdistributeddata
DukeCS,Fall2017 CompSci516:DatabaseSystems 5

Parallelvs.DistributedDBMSParallelDBMS
• Parallelizationofvariousoperations– e.g.loadingdata,building
indexes,evaluatingqueries
• Datamayormaynotbedistributedinitially
• Distributionisgovernedbyperformanceconsideration
DukeCS,Fall2017 CompSci516:DatabaseSystems 6
DistributedDBMS
• Dataisphysicallystoredacrossdifferentsites– Eachsiteistypicallymanagedbyan
independentDBMS
• LocationofdataandautonomyofsiteshaveanimpactonQueryopt.,Conc.Controlandrecovery
• Alsogovernedbyotherfactors:– increasedavailabilityforsystem
crash– localownershipandaccess
Lecture18

ParallelDBMS
DukeCS,Fall2017 CompSci516:DatabaseSystems 7

WhyParallelAccessToData?
At 10 MB/s1.2 days to scan
1,000 x parallel1.5 minute to scan.
Parallelism:divide a big problem into many smaller onesto be solved in parallel.
DukeCS,Fall2017 CompSci516:DatabaseSystems 8
1TBData
1TBData

ParallelDBMS• ParallelismisnaturaltoDBMSprocessing
– Pipelineparallelism:manymachineseachdoingonestepinamulti-stepprocess.
– Data-partitionedparallelism:manymachinesdoingthesamethingtodifferentpiecesofdata.
– BotharenaturalinDBMS!
PipelineAny
SequentialProgram
AnySequentialProgram
Partition SequentialSequential SequentialSequential Any SequentialProgram
Any SequentialProgram
outputs split N ways, inputs merge M waysDukeCS,Fall2017 CompSci516:DatabaseSystems 9

DBMS:TheparallelSuccessStory
• DBMSsarethemostsuccessfulapplicationofparallelism– Teradata(1979),Tandem(1974,lateracquiredbyHP),..– EverymajorDBMSvendorhassomeparallelserver
• Reasonsforsuccess:– Bulk-processing(=partitionparallelism)– Naturalpipelining– Inexpensivehardwarecandothetrick– Users/app-programmersdon’tneedtothinkinparallel
DukeCS,Fall2017 CompSci516:DatabaseSystems 10

Some||Terminology
• Speed-Up– Moreresourcesmeansproportionallylesstimeforgivenamountofdata.
• Scale-Up– Ifresourcesincreasedinproportiontoincreaseindatasize,timeisconstant.
#CPUs(degreeof||-ism)
#ops/sec.
(throughp
ut)
Ideal:linearspeed-up
sec./op
(respon
setime)
#CPUs+sizeofdatabasedegreeof||-ism
Ideal:linearscale-up
Idealgraphs
DukeCS,Fall2017 CompSci516:DatabaseSystems 11

Some||Terminology
• Duetooverheadinparallelprocessing
• Start-upcostStartingtheoperationonmanyprocessor,mightneedtodistributedata
• InterferenceDifferentprocessorsmaycompeteforthesameresources
• SkewTheslowestprocessor(e.g.withahugefractionofdata)maybecomethebottleneck
#CPUs(degreeof||-ism)
#ops/sec.
(throughp
ut)
#CPUs+sizeofdatabasedegreeof||-ism
sec./op
(respon
setime)
Inpractice
Ideal:linearspeed-up
Ideal:linearscale-up
Actual:sub-linearspeed-up
Actual:sub-linearscale-up
DukeCS,Fall2017 CompSci516:DatabaseSystems 12

ArchitectureforParallelDBMS
• Amongdifferentcomputingunits
– Whethermemoryisshared– Whetherdiskisshared
DukeCS,Fall2017 CompSci516:DatabaseSystems 13

BasicsofParallelism
• Units:acollectionofprocessors– assumealwayshavelocalcache– mayormaynothavelocalmemoryordisk(next)
• Acommunicationfacilitytopassinformationamongprocessors– asharedbusoraswitch
DukeCS,Fall2017 CompSci516:DatabaseSystems 14

SharedMemory
DukeCS,Fall2017 CompSci516:DatabaseSystems 15
InterconnectionNetwork
P P P
D D D
GlobalSharedMemorysharedmemory

SharedDisk
DukeCS,Fall2017 CompSci516:DatabaseSystems 16
P P P
M
D
M
D
M
D
InterconnectionNetwork
localmemory
shareddisk

SharedNothing
DukeCS,Fall2017 CompSci516:DatabaseSystems 17
InterconnectionNetwork
P P P
M
D
M
D
M
D
localmemoryanddisk
notwoCPUcanaccessthesamestoragearea
allcommunicationthroughanetworkconnection

Architecture:AtAGlanceShared Memory
(SMP)Shared Disk Shared Nothing
(network)
CLIENTS CLIENTSCLIENTS
MemoryProcessors
• Easy to program• Expensive to build• Low communication
overhead: shared mem.• Difficult to scaleup
(memory contention)
• Hard to program and design parallel algos
• Cheap to build• Easy to scaleup and
speedup• Considered to be the
best architectureSequent, SGI, Sun VMScluster, Sysplex Tandem, Teradata, SP2
• Trade-off but still interference like shared-memory (contention of memory and nw bandwidth)
wewillassumesharednothing
DukeCS,Fall2017 CompSci516:DatabaseSystems 18

WhatSystemsWorkedThisWay
Shared NothingTeradata: 400 nodesTandem: 110 nodesIBM / SP2 / DB2: 128 nodesInformix/SP2 48 nodesATT & Sybase ? nodes
Shared DiskOracle 170 nodesDEC Rdb 24 nodes
Shared MemoryInformix 9 nodes RedBrick ? nodes
CLIENTS
MemoryProcessors
CLIENTS
CLIENTS
NOTE:(asof9/1995)!
DukeCS,Fall2017 CompSci516:DatabaseSystems 19

DifferentTypesofDBMSParallelism• Intra-operatorparallelism
– getallmachinesworkingtocomputeagivenoperation(scan,sort,join)
– OLAP(decisionsupport)
• Inter-operatorparallelism– eachoperatormayrunconcurrentlyona
differentsite(exploitspipelining)– ForbothOLAPandOLTP
• Inter-queryparallelism– differentqueriesrunondifferentsites– ForOLTP
• We’llfocusonintra-operatorparallelism
⨝
𝝲
⨝
𝝲
⨝
𝝲
⨝
𝝲
DukeCS,Fall2017 CompSci516:DatabaseSystems 20
Ack:SlidebyProf.DanSuciu

DataPartitioningHorizontally Partitioning a table (why horizontal?):Range-partition Hash-partition Block-partition
or Round Robin
Shared disk and memory less sensitive to partitioning, Shared nothing benefits from "good" partitioning
A...E F...J K...N O...S T...Z A...E F...J K...N O...S T...Z A...E F...J K...N O...S T...Z
• Good for equijoins, range queries, group-by• Can lead to data skew
• Good for equijoins• But only if hashed
on that attribute• Can lead to data
skew
• Send i-th tuple to i-mod-n processor
• Good to spread load
• Good when the entire relation is accessed
DukeCS,Fall2017 CompSci516:DatabaseSystems 21

Example
• R(Key,A,B)
• CanBlock-partitionbeskewed?– no,uniform
• CanHash-partitionbeskewed?– onthekey:uniformwithagoodhashfunction– onA:maybeskewed,
• e.g.whenalltupleshavethesameA-value
DukeCS,Fall2017 CompSci516:DatabaseSystems 22

ParallelizingSequentialEvaluationCode
• “Streams”fromdifferentdisksortheoutputofotheroperators– are“merged”asneededasinputtosomeoperator– are“split”asneededforsubsequentparallelprocessing
• DifferentSplit andmerge operationsappearinadditiontorelationaloperators
• Nofixedformulaforconversion• Next:parallelizingindividualoperations
DukeCS,Fall2017 CompSci516:DatabaseSystems 23

ParallelScans
• Scaninparallel,andmerge.• Selectionmaynotrequireallsitesforrangeorhashpartitioning– butmayleadtoskew– SupposesA=10RandpartitionedaccordingtoA– Thenalltuplesinthesamepartition/processor
• Indexescanbebuiltateachpartition
DukeCS,Fall2017 CompSci516:DatabaseSystems 24

ParallelSorting
Idea:• Scaninparallel,andrange-partitionasyougo
– e.g.salarybetween10to210,#processors=20– salaryinfirstprocessor:10-20,second:21-30,third:31-40,….
• Astuplescomein,begin“local”sortingoneach• Resultingdataissorted,andrange-partitioned• Visittheprocessorsinordertogetafullsortedorder• Problem:skew!• Solution:“sample”thedataatstarttodeterminepartitionpoints.DukeCS,Fall2017 CompSci516:DatabaseSystems 25

ParallelJoins
• Needtosendthetuplesthatwilljointothesamemachine– alsoforGROUP-BY
• Nestedloop:– Eachoutertuplemustbecomparedwitheachinnertuplethatmightjoin
– Easyforrangepartitioningonjoincols,hardotherwise
• Sort-Merge:– Sortinggivesrange-partitioning– Mergingpartitionedtablesislocal
DukeCS,Fall2017 CompSci516:DatabaseSystems 26
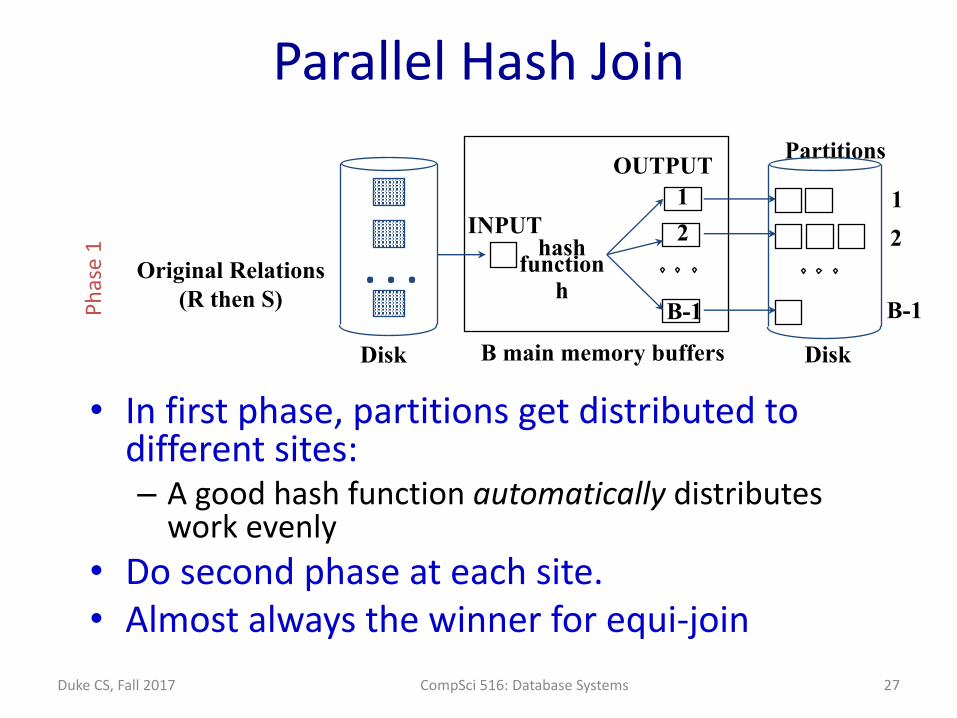
ParallelHashJoin
• Infirstphase,partitionsgetdistributedtodifferentsites:– Agoodhashfunctionautomaticallydistributesworkevenly
• Dosecondphaseateachsite.• Almostalwaysthewinnerforequi-join
Original Relations(R then S)
OUTPUT
2
B main memory buffers DiskDisk
INPUT1
hashfunction
hB-1
Partitions
12
B-1...
Phase1
DukeCS,Fall2017 CompSci516:DatabaseSystems 27

DataflowNetworkforparallelJoin
• Gooduseofsplit/mergemakesiteasiertobuildparallelversionsofsequentialjoincode.
DukeCS,Fall2017 CompSci516:DatabaseSystems 28
ExamplewithparallelhashjoinbetweenAandB
Machine0 Machine1 Machine0 Machine1
hmod2=0
hmod2=0
hmod2=0
hmod2=1
hmod2=1hmod2
=1
hmod2=1
hmod2=0
hmod2=1
hmod2=0

Jim Gray & Gordon Bell: VLDB 95 Parallel Database Systems Survey
ParallelAggregates
A...E F...J K...N O...S T...Z
A Table
Count Count Count Count Count
Count
• Foreachaggregatefunction,needadecomposition:– count(S)=S count(s(i)),dittoforsum()– avg(S)=(S sum(s(i)))/S count(s(i))– andsoon...
• Forgroup-by:– Sub-aggregategroupsclosetothesource.– Passeachsub-aggregatetoitsgroup’ssite.
• Chosenviaahashfn.
DukeCS,Fall2017 CompSci516:DatabaseSystems 29
WhichSQLaggregateoperatorsarenotgoodforparallelexecution?

• Why?• Trivialcounter-example:
– Tablepartitionedwithlocalsecondaryindexattwonodes
– Rangequery:allofnode1and1%ofnode2.– Node1shoulddoascanofitspartition.– Node2shouldusesecondaryindex.
Bestserialplanmaynotbebest||
N..Z
TableScan
A..M
Index Scan
DukeCS,Fall2017 CompSci516:DatabaseSystems 30

Examples
DukeCS,Fall2017 CompSci516:DatabaseSystems 31

Exampleproblem:ParallelDBMSR(a,b)ishorizontallypartitionedacrossN=3machines.
Eachmachinelocallystoresapproximately1/Nofthetuples inR.
Thetuples arerandomlyorganizedacrossmachines(i.e.,Risblockpartitionedacrossmachines).
ShowaRAplanforthisqueryandhowitwillbeexecutedacrosstheN=3machines.
Pickanefficientplanthatleveragestheparallelismasmuchaspossible.
• SELECTa,max(b)astopb• FROMR• WHEREa>0• GROUPBYa
DukeCS,Fall2017 CompSci516:DatabaseSystems 32
WedidthisexampleforMap-ReduceinLecture12!

1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopbFROMRWHEREa>0GROUPBYa
R(a,b)
DukeCS,Fall2017 CompSci516:DatabaseSystems 33

1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopbFROMRWHEREa>0GROUPBYa
R(a,b)
scan scan scan
Ifmorethanonerelationonamachine,then“scanS”,“scanR”etc
DukeCS,Fall2017 CompSci516:DatabaseSystems 34
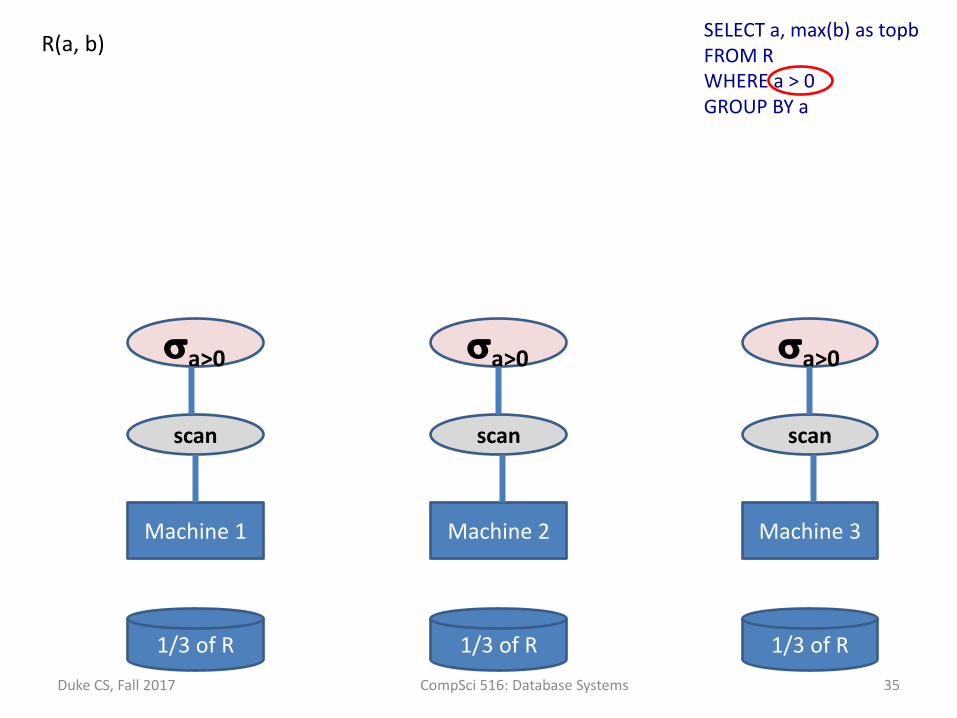
1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopbFROMRWHEREa>0GROUPBYa
R(a,b)
scan scan scan
sa>0 sa>0 sa>0
DukeCS,Fall2017 CompSci516:DatabaseSystems 35

1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopbFROMRWHEREa>0GROUPBYa
R(a,b)
scan scan scan
sa>0 sa>0 sa>0
ga,max(b)-> b ga,max(b)-> b ga,max(b)-> b
DukeCS,Fall2017 CompSci516:DatabaseSystems 36

1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopbFROMRWHEREa>0GROUPBYa
R(a,b)
scan scan scan
sa>0 sa>0 sa>0
ga,max(b)-> b ga,max(b)-> b ga,max(b)-> b
Hashona Hashona Hashona
DukeCS,Fall2017 CompSci516:DatabaseSystems 37

1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopb FROMRWHEREa>0 GROUPBYaR(a,b)
scan scan scan
sa>0 sa>0 sa>0
ga,max(b)-> b ga,max(b)-> b ga,max(b)-> b
Hashona Hashona Hashona
DukeCS,Fall2017 CompSci516:DatabaseSystems 38

1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopb FROMRWHEREa>0 GROUPBYaR(a,b)
scan scan scan
sa>0 sa>0 sa>0
ga,max(b)-> b ga,max(b)-> b ga,max(b)-> b
Hashona Hashona Hashona
ga,max(b)->topb ga,max(b)->topb ga,max(b)->topb
DukeCS,Fall2017 CompSci516:DatabaseSystems 39

Benefitofhash-partitioning
• Whatwouldchangeifwehash-partitionedRonR.a beforeexecutingthesamequeryonthepreviousparallelDBMSandMR
• FirstParallelDBMS
SELECTa,max(b)astopbFROMR
WHEREa>0GROUPBYa
DukeCS,Fall2017 CompSci516:DatabaseSystems 40
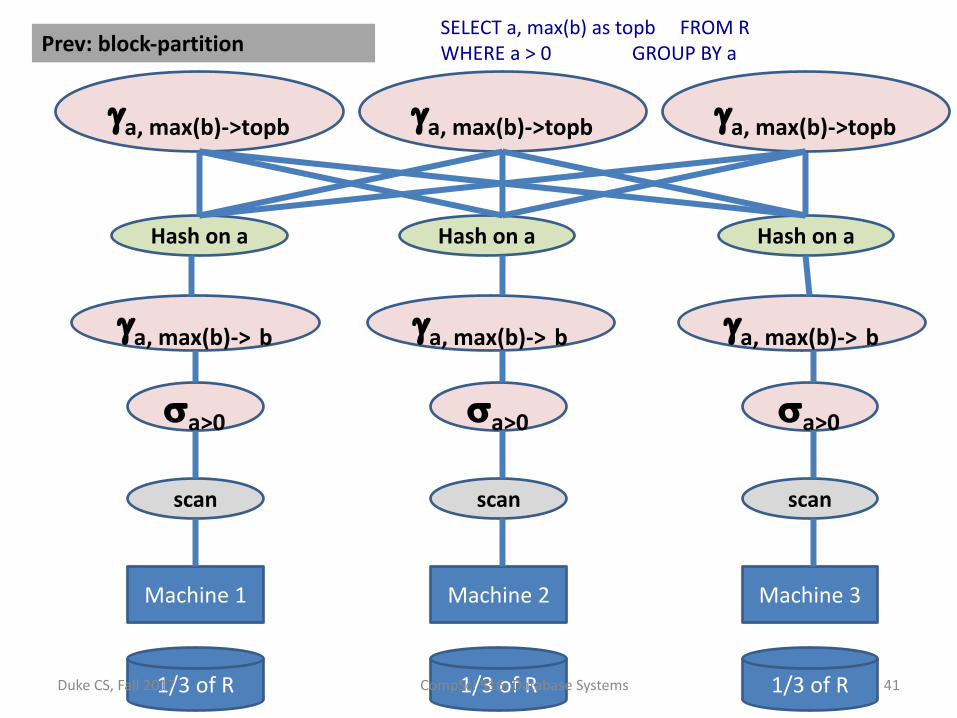
1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopb FROMRWHEREa>0 GROUPBYaPrev:block-partition
scan scan scan
sa>0 sa>0 sa>0
ga,max(b)-> b ga,max(b)-> b ga,max(b)-> b
Hashona Hashona Hashona
ga,max(b)->topb ga,max(b)->topb ga,max(b)->topb
DukeCS,Fall2017 CompSci516:DatabaseSystems 41

• Itwouldavoidthedatare-shufflingphase• Itwouldcomputetheaggregateslocally
SELECTa,max(b)astopbFROMR
WHEREa>0GROUPBYa
DukeCS,Fall2017 CompSci516:DatabaseSystems 42
Hash-partitiononaforR(a,b)

1/3ofR 1/3ofR 1/3ofR
Machine1 Machine2 Machine3
SELECTa,max(b)astopb FROMRWHEREa>0 GROUPBYaHash-partitiononaforR(a,b)
scan scan scan
sa>0 sa>0 sa>0
ga,max(b)->topb ga,max(b)->topb ga,max(b)->topb
DukeCS,Fall2017 CompSci516:DatabaseSystems 43

Benefitofhash-partitioningforMap-Reduce• ForMapReduce
– Logically,MRwon’tknowthatthedataishash-partitioned
– MRtreatsmapandreducefunctionsasblack-boxesanddoesnotperformanyoptimizationsonthem
• But,ifalocalcombinerisused– Savescommunicationcost:
• fewertuples willbeemittedbythemaptasks– Savescomputationcostinthereducers:
• thereducerswouldhavetodoanything
SELECTa,max(b)astopbFROMR
WHEREa>0GROUPBYa
DukeCS,Fall2017 CompSci516:DatabaseSystems 44

ColumnStore(slidesfromLecture19)
DukeCS,Fall2017 CompSci516:DatabaseSystems 45

Rowvs.ColumnStore
• Rowstore– storeallattributesofatupletogether– storagelike“row-majororder”inamatrix
• Columnstore– storeallrowsforanattribute(column)together– storagelike“column-majororder”inamatrix
• e.g.– MonetDB,Vertica(earlier,C-store),SAP/SybaseIQ,GoogleBigtable (withcolumngroups)
DukeCS,Fall2017 CompSci516:DatabaseSystems 46

DukeCS,Fall2017 CompSci516:DatabaseSystems 47
Ack:SlidefromVLDB2009tutorialonColumnstore

DukeCS,Fall2017 CompSci516:DatabaseSystems 48
Ack:SlidefromVLDB2009tutorialonColumnstore

DukeCS,Fall2017 CompSci516:DatabaseSystems 49
Ack:SlidefromVLDB2009tutorialonColumnstore

DukeCS,Fall2017 CompSci516:DatabaseSystems 50
Ack:SlidefromVLDB2009tutorialonColumnstore

DukeCS,Fall2017 CompSci516:DatabaseSystems 51
Ack:SlidefromVLDB2009tutorialonColumnstore