lec04, speech ii, v1.10.ppt -...
TRANSCRIPT

Multimedia Systems
Speech II
Mahdi Amiri
October 2015
Sharif University of Technology
Course Presentation

Page 1 Multimedia Systems, Speech II
Speech Compression
Based on Time Domain analysis
Differential Pulse-Code Modulation (DPCM)
Adaptive DPCM (ADPCM)
Based on Frequency Domain analysis
Linear Predictive Coding (LPC)
Code Excited Linear Prediction (CELP)
Road Map

Page 2 Multimedia Systems, Speech II
Differential PCM (DPCM)Idea
Take advantage of data redundancy
[… 110 112 111 112 112 114 115 115 114 114… ] [… +2 -1 +1 0 +2 +1 0 -1 0 …]
Or histogram of PCM samples in a chunk
of digitized audio.Typ. Chunk length: 50 ms

Page 3 Multimedia Systems, Speech II
Differential PCM (DPCM)
Simplest prediction: The difference between the current
sample value and previous sample is quantized. It means
we predicted current sample by assuming it to be equal to
the previous sample.
Another better prediction: The difference between the
current sample value and the average of e.g. 2 previous
samples.
Much better prediction: The difference between the
current sample value and the weighted average of e.g. 10
previous samples.
Prediction

Page 4 Multimedia Systems, Speech II
Differential PCM (DPCM)Basic Scheme
1Delta Modulation (DM): i n ia x z−−⇒∑
Problem?
General Predictive Coding

Page 5 Multimedia Systems, Speech II
Differential PCM (DPCM)Error Propagation
The output of dequantizer in decoder is not
equal with the input of the quantizer in the
encoder
� The input of predictor in decoder is not
the same as input values of predictor in
encoder
� This is the source of error propagation.
General Predictive Coding
x_n: 0 0.6 1.2 1.8 2.4 3.0 3.6 4.2
p_n: 0 0 0.6 1.2 1.8 2.4 3.0 3.6
d_n: 0 0.6 0.6 0.6 0.6 0.6 0.6 0.6
Q : 0 1 1 1 1 1 1 1
^Q : 0 1 1 1 1 1 1 1
^dn: 0 1 1 1 1 1 1 1
^pn: 0 0 1 2 3 4 5 6
^xn: 0 1 2 3 4 5 6 7
Err: 0 0.4 0.8 1.2 1.6 2.0 2.4 2.8
Error propagation example in above structure when input signal increases constantly by +0.6.
Quantization step size is 1; Therefore, e.g. -0.5 thr. 0.5 quantized as 0 and 0.5 thr. 1.5 quantized as 1.

Page 6 Multimedia Systems, Speech II
Differential PCM (DPCM)Better Structure

Page 7 Multimedia Systems, Speech II
Adaptive DPCM (ADPCM)Idea
Problem?

Page 8 Multimedia Systems, Speech II
Adaptive DPCM (ADPCM)Size of Quantization Step
ADM: [ ] [ 1]n M n∆ = ∆ −
12, 2
P Q= =
1 if [ ] [ 1]
1 if [ ] [ 1]
M P c n c n
M Q c n c n
= > = −
= < ≠ −
Delta Modulation (DM)
Adaptive Delta Modulation (ADM)
1 bit quantizer: 0 means + and 1 means ∆ −∆
Page 9 Multimedia Systems, Speech II
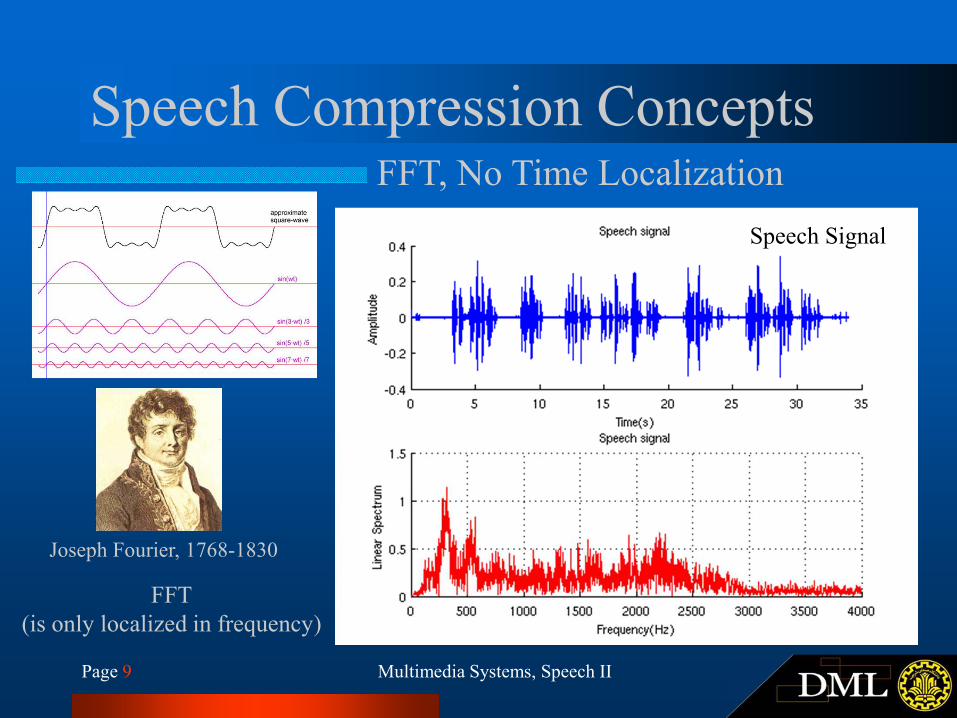
Speech Compression ConceptsFFT, No Time Localization
Speech Signal
FFT
(is only localized in frequency)
Joseph Fourier, 1768-1830

Page 10 Multimedia Systems, Speech II
Speech Compression ConceptsFFT, No Time Localization, Ex. 1
See Power Spectral Density (PSD) examples in MATLAB
(PSD_test01_2sine.m and PSD_test03_1sineIn4sig.m)

0 0.2 0.4 0.6 0.8 1-1
-0.5
0
0.5
1x4 = x1+x2+x3
0 0.2 0.4 0.6 0.8 1-1
-0.5
0
0.5
1x5 = x1 then x2 then x3
0 0.2 0.4 0.6 0.8 1-1
-0.5
0
0.5
1x6 = x3 then x1 then x2
Page 11 Multimedia Systems, Speech II
Speech Compression ConceptsFFT, No Time Localization, Ex. 2
See Power Spectral Density (PSD) examples in MATLAB
0 0.005 0.01 0.015-1
0
1x1, freq.: 400 Hz
0 1000 2000 3000 4000 5000 6000 7000 80000
50
100
150PSD x1
Frequency (Hz)
0 0.005 0.01 0.015-1
0
1x1, freq.: 900 Hz
0 1000 2000 3000 4000 5000 6000 7000 80000
50
100
150PSD x2
Frequency (Hz)
0 0.005 0.01 0.015-1
0
1x1, freq.: 1600 Hz
0 1000 2000 3000 4000 5000 6000 7000 80000
50
100
150PSD x3
Frequency (Hz)
0 0.005 0.01 0.015-3
-2
-1
0
1
2
3x4 = x1+x2+x3
0 1000 2000 3000 4000 5000 6000 7000 80000
100
200
300
400
500PSD x4
Frequency (Hz)
0 1000 2000 3000 4000 5000 6000 7000 80000
100
200
300
400
500PSD x5
Frequency (Hz)
0 1000 2000 3000 4000 5000 6000 7000 80000
100
200
300
400
500PSD x6
Frequency (Hz)
0.325 0.33 0.335 0.34-1
-0.5
0
0.5
1x5 = x1 then x2 then x3
0.325 0.33 0.335 0.34 0.345-1
-0.5
0
0.5
1x6 = x3 then x1 then x2
Part of
x4
X4 = (x1 + x2 + x3) / 3
X5 = x1 then x2 then x3
X6 = x3 then x1 then x2Zoomed
Parts �
Part of
x5
Part of
x6
PSD_test04_3sinesInDiffLoc.m

Page 12 Multimedia Systems, Speech II
Speech Compression ConceptsSTFT
Speech Signal
STFT
(fixed time and frequency localization)
Dennis Gabor, 1900-1979

Page 13 Multimedia Systems, Speech II
Speech Compression ConceptsSpectrogram
3D surface spectrogram of a part
from a music piece.

Page 14 Multimedia Systems, Speech II
Speech Compression ConceptsSpectrogram
Spectrogram of a male voice saying ‘nineteenth century’.

Page 15 Multimedia Systems, Speech II
Speech Compression ConceptsSpectrogram Display in AudaCity
Waveform
Spectrogram

Page 16 Multimedia Systems, Speech II
Speech Compression ConceptsSpectrogram Display in AudaCity
AudaCity | Edit | Preferences |
Spectrograms | FFT Window |
Window size
FFT Window size:128
FFT Window size:1024

Page 17 Multimedia Systems, Speech II
Speech Compression ConceptsSpectrogram, Demonstration
Bat Echolocation Call Flute by Jean Pierre Rampal
Singing Voice Face!

Page 18 Multimedia Systems, Speech II
Speech Compression ConceptsFormant
The time and frequency domain
presentation of vowels /a/, /i/, and /u//a/
/i/
/u/
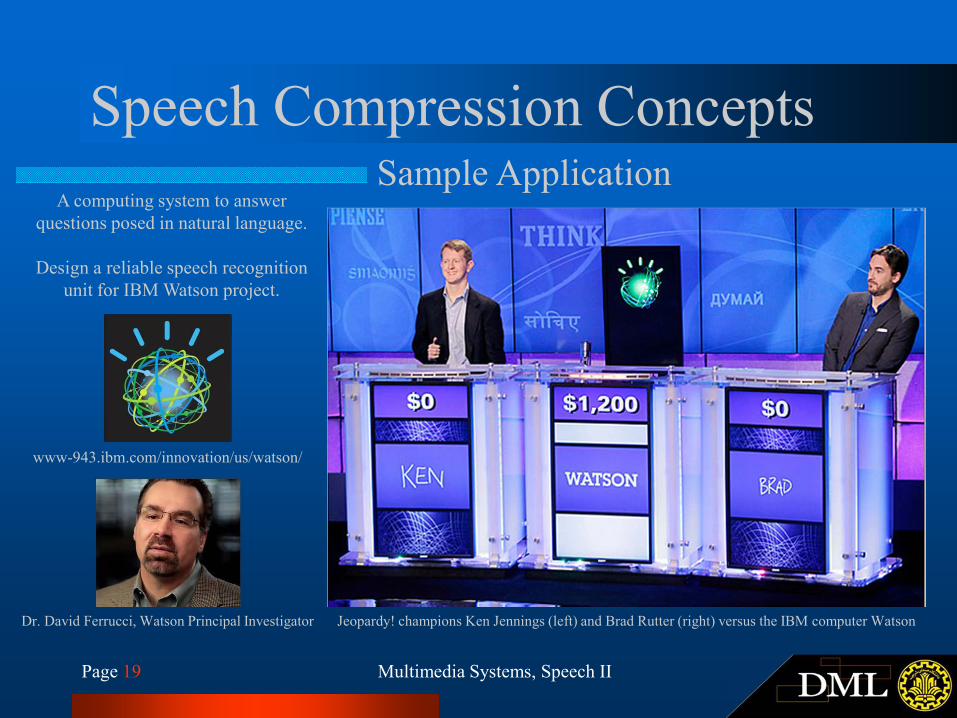
Page 19 Multimedia Systems, Speech II
Speech Compression ConceptsSample Application
Jeopardy! champions Ken Jennings (left) and Brad Rutter (right) versus the IBM computer Watson
www-943.ibm.com/innovation/us/watson/
Dr. David Ferrucci, Watson Principal Investigator
A computing system to answer
questions posed in natural language.
Design a reliable speech recognition
unit for IBM Watson project.
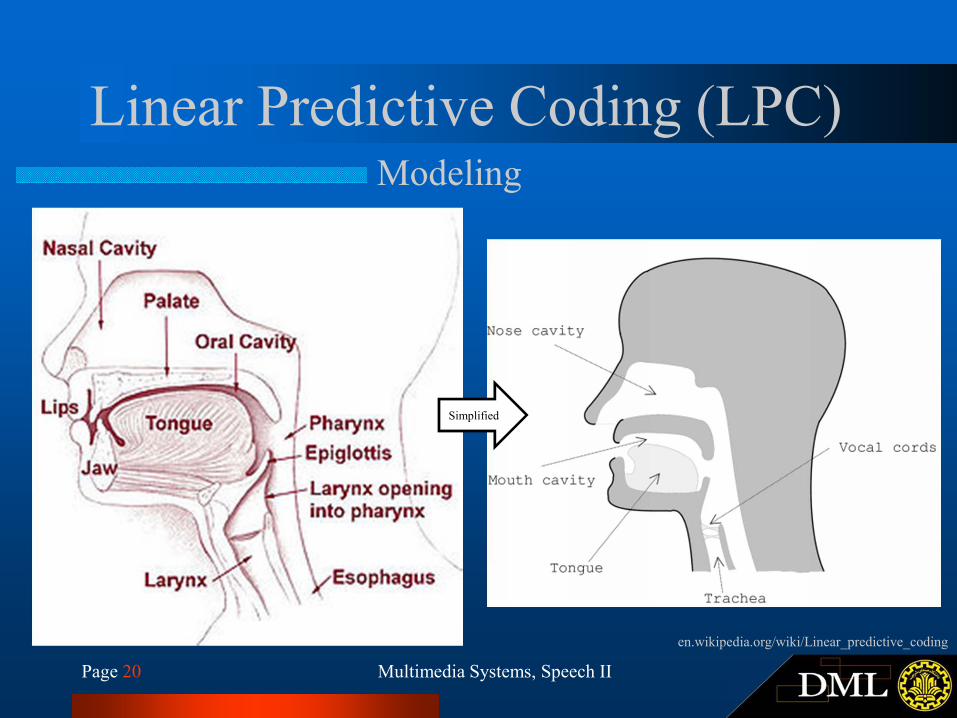
Page 20 Multimedia Systems, Speech II
Linear Predictive Coding (LPC)Modeling
Simplified
en.wikipedia.org/wiki/Linear_predictive_coding

Page 21 Multimedia Systems, Speech II
Linear Predictive Coding (LPC)Modeling (Hiss or Buzz)
1
[ ] [ ]P
i
i
x n a x n i=
= −∑%
Predictor for each frame:
Buzzer � Filter
Speech = Formants + Residue
Chuncks: 30 thr. 50 frames/sec.

Page 22 Multimedia Systems, Speech II
Linear Predictive Coding (LPC)Modeling (Hiss or Buzz)
The human vocal tract as an infinite impulse response (IIR) system
LPC Block Diagram
Vowel /a/
The fundamental frequency of speech (pitch) can vary from 40
Hz for low-pitched male voices to 600 Hz for children or high-
pitched female voices.

Page 23 Multimedia Systems, Speech II
Linear Predictive Coding (LPC)Original Paper, Atal-Hanauer 1971
Comparison of wide-band sound spectrograms for synthetic and original speech signal for the utterance "It's
time we rounded up that herd of Asian cattle," spoken by a male speaker
Original
Synthetic
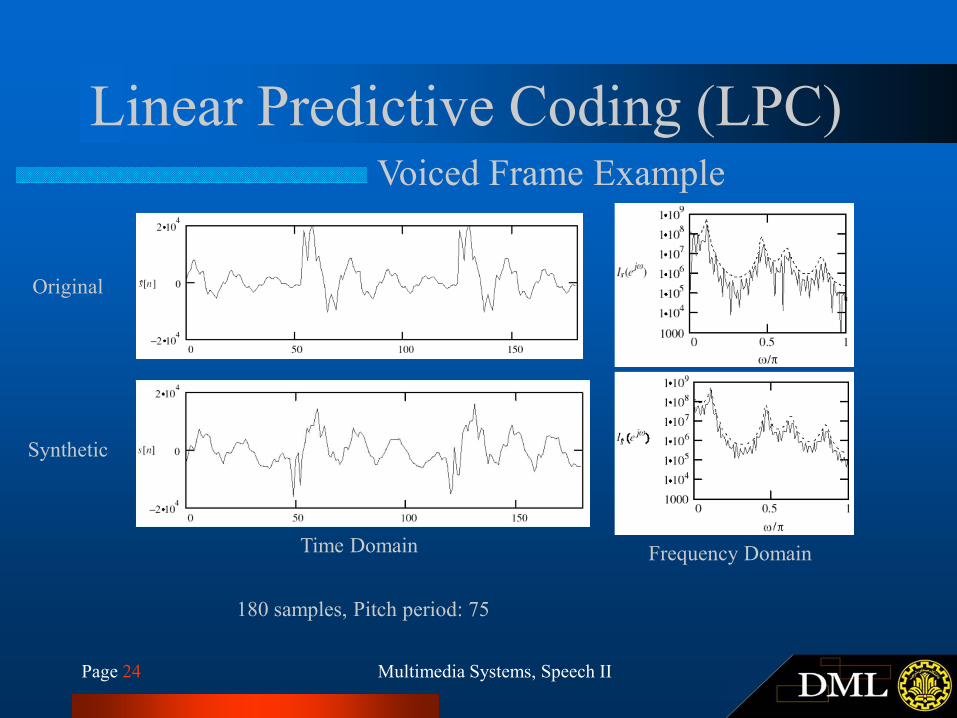
Page 24 Multimedia Systems, Speech II
Linear Predictive Coding (LPC)Voiced Frame Example
Original
Synthetic
Time Domain Frequency Domain
180 samples, Pitch period: 75

Page 25 Multimedia Systems, Speech II
Linear Predictive Coding (LPC)Unvoiced Frame Example
Original
Synthetic:
White noise
with uniform
distribution
Time Domain Frequency Domain
180 samples
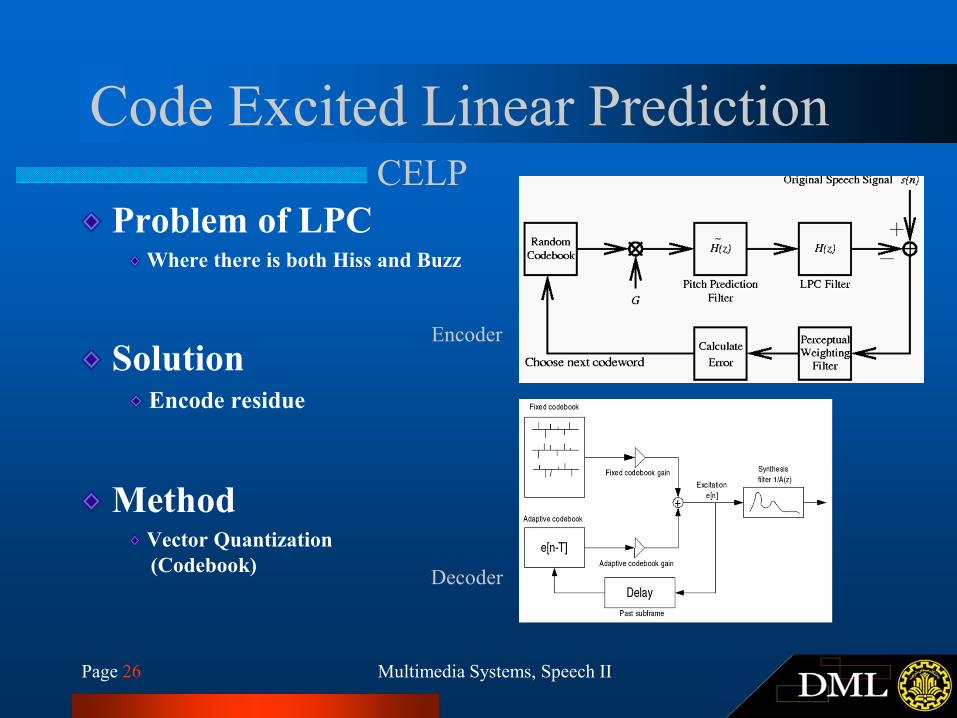
Page 26 Multimedia Systems, Speech II
Code Excited Linear Prediction
Problem of LPCWhere there is both Hiss and Buzz
SolutionEncode residue
MethodVector Quantization
(Codebook)
CELP
Encoder
Decoder

Page 27 Multimedia Systems, Speech II
Vector QuantizationBlock Diagram

Page 28 Multimedia Systems, Speech II
Vector QuantizationExample
Sample scalar quantizer
We have 3 possible colors for
each square; so we can quantize
each square with 2 bits � (28 *
2 = 56 bits for all 28 (7*4)
squares.
Sample vector quantizer
We have 8 forms in the
codebook; so we can quantize
each form with 3 bits � (7 * 3
= 21 bits for all 28 (7*4)
squares.Codebook

Page 29 Multimedia Systems, Speech II
Vector QuantizationCodebook Design
Feature Space
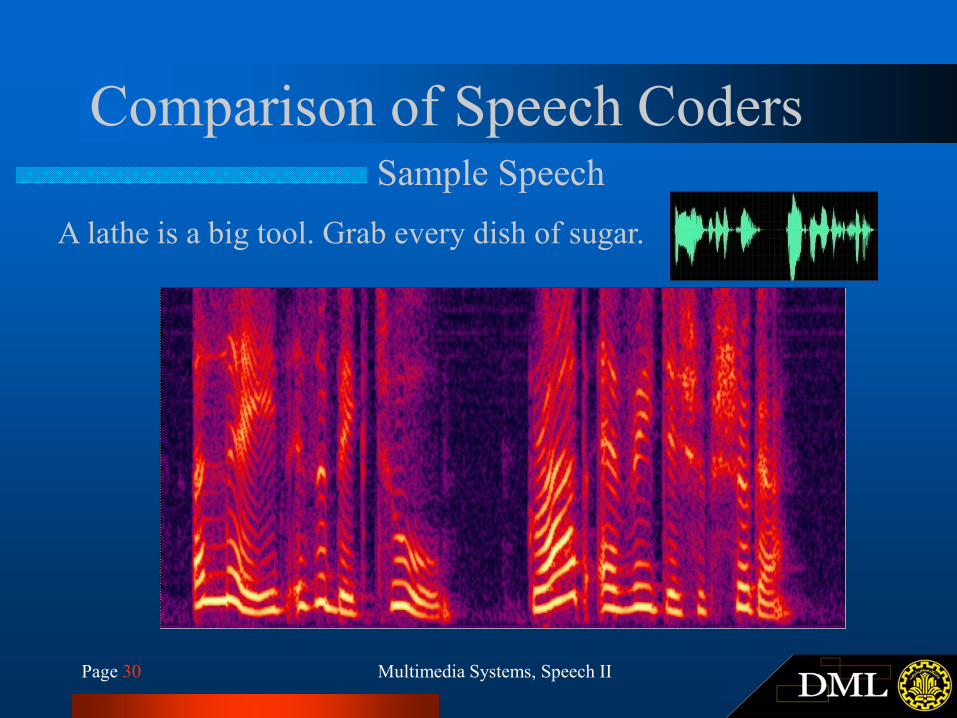
Page 30 Multimedia Systems, Speech II
Comparison of Speech CodersSample Speech
A lathe is a big tool. Grab every dish of sugar.

Page 31 Multimedia Systems, Speech II
Comparison of Speech CodersDemonstration
Original ADPCM
LPC CELP

Page 32 Multimedia Systems, Speech II
Speech Coding
G.711
PCM
u-law, a-law
64, 80 and 96 kbps
G.722
ADPCM
48, 56 and 64 kbps
G.728
A form of CELP
16 kbps
ITU-T Standards
Check out a complete list athttp://en.wikipedia.org/wiki/List_of_codecs#Audio_codecs
Vocoders
A comparison of Internet audio compression formats
http://www.sericyb.com.au/audio.html

Page 33 Multimedia Systems, Speech II
Speech Coding
HawkVoice
Free and Open Source Code
http://hawksoft.com/hawkvoice/
Check out voice samples of HawkVoice™ codecs at
http://hawksoft.com/hawkvoice/codecs.shtml

Page 34 Multimedia Systems, Speech II
Thank You
1. http://ce.sharif.edu/~m_amiri/
2. http://www.aictc.ir/
FIND OUT MORE AT...
Multimedia Systems
Speech II
Next Session: Entropy Coding