learning to communicate to solve riddles with deep … · learning to communicate to solve riddles...
TRANSCRIPT

Learning to Communicate to Solve Riddleswith Deep Distributed Recurrent Q-Networks
Jakob N. Foerster1,† [email protected] M. Assael1,† [email protected] de Freitas1,2,3 [email protected] Whiteson1 [email protected] of Oxford, United Kingdom2Canadian Institute for Advanced Research, CIFAR NCAP Program3Google DeepMind
AbstractWe propose deep distributed recurrent Q-networks (DDRQN), which enable teams ofagents to learn to solve communication-based co-ordination tasks. In these tasks, the agents arenot given any pre-designed communication pro-tocol. Therefore, in order to successfully com-municate, they must first automatically developand agree upon their own communication proto-col. We present empirical results on two multi-agent learning problems based on well-knownriddles, demonstrating that DDRQN can success-fully solve such tasks and discover elegant com-munication protocols to do so. To our knowl-edge, this is the first time deep reinforcementlearning has succeeded in learning communica-tion protocols. In addition, we present ablationexperiments that confirm that each of the maincomponents of the DDRQN architecture are crit-ical to its success.
1. IntroductionIn recent years, advances in deep learning have been in-strumental in solving a number of challenging reinforce-ment learning (RL) problems, including high-dimensionalrobot control (Levine et al., 2015; Assael et al., 2015; Wat-ter et al., 2015), visual attention (Ba et al., 2015), and theAtari learning environment (ALE) (Guo et al., 2014; Mnihet al., 2015; Stadie et al., 2015; Wang et al., 2015; Schaulet al., 2016; van Hasselt et al., 2016; Oh et al., 2015; Belle-mare et al., 2016; Nair et al., 2015).
The above-mentioned problems all involve only a singlelearning agent. However, recent work has begun to addressmulti-agent deep RL. In competitive settings, deep learn-†These authors contributed equally to this work.
ing for Go (Maddison et al., 2015; Silver et al., 2016) hasrecently shown success. In cooperative settings, Tampuuet al. (2015) have adapted deep Q-networks (Mnih et al.,2015) to allow two agents to tackle a multi-agent exten-sion to ALE. Their approach is based on independent Q-learning (Shoham et al., 2007; Shoham & Leyton-Brown,2009; Zawadzki et al., 2014), in which all agents learn theirown Q-functions independently in parallel.
However, these approaches all assume that each agent canfully observe the state of the environment. While DQNhas also been extended to address partial observability(Hausknecht & Stone, 2015), only single-agent settingshave been considered. To our knowledge, no work on deepreinforcement learning has yet considered settings that areboth partially observable and multi-agent.
Such problems are both challenging and important. In thecooperative case, multiple agents must coordinate their be-haviour so as to maximise their common payoff while fac-ing uncertainty, not only about the hidden state of the envi-ronment but about what their teammates have observed andthus how they will act. Such problems arise naturally in avariety of settings, such as multi-robot systems and sensornetworks (Matari, 1997; Fox et al., 2000; Gerkey & Matari,2004; Olfati-Saber et al., 2007; Cao et al., 2013).
In this paper, we propose deep distributed recurrent Q-networks (DDRQN) to enable teams of agents to learn ef-fectively coordinated policies on such challenging prob-lems. We show that a naive approach to simply train-ing independent DQN agents with long short-term memory(LSTM) networks (Hochreiter & Schmidhuber, 1997) is in-adequate for multi-agent partially observable problems.
Therefore, we introduce three modifications that are key toDDRQN’s success: a) last-action inputs: supplying eachagent with its previous action as input on the next time stepso that agents can approximate their action-observation his-tories; b) inter-agent weight sharing: a single network’s
arX
iv:1
602.
0267
2v1
[cs
.AI]
8 F
eb 2
016

Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
weights are used by all agents but that network conditionson the agent’s unique ID, to enable fast learning while alsoallowing for diverse behaviour; and c) disabling experiencereplay, which is poorly suited to the non-stationarity aris-ing from multiple agents learning simultaneously.
To evaluate DDRQN, we propose two multi-agent rein-forcement learning problems that are based on well-knownriddles: the hats riddle, where n prisoners in a line mustdetermine their own hat colours; and the switch riddle, inwhich n prisoners must determine when they have all vis-ited a room containing a single switch. Both riddles havebeen used as interview questions at companies like Googleand Goldman Sachs.
While these environments do not require convolutional net-works for perception, the presence of partial observabil-ity means that they do require recurrent networks to dealwith complex sequences, as in some single-agent works(Hausknecht & Stone, 2015; Ba et al., 2015) and language-based (Narasimhan et al., 2015) tasks. In addition, becausepartial observability is coupled with multiple agents, op-timal policies critically rely on communication betweenagents. Since no communication protocol is given a pri-ori, reinforcement learning must automatically develop acoordinated communication protocol.
Our results demonstrate that DDRQN can successfullysolve these tasks, outperforming baseline methods, and dis-covering elegant communication protocols along the way.To our knowledge, this is the first time deep reinforcementlearning has succeeded in learning communication proto-cols. In addition, we present ablation experiments that con-firm that each of the main components of the DDRQN ar-chitecture are critical to its success.
2. BackgroundIn this section, we briefly introduce DQN and its multi-agent and recurrent extensions.
2.1. Deep Q-Networks
In a single-agent, fully-observable, reinforcement learningsetting (Sutton & Barto, 1998), an agent observes its cur-rent state st ∈ S at each discrete time step t, chooses anaction at ∈ A according to a potentially stochastic policyπ, observes a reward signal rt, and transitions to a new statest+1. Its objective is to maximize an expectation over thediscounted return, Rt
Rt = rt + γrt+1 + γ2rt+2 + · · · , (1)
where γ ∈ [0, 1) is a discount factor. The Q-function of apolicy π is:
Qπ(s, a) = E [Rt|st = s, at = a] . (2)
The optimal action-value function Q∗(s, a) =maxπ Q
π(s, a) obeys the Bellman optimality equation:
Q∗(s, a) = Es′[r + γmax
a′Q∗(s′, a′) | s, a
]. (3)
Deep Q-networks (Mnih et al., 2015) (DQNs) use neuralnetworks parameterised by θ to representQ(s, a; θ). DQNsare optimised by minimising the following loss function ateach iteration i:
Li(θi) = Es,a,r,s′[(yDQNi −Q(s, a; θi)
)2], (4)
with target
yDQNi = r + γmaxa′
Q(s′, a′; θ−i ). (5)
Here, θ−i are the weights of a target network that is frozenfor a number of iterations while updating the online net-workQ(s, a; θi) by gradient descent. DQN uses experiencereplay (Lin, 1993; Mnih et al., 2015): during learning, theagent builds a datasetDt = {e1, e2, . . . , et} of experienceset = (st, at, rt, st+1) across episodes. The Q-network isthen trained by sampling mini-batches of experiences fromD uniformly at random. Experience replay helps preventdivergence by breaking correlations among the samples. Italso enables reuse of past experiences for learning, therebyreducing sample costs.
2.2. Independent DQN
DQN has been extended to cooperative multi-agent set-tings, in which each agent m observes the global st, se-lects an individual action amt , and receives a team reward,rt, shared among all agents. Tampuu et al. (2015) ad-dress this setting with a framework that combines DQNwith independent Q-learning, applied to two-player pong,in which all agents independently and simultaneously learntheir own Q-functions Qm(s, am; θmi ). While indepen-dent Q-learning can in principle lead to convergence prob-lems (since one agent’s learning makes the environment ap-pear non-stationary to other agents), it has a strong empir-ical track record (Shoham et al., 2007; Shoham & Leyton-Brown, 2009; Zawadzki et al., 2014).
2.3. Deep Recurrent Q-Networks
Both DQN and independent DQN assume full observabil-ity, i.e., the agent receives st as input. By contrast, in par-tially observable environments, st is hidden and instead theagent receives only an observation ot that is correlated withst but in general does not disambiguate it.
Hausknecht & Stone (2015) propose the deep recurrent Q-network (DRQN) architecture to address single-agent, par-tially observable settings. Instead of approximatingQ(s, a)

Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
with a feed-forward network, they approximate Q(o, a)with a recurrent neural network that can maintain an in-ternal state and aggregate observations over time. This canbe modelled by adding an extra input ht−1 that representsthe hidden state of the network, yielding Q(ot, ht−1, a; θi).Thus, DRQN outputs both Qt, and ht, at each time step.DRQN was tested on a partially observable version of ALEin which a portion of the input screens were blanked out.
2.4. Partially Observable Multi-Agent RL
In this work, we consider settings where there are both mul-tiple agents and partial observability: each agent receivesits own private omt at each time step and maintains an inter-nal state hmt . However, we assume that learning can occurin a centralised fashion, i.e., agents can share parameters,etc., during learning so long as the policies they learn con-dition only on their private histories. In other words, weconsider centralised learning of decentralised policies.
We are interested in such settings because it is only whenmultiple agents and partial observability coexist that agentshave the incentive to communicate. Because no communi-cation protocol is given a priori, the agents must first au-tomatically develop and agree upon such a protocol. Toour knowledge, no work on deep RL has considered suchsettings and no work has demonstrated that deep RL cansuccessfully learn communication protocols.
3. DDRQNThe most straightforward approach to deep RL in par-tially observable multi-agent settings is to simply combineDRQN with independent Q-learning, in which case eachagent’s Q-network represents Qm(omt , h
mt−1, a
m; θmi ),which conditions on that agent’s individual hidden state aswell as observation. This approach, which we call the naivemethod, performs poorly, as we show in Section 5.
Instead, we propose deep distributed recurrent Q-networks(DDRQN), which makes three key modifications to thenaive method. The first, last-action input, involves pro-viding each agent with its previous action as input to thenext time step. Since the agents employ stochastic policiesfor the sake of exploration, they should in general condi-tion their actions on their action-observation histories, notjust their observation histories. Feeding the last action asinput allows the RNN to approximate action-observationhistories.
The second, inter-agent weight sharing, involves tying theweights of all agents networks. In effect, only one networkis learned and used by all agents. However, the agents canstill behave differently because they receive different ob-servations and thus evolve different hidden states. In ad-dition, each agent receives its own index m as input, mak-
Algorithm 1 DDRQN
Initialise θ1 and θ−1for each episode e dohm1 = 0 for each agent ms1 = initial state, t = 1while st 6= terminal and t < T do
for each agent m doWith probability ε pick random amtelse amt = argmaxaQ(omt , h
mt−1,m, a
mt−1, a; θi)
Get reward rt and next state st+1, t = t+ 1
∇θ = 0 . reset gradientfor j = t− 1 to 1, −1 do
for each agent m do
ymj ={ rj , if sj terminal, elserj + γmaxaQ(omj+1, h
mj ,m, a
mj , a; θ
−i )
Accumulate gradients for:(ymj −Q(omj , h
mj−1,m, a
mj−1, a
mj ; θi))
2
θi+1 = θi + α∇θ . update parametersθ−i+1 = θ−i + α−(θi+1 − θ−i ) . update target network
ing it easier for agents to specialise. Weight sharing dra-matically reduces the number of parameters that must belearned, greatly speeding learning.
The third, disabling experience replay, simply involvesturning off this feature of DQN. Although experience re-play is helpful in single-agent settings, when multipleagents learn independently the environment appears non-stationary to each agent, rendering its own experience ob-solete and possibly misleading.
Given these modifications, DDRQN learns a Q-function ofthe form Q(omt , h
mt−1,m, a
mt−1, a
mt ; θi). Note that θi does
not condition on m, due to weight sharing, and that amt−1 isa portion of the history while amt is the action whose valuethe Q-network estimates.
Algorithm 1 describes DDRQN. First, we initialise the tar-get and Q-networks. For each episode, we also initialisethe state, s1, the internal state of the agents, hm1 , and am0 .Next, for each time step we pick an action for each agentε-greedily w.r.t. the Q-function. We feed in the previousaction, amt−1, the agent index, m, along with the observa-tion omt and the previous internal state, hmt−1. After allagents have taken their action, we query the environmentfor a state update and reward information.
When we reach the final time step or a terminal state, weproceed to the Bellman updates. Here, for each agent, m,and time step, j, we calculate a target Q-value, ymj , usingthe observed reward, rj , and the discounted target network.We also accumulate the gradients, ∇θ, by regressing theQ-value estimate, Q(omj , h
mj−1,m, a
mj−1, a; θi), against the
target Q-value, ymj , for the action chosen, amj .

Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
Lastly, we conduct two weight updates, first θi in the direc-tion of the accumulated gradients, ∇θ, and then the targetnetwork, θ−i , in the direction of θi.
4. Multi-Agent RiddlesIn this section, we describe the riddles on which we evalu-ate DDRQN.
4.1. Hats Riddle
The hats riddle can be described as follows: “An execu-tioner lines up 100 prisoners single file and puts a red or ablue hat on each prisoner’s head. Every prisoner can seethe hats of the people in front of him in the line - but nothis own hat, nor those of anyone behind him. The execu-tioner starts at the end (back) and asks the last prisonerthe colour of his hat. He must answer “red” or “blue.” Ifhe answers correctly, he is allowed to live. If he gives thewrong answer, he is killed instantly and silently. (While ev-eryone hears the answer, no one knows whether an answerwas right.) On the night before the line-up, the prisonersconfer on a strategy to help them. What should they do?”(Poundstone, 2012). Figure 1 illustrates this setup.
21 3 4 5 6
“Red”Answers:
Prisoners:
Hats:
“Red” Observed hats
?
Figure 1. Hats: Each prisoner can hear the answers from all pre-ceding prisoners (to the left) and see the colour of the hats in frontof him (to the right) but must guess his own hat colour.
An optimal strategy is for all prisoners to agree on a com-munication protocol in which the first prisoner says “blue”if the number of blue hats is even and “red” otherwise (orvice-versa). All remaining prisoners can then deduce theirhat colour given the hats they see in front of them and theresponses they have heard behind them. Thus, everyoneexcept the first prisoner will definitely answer correctly.
To formalise the hats riddle as a multi-agent RL task, wedefine a state space s = (s1, . . . , sn, a1, . . . , an), where nis the total number of agents, sm ∈ {blue, red} is the m-th agent’s hat colour and am ∈ {blue, red} is the action ittook on the m-th step. At all other time steps, agent m canonly take a null action. On the m-th time step, agent m’sobservation is om = (a1, . . . , am−1, sm+1, . . . , sn). Re-ward is zero except at the end of the episode, when it isthe total number of agents with the correct action: rn =∑m I(am = sm). We label only the relevant observation
om and action am of agent m, omitting the time index.
Although this riddle is a single action and observation prob-lem it is still partially observable, given that none of theagents can observe the colour of their own hat.
4.2. Switch Riddle
The switch riddle can be described as follows: “One hun-dred prisoners have been newly ushered into prison. Thewarden tells them that starting tomorrow, each of themwill be placed in an isolated cell, unable to communicateamongst each other. Each day, the warden will choose oneof the prisoners uniformly at random with replacement, andplace him in a central interrogation room containing onlya light bulb with a toggle switch. The prisoner will be ableto observe the current state of the light bulb. If he wishes,he can toggle the light bulb. He also has the option of an-nouncing that he believes all prisoners have visited the in-terrogation room at some point in time. If this announce-ment is true, then all prisoners are set free, but if it is false,all prisoners are executed. The warden leaves and the pris-oners huddle together to discuss their fate. Can they agreeon a protocol that will guarantee their freedom?” (Wu,2002).
Day 1
3 2 3 1
OffOn
OffOn
OffOn
Day 2 Day 3 Day 4
Switch:
Action: On None None Tell
OffOn
Prisoner in IR
:
Figure 2. Switch: Every day one prisoner gets sent to the inter-rogation room where he can see the switch and choose betweenactions “On”, “Off”, “Tell” and “None”.
A number of strategies (Song, 2012; Wu, 2002) have beenanalysed for the infinite time-horizon version of this prob-lem in which the goal is to guarantee survival. One well-known strategy is for one prisoner to be designated thecounter. Only he is allowed to turn the switch off whileeach other prisoner turns it on only once. Thus, when thecounter has turned the switch off n−1 times, he can “Tell”.
To formalise the switch riddle, we define a state spaces = (SWt, IRt, s
1, . . . , sn), where SWt ∈ {on, off} isthe position of the switch, IR ∈ {1 . . . n} is the currentvisitor in the interrogation room and s1, . . . , sn ∈ {0, 1}tracks which agents have already been to the interrogationroom. At time step t, agent m observes omt = (irt, swt),where irt = I(IRt = m), and swt = SWt if the agentis in the interrogation room and null otherwise. If agentm is in the interrogation room then its actions are amt ∈{“On”, “Off”, “Tell”, “None”}; otherwise the only actionis ”None”. The episode ends when an agent chooses “Tell”or when the maximum time step is reached. The reward rt
Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
Q m
m, na 1
+ + +
m, na m-1
m, n
+++
m, ns m+1 s nm, ns k
m, na k
LSTM unrolled for m-1 steps
LSTM unrolled for n-m steps
… …
… …
z a1
z sm+1
z ak
z sk
z am-1
z sn
h a1
h sm+1
h ak
h sk
y am-1
y sn
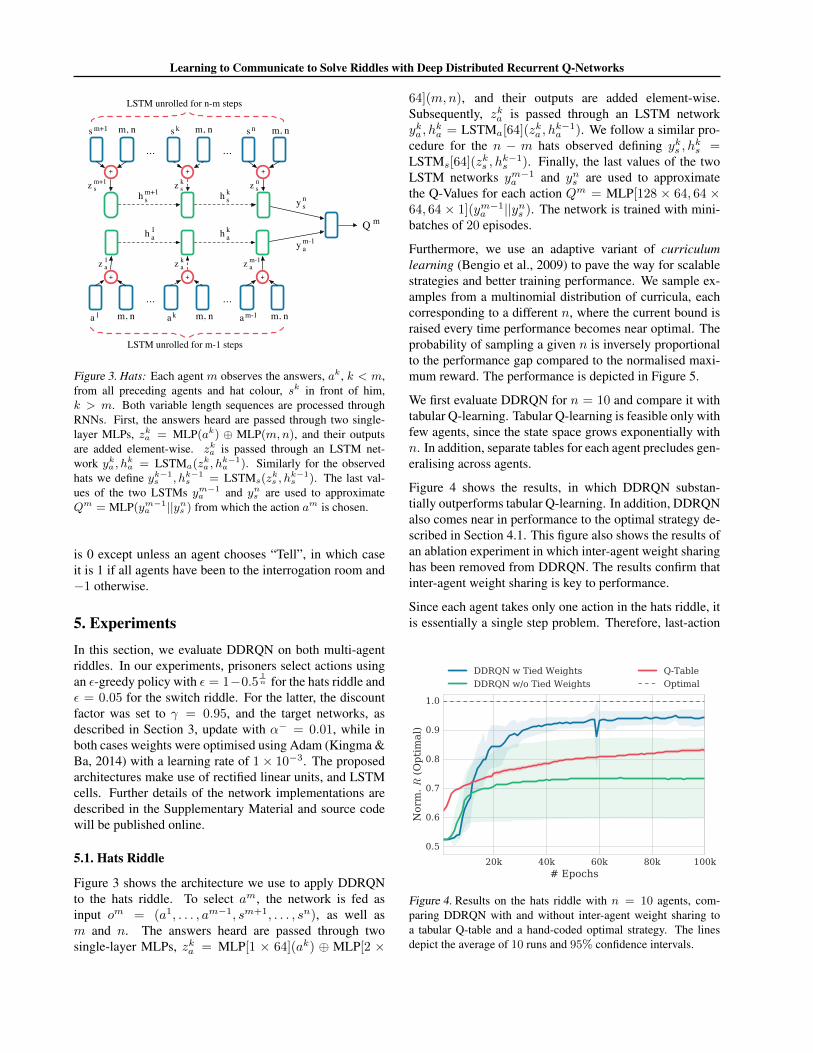
Figure 3. Hats: Each agent m observes the answers, ak, k < m,from all preceding agents and hat colour, sk in front of him,k > m. Both variable length sequences are processed throughRNNs. First, the answers heard are passed through two single-layer MLPs, zka = MLP(ak) ⊕ MLP(m,n), and their outputsare added element-wise. zka is passed through an LSTM net-work yk
a , hka = LSTMa(z
ka , h
k−1a ). Similarly for the observed
hats we define yk−1s , hk−1
s = LSTMs(zks , h
k−1s ). The last val-
ues of the two LSTMs ym−1a and yn
s are used to approximateQm = MLP(ym−1
a ||yns ) from which the action am is chosen.
is 0 except unless an agent chooses “Tell”, in which caseit is 1 if all agents have been to the interrogation room and−1 otherwise.
5. ExperimentsIn this section, we evaluate DDRQN on both multi-agentriddles. In our experiments, prisoners select actions usingan ε-greedy policy with ε = 1−0.5 1
n for the hats riddle andε = 0.05 for the switch riddle. For the latter, the discountfactor was set to γ = 0.95, and the target networks, asdescribed in Section 3, update with α− = 0.01, while inboth cases weights were optimised using Adam (Kingma &Ba, 2014) with a learning rate of 1× 10−3. The proposedarchitectures make use of rectified linear units, and LSTMcells. Further details of the network implementations aredescribed in the Supplementary Material and source codewill be published online.
5.1. Hats Riddle
Figure 3 shows the architecture we use to apply DDRQNto the hats riddle. To select am, the network is fed asinput om = (a1, . . . , am−1, sm+1, . . . , sn), as well asm and n. The answers heard are passed through twosingle-layer MLPs, zka = MLP[1 × 64](ak) ⊕ MLP[2 ×
64](m,n), and their outputs are added element-wise.Subsequently, zka is passed through an LSTM networkyka , h
ka = LSTMa[64](z
ka , h
k−1a ). We follow a similar pro-
cedure for the n − m hats observed defining yks , hks =
LSTMs[64](zks , h
k−1s ). Finally, the last values of the two
LSTM networks ym−1a and yns are used to approximatethe Q-Values for each action Qm = MLP[128 × 64, 64 ×64, 64 × 1](ym−1a ||yns ). The network is trained with mini-batches of 20 episodes.
Furthermore, we use an adaptive variant of curriculumlearning (Bengio et al., 2009) to pave the way for scalablestrategies and better training performance. We sample ex-amples from a multinomial distribution of curricula, eachcorresponding to a different n, where the current bound israised every time performance becomes near optimal. Theprobability of sampling a given n is inversely proportionalto the performance gap compared to the normalised maxi-mum reward. The performance is depicted in Figure 5.
We first evaluate DDRQN for n = 10 and compare it withtabular Q-learning. Tabular Q-learning is feasible only withfew agents, since the state space grows exponentially withn. In addition, separate tables for each agent precludes gen-eralising across agents.
Figure 4 shows the results, in which DDRQN substan-tially outperforms tabular Q-learning. In addition, DDRQNalso comes near in performance to the optimal strategy de-scribed in Section 4.1. This figure also shows the results ofan ablation experiment in which inter-agent weight sharinghas been removed from DDRQN. The results confirm thatinter-agent weight sharing is key to performance.
Since each agent takes only one action in the hats riddle, itis essentially a single step problem. Therefore, last-action
20k 40k 60k 80k 100k# Epochs
0.5
0.6
0.7
0.8
0.9
1.0
Norm
. R
(O
pti
mal)
DDRQN w Tied Weights
DDRQN w/o Tied Weights
Q-Table
Optimal
Figure 4. Results on the hats riddle with n = 10 agents, com-paring DDRQN with and without inter-agent weight sharing toa tabular Q-table and a hand-coded optimal strategy. The linesdepict the average of 10 runs and 95% confidence intervals.

Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
Table 1. Percent agreement on the hats riddle between DDRQNand the optimal parity-encoding strategy.
N % AGREEMENT
3 100.0%5 100.0%8 79.6%
12 52.6%16 50.8%20 52.5%
inputs and disabling experience replay do not play a roleand do not need to be ablated. We consider these compo-nents in the switch riddle in Section 5.2.
We compare the strategies DDRQN learns to the optimalstrategy by computing the percentage of trials in which thefirst agent correctly encodes the parity of the observed hatsin its answer. Table 1 shows that the encoding is almostperfect for n ∈ {3, 5, 8}. For n ∈ {12, 16, 20}, the agentsdo not encode parity but learn a different distributed solu-tion that is nonetheless close to optimal. We believe thatqualitatively this solution corresponds to more the agentscommunicating information about other hats through theiranswers, instead of only the first agent.
5.2. Switch Riddle
Figure 6 illustrates the model architecture used in theswitch riddle. Each agent m is modelled as a recurrentneural network with LSTM cells that is unrolled for Dmax
time-steps, where d denotes the number of days of theepisode. In our experiments, we limit d to Dmax = 4n− 6in order to keep the experiments computationally tractable.
The inputs, omt , amt−1,m and n, are processed through
a 2-layer MLP zmt = MLP[(7 + n) × 128, 128 ×
20k 40k 60k 80k 100k 120k 140k 160k# Epochs
0.5
0.6
0.7
0.8
0.9
1.0
Norm
. R
(O
pti
mal)
n=3 C.L.
n=5 C.L.
n=8 C.L.
n=12 C.L.
n=16 C.L.
n=20 C.L.
n=20
Optimal
Figure 5. Hats: Using Curriculum Learning DDRQN achievesgood performance for n = 3...20 agents, compared to the op-timal strategy.
Q 2m
,sw1 m, n)ir 1m, a 0
m,( ,sw3 m, n)ir 3m, a 2
m ,( ,swDmax m, n)ir Dmax
m , a Dmax -1m ,(
… …
… …
Q 1m Q t
m Q Dmax
mQ 3m
… …
h 1m h 2
m h tm h Dmax -1
m
y 1m y 2
m y 3m y t
m y Dmax
m
z 1m z 2
m z 3m z t
m z Dmax
m
Figure 6. Switch: Agent m receives as input: the switchstate swt, the room he is in, irmt , his last action, am
t−1,his ID, m, and the # of agents, n. At each step,the inputs are processed through a 2-layer MLP zmt =MLP(swt, ir
mt ,OneHot(am
t−1),OneHot(m), n). Their embed-ding zmt is then passed to an LSTM network, ym
t , hmt =
LSTM(zmt , hmt−1), which is used to approximate the agent’s
action-observation history. Finally, the output ymt of the LSTM
is used at each step to compute Qmt = MLP(ym
t ).
128](omt ,OneHot(amt−1),OneHot(m), n). Their embed-ding zmt is then passed an LSTM network, ymt , h
mt =
LSTM[128](zmt , hmt−1), which is used to approximate the
agent’s action-observation history. Finally, the output ymtof the LSTM is used at each step to approximate theQ-values of each action using a 2-layer MLP Qmt =MLP[128 × 128, 128 × 128, 128 × 4](ymt ). As in the hatsriddle, curriculum learning was used for training.
Figure 7, which shows results for n = 3, shows thatDDRQN learns an optimal policy, beating the naive methodand the hand coded strategy, “tell on last day”. This veri-fies that the three modifications of DDRQN substantiallyimprove performance on this task. In following paragraphswe analyse the importance of the individual modifications.
We analysed the strategy that DDRQN discovered for n =3 by looking at 1000 sampled episodes. Figure 8 shows adecision tree, constructed from those samples, that corre-sponds to an optimal strategy allowing the agents to col-lectively track the number of visitors to the interrogationroom. When a prisoner visits the interrogation room afterday two, there are only two options: either one or two pris-oners may have visited the room before. If three prisonershad been, the third prisoner would have already finishedthe game. The two remaining options can be encoded viathe “on” and “off” position respectively. In order to carryout this strategy each prisoner has to learn to keep trackof whether he has visited the cell before and what day itcurrently is.
Figure 9 compares the performance of DDRQN to a variantin which the switch has been disabled. After around 3,500episodes, the two diverge in performance. Hence, there is aclearly identifiable point during learning when the prison-
Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
10k 20k 30k 40k 50k# Epochs
1.0
0.5
0.0
0.5
1.0
Norm
. R
(O
racl
e)
DDRQN
Naive Method
Hand-coded Oracle
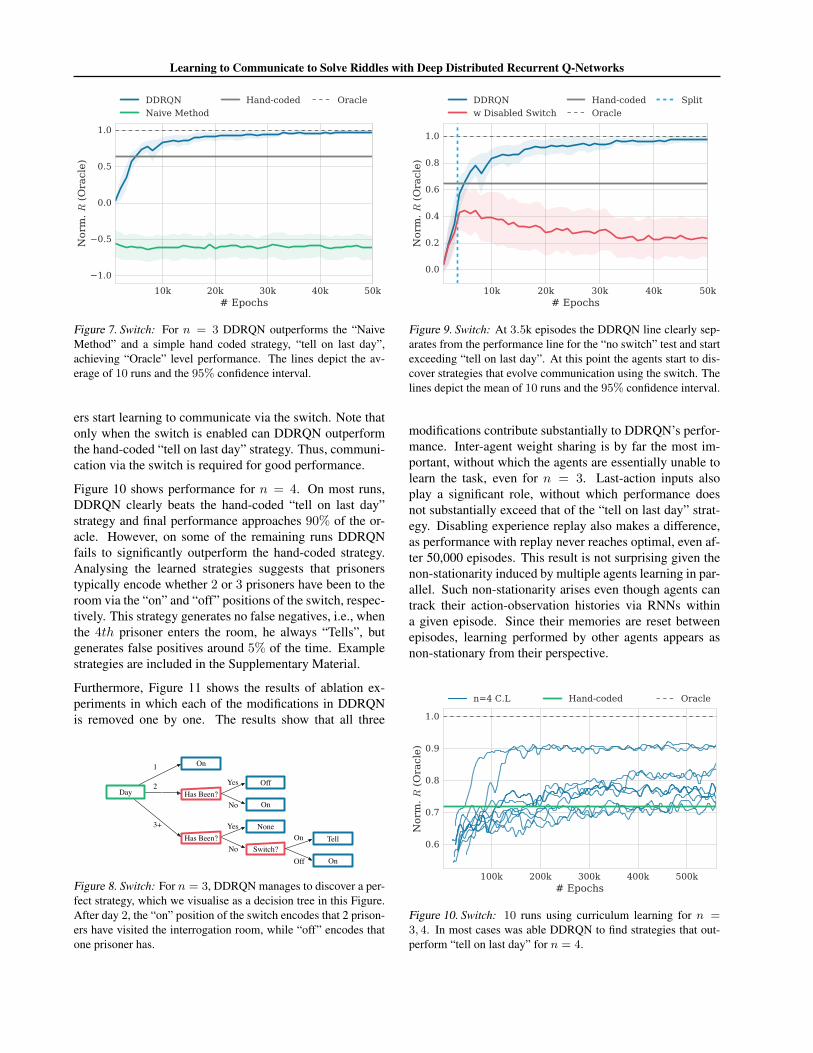
Figure 7. Switch: For n = 3 DDRQN outperforms the “NaiveMethod” and a simple hand coded strategy, “tell on last day”,achieving “Oracle” level performance. The lines depict the av-erage of 10 runs and the 95% confidence interval.
ers start learning to communicate via the switch. Note thatonly when the switch is enabled can DDRQN outperformthe hand-coded “tell on last day” strategy. Thus, communi-cation via the switch is required for good performance.
Figure 10 shows performance for n = 4. On most runs,DDRQN clearly beats the hand-coded “tell on last day”strategy and final performance approaches 90% of the or-acle. However, on some of the remaining runs DDRQNfails to significantly outperform the hand-coded strategy.Analysing the learned strategies suggests that prisonerstypically encode whether 2 or 3 prisoners have been to theroom via the “on” and “off” positions of the switch, respec-tively. This strategy generates no false negatives, i.e., whenthe 4th prisoner enters the room, he always “Tells”, butgenerates false positives around 5% of the time. Examplestrategies are included in the Supplementary Material.
Furthermore, Figure 11 shows the results of ablation ex-periments in which each of the modifications in DDRQNis removed one by one. The results show that all three
OffHas Been?
On
Yes
No
NoneHas Been?
Yes
No Switch?
On
On
Off
Tell
On
Day
1
2
3+
Figure 8. Switch: For n = 3, DDRQN manages to discover a per-fect strategy, which we visualise as a decision tree in this Figure.After day 2, the “on” position of the switch encodes that 2 prison-ers have visited the interrogation room, while “off” encodes thatone prisoner has.
10k 20k 30k 40k 50k# Epochs
0.0
0.2
0.4
0.6
0.8
1.0
Norm
. R
(O
racl
e)
DDRQN
w Disabled Switch
Hand-coded
Oracle
Split
Figure 9. Switch: At 3.5k episodes the DDRQN line clearly sep-arates from the performance line for the “no switch” test and startexceeding “tell on last day”. At this point the agents start to dis-cover strategies that evolve communication using the switch. Thelines depict the mean of 10 runs and the 95% confidence interval.
modifications contribute substantially to DDRQN’s perfor-mance. Inter-agent weight sharing is by far the most im-portant, without which the agents are essentially unable tolearn the task, even for n = 3. Last-action inputs alsoplay a significant role, without which performance doesnot substantially exceed that of the “tell on last day” strat-egy. Disabling experience replay also makes a difference,as performance with replay never reaches optimal, even af-ter 50,000 episodes. This result is not surprising given thenon-stationarity induced by multiple agents learning in par-allel. Such non-stationarity arises even though agents cantrack their action-observation histories via RNNs withina given episode. Since their memories are reset betweenepisodes, learning performed by other agents appears asnon-stationary from their perspective.
100k 200k 300k 400k 500k# Epochs
0.6
0.7
0.8
0.9
1.0
Norm
. R
(O
racl
e)
n=4 C.L Hand-coded Oracle
Figure 10. Switch: 10 runs using curriculum learning for n =3, 4. In most cases was able DDRQN to find strategies that out-perform “tell on last day” for n = 4.

Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
10k 20k 30k 40k 50k# Epochs
0.4
0.2
0.0
0.2
0.4
0.6
0.8
1.0
Norm
. R
(O
racl
e)
DDRQN
w/o Last Action
w/o Tied Weights
w Experience Replay
Hand-coded
Oracle
Figure 11. Switch: Tied weights and last action input are key forthe performance of DDRQN. Experience replay prevents agentsfrom reaching Oracle level. The experiment was executed forn = 3 and the lines depict the average of 10 runs and the 95%confidence interval.
However, it is particularly important in communication-based tasks like these riddles, since the value function forcommunication actions depends heavily on the interpreta-tion of these messages by the other agents, which is in turnset by their Q-functions.
6. Related WorkThere has been a plethora of work on multi-agent rein-forcement learning with communication, e.g., (Tan, 1993;Melo et al., 2011; Panait & Luke, 2005; Zhang & Lesser,2013; Maravall et al., 2013). However, most of this workassumes a pre-defined communication protocol. One ex-ception is the work of Kasai et al. (2008), in which thetabular Q-learning agents have to learn the content of amessage to solve a predator-prey task. Their approach issimilar to the Q-table benchmark used in Section 5.1. Bycontrast, DDRQN uses recurrent neural networks that al-low for memory-based communication and generalisationacross agents.
Another example of open-ended communication learningin a multi-agent task is given in (Giles & Jim, 2002). How-ever, here evolutionary methods are used for learning com-munication protocols, rather than RL. By using deep RLwith shared weights we enable our agents to develop dis-tributed communication strategies and to allow for fasterlearning via gradient based optimisation.
Furthermore, planning-based RL methods have been em-ployed to include messages as an integral part of themulti-agent reinforcement learning challenge (Spaan et al.,2006). However, so far this work has not been extended to
deal with high dimensional complex problems.
In ALE, partial observability has been artificially in-troduced by blanking out a fraction of the inputscreen (Hausknecht & Stone, 2015). Deep recurrentreinforcement learning has also been applied to text-based games, which are naturally partially observable(Narasimhan et al., 2015). Recurrent DQN was also suc-cessful in the email campaign challenge (Li et al., 2015).
However, all these examples apply recurrent DQN insingle-agent domains. Without the combination of multipleagents and partial observability, there is no need to learn acommunication protocol, an essential feature of our work.
7. Conclusions & Future WorkThis paper proposed deep distributed recurrent Q-networks(DDRQN), which enable teams of agents to learn to solvecommunication-based coordination tasks. In order to suc-cessfully communicate, agents in these tasks must first au-tomatically develop and agree upon their own communi-cation protocol. We presented empirical results on twomulti-agent learning problems based on well-known rid-dles, demonstrating that DDRQN can successfully solvesuch tasks and discover elegant communication protocolsto do so. In addition, we presented ablation experimentsthat confirm that each of the main components of theDDRQN architecture are critical to its success.
Future work is needed to fully understand and improvethe scalability of the DDRQN architecture for large num-bers of agents, e.g., for n > 4 in the switch riddle. Wealso hope to further explore the “local minima” structureof the coordination and strategy space that underlies theseriddles. Another avenue for improvement is to extendDDRQN to make use of various multi-agent adaptations ofQ-learning (Tan, 1993; Littman, 1994; Lauer & Riedmiller,2000; Panait & Luke, 2005).
A benefit of using deep models is that they can efficientlycope with high dimensional perceptual signals as inputs. Inthe future this can be tested by replacing the binary repre-sentation of the colour with real images of hats or applyingDDRQN to other scenarios that involve real world data asinput.
While we have advanced a new proposal for using riddlesas a test field for multi-agent partially observable reinforce-ment learning with communication, we also hope that thisresearch will spur the development of further interestingand challenging domains in the area.

Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
8. AcknowledgementsThis work was supported by the Oxford-Google DeepMindGraduate Scholarship and the EPSRC.
ReferencesAssael, J.-A. M, Wahlstrom, N., Schon, T. B., and Deisen-
roth, M. p. Data-efficient learning of feedback policiesfrom image pixels using deep dynamical models. arXivpreprint arXiv:1510.02173, 2015.
Ba, J., Mnih, V., and Kavukcuoglu, K. Multiple objectrecognition with visual attention. In ICLR, 2015.
Bellemare, M. G., Ostrovski, G., Guez, A., Thomas, P. S.,and Munos, R. Increasing the action gap: New operatorsfor reinforcement learning. In AAAI, 2016.
Bengio, Y., Louradour, J., Collobert, R., and Weston, J.Curriculum learning. In ICML, pp. 41–48, 2009.
Cao, Y., Yu, W., Ren, W., and Chen, G. An overview of re-cent progress in the study of distributed multi-agent co-ordination. IEEE Transactions on Industrial Informatics,9(1):427–438, 2013.
Fox, D., Burgard, W., Kruppa, H., and Thrun, S. Prob-abilistic approach to collaborative multi-robot localiza-tion. Autonomous Robots, 8(3):325–344, 2000.
Gerkey, B.P. and Matari, M.J. A formal analysis and tax-onomy of task allocation in multi-robot systems. Inter-national Journal of Robotics Research, 23(9):939–954,2004.
Giles, C. L. and Jim, K. C. Learning communication formulti-agent systems. In Innovative Concepts for Agent-Based Systems, pp. 377–390. Springer, 2002.
Guo, X., Singh, S., Lee, H., Lewis, R. L., and Wang, X.Deep learning for real-time Atari game play using offlineMonte-Carlo tree search planning. In NIPS, pp. 3338–3346. 2014.
Hausknecht, M. and Stone, P. Deep recurrent Q-learning for partially observable MDPs. arXiv preprintarXiv:1507.06527, 2015.
Hochreiter, S. and Schmidhuber, J. Long short-term mem-ory. Neural computation, 9(8):1735–1780, 1997.
Kasai, T., Tenmoto, H., and Kamiya, A. Learning of com-munication codes in multi-agent reinforcement learningproblem. In IEEE Conference on Soft Computing in In-dustrial Applications, pp. 1–6, 2008.
Kingma, D. and Ba, J. Adam: A method for stochasticoptimization. arXiv preprint arXiv:1412.6980, 2014.
Lauer, M. and Riedmiller, M. An algorithm for distributedreinforcement learning in cooperative multi-agent sys-tems. In ICML, 2000.
Levine, S., Finn, C., Darrell, T., and Abbeel, P. End-to-end training of deep visuomotor policies. arXiv preprintarXiv:1504.00702, 2015.
Li, X., Li, L., Gao, J., He, X., Chen, J., Deng, L., and He,J. Recurrent reinforcement learning: A hybrid approach.arXiv preprint 1509.03044, 2015.
Lin, L.J. Reinforcement learning for robots using neu-ral networks. PhD thesis, School of Computer Science,Carnegie Mellon University, 1993.
Littman, M. L. Markov games as a framework for multi-agent reinforcement learning. In International Confer-ence on Machine Learning (ICML), pp. 157–163, 1994.
Maddison, C. J., Huang, A., Sutskever, I., and Silver, D.Move Evaluation in Go Using Deep Convolutional Neu-ral Networks. In ICLR, 2015.
Maravall, D., De Lope, J., and Domnguez, R. Coordina-tion of communication in robot teams by reinforcementlearning. Robotics and Autonomous Systems, 61(7):661–666, 2013.
Matari, M.J. Reinforcement learning in the multi-robot do-main. Autonomous Robots, 4(1):73–83, 1997.
Melo, F. S., Spaan, M., and Witwicki, S. J. QueryPOMDP:POMDP-based communication in multiagent systems.In Multi-Agent Systems, pp. 189–204. 2011.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Ve-ness, J., Bellemare, M. G., Graves, A., Riedmiller, M.,Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C.,Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wier-stra, D., Legg, S., and Hassabis, D. Human-level con-trol through deep reinforcement learning. Nature, 518(7540):529–533, 2015.
Nair, A., Srinivasan, P., Blackwell, S., Alcicek, C.,Fearon, R., Maria, A. De, Panneershelvam, V., Suley-man, M., Beattie, C., Petersen, S., Legg, S., Mnih,V., Kavukcuoglu, K., and Silver, D. Massively paral-lel methods for deep reinforcement learning. In DeepLearning Workshop, ICML, 2015.
Narasimhan, K., Kulkarni, T., and Barzilay, R. Lan-guage understanding for text-based games using deep re-inforcement learning. In EMNLP, 2015.
Oh, J., Guo, X., Lee, H., Lewis, R. L., and Singh,S. Action-conditional video prediction using deep net-works in Atari games. In NIPS, pp. 2845–2853, 2015.

Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
Olfati-Saber, R., Fax, J.A., and Murray, R.M. Consensusand cooperation in networked multi-agent systems. Pro-ceedings of the IEEE, 95(1):215–233, 2007.
Panait, L. and Luke, S. Cooperative multi-agent learning:The state of the art. Autonomous Agents and Multi-AgentSystems, 11(3):387–434, 2005.
Poundstone, W. Are You Smart Enough to Work atGoogle?: Fiendish Puzzles and Impossible InterviewQuestions from the World’s Top Companies. OneworldPublications, 2012.
Schaul, T., Quan, J., Antonoglou, I., and Silver, D. Priori-tized experience replay. In ICLR, 2016.
Shoham, Y. and Leyton-Brown, K. Multiagent Systems:Algorithmic, Game-Theoretic, and Logical Foundations.Cambridge University Press, New York, 2009.
Shoham, Y., Powers, R., and Grenager, T. If multi-agentlearning is the answer, what is the question? ArtificialIntelligence, 171(7):365–377, 2007.
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L.,van den Driessche, G., Schrittwieser, J., Antonoglou, I.,Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe,D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap,T., Leach, M., Kavukcuoglu, K., Graepel, T., and Has-sabis, D. Mastering the game of Go with deep neuralnetworks and tree search. Nature, 529(7587):484–489,2016.
Song, Y. 100 prisoners and a light bulb. Technical report,University of Washington, 2012.
Spaan, M., Gordon, G. J., and Vlassis, N. Decentralizedplanning under uncertainty for teams of communicatingagents. In International joint conference on Autonomousagents and multiagent systems, pp. 249–256, 2006.
Stadie, B. C., Levine, S., and Abbeel, P. Incentivizing ex-ploration in reinforcement learning with deep predictivemodels. arXiv preprint arXiv:1507.00814, 2015.
Sutton, R. S. and Barto, A. G. Introduction to reinforce-ment learning. MIT Press, 1998.
Tampuu, A., Matiisen, T., Kodelja, D., Kuzovkin, I., Kor-jus, K., Aru, J., Aru, J., and Vicente, R. Multiagent coop-eration and competition with deep reinforcement learn-ing. arXiv preprint arXiv:1511.08779, 2015.
Tan, M. Multi-agent reinforcement learning: Independentvs. cooperative agents. In ICML, 1993.
van Hasselt, H., Guez, A., and Silver, D. Deep reinforce-ment learning with double Q-learning. In AAAI, 2016.
Wang, Z., de Freitas, N., and Lanctot, M. Dueling networkarchitectures for deep reinforcement learning. arXivpreprint 1511.06581, 2015.
Watter, M., Springenberg, J. T., Boedecker, J., and Ried-miller, M. A. Embed to control: A locally linear latentdynamics model for control from raw images. In NIPS,2015.
Wu, W. 100 prisoners and a lightbulb. Technical report,OCF, UC Berkeley, 2002.
Zawadzki, E., Lipson, A., and Leyton-Brown, K. Empir-ically evaluating multiagent learning algorithms. arXivpreprint 1401.8074, 2014.
Zhang, C. and Lesser, V. Coordinating multi-agent rein-forcement learning with limited communication. vol-ume 2, pp. 1101–1108, 2013.