learning qualitative spatial relations for robotic … · learning qualitative spatial relations...
TRANSCRIPT

Learning Qualitative Spatial Relations for Robotic Navigation
Abdeslam BoulariasDepartment of Computer Science
Rutgers University
Felix DuvalletEcole Polytechnique
Federale de Lausanne (EPFL)
Jean Oh and Anthony Stentz⇤Robotics Institute
Carnegie Mellon University
AbstractWe consider the problem of robots following nat-ural language commands through previously un-known outdoor environments. A robot receivescommands in natural language, such as “Navigatearound the building to the car left of the fire hydrantand near the tree.” The robot needs first to classifyits surrounding objects into categories, using im-ages obtained from its sensors. The result of thisclassification is a map of the environment, whereeach object is given a list of semantic labels, such as“tree” or “car”, with varying degrees of confidence.Then, the robot needs to ground the nouns in thecommand, i.e., mapping each noun in the commandinto a physical object in the environment. The robotneeds also to ground a specified navigation mode,such as “navigate quickly” or “navigate covertly”,as a cost map. In this work, we show how to groundnouns and navigation modes by learning from ex-amples demonstrated by humans.
1 IntroductionWe consider the problem of commanding mobile robots inunknown, semi-structured, outdoor environments using nat-ural language. This problem arises in human-robot teams,where natural language is a favored communication means.Therefore, robots need to understand the environment fromthe standpoint of their human teammates, and to translate in-structions received in natural language into plans.
For example, to execute the command “Navigate aroundthe building to the car that is left of the fire hydrant and nearthe tree”, the robot needs to find out which objects in the en-vironment are meant by “building” and “car”, and to plan apath accordingly. To accomplish this goal, the robot needs toground all the nouns in the command (“building”, “car”, “firehydrant” and “tree”) into specific objects in the environment,and to interpret the spatial relations (“left of” and “near”) andthe navigation mode (“around”).
The robot must first recognize the objects in the environ-ment and to label them. We use the semantic perception
⇤This work was done while all the authors were with the RoboticsInstitute of Carnegie Mellon University.
Commands:- “Navigate to the building behind the pole.”- “Navigate covertly to the grass in front of
the building.”- “Navigate near the building to the car left
of the building and right of the pole.”
Figure 1: ClearpathTM Husky robot used in the experiments
method proposed in [Munoz, 2013] which has been proveneffective in outdoor environments [Munoz et al., 2010]. Thesemantic perception module receives scene images from a 2Dcamera and classifies each object into categories with differ-ent confidence values.
Grounding is performed by combining the labels obtainedfrom semantic perception with the spatial relations obtainedfrom parsing the command. There are three types of uncer-tainty that make grounding a challenging task. First, objectsare often misclassified because of occlusions and noise in thesensory input. Classification errors also occur when the envi-ronment contains objects that are significantly different fromthe ones used for training the classifier. Second, the com-mands can be ambiguous, i.e., multiple objects may satisfythe constraints in a given command. Third, spatial relationsare often subjectively interpreted. People have different viewson what “left of a building” is, for example.
To trade off these uncertainties, we use a Bayesian modelfor grounding. Our approach is based on using the confidencevalues of the perception as a prior distribution on the true cat-egory of each object. A posterior joint distribution on the ob-jects is computed based on how well each object satisfies thespatial constraints. A key component of this model is a func-tion that maps two objects and a spatial relation into a prob-ability. This function is learned from annotated examples.We also learn a function that maps a navigation mode into acost map for path planning, using Imitation Learning [Ratliffet al., 2006]. Learning by imitation enables the robot to in-
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16)
4130

terpret commands according to the subjective definitions ofits human user. Moreover, navigation modes as “navigatecovertly” do not have clear definitions that can be used forhandcrafting a path cost function.
Finally, we compute a joint distribution on goal objects andon landmark objects used for specifying a navigation mode,so that results with small path costs have high probabilities.For path planning, we use the cost map based planner, PMAPwith Field D* [Stentz, 1994; Ferguson and Stentz, 2005;Gonzalez et al., 2006; Stentz and Naggy, 2007]. The plan ofthe grounding result with the highest probability is executedby the robot. For more technical details on this work, we re-fer the reader to the longer version of this paper [Boulariaset al., 2015] and the intelligence architecture paper [Oh et al.,2015] that describes how symbol grounding is used in seman-tic navigation.
2 Related WorkThe challenge of building human-robot interfaces using natu-ral language generated a large body of work [Harnad, 1990;MacMahon et al., 2006; Matuszek et al., 2012b; Zenderet al., 2009; Dzifcak et al., 2009; Golland et al., 2010;Tellex et al., 2011; Kollar et al., 2010; Tellex et al., 2012;Walter et al., 2013; Matuszek et al., 2012a; Guadarrama etal., 2013]. A full review of the related works is beyond thescope of this paper, so we highlight here some relevant ex-amples. Symbol grounding was first formulated in [Harnad,1990] as the problem of mapping words (symbols) into man-ifestations in the physical world. The Generalized Ground-ing Graphs (G3) [Tellex et al., 2011] is a generic frameworkthat casts symbol grounding as a learning and inference prob-lem in a Conditional Random Field. The same type of spatialrelation clauses presented in [Kollar et al., 2010] and usedin [Tellex et al., 2011] are used in the current work. Thenavigation system described in [Walter et al., 2013], alsobased on G3, incorporates odometry and path constraints ingrounding, which is conceptually comparable to our use ofperception confidence and path costs in grounding. Guadar-rama et al. [Guadarrama et al., 2013] presented a system forhuman-robot interaction that also learns both models for spa-tial prepositions and for object recognition. However, simplerelations were considered and perception uncertainty was nottaken into account.
3 Tactical Behavior Specification GrammarThe Tactical Behavior Specification (TBS) language is de-fined to instruct a robot to perform tactical behavior includingnavigation, searching for an object or observation. The lan-guage is specifically focused on describing desired behaviorusing spatial relationships with objects in an environment. Inthis paper, we focus on the navigate action, where the maincomponents of a command are a goal and a navigation mode.An object (or a symbol) referenced in a command can be as-sociated with a spatial constraint relative to other objects. Forinstance, in a command “Navigate covertly to a fire hydrantbehind the building,” a goal is to reach a fire hydrant, “be-hind the building” is a goal constraint, and “covertly” is thenavigation mode. Often, the navigation mode also refers to
an object. For instance, the navigation mode in “Navigatearound the car to a fire hydrant behind the building” refers toan object named “car,” which can also have its own spatialconstraints that are independent from the constraints of thegoal named “fire hydrant.”
4 Navigation Mode GroundingOnce the landmarks have been grounded and the position ofthe goal has been determined, the robot must plan a path fromits current position to the given goal location that obeys thepath constraints imposed in the command. Path constraintsdescribe a navigation mode. For example, the user may spec-ify that the robot should stay “left of the building,” or navi-gate “covertly”. We return to the object grounding questionin Section 5: “Which building should the robot stay left of?”
Path constraints are subjective and explicitly writing downa cost function that encapsulates them would be time con-suming due to the many trade-offs inherently present in theplanning problem. For example, the robot must trade off pathlength with distance from the building. A covert navigationbehavior may look different to different people. We insteaduse Imitation Learning to learn how to navigate between astart and end position using examples of desired behavior.
We treat understanding spatial language as learning a map-ping from terms (such as “left of,” “around,” or “covertly”)to a cost function c which can be used to generate a matrixof costs known as a cost map. A planner can then optimizeto produce the minimum cost path under this cost function.Given term � (such as “left of”) in the command specifyingthe navigation mode, the robot solves the planning problemof finding the minimum cost path ⇠⇤ under cost function c
�
:⇠⇤ = argmin
⇠2⌅c�
(⇠) = argmin
⇠2⌅wT
�
� (⇠) (1)
where the set of valid paths is ⌅, and we assume that the costfunction c
�
takes the form of a linear sum of features � underweights w
�
. The features describe the shape of the path, thegeometry of the landmark, and the relationship between thetwo [Tellex et al., 2011]. We use imitation learning to learnthe weights w
�
from a set of demonstrated paths {ˆ⇠i
}N1 .To learn the weights w
�
, we minimize the difference be-tween the cost of the expert’s demonstrated path ˆ⇠ and theminimum cost path under the current cost function:
`⇣w
�
, ˆ⇠⌘= wT
�
�(ˆ⇠)�min
⇠2⌅wT
�
� (⇠) +�
2
kw�
k2 (2)
under our regularization parameter �. The first term in Equa-tion 2 is the cost of the demonstrated path under the currentcost function, and the second term is the cost of the optimalpath (again, under the current cost function). Note that weare omitting the loss-augmentation term for clarity. Ignoringregularization, we achieve zero loss when the cost functionproduces the expert’s path. This loss is optimized using thesub-gradient technique [Ratliff et al., 2006].
Figure 2 shows the learned cost function for the rela-tion “left of,” and Figure 3 shows the training examples andlearned cost function for “covert” navigation, along with theminimum cost path for a given start and end. Note that welearned to avoid being in the center area between the rows ofbuildings, and the planner took a sharper path across.
4131
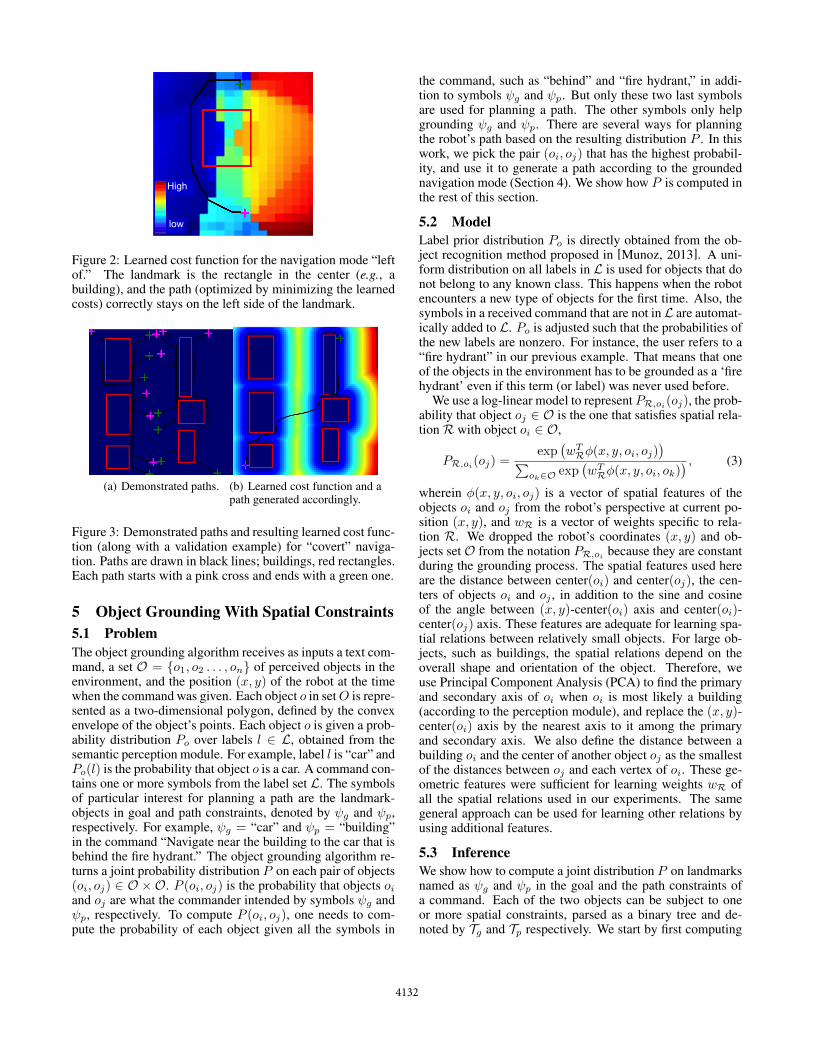
High
low
Figure 2: Learned cost function for the navigation mode “leftof.” The landmark is the rectangle in the center (e.g., abuilding), and the path (optimized by minimizing the learnedcosts) correctly stays on the left side of the landmark.
(a) Demonstrated paths. (b) Learned cost function and apath generated accordingly.
Figure 3: Demonstrated paths and resulting learned cost func-tion (along with a validation example) for “covert” naviga-tion. Paths are drawn in black lines; buildings, red rectangles.Each path starts with a pink cross and ends with a green one.
5 Object Grounding With Spatial Constraints5.1 ProblemThe object grounding algorithm receives as inputs a text com-mand, a set O = {o1, o2 . . . , on} of perceived objects in theenvironment, and the position (x, y) of the robot at the timewhen the command was given. Each object o in set O is repre-sented as a two-dimensional polygon, defined by the convexenvelope of the object’s points. Each object o is given a prob-ability distribution P
o
over labels l 2 L, obtained from thesemantic perception module. For example, label l is “car” andPo
(l) is the probability that object o is a car. A command con-tains one or more symbols from the label set L. The symbolsof particular interest for planning a path are the landmark-objects in goal and path constraints, denoted by
g
and p
,respectively. For example,
g
= “car” and p
= “building”in the command “Navigate near the building to the car that isbehind the fire hydrant.” The object grounding algorithm re-turns a joint probability distribution P on each pair of objects(o
i
, oj
) 2 O ⇥O. P (oi
, oj
) is the probability that objects oi
and oj
are what the commander intended by symbols g
and p
, respectively. To compute P (oi
, oj
), one needs to com-pute the probability of each object given all the symbols in
the command, such as “behind” and “fire hydrant,” in addi-tion to symbols
g
and p
. But only these two last symbolsare used for planning a path. The other symbols only helpgrounding
g
and p
. There are several ways for planningthe robot’s path based on the resulting distribution P . In thiswork, we pick the pair (o
i
, oj
) that has the highest probabil-ity, and use it to generate a path according to the groundednavigation mode (Section 4). We show how P is computed inthe rest of this section.
5.2 ModelLabel prior distribution P
o
is directly obtained from the ob-ject recognition method proposed in [Munoz, 2013]. A uni-form distribution on all labels in L is used for objects that donot belong to any known class. This happens when the robotencounters a new type of objects for the first time. Also, thesymbols in a received command that are not in L are automat-ically added to L. P
o
is adjusted such that the probabilities ofthe new labels are nonzero. For instance, the user refers to a“fire hydrant” in our previous example. That means that oneof the objects in the environment has to be grounded as a ‘firehydrant’ even if this term (or label) was never used before.
We use a log-linear model to represent PR,oi(oj), the prob-ability that object o
j
2 O is the one that satisfies spatial rela-tion R with object o
i
2 O,
PR,oi(oj) =exp
�wT
R�(x, y, oi, oj)�
Pok2O exp
�wT
R�(x, y, oi, ok)� , (3)
wherein �(x, y, oi
, oj
) is a vector of spatial features of theobjects o
i
and oj
from the robot’s perspective at current po-sition (x, y), and wR is a vector of weights specific to rela-tion R. We dropped the robot’s coordinates (x, y) and ob-jects set O from the notation PR,oi because they are constantduring the grounding process. The spatial features used hereare the distance between center(o
i
) and center(oj
), the cen-ters of objects o
i
and oj
, in addition to the sine and cosineof the angle between (x, y)-center(o
i
) axis and center(oi
)-center(o
j
) axis. These features are adequate for learning spa-tial relations between relatively small objects. For large ob-jects, such as buildings, the spatial relations depend on theoverall shape and orientation of the object. Therefore, weuse Principal Component Analysis (PCA) to find the primaryand secondary axis of o
i
when oi
is most likely a building(according to the perception module), and replace the (x, y)-center(o
i
) axis by the nearest axis to it among the primaryand secondary axis. We also define the distance between abuilding o
i
and the center of another object oj
as the smallestof the distances between o
j
and each vertex of oi
. These ge-ometric features were sufficient for learning weights wR ofall the spatial relations used in our experiments. The samegeneral approach can be used for learning other relations byusing additional features.
5.3 InferenceWe show how to compute a joint distribution P on landmarksnamed as
g
and p
in the goal and the path constraints ofa command. Each of the two objects can be subject to oneor more spatial constraints, parsed as a binary tree and de-noted by T
g
and Tp
respectively. We start by first computing
4132

a distribution on the objects in O for each label mentionedin the command. The object distribution, denoted by P
l
forlabel l, is computed from the label distributions P
o
(availablefrom semantic perception) using Bayes’ rule and a uniformprior. The next step consists in computing two distributionson goal and path landmarks, denoted as PTg and PTp , fromthe spatial constraints in trees T
g
and Tp
. The trees are tra-versed in a post-order depth-first search, which correspondsto reading the constraints in a reverse Polish notation. Thelogical operators (“and,” “or,” “not”) are in the internal nodesof the tree, whereas the atomic spatial constraints (“behindbuilding,” “near car,” etc.) are in the leaves.
5.4 LearningGiven a weight vector wR, probability PR,oi(oj) (Equa-tion 3) indicates how likely a human user would choose o
j
among all objects in a set O as the one that satisfies R(oi
, oj
).Because of perception uncertainties, estimating PR,oi(oj) foreach object o
j
is more important than simply finding the ob-ject that most satisfies relation R with o
j
.We used twenty examples for learning the spatial rela-
tions R 2 {“left”, “right”, “front”, “behind”,“near”,“away”}.Each example i contains a set of objects in a simulated en-vironment, a position (x
i
, yj
) of the robot, a command withspatial constraints, in addition to the best answer o⇤
i
accordingto a human teacher. Weight vector wR of each relation R isobtained by maximizing the log-likelihood of all the trainingexamples using gradient descent, with the l1 regularizationfor sparsifying the weights [Bishop, 2006].
6 Experiments6.1 Simulation experimentsThese experiments are a study involving three uninformedhuman subjects. We created a world model with eleven ob-jects: a building, two cars, six traffic cones and two un-known objects. We used five simple commands and five com-plex commands. Each command contains a navigation mode(“quickly” or “covertly”) with a spatial constraint of the path,in addition to a spatial constraint of the goal. Complex com-mands contain additional goal constraints. Participants wereseparately asked to point to the goal they would choose for ex-ecuting each command. The best answer, chosen by a major-ity vote, is compared to the robot’s answer. Table 1 shows thatthe robot’s answer matches with the best answer in 80% of thecommands. A robot’s answer is counted as valid if it matchesthe answer of at least one participant. All the grounded goalswere valid in this study. We also report the consensus ratethat is the percentage of commands where all the three par-ticipants agreed on one answer. The low rates of consensusclearly show the advantage of customized human-robot inter-faces that can learn from users. For instance, one participantinterpreted “front of a building” as the side where the carswere located. Similarly, we asked each participant to classifythe robot’s path as conform to the navigation mode (style)and constraints or as non-conform. The mode was classifiedas conform by the majority of the participants in only 60%
of the commands. We noticed that the participants had alldifferent definitions of what it means to navigate covertly.
Simple ComplexBest goal 80% 80%Valid goal 100% 100%
Consensus 40% 20%
Best navigation mode 60% 60%Valid navigation mode 100% 100%
Consensus 60% 60%
Table 1: Comparing the learned model to human subjects, us-ing simple and complex commands. Navigation mode refersto style. Notice how low is the consensus among the subjectson the best answers, which are chosen by a majority vote.
6.2 Robot experimentsWe performed extensive experiments using the robotic plat-form shown in Figure 1. The robot’s environment containedmainly buildings, cars, traffic cones, fire hydrants, and a gaspump. We evaluated the performance of the learned ground-ing model in five different scenes. In each scene, we used fivesimple commands and five complex ones. The total numberof test scenarios is then 50. In each test scenario, we selecta goal and a navigation mode (style), send a command to therobot, and rate the planned path as a success if it matches theselected goal and mode, and as a failure otherwise. Over-all, we notice that complex commands help finding the rightgoals because they are less ambiguous than simple commands(88±11 vs. 84±17 success rate).
7 ConclusionTo become useful teammates, robots will need to understandnatural language commands given to them. This problem ishighly challenging when the environment is unknown. Spa-tial navigation and relations are one type of subjective lin-guistic concepts that robots can learn from human users. Ourapproach to solving this problem uses imitation learning forlearning navigation modes, and a probabilistic model for trad-ing off perception uncertainties with spatial constraints. Em-pirical evaluations show that the human-robot interface builtusing the proposed approach is an efficient tool for command-ing mobile robots.
AcknowledgmentThis work was conducted in part through collaborative par-ticipation in the Robotics Consortium sponsored by the U.SArmy Research Laboratory under the Collaborative Technol-ogy Alliance Program, Cooperative Agreement W911NF-10-2-0016, and in part by ONR under MURI grant “Reasoningin Reduced Information Spaces” (no. N00014-09-1-1052).The views and conclusions contained in this document arethose of the authors and should not be interpreted as repre-senting the official policies, either expressed or implied, ofthe Army Research Laboratory of the U.S. Government. TheU.S. Government is authorized to reproduce and distributereprints for Government purposes notwithstanding any copy-right notation herein.
4133

References[Bishop, 2006] Christopher M. Bishop. Pattern Recognition
and Machine Learning (Information Science and Statis-tics). Springer-Verlag New York, Inc., Secaucus, NJ, USA,2006.
[Boularias et al., 2015] Abdeslam Boularias, Felix Duvallet,Jean Oh, and Anthony Stentz. Grounding spatial relationsfor outdoor robot navigation. In IEEE International Con-ference on Robotics and Automation, ICRA 2015, Seattle,WA, USA, 26-30 May 2015, 2015.
[Dzifcak et al., 2009] Juraj Dzifcak, Matthias Scheutz,Chitta Baral, and Paul W. Schermerhorn. What to doand how to do it: Translating natural language directivesinto temporal and dynamic logic representation for goalmanagement and action execution. In Proceedings ofthe IEEE International Conference on Robotics andAutomation (ICRA), pages 4163–4168, 2009.
[Ferguson and Stentz, 2005] David Ferguson and AnthonyStentz. Field D*: an interpolation-based path planner andreplanner. In Proceedings of the International Symposiumon Robotics Research (ISRR), October 2005.
[Golland et al., 2010] Dave Golland, Percy Liang, and DanKlein. A game-theoretic approach to generating spatial de-scriptions. In Proceedings of the 2010 Conference on Em-pirical Methods in Natural Language Processing, pages410–419, 2010.
[Gonzalez et al., 2006] Juan Pablo Gonzalez, Bryan Nagy,and Anthony Stentz. The geometric path planner for nav-igating unmanned vehicles in dynamic environments. InProceedings of the 1st Joint Emergency Preparedness andResponse and Robotic and Remote Systems, 2006.
[Guadarrama et al., 2013] Sergio Guadarrama, Lorenzo Ri-ano, Dave Golland, Daniel Gouhring, Yangqing Jia, DanKlein, Pieter Abbeel, and Trevor Darrell. Grounding spa-tial relations for human-robot interaction. In Proceedingsof the 26th IEEE International Conference on IntelligentRobots and Systems (IROS), pages 1640–1647, 2013.
[Harnad, 1990] Stevan Harnad. The symbol grounding prob-lem. Physica D, 42:335–346, 1990.
[Kollar et al., 2010] Thomas Kollar, Stefanie Tellex, DebRoy, and Nicholas Roy. Toward understanding nat-ural language directions. In Proceedings of the 5thACM/IEEE International Conference on Human-robot In-teraction (HRI), pages 259–266, 2010.
[MacMahon et al., 2006] Matt MacMahon, BrianStankiewicz, and Benjamin Kuipers. Walk the Talk:Connecting Language, Knowledge, and Action in RouteInstructions. In National Conference on ArtificialIntelligence, 2006.
[Matuszek et al., 2012a] Cynthia Matuszek, NicholasFitzgerald, Luke Zettlemoyer, Liefeng Bo, and DieterFox. A joint model of language and perception forgrounded attribute learning. In Proceedings of the 29thInternational Conference on Machine Learning (ICML),pages 1671–1678, 2012.
[Matuszek et al., 2012b] Cynthia Matuszek, Evan Herbst,Luke Zettlemoyer, and Dieter Fox. Learning to Parse Nat-ural Language Commands to a Robot Control System. InInternational Symposium on Experimental Robotics, 2012.
[Munoz et al., 2010] Daniel Munoz, J. Andrew Bagnell, andMartial Hebert. Stacked Hierarchical Labeling. In Pro-ceedings of the European Conference on Computer Vision(ECCV), 2010.
[Munoz, 2013] Daniel Munoz. Inference Machines: ParsingScenes via Iterated Predictions. PhD thesis, The RoboticsInstitute, Carnegie Mellon University, June 2013.
[Oh et al., 2015] Jean Oh, Arne Suppe, Felix Duvallet,Abdeslam Boularias, Jerry Vinokurov, Luis Navarro-Serment, Oscar Romero, Robert Dean, Christian Lebiere,Martial Hebert, and Anthony Stentz. Toward MobileRobots Reasoning Like Humans. In Proceedings of the29th AAAI Conference on Artificial Intelligence, 2015.
[Ratliff et al., 2006] Nathan D. Ratliff, J. Andrew Bagnell,and Martin A. Zinkevich. Maximum Margin Planning. InProceedings of the International Conference on MachineLearning, 2006.
[Stentz and Naggy, 2007] Anthony Stentz and Bryan Naggy.PMAP User’s Guide. National Robotics Engineering Cen-ter, Carnegie Mellon University, 1.0 edition, Mar. 2007.
[Stentz, 1994] Anthony Stentz. Optimal and efficient pathplanning for partially-known environments. In Proceed-ings of IEEE International Conference on Robotics andAutomation (ICRA), pages 3310–3317, 1994.
[Tellex et al., 2011] Stefanie Tellex, Thomas Kollar, StevenDickerson, Matthew R Walter, Ashis Gopal Banerjee,Seth J Teller, and Nicholas Roy. Understanding natu-ral language commands for robotic navigation and mobilemanipulation. In Proceedings of the 25th AAAI Conferenceon Artificial Intelligence, 2011.
[Tellex et al., 2012] Stefanie Tellex, Pratiksha Thaker, RobinDeits, Thomas Kollar, and Nicholas Roy. Toward informa-tion theoretic human-robot dialog. In Robotics: Scienceand Systems IIX, 2012.
[Walter et al., 2013] Matthew R. Walter, SachithraHemachandra, Bianca Homberg, Stefanie Tellex, andSeth J. Teller. Learning semantic maps from naturallanguage descriptions. In Robotics: Science and SystemsIX, 2013.
[Zender et al., 2009] Hendrik Zender, Geert-Jan M. Kruijff,and Ivana Kruijff-Korbayova. Situated resolution and gen-eration of spatial referring expressions for robotic assis-tants. In Proceedings of the Twenty-First InternationalJoint Conference on Artificial Intelligence (IJCAI), pages1604–1609, 2009.
4134