large scale data with hadoop
TRANSCRIPT

LARGE SCALE DATA WITH HADOOPGalen Riley and Josh Patterson
Presented at DevChatt 2010

Agenda
Thinking at Scale Hadoop Architecture
Distributed File SystemMapReduce Programming Model
Examples

Data is Big
The Data Deluge (2/25/2010)“Eighteen months ago, Li & Fung, a firm that
manages supply chains for retailers, saw 100 gigabytes of information flow through its network each day. Now the amount has increased tenfold.”http://www.economist.com/opinion/displaystory.cfm?story_id=15579717

Data is Big
Sensor data collection128 sensors37 GB/day
○ 10 bytes/sample, 30 per secondIncreasing 10x by 2012
http://jpatterson.floe.tv/index.php/2009/10/29/the-smartgrid-goes-open-source

Disks are Slow
Disk Seek, Data Transfer
Reading FilesDisk seek for every accessBuffered reads, locality still seeking every
disk page

Disks are Slow
10ms seek, 10MB/s transfer 1TB file, 100b records, 10kb page
10B entries, 1B pages1GB of updatesSeek for each update, 1000 daysSeek for each page, 100 days
Transfer entire TB, 1 day

Disks are Slow
IDE drive – 75 MB/sec, 10ms seek SATA drive – 300MB/s, 8.5ms seek SSD – 800MB/s, 2 ms “seek”
(1TB = $4k!)

// Sidetrack
Observation: transfer speed improves at a greater rate than seek speed
Improvement by treating disks like tapesSeek as little as possible in favor of
sequential reads Operate at transfer speed
http://weblogs.java.net/blog/2008/03/18/disks-have-become-tapes

An Idea: Parallelism
1 drive – 75 MB/sec16 days for 100TB
1000 drives – 75 GB/sec22 minutes for 100TB

A Problem: Parallelism is Hard
IssuesSynchronizationDeadlockLimited bandwidthTiming issues
Apples v. Oranges, but… MPIData distribution, communication between nodes
done manually by the programmerConsiderable effort achieving parallelism
compared to actual processing

A Problem: Reliability
Computers are complicatedHard drivePower supplyOverheating

A Problem: Reliability
1 Machine3 years mean time between failures
1000 Machines1 day mean time between failures

Requirements Backup Reliable
Partial failure, graceful decline rather than full halt
Data recoverability, if a node fails, another picks up its workload
Node recoverability, a fixed node can rejoin the group without a full group restart
Scalability, adding resources adds load capacity Easy to use

Hadoop: Robust, Cheap, Reliable Apache project, open source Designed for commodity hardware Can lose whole nodes and not lose data Includes MapReduce programming
model

Why Commodity Hardware? Single large computer systems are
expensive and proprietaryHigh initial costs, plus lock-in with vendor
Existing methods do not work at petabyte-scale
Solution: Scale “out” instead of “up”

Hadoop Distributed File System
Throughput Good, Latency Bad Data Coherency
Write-once, read-many access model Files are broken up into blocks
Typically 64MB or 128MB block sizeEach replicated on multiple DataNodes on
write Intelligent Client
Client can find location of blocksClient accesses data directly from DataNode

Source: http://wiki.apache.org/hadoop/HadoopPresentations?action=AttachFile&do=get&target=hdfs_dhruba.pdf

HDFS: Performance
Robust in the face of multiple machine failures through aggressive replication of data blocks
High PerformanceChecksum of 100 TB in 10 minutes,
~166 GB/sec Built to house petabytes of data

MapReduce
Simple programming model that abstracts parallel programming complications away from data processing logic
Made popular at Google, drives their processing systems, used on 1000s of computers in various clusters
Hadoop provides an open source version of MR

MapReduce Data Flow

Using MapReduce MapReduce is a programming model for efficient
distributed computing It works like a Unix pipeline:
cat input | grep | sort | uniq -c | cat > outputInput | Map | Shuffle & Sort | Reduce | Output
Efficiency fromStreaming through data, reducing seeksPipelining
A good fit for a lot of applicationsLog processingWeb index building

Hadoop In The Field
Yahoo Facebook Twitter
Commercial support available from Cloudera

Hadoop In Your Backyard
openPDC project at TVAhttp://openpdc.codeplex.com
Cluster is currently:20 nodes200TB of physical drive space
Used for Cheap, redundant storageTime series data mining

Examples – Word Count Hello, World! Map
Input:foo foo bar
Output all words in a dataset as:{ key, value }{“foo”, 1}, {“foo”, 1}, {“bar”, 1}
ReduceInput:{“foo”, (1, 1)}, {“bar”, (1)}
Output:{“foo”, 2}, {“bar”, 1}

Word Count: Mapperpublic static class MapClass extends MapReduceBaseimplements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException {String line = value.toString();StringTokenizer itr = new
StringTokenizer(line);
while (itr.hasMoreTokens()) {word.set(itr.nextToken());output.collect(word, one);
}}
}

Word Count: Reducerpublic static class Reduce extends MapReduceBaseimplements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,Reporter reporter) throws IOException {
int sum = 0;while (values.hasNext()) {
sum += values.next().get();}output.collect(key, new IntWritable(sum));
}}
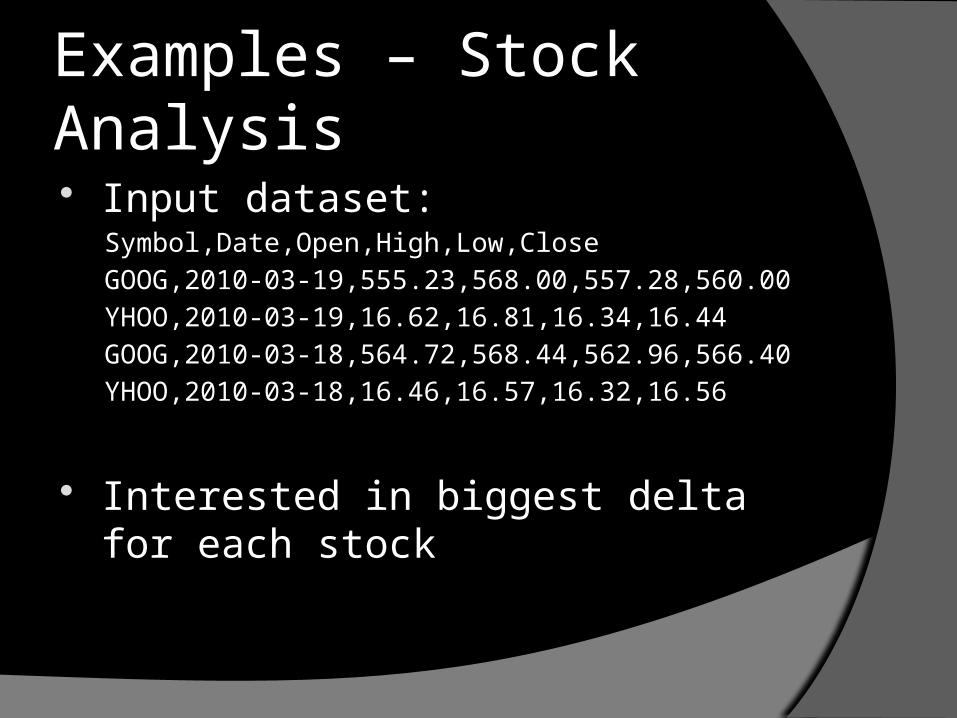
Examples – Stock Analysis Input dataset:
Symbol,Date,Open,High,Low,CloseGOOG,2010-03-19,555.23,568.00,557.28,560.00YHOO,2010-03-19,16.62,16.81,16.34,16.44GOOG,2010-03-18,564.72,568.44,562.96,566.40YHOO,2010-03-18,16.46,16.57,16.32,16.56
Interested in biggest delta for each stock

Examples – Stock Analysis Map
Output{“GOOG”, 10.72},{“YHOO”, 0.47},{“GOOG”, 5.48},{“YHOO”, 0.25}
ReduceInput: {“GOOG”, (10.72, 5.48)},{“YHOO”, (0.47, 0.25)}
Output:{“GOOG”, 10.72},{“YHOO”, 0.47}

Examples – Time Series Analysis Map:
{pointId, Timestamp + 30s of data}
Reduce:Data mining!Classify samples based on training datasetOutput samples that fall into interesting
categories, index in database

Other Stuff Compatibility with Amazon Elastic Cloud
Hadoop StreamingMapReduce with anything that uses stdin/stdout
Hbase, distributed column-store database Pig, data analysis (transforms, filters, etc) Hive, data warehousing infrastructure Mahout, machine learning algorithms

Parting Thoughts
“We don't have better algorithms than anyone else. We just have more data.”Peter Norvig
○ Artificial Intelligence: A Modern Approach○ Chief scientist at Google

Contact
Galen Rileyhttp://galenriley.com@TotallyGreat
Josh Pattersonhttp://jpatterson.floe.tv@jpatanooga