language evolution on a dynamic social network
TRANSCRIPT

Language Evolution on a Dynamic Social Network
Samarth Swarup1 and Les Gasser1,2
1Graduate School of Library and Information Science,2Department of Computer Science,
University of Illinois at Urbana-Champaign.{swarup,gasser}@uiuc.edu
Abstract
We study the role of the interaction network in a collaborative learning model known as the classification game.This involves a population of agents collaboratively learning to solve a classification task. We have previously shownthat interaction while learning allows the agents to converge upon a simpler solution, which in turns guarantees bettergeneralization. This clearly shows the benefits of social learning over individual learning. Here we show that byvarying the interaction topology during the learning process, convergence can be achieved very rapidly, at the expenseof only a small decrease in the quality of the solution. The interaction topology is evolved using Noisy PreferentialAttachment (NPA) algorithm, which is a variant of preferential attachment that unifies the network dynamics withevolutionary dynamics. In the classification game, NPA can be viewed as a recommendation mechanism. We alsocompare convergence times for several fixed topologies, and show that convergence using NPA is the fastest.
1 IntroductionOne of the hallmarks of an emerging society is a new way of communication, be it a new language, a new dialect, or anew slang. Often this new language is used as a marker of identity, to separate the in-group from others. Creating a newlanguage involves the creation of a new shared lexicon to refer to a shared set of meanings, and often also the creationof some new rules of composition (i.e. syntactic rules). All of these must be propagated across the social network untilconsensus is achieved. In other words, it is important for language to become conventionalized. The topology of thesocial network plays an important role in this process, particularly in the time to consensus.
Here we study a population of agents that must develop a language to communicate about a classification task thatthey are learning to solve. This setup is known as the classification game [31, 30]. “Language” in this context refers toencodings of inputs that the agents share with each other by associating a set of arbitrary symbols with them. In additionto minimizing the classification error on the task, the agents develop a shared set of encodings of the data and a sharedset of symbol associations, i.e. a shared language. We look at various topologies of interaction, both fixed and dynamic,and measure both the time to convergence and the “quality” of the final solution. Quality is measured by entropy of thelanguage, because low complexity (i.e. low entropy) solutions are expected to have lower generalization error [6]. Ourmain result is that the population can converge on a shared solution very quickly by adapting the interaction topologyintelligently. The shared solution that emerges is almost as good as one found on a fully-connected network. Thedisadvantage of a fully-connected network is that the time to consensus is typically very high.
There has been a lot of recent interest in the role of the topology of the interaction network in the emergenceof conventions. We are extending this stream of research in multiple ways. First, our agreement space is very large.Studies of the emergence of conventions generally assume a very small space of possible conventions, often binary. Ouragents, on the other hand, have to converge on a shared language, which is a much more complex structure. Second, ouragents are learning to solve a task. This means that there is a source of external feedback. The environment provides
1

an error signal. This means that some languages/representations are intrinsically preferred. These are the ones thatminimize the error. Previous studies do not assign any intrinsic fitness to the alternative conventions, though it is wellknown that people have many intrinsic biases which lead to preferences for various types of conventions. Third, moststudies of the emergence of conventions assume a fixed social network. This is an unrealistic assumption because thetimescales of language change are quite long. We expect the network itself to change on such long timescales. Thuswe study a dynamic topology of interaction.
The rest of this article is organized as follows. We begin by discussing and summarizing recent work in severaldifferent areas on the emergence of conventions and various other convergence problems on structured interactiontopologies. We then describe the classification game, which is our collaborative learning model, and the Noisy Pref-erential Attachment algorithm which we use to generate a realistic dynamic social network. This algorithm can beunderstood as a process where agents query each other for recommendations of interaction partners. This is followedby experiments which compare the results of the classification game on various fixed topologies with the results us-ing NPA and a randomly evolving topology. We shall also show the emergence of linguistic communities on somenetworks. We end with a general discussion and directions for future work.
2 Conventions and convergence in structured populationsRelevant work on this topic is emerging from multiple streams of research. While we discuss these separately below,there is actually a fair amount of crosstalk, because often the same researchers are involved in multiple streams. Further,sometimes techniques or approaches are shared between disciplines. Both evolutionary and economic models make useof game theory, e.g., making some classifications into this area of research or that arbitrary. Nevertheless, we believethat splitting up the related work into these different areas clarifies the differing motivations behind these studies, andalso presents this large and growing body of work in a digestible form.
Language evolution
There are have been several recent studies of the role of various fixed topologies in convergence to a shared language.Loreto et al. have studied the convergence of a simplified version of the naming game [27] on various topologies,particularly small-world networks [2, 3, 4, 5, 10, 11].
In their version of the naming game, agents have to come to consensus on a single word, which is the name ofsingle, commonly perceptible, object. The algorithm they use in this process is as follows. All agents begin with emptyvocabularies. When an agent, Alice, interacts with another agent, Bob, she makes up a word for the object (since hervocabulary is empty). Bob does the same. Since they won’t agree (except in the extremely unlikely situation wherethey both invent the same word), they add each others’ words to their vocabularies. Thus they both have vocabulariesof size two now. This process continues through interactions with other agents. Every time two agents meet, if theyhave a word in common, they settle upon that word as the word for the object, and remove all other words from theirvocabularies. Otherwise, they each add the word chosen by the other to their own vocabulary.
Loreto et al. have shown that this algorithm always results in eventual convergence to a single shared word in thepopulation, and that the time to convergence as well as the maximum size attained by the agent vocabularies depend onthe topology of the network. In a perfectly mixed population, convergence happens fairly quickly, inO(N) time, whereN is the size of the population. However the size of the vocabulary of an agent reaches O(N) before convergence.In contrast, when agents are arranged on a regular lattice, the maximum size of the vocabulary is dramatically lowerbecause they have a small number of neighbors, but the time to convergence is much higher, being O(N3) in onedimension and O(N1+2/d) in dimension d ≤ 4. They have also shown that a small-world topology, which is achievedby starting with a regular lattice and randomly rewiring a small number of edges, manages to attain the best of bothworlds, exhibiting both rapid convergence, in approximately O(N3/2) time steps, and a limited maximum vocabularysize (which means limited memory requirements for the agents).
2

They have also provided some very insightful analysis of the dynamics of convergence, showing that it proceeds bya coarsening process. Initially local convergence is achieved, which results in many small regions where agents haveachieved consensus. After that these regions expand slowly, until they reach the long-distance links in the small-worldnetwork, after which a mean-field like behavior takes over and results in rapid convergence.
However, their agents are following a very simple algorithm, and have to converge upon the use of a single word.They are not really doing any learning, and don’t have any feedback from the environment. In other words, they arenot grounded. We shall see, in what follows, that the convergence dynamics in our learning experiments are somewhatdifferent.
Cucker, Smale, and Zhou have studied convergence in a population of learning agents [9], as discussed before. Theyderived a minimum connectedness constraint on the topology of interaction for convergence. They model a language asa continuous function mapping forms to meanings, and each agent in their setup is assumed to collect m samples of itsneighbors’ languages at each time step. Each agent then uses its collected samples as a training set to updates its ownlanguage to minimize the squared error. They showed that the population will converge upon a shared language if theinteraction matrix satisfies a property called weak irreducibility. A stochastic matrix is said to be weakly irreducible if1 is a simple eigenvalue and all its other eigenvalues are less than 1 in modulus. The agents interaction matrix can beconverted into a stochastic matrix by normalization. They also derive a bound on the number of examples that must beavailable to each agent at each time step to ensure convergence within error ε with confidence at least 1− δ.
Sole et al. have also studied the roles of various complex networks in language evolution [26, 8]. They considera population of agents that use two form-meaning association matrices, P and Q, one for production, and the otherfor comprehension. This model was originally proposed by Hurford [15], and was also considered by Komarova andNiyogi [16]. One of the main issues in this case is to ensure self-consistency, that the agent is able interpret its ownutterances correctly. Corominas and Sole showed that for certain kinds of non-trivial network topologies (those withclustering), self-consistency is automatically achieved, without needing to bias the system in its favor [8].
Gong and Wang are the only ones we know of who have studied the co-evolution of lexicon, syntax, and topology[13, 14]. In their model, agents prefer to link to those other agents with whom they can communicate successfully, orones that have a lot of links. Thus the fitness of the agents is defined by their ability to communicate. They are notengaged in solving some task, and thus they don’t have intrinsic fitness. In their model, thus, it is the language thatinfluences the development of the network, whereas in our model the influence is more in the other direction. Theyshowed that their resulting networks are highly localized, and sometimes show small-world characteristics.
These are the main studies of network topology in language evolution. There are a number of studies in moreperipherally related areas. We summarize these briefly below.
Biological evolution
Results from biological evolution are interesting because they can conceivably be applied directly to language evolu-tion. Nowak et al. have studied evolution on graphs and derived probabilities of fixation for various graph topologies[17]. They show that the probability of fixation of a mutant, i.e. the probability that a new trait gets adopted by theentire population, is strongly affected by the structure of the graph. There exist graph structures which can make theeffective fitness of the mutant with respect to the population arbitrarily large. Conversely there are also structuresthat can make it arbitrarily small. They showed through numerical simulations that scale free networks act as fitnessamplifiers when the difference between the fitness of the mutant and the population is small, but are neither amplifiersnor suppressors when the difference is large. The fitness landscape itself is fixed in their model.
Wilke et al. have studied dynamic fitness landscapes in molecular evolution [32, 33]. They showed that if the fitnesslandscape changes very fast with respect to the timescale of evolution, then the species adapts to the time average of thefitness landscape. If, on the other hand, the fitness landscape changes slowly, the species can track the fitness landscapearbitrarily closely. However, they assume that the source of change to the fitness landscape is extrinsic and periodic. Inour model, the nodes define the fitness landscape for the evolution of the population of links. However since the nodes(agents) are learning, their fitness (accuracy) changes, and thus the fitness landscape is dynamic. However, the above
3

conditions are not met. The timescales of language and topology evolution are comparable, the source of change in thefitness landscape is intrinsic, due to the task learning and learning from interaction, and it is not periodic.
Economics
H. Peyton Young did some seminal work on the emergence of conventions over social networks [34, 35]. Delgado etal. have also done some work on the role of network structure on the emergence of conventions [12, 24]. They showedthat scale-free networks are very efficient at converging to a convention. He used two different update rules, known asGeneralized Simple Majority (GSM), and Highest Cumulative Reward (HCR). In both cases, he found that scale-freenetworks converge very quickly. Small-world networks converge quickly too, but seem to be a little less efficient.Regular topologies tend to be the slowest, takingO(N3) time on a one-dimensional network. This confirms the resultsof Loreto et al. discussed above.
Santos et al. have shown that allowing the topology of interaction to evolve allows cooperation to persist in variousiterated social dilemma games [25]. Their topology evolution algorithm is also a heuristic. Basically agents will droplinks to agents that are giving them a low payoff (by defecting), and will try to add links to the neighbors of theseagents. The intuition is that the neighbors of these agents would also be trying to do the same. They showed thatthis simple topology update rule results in the persistence of cooperation even though the only evolutionarily stablestrategy in these games is to defect. Their model is quite unrelated to ours, but it is nice to know that essentially thesame topology update algorithm results in some interesting phenomena in multiple models.
Control theory and multi-agent systems
In the realm of control theory, Olfati-Saber and Murray have studied the role of network topologies in the convergenceto a shared value, typically by using an algorithm where each agent averages the values of its neighbors at each time step[20, 21, 22, 23]. The time to convergence in this case can analytically be shown to depend on the Laplacian spectrumof the graph. More precisely, the worst case time to convergence is determined by the second smallest eigenvalue ofthe Laplacian matrix of the graph. It can be shown that as we begin to randomly rewire a regular network to create asmall-world network, the second smallest eigenvalue increases rapidly, which implies faster convergence.
This property follows from the averaging algorithm being used. There is no analogous measure, which we knowof, for analyzing time to convergence for learning agents. If one such could be found, it would represent a majorbreakthrough in the understanding of systems of learning agents.
3 The Classification Game with Noisy Preferential AttachmentWe now present our learning model and the mechanism for evolving the topology of the interaction network.
3.1 The Classification GameIn the classification game we have a population of agents all learning to solve the same classification problem. At eachstep, we select two of the agents randomly from the population and designate them as speaker and hearer. They arepresented with an example from the training set. The speaker chooses the encoding of this example, and converts thisencoding into an utterance that it communicates to the hearer. For instance, our agents use artificial neural networksto learn, and the encoding of an example corresponds to choosing which hidden layer nodes are active in responseto the example. A hidden layer node is considered active if its output is greater than 0.5. The utterance is generatedby associating active hidden layer nodes with arbitrary symbols such as letters of the alphabet. These associationsare maintained using a form-meaning matrix. Each entry in the matrix counts the number of times the correspondinghidden layer node has been used (or observed, in the case of the hearer) with the corresponding symbol. This speaker-hearer interaction is illustrated in fig. 1.
4

0 1
1 0 1 1 1011
1
Form-MeaningMapping
ACD
Speaker
0 1
Hearer
Form-MeaningMapping
? ? ? ? ?
?
Figure 1: Speaker-hearer interaction in the classification game. Active hidden layer nodes are converted into an utter-ance using the form-meaning mapping. The hearer must interpret this utterance to set its own hidden layer activationsand predict the label. They are both then given the true label and can update their neural networks and form-meaningmappings.
Both the agents then have to decode the internal representation chosen by the speaker. They do this with the secondor output layer of their neural networks. This results in a prediction of a label for the given training example. They areboth then given the true label of the example and update their neural network weights using gradient descent and errorbackpropagation. More details of the representations and learning algorithms can be found in [28].
This process is repeated until some termination criterion is satisfied. Typically we let learning continue until theerror stabilizes. Error is calculated separately for speakers and hearers. Speaker error is simply the average number ofmisclassifications made by an agent on the entire training set. Hearer error is calculated as follows. For each agent,we choose a random speaker. The agent must then label the entire training set by decoding encodings chosen by thisspeaker. The average number of misclassifications made by the agents in this setting is called the hearer error.
We show learning curves for both types of error in fig. 2, on a simple learning task where the input is a Booleanvector of length 8. The output is 1 if there are three adjacent bits valued 1 in the input. Fifty randomly chosen bitvectors out of the 256 possible made up the training set. Four curves are shown in fig. 2, because we have included trueerror curves, which are computed on all the 256 possible examples, even though this information is not used duringlearning. We see that for both the training set and the testing set, the speaker and hearer curves come very close toeach other. This shows that the internal representations (neural networks and form-meaning matrices) of the agents areconverging.
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Ave
rage
Pop
ulat
ion
Err
or
Time step (x 10000)
speakerhearer
speaker-traininghearer-training
Figure 2: Speaker and hearer learning curves on the 8in-3ones learning problem, with a perfectly mixed population of100 agents.
The classification game results in a trade-off between two evolutionary pressures. A pressure for learnability
5

......
...
...
A
B
D
C
(a) Initial topology.
......
...
...
A
B C
D
(b) After one update.
Figure 3: A single update to the topology. Node B recommends node C to node A, whereupon node A drops one of itslinks (the one to node D) randomly, and adds a link to node C.
selects solutions of lesser complexity. Simpler solutions can be learned more quickly, and thus can spread quickly in apopulation. On the other hand, excessively simple encodings are not capable of carrying enough information to solvethe classification problem at hand. Thus there is a pressure for functionality that selects more complex solutions. Thesetwo opposing pressures result in complexity regularization, i.e. the population converges on a solution of minimalcomplexity (or close to it) [31].
3.2 Noisy Preferential AttachmentWe introduce topological structure into the agent interactions as follows. Agents are now situated on a directed graph,and the adjacency matrix defines the neighbors of each agent. At each time step we select a hearer, and this agentchooses a speaker from among its neighbors. The classification game then proceeds as before with this speaker-hearerpair. Once in a while, though, an agent rewires one of its links, using the Noisy Preferential Attachment (NPA)algorithm.
NPA is a modification of preferential attachment [1] that unifies the dynamics of network growth with the dynamicsof molecular evolution [29]. It allows us to view the process of network growth as a process where the population oflinks in the network is evolving on a fitness landscape defined by the nodes in the network. The nodes can be viewedas the space of possible species. Thus, node i has a fitness defined by,
fi = ai +∑
j
xjwj , (1)
where ai is the intrinsic fitness of node i (and thus of every link to node i), xj is the number of links to node j, and wj
is a weighting term. This kind of fitness function is known as frequency-dependent fitness because the fitness of a typedepends on the other types in the population.
In the experiments to follow, we define ai to be the current classification accuracy of node i (agent i). The topologyevolution can be viewed as a recommendation process. Agents are initially arranged on a regular network, whichis a square grid in two dimensions. Each agent has four neighbors, except the ones on the borders (which havethree neighbors each), and the ones on the corners (which have just two). They proceed to update their interactiontopology as follows. An agent, A, queries one of its neighbors, B, for a recommendation of the best agent known to
6

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
Pajek
(a) A regular network.
12
3
45
6
7
8 9
1011
12
13
1415
16
17
1819
20
21
22
23
24
2526
27 2829
30
3132
33
34
35
36
37
38
39
40
4142
43
44
45
46
47
48
49
50
51
52
53
54
55
56
5758
59
60
61
62
63
64
65
66
67
68 69
70
71
72 73
74
75
7677
7879 80
81
82
83
84
85
86
87
8889
90
91
9293
94
95
96
97 98 99
100
Pajek
(b) A small world network.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
4748
4950
51
52
535455
56
57
58
5960
61
62
6364
65
6667
68
69
70
71
7273
74
75
76 77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99100
Pajek
(c) A scale-free small world network.
Figure 4: A regular network is shown on the left. There are two directed links, pointing in opposite directions, betweeneach pair of neighboring agents. The small-world network, shown in the middle, is generated by randomly rewiring5% of the links in the square network. The network on the right is a small-world network with a scale-free degreedistribution. It was generated with the R-MAT algorithm [7].
it. “Best” is measured by the current performance (classification accuracy) of each of the neighbors of B on the task.Suppose B recommends agent C. Agent A then drops one of its links to its neighbors randomly, and creates a linkto C. This process is illustrated in figure 3. Agent A is effectively selecting the link from B to C and replicating it.With some small noise probability, a mutation can occur, and A might end up linking to a randomly chosen agent fromthe population. The probability of mutation is decreased over time, because this results in realistic dynamic socialnetworks, as demonstrated in [29].
We compare this dynamic topology with a few different interaction topologies in this paper. The first is the fullyconnected topology, where every agent interacts with every other agent. The next is a fixed regular graph, as describedabove and illustrated in figure 4(a). From the regular graph, we get a small-world topology by randomly rewiring 5% ofthe links. The resulting network is shown in figure 4(b). Rewiring just this small number of links causes the diameter ofthe network to drop substantially. In the network shown, the diameter is 11, as compared to 18 for the square network.The next kind of network we experiment with are small-world networks which have a scale-free degree distribution.This network was generated with the R-MAT algorithm [7], and is shown in figure 4(c).
Finally we include another dynamic network, which evolves randomly. When the topology is dynamic, we haveto consider the relative time scales of topology and language evolution. Since it is difficult to actually measure thetimescale of language evolution, we do simulations with a variety of time scales of topology evolution.
In the random topology evolution case, we rewire a randomly chosen link every τ time steps. Different values ofτ are chosen for different simulations (for both NPA and random evolution), ranging exponentially from τ = 1 toτ = 1000000.
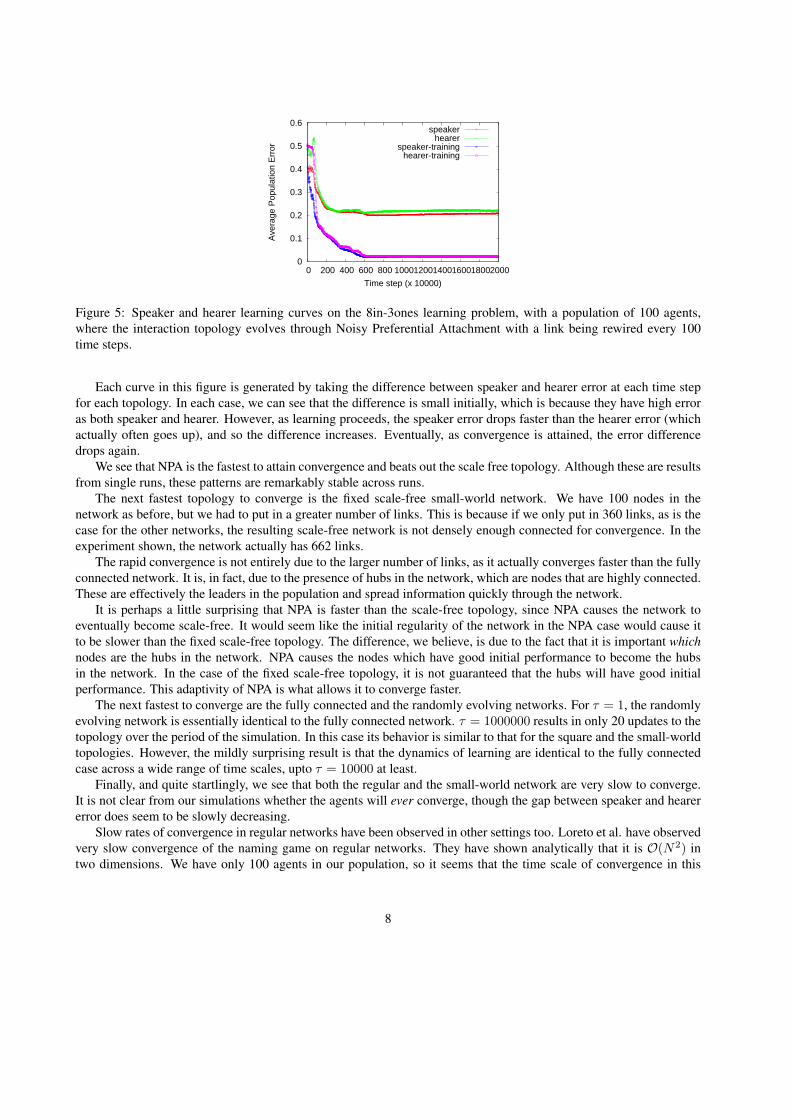
4 ExperimentsLearning curves for NPA with τ = 100 are shown in fig. 5. Comparing with fig. 2, we can see that convergence occursmuch more rapidly. For τ = 100, for a population of 100 agents, the timescales of language and topology evolutionare comparable. For smaller values of τ , the network very quickly evolves into a scale-free small-world network, andthus the convergence times are identical to that case (shown further below). As we increase the value of τ , convergencebecomes slower and slower until it approaches a fixed regular network in behavior, because hardly any links get rewiredin the course of the simulation.
Since we are interested in convergence time, instead of presenting learning curves for all the different interactiontopologies, we plot the average difference between speaker and hearer error for each of the topologies. These curvesare presented in fig. 6. τ = 100 was chosen as a representative time scale for both NPA and random evolution, so asnot to clutter up the graph with too many curves.
7
0
0.1
0.2
0.3
0.4
0.5
0.6
0 200 400 600 800 1000 1200 1400 1600 1800 2000A
vera
ge P
opul
atio
n E
rror
Time step (x 10000)
speakerhearer
speaker-traininghearer-training
Figure 5: Speaker and hearer learning curves on the 8in-3ones learning problem, with a population of 100 agents,where the interaction topology evolves through Noisy Preferential Attachment with a link being rewired every 100time steps.
Each curve in this figure is generated by taking the difference between speaker and hearer error at each time stepfor each topology. In each case, we can see that the difference is small initially, which is because they have high erroras both speaker and hearer. However, as learning proceeds, the speaker error drops faster than the hearer error (whichactually often goes up), and so the difference increases. Eventually, as convergence is attained, the error differencedrops again.
We see that NPA is the fastest to attain convergence and beats out the scale free topology. Although these are resultsfrom single runs, these patterns are remarkably stable across runs.
The next fastest topology to converge is the fixed scale-free small-world network. We have 100 nodes in thenetwork as before, but we had to put in a greater number of links. This is because if we only put in 360 links, as is thecase for the other networks, the resulting scale-free network is not densely enough connected for convergence. In theexperiment shown, the network actually has 662 links.
The rapid convergence is not entirely due to the larger number of links, as it actually converges faster than the fullyconnected network. It is, in fact, due to the presence of hubs in the network, which are nodes that are highly connected.These are effectively the leaders in the population and spread information quickly through the network.
It is perhaps a little surprising that NPA is faster than the scale-free topology, since NPA causes the network toeventually become scale-free. It would seem like the initial regularity of the network in the NPA case would cause itto be slower than the fixed scale-free topology. The difference, we believe, is due to the fact that it is important whichnodes are the hubs in the network. NPA causes the nodes which have good initial performance to become the hubsin the network. In the case of the fixed scale-free topology, it is not guaranteed that the hubs will have good initialperformance. This adaptivity of NPA is what allows it to converge faster.
The next fastest to converge are the fully connected and the randomly evolving networks. For τ = 1, the randomlyevolving network is essentially identical to the fully connected network. τ = 1000000 results in only 20 updates to thetopology over the period of the simulation. In this case its behavior is similar to that for the square and the small-worldtopologies. However, the mildly surprising result is that the dynamics of learning are identical to the fully connectedcase across a wide range of time scales, upto τ = 10000 at least.
Finally, and quite startlingly, we see that both the regular and the small-world network are very slow to converge.It is not clear from our simulations whether the agents will ever converge, though the gap between speaker and hearererror does seem to be slowly decreasing.
Slow rates of convergence in regular networks have been observed in other settings too. Loreto et al. have observedvery slow convergence of the naming game on regular networks. They have shown analytically that it is O(N2) intwo dimensions. We have only 100 agents in our population, so it seems that the time scale of convergence in this
8

0
0.05
0.1
0.15
0.2
0.25
0.3
0 500 1000 1500 2000
Spe
aker
-Hea
rer
Err
or D
iffer
ence
Time step (x 10000)
Fully connectedSquare
Scale freeSmall-world
Random 100NPA 100
Figure 6: A comparison of the convergence dynamics. Each curve in the plot is generated by taking the differencebetween speaker and hearer error for that topology at each time step. A topology update time scale of 100 was takenas representative from the NPA and random update experiments. Note that the curve for NPA-100 settles much morequickly than the other ones.
experiment is much slower than that. There are at least a couple of factors that are responsible for the difference. Thefirst is that Loreto et al. studied convergence on a single shared word. Our agents have to achieve consensus on a morecomplicated structure. Second, the rate of change of an agent’s solution to the task is governed by the learning rate,which is (intentionally) a small number.
Olfati-Saber et al. have also reported slow rates of convergence on regular networks [21]. The process they havestudied, as described previously, is one where each agent averages the states of its neighbors at each time step. Theyhave to achieve consensus only on a scalar variable.
While the processes studied by Loreto et al. and by Olfati-Saber et al. are quite different from ours, the generalfact that regular networks are slow to achieve consensus seems to hold across each of the cases.
However, our results differ from those of Loreto et al. and Olfati-Saber et al. when it comes to small-worldnetworks. They have found that consensus is achieved much faster, for the respective processes they have studied, on asmall-world network [20, 10]. Delgado also studied consensus formation on various network topologies, and he foundthat small world networks have the same kind of convergence behavior as scale-free networks, though they are a bitless efficient [12]. In our experiment, the convergence time scale seems to be the same as that for the regular network.
4.1 Average code lengthWe also compare the average code length for the various topologies. The average code length, or entropy, is calculatedas follows. We count the frequencies of occurrence of each of the symbols that appear in the utterances generated byan agent for all the training examples. If pi is the probability of seeing symbol i, then the entropy in bits is given by,
H = −∑
i
pi log2 pi. (2)
As mentioned earlier, lower entropy solutions are preferred because they have lower expected generalization error. Acomparison of entropies for the final solutions for the different topologies is shown in figure 7. We see that when the
9

0 0.2 0.4 0.6 0.8
1 1.2 1.4 1.6
Ful
ly C
onne
cted
Reg
ular
(sq
uare
)S
mal
l wor
ldS
cale
free
NP
A-1
NP
A-1
0N
PA
-100
NP
A-1
000
NP
A-1
0000
NP
A-1
0000
0N
PA
-100
0000
Ran
dom
-1R
ando
m-1
0R
ando
m-1
00R
ando
m-1
000
Ran
dom
-100
00R
ando
m-1
0000
0R
ando
m-1
0000
00
Ave
rage
Cod
e Le
ngth
Figure 7: A comparison of the average code length for various topologies. We see that NPA on average results inslightly higher code lengths than other topologies, whereas the fully-connected topology results in the lowest averagecode length. Random evolution is comparable to that, but for low values of τ , random evolution is essentially equivalentto a fully connected topology.
topology evolves according to NPA, the resulting solution tends to have a slightly higher average code length than inother cases. Thus there is a tradeoff between rapid convergence and optimality. However the average code length isstill much less than that of an individual learner, and does not scale with the number of hidden layer nodes. Thus, thepopulation is still trying to minimize the average code length, but is not as successful due to the higher influence of arelatively small number of agents.
4.2 The emergence of communitiesIn order to take a closer look at why the regular network does not seem to be converging, we developed a visualization.The agents are represented by circles arranged in a square grid. The size of the circle indicates the accuracy of theagent on the task. If the agents all have 100% accuracy, they will be large enough to touch each other. The color ofthe circle represents the language of the agent. It is computed as follows. We observe the utterance associated by eachagent with a single, randomly chosen, training vector. The agents have 10 hidden layer nodes, and can thus have 210
possible utterances for a single point. We treat this as a 10 bit binary number which we scale to 224 and treat as an RGBcolor. Thus, identical encodings will have identical colors, and similar encodings will have (somewhat) similar colors.We examine the encodings for only a single point, and thus convergence does not of course mean convergence on theentire training set. But by watching a single point we can nevertheless get a good idea of the emerging encodings.
Figure 8 shows the initial, intermediate, and final stages of the population for a topology evolving according toNPA. The final stage here is just after 100,000 time steps. We see that initially there is a wide range of colors and sizes,due to random initialization. Pretty soon, though, in the intermediate step, we see that there are two main languagescompeting for dominance, and after 100,000 time steps, one has become entirely established in the population andperformance is close to 100%. Note that the topology of the network is changing during this process, but this is notshown in the visualization.
In the case of the regular network, we find something quite different, as shown in figure 9. The agents start outwith a wide range of colors and sizes as before. However, in the intermediate stage there are multiple languages co-
10

(a) Initial (b) Intermediate (c) Final
Figure 8: A visualization of language convergence over 100,000 timesteps, where the topology is being updated usingNPA at every timestep.
(a) Initial (b) Intermediate (c) Final
Figure 9: A visualization of language convergence over 100,000 timesteps, where the topology is fixed and regularwith Manhattan neighborhoods. We see local convergence but not global convergence.
existing in the population. Further, these are all localized spatially. They continue to persist with very little changein the boundaries after 100,000 time steps also, by which time NPA had already converged. Thus, it seems thatthis community formation is the key difference between regular and dynamic topologies. Community formation isprevented by the rewiring that takes place due to NPA.
5 ConclusionWe have shown that a dynamic topology that evolves by Noisy Preferential Attachment is able to converge very rapidly,at the expense of a slightly higher complexity of the final solution. We have seen that NPA can be seen as a recommen-dation process, which is an optimization heuristic that allows the agents to quickly locate the best-performing agents inthe population. These agents become the hubs of the network and good solutions can spread rapidly in the population.
We compared this with a few different fixed topologies that are popular in the literature, and also with a randomlyevolving topology. We found that regular networks result in extremely slow convergence. We also found that, contrary
11

to other people’s results, a small-world network does not result in an quicker convergence than a regular network.A scale-free small-world network, however, results in more rapid convergence than any other topology except oneevolving by NPA.
We also developed a visualization to better understand the dynamics of learning in regular networks. We observedthat the seeming lack of convergence in regular networks is due to community formation. Agents that are close to eachother on the network converge onto a shared representation, and this tends to be close to optimal. However, agents thatare widely separated from each other end up using different symbols to represent the same points and thus are unableto communicate with each other. This lack of global convergence shows up in the learning curves.
One of the main directions for future work is build a theoretical framework for understanding these experiments.Game theory, especially evolutionary game theory, seems to be a particularly appropriate formalism for the workpresented here. Games on lattices have been studied for a long time now [34]. It is only in recent years, though, thatseveral good results about games on fixed interaction topologies such as the ones considered here have begun to appear[18, 19, 24]. However, the theory of games on dynamical networks does not yet exist, though some numerical studieshave begun to appear [25]. Development of this theory, and its application to the problem considered in this paper, is avery promising direction for future work
References[1] Albert-Laszlo Barabasi and Reka Albert. Emergence of scaling in random networks. Science, 286:509–512,
October 1999.
[2] A. Baronchelli, M. Felici, E. Cagliotti, V. Loreto, and L. Steels. Self-organizing communication in languagegames. In Proceedings of the First European Conference on Complex Systems (ECCS’05), Paris, France, Novem-ber 2005.
[3] Andrea Baronchelli, Luca Dall’Asta, Alain Barrat, and Vittorio Loreto. Strategies for fast convergence in semioticdynamics. arXiv:Physics/0511201 v1, November 2005.
[4] Andrea Baronchelli, Luca Dall’Asta, Alain Barrat, and Vittorio Loreto. Topology induced coarsening in languagegames. Physical Review E, 73(015102), 2006.
[5] Andrea Baronchelli, Vittorio Loreto, Luca Dall’Asta, and Alain Barrat. Bootstrapping communication in lan-guage games: Strategy, topology, and all that. In Proceedings of the Sixth International Conference on theEvolution of Language (EVOLANG), 2006.
[6] Anselm Blumer, Andrzej Ehrenfeucht, David Haussler, and Manfred K. Warmuth. Occam’s razor. InformationProcessing Letters, 24(6):377–380, 1987.
[7] Deepayan Chakrabarti, Yiping Zhan, and Christos Faloutsos. R-MAT: A recursive model for graph mining. InSIAM conference on data mining, 2004.
[8] Bernat Corominas and Ricard Sole. Network topology and self-consistency in language games. Journal ofTheoretical Biology, 241(2):438–441, July 2006.
[9] Felipe Cucker, Steve Smale, and Ding-Xuan Zhou. Modeling language evolution. In J. Minett and W. S. Y. Wang,editors, Language Acquisition, Change and Emergence. 2003.
[10] Luca Dall’Asta, Andrea Baronchelli, Alain Barrat, and Vittorio Loreto. Agreement dynamics on small-worldnetworks. Europhysics Letters, 73(969), 2006.
[11] Luca Dall’Asta, Andrea Baronchelli, Alain Barrat, and Vittorio Loreto. Nonequilibrium dynamics of languagegames on complex networks. Physical Review E, 74(036105), 2006.
12

[12] Jorgi Delgado. Emergence of social conventions in complex networks. Artificial Intelligence, 141:171–185, 2002.
[13] Tao Gong, Jinyun Ke, James W. Minett, and William S-Y. Wang. A computational framework to simulate thecoevolution of language and social structure. In Proceedings of the Ninth International Conference on ArtificialLife (ALifeIX), Boston, MA, USA, 2004.
[14] Tao Gong and William S-Y. Wang. Computational modeling on language emergence: A coevolution model oflexicon, syntax and social structure. Language and Linguistics, 6(1):1–41, 2005.
[15] James R. Hurford. Biological evolution of the Saussurean sign as a component of the language acquisition device.Lingua, 77:187–222, 1989.
[16] Natalia Komarova and Partha Niyogi. Optimizing the mutual intelligibility of linguistic agents in a shared world.Artificial Intelligence, 154:1–42, 2004.
[17] Erez Lieberman, Christoph Hauert, and Martin A. Nowak. Evolutionary dynamics on graphs. Nature, 433:312–316, January 2005.
[18] Elchanan Mossel and Sebastien Roch. Slow emergence of cooperation for win-stay lose-shift on trees. MachineLearning, 67:7–22, 2007.
[19] Hisashi Ohtsuki and Martin A. Nowak. The replicator equation on graphs. Journal of Theoretical Biology,243:86–97, 2006.
[20] Reza Olfati-Saber. Ultra-fast consensus in small-world networks. In Proceedings of the American Control Con-ference, pages 2371–2378, June 2005.
[21] Reza Olfati-Saber, J. Alex Fax, and Richard M. Murray. Consensus and cooperation in networked multi-agentsystems. Proceedings of the IEEE, 95(1):1–17, 2007.
[22] Reza Olfati-Saber and Richard M. Murray. Consensus protocols for networks of dynamic agents. In Proceedingsof the American Control Conference, 2003.
[23] Reza Olfati-Saber and Richard M. Murray. Consensus problems in networks of agents with switching topologyand time delays. IEEE Transactions on Automatic Control, 49(9):1520–1533, September 2004.
[24] Josep M. Pujol, Jordi Delgado, Ramon Sanguesa, and Andreas Flache. The role of clustering in the emergenceof efficient social conventions. In Proceedings of the Nineteenth International Joint Conference on ArtificialIntelligence (IJCAI), pages 965–970, Edinburgh, Scotland, July 2005.
[25] Francisco C. Santos, Jorge M. Pacheco, and Tom Lenaerts. Cooperation prevails when individuals adjust theirsocial ties. PLoS Computational Biology, 2(10):1284–1291, October 2006.
[26] Ricard V. Sole, Bernat Corominas Murtra, Sergi Valverde, and Luc Steels. Language networks: Their structure,function, and evolution. Working Paper 05-12-042, Santa Fe Institute, 2005.
[27] Luc Steels. The origins of ontologies and communication conventions in multi-agent systems. AutonomousAgents and Multi-Agent Systems, 1(2):169–194, 1998.
[28] Samarth Swarup. Artificial Language Evolution on a Dynamical Interaction Network. PhD thesis, Departmentof Computer Science, University of Illinois at Urbana-Champaign, Urbana, IL, USA, October 2007. UIUCDCS-R-2007-2890.
[29] Samarth Swarup and Les Gasser. Unifying evolutionary and network dynamics. Phys. Rev. E, 75:066114, 2007.
13

[30] Samarth Swarup and Les Gasser. The classification game: Combining supervised learning and language evolu-tion. Submitted, 2008.
[31] Samarth Swarup and Les Gasser. Simple, but not too simple: Learnability vs. functionality in language evolution.In Proceedings of the 7th Conference on the Evolution of Language, Barcelona, Spain, March 11-15 2008.
[32] Claus O. Wilke and C. Ronnewinkel. Dynamic fitness landscapes: Expansions for small mutation rates. PhysicaA, 290:475–490, 2001.
[33] Claus O. Wilke, C. Ronnewinkel, and T. Martinetz. Dynamic fitness landscapes in molecular evolution. Phys.Rep., 349:395–446, 2001.
[34] H. Peyton Young. The evolution of conventions. Econometrica, 61(1):57–84, 1993.
[35] H. Peyton Young. Individual Strategy and Social Structure. Princeton University Press, 1998.
14