language epidemic - peoplepeople.sc.fsu.edu/.../2013/1/28_language_epidemic_files/language.pdf ·...
TRANSCRIPT

Language epidemichow to use epidemiological and evolutionary biology to
find the origin of indo-european languages
1Monday, January 28, 13

2Monday, January 28, 13
3Monday, January 28, 13

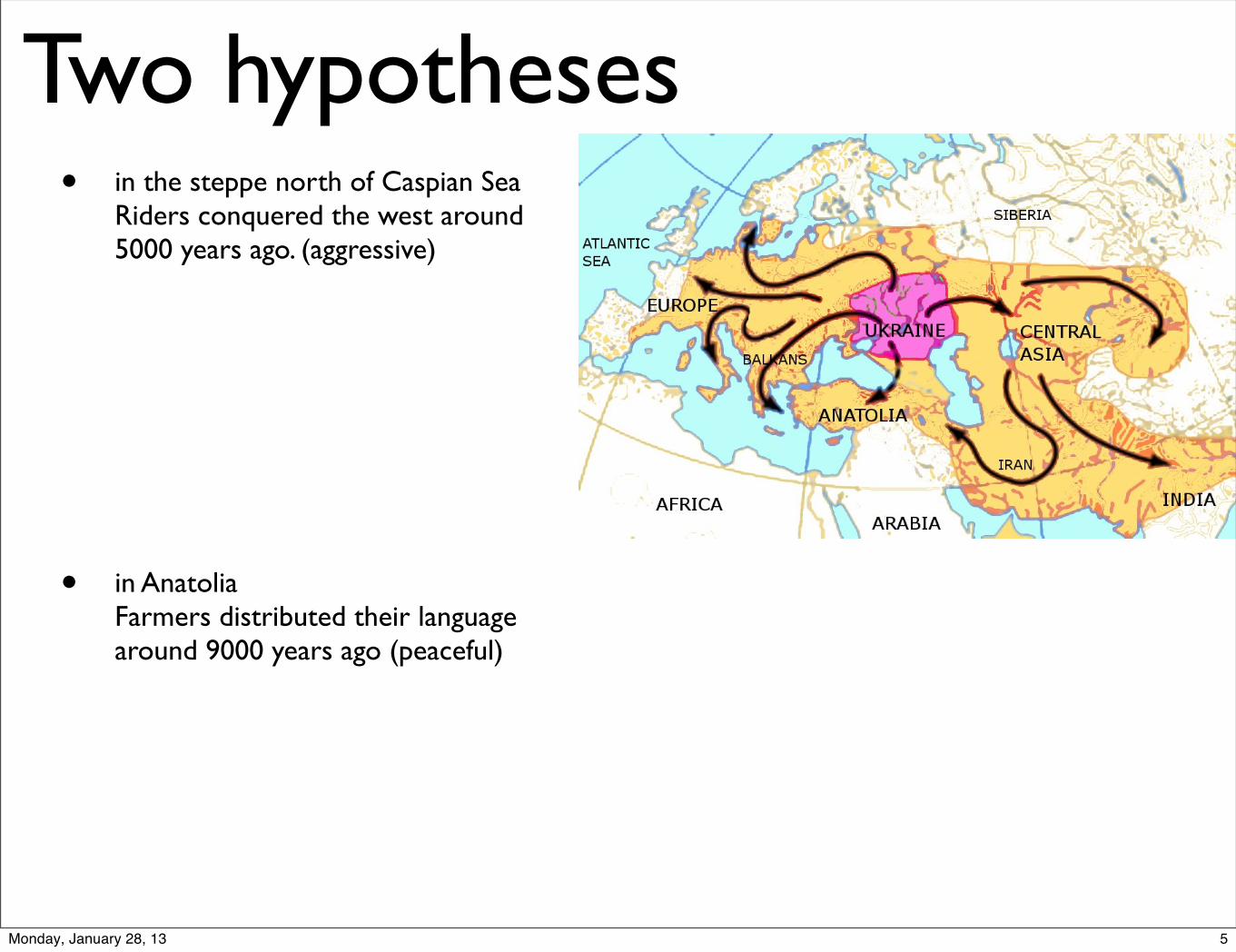
Two hypothesesIndo-european languages originate
• in the steppe north of Caspian SeaRiders conquered the west around 5000 years ago. (aggressive)
• in AnatoliaFarmers distributed their language around 9000 years ago (peaceful)
4Monday, January 28, 13
Two hypotheses• in the steppe north of Caspian Sea
Riders conquered the west around 5000 years ago. (aggressive)
• in AnatoliaFarmers distributed their language around 9000 years ago (peaceful)
5Monday, January 28, 13

Cognates are homologues [although it seems that some linguists disagree]
The wings of pterosaurs (1), bats (2) and birds (3) are analogous as wings, but homologous as forelimbs.
6Monday, January 28, 13
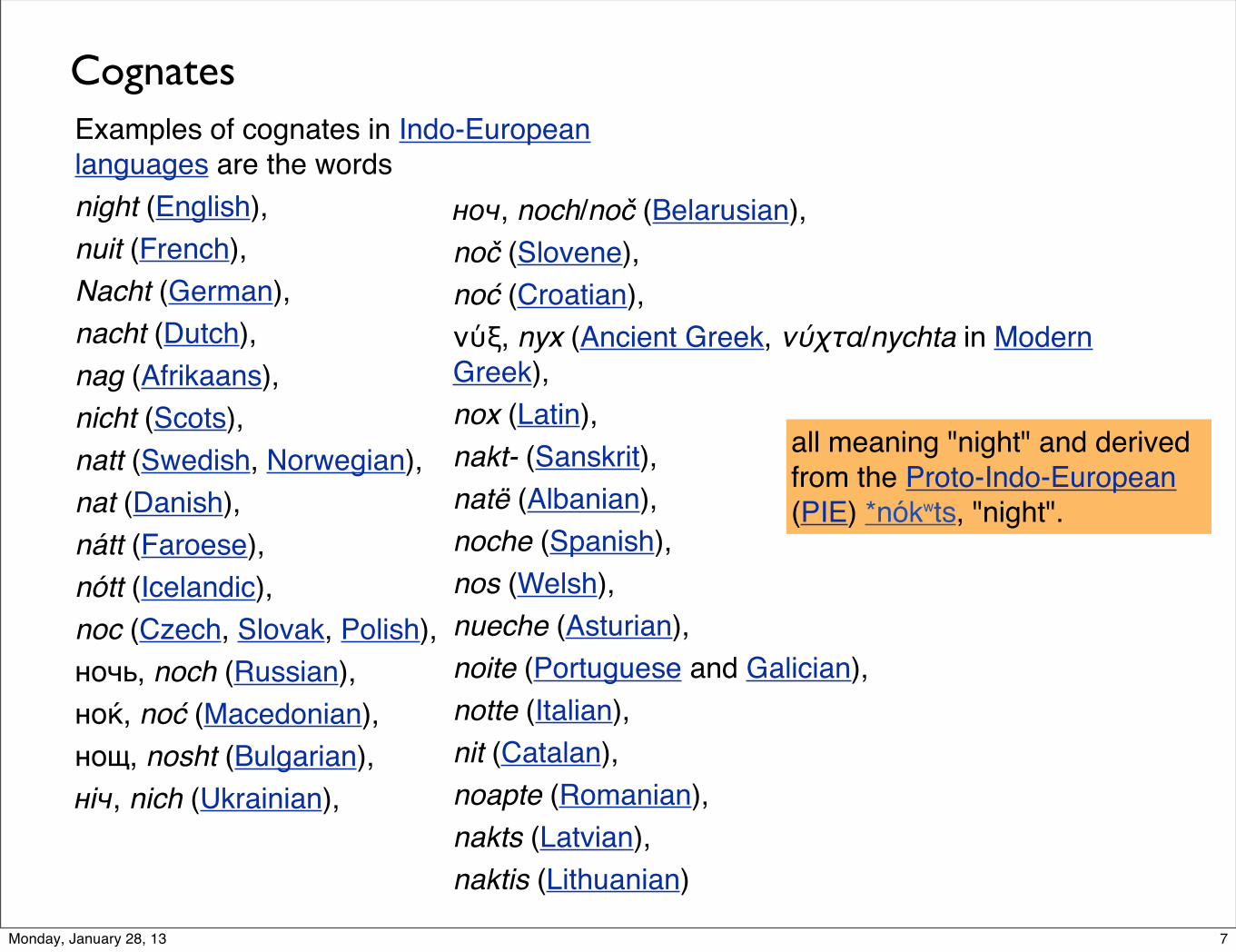
CognatesExamples of cognates in Indo-European languages are the words night (English), nuit (French), Nacht (German), nacht (Dutch), nag (Afrikaans), nicht (Scots), natt (Swedish, Norwegian), nat (Danish), nátt (Faroese), nótt (Icelandic), noc (Czech, Slovak, Polish), ночь, noch (Russian), ноќ, noć (Macedonian), нощ, nosht (Bulgarian), ніч, nich (Ukrainian),
ноч, noch/noč (Belarusian), noč (Slovene), noć (Croatian), νύξ, nyx (Ancient Greek, νύχτα/nychta in Modern Greek), nox (Latin), nakt- (Sanskrit), natë (Albanian), noche (Spanish), nos (Welsh), nueche (Asturian), noite (Portuguese and Galician), notte (Italian), nit (Catalan), noapte (Romanian), nakts (Latvian),naktis (Lithuanian)
all meaning "night" and derived from the Proto-Indo-European (PIE) *nókʷts, "night".
7Monday, January 28, 13

100000000100000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000100000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001000000000000001000000000000000000000000000000000000000100000000000000000000100000000000000000001000000000000000000000000000100000000000000001000000000000000000000000000000000000000010000000000000001000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000000000100000000000000100000000000000000000000000010000000000000000000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000001000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000010000000001000000000000001000000000000000000000100000000000000000000000000000000000000000000000000000000001000000000000000000000001000000100000000000000000000000000000000000000001000000000000000000001000000000000000100000000000100000000000000000000000000000000100000000000000000000000000010000000000000000000000000000000000000000000000000100000000000000000001000000000000000000000000000000100000000000000000000100000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000010000100000000000000000000000000000000100000000001000100000000000000000000000000001000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000001000000000000000000010000000000000000000101000000000000000000000000000000000000000000000000000000000100000001000000000000010000000000000000000000000000000000000000000000010000000000000000000000000000100000000000000000000000000000000000001000000000000000000000000000000000100000000000000000000000000000000000000000100000000010000000000000000000000000001000000000000000000000000100000000000000000000001000000000000000000000000001000000000000000000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000100000000000100000000000000010000000000000000000000000000000000000000000000100000000000000000000000000000100000000000000000000000000000000000010000000000000000000000000000000000000001000000000000000000000000000000000001000000000000000000000000000000000000000001000000000010000000000000000000000000000000000000000000000000000000100000000000000000000000010000000000000000000000000000000000000100000000000000000000000000000000000010000000000000000000000000000000000000000000100000000000000000010000000000000000000000001000000000000000100000000000000000000000100000000000000000000000000000010000000000000000000000000000000000000000000010000000000001000000000000000010000000000000000000000000000000000000000001000000000000000000000100000000000000100000000000001000000000000000000000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000100000000001000000000000001000000000000000001000000100000000000000000000000000100001000000000000000000000000000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000001000000000000000000000000001000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001000000000000000000000000100000000001000000000000000000000000010000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000001000000000001000000000000000000000000010000000000000000000000000000010000000000100000000000000000000000000000000000000100000000000000000000000001000000000000000000000000100000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000100000000000000000000000000000000000000000000000000000000001000000000000000100000000000000000000000000010000000000000000000000000000000000000000000100000000000000000000000010000000000000000000000000001000000000000000000000000000000000000001000000000000000000000000010000000000000000000000000000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000100000000000000000000000000000100000000001000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000100000000100000000000000000000000000000100000000000100000000000000000000000000000000000001000000000000000000000000000000000000100000000000000000000000000000010000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000001000000000000000000000000000000000000000100000000000000000000000000000000000000000000001000000000000000000001000000001000000000000000001000000000000000000000000000000000000000000000001000000000000000000000000000010000000010000000000010000000000000000000000000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000001000000000000000000000000000000000000000000000000000000000001000000000000000000000000000100000000000000000000000000000000000100000000000000000100000000000100000000000000000000000000000010000001000000000001000000000000000001000000000000000000000000000000100100000000000010000000000000000100000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000000001000000000000000000000000000000000100000000000000000000000000000000000001000000000000000000000000000000000000000100000000000000000000001000000000000000000000000000001000000000000000000000100000000000000000000010000000000000000
8Monday, January 28, 13

support this. Third, we can compare the fit of a range of models of language
lineage evolution and spatial di↵usion, including di↵erent cognate replacement
models and relaxing the assumption of constant rates of change across the tree.
We can also use simulated data to evaluate the accuracy of our findings and
how robust results are to violations of model assumptions. We can therefore
be confident that, for example, the binary coding of the cognate data allows
accurate phylogenetic inference, and that inferences are not impaired by the
presence of realistic rates of borrowing between lineages (32, 36, 37 ). Finally,
we can explicitly test between competing origin hypotheses by quantifying their
relative support, given our data and model (1, 2, 32 ).
Given a binary matrix representing the presence (1) or absence (0) of each
cognate set in each language, we model the process of cognate gain and loss
using transition rates defined as the probability of a cognate appearing (0 ! 1)
or disappearing (1 ! 0) along each branch over a given amount of time. Starting
at the root of the tree, an ancestral Indo-European language comprising some
set of cognates thus evolves through descent with modification into the Indo-
European languages we observe today.
Let D = {D1, . . . , Dm
} represent m columns of cognate presence/absence
data, with each column spanning n languages. Data element Dj,k
(1 j m, 1 k n) indicates the presence or absence of cognate j in language k. The
distribution of interest is the distribution of language trees given the cognate
data, that is, P (T |D) where T is the tree. Using Bayes theorem, this can be
interpreted through
P (T |D) / P (T )P (D|T ) (1)
where P (T ) is the prior on the tree, P (D|T ) the likelihood and P (T |D) the
posterior. Considering individual cognates,
P (D|T ) =mY
j=1
P (Dj
|T )
The tree T has languages at its leaves. The branches of the tree are labeled
with time, which allows us to write the likelihood for the jth cognate P (Dj
|T )
4
Prior Probability of a tree Fit of the data to the treePosterior Probability of a tree
Cognates are independent from each other, we multiply the likelihood (data-model fit)
for P(D|T) we need a model to change the cognates (stochastic Dollo: gaining state is difficult, loosing state is easy.)
9Monday, January 28, 13

Figure S7: 32x32 grid locations. In rotated Mercator projection (top) and drawnon a standard Mercator projection (bottom).
30
Brownian motion model to model the geographical expansion of languagescreating a set of ordinary differential equations
10Monday, January 28, 13

features such as mountains or deserts. Consider a K ⇥ K matrix R = {rk`
},where r
k`
is the infinitesimal transition rate (proportional to the finite-time
transition probability) for moving from location type k to type ` given that two
locations are adjacent. Then infinitesimal-time rate matrix ⇤ = {�ij
}, can be
defined as
�ij
= rT (i)T (j) for j 2 � (i)
�ii
= �X
j 6=i
�ij
,
�ij
= 0 elsewhere
The finite-time transition probabilities for this CTMCmodel satisfy the Chapman-
Kolmogorov equation
P (t) = �tP (t)⇤ with initial conditions P (0) = I, (8)
The solution of this ODE is
P (t) = exp (t⇤) . (9)
Computing the matrix exponential in (9) is best approached through numeric
approximation. For very small �t, a first-order Taylor expansion
exp (�t⇤) ⇡ I +�t⇤ = P
furnishes approximate equality between a discrete time Markov chain (DTMC)
and CTMC representations. The corresponding DTMC unfolds as
pij
= rT (i)T (j) ⇥�t for j 2 � (i) ,
pii
= 1�X
j 6=i
pij
, (10)
pij
= 0 elsewhere
where �t is a small time increment. This is known as the Euler method for
solving the ODE from Equation (8).
Neighborhood Definition and Parameterization
Now the ODE is derived we are ready to describe the method of discretization
and parameterization. With the Euler method it is computationally feasible
13
kl
11Monday, January 28, 13
0.0
1000.0
2000.0
3000.0
4000.0
5000.0
6000.0
7000.0
8000.0
Czech
Wakhi
Tocharian_B
Old_High_German
Old_Prussian
Slovak
Singhalese
Irish_A
Gujarati
Czech_E
Old_English
Sardinian_C
Romansh
Polish
Scots_Gaelic
Cornish
Urdu
Russian
Dutch_List
Afghan
Walloon
Old_Church_Slavonic
Portuguese_ST
Spanish
Romanian_List
Byelorussian
Greek_Mod
Digor_Ossetic
Old_Persian
Armenian_List
French
Baluchi
Lusatian_U
Welsh_C
Greek_ML
Gothic
Ladin
Old_Norse
Assamese
Romani
Faroese
Lahnda
Lusatian_L
Persian_List
Sindhi
Riksmal
Armenian_Mod
Sardinian_L
Vedic_Sanskrit
Breton_SE
Kurdish
Provencal
Hittite
Hindi
Friulian
Luvian
Welsh_N
Ukrainian
Iron_Ossetic
Latvian
Luxembourgish
Bihari
Serbocroatian
Old_Irish
Sardinian_N
Tadzik
Icelandic_ST
Albanian_G
Bulgarian
Breton_ST
Swedish_Up
Classical_Armenian
Latin
Catalan
German_ST
Breton_List
English_ST
Tocharian_A
Albanian_Top
Marathi
Albanian_C
Lycian
Kashmiri
Macedonian
Frisian
Umbrian
Swedish_List
Nepali_List
Vlach
Oriya
Lithuanian_ST
Albanian_K
Marwari
Ancient_Greek
Slovenian
Waziri
Danish
Bengali
Oscan
Italian
Flemish
Swedish_VL
Avestan
12Monday, January 28, 13
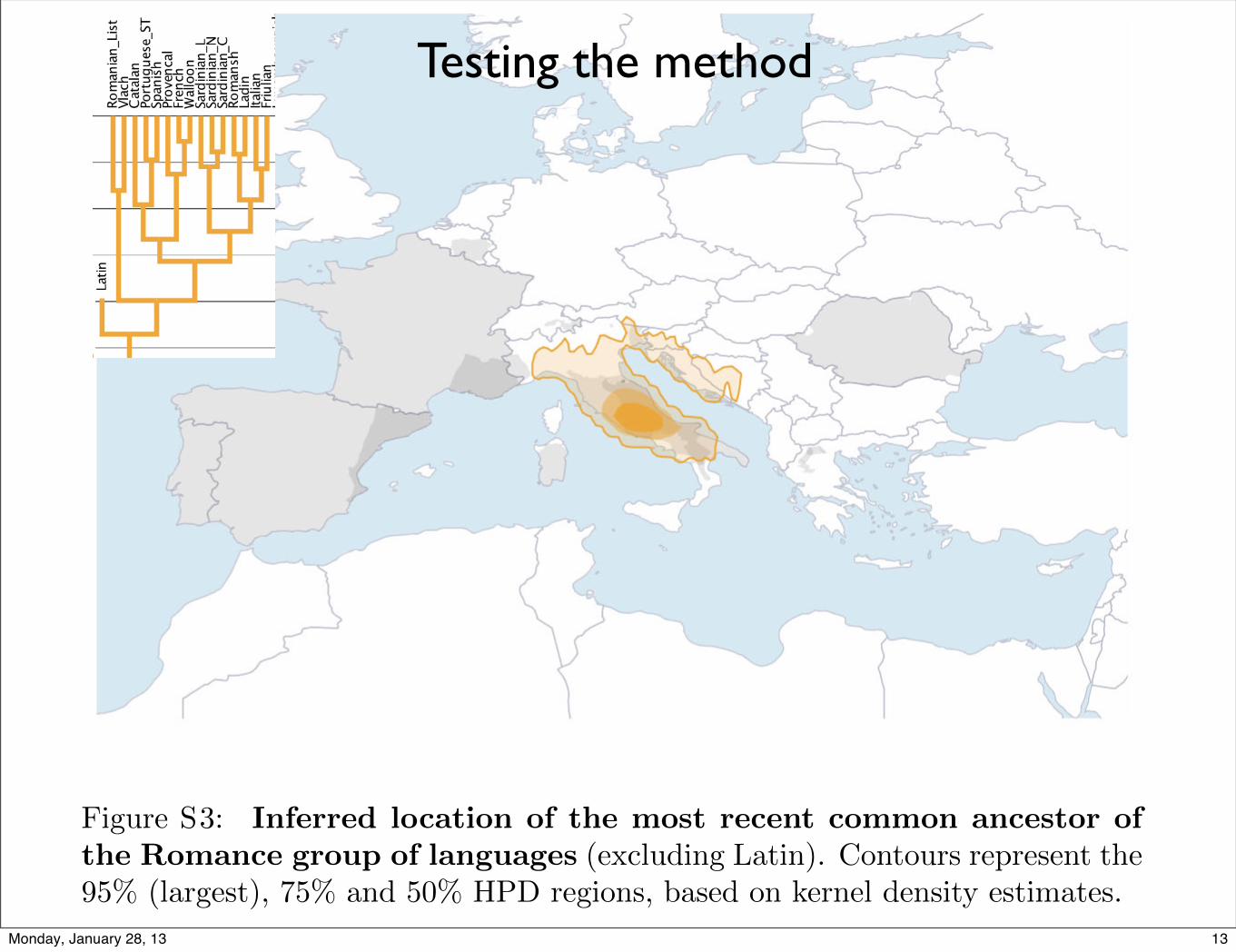
Figure S3: Inferred location of the most recent common ancestor ofthe Romance group of languages (excluding Latin). Contours represent the95% (largest), 75% and 50% HPD regions, based on kernel density estimates.
26
Testing the method
13Monday, January 28, 13
As the earliest representatives of the mainIndo-European lineages, our 20 ancient languagesmight provide more reliable location informa-tion. Conversely, the position of the ancient lan-guages in the tree, particularly the three Anatolianvarieties, might have unduly biased our resultsin favor of an Anatolian origin. We investigatedboth possibilities by repeating the above analy-
ses separately on only the ancient languages andonly the contemporary languages (which ex-cludes Anatolian). Consistent with the analysisof the full data set, both analyses still supportedan Anatolian origin (Table 1).
The RRW approach avoids internal node as-signments over water, but it does assume, alongthe unknown tree branches, the same underlying
migration rate across water as across land. Toinvestigate the robustness of our results to het-erogeneity in rates of spatial diffusion, we devel-oped a second inference procedure that allowsmigration rates to vary over land and water (15).This landscape-based model allows for the in-clusion of a more complex diffusion process inwhich rates of migration are a function of geog-raphy. We examined the effect of varying relativerate parameters to represent a range of differentmigration patterns (15). Figure 1B shows the in-ferred Indo-European homeland under a modelin which migration from land into water is lesslikely than from land to land by a factor of 100.At the other extreme, we fit a “sailor”model withno reluctance to move into water and rapid move-ment across water. Consistent with the findingsbased on the RRW model, each of the landscape-based models supports the Anatolian farmingtheory of Indo-European origin (Table 1).
Our results strongly support an Anatolianhomeland for the Indo-European language family.The inferred location (Fig. 1) and timing [95%highest posterior density (HPD) interval, 7116 to10,410 years ago] of Indo-European origin is con-gruent with the proposal that the family beganto diverge with the spread of agriculture from
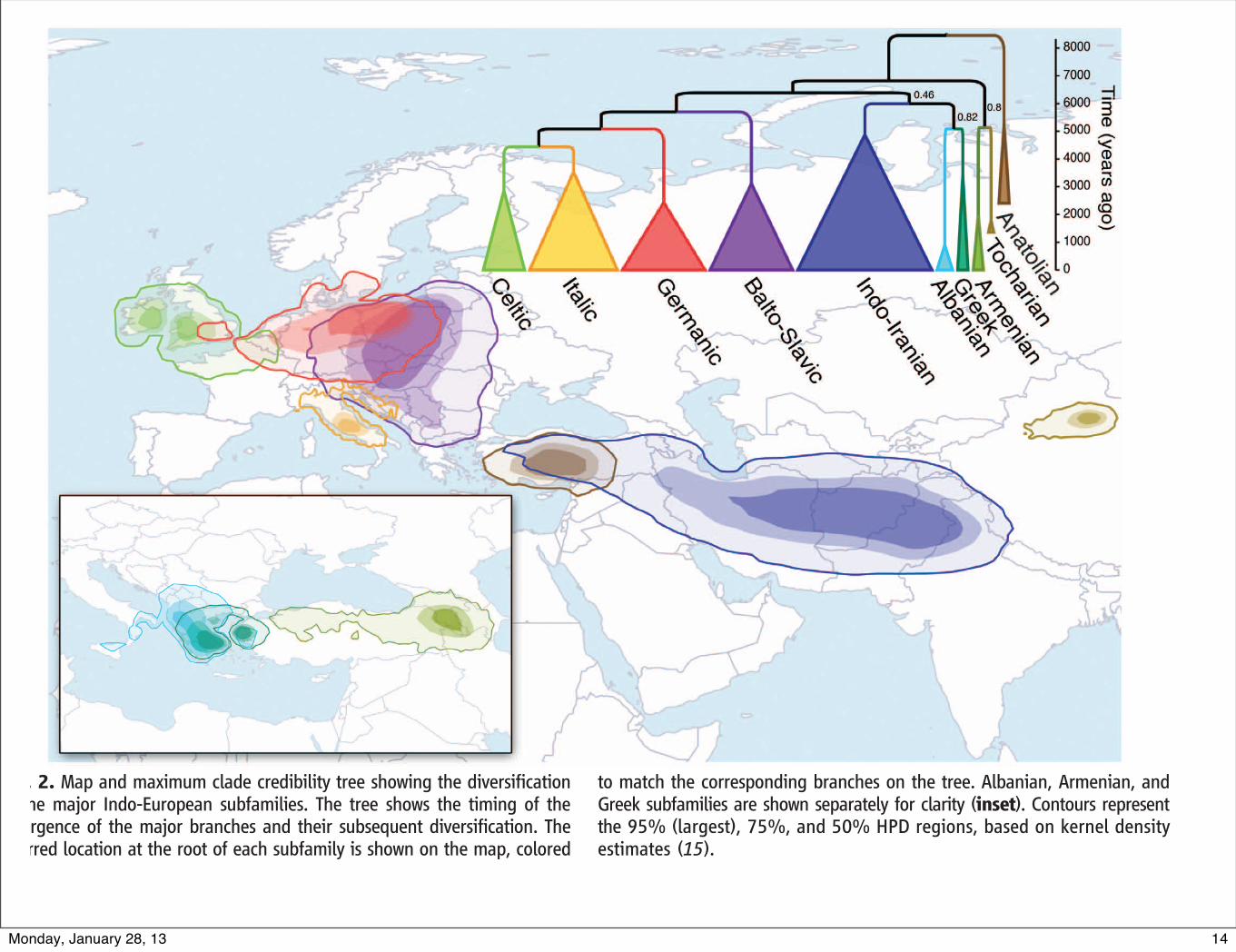
Fig. 2. Map and maximum clade credibility tree showing the diversificationof the major Indo-European subfamilies. The tree shows the timing of theemergence of the major branches and their subsequent diversification. Theinferred location at the root of each subfamily is shown on the map, colored
to match the corresponding branches on the tree. Albanian, Armenian, andGreek subfamilies are shown separately for clarity (inset). Contours representthe 95% (largest), 75%, and 50% HPD regions, based on kernel densityestimates (15).
Table 1. Bayes factors comparing support for the Anatolian and steppe hypotheses. We estimatedBayes factors directly, using expectations of a root model indicator function taken over the MCMCsamples drawn from the posterior and prior of each hypothesis. Bayes factors greater than 1 favoran Anatolian origin. A Bayes factor of 5 to 20 is taken as substantial support, greater than 20 asstrong support, and greater than 100 as decisive (30).
Phylogeographic analysisBayes factor
Anatolian vs. steppe I Anatolian vs. steppe II
RRW: All languages 175.0 159.3RRW: Ancient languages only 1404.2 1582.6RRW: Contemporary languages only 12.0 11.4Landscape aware: Diffusion 298.2 141.9Landscape aware: Migration from land into water less
likely than from land to land by a factor of 10197.7 92.3
Landscape aware: Migration from land into water lesslikely than from land to land by a factor of 100
337.3 161.0
Landscape aware: Sailor 236.0 111.7
www.sciencemag.org SCIENCE VOL 337 24 AUGUST 2012 959
REPORTS
on
Augu
st 3
1, 2
012
ww
w.s
cien
cem
ag.o
rgD
ownl
oade
d fro
m
14Monday, January 28, 13

of an expansion into Europe and the Near Eastby Kurgan seminomadic pastoralists beginning5000 to 6000 years ago (5–7). Evidence from “lin-guistic paleontology”—an approach in which termsreconstructed in the ancestral “proto-language”are used to make inferences about its speakers’culture and environment—and putative early bor-rowings between Indo-European and the Uraliclanguage family of northern Eurasia (8) are citedas possible evidence for a steppe homeland (9).However, the reliability of inferences derived fromlinguistic paleontology and claimed borrowings re-mains uncertain (5, 10). The alternative “Anatolianhypothesis” holds that Indo-European languagesspread with the expansion of agriculture fromAnatolia (in present-day Turkey), beginning 8000to 9500 years ago (11). Estimates of the age of
the Indo-European family derived from modelsof vocabulary evolution support the chronologyimplied by the Anatolian hypothesis, but the in-ferred dates remain controversial (5, 10, 12), andthe implied models of geographic expansion undereach hypothesis remain untested.
To test these two hypotheses, we adapted andextended a Bayesian phylogeographic inferenceframework developed to investigate the origin ofvirus outbreaks from molecular sequence data(13, 14). We used this approach to analyze a dataset of basic vocabulary terms and geographic rangeassignments for 103 ancient and contemporaryIndo-European languages (15–17). Following pre-vious work that applied Bayesian phylogeneticmethods to linguistic data (1–3), we modeled lan-guage evolution as the gain and loss of “cognates”(homologous words) through time (18–20). Wecombined phylogenetic inference with a relaxedrandom walk (RRW) (14) model of continuousspatial diffusion along the branches of an unknown,yet estimable, phylogeny to jointly infer the Indo-European language phylogeny and the most prob-able geographic ranges at the root and internalnodes. This phylogeographic approach treats lan-guage location as a continuous vector (longitudeand latitude) that evolves through time along thebranches of a tree and seeks to infer ancestral lo-cations at internal nodes on the tree while simul-taneously accounting for uncertainty in the tree.
To increase the realism of the spatial diffu-sion, our method extends the RRW process intwo ways. First, to reduce potential bias associatedwith assigning point locations to sampled lan-guages, we use geographic ranges of the languagesto specify uncertainty in the location assignments.Second, to account for geographic heterogeneity,we accommodate spatial prior distributions on theroot and internal node locations. By assigning zero
probability to node locations over water, we canincorporate into the analysis prior informationabout the shape of the Eurasian landmass.
The estimated posterior distribution for thelocation of the root of the Indo-European treeunder the RRW model is shown in Fig. 1A. Thedistribution for the root location lies in the re-gion of Anatolia in present-day Turkey. To quan-tify the strength of support for an Anatolian origin,we calculated the Bayes factors (21) comparingthe posterior to prior odds ratio of a root locationwithin the hypothesized Anatolian homeland (11)(Fig. 1, yellow polygon) with two versions of thesteppe hypothesis—the initial proposed Kurgansteppe homeland (6) and a later refined hypoth-esis (7) (Table 1). Bayes factors show strong sup-port for the Anatolian hypothesis under a RRWmodel. This model allows large variation in ratesof expansion and so is sufficiently flexible to fitthe alternative hypothesis if the data support it.Further, the geographic centroid of the languagesconsidered here falls within the broader steppehypothesis (Fig. 1, green star), indicating that ourmodel is not simply returning the center of massof the sampled locations, as would be predictedunder a simple diffusion process that ignores phy-logenetic information and geographic barriers.
Our results incorporate phylogenetic uncer-tainty given our data and model and so are notcontingent on any single phylogeny. However,phonological and morphological data have beeninterpreted to support an Indo-European branch-ing structure that differs slightly from the patternwe find, particularly near the base of the tree(16). If we constrain our analysis to fit with thisalternative pattern of diversification, we find evenstronger support for an Anatolian origin (in termsof Bayes factors, BFSteppe I = 216; BFSteppe II =227) (15).
Fig. 1. Inferred geographic origin of the Indo-European language family.(A) Map showing the estimated posterior distribution for the location ofthe root of the Indo-European language tree under the RRW analysis. Markovchain Monte Carlo (MCMC) sampled locations are plotted in translucentred such that darker areas correspond to increased probability mass. (B)The same distribution under a landscape-based analysis in which move-ment into water is less likely than movement into land by a factor of 100
(see fig. S5 for results under the other landscape-based models). The bluepolygons delineate the proposed origin area under the steppe hypothesis;dark blue represents the initial suggested Kurgan homeland (6) (steppe I),and light blue denotes a later version of the steppe hypothesis (7) (steppeII). The yellow polygon delineates the proposed origin under the Anatolianhypothesis (11). A green star in the steppe region shows the location of thecentroid of the sampled languages.
1Department of Computer Science, University of Auckland,Auckland 1142, New Zealand. 2Department of Microbiologyand Immunology, Rega Institute, KU Leuven, 3000 Leuven,Belgium. 3Max Planck Institute for Psycholinguistics, Post OfficeBox 310, 6500 AH Nijmegen, Netherlands. 4Donders Institutefor Brain, Cognition and Behaviour, Radboud University Nijmegen,Kapittelweg 29, 6525 EN Nijmegen, Netherlands. 5Department ofPsychology, University of Auckland, Auckland 1142, New Zealand.6School of Culture, History & Language and College of Asia &the Pacific, Australian National University, 0200 Canberra, ACT,Australia. 7Center for Health Informatics and Bioinformatics, NewYork University School of Medicine, New York, NY 10016, USA.8Allan Wilson Centre for Molecular Ecology and Evolution, Uni-versity of Auckland, Auckland 1142, New Zealand. 9Departmentof Philosophy, Research School of the Social Sciences, AustralianNational University, 0200 Canberra, ACT, Australia. 10Departmentof Biomathematics, David Geffen School of Medicine, Universityof California, Los Angeles, CA 90095, USA. 11Department of Bio-statistics, School of Public Health, University of California, LosAngeles, CA 90095, USA. 12Department of Human Genetics,David Geffen School of Medicine, University of California, LosAngeles, CA 90095, USA. 13Institute of Cognitive and EvolutionaryAnthropology, University of Oxford, Oxford OX2 6PN, UK.
*To whom correspondence should be addressed. E-mail:[email protected]
24 AUGUST 2012 VOL 337 SCIENCE www.sciencemag.org958
REPORTS
on
Augu
st 3
1, 2
012
ww
w.s
cien
cem
ag.o
rgD
ownl
oade
d fro
m
15Monday, January 28, 13

opinionated?A key piece of their evidence is that proto-Indo-European had a vocabulary for chariots and wagons that included words for “wheel,” “axle,” “harness-pole” and “to go or convey in a vehicle.” These words have numerous descendants in the Indo-European daughter languages. So Indo- European itself cannot have fragmented into those daughter languages, historical linguists argue, before the invention of chariots and wagons, the earliest known examples of which date to 3500 B.C. This would rule out any connection between Indo-European and the spread of agriculture from Anatolia, which occurred much earlier.“I see the wheeled-vehicle evidence as a trump card over any evolutionary tree,” said David Anthony, an archaeologist at Hartwick College who studies Indo-European origins. [New York Times interview]
Defender of the Kurgan expansion hypothesis
The Misleading and Inconsistent Language Selection in Bouckaert et al.Source: http://geocurrents.info/cultural-geography/linguistic-geography/the-misleading-and-inconsistent-language-selection-in-bouckaert-et-al#ixzz2JGeZeB4f
16Monday, January 28, 13

Verdict
• Historical linguists think the paper is utterly wrong: in data collection, in assumptions, in relationships among languages, they believe that there are too many assumptions (e.g. languages are not viruses)
• It will be interesting to follow this discussion because it seems that historical linguists today are about as opinionated as taxonomists in the sixties when phylogenetic methods came along, perhaps it is time for them to become a modern and embrace Bayesian approaches.
17Monday, January 28, 13