l23 – adder architectures. adders carry lookahead adder carry select adder (staged) carry...
TRANSCRIPT

L23 – Adder Architectures

Adders Carry Lookahead adder Carry select adder (staged) Carry Multiplexed Adder
Ref: text Unit 15
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 2

The carry lookahead adder The generation of all outputs is a direct
function of the inputs. The carry out is a function of all inputs. The msb sum output is also a function of all
inputs. Time of addition is the shortest.
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 3

The equations Create two signals called propagate and generate,
Pi and Gi Pi (A,B) = Ai + Bi or Ai Bi Gi (A,B) = Ai· Bi G is the generate function – when both A and B
are a 1, there is a carry generated P is the propagate function – when a 1 it will
propagate the carry in. When both inputs are 1, the G function generates a
carry so either form of the P function works.9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 4

The equations C1 = G0 + P0 C0 C2 = G1 + P1 C1 C2 = G1 + G0 P1 + C0 P0 P1 C3 = G2 + P2 C2 C3 = G2 + G1 P2 + G0 P1 P2 + C0 P0 P1 P2 C4 = G3 + P3 C3 C4 = G3 + G2 P3 + G1 P2 P3 + G0 P1 P2 P3 + C0 P0 P1 P2 P39/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 5

And the sum output The sum is the conventional equation Sum (i) = A(i) B(i) C(i) If the XOR form of propagate is used Sum (i) = P(i) C(i) Note on CLA – the logic required to
implement it exponentially increases with the number of bits to be added.
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 6

The VHDL – 4-bit carry lookahead ENTITY cla IS
PORT (a,b : IN bit_vector (3 downto 0); cin : IN bit; sum : OUT bit_vector (3 downto 0); cout : OUT bit);END cla;
ARCHITECTURE one OF cla IS SIGNAL P,G : bit_vector (3 downto 0); SIGNAL C : bit_vector (4 downto 0);BEGIN P <= A OR B; G <= A AND B; C(0) <= cin; C(1) <= G(0) OR (P(0) AND C(0)); C(2) <= G(1) OR (G(0) AND P(1)) OR (C(0) AND P(0) AND P(1)); C(3) <= G(2) OR (G(1) AND P(2)) OR (G(0) AND P(1) AND P(2)) OR (C(0) AND P(0) AND P(1) AND P(2)); C(4) <= G(3) OR (G(2) AND P(3)) OR (G(1) AND P(2) AND P(3)) OR (G(0) AND P(1) AND P(2) AND P(3)) OR (C(0) AND P(0) AND P(1) AND P(2) AND P(3)); sum <= P XOR C(3 downto 0);END one;
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 7

And the synthesis Resources used
Combinational LUTs – 8 Pins - 14
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 8

Growth of LUTs For a 6 bit unit
C5 = G4 + P4 C4 C5 = G4 + G3 P4 + G2 P3 P4 + G1 P2 P3 P4 + G0 P1 P2 P3 P4 + C0 P0 P1 P2 P3 P4 C6 = G5 + P5 C5 C6 = G5 + G4 P5 + G3 P4 P5 + G2 P3 P4 P5 + G1 P2 P3 P4 P5 + G0 P1 P2 P3 P4 P5 + C0 P0 P1 P2 P3 P4 P5
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 9

When done for a 5-bit adder Resources
LUTs – 12 Pins - 71
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 10
0
C~3
C~5C~6
C~8C~9
C~10
C~12C~13
C~14C~15
C[1]
C[2]
C[4]
G[0]
G[1]
G[2]
G[3]
P[1]
P[2]
P[3]
P[4]
sum~0
sum~1
sum~2
sum~4
cin
couta[4..0]b[4..0]
sum[4..0]
P[0]
sum~3C[3]

And for a 6-bit CLA Resources
LUTs – 17 Pins – 20
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 11
0
C~6
C~8C~9
C~11C~12
C~13
C~15C~16
C~17C~18
C~20C~21
C~22C~23
C~24
C[1]
C[2]
C[3]
C[4]
C[5]
G[0]
G[1]
G[2]
G[3]
G[4]
P[0]
P[1]
P[2]
P[3]
P[4]
P[5]
sum~0
sum~1
sum~2
sum~3
sum~4
sum~5
cin
couta[5..0]b[5..0]
sum[5..0]

The carry select adder The basic idea is to group the add. The group
of bits is added assuming a 0 carry in and in a parallel adder assuming a 1 carry in. Once the correct carry arrives the valid result is chosen.
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 12

Carry select metrics Speed is better than ripple carry adder but
only by the staging factor. Area growth is linear and a constant factor
more than ripple. Will see this at end of lecture.
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 13

The Carry Multiplexed adder An extension of the Carry select
Speed is on the order of full carry lookahead # gates used is linear growth and ~3x that of a ripple
adder of the same bit with. As speed is about as fast as the add can be completed
and growth is linear this area has the best area time metric of all adders.
This is the adder architecture used in all modern computer architectures.
24 patents exist for CMA architectures.
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 14
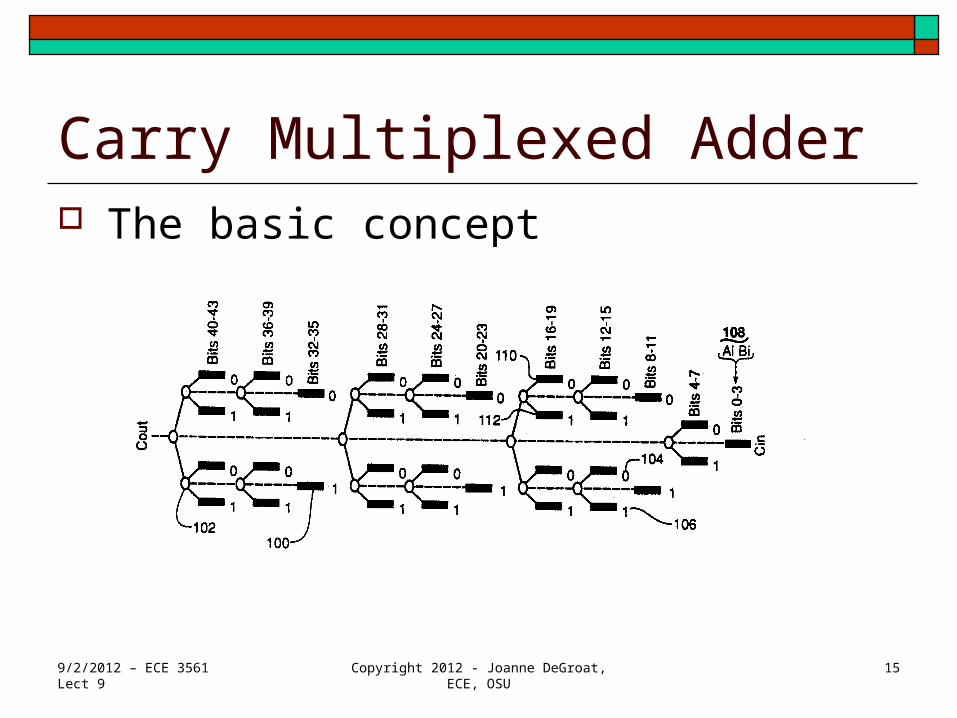
Carry Multiplexed Adder The basic concept
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 15

Goals in the CMA No redundant operations.
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 16

Moving to higher order Still just add twice – presumed 0 and 1
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 17

Adder performance – Area metric Number of gates
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 18

The time metric Speed
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 19

Area Time Metric Area Time Product
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 20

Lecture summary The adder was a simple ripple carry adder.
Other Architectures Carry Lookahead Carry select Carry multiplexed
9/2/2012 – ECE 3561 Lect 9
Copyright 2012 - Joanne DeGroat, ECE, OSU 21