l15: tree-structured algorithms on gpus cs6963l15: tree algorithms
TRANSCRIPT

L15: Tree-Structured Algorithms on GPUs
CS6963 L15: Tree Algorithms

AdministrativeSTRSM due March 17 (EXTENDED)
Midterm comingIn class April 4, open notes
Review notes, readings and review lecture (before break)
Will post prior exams
Design ReviewIntermediate assessment of progress on project, oral and short
Tentatively April 11 and 13
Final projects Poster session, April 27 (dry run April 25)
Final report, May 4
CS6963 L15: Tree Algorithms

Outline• Mapping trees to data-parallel architectures
• Sources:• Parallel scan from Lin and Snyder, _Principles of Parallel Programming_
• “An Effective GPU Implementation of Breadth-First Search,” Lijuan Luo, Martin Wong and Wen-mei Hwu, DAC ‘10, June 2010.
• “Inter-block GPU communication via fast barrier synchronization,” S. Xiao and W. Feng, ?2009 Va. Tech TR?.
• “Stackless KD-Tree Traversal for High Performance GPU Ray Tracing,” S. Popov, J. Gunther, H-P Seidel, P. Slusallek, Eurographics 2007, 26(3), 2007.
CS6963 L15: Tree Algorithms
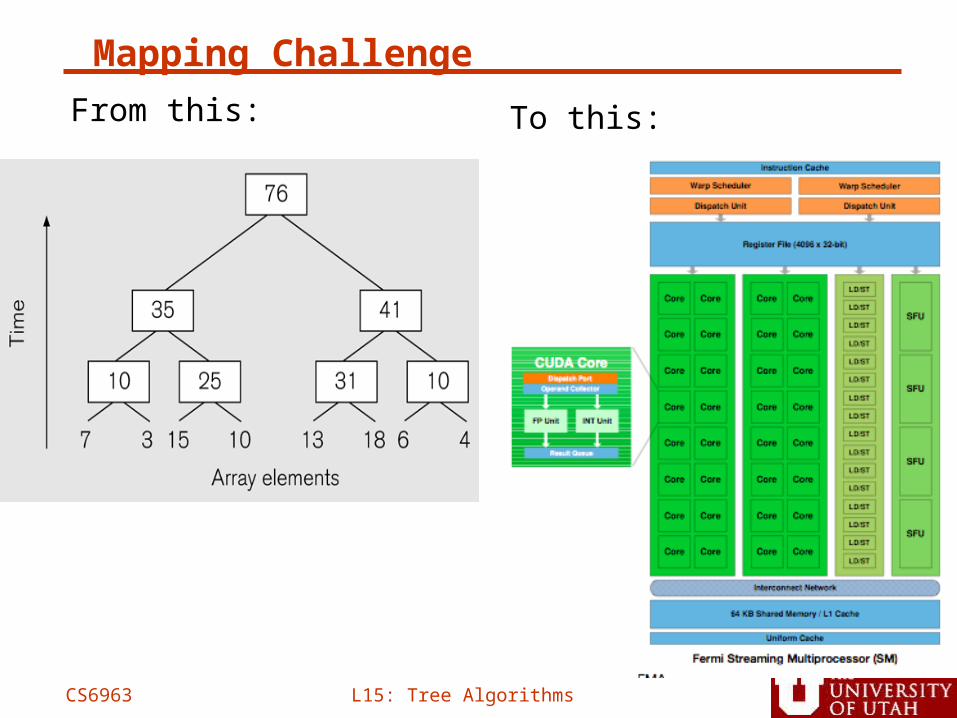
Mapping Challenge
From this:
CS6963 L15: Tree Algorithms
To this:

Simple Example
Parallel Prefix Sum:Compute a partial sum from A[0],…,A[n-1]
Standard way to express it for (i=0; i<n; i++) {
sum += A[i]; y[i] = sum; }
Semantics require:
(…((sum+A[0])+A[1])+…)+A[n-1]
That is, sequential
Can it be executed in parallel?
CS6963 L15: Tree Algorithms

Graphical Depiction of Sum Code
CS6963 L15: Tree Algorithms
Original Order Pairwise OrderWhich decomposition is better suited for parallel execution.

Parallelization Strategy
1. Map tree to flat array
2. Two passes through tree:a. Bottom up: Compute sum for each subtree
and propagate all the way up to root nodeb. Top down:
• Each non-leaf node receives a value from its parent for sum up to current element. It sends the right child the sum of the parent plus left child value computed on top-down pass.
• Leaves add the prefix value from parent and saved value to compute final result.
3. Solution can be found on my website from CS4961 last fall
CS6963 L15: Tree Algorithms
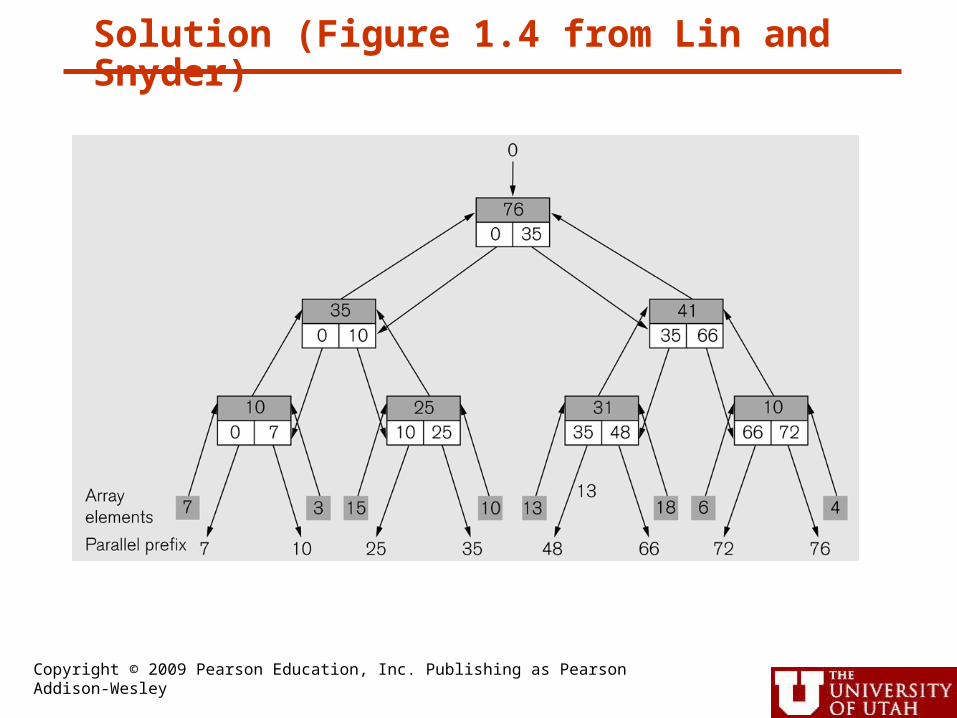
Solution (Figure 1.4 from Lin and Snyder)
Copyright © 2009 Pearson Education, Inc. Publishing as Pearson Addison-Wesley

Breadth First Search
9
Definition: Beginning at a node s in a connected component, explore all the neighboring nodes. Then for each of the neighbors, explore their unexplored neighbors until all nodes have been visited. The result of this search is the set of nodes reachable from s.
Input: G=(V,E) and distinguished vertex sOutput: a breadth first spanning tree with root s
that contains all reachable vertices Key data structure: a frontier queue of nodes
that have been visited at the current level of the tree
CS6963 L15: Tree Algorithms

CS6963 L15: Tree Algorithms
GPU Challenges
Very little work at the root node. Much more work as the algorithm progresses to leaves.
Managing global frontier queue can lead to high overhead.
Sparse matrix implementation (L multiplications corresponding to L levels) can be slower than sequential CPU algorithms for large graphs.
Assumption for this paper: graph is sparse

CS6963 L15: Tree Algorithms
Overview of Strategy
Parallelism comes from propagation from all frontier vertices in parallel.With sparse graph, searching each neighbor of
a frontier vertex in parallel will not have as much work associated with it.
Vary the amount of GPU that is being used depending on threshold of profitabilityA single warp as the baselineA single block as the next levelThe entire device as the outermost level

Overview of Data Decomposition
12
Corresponding mapping of frontier queue to levels in implementation• Hierarchical frontier queue leads to infrequent global synchronization. • Split the frontier queue into levels according to position in the tree
• Lowest level is for a single warp• Next level for per block shared memory • Outermost level is for a larger global memory structure.
CS6963 L15: Tree Algorithms

CS6963 L15: Tree Algorithms
A Few Details
Warp level writes to W-Frontier atomically.Add a single element to queue and update end
of queue Different warps write to different W-Frontier
queues.A B-Frontier is the union of 8 W-Frontiers.
A single thread walks the W-Frontiers to derive indices of frontier nodes.
A G-Frontier is shared across the device.Copies from B-Frontier to G-Frontier are done
atomically. (Can use coalescing.)

CS6963 L15: Tree Algorithms
Global synchronization across blocks uses reference to Va Tech TR.
Approach depends on:Using the entire device, all SMsExact match of blocks to SMsAll SMs must be included in “global barrier” to
prevent deadlock.
Global Synchronization Approach

CS6963 L15: Tree Algorithms
Another Algorithm: K-Nearest Neighbor
Ultimate goal: identify the k nearest neighbors to a distinguished point in space from a set of points
Create an acceleration data structure, called a KD-tree, to represent the points in space.Given this tree, finding neighbors can be
identified for any distinguished pointOne application of K-Nearest Neighbor is ray
tracing
CS6963 L15: Tree Algorithms
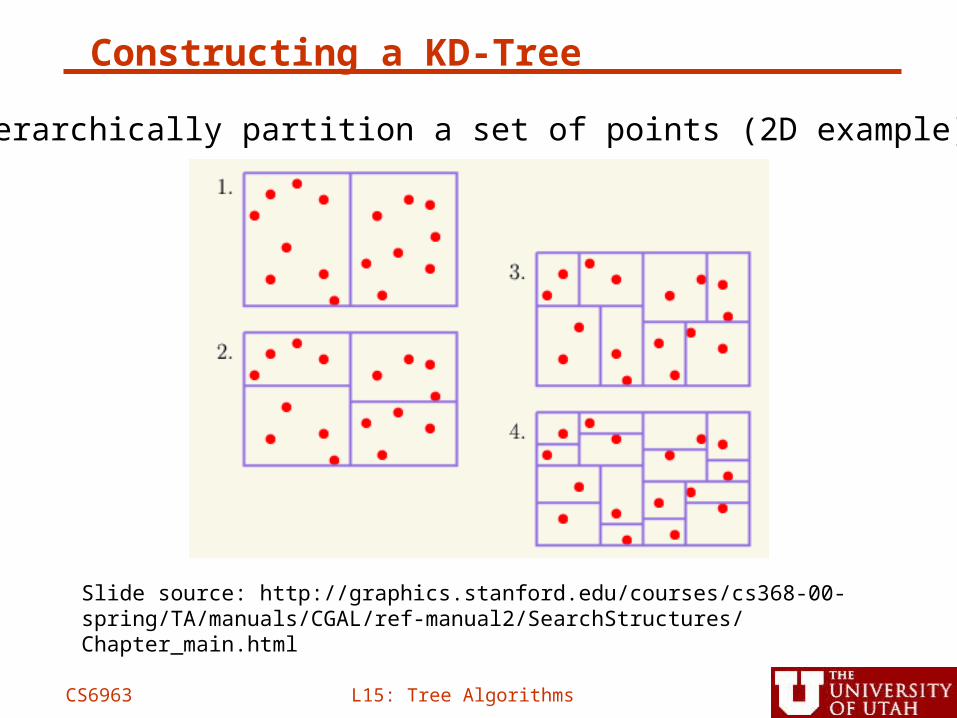
Constructing a KD-Tree
Hierarchically partition a set of points (2D example)
Slide source: http://graphics.stanford.edu/courses/cs368-00-spring/TA/manuals/CGAL/ref-manual2/SearchStructures/Chapter_main.html

CS6963 L15: Tree Algorithms
Representing the KD-Tree
Like the parallel prefix sum, we flatten the tree data structure to represent KD-Tree in memory.Difference: Tree is not fully populated. So,
cannot use linearized structure of parallel prefix sum.
An auxiliary structure, called “ropes”, provides a link between neighboring cells.
Called a “stackless” KD-tree traversal because it is not recursive.

CS6963 L15: Tree Algorithms
Summary of Lecture
To map trees to data parallel architectures with little or no support for recursionFlatten hierarchical data structures into dense
vectorsUse hierarchical storage corresponding to
hierarchical algorithm decomposition to avoid costly global synchronization and minimize global memory accesses.
Possibly vary amount of device participating in computation for different levels of the tree.