knowledge inheritance for pre-trained language models
TRANSCRIPT

Knowledge Inheritance forPre-trained Language Models
Yujia Qin12, Yankai Lin2, Jing Yi1, Jiajie Zhang1, Xu Han1, Zhengyan Zhang1,Yusheng Su1, Zhiyuan Liu1, Peng Li2, Maosong Sun1, Jie Zhou2
1Department of Computer Science and Technology, Tsinghua University2Pattern Recognition Center, WeChat AI, Tencent Inc.
Abstract
Recent explorations of large-scale pre-trained language models (PLMs) such asGPT-3 have revealed the power of PLMs with huge amounts of parameters, set-ting off a wave of training ever-larger PLMs. However, training a large-scalePLM requires tremendous amounts of computational resources, which is time-consuming and expensive. In addition, existing large-scale PLMs are mainlytrained from scratch individually, ignoring the availability of many existing well-trained PLMs. To this end, we explore the question that how can previously trainedPLMs benefit training larger PLMs in future. Specifically, we introduce a novelpre-training framework named “knowledge inheritance” (KI), which combines bothself-learning and teacher-guided learning to efficiently train larger PLMs. Sufficientexperimental results demonstrate the feasibility of our KI framework. We alsoconduct empirical analyses to explore the effects of teacher PLMs’ pre-trainingsettings, including model architecture, pre-training data, etc. Finally, we show thatKI can well support lifelong learning and knowledge transfer1.
1 Introduction
Recently, huge efforts have been devoted to pre-trained language models (PLMs), targeting atacquiring versatile syntactic and semantic knowledge from large-scale corpora [1, 2, 3, 4, 5]. Bytaking full advantage of the rich knowledge distributed in these PLMs, the state-of-the-art acrossa wide range of NLP tasks is continuously being pushed. Up to now, it has become a consensusin the NLP community to use PLMs as the backbone for downstream tasks. Despite the greatfollow-up efforts of exploring various pre-training techniques and model architectures, researchersfind that simply enlarging the model capacity, data size, and training steps can further improvethe performance of PLMs [6]. This discovery sets off a wave of training large-scale PLMs, fromGPT-3 [7] and PANGU-α [8] with hundreds of billions of parameters, to Switch-Transformer [9]with trillions of parameters.
Although these PLMs with huge parameters have shown awesome performance, especially theamazing ability of zero-shot and few-shot learning, training large-scale PLMs requires tremendousamounts of computational resources. For example, about 10, 000 GPUs were used to train GPT-3,costing millions of dollars at a rough estimate. Therefore, severe environmental concerns on theprohibitive computational costs have been raised. Moreover, existing PLMs are generally trainedfrom scratch individually, ignoring the availability of a number of well-trained PLMs. In contrast,humans can leverage the knowledge summarized by their predecessors to learn new tasks, so thatthe learning process could become efficient and effective. This leaves us an important question:How can previously trained PLMs benefit learning larger PLMs in future?
1Our code and data are publicly available at https://github.com/thunlp/Knowledge-Inheritance
Preprint. Under review.
arX
iv:2
105.
1388
0v1
[cs
.CL
] 2
8 M
ay 2
021

We argue that the implicit knowledge distributed in different PLMs is inheritable. In order to train alarger PLM, it is worth reusing the knowledge summarized and organized by an existing well-trainedPLM, which is similar to the learning process of human beings. More specifically, different fromlearning from scratch, we introduce a novel pre-training framework, named “knowledge inheritance”(KI), which combines both self-learning and teacher-guided learning to efficiently train larger PLMs.Intuitively, such a process of inheriting knowledge from teachers is much more efficient and effectivethan the common practice of self-learning.
To some extent, the process of KI is similar to Knowledge Distillation (KD) [10], which transfersthe knowledge from a high-capacity teacher model to a more compact student model. However,conventional KD methods presume that teacher models play pivotal roles in mastering knowledge,and student models with smaller capacities generally cannot match their teachers in performance.When it comes to the scenario of KI, since student models have larger capacities, the performance ofteacher models is no longer an “upper bound” of student models, leading to many challenges thathave not been encountered in KD.
In addition, as more and more PLMs with different pre-training settings (model architectures,training data, training strategies, etc) emerge, it is unclear how these different settings will affect theperformance of KI. Besides, human beings excel at learning knowledge in a lifelong manner, thatis, incrementally acquiring, refining, and transferring knowledge. In real scenarios where data isstreaming, whether larger PLMs can continuously inherit the special skills from multiple smallerteachers and evolve is unanswered. Lastly, the ability to hand down knowledge from generation togeneration is also vital for PLMs, which is not considered in conventional KD methods either.
In this paper, we propose a general KI framework that leverages previously trained PLMs for traininglarger ones. We carry out thorough experiments to rigorously evaluate the feasibility of KI. Wealso systematically conduct empirical analyses to show the effects of various teacher pre-trainingsettings, which may indicate how to select the most appropriate PLM as the teacher for KI. We furtherextend the above framework and show that an already trained large PLM can continuously inheritnew knowledge from multiple models pre-trained on different specific domains; the newly learnedknowledge can further be passed down to descendants. This demonstrates that our KI framework canwell support lifelong learning and knowledge transfer, providing a promising direction to share andexchange the knowledge learned by different models and continuously promote their performance.
2 Knowledge Inheritance Framework
Background. A PLM M generally consists of an embedding layer and N Transformer layers.Given a textual input x = {x1, . . . , xn} and the corresponding label y ∈ RK , whereK is the numberof classes for the specific pre-training task, e.g., the vocabulary size for masked language modeling(MLM) [3],M first converts x to an embedding matrix H0 = [h1
0, ...,hn0 ], which is then encoded by
the Transformer layers into representations Hl = [h1l , ...,h
nl ] at different levels as follows:
[h1l , . . . ,h
nl ] = Transformerl([h1
l−1, . . . ,hnl−1]), l ∈ {1, 2, ..., N}. (1)
Upon these representations, a classifierF is applied to produce task-specific logits zj = [zj1, ..., zjK ] =
F(hjN ) for token xj . Each logit can be then converted to a probability distribution P(xj ; τ) =[p1(x
j ; τ), ..., pK(xj ; τ)] by comparing with other logits using a softmax function with temperatureτ . M is then pre-trained with the objective LSELF(x,y) = H(y,P(x; τ)), where H is the lossfunction, e.g., cross-entropy for MLM.
Knowledge Inheritance. The goal of knowledge inheritance is to train a large PLMML on thecorpora DL = {(xi,yi)}|DL|
i=1 . The common practice of trainingML is to directly optimize LSELFon DL from beginning to end. We first consider a simple scenario that we have a well-trainedsmall PLMMS optimized on DL with the self learning objective (such as MLM) LSELF. Sincewe have already trained a smaller PLMMS , it is worth inheriting the knowledge summarized andorganized byMS , so thatML can at least achieve the same performance as the teacher requiringminor effort. Such a process is far more efficient than learning on ML’s own, which is alignedwith humans’ learning experience that, having a knowledgeable teacher to guide students and clarifytheir faults is more effective than self-learning in most cases. More specifically, impartingMS ’sknowledge to ML on DL is implemented by minimizing the Kullback-Leibler (KL) divergence
2

between two probability distributions output by MS and ML on the same input xi ∈ DL, i.e.,LKI(xi;MS) = τ2KL(PMS
(xi; τ)||PML(xi; τ))). Besides teacher-guided learning,ML is also
encouraged to conduct self-learning by optimizing LSELF(xi,yi). To control how much we wantto trust the knowledge from the teacher, we set an inheritance rate α to balance self-learning andteacher-guided learning:
L(DL;MS) =∑
(xi,yi)∈DL
(1− α)LSELF(xi, yi) + αLKI(xi;MS)
=∑
(xi,yi)∈DL
(1− α)H(yi,PML(xi; 1)) + ατ2KL(PMS
(xi; τ)||PML(xi; τ))).
(2)
Dynamic Inheritance Rate. However, since larger models generally converge faster and canachieve better final performance [11], the PLMML can be seen as a student, who is a fast learner,but with poorer knowledge at first. This is different from conventional KD, where the teacher’sability is the upper bound for the student. In KI, since the student’s learning ability is better than theteacher, it becomes more and more knowledgeable during the learning process, and will surpass theteacher eventually. Thus, it is necessary to encourageML increasingly learning knowledge on itsown, not only memorizing the teacher’s instructions. This can be done by dynamically changingthe inheritance rate α to balance LSELF and LKI. Additionally, afterML has surpassed its teacher,it no longer needs the guidance fromMS and should conduct pure self-learning from then on. Toimplement this, for a total training steps of T , we choose the αt that is linearly decayed with a slopeof αT
T and the student only inherits knowledge from the teacher for TαT
steps, and then conducts pureself-learning, i.e., αt = max(1−αT × t
T , 0). Specifically, at step t = {1, 2, ..., T}, the loss functionfor inheriting knowledge ofMS on DL is formulated as follows:
L(DL;MS) =∑
(xi,yi)∈DL
(1− αt)LSELF(xi, yi) + αtLKI(xi;MS). (3)
Note the logits of MS on DL can be pre-computed and saved offline so that we do not need tore-compute the inference ofMS when training larger PLMs. This process is done once and for all.
Diverse Teachers & Domains. Taking a step further, in real world scenarios, we generally have aseries of well-trained smaller PLMsMS = {M1
S ,M2S , ...,M
NS
S }, each having been optimized onDS = {D1
S ,D2S , ...,D
NS
S }, respectively, and thus gained sufficient knowledge on the correspondingcorpus. Considering that the PLMs inMS , consisting of varied model architectures, are pre-trainedon different corpora of various sizes and domains with arbitrary strategies, thus the knowledge theymaster is also manifold, making it beneficial to letML continuously absorb knowledge from eachteacher. In addition,ML’s pre-training data DL may also consist of massive, heterogeneous corporafrom multiple sources, i.e., DL = {D1
L,D2L, ...,D
NL
L }. Due to the difference between DL and DS ,MS may be required to transfer its knowledge on instances unseen during its pre-training. Ideally,we wantMS to teach the courses it is skilled in so thatML can make the best of teacher models. Tobetter summarize the hybrid knowledge of DL, it is essential to choose the most appropriate teacherM∗S = optimal(MS |D∗L) for each composition D∗L ∈ DL, where optimal denotes the teacherselection strategy. We extensively analyze the effects that contribute to the optimal teacher selectionstrategy in the next section. The overall formulation for inheriting knowledge fromMS on DL is asfollows:
L(DL;MS) =
NL∑i=1
L(DiL; optimal(MS |DiL)) (4)
3 Experiments
In this section, we first present a preliminary experiment to demonstrate the feasibility and effective-ness of KI framework in Section 3.1. Then we systematically conduct empirical analyses to showthe effects of different pre-training settings of the teacher models in Section 3.2. Finally, we showthat our KI framework can well support lifelong learning and knowledge transfer so that PLMs cancontinuously absorb knowledge from multiple teachers in Section 3.3, and PLMs can accumulateknowledge over generations in Section 3.4. All these results show that our KI framework can make
3

0 20k 40k 60k 80k 100k 120kNumber of gradient steps
3
44.18
5
6
7
8
MLM
val
idat
ion
perp
lexi
ty
RoBERTaLARGERoBERTaBASE RoBERTaLARGERoBERTaBASE(final)
20k 30k 40k 50k 60kNumber of gradient steps
4.75
4.955
5.25
5.5
5.75
6
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaMEDIUM RoBERTaBASE_HevisideRoBERTaMEDIUM RoBERTaBASE_ConstantRoBERTaMEDIUM RoBERTaBASE_LinearRoBERTaMEDIUM(final)
10k 20k 30k 40k 50kNumber of gradient steps
5
5.5
6
6.5
7
7.5
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaMEDIUM RoBERTaBASERoBERTaMEDIUM RoBERTaBASE_Top 10RoBERTaMEDIUM RoBERTaBASE_Top 50RoBERTaMEDIUM RoBERTaBASE_Top 100RoBERTaMEDIUM RoBERTaBASE_Top 1000
Figure 1: Left: the validation PPL curve for pre-training ML under KI framework (RoBERTaBASE →RoBERTaLARGE) and the self-learning baseline (RoBERTaLARGE). The teacher’s (RoBERTaBASE) performanceis 4.18. Middle: pre-training RoBERTaBASE under KI with three strategies for the inheritance rate αt:Linear, Heviside and Constant. The teacher’s (RoBERTaMEDIUM) performance is 4.95. Right: pre-trainingRoBERTaBASE under KI with top-K logits, we vary K in {10, 50, 100, 1000}, respectively.
training larger PLMs effective and efficient by taking advantage of existing smaller PLMs. For a faircomparison, we train all models in the same computation environment with 8 NVIDIA 32GB V100GPUs. Detailed hyper-parameters for pre-training are listed in our appendix.
3.1 Preliminary Experiments
Setting. Our KI framework is agnostic to the specific self-supervised pre-training task. Without lossof generality, we focus on the representative MLM task in the main paper and leave the discussion onauto-regressive language modeling in our appendix. We closely follow the pre-training setup andmodel structure of RoBERTa [4]. We first choose RoBERTaBASE as the teacher (MS) architectureand RoBERTaLARGE as the student (ML) architecture in our preliminary experiments.
Since the pre-training corpus of RoBERTa is not available in public, we use the concatenation ofWikipedia and BookCorpus [12] same as BERT [3], with roughly 3, 400M tokens in total. Thetraining-validation ratio is set to 199 : 1. All models are pre-trained for 125k steps, with a batchsize of 2, 048 and a sequence length of 512, and we ensure that they have well converged in the end.Note the whole training computation cost is approximately equivalent to that of BERT [3]. We adoptAdam [13] as the optimizer, warm up learning rate for the first 10% steps and then linearly decay it.
We first pre-train RoBERTaBASE (MS) and then pre-train RoBERTaLARGE (ML) by inheritingMS’sknowledge under KI framework (denoted as “RoBERTaBASE → RoBERTaLARGE”). We compare it with“RoBERTaLARGE” that conducts pure self-learning from beginning to end. For performance evaluation,we report the MLM validation perplexity (PPL) during pre-training and the downstream performanceon development sets of eight GLUE [14] tasks.
Note compared with the self-learning baseline, in KI, the logits output by ML are additionallyused to calculate LKI by comparing with the pre-computed logits ofMS , we empirically find thatthe additional computations are almost negligible compared with the cumbersome computations inTransformer blocks. Therefore, it requires almost the same computational cost between KI and theself-learning baseline for each step. Hence, we report the performance w.r.t pre-training step [15],while the performance w.r.t. FLOPs [16, 17] can be roughly obtained by stretching the figurehorizontally.
Overall Results. As shown in Figure 1 and Table 1, we can find that: (1) training ML underKI framework converges faster than the self-learning baseline, indicating that inheriting theknowledge from an existing teacher is far more efficient than solely discovering such knowledge fromthe plain text. That is, to achieve the same level of validation PPL, KI requires less computationalcost. Specifically, with the guidance of MS , whose validation PPL is 4.18, RoBERTaBASE →RoBERTaLARGE achieves a validation PPL of 3.41 at the end of pre-training, compared with baseline(RoBERTaLARGE) 3.58. After RoBERTaBASE → RoBERTaLARGE breaks away from teacher-guidedlearning at step 40k, it improves the validation PPL from 4.60 (RoBERTaLARGE) to 4.28, whichis almost the performance when the baseline RoBERTaLARGE conducts self-learning for 55k steps,thus saving roughly 27.3% pre-training computations2. (2) ML trained under KI framework
2If we load RoBERTaBASE and compute its inference during pre-training, 18.7% computations can be savedroughly, w.r.t. FLOPs consumed, since the forward passes of the small teacher also take up a small part.
4

Table 1: Downstream performances on GLUE tasks (dev). Our KI framework takes fewer pre-training steps toget a high score after fine-tuning. More detailed results are visualized in our appendix.
Step Model CoLA MNLI QNLI RTE SST-2 STS-B MRPC QQP Avg
5kRoBERTaLARGE 0.0 73.5 81.7 53.0 81.7 45.8 71.4 87.5 61.8
RoBERTaBASE → RoBERTaLARGE 17.4 75.8 83.4 54.7 85.7 72.0 72.6 88.6 68.8
45kRoBERTaLARGE 61.8 84.9 91.7 63.4 92.9 88.6 87.7 91.5 82.8
RoBERTaBASE → RoBERTaLARGE 64.3 85.9 92.2 75.3 93.2 89.3 89.4 91.5 85.2
85kRoBERTaLARGE 64.5 86.8 92.7 69.7 93.5 89.9 89.7 91.7 84.8
RoBERTaBASE → RoBERTaLARGE 65.7 87.2 93.0 77.0 94.3 90.0 90.4 91.8 86.2
125kRoBERTaLARGE 64.3 87.1 93.2 73.4 94.1 90.3 90.1 91.8 85.5
RoBERTaBASE → RoBERTaLARGE 67.7 87.7 93.1 74.9 94.8 90.6 88.2 91.9 86.1
achieves better performance than the baseline on downstream tasks at each step. We alsofound empirically that, under the same setting (e.g., data, hyper-parameters and model architectures),lower validation PPL generally indicates better downstream task performance. Since the performancegain in downstream tasks is consistent with that reflected in the validation PPL, we only showthe latter for the remaining experiments due to the length limit. (3) More evident improvementsfor larger PLMs. We experiment on different sizes of MS and ML in our appendix to furtherdemonstrate the universal superiority of KI over self-learning. We also find with the size of bothMS
andML growing, the improvements from KI become more evident. Concerning the energy cost,for the remaining experiments, unless otherwise specified, we choose RoBERTaMEDIUM (9 layers, 576hidden size) as the teacher architecture and RoBERTaBASE as the student architecture.
Effects of Inheritance Rate. In KI, we set αt in Eq. (3) to be linearly decayed (denoted as Linear)to gradually encourageML exploring knowledge on its own. We analyze whether this design isessential for our framework by comparing it with two other strategies: the first is to only learnfrom the teacher at first and change to pure self-learning (denoted as Heviside) at the 35k-th step;the second is to use a constant ratio (1 : 1) between LSELF and LKI throughout the whole trainingprocess (denoted as Constant). We can conclude from Figure 1 that: (1) annealing at first isnecessary. The validation PPL curve of Linear converges the fastest, while the validation PPL ofHeviside tends to increase after the PLM stops learning from the teacher, indicating that, due to thedifference between teacher-guided learning and self-learning, annealing at first is necessary so thatthe performance won’t decay at the transition point (35k-th step). (2) Teacher-guided learning isredundant afterML surpassesMS . Although Constant performs well in the beginning, its PPLcurve gradually becomes even worse than the other two strategies. The reason is that, afterML hasalready surpassedMS , it will be encumbered by keeping following guidance fromMS .
Saving Storage Space with Top-K Logits. Loading the teacher MS repeatedly for knowledgeinheritance is cumbersome, and an alternative way is to pre-compute and save the predictions ofMS
offline once and for all. We show that using the information of top-K logits [18] can reduce thememory footprint without much performance decrease. Specifically, we save only top-K probabilitiesof PS(xj ; τ) followed by re-normalization, instead of the full distribution over all tokens. ForRoBERTa, the dimension of PS(xj ; τ) is decided by its vocabulary size, which is around 50, 000. Wethus vary K in {10, 50, 100, 1000} to see its effects in Figure 1, from which we observe that: top-Klogits contain the vast majority of information. Choosing a relatively small K is already goodenough for inheriting knowledge from the teacher without much performance decrease compared withthe full distribution. It demonstrates that, for P(xj ; τ), the vast majority of information is containedin the top-K probabilities, while the tail probabilities tend to be some noise, which is aligned withprevious observations [18] to some extent.
3.2 The Effects of Teacher PLM’s Pre-training Setting
Existing PLMs are typically trained under quite different settings, and it is unclear how these differentsettings will affect the performance of KI. To this end, we conduct thorough experiments to analyzethe effects of two representative factors: model architecture and pre-training data. We leave thediscussion on effects ofMS’s pre-training step and batch size in our appendix.
Effects of Model Architecture. The total number of parameters is closely related to the convergencerate of PLMs. Large PLMs generally converge faster and achieve lower validation PPL, which
5

20k 40k 60k 80k 100k 120kNumber of gradient steps
4
4.25
4.5
4.75
5
5.25
5.5
5.75
6
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaD_384 RoBERTaBASERoBERTaD_480 RoBERTaBASERoBERTaD_576 RoBERTaBASERoBERTaD_672 RoBERTaBASE
20k 40k 60k 80k 100k 120kNumber of gradient steps
4
4.25
4.5
4.75
5
5.25
5.5
5.75
6
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaH_4 RoBERTaBASERoBERTaH_6 RoBERTaBASERoBERTaH_8 RoBERTaBASERoBERTaH_10 RoBERTaBASE
10k 20k 30k 40k 50kNumber of gradient steps
5
5.5
6
6.5
7
7.5
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaMEDIUM_ 1
16RoBERTaBASE
RoBERTaMEDIUM_14
RoBERTaBASERoBERTaMEDIUM_1
2RoBERTaBASE
RoBERTaMEDIUM RoBERTaBASE
Figure 2: Left & Middle: effects ofMS’s model architecture (width and depth). Right: effects ofMS’spre-training data size.
means they are fast learners with more knowledge acquired through pre-training, and thus serving asmore competent teachers. We experiment with two widely chosen architecture variations, i.e., width(hidden size) and depth (number of layers), to explore the effects of different model architectures. Wechoose RoBERTaBASE (12 layer, 768 hidden size) asML’s architecture, and choose the architectureof MS to differ from ML in either width or depth. Specifically, for MS , we vary the width in{384, 480, 576, 672}, and the depth in {4, 6, 8, 10}, respectively, and keep other architecture factorsthe same as RoBERTaBASE. We pre-train the corresponding teacherMS on the same data, keepingother pre-training settings the same. The validation PPL curve for each teacher model is shown inour appendix, from which we observe that deeper / wider teachers with more parameters convergefaster and achieve lower final validation PPL during pre-training. After that, we pre-trainML underthe KI framework leveraging these teacher models, respectively. As shown in Figure 2, choosing awider / deeper teacher, which has lower validation PPL, further acceleratesML’s convergence,demonstrating the benefits of learning from a more knowledgeable teacher. Since the performanceof PLMs is weakly related to model shape but highly related to model parameters [11], it is alwaysa better strategy to choose the teacher with more parameters if other settings are kept the same. Inexperiments, we also find empirically that, the optimal duration for teacher-guided learning is longerfor larger teachers, which means it takes more time to learn from a more knowledgeable teacher.
Effects of Pre-training Data. In previous experiments, we assumeML is pre-trained on the samecorpus asMS , i.e., DL = DS . However, in real world scenarios, it may occur that the pre-trainingcorpus used by bothML andMS is mis-matched, due to three main factors: (1) data size. Whentraining larger models, the pre-training corpus is often enlarged to improve downstream performance,i.e., |DS | � |DL|; (2) data domain. PLMs are trained on heterogeneous corpora from varioussources (e.g., news articles, web content, literary works, etc.) with different genres, i.e., PDS
6= PDL.
The different knowledge contained in each domain may affect PLMs’ generalization in variousdownstream tasks; (3) data privacy. Even if both size and domain of data are ensured to be thesame, it can be hard to retrieve the pre-training corpus used byMS due to privacy reasons, with anextreme case: DL∩DS = ∅. The existence of the above factors may hinder the successful knowledgetransferring by requiringMS to teach courses it is not skilled in. We thus design experiments tosystematically analyze the effects of these factors, with three observations concluded:
• Obs. 1: PLMs can image the big from the small for in-domain data. To evaluate the effects ofdata size, we first pre-train teacher models on different partitions of the original training corpus underthe same setting by randomly sampling { 1
16 ,18 ,
14 ,
12 ,
11} of it, resulting in teacher models with final
validation PPL of {5.43, 5.15, 5.04, 4.98, 4.92}, respectively. The final validation PPL increases aswe shrink the size ofMS’s pre-training corpus, which implies that training with less data weakensthe teacher’s ability. Next, we compare the differences when their knowledge is inherited byML. Asreflected in Figure 2, however, the performance of KI is not substantially undermined until only 1
16 ofthe original data is leveraged by the teacher. This indicates that PLMs can well image the overall datadistribution even if it only sees a small part. Hence, when training larger PLMs, unless the data sizeis extensively enlarged, its impact can be largely ignored.
• Obs. 2: Inheriting on similar domain improves performance. To evaluate the effects of datadomain, we experiment on the cases where the pre-training corpus used by MS and ML hasdomain mis-match. Specifically, keeping data size the same (3, 400M tokens), we mix Wikipedia andBookCorpus (WB) used previously with computer science (CS) papers from S2ORC [19], whosegenre (domain) is very different from WB, using different proportions, i.e., WB : CS = {1 : 2, 2 :1, 3 : 1, 4 : 1}, respectively. We pre-trainMS on these constructed corpora and the original WB
6

10k 20k 30k 40k 50kNumber of gradient steps
5
5.5
6
6.5
7
7.5
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaMEDIUM_WB : CS = 1 : 2 RoBERTaBASERoBERTaMEDIUM_WB : CS = 2 : 1 RoBERTaBASERoBERTaMEDIUM_WB : CS = 3 : 1 RoBERTaBASERoBERTaMEDIUM_WB : CS = 4 : 1 RoBERTaBASERoBERTaMEDIUM_WB RoBERTaBASE
10k 20k 30k 40k 50kNumber of gradient steps
5
5.5
6
6.5
7
7.5
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASE_BRoBERTaMEDIUM_A RoBERTaBASE_BRoBERTaMEDIUM_B RoBERTaBASE_B
10k 20k 30k 40k 50k 60kNumber of gradient steps
4
4.5
5
5.5
6
6.5
MLM
val
idat
ion
perp
lexi
ty
G1G2G3G1 G2G1 G3G2 G3G1 G2 G3
Figure 3: Left & Middle: effects of data domain and privacy. Right: knowledge inheritance over generations.
corpus, then test the performance whenML inherits these teachers’ knowledge on the WB domaindata. As shown in Figure 3, with the domain of the constructed corpusMS is trained on becominggradually similar to WB, the benefits from KI become more obvious, which means it is essentialthat bothMS andML are trained on similar domain of data, so thatMS can successfully impartknowledge toML by teaching the “right” course.
• Obs. 3: Data privacy is not important if the same domain is ensured. To evaluate the effectsof data privacy, we experiment in an extreme case where the pre-training corpus ofMS andML
has no overlap at all. To avoid the influences of size and domain, we randomly split the WB domaintraining corpus D into two halves (DA and DB) and pre-train two teacher models (denoted asRoBERTaMEDIUM_A and RoBERTaMEDIUM_B) on them. After pre-training, both of them achieve almostthe same final PPL (4.99) on the same validation set. They are then inherited by the student modelRoBERTaBASE on DB (denoted as RoBERTaMEDIUM_A → RoBERTaBASE_B and RoBERTaMEDIUM_B →RoBERTaBASE_B), which is exactly the pre-training corpus of RoBERTaMEDIUM_B and has no overlapwith that of RoBERTaMEDIUM_A. We also chooseML that conducts pure self-learning on DB as thebaseline (denoted as RoBERTaBASE_B). It is observed from Figure 3 that, there is little differencebetween the validation PPL curves of RoBERTaMEDIUM_A → RoBERTaBASE_B and RoBERTaMEDIUM_B →RoBERTaBASE_B, indicating that whether the pre-training corpus ofMS andML has overlap or not isnot important as long as they share the same domain. This is extremely meaningful when organizationsaim to share the knowledge of their trained PLMs without exposing either the pre-training data orthe model parameters due to privacy concerns. In other words, as long as the recipients preparepre-training data in similar domain, the knowledge can be successfully inherited by receivingMS’spredictions.
3.3 Continual Knowledge Inheritance across Domain
With streaming data of various domains continuously increasing rapidly, training domain-specificPLMs and storing the model parameters for each domain can be prohibitively expensive. To thisend, researchers recently demonstrate the feasibility of adapting PLMs to the target domain throughcontinual pre-training [20], making PLMs continuously acquire new knowledge. In this section, wefurther extend our KI framework to a continual setting and demonstrate that domain adaptation forPLM can benefit from inheriting knowledge of existing domain experts.
Specifically, instead of training large PLMs from scratch, we focus on adapting RoBERTaBASE_WB,which has been well-trained on the concatenation of Wikipedia and BookCorpus (WB domain)for 125k steps with a batch size of 2, 048, to two target domains, i.e., computer science (CS)and biomedical (BIO) papers from S2ORC [19]. The proximity (vocabulary overlap) of threedomains is listed in our appendix. We assume the existence of two domain experts RoBERTaMEDIUM_CSand RoBERTaMEDIUM_BIO, which have been trained on CS and BIO domain for 125k steps witha batch size of 2, 048. Note their training computation is far less than RoBERTaBASE_WB due tofewer model parameters. Hence, either RoBERTaMEDIUM_CS or RoBERTaMEDIUM_BIO is no match forRoBERTaBASE_WB in WB domain but has richer domain knowledge than RoBERTaBASE_WB in CS /BIO domain. For performance evaluation, we compare both (1) the MLM validation PPL on thetarget domain and (2) the performance (test F1) on downstream tasks, i.e. ACL-ARC [21] for CSdomain and CHEMPROT [22] for BIO domain, each repeated 10 times with different seeds. Beforeadaptation, RoBERTaBASE_WB achieves a PPL of 5.41 / 4.86 and F1 of 68.5 / 81.6 on CS / BIO domain,while RoBERTaMEDIUM_CS achieves 2.95 (PPL) and 69.4 (F1) on CS domain, RoBERTaMEDIUM_BIO
7
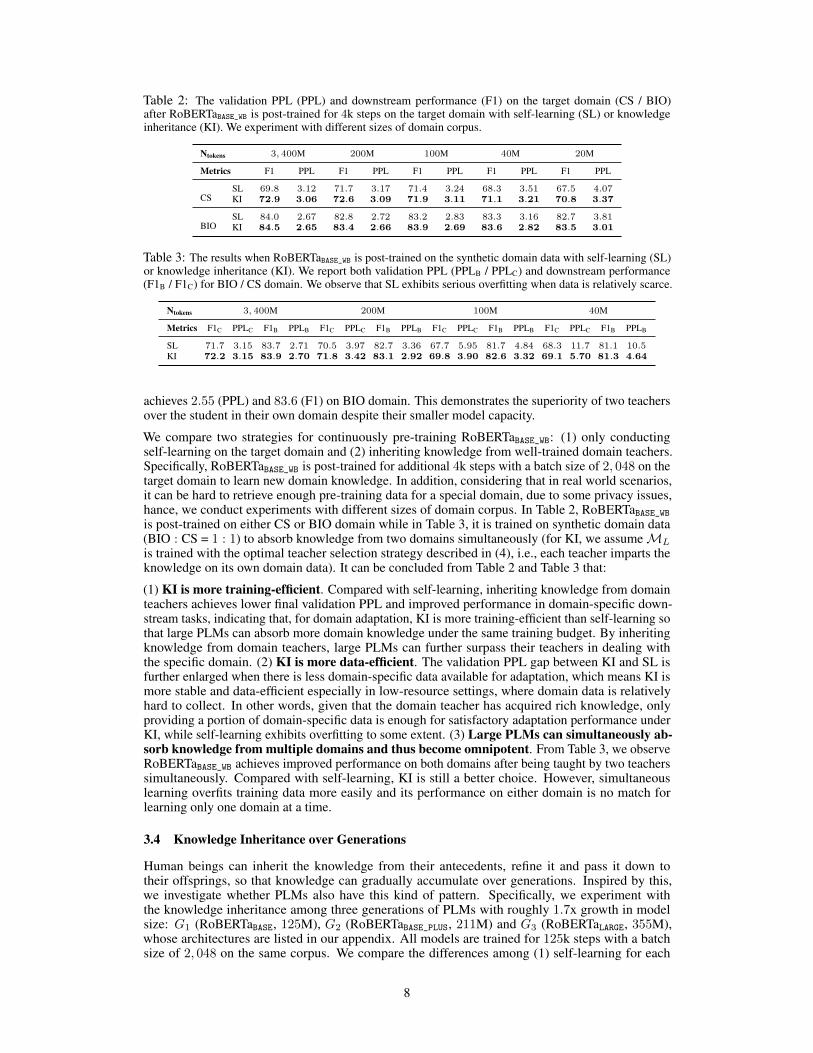
Table 2: The validation PPL (PPL) and downstream performance (F1) on the target domain (CS / BIO)after RoBERTaBASE_WB is post-trained for 4k steps on the target domain with self-learning (SL) or knowledgeinheritance (KI). We experiment with different sizes of domain corpus.
Ntokens 3, 400M 200M 100M 40M 20M
Metrics F1 PPL F1 PPL F1 PPL F1 PPL F1 PPL
CSSL 69.8 3.12 71.7 3.17 71.4 3.24 68.3 3.51 67.5 4.07KI 72.9 3.06 72.6 3.09 71.9 3.11 71.1 3.21 70.8 3.37
BIOSL 84.0 2.67 82.8 2.72 83.2 2.83 83.3 3.16 82.7 3.81KI 84.5 2.65 83.4 2.66 83.9 2.69 83.6 2.82 83.5 3.01
Table 3: The results when RoBERTaBASE_WB is post-trained on the synthetic domain data with self-learning (SL)or knowledge inheritance (KI). We report both validation PPL (PPLB / PPLC) and downstream performance(F1B / F1C) for BIO / CS domain. We observe that SL exhibits serious overfitting when data is relatively scarce.
Ntokens 3, 400M 200M 100M 40M
Metrics F1C PPLC F1B PPLB F1C PPLC F1B PPLB F1C PPLC F1B PPLB F1C PPLC F1B PPLB
SL 71.7 3.15 83.7 2.71 70.5 3.97 82.7 3.36 67.7 5.95 81.7 4.84 68.3 11.7 81.1 10.5KI 72.2 3.15 83.9 2.70 71.8 3.42 83.1 2.92 69.8 3.90 82.6 3.32 69.1 5.70 81.3 4.64
achieves 2.55 (PPL) and 83.6 (F1) on BIO domain. This demonstrates the superiority of two teachersover the student in their own domain despite their smaller model capacity.
We compare two strategies for continuously pre-training RoBERTaBASE_WB: (1) only conductingself-learning on the target domain and (2) inheriting knowledge from well-trained domain teachers.Specifically, RoBERTaBASE_WB is post-trained for additional 4k steps with a batch size of 2, 048 on thetarget domain to learn new domain knowledge. In addition, considering that in real world scenarios,it can be hard to retrieve enough pre-training data for a special domain, due to some privacy issues,hance, we conduct experiments with different sizes of domain corpus. In Table 2, RoBERTaBASE_WBis post-trained on either CS or BIO domain while in Table 3, it is trained on synthetic domain data(BIO : CS = 1 : 1) to absorb knowledge from two domains simultaneously (for KI, we assumeML
is trained with the optimal teacher selection strategy described in (4), i.e., each teacher imparts theknowledge on its own domain data). It can be concluded from Table 2 and Table 3 that:
(1) KI is more training-efficient. Compared with self-learning, inheriting knowledge from domainteachers achieves lower final validation PPL and improved performance in domain-specific down-stream tasks, indicating that, for domain adaptation, KI is more training-efficient than self-learning sothat large PLMs can absorb more domain knowledge under the same training budget. By inheritingknowledge from domain teachers, large PLMs can further surpass their teachers in dealing withthe specific domain. (2) KI is more data-efficient. The validation PPL gap between KI and SL isfurther enlarged when there is less domain-specific data available for adaptation, which means KI ismore stable and data-efficient especially in low-resource settings, where domain data is relativelyhard to collect. In other words, given that the domain teacher has acquired rich knowledge, onlyproviding a portion of domain-specific data is enough for satisfactory adaptation performance underKI, while self-learning exhibits overfitting to some extent. (3) Large PLMs can simultaneously ab-sorb knowledge from multiple domains and thus become omnipotent. From Table 3, we observeRoBERTaBASE_WB achieves improved performance on both domains after being taught by two teacherssimultaneously. Compared with self-learning, KI is still a better choice. However, simultaneouslearning overfits training data more easily and its performance on either domain is no match forlearning only one domain at a time.
3.4 Knowledge Inheritance over Generations
Human beings can inherit the knowledge from their antecedents, refine it and pass it down totheir offsprings, so that knowledge can gradually accumulate over generations. Inspired by this,we investigate whether PLMs also have this kind of pattern. Specifically, we experiment withthe knowledge inheritance among three generations of PLMs with roughly 1.7x growth in modelsize: G1 (RoBERTaBASE, 125M), G2 (RoBERTaBASE_PLUS, 211M) and G3 (RoBERTaLARGE, 355M),whose architectures are listed in our appendix. All models are trained for 125k steps with a batchsize of 2, 048 on the same corpus. We compare the differences among (1) self-learning for each
8

generation (denoted as G1, G2 and G3), (2) knowledge inheritance over two generations (denotedas G1 → G2, G1 → G3 and G2 → G3), and (3) knowledge inheritance over three generations(denoted as G1 → G2 → G3), where G2 first inherit the knowledge from G1, refine it by additionalself-exploring and pass its knowledge down to G3. The results are drawn in Figure 3. Comparingthe performance of G2 and G1 → G2, G3 and G1 → G3, or G3 and G2 → G3, we can againdemonstrate the superiority of KI over self-training as concluded before. Comparing the performanceof G1 → G3 and G1 → G2 → G3, or G2 → G3 and G1 → G2 → G3, it is observed that theperformance of G3 benefits from the involvements of both G1 and G2, which means knowledge isaccumulating through more generations’ involvements.
4 Related Work
Pre-training models on the unlabeled text and then performing task-specific fine-tuning have becomethe dominant method for NLP field [23]. Various early work focuses on pre-training word embeddingsfor downstream tasks, such as Word2Vec [24] and Glove [25]. To handle the polysemy problem ofword embeddings, modern PLMs built on shallow neural networks are proposed, like CoVE [26]and ELMo [27], which can provide contextual word representations. With the introduction ofTransformer [28] and the advance of distributed computing systems, PLMs built on deep neuralnetworks have gradually appeared, such as GPT [1], BERT [3] and XLNet [2]. All these transformer-based PLMs have been regarded as an unequivocal advancement over their predecessors. Thenceforth,numerous efforts have been devoted to investigate better PLMs, including designing effective modelarchitectures [29], formalizing novel pre-training objectives [5, 17, 30, 31], applying additionalsupervision from knowledge base [32, 33, 34, 35], etc. In spite of these efforts, researchers findthat the performance of PLMs can be improved by directly increasing the model size, data size andtraining steps [4, 5, 6, 36, 37], sparking a recent wave of training ever-larger PLMs. For instance,the revolutionary OpenAI GPT-3 [7], which contains 175 billion parameters and is pre-trained on570GB textual data, shows strong few-shot (even zero-shot) capabilities for language understandingand generation. This means that utilizing PLMs with huge parameters for downstream tasks maygreatly relieve the cost of manual labeling and model training for new tasks. The recent birth ofSwitch-Transformer [9] further pushes the parameter bound to 1.6 trillion.
Nevertheless, larger models require greater computational demands and, by extension, greaterenergy demands [38]. To this end, researchers propose to accelerate pre-training by mixed-precisiontraining [39, 40], distributed training [39, 41, 42, 43], large batch optimization [44] and architectureinnovation (layer sharing [37] and progressive layer dropping [45]). Another line of methods [46, 47]proposes to pre-train larger PLMs progressively. They first train a small PLM, and then graduallyincrease the depth or width of the network based on parameter initialization. However, they requirethat the architectures of both models are matched to some extent, making progressive training hard tobe implemented practically for the goal of KI because the architecture of a large model can be chosenarbitrarily, let alone other advanced non-trivial Transformer structure modifications. In addition,progressive training is not applicable for absorbing knowledge from multiple teacher models andcontinual KI, which is important in practice.
Our work is also related to Knowledge Distillation (KD) [10], which is designed for model compres-sion initially and has renewed a surge of interest in PLMs recently [48, 49, 50, 51, 52, 53, 54]. Asmentioned before, conventional KD presumes the pivotal role of the teacher in mastering knowledgeand the teacher performance is an “upper bound” for the student. However, in KI, the student isexpected to surpass the teacher eventually.
5 Conclusion
In this work, we propose a general KI framework that leverages previously trained PLMs fortraining larger ones, and conduct thorough experiments to demonstrate its feasibility. In addition,we comprehensively analyze various pre-training settings of the teacher model that may affectKI’s performance. Finally, we extend KI and show that it can well support continual learning andknowledge transfer so that large PLMs can continuously absorb knowledge from multiple smallteachers. In general, we provide a promising direction to share and exchange the knowledge learnedby different models and continuously promote their performance.
9

Appendices
A Additional Experiments and Analysis
A.1 Effects of Model Size
We experiment on four PLMs with roughly 1.7x growth in model size: M1 (RoBERTaMEDIUM,73.5M), M2 (RoBERTaBASE, 125M), M3 (RoBERTaBASE_PLUS, 211M) and M4 (RoBERTaLARGE,355M), whose architectures are listed in Table 5. We first pre-train a teacher PLM Mi (MS)for 125k steps with a batch size of 2, 048 under the same setting then train a larger oneMi+1 (ML)by inheritingMi’s knowledge under KI framework (denoted asMi →Mi+1, i ∈ {1, 2, 3}). WecompareMi →Mi+1 withMi+1 that conducts self-learning from beginning to end. As shown inFigure 4, the superiority of KI is observed across all models. In addition, with the overall modelsize ofMS andML gradually increasing, the benefits of KI become more evident, reflected in thebroader absolute gap between the PPL curve ofMi →Mi+1 andMi+1 when i gradually grows.This implies that with the advance of computing power, training future larger PLMs will benefit moreand more from our KI framework.
A.2 Effects of Pre-training Steps
Longer pre-training has been demonstrated as an effective way for PLMs to achieve better perfor-mance [4] and thus become more knowledgeable. To evaluate the benefits of more pre-trainingsteps for MS , we first vary RoBERTaMEDIUM’s pre-training steps in {62.5k, 125k, 250k, 500k},and keep all other settings the same. This results in teacher models with final validation PPL of{5.25, 4.92, 4.72, 4.51}, respectively. Then we compare the performances when RoBERTaBASE learnfrom different teachers in Figure 4, from which we can conclude that, inheriting knowledge fromteachers with longer pre-training time helpsML converge faster. However, such a benefit is lessand less obvious asMS’s pre-training steps increase, and the reason is that, after enough trainingcomputations invested, the teacher model enters a plateau of convergence in validation PPL (wefound empirically that, all the models used in this paper have well converged after being pre-trainedfor 125k steps on the corpus with a batch size of 2, 048, longer pre-training only results in limitedperformance gain in either PPL or downstream performance.). And digging deeper in knowledgebecomes even harder and the bottleneck more lies in other factors, e.g., the size and diversity ofpre-training data, which hinderMS from becoming more knowledgeable.
A.3 Effects of Batch Size
Batch size is highly related to PLM’s training efficiency, previous work [4, 11, 55] found that slow-but-accurate large batch sizes can bring improvements to model training, although the improvementsbecome marginal after increasing the batch size beyond a certain point (around 2, 048). BERT [3]is pre-trained for 1, 000k steps with a batch size of 256, and the computational cost is equivalentto training for 125k steps with a batch size of 2, 048 [4]. Choosing RoBERTaMEDIUM as the teachermodel and RoBERTaBASE as the student model, in Figure 4 we compare the validation PPL aswe vary the batch size in {256, 512, 1024, 2, 048}, controlling for the number of passes throughthe pre-training corpus. Following the common practice, we also vary the peak learning rate in{1.0 × 10−4, 2.5 × 10−4, 3.8 × 10−4, 5.0 × 10−4} and pre-train for {1, 000k, 500k, 250k, 125k}steps, respectively, when increasing the batch size. We observe that increasing the batch size resultsin improved final validation PPL, which is aligned with previous findings [4]. When adjusting batchsize, KI improves the convergence rate unanimously, and its benefits become more evident whentraining with a smaller batch size, reflected in the absolute improvement in final validation PPL. Wehypothesize that this is because learning from the smoothed target probability of KI, containing richsecondary information [56] or dark knowledge [57], makes the pre-training process more stable. Thestudent PLM is prevented from fitting to unnecessarily strict distributions and can thus learn fasterand more efficiently.
A.4 Experiments on GPT
To demonstrate that our KI framework is agnostic to the specific self-supervised pre-training task, inaddition to the experiments on MLM in the main paper, we conduct experiments on auto-regressive
10

20k 40k 60k 80k 100k 120kNumber of gradient steps
3
4
5
6
7
8
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaBASE_PULSRoBERTaLARGERoBERTaMEDIUM RoBERTaBASERoBERTaBASE RoBERTaBASE_PULSRoBERTaBASE_PULS RoBERTaLARGE
10k 20k 30k 40k 50kNumber of gradient steps
5
5.5
6
6.5
7
7.5
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaMEDIUM_62.5k RoBERTaBASERoBERTaMEDIUM_125k RoBERTaBASERoBERTaMEDIUM_250k RoBERTaBASERoBERTaMEDIUM_500k RoBERTaBASE
2k 4k 6k 8k 10kNumber of gradient steps
4.0
4.5
5.0
5.5
6.0
6.5
7.0
7.5
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASE_2048RoBERTaBASE_1024RoBERTaBASE_512RoBERTaBASE_256RoBERTaMEDIUM RoBERTaBASE_2048RoBERTaMEDIUM RoBERTaBASE_1024RoBERTaMEDIUM RoBERTaBASE_512RoBERTaMEDIUM RoBERTaBASE_256
Figure 4: Effects of model size (left), pre-training step (middle) and batch size (right) for pre-trainingML
under KI framework.
10k 20k 30k 40k 50kNumber of gradient steps
25
30
35
40
45
MLM
val
idat
ion
perp
lexi
ty
GPTBASEGPTBASE_PLUSGPTMEDIUM GPTBASEGPTBASE GPTBASE_PLUS
1k 2k 3k 4k 5kNumber of gradient steps
3.0
3.1
3.2
3.3
3.4
3.5
3.6
MLM
val
idat
ion
perp
lexi
ty
RoBERTaCS_40MRoBERTaBASE_WB CS_40MRoBERTaCS_100MRoBERTaBASE_WB CS_100MRoBERTaCS_200MRoBERTaBASE_WB CS_200MRoBERTaCS_3400MRoBERTaBASE_WB CS_3400M
1k 2k 3k 4k 5kNumber of gradient steps
2.6
2.7
2.8
2.9
3.0
3.1
3.2
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBIO_40MRoBERTaBASE_WB BIO_40MRoBERTaBIO_100MRoBERTaBASE_WB BIO_100MRoBERTaBIO_200MRoBERTaBASE_WB BIO_200MRoBERTaBIO_3400MRoBERTaBASE_WB BIO_3400M
Figure 5: Left: experiments of auto-regressive language modeling for GPT. Middle & Right: adaptingRoBERTaBASE_WB to CS (middle) / BIO (right) domain with different number of training steps on differentsizes of domain data. We compare two strategies: self-learning and KI. For example, RoBERTaCS_3400M de-notes post-training RoBERTaBASE_WB with the self-learning strategy on the 3, 400M token CS domain corpus.RoBERTaBASE_WB→CS_3400M denotes post-training RoBERTaBASE_WB with the KI strategy on the 3, 400M token CSdomain corpus.
language modeling and choose GPT [1] as the PLM structure. Specifically, we choose three archi-tectures: GPTMEDIUM, GPTBASE and GPTBASE_PLUS with their specific architecture hyper-parametersspecified in Table 5. We experiment with GPTMEDIUM → GPTBASE and GPTBASE → GPTBASE_PLUS,and compare them with the self-training baseline GPTBASE and GPTBASE_PLUS, respectively. All theteacher models are pre-trained for 62.5k steps with a batch size of 2, 048. As reflected in Figure 5,training larger GPTs under our KI framework converges faster than the self-learning baseline, whichdemonstrates that KI is agnostic to the specific pre-training task and PLM structure chosen.
A.5 Additional Experiments for Continual Knowledge Inheritance across Domain
Table 4: The validation PPL on the source domain (WB) after RoBERTaBASE_WB is post-trained on the targetdomain (CS / BIO) with self-learning (SL) and knowledge inheritance (KI).
Domain Strategy 3, 400M 200M 100M 40M
CSSL 6.71 7.01 7.39 8.77KI 8.63 9.39 9.48 9.87
BIOSL 7.29 6.61 8.16 10.34KI 10.74 10.78 10.93 11.66
Effects of Number of Post-training Steps. In the main paper, we adapt RoBERTaBASE_WB to CS/ BIO domain by post-training it for 4k steps. In Figure 5, we further visualize the validation PPLfor post-training RoBERTaBASE_WB with different number of steps in {1k, 2k, 3k, 4k, 5k}. We alsoexperiment on different sizes of domain corpus as done in the main paper. We observe that generallythe validation PPL on each domain decreases with the training step growing. The gap between KIand self-learning is further enlarged when post-training RoBERTaBASE_WB on less target domain data.Self-learning exhibits overfitting problems when the data size of the target domain is relatively small,which is not observed under our KI framework, demonstrating that KI can mitigate overfitting tosome extent.
11
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
40
45
50
55
60
65
70
Val
idat
ion
Mat
thew
s cor
r
CoLA
RoBERTaLARGERoBERTaBASE RoBERTaLARGE
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
74
76
78
80
82
84
86
88
Val
idat
ion
Acc
urac
y
MNLI
RoBERTaLARGERoBERTaBASE RoBERTaLARGE
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
82
84
86
88
90
92
94
Val
idat
ion
Acc
urac
y
QNLI
RoBERTaLARGERoBERTaBASE RoBERTaLARGE
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
55
60
65
70
75
Val
idat
ion
Acc
urac
y
RTE
RoBERTaLARGERoBERTaBASE RoBERTaLARGE
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
82
84
86
88
90
92
94
Val
idat
ion
Acc
urac
y
SST-2
RoBERTaLARGERoBERTaBASE RoBERTaLARGE
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
80
82
84
86
88
90
Val
idat
ion
Pear
son
corr
STS-B
RoBERTaLARGERoBERTaBASE RoBERTaLARGE
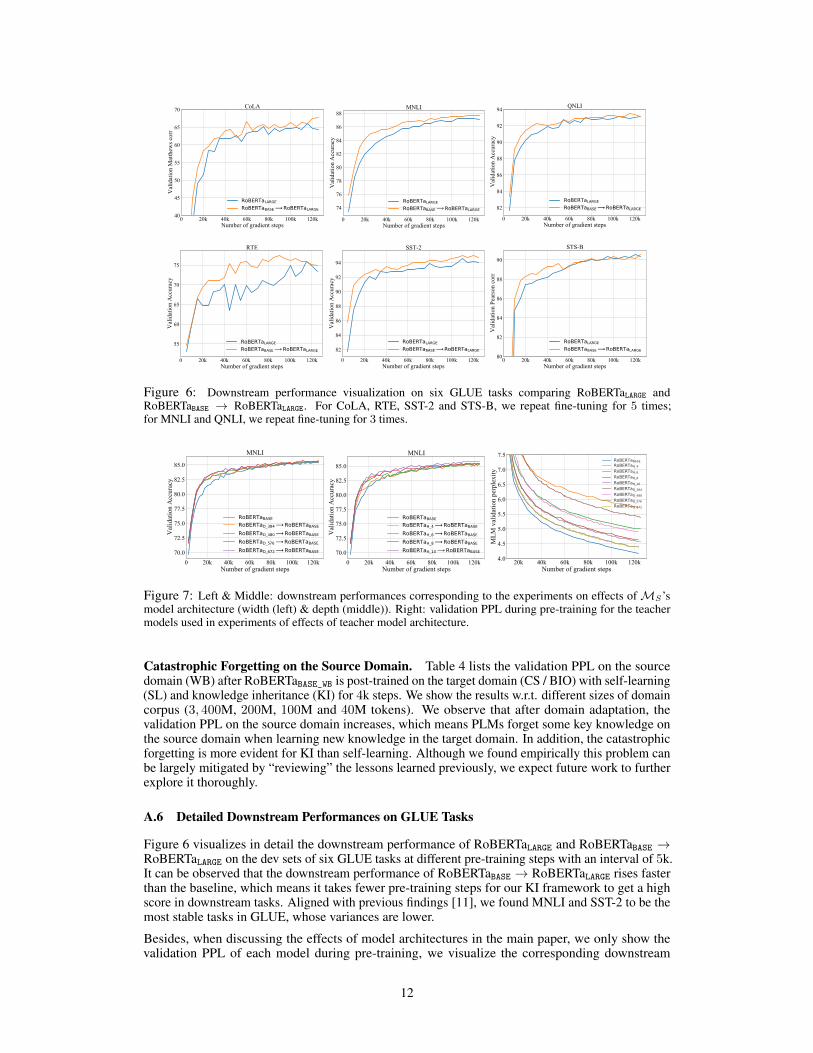
Figure 6: Downstream performance visualization on six GLUE tasks comparing RoBERTaLARGE andRoBERTaBASE → RoBERTaLARGE. For CoLA, RTE, SST-2 and STS-B, we repeat fine-tuning for 5 times;for MNLI and QNLI, we repeat fine-tuning for 3 times.
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
70.0
72.5
75.0
77.5
80.0
82.5
85.0
Val
idat
ion
Acc
urac
y
MNLI
RoBERTaBASERoBERTaD_384 RoBERTaBASERoBERTaD_480 RoBERTaBASERoBERTaD_576 RoBERTaBASERoBERTaD_672 RoBERTaBASE
0 20k 40k 60k 80k 100k 120kNumber of gradient steps
70.0
72.5
75.0
77.5
80.0
82.5
85.0
Val
idat
ion
Acc
urac
y
MNLI
RoBERTaBASERoBERTaH_4 RoBERTaBASERoBERTaH_6 RoBERTaBASERoBERTaH_8 RoBERTaBASERoBERTaH_10 RoBERTaBASE
20k 40k 60k 80k 100k 120kNumber of gradient steps
4.0
4.5
5.0
5.5
6.0
6.5
7.0
7.5
MLM
val
idat
ion
perp
lexi
ty
RoBERTaBASERoBERTaH_4RoBERTaH_6RoBERTaH_8RoBERTaH_10RoBERTaD_384RoBERTaD_480RoBERTaD_576RoBERTaD_672
Figure 7: Left & Middle: downstream performances corresponding to the experiments on effects ofMS’smodel architecture (width (left) & depth (middle)). Right: validation PPL during pre-training for the teachermodels used in experiments of effects of teacher model architecture.
Catastrophic Forgetting on the Source Domain. Table 4 lists the validation PPL on the sourcedomain (WB) after RoBERTaBASE_WB is post-trained on the target domain (CS / BIO) with self-learning(SL) and knowledge inheritance (KI) for 4k steps. We show the results w.r.t. different sizes of domaincorpus (3, 400M, 200M, 100M and 40M tokens). We observe that after domain adaptation, thevalidation PPL on the source domain increases, which means PLMs forget some key knowledge onthe source domain when learning new knowledge in the target domain. In addition, the catastrophicforgetting is more evident for KI than self-learning. Although we found empirically this problem canbe largely mitigated by “reviewing” the lessons learned previously, we expect future work to furtherexplore it thoroughly.
A.6 Detailed Downstream Performances on GLUE Tasks
Figure 6 visualizes in detail the downstream performance of RoBERTaLARGE and RoBERTaBASE →RoBERTaLARGE on the dev sets of six GLUE tasks at different pre-training steps with an interval of 5k.It can be observed that the downstream performance of RoBERTaBASE → RoBERTaLARGE rises fasterthan the baseline, which means it takes fewer pre-training steps for our KI framework to get a highscore in downstream tasks. Aligned with previous findings [11], we found MNLI and SST-2 to be themost stable tasks in GLUE, whose variances are lower.
Besides, when discussing the effects of model architectures in the main paper, we only show thevalidation PPL of each model during pre-training, we visualize the corresponding downstream
12

performance (MNLI) in Figure 7, from which it can be observed that learning from teacher modelswith more parameters helps achieve better downstream performance at the same pre-training step.
A.7 Teacher Models’ Validation PPL Curves for Effects of Model Architecture
Figure 7 visualizes the validation PPL curves for all the teacher models used in the exper-iments on the effects of model architecture. The teacher models differ from RoBERTaBASEin either the depth or width. Specifically, we vary the depth in {4, 6, 8, 10} (denoted as{RoBERTaH_4,RoBERTaH_6,RoBERTaH_8,RoBERTaH_10}), and the width in {384, 480, 576, 672}(denoted as {RoBERTaD_384,RoBERTaD_480,RoBERTaD_576,RoBERTaD_672}). Generally, PLMswith larger model parameters converge faster and achieve better final performance.
B Pre-training Hyper-parameters
Table 5: Model architectures for all the models we used in this paper.
Model Name nparams nlayers dmodel nheads dFFN lr (bs = 2, 048)
RoBERTaMEDIUM 73.5M 9 576 12 3072 5.0× 10−4
RoBERTaD_d - 12 d 12 3072 5.0× 10−4
RoBERTaH_h - h 768 12 3072 5.0× 10−4
RoBERTaBASE 125M 12 768 12 3072 5.0× 10−4
RoBERTaBASE_PLUS 211M 18 864 12 3600 3.5× 10−4
RoBERTaLARGE 355M 24 1024 16 4096 2.5× 10−4
GPTMEDIUM 72.8M 9 576 12 3072 5.0× 10−4
GPTBASE 124M 12 768 12 3072 5.0× 10−4
GPTBASE_PLUS 209M 18 864 12 3600 3.5× 10−4
Table 6: The total number of steps for teacher-guided learning for differentML,MS pairs.
ML MS Steps of teacher-guided learning
RoBERTaBASE
RoBERTaMEDIUM 35kRoBERTaD_384 28kRoBERTaD_480 40kRoBERTaD_576 70kRoBERTaD_672 85kRoBERTaH_4 22kRoBERTaH_6 35kRoBERTaH_8 55kRoBERTaH_10 65k
RoBERTaBASE_PLUS RoBERTaBASE 55k
RoBERTaLARGE
RoBERTaBASE 40kRoBERTaBASE_PLUS 65k
RoBERTaBASE → RoBERTaBASE_PLUS 75k
GPTBASE GPTMEDIUM 10k
GPTBASE_PLUS GPTBASE 15k
Table 5 describes the architectures we used for all models in this paper, covering the details for thetotal number of trainable parameters (nparams), the total number of layers (nlayers), the number of unitsin each bottleneck layer (dmodel), the total number of attention heads (nheads), the inner hidden size ofFFN layer (dFFN) and the learning rate when batch size is set to 2, 048 (lr). We set the dropout ratefor each model to 0.1, weight decay to 0.01 and use linear learning rate decay. The hyper-parametersfor Adam optimizer is set to 1× 10−6, 0.9, 0.98 for ε, β1, β2, respectively. As mentioned in the mainpaper, all experiments are done in the same computation environment with 8 NVIDIA 32GB V100GPUs and it takes around 1 week to pre-train RoBERTaBASE and 2 weeks to pre-train RoBERTaLARGE.It has been shown by previous work [6] that, within a reasonably broad range, the validation PPL is
13

not sensitive to these parameters. All the pre-training implementations are based on fairseq3 [58](MIT-license). As mentioned in the main paper, all the source code and trained models will bepublicly available to advance further research explorations and save energy costs.
Table 6 describes the total number of pre-training steps for each ML, MS pair chosen in ourexperiments. Within a reasonably broad range, the performance of KI is not sensitive to its choice.
C Fine-tuning Hyper-parameters
Table 7: Hyper-parameters for fine-tuning RoBERTa on ACL-ARC, CHEMPROT and GLUE.
HyperParam ACL-ARC & CHEMPROT GLUE
Learning Rate 2× 10−5 {1× 10−5, 2× 10−5, 3× 10−5}Batch Size 256 {16, 32}Weight Decay 0.1 0.1Max Epochs 10 10Learning Rate Decay Linear LinearWarmup Ratio 0.06 0.06
Table 7 describes the hyper-parameters for ACL-ARC, CHEMPROT and GLUE tasks. The selectionof these hyper-parameters follows [4] and [20]. The implementations of ACL-ARC and CHEMPROTare based on [20]4; the implementations of GLUE tasks are based on fairseq5 [58] (MIT-license).
D Domain Proximity of WB, CS and BIO
Table 8: Domain proximity (vocabulary overlap) among three domains (WB, CS, BIO) discussed in this paper.Following [20], we create the vocabulary for each domain by considering the top 10k most frequent words(excluding stopwords).
WB CS BIO
WB 100% 19.1% 25.6%CS 19.1% 100% 22.5%BIO 25.6% 22.5% 100%
Table 8 lists the domain proximity (vocabulary overlap) of WB, CS and BIO used in this paper.
E Limitations and Future Work
There are some limitations which are not addressed in this paper and left as future work: (1) hyper-parameter choice: the total number of pre-training steps of teacher-guided learning is not a knownprior and we need to change the hyper-parameter αT under different circumstances. However, wefound empirically that estimating the optimal choice of αT is relatively easy, and within a reasonablybroad range, the performance of KI is not sensitive to the choice of αT . (2) Catastrophic forgettingproblem: when adapted to a new domain, PLMs exhibit catastrophic forgetting problems on thesource domain, which is not well-addressed in our paper. (3) Data privacy problem: in the main paper,we demonstrate that the knowledge of an existing PLM can be successfully extracted by saving itspredictions on corpus unseen during its pre-training as long as the same domain is ensured. However,it does not mean the privacy of pre-training corpus used by the existing PLM is 100% preserved. Infact, it is still under-explored whether some malicious adversarial attacks can be applied to access theprivate data, causing potential privacy concerns. We expect future work to explore this direction anddesign corresponding defense strategies.
In general, we believe it a promising direction to share and exchange the knowledge learned bydifferent models and continuously promote their performances. In future, we aim to explore the
3https://github.com/pytorch/fairseq4https://github.com/allenai/dont-stop-pretraining5https://github.com/pytorch/fairseq
14

following directions. (1) The efficiency of KI, i.e., given limited computational budget and pre-training corpus, how to more efficiently absorb knowledge from teacher models. Potential solutionsinclude denoising teacher models’ predictions and utilizing more information from the teacher, i.e.,the inner hidden units computed by the teacher. How to select the most representative data pointsfor KI is also an interesting topic. (2) The effectiveness of KI under different circumstances, i.e.,how can KI be applied if the teachers and the students are pre-trained on different vocabularies (e.g.,from BERT to RoBERTa), languages, pre-training objectives (e.g., from GPT to BERT) and evenmodalities. In addition, in the main paper, we systematically analyze the effects of pre-training settingof the teacher model for KI. However, in real world scenarios, we need to consider these effectsjointly to design the optimal teacher selection strategy.
References[1] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding
by generative pre-training,” 2018.[2] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov, and Q. V. Le, “Xlnet: Generalized
autoregressive pretraining for language understanding,” arXiv preprint arXiv:1906.08237, 2019.[3] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional
transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.[4] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer,
and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprintarXiv:1907.11692, 2019.
[5] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu,“Exploring the limits of transfer learning with a unified text-to-text transformer,” arXiv preprintarXiv:1910.10683, 2019.
[6] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad-ford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprintarXiv:2001.08361, 2020.
[7] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan,P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” arXiv preprintarXiv:2005.14165, 2020.
[8] W. Zeng, X. Ren, T. Su, H. Wang, Y. Liao, Z. Wang, X. Jiang, Z. Yang, K. Wang, X. Zhang et al.,“Pangu-α: Large-scale autoregressive pretrained chinese language models with auto-parallelcomputation,” arXiv preprint arXiv:2104.12369, 2021.
[9] W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter modelswith simple and efficient sparsity,” arXiv preprint arXiv:2101.03961, 2021.
[10] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXivpreprint arXiv:1503.02531, 2015.
[11] Z. Li, E. Wallace, S. Shen, K. Lin, K. Keutzer, D. Klein, and J. Gonzalez, “Train big, thencompress: Rethinking model size for efficient training and inference of transformers,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 5958–5968.
[12] Y. Zhu, R. Kiros, R. Zemel, R. Salakhutdinov, R. Urtasun, A. Torralba, and S. Fidler, “Aligningbooks and movies: Towards story-like visual explanations by watching movies and readingbooks,” in Proceedings of the IEEE international conference on computer vision, 2015, pp.19–27.
[13] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprintarXiv:1412.6980, 2014.
[14] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “Glue: A multi-task benchmark and analysis platform for natural language understanding,” arXiv preprintarXiv:1804.07461, 2018.
[15] M. Li, E. Yumer, and D. Ramanan, “Budgeted training: Rethinking deep neural network trainingunder resource constraints,” arXiv preprint arXiv:1905.04753, 2019.
[16] R. Schwartz, J. Dodge, N. A. Smith, and O. Etzioni, “Green ai,” arXiv preprintarXiv:1907.10597, 2019.
15

[17] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “Electra: Pre-training text encoders asdiscriminators rather than generators,” arXiv preprint arXiv:2003.10555, 2020.
[18] X. Tan, Y. Ren, D. He, T. Qin, Z. Zhao, and T.-Y. Liu, “Multilingual neural machine translationwith knowledge distillation,” arXiv preprint arXiv:1902.10461, 2019.
[19] K. Lo, L. L. Wang, M. Neumann, R. Kinney, and D. S. Weld, “S2orc: The semantic scholaropen research corpus,” arXiv preprint arXiv:1911.02782, 2019.
[20] S. Gururangan, A. Marasovic, S. Swayamdipta, K. Lo, I. Beltagy, D. Downey, and N. A.Smith, “Don’t stop pretraining: Adapt language models to domains and tasks,” arXiv preprintarXiv:2004.10964, 2020.
[21] D. Jurgens, S. Kumar, R. Hoover, D. McFarland, and D. Jurafsky, “Measuring the evolution ofa scientific field through citation frames,” Transactions of the Association for ComputationalLinguistics, vol. 6, pp. 391–406, 2018.
[22] J. Kringelum, S. K. Kjaerulff, S. Brunak, O. Lund, T. I. Oprea, and O. Taboureau, “Chemprot-3.0: a global chemical biology diseases mapping,” Database, vol. 2016, 2016.
[23] X. Qiu, T. Sun, Y. Xu, Y. Shao, N. Dai, and X. Huang, “Pre-trained models for natural languageprocessing: A survey,” Science China Technological Sciences, pp. 1–26, 2020.
[24] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations invector space,” arXiv preprint arXiv:1301.3781, 2013.
[25] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,”in Proceedings of the 2014 conference on empirical methods in natural language processing(EMNLP), 2014, pp. 1532–1543.
[26] B. McCann, J. Bradbury, C. Xiong, and R. Socher, “Learned in translation: Contextualizedword vectors,” arXiv preprint arXiv:1708.00107, 2017.
[27] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deepcontextualized word representations,” arXiv preprint arXiv:1802.05365, 2018.
[28] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, andI. Polosukhin, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017.
[29] Y. Tay, M. Dehghani, J. Gupta, D. Bahri, V. Aribandi, Z. Qin, and D. Metzler, “Are pre-trainedconvolutions better than pre-trained transformers?” 2021.
[30] K. Song, X. Tan, T. Qin, J. Lu, and T.-Y. Liu, “Mass: Masked sequence to sequence pre-trainingfor language generation,” arXiv preprint arXiv:1905.02450, 2019.
[31] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, andL. Zettlemoyer, “Bart: Denoising sequence-to-sequence pre-training for natural languagegeneration, translation, and comprehension,” arXiv preprint arXiv:1910.13461, 2019.
[32] Z. Zhang, X. Han, Z. Liu, X. Jiang, M. Sun, and Q. Liu, “Ernie: Enhanced language representa-tion with informative entities,” arXiv preprint arXiv:1905.07129, 2019.
[33] Y. Qin, Y. Lin, R. Takanobu, Z. Liu, P. Li, H. Ji, M. Huang, M. Sun, and J. Zhou, “Erica:Improving entity and relation understanding for pre-trained language models via contrastivelearning,” arXiv preprint arXiv:2012.15022, 2020.
[34] X. Wang, T. Gao, Z. Zhu, Z. Zhang, Z. Liu, J. Li, and J. Tang, “Kepler: A unified model forknowledge embedding and pre-trained language representation,” Transactions of the Associationfor Computational Linguistics, vol. 9, pp. 176–194, 2021.
[35] M. E. Peters, M. Neumann, R. L. Logan IV, R. Schwartz, V. Joshi, S. Singh, and N. A. Smith,“Knowledge enhanced contextual word representations,” arXiv preprint arXiv:1909.04164,2019.
[36] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models areunsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
[37] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Albert: A lite bert forself-supervised learning of language representations,” arXiv preprint arXiv:1909.11942, 2019.
[38] D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, andJ. Dean, “Carbon emissions and large neural network training,” arXiv preprint arXiv:2104.10350,2021.
16

[39] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm:Training multi-billion parameter language models using model parallelism,” arXiv preprintarXiv:1909.08053, 2019.
[40] P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston,O. Kuchaiev, G. Venkatesh et al., “Mixed precision training,” arXiv preprint arXiv:1710.03740,2017.
[41] Y. Huang, Y. Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, H. Lee, J. Ngiam, Q. V. Le,Y. Wu et al., “Gpipe: Efficient training of giant neural networks using pipeline parallelism,”arXiv preprint arXiv:1811.06965, 2018.
[42] N. Shazeer, Y. Cheng, N. Parmar, D. Tran, A. Vaswani, P. Koanantakool, P. Hawkins, H. Lee,M. Hong, C. Young et al., “Mesh-tensorflow: Deep learning for supercomputers,” arXiv preprintarXiv:1811.02084, 2018.
[43] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand,P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model trainingon gpu clusters,” arXiv preprint arXiv:2104.04473, 2021.
[44] Y. You, J. Li, S. Reddi, J. Hseu, S. Kumar, S. Bhojanapalli, X. Song, J. Demmel, K. Keutzer,and C.-J. Hsieh, “Large batch optimization for deep learning: Training bert in 76 minutes,”arXiv preprint arXiv:1904.00962, 2019.
[45] M. Zhang and Y. He, “Accelerating training of transformer-based language models with pro-gressive layer dropping,” arXiv preprint arXiv:2010.13369, 2020.
[46] L. Gong, D. He, Z. Li, T. Qin, L. Wang, and T. Liu, “Efficient training of bert by progressivelystacking,” in International Conference on Machine Learning. PMLR, 2019, pp. 2337–2346.
[47] X. Gu, L. Liu, H. Yu, J. Li, C. Chen, and J. Han, “On the transformer growth for progressivebert training,” arXiv preprint arXiv:2010.12562, 2020.
[48] S. Sun, Y. Cheng, Z. Gan, and J. Liu, “Patient knowledge distillation for bert model compression,”arXiv preprint arXiv:1908.09355, 2019.
[49] V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller,faster, cheaper and lighter,” arXiv preprint arXiv:1910.01108, 2019.
[50] X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu, “Tinybert: Distillingbert for natural language understanding,” arXiv preprint arXiv:1909.10351, 2019.
[51] Y.-C. Chen, Z. Gan, Y. Cheng, J. Liu, and J. Liu, “Distilling knowledge learned in bert for textgeneration,” arXiv preprint arXiv:1911.03829, 2019.
[52] K. Krishna, G. S. Tomar, A. P. Parikh, N. Papernot, and M. Iyyer, “Thieves on sesame street!model extraction of bert-based apis,” arXiv preprint arXiv:1910.12366, 2019.
[53] S. Sun, Z. Gan, Y. Cheng, Y. Fang, S. Wang, and J. Liu, “Contrastive distillation on intermediaterepresentations for language model compression,” arXiv preprint arXiv:2009.14167, 2020.
[54] W. Zhang, L. Hou, Y. Yin, L. Shang, X. Chen, X. Jiang, and Q. Liu, “Ternarybert: Distillation-aware ultra-low bit bert,” arXiv preprint arXiv:2009.12812, 2020.
[55] Y. You, J. Li, J. Hseu, X. Song, J. Demmel, and C.-J. Hsieh, “Reducing bert pre-training timefrom 3 days to 76 minutes,” arXiv preprint arXiv:1904.00962, 2019.
[56] C. Yang, L. Xie, S. Qiao, and A. L. Yuille, “Training deep neural networks in generations: Amore tolerant teacher educates better students,” in Proceedings of the AAAI Conference onArtificial Intelligence, vol. 33, no. 01, 2019, pp. 5628–5635.
[57] T. Furlanello, Z. Lipton, M. Tschannen, L. Itti, and A. Anandkumar, “Born again neuralnetworks,” in International Conference on Machine Learning. PMLR, 2018, pp. 1607–1616.
[58] M. Ott, S. Edunov, A. Baevski, A. Fan, S. Gross, N. Ng, D. Grangier, and M. Auli, “fairseq: Afast, extensible toolkit for sequence modeling,” in Proceedings of NAACL-HLT 2019: Demon-strations, 2019.
17