knowledg graphs yosi mass
TRANSCRIPT

IBM Research
© 2014 IBM Corporation
A Scalable Graph Representation of Knowledge Bases and its Uses for Semantic Document Relatedness
Yosi Mass, Dafna Sheinwald (HRL)Feng Cao, Yuan Ni, Hai Pei Zhang, Qiongkai Xu (CRL)
© 2014 IBM Corporation
IBM Research
2
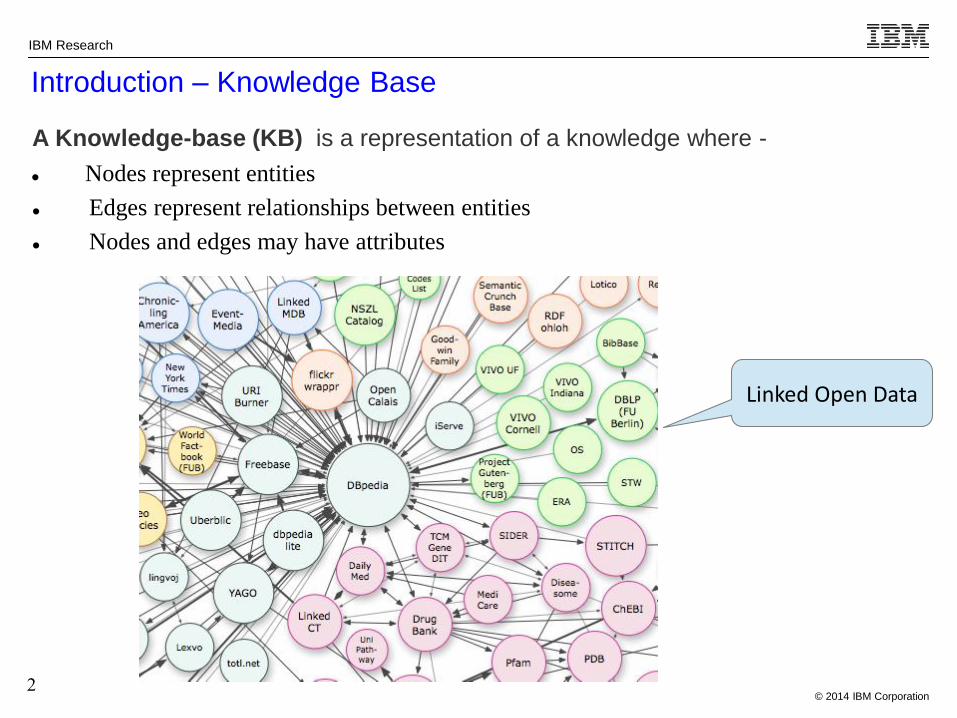
Introduction – Knowledge Base
A Knowledge-base (KB) is a representation of a knowledge where -
Nodes represent entities
Edges represent relationships between entities
Nodes and edges may have attributes
Linked Open Data
© 2014 IBM Corporation
IBM Research
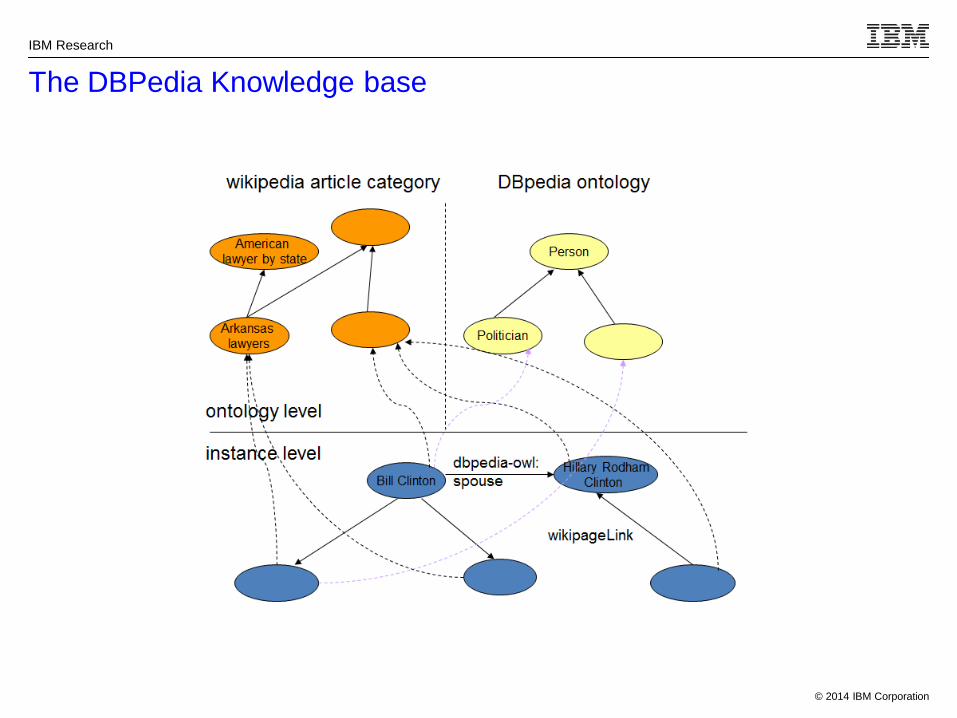
The DBPedia Knowledge base

© 2014 IBM Corporation
IBM Research
4
Usage of Knowledge Bases
1. Semantic understanding of a text by mapping phrases to the knowledge base.
2. Helps to find relatedness/similarity between two given texts
In the United Kingdom and Ireland, high school students traditionally do not have 'free
periods' but do have 'break' which normally occurs just after their second lesson of the
day (normally referred to as second period).
Mentions
United Kingdom - http://en.wikipedia.org/wiki/United_Kingdom
Ireland - http://en.wikipedia.org/wiki/Ireland
high school students - http://en.wikipedia.org/wiki/High_school - note the derivation to "high school
student" and then the re-direct to "High school".
‘free periods’ - http://en.wikipedia.org/wiki/Period_(school) - note the disambiguation.
‘break’ - http://en.wikipedia.org/wiki/Break_(work) - note the disambiguation.
lesson - http://en.wikipedia.org/wiki/Lesson
day - http://en.wikipedia.org/wiki/Day
– period - http://en.wikipedia.org/wiki/Period_(school) - note the disambiguation.
© 2014 IBM Corporation
IBM Research
5
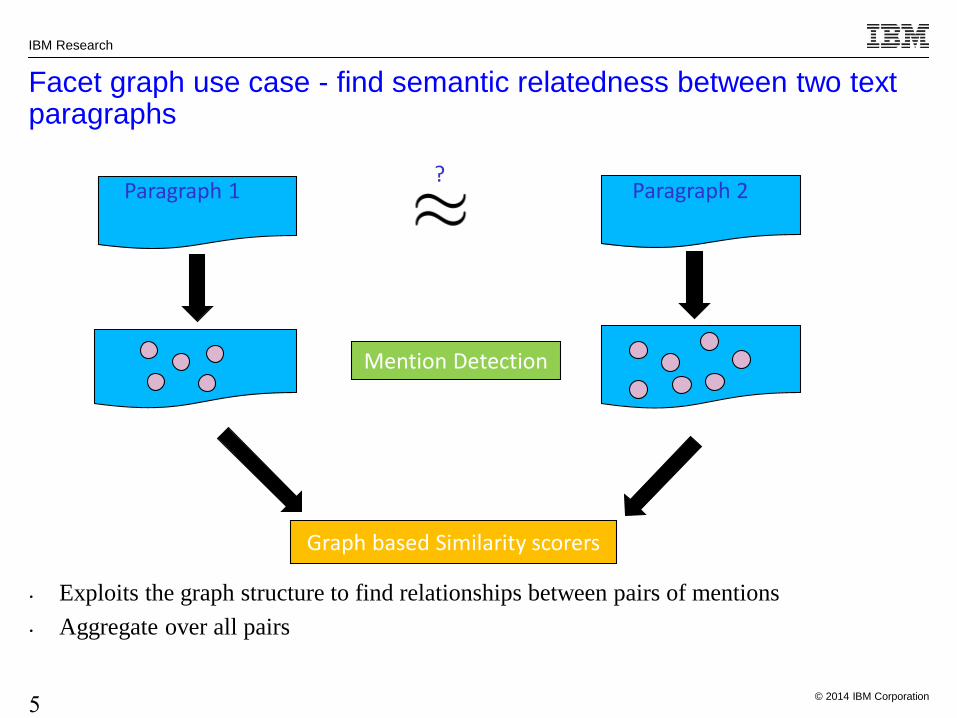
Mention Detection
Graph based Similarity scorers
• Exploits the graph structure to find relationships between pairs of mentions
• Aggregate over all pairs
Facet graph use case - find semantic relatedness between two text paragraphs
Paragraph 1 Paragraph 2 ?

© 2014 IBM Corporation
IBM Research
Outline
• Generation of the Facet Graph from DBPedia
• Mention Detection
• Similarity measures on the FacetGraph

© 2014 IBM Corporation
IBM Research
Outline
• Generation of the Facet Graph from DBPedia
• Mention Detection
• Similarity measures on the FacetGraph
© 2014 IBM Corporation
IBM Research
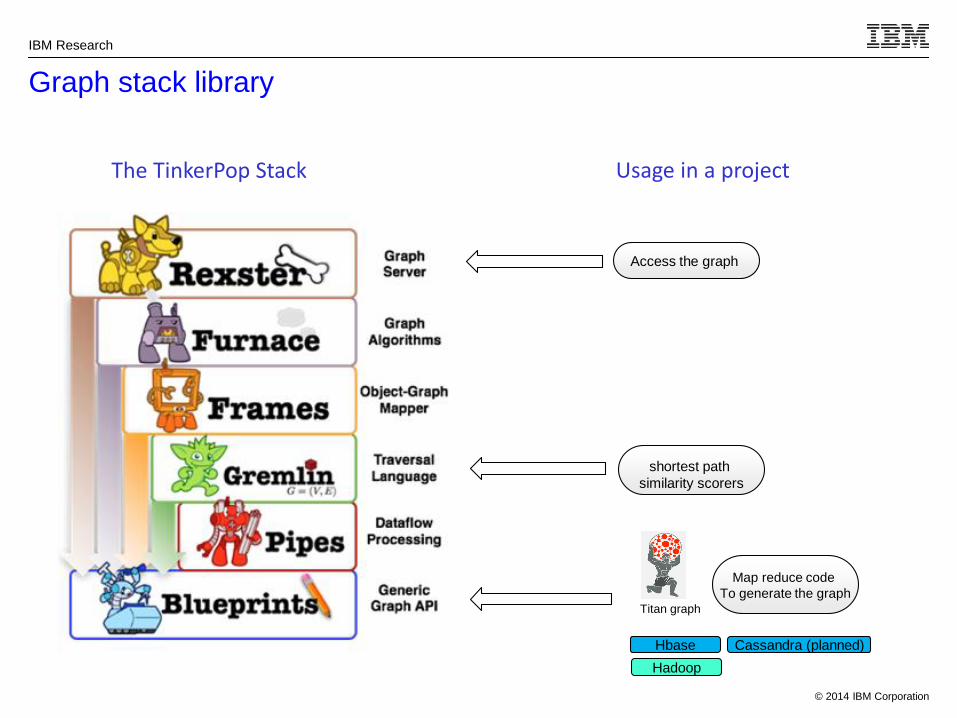
Titan graph
Hbase
shortest path
similarity scorers
The TinkerPop Stack Usage in a project
Cassandra (planned)
Hadoop
Access the graph
Map reduce code
To generate the graph
Graph stack library
© 2014 IBM Corporation
IBM Research
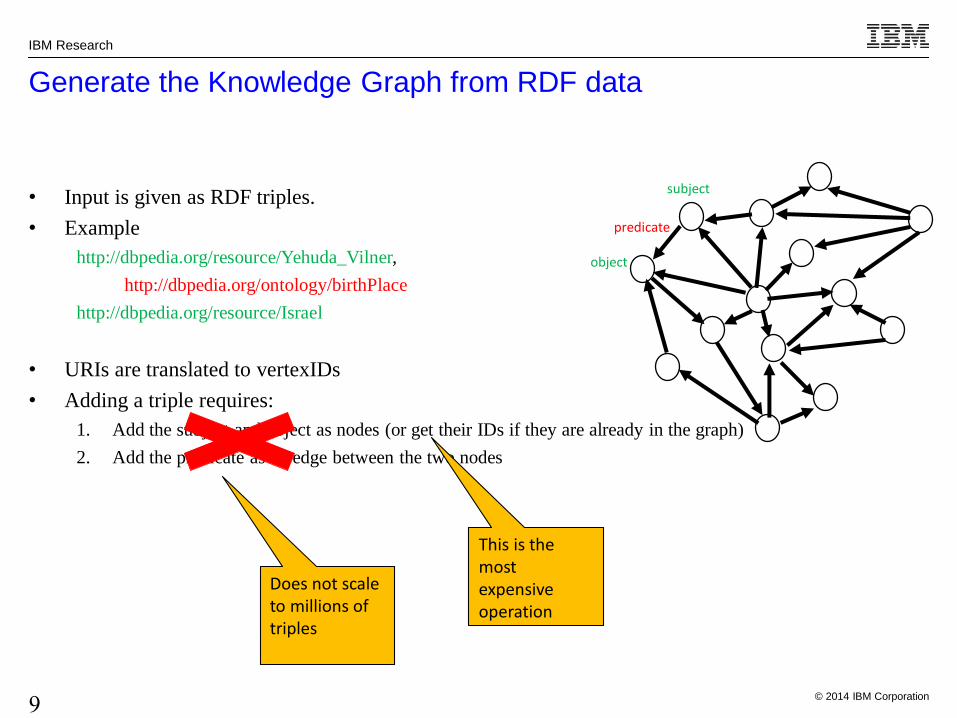
• Input is given as RDF triples.
• Example
http://dbpedia.org/resource/Yehuda_Vilner,
http://dbpedia.org/ontology/birthPlace
http://dbpedia.org/resource/Israel
• URIs are translated to vertexIDs
• Adding a triple requires:
1. Add the subject and object as nodes (or get their IDs if they are already in the graph)
2. Add the predicate as an edge between the two nodes
This is the most expensive operation
9
Generate the Knowledge Graph from RDF data
subject
object
predicate
Does not scale to millions of triples

© 2014 IBM Corporation
IBM Research
A scalable solution using MapReduce
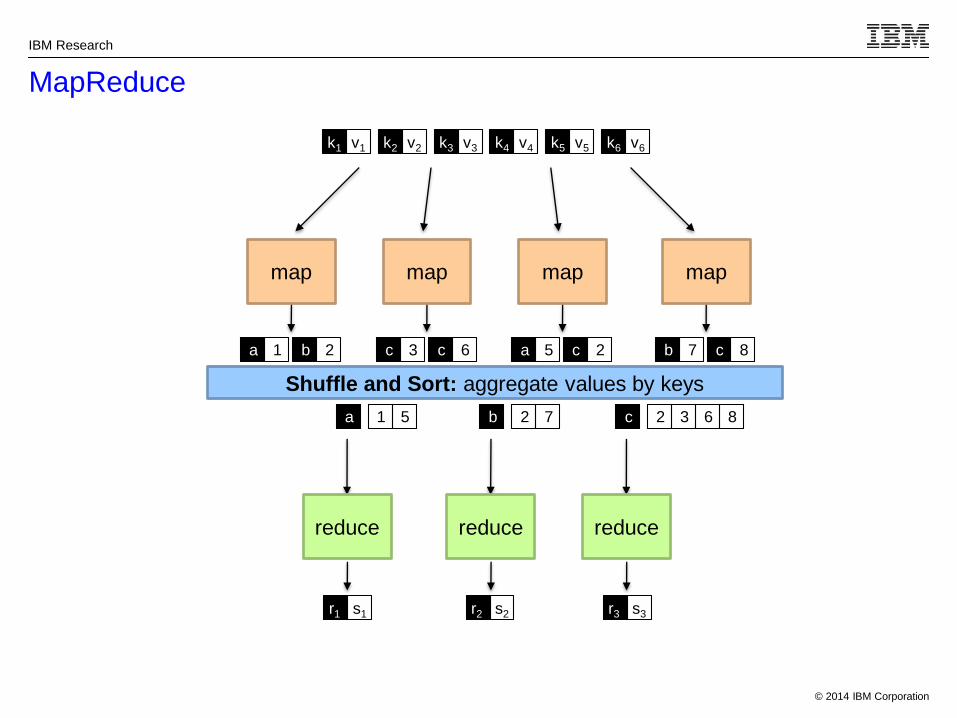
• What is MapReduce?
• Programming model for expressing distributed computations at a massive scale
• Execution framework for organizing and performing such computations
• Open-source implementation called Hadoop
• Programmers specify two functions:
map (k, v) → <k’, v’>*
reduce (k’, v’*) → <k’’, v’’>*
All values with the same key are sent to the same reducer
The execution framework handles everything else…
© 2014 IBM Corporation
IBM Research
mapmap map map
Shuffle and Sort: aggregate values by keys
reduce reduce reduce
k1 k2 k3 k4 k5 k6v1 v2 v3 v4 v5 v6
ba 1 2 c c3 6 a c5 2 b c7 8
a 1 5 b 2 7 c 2 3 6 8
r1 s1 r2 s2 r3 s3
MapReduce
© 2014 IBM Corporation
IBM Research
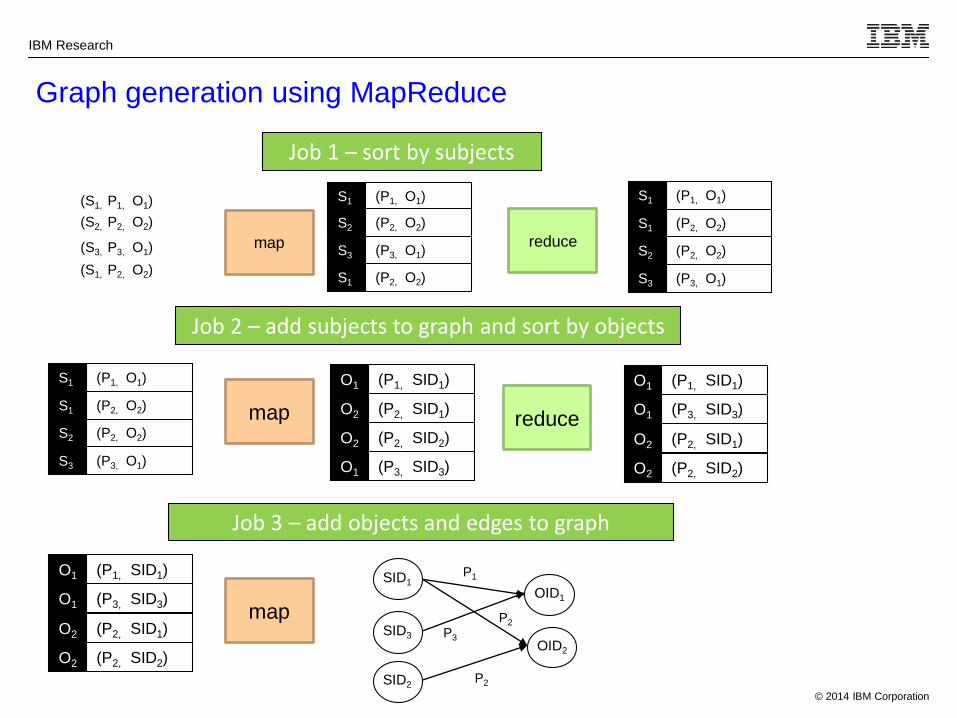
Graph generation using MapReduce
Job 1 – sort by subjects
(S1, P1, O1)
(S2, P2, O2)
(S3, P3, O1)
(S1, P2, O2)
map
S1 (P1, O1)
S2 (P2, O2)
S3 (P3, O1)
S1 (P2, O2)
reduce
Job 2 – add subjects to graph and sort by objects
map
O1 (P1, SID1)
O2 (P2, SID2)
O1 (P3, SID3)
O2 (P2, SID1) reduce
S1 (P1, O1)
S2 (P2, O2)
S3 (P3, O1)
S1 (P2, O2)
O1 (P1, SID1)
O2 (P2, SID1)
O1 (P3, SID3)
O2 (P2, SID2)
Job 3 – add objects and edges to graph
S1 (P1, O1)
S2 (P2, O2)
S3 (P3, O1)
S1 (P2, O2)
O1 (P1, SID1)
O2 (P2, SID1)
O1 (P3, SID3)
O2 (P2, SID2)
map
SID1
OID1
P1
OID2
P2SID3 P3
SID2P2
© 2014 IBM Corporation
IBM Research
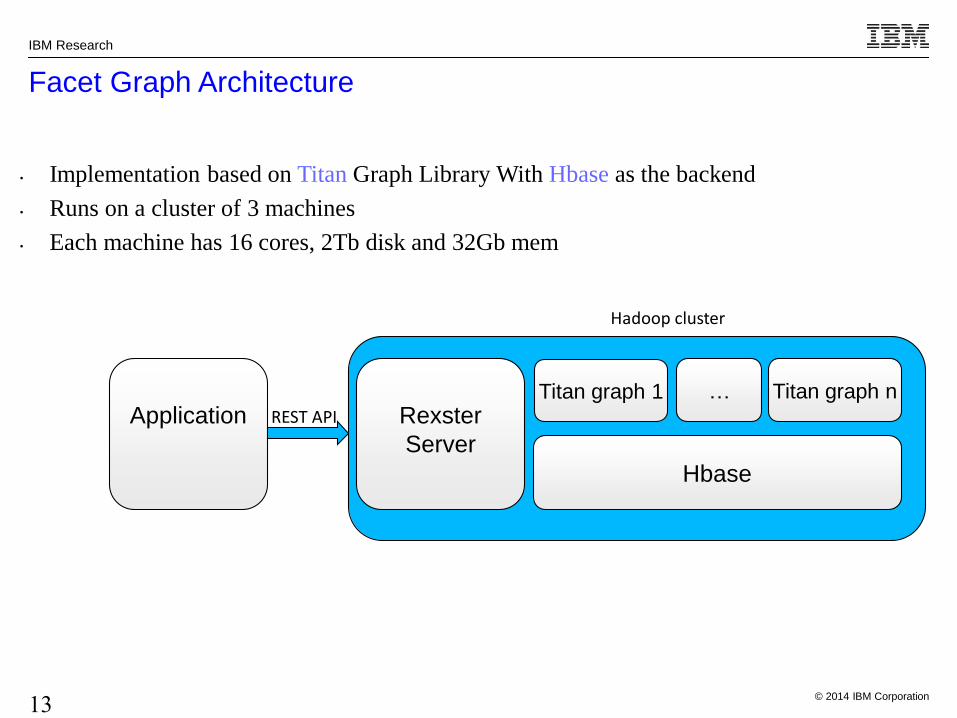
• Implementation based on Titan Graph Library With Hbase as the backend
• Runs on a cluster of 3 machines
• Each machine has 16 cores, 2Tb disk and 32Gb mem
13
Facet Graph Architecture
Rexster
Server
Titan graph 1
Hbase
Application REST API
Hadoop cluster
Titan graph n…
© 2014 IBM Corporation
IBM Research
14
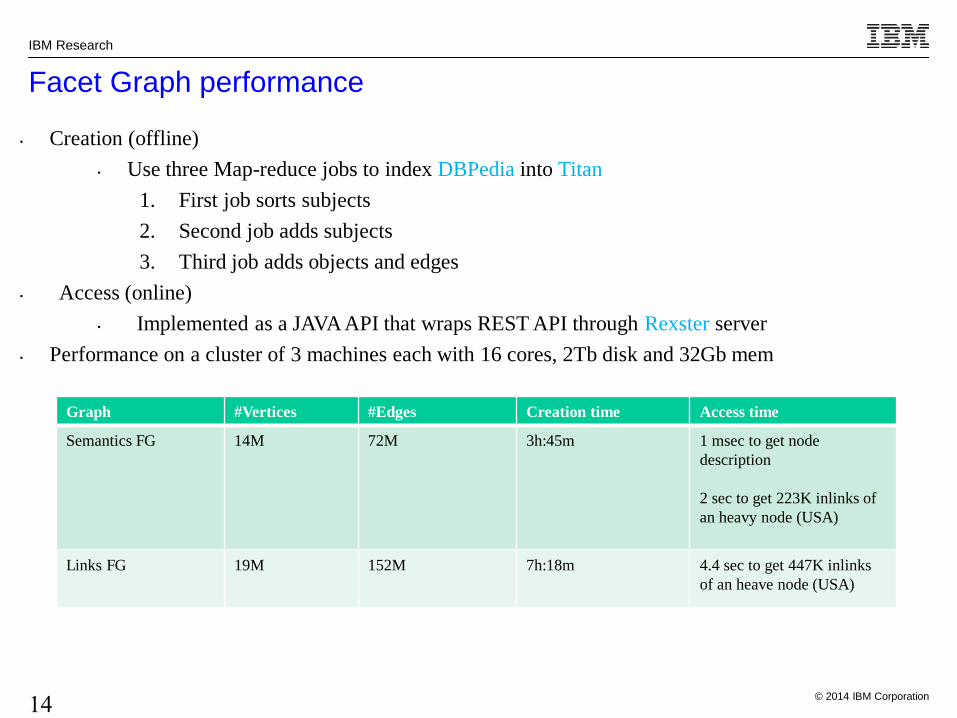
Facet Graph performance
• Creation (offline)
• Use three Map-reduce jobs to index DBPedia into Titan
1. First job sorts subjects
2. Second job adds subjects
3. Third job adds objects and edges
• Access (online)
• Implemented as a JAVA API that wraps REST API through Rexster server
• Performance on a cluster of 3 machines each with 16 cores, 2Tb disk and 32Gb mem
Graph #Vertices #Edges Creation time Access time
Semantics FG 14M 72M 3h:45m 1 msec to get node
description
2 sec to get 223K inlinks of
an heavy node (USA)
Links FG 19M 152M 7h:18m 4.4 sec to get 447K inlinks
of an heave node (USA)

© 2014 IBM Corporation
IBM Research
Outline
• Generation of the Facet Graph from DBPedia
• Mention Detection
• Similarity measures on the FacetGraph
© 2014 IBM Corporation
IBM Research
16
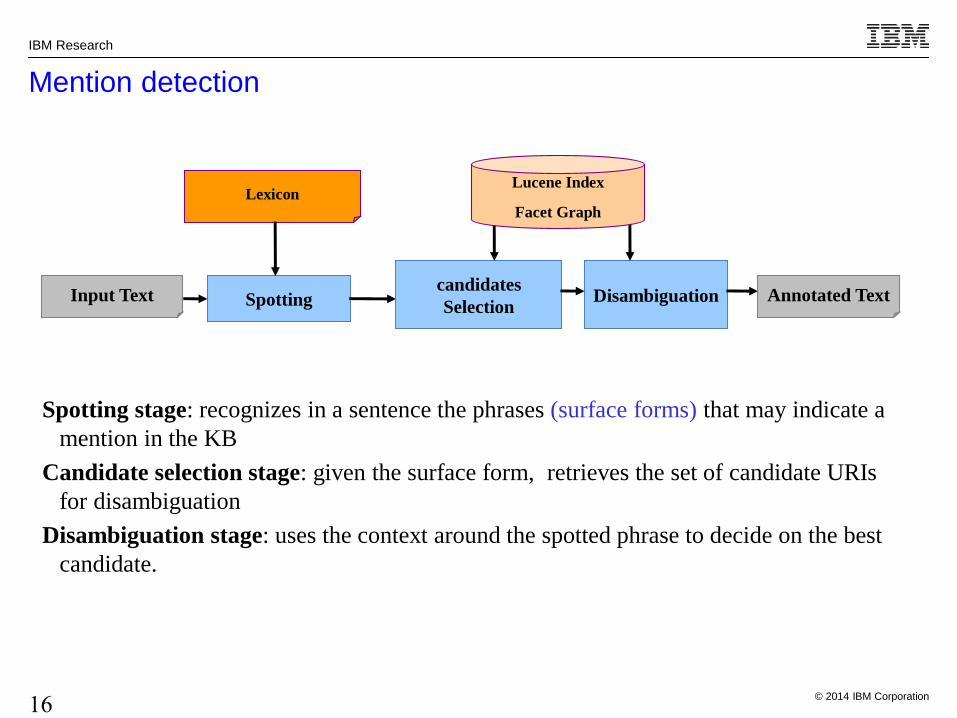
Mention detection
Input Text
Lexicon
Spotting candidates
SelectionDisambiguation
Lucene Index
Facet Graph
Spotting stage: recognizes in a sentence the phrases (surface forms) that may indicate a
mention in the KB
Candidate selection stage: given the surface form, retrieves the set of candidate URIs
for disambiguation
Disambiguation stage: uses the context around the spotted phrase to decide on the best
candidate.
Annotated Text

© 2014 IBM Corporation
IBM Research
Outline
• Generation of the Facet Graph from DBPedia
• Mention Detection
• Similarity measures on the FacetGraph
© 2014 IBM Corporation
IBM Research
18
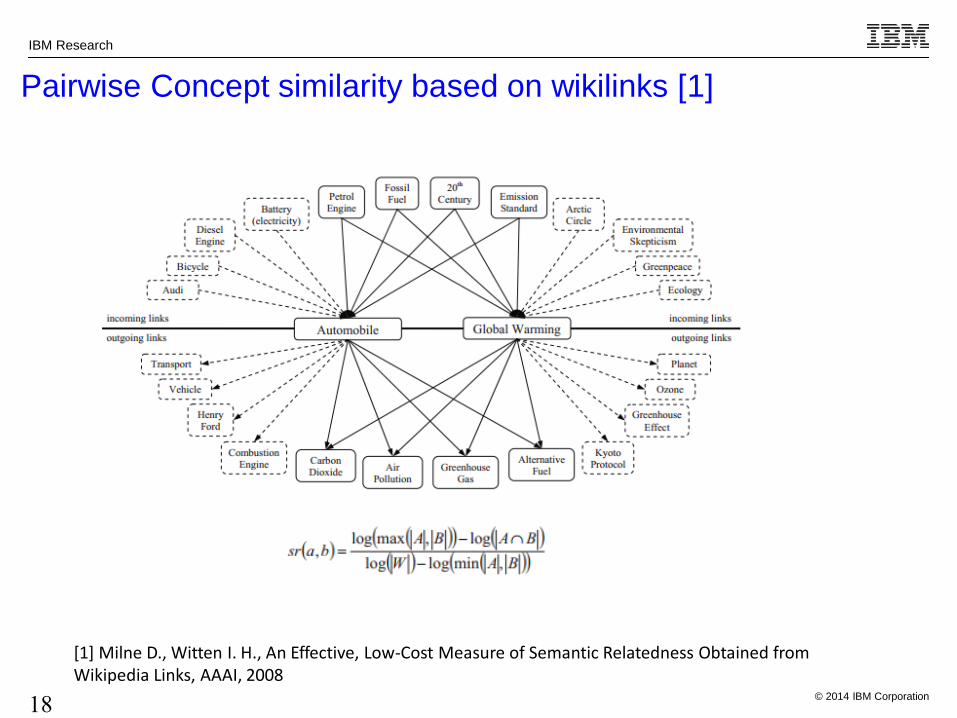
Pairwise Concept similarity based on wikilinks [1]
[1] Milne D., Witten I. H., An Effective, Low-Cost Measure of Semantic Relatedness Obtained from Wikipedia Links, AAAI, 2008
© 2014 IBM Corporation
IBM Research
Our assets on IBM.next
IBM Confidential14/9/8
http://ibmnext.stage1.mybluemix.net/assets

© 2014 IBM Corporation
IBM Research
Thank You