keyword spotting in multi-player voice driven games for ... · keyword spotting in multi-player...
TRANSCRIPT

Keyword spotting in multi-player voice driven games for children
Harshavardhan Sundar2, Jill Fain Lehman1, Rita Singh1
1Disney Research Labs, Pittsburgh, PA, USA.2Language Technologies Institute, Carnegie Mellon University, Pittsburgh, PA, USA.
[email protected], [email protected], [email protected]
AbstractWord spotting, or keyword identification, is a highly challeng-ing task when there are multiple speakers speaking simultane-ously. In the case of a game being controlled by children solelythrough voice, the task becomes extremely difficult. Children,unlike adults, typically do not await their turn to speak in an or-derly fashion. They interrupt and shout at arbitrary times, speakor say things that are not within the purview of the game vocab-ulary, arbitrarily stretch, contract, distort or rapid-repeat words,and do not stay in one location either horizontally or vertically.Consequently, standard state-of-art keyword spotting systemsthat work admirably for adults in multiple keyword settings, failto perform well even in a basic two-word vocabulary keywordspotting task in the case of children. This paper highlights theissues with keyword spotting using a simple two-word gameplayed by children of different age groups, and gives quantita-tive performance assessments using a novel keyword spottingtechnique that is especially suited to such scenarios.
Index Terms: Word spotting, Keyword identification, Chil-dren’s speech, Children’s games, Distant speech recognition,Voice driven games.
1. IntroductionKeyword spotting in continuous speech involves detectingwhether and where in a recording a specified word occurs. Cur-rently, depending on the task setting, there are four categoriesof approaches that are mainstream for keyword spotting. Themost basic approach is to simply set the key-terms in oppositionto a generic garbage model and apply a likelihood ratio test toidentify the keywords [1, 2]. The second comprises performingphoneme (or syllable, or other sub-word unit) recognition. Key-word spotting is then done by searching for specific sequencesof phonemes in a recording and coalescing them into words[3]. The third category comprises performing large-vocabularyrecognition with a language model, and searching for the de-sired key-terms in the ASR system lattices [4].
In the fourth set of techniques, spoken examples of thekeywords are used to build specific word detectors. We re-fer to these as example-based methods. Example-based meth-ods model each keyword to be spotted in its entirety. Whilephoneme-based methods are flexible, example-based methodsare generally more accurate or faster, e.g. [5, 6, 7]. Manyexample-based methods basically mimic the phoneme-basedmethods in that they attempt to first derive a phoneme sequenceor lattice, which is re-evaluated with the phonetic models in anASR system to generate word identities [8]. Such example-based techniques also include those based on neural networks.Lately, bidirectional neural networks [9], especially bidirec-tional long-short-term memory (BLSTM) neural networks have
been employed with particular success for word spotting tasks[10]. Word spotting with BLSTMs has focused on text- orphoneme-sequence-based word specification: the word spottereither scans the phoneme lattice generated with the BLSTMsfor the specified words [11, 12], or uses a second-level discrim-inative classifier that employs features derived from the latticeto detect the words [13].
In this paper we address the problem of keyword spottingin the setting of a multiplayer children’s game. This setting ischallenging for multiple reasons. First, there is a much largerinherent variability in the quality of children’s voices than foradults. This is related to physiological issues [14]. In chil-dren, the length of the vocal cord, and the shape of the vocaltract changes more rapidly with age than in adults. As a result,marked changes in voice characteristics are seen with smallerage differentials in children [15], and a system cannot be triv-ially set up to work optimally for all age groups with one set-ting. In addition, through childhood, the length of the vocalcords is not at the optimal adult length needed to discrimina-tively pronounce each sound in the language. Children thereforeenunciate sounds in a much more varied fashion than adults do[16]. In fact, children’s speech becomes clearer with increasingage, although the pitch is higher on average in child speech, andthere is more energy in higher frequencies as compared to adultspeech. For all these reasons, training keyword detectors forchildren’s voices is expected to be an inherently difficult task.
The second reason is related to stylistic issues that cor-relate with developmental and emotional factors [17, 18, 19].Children also generally do not adhere to turn-taking rules, andeven within a restricted vocabulary game, they often speakconcurrently. In the keyword-spotting scenario, multiple key-words could be spoken by multiple children at the same time.Thus any effective keyword-spotting algorithm used for a mul-tiplayer scenario must also necessarily address the case wherekeywords are simultaneously uttered by multiple players. Thestylistic issues are exemplified clearly in the context of a gamecalled “Mole Madness” in this paper. Mole Madness is a two-dimensional side-scroller game, similar to video games like Su-per Mario Bros R©. The goal of the game is to move a molecharacter through its environment, capturing food and avoid-ing dangers (see Figure 1). Two children work cooperatively tomove the mole, one child effecting horizontal movement withthe word GO, and the other controlling vertical movement withJUMP. Without speech, the mole simply falls to the ground andspins in place.
On the surface, the game presents a simple two-keywordspotting task that should be easy to address with any of theexisting techniques mentioned above that are known to workwell for adult voices. However, stylistic issues with children’svoices, especially when trying to stress function word sounds[20], seriously confound the solutions. In addition to the ex-

Figure 1: A screen shot of Mole Madness. The mole (blue)must GO and JUMP to scale the wall and avoid the cactii.
pected physiologically-variable pronunciations of participants(ages 4 to 10), the following phenomena occur throughout:
1. Extreme variability in duration: On one hand, we findthe word “go” so contracted that multiple repetitions areincluded in one rapid-fire instance, e.g. GOGGOGGO.Note the skipped syllable. On the other hand, wealso find the word extremely prolonged in duration, e.gGOOOOOOOOOOOOOOO. Figure 2 presents some ex-amples.
2. Keyword merging: Under time pressure and in an ex-cited state, children will subsume each other’s roles,producing garbled, merged forms of the keywords e.g.GJMP, JUMPGOOJJJJJUMP, etc.
3. Speech-on-speech: Areas of the game environment aredesigned to make the children work together to acquirea reward or overcome an obstacle, creating instances ofmoderate to near-perfect overlap in speech. In such casesthe system must be able to detect that both words werespoken. This is the main motivation for presenting thealgorithm in this paper.
4. Voice tremors and acoustic distortion: Jumping verti-cally and horizontally while screaming causes acousticdistortions in voice, more in adults but even in children.
5. Out-of-vocabulary words: Despite the desire to move themole quickly and achieve a high score, children will,nevertheless, participate in social and strategic side-talk[21], e.g. SAY GO, I SAID JUMP, NICE MOVE, etc.This introduces out-of-vocabulary words that are notmerely resultant from mergings or contractions.
In the following sections we present an algorithm for key-word spotting that is best suited for multi-person game scenar-ios when overlaps are expected between spoken instances ofkeywords. We compare the algorithm to state-of-art BLSTMsmodified for keyword spotting in a multi-person scenario, andevaluate its performance in different environmental noise con-ditions. Experiments show that the algorithm outperformsconventional techniques in scenarios where the keywords arephonemically and durationally altered or distorted, and espe-cially when the keywords are overlapped.
GO: short GO: extended
JUMP: short JUMP: extended
Figure 2: Spectrograms showing durational variability of key-words in Mole Madness.
2. Maximum-likelihood wordspotting withheavy-tailed distributions
Let us consider a task where N keywords {w1, w2, . . . , wN}are to be spotted. The recording environment includes multiplespeakers, any of who may speak the keywords. Speakers mayalso speak concurrently. The task is to determine which of thekeywords were spoken. If multiple keywords are concurrentlyspoken (possibly with partial overlap), all of them must be iden-tified.
We process the incoming speech in overlapping blocks. Thewidth of the blocks and the overlap between adjacent blocks isoptimized empirically. The audio in any block is parameter-ized into a sequence of feature vectors (Mel-frequency cepstralvectors in our case), each representing one frame of the block.We represent the sequence of feature vectors derived from anyaudio block as F and the individual feature vectors in it by f .
Recalling that keywords may be spoken concurrently, oneor more of the keywords may occcur within each block. Weview every combination of keywords as a separate class ofevents. Since there are N keywords, there are 2N classes,representing the 2N possible combinations of keywords. Fornotational convenience, we can represent the combination ofkeywords in any block through an N -bit indicator Z =z1z2 · · · zN , where each zi is a single bit indicating the occur-rence or absence of the ith keyword. Z can take 2N possiblevalues, each indicating one of the 2N possible combinations ofkeywords, and indexes the classes.
The features F derived from the audio for each combinationof keywords Z can be expected to have their own distinctivestatistical signature. In practice, however, there is potentiallyinfinite variation in the asynchrony between the utterance of theindividual words in the combination, resulting in a large vari-ation in the temporal patterns in F . To effectively capture the
Figure 3: Generative model for F
asynchrony, we assume the generative model shown in Figure3 for F . The model assumes every vector f in F to be statis-tically independent of every other vector. In order to generateany vector f , first the class Z is drawn from a prior distribu-tion P (Z); subsequently the vector f is drawn from the class-conditional distribution P (f |Z). In effect, the model assumesthat every vector in F may have been drawn from a differentclass. The model implicitly accounts for the fact that when mul-tiple keywords are spoken concurrently, different combinationsof these keywords may be active in any individual frame dueto the asynchrony between the keywords. This results in thefollowing probability distribution for F
P (F ) =∏f∈F
∑Z
P (Z)P (f |Z)
Note that in this model P (Z) effectively represents the expectedfraction of feature vectors in F that were obtained from thecombination Z. If the class-specific distributions P (f |Z) areknown, the task of identifying the set of keywords active in anyblock thus reduces to identifying the set of Zs that are mostdominant in the block, i.e., the Zs corresponding to the largestP (Z) values.
This leads to the following algorithm for identifying key-words.

• In a training phase, we learn a model P (f |Z) for the distri-bution of feature vectors recorded under every combination Zof keywords from appropriate collections of training data.
• In the test phase, for every block B of test-data audio repre-sented by the features FB , we estimate the probability distri-bution P (FB) =
∑Z PB(Z)P (f |Z), where we have used
the subscript B in PB(Z) to denote that the distribution isspecific to block B. Since P (f |Z) is already known (fromthe training phase), only PB(Z) must be estimated. We usea simple EM algorithm to obtain a maximum-likelihood es-timate of PB(Z). Subsequently, we compute the probabilitythat the ith keyword was spoken as the sum of the PB(Z)values for all Zs in which the keyword was included.
PB(i) =∑
Z:zi=1
PB(Z) (1)
PB(i) estimates the fraction of frames in FB in which the ith
keyword was active. The keywords with the largest PB(i)values are returned as candidates for the block.
The procedure above places no explicit constraint on theactual combination-specific distributions P (f |Z). Although, inprinciple, conventional distributions such as Gaussian mixturemodels may be employed, in mixed-speech scenarios, we havefound that the features are most effectively modeled by heavy-tailed distributions [22]. In this work we have found it mosteffective to model P (f |Z) as a mixture of Student’s-t distribu-tions. The parameters of these distributions can be learned fromtraining examples, as given in [22]. Distributions for Z valuesrepresenting multiple concurrent keywords may be learned fromsynthetic mixtures of the keywords. We refer to the mixture-Student’s-t based models as M-TMMs. As a comparator wehave also modeled P (f |Z) by GMMs. We refer to this modelas M-GMM.
For large values of N , the total number 2N of keywordcombinations can become very large. In these situations, wehave found it effective to assume that no more than one (or asmall number K) of the keywords is spoken at any time, i.e.,assume that individual frames are dominated either by a singlekeyword, or no keyword at all. For the results reported in thispaper, however, N = 2, and the entire set of 2N possible com-binations are considered.
3. The BLSTM comparatorAs a comparator to our proposed method, we evaluated bidi-rectional long-short-term memory networks (BLSTMs) for theword-spotting task. These have been known to work well forchildren’s speech [23]. BLSTMs capture both causal and anti-causal recurrence, through a network that has both a forwardand a backward component; classification is performed usinginformation from both the networks. A BLSTM network is abidirectional recurrent neural network with LSTM cells in itshidden layers. An LSTM neuron or cell is a unit comprisinga central memory unit and gates that determine when it mustconsider an input, when it must remember a value, and whenit should output its value [24]. BLSTMs have been shown tobe highly effective at a variety of speech recognition tasks, in-cluding word spotting, and are considered state-of-art in manyof these tasks [25].
In our setup, we employed a BLSTM network to directlyclassify each block of incoming speech into one of 2N classes,corresponding to the 2N possible combinations of keywords.The network is trained with several instances from each of these
Figure 4: A schematic of the BLSTM network architecture.Forward blocks of LSTM neurons are colored yellow and back-ward ones are colored blue. The number of memory neuronsused is indicated within each block.
2N conditions. The output layer has 2N soft-max neurons, theoutputs of which may be interpreted as P (Z|F ), where Z isdefined as in Section 2. In the test phase, each block of incom-ing data is processed by the BLSTM network. The outputs arecombined according to Equation 1 to compute probabilities forthe individual words.
The configuration of the network used in our experimentswas identical to the one used for word recognition in the 20132nd ChiME Challenge track-1 [26]: the network had three hid-den layers (indicated as Layers 1, 2 and 3 in Fig. 4) containing156, 300 and 102 neurons, respectively. The full architecture isshown in Fig. 4. We used CURRENNT [27], a publicly avail-able CUDA-based implementation. A learning rate of 10−5
and a momentum of 0.9 is used in a stochastic gradient descentmethod for optimizing the network parameters during training.
4. Experimental resultsWe evaluated three algorithms: both the M-TMM and M-GMMvariants of the proposed algorithm and BLSTMs, on Mole Mad-ness data collected in-house at Disney Research. The data com-prise recordings from 34 distinct pairs of children between theages of 4 and 10 years (mean age 7 years, standard deviation= 2.01 years, male-female ratio of 3:2). Each pair of childrenplayed twice, once as GO and once as JUMP. For data collec-tion, the application did not use a speech recognizer to respondto the children’s voices. Instead, the players controlled the molethrough “Wiimotes” [28], while simultaneously uttering the re-quired keywords. Each child wore a close-talking microphoneon his or her shoulder, with data recorded at a sampling rate of16 kHz.
The Mole Madness database contains 1723 isolated utter-ances of GO and 1214 utterances of JUMP. Tracks from eachchild were independently annotated. Overlaps can thus be de-termined by matching time-stamps between the tracks. Datasegments which did not contain these keywords are annotatedas “Background”. For our experiments, we used 1200 non-overlapping GO, 800 instances of non-overlapping JUMP and254 segments of Background.
The test set for evaluating performance on non-overlappedspeech comprised 523 instances of GO, 414 instances of JUMPand 230 instances of Background. The sets of children fromwhich the training and testing data are chosen were mutually ex-clusive. The test set for evaluating performance on overlappedspeech comprised 523 instances of concurrent instances of GOand JUMP being spoken together. These latter count as pos-itives for both GO and JUMP. To test the performance under
0.1 0.2 0.5 1 2 5 10 20 40
0.1
0.2
0.5
1
2
5
10
20
40
False Alarms (%) 0.1 0.2 0.5 1 2 5 10 20 40
False Alarms (%)
0.1
0.2
0.5
1
2
5
10
20
40
Mis
se
d D
ete
ctio
n (
%)
BLSTM, Go
TMM, Go
GMM, Go
BLSTM, Jump
TMM, Jump
GMM,Jump
BLSTM, Go
M−TMM, Go
M−GMM, Go
BLSTM, Jump
M−TMM, Jump
M−GMM,Jump
(a) (b)
Figure 5: (a): Performance obtained within a hypothesis-testing framework. (b) DET Curves for M-TMM, M-GMM andBLSTMs under the proposed framework.
different SNR conditions, we synthetically added babble noise(recorded in a gaming parlor) to the test set.
In all experiments, the features used were 39-dimensionalMel-Frequency Cepstra (including delta and acceleration coef-ficients). Performance was evaluated by generating DetectionError Threshold (DET) curves for each. The DET curve plotsmissed-detection (MD) vs. false-alarm (FA). We also computedthe detection cost function (DCF) as a scalar quantitative metricof performance. The DCF is a weighted combination of false-alarm and missed-detection. Because the cost of FA is higherthan MD in Mole Madness, we set the DCF to be the weightedcombination: 0.3∗P (MD)+0.7∗P (FA), where P () denotesprobability.
We note that keyword spotting may also be viewed as a con-ventional hypothesis-testing problem. To establish the baselinefor this task, we first performed spotting within a hypothesis-testing framework. Two models were trained for each word:one for the word itself, and the other for the negative class usingall data that did not include the word. For the spotting task, a loglikelihood score was obtained using both models. Both TMMsand GMMs were used for this purpose. TMMs and GMMsused mixtures of 64 component distributions. Since TMMs andGMMs do not incorporate temporal structure, we also trained athird spotter using BLSTMs. Here, for each word we trained aBLSTM to distinguish between the word and the absence of theword. Figure 5a shows the DET curves for all three spotters, forboth words in our test set. We note that there is no significantdifference in performance between the three. In particular, thetemporal structure captured by the BLSTM brings no signifi-cant benefit, showing clearly that even the BLSTM is unable tocapture the large variations in temporal structure in children’sspeech under game conditions.
Figure 5b shows the performance obtained using our pro-posed method on clean test instances of both words. We showthe performance with M-TMMs, M-GMMs, and BLSTMS im-plemented as described in Section 3. We note directly that ex-plicitly modeling the condition where words overlap improvesthe performance of BLSTMs. However the best performance isobtained using M-TMMs. The combination of the proposedmaximum-likelihood framework and the use of mixtures ofStudent’s-t distributions to model the words results in the bestperformance.
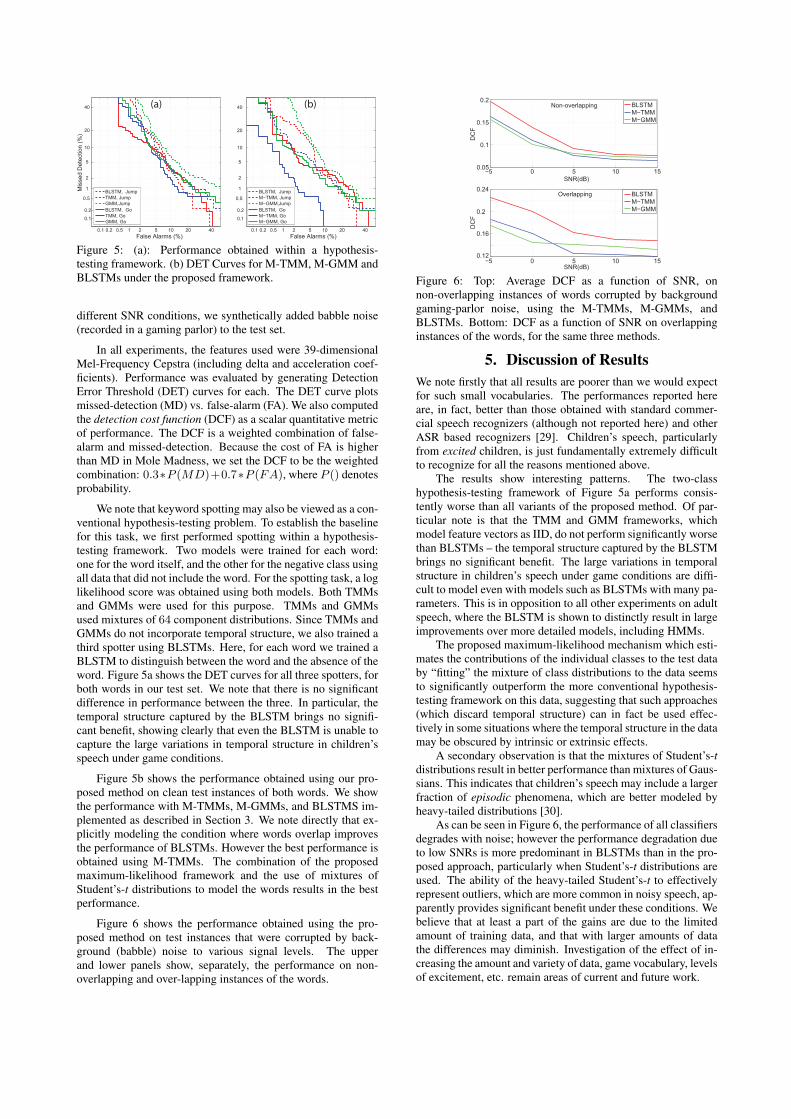
Figure 6 shows the performance obtained using the pro-posed method on test instances that were corrupted by back-ground (babble) noise to various signal levels. The upperand lower panels show, separately, the performance on non-overlapping and over-lapping instances of the words.
−5 0 5 10 150.12
0.16
0.2
0.24
−5 0 5 10 150.05
0.1
0.15
0.2BLSTM
M−TMM
M−GMM
SNR(dB)
SNR(dB)
DCF
Non-overlapping
Overlapping
DCF
BLSTM
M−TMM
M−GMM
Figure 6: Top: Average DCF as a function of SNR, onnon-overlapping instances of words corrupted by backgroundgaming-parlor noise, using the M-TMMs, M-GMMs, andBLSTMs. Bottom: DCF as a function of SNR on overlappinginstances of the words, for the same three methods.
5. Discussion of ResultsWe note firstly that all results are poorer than we would expectfor such small vocabularies. The performances reported hereare, in fact, better than those obtained with standard commer-cial speech recognizers (although not reported here) and otherASR based recognizers [29]. Children’s speech, particularlyfrom excited children, is just fundamentally extremely difficultto recognize for all the reasons mentioned above.
The results show interesting patterns. The two-classhypothesis-testing framework of Figure 5a performs consis-tently worse than all variants of the proposed method. Of par-ticular note is that the TMM and GMM frameworks, whichmodel feature vectors as IID, do not perform significantly worsethan BLSTMs – the temporal structure captured by the BLSTMbrings no significant benefit. The large variations in temporalstructure in children’s speech under game conditions are diffi-cult to model even with models such as BLSTMs with many pa-rameters. This is in opposition to all other experiments on adultspeech, where the BLSTM is shown to distinctly result in largeimprovements over more detailed models, including HMMs.
The proposed maximum-likelihood mechanism which esti-mates the contributions of the individual classes to the test databy “fitting” the mixture of class distributions to the data seemsto significantly outperform the more conventional hypothesis-testing framework on this data, suggesting that such approaches(which discard temporal structure) can in fact be used effec-tively in some situations where the temporal structure in the datamay be obscured by intrinsic or extrinsic effects.
A secondary observation is that the mixtures of Student’s-tdistributions result in better performance than mixtures of Gaus-sians. This indicates that children’s speech may include a largerfraction of episodic phenomena, which are better modeled byheavy-tailed distributions [30].
As can be seen in Figure 6, the performance of all classifiersdegrades with noise; however the performance degradation dueto low SNRs is more predominant in BLSTMs than in the pro-posed approach, particularly when Student’s-t distributions areused. The ability of the heavy-tailed Student’s-t to effectivelyrepresent outliers, which are more common in noisy speech, ap-parently provides significant benefit under these conditions. Webelieve that at least a part of the gains are due to the limitedamount of training data, and that with larger amounts of datathe differences may diminish. Investigation of the effect of in-creasing the amount and variety of data, game vocabulary, levelsof excitement, etc. remain areas of current and future work.

6. References[1] Mitchel Weintraub. LVCSR log-likelihood ratio scoring
for keyword spotting. In International Conference onAcoustics, Speech, and Signal Processing (ICASSP-95),volume 1, pages 297–300. IEEE, 1995.
[2] Igor Szoke, Petr Schwarz, Pavel Matejka, Lukas Burget,Martin Karafiat, Michal Fapso, and Jan Cernocky. Com-parison of keyword spotting approaches for informal con-tinuous speech. In Interspeech, pages 633–636, 2005.
[3] Richard C Rose and Douglas B Paul. A hidden markovmodel based keyword recognition system. In Interna-tional Conference on Acoustics, Speech, and Signal Pro-cessing (ICASSP-90), pages 129–132. IEEE, 1990.
[4] Petr Motlicek, Fabio Valente, and Igor Szoke. Improvingacoustic based keyword spotting using LVCSR lattices. InInternational Conference on Acoustics, Speech and Sig-nal Processing (ICASSP2012), pages 4413–4416. IEEE,2012.
[5] T. Ezzat and T. Poggio. Discriminative word-spottingusing ordered spectro-temporal patch features. In SAPAworkshop (INTERSPEECH), Brisbane, Australia, 2008.
[6] S.Fernandez, A. Graves, and J. Schmidhuber. An appli-cation of recurrent neural networks to discriminative key-word spotting. In Proc. ICANN, page 220229, Porto, Por-tugal, 2007.
[7] A. Jansen and P. Niyogi. Point process models for spot-ting keywords in continuous speech. IEEE Transactionson Audio, Speech, and Language Processing, 17(8):1457–1470, 2009.
[8] T. J. Hazen, W. Shen, and C. White. Query-by-examplespoken term detection using phonetic posteriogram tem-plates. In Proceedings of the IEEE Workshop on Auto-matic Speech Recognition and Understanding, Merano,Italy, December 2009.
[9] M. Schuster and K. K. Paliwal. Bidirectional recurrentneural networks. IEEE Transactions on Signal Process-ing, 45(11):2673–2681, 1997.
[10] F. A. Gers. Long short-term memory in recurrent neuralnetworks. PhD thesis, pages 2673–2681, 2001.
[11] Martin Wollmer, Florian Eyben, Alex Graves, BjornSchuller, and Gerhard Rigoll. Improving keyword spot-ting with a tandem BLSTM-DBN architecture. In Ad-vances in Nonlinear Speech Processing, pages 68–75.Springer, Heidelberg, 2010.
[12] Martin Wollmer, Florian Eyben, Bjorn Schuller, Y. Sun,T. Moosmayr, and N. Nguyen-Thien. Robust in-car spelling recognition - a tandem BLSTM-HMM ap-proach. In Proc. of Interspeech, ISCA, pages 2507–2510,Brighton, UK, 2009.
[13] Y. Sun, T. Bosch, and L. Boves. Hybrid HMM/BLSTM-RNN for robust speech recognition. In Proceedings of the13th International Donference on Text, Speech and Dia-logue, pages 400–407, Springer-Verlag, September 2010.
[14] Annerose Keilmann and Carl-Albert Bader. Developmentof aerodynamic aspects in children’s voice. InternationalJournal of Pediatric Otorhinolaryngology, 31(2):183–190, 1995.
[15] Leslie E Glaze, Diane M Bless, Paul Milenkovic, andRobin D Susser. Acoustic characteristics of children’svoice. Journal of Voice, 2(4):312–319, 1988.
[16] Sungbok Lee, Alexandros Potamianos, and ShrikanthNarayanan. Acoustics of children’s speech: Developmen-tal changes of temporal and spectral parameters. The Jour-nal of the Acoustical Society of America, 105(3):1455–1468, 1999.
[17] Bruce L Smith. Relationships between duration and tem-poral variability in childrens speech. The Journal of theAcoustical Society of America, 91(4):2165–2174, 1992.
[18] Harry Levin, Irene Silverman, and Boyce L Ford. Hesita-tions in children’s speech during explanation and descrip-tion. Journal of Verbal Learning and Verbal Behavior,6(4):560–564, 1967.
[19] Stefan Steidl. Automatic classification of emotion relateduser states in spontaneous children’s speech. Phd thesis,University of Erlangen-Nuremberg, Germany, 2009.
[20] Margaret Kehoe, Carol Stoel-Gammon, and Eugene HBuder. Acoustic correlates of stress in young children’sspeech. Journal of Speech, Language, and Hearing Re-search, 38(2):338–350, 1995.
[21] J. F. Lehman and S. Al Moubayed. Mole madness: Amulti-child, fast-paced, speech-controlled game. In AAAISpring Symposium on Turn-taking and Coordination inHuman-Machine Interaction, 2015.
[22] Harshavardhan Sundar, Thippur V Sreenivas, and WalterKellermann. Identification of active sources in single-channel convolutive mixtures using known source models.IEEE Signal Processing Letters, 20(2):153–156, 2013.
[23] Martin Wollmer, Bjorn Schuller, Anton Batliner, StefanSteidl, and Dino Seppi. Tandem decoding of children’sspeech for keyword detection in a child-robot interactionscenario. ACM Transactions on Speech and LanguageProcessing (TSLP), 7(4):12, 2011.
[24] S. Hochreiter and J. Schmidhuber. Long short-term mem-ory. Neural Computation, 9(8):1735–1780, 1997.
[25] A. Graves. Supervised Sequence Labelling with Recur-rent Neural Networks. Phd thesis, Technische UniversittMunchen, July 2008.
[26] F. Weninger, J. Geiger, M. Wollmer, B. Schuller, andG. Rigoll. The Munich feature enhancement approach tothe 2013 CHiME Challenge using BLSTM recurrent neu-ral networks. In Proc. 2nd CHiME Speech Separation andRecognition Challenge, 2013.
[27] F. Weninger, J. Bergmann, and B. Schuller. IntroducingCURRENNT - the Munich open-source CUDA recurrentneural network toolkit. Journal of Machine Learning Re-search, 2014.
[28] Wikipedia. http://en.wikipedia.org/wiki/Wii_Remote.
[29] P. Baljekar, J. F. Lehman, and R. Singh. Online word-spotting in continuous speech with recurrent neural net-works. In Spoken Language Technology Workshop. IEEE,2014.
[30] Deniz Gencaga. Sequential Bayesian modeling of non-stationary non-Gaussian processes. Phd thesis, BogaziciUniversity, 2007.