kapitel 4: record stores und rdbms in der cloud · 4-2 inhaltsverzeichnis • record stores –...
TRANSCRIPT

4-1
NoSQL-Datenbanken
Kapitel 4: Record Stores und
RDBMS in der Cloud
Dr. Anika Groß
Sommersemester 2017
Universität Leipzig
http://dbs.uni-leipzig.de

4-2
Inhaltsverzeichnis
• Record Stores
– BigTable/Hbase
– Megastore
– Replikation
• Relationale Datenbanken in der Cloud
– H-Store/VoltDB
• Transaktionen in der Cloud

4-3
DB RankingQuelle: http://db-engines.com/en/ranking/
• Wide Column Stores
• alle

4-4
Apache Cassandra
http://de.slideshare.net/DataStax/an-overview-of-apache-cassandra
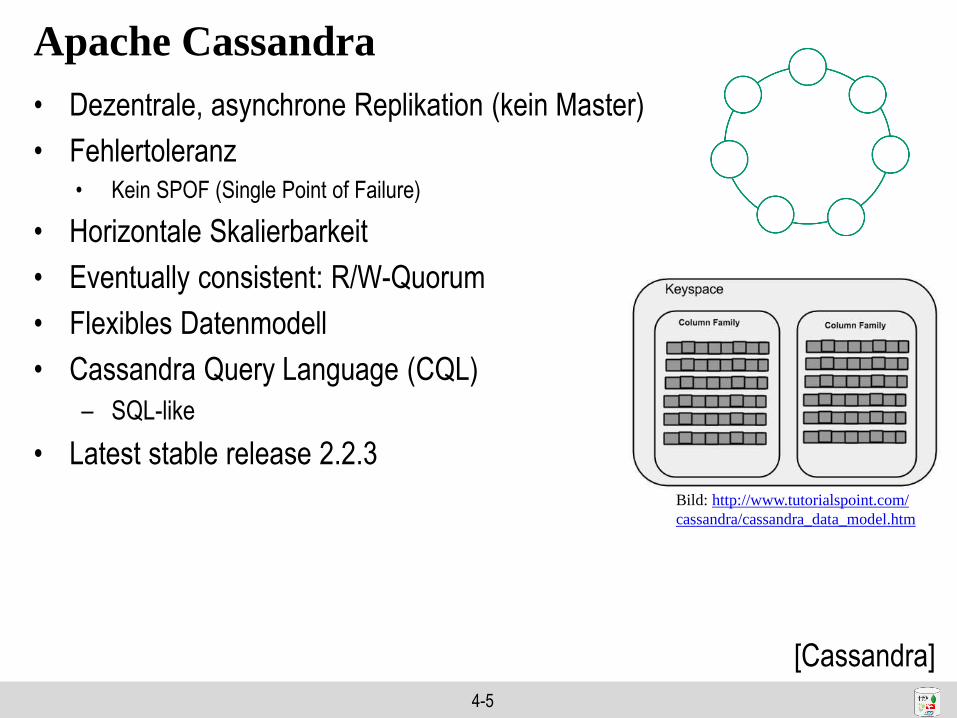
4-5
Apache Cassandra
• Dezentrale, asynchrone Replikation (kein Master)
• Fehlertoleranz• Kein SPOF (Single Point of Failure)
• Horizontale Skalierbarkeit
• Eventually consistent: R/W-Quorum
• Flexibles Datenmodell
• Cassandra Query Language (CQL)
– SQL-like
• Latest stable release 2.2.3
Bild: http://www.tutorialspoint.com/
cassandra/cassandra_data_model.htm
[Cassandra]

4-6
Some Cassandra Users …
http://www.planetcassandra.org/companies/

4-7
BigTable und HBase
• Verteilte Datenspeicherung mit erweiterbarem relationalen Modell
– Spaltenorientierter Key-Value-Store
– Multi-Dimensional, versioniert
– Hochverfügbar, High-Performance
• Ziele
– Milliarden von Zeilen, Millionen von Spalten, Tausende von Versionen
– Real-time read/write random access
– Große Datenmengen (mehrere PB)
– Lineare Skalierbarkeit mit Anzahl Nodes
• HBase ist Hadoop’s
BigTable Implementierung
BigTable HBase
Tablet Region
Master Server HBase Master
Tablet Server HBase Region Server
GFS HDFS
SSTable File MapFile

4-8
Einsatzfälle
• Beispiel Web-Tabelle
– Tabelle mit gecrawlten Webseiten mit ihren Attributen/Inhalten
– Key: Webseiten-URL
– Millionen/Milliarden Seiten
• Szenarien
– Random-Zugriff durch Crawler zum Einfügen neuer/geänderter Webseiten
– Batch-Auswertungen zum Aufbau eines Suchmaschinenindex
– Random-Zugriff in Realzeit für Suchmaschinennutzer, um Cache-Version von
Webseiten zu erhalten
Sports Illustrated
… CNN …
cnnsi.com
My Look
… CNN.com …
my.look.ca
CNN
…
www.cnn.com
CNN
…
CNN
…
t3iwww.cnn.com t5
www.cnn.com t6

4-9
Datenmodell
• Verteilte, mehrdimensionale, sortierte Abbildung(row:string, column:string, time:int64) → string
– Spalten- und Zeilenschlüssel
– Zeitstempel
– Daten bestehen aus beliebigen Zeichenketten / Bytestrings
• Zeilen
– (nur) Lese- und Schreiboperationen auf einer Zeile sind atomar
– Speicherung der Daten in lexikographischer Reihenfolge der Zeilenschlüssel
[CDG+08]

4-10
Datenmodell (2)
• Spalten
– können zur Laufzeit beliebig hinzugefügt werden
• Spaltenfamilien (column families)
– Können n verwandte Spalten (ähnliche Inhalte) umfassen
– Spaltenschlüssel = Spaltenfamilie:Kennzeichen
– Benachbarte Speicherung von Spalten einer Familie
– innerhalb Familie: flexible Erweiterbarkeit um neue Spalten
• Zeitstempel
– mehrere Versionen pro Zelle
– festgelegte Versionszahl: automatisches Löschen älterer Daten
[CDG+08]

4-11
Data Model – WebTable Example
Row Key
Tablet - Group of rows with consecutive keys.
Unit of Distribution
Bigtable maintains data in lexicographic order by row key

4-12
Data Model – WebTable Example
Column
FamilyColumn family is the unit of access control
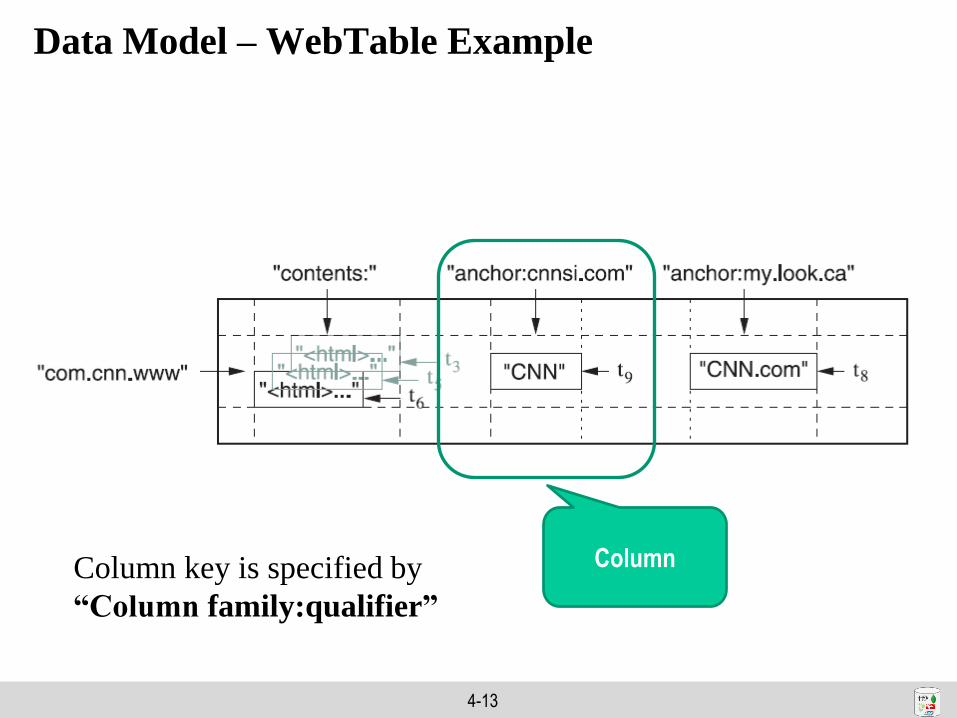
4-13
Data Model – WebTable Example
ColumnColumn key is specified by
“Column family:qualifier”

4-14
Data Model – WebTable Example
ColumnYou can add a column in a
column family if the column
family was created

4-15
Data Model – WebTable Example
CellCell: the storage referenced by
a particular row key, column
key, and timestamp

4-16
Data Model – WebTable Example
Different cells in a table can
contain multiple versions
indexed by timestamp

4-17
Datenmodell (3)
• Konzeptionelle Sicht „Wide Table“ (alternativ)
• Physische Speicherung
Row Key Time Stamp Column Contents Column Family Anchor
“com.cnn.www” T9 Anchor:cnnsi.com CNN
T8 Anchor:my.look.ca CNN.COM
T6 “<html>.. “
T5 “<html>.. “
T3 “<html>…”
Row Key Time Stamp Contents
com.cnn.www T6 “<html>..”
T5 “<html>..”
T3 “<html>..”
Row Key Time Stamp Anchor
com.cnn.www T9 Anchor:cnnsi.com CNN
T8 Anchor:my.look.ca CNN.COM

4-18
Architektur
• Datenpartitionierung
– Zeilen in Tabelle sortiert nach Key
– Horizontale Partitionierung von Tabellen in Tablets
– Verteilung von Tablets auf mehrere Tablet Server
• Master Server
– Zuordnung: Tablet Tablet Server
– Hinzunahme/Entfernung von Tablet Servern
– Lastbalancierung für Tablet Server
• Tablet Server
– Verwaltung von ca. 10-1000 Tablets
– Koordiniert Lese- und Schreibzugriffe
– Tablet-Split für zu große Tablets (100-200MB)
– Replikation durch Google File System (GFS)
• Client
– Kommunikation mit Tablet Server für Lesen und Schreiben
Master Server
(GFS Master Server)
Tablet Server
(GFS Chunk
Server)
...
Tablet Server
(GFS Chunk
Server)
...Tablets (Chunks)

4-19
Einschub: Google File System
• Proprietäres, verteiltes Linux-basiertes Dateisystem
– Hochskalierend: tausende Festplatten, mehrere 100TB
– Open Source-Alternative: Hadoop Distributed File System
• Netzknoten: günstige Standardhardware
• Optimiert für Streaming Access (Write-once-read-many)
• Physische Datenpartitionierung in Chunks (Default: 64 MB)
– Verteilung über mehrere Chunkserver (und Replizierung jedes Chunks)
• Master-Server
– Mapping: Datei → Chunk → Node
– Replikat-Management: Default 3 Chunk-Kopien (in 2 Racks)
– Anfragebearbeitung, Zugriffsverwaltung
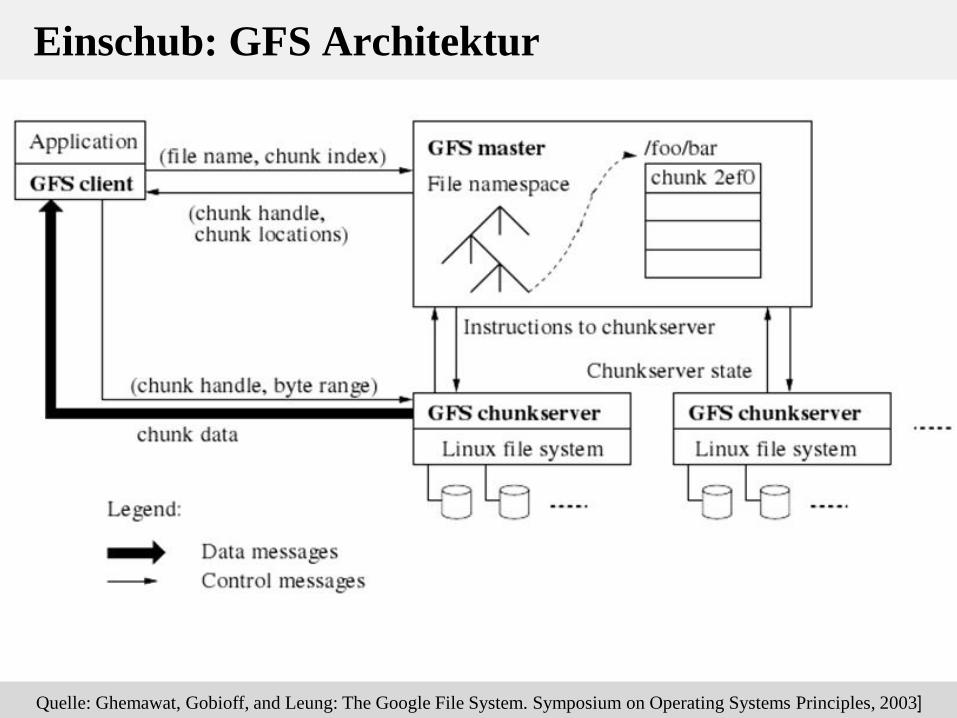
4-20
Einschub: GFS Architektur
Quelle: Ghemawat, Gobioff, and Leung: The Google File System. Symposium on Operating Systems Principles, 2003]

4-21
Einschub: GFS Datenmanipulation
• Mutation (Schreiben oder Anhängen)
– muss für alle Replikate
durchgeführt werden
• Lease Mechanismus
– Master bestimmt ein Replica zur
Koordinierung (“lease for mutation”)
– Primary Replica sendet Folge von
Mutations-Operationen an alle
Secondary Replicas
– Reduzierter Master-Workload
– Datenfluss von Kontrollfluss entkoppelt
• Append-Operation
– GFS hängt Daten von Client an File an
– optimiert für Multiple-Producer-Single-Reader-Queues (z.B. MapReduce)
Quelle: Ghemawat, Gobioff, and Leung: The Google File System. Symposium on Operating Systems Principles, 2003]

4-22
Big Table: Tablet Location
• Zweistufige Katalogverwaltung mit Root- und METADATA-Tabellen
• Root Tabelle
– Verweis auf alle Tablets einer METADATA Tabelle
– wird niemals geteilt = genau ein Tablet
• METADATA Tabelle
– Verweis auf alle Tablets (von User Tabellen)
– Identifikator: Tabellenname + letzte Zeile (Key)
– Tabellen sind sortiert nach Key
• Adressraum
– Eintragsgröße: 1KB
– Tablet Größe: 128MB= 217 KB
– Adressierbare Tablets: 217*217 = 234
– Größe aller Tablets:
234*128 MB= 234*227 B
= 221 TB = 211 PB = 2 ExaBytes
table name end row key tablet server
UserTable1 Alice server1.google.com
UserTable1 Bob server1.google.com
UserTable1 Eve server9.google.com
UserTable2 Angie server3.google.com

4-23
BigTable: Tablet Speicherung
• Speichern der Log- und Daten-Files in GFS
– metadata = METADATA Tablets: Speichern der Tablet Location
– data = SSTables Collection pro Tablet
– log = Tablet logs
• Google SSTable Dateiformat
(Sorted String Table )
– Zur Speicherung der Daten
– Persistente geordnete, nicht änderbare
Key-Value-Map
– Mehrere SSTables bilden ein
Tablet (=Menge aufeinanderfolgender Zeilen)
Romain Jacotin: Lecture: The Google BigTable, 2014
http://de.slideshare.net/romain_jacotin/undestand-google-bigtable-is-as-easy-as-playing-lego-bricks-lecture-by-romain-jacotin

4-24
SSTable (Sorted String Table)
• Nicht änderbare, sortierte Datei mit Key-Value Paaren
• Sequenz von 64KB Blöcken
– Optional: Laden der Blöcke in Memory (= Lookups + Scans ohne Disk Zugriff)
• Index am Ende der SSTable
– Index wird beim Öffnen von SSTable in Memory geladen
– Lookup: single disk seek
1. Finde entsprechenden Block (Binäre Suche in memory index)
2. Lesen des Blocks von Disk
Romain Jacotin: Lecture: The Google BigTable, 2014
http://de.slideshare.net/romain_jacotin/undestand-google-bigtable-is-as-easy-as-playing-lego-bricks-lecture-by-romain-jacotin

4-25
Tablet: Lese-und Schreibzugriffe
• SSTable File
– Sortierte Map, unveränderbar
nach Erstellung
– Bloom Filter zur Prüfung,
ob Daten vorhanden für
row+column
• Schreiben
– Schreiben in Transaction Log (für redo)
– Schreiben in MemTable (RAM)
• Asynchrone SSTable Erstellung: Compaction (Verdichtung)
– Minor: Kopieren von MemTable-Daten in neue SSTable (und entfernen aus Log)
– Merge: Zusammenführen von MemTable-Daten und SSTable zu neuer SSTable
– Major: Entfernen gelöschter Daten (= Merge in eine einzige große SSTable)
• Lesen
– Zugriff auf „merged view“ von MemTable-Daten und SSTables, um Daten zu finden

4-26
Google Chubby Lock Service
• Verteilter Lock Manager
– für Synchronisation in verteilten Systemen
– z.B. Koordination für parallele Schreibzugriffe
durch versch. Clients notwendig
• Clients mit Chubby-Library
• Chubby-Zelle: 5 Replikas, davon 1 Master
– PAXOS consensus
• Einsatz:
– Speichern der Root tablet location
– Sicherstellen max. 1 Master
– Zugangskontrolle
– …
Romain Jacotin: Lecture: The Google BigTable, 2014:
http://de.slideshare.net/romain_jacotin/undestand-google-bigtable-is-as-easy-as-playing-lego-bricks-lecture-by-romain-jacotin

4-27
Performanz
• Anzahl der
1000 Byte Lese-
und Schreib-Ops
pro Sekunde
• Gute Skalierbarkeit
für bis zu
250 Tablet Server
• Wahlfreies & sequenzielles Schreiben schneller als wahlfreies Lesen
– Commit-Log ist nur ein append; Lesen erfordert Zugriff auf MemTable + SSTables
• Wahlfreies Lesen (random reads) am langsamsten
– Zugriff auf (alle) SSTables notwendig
• Scanning und sequenzielles Lesen performanter
– Ausnutzung sortierter Keys, kein Zugriff auf GFS

4-28
BigTable Übersicht
BigTable (CP)pr
o K
note
n
Datenmodell (row, column, timestamp) string
Lesen MemTable + SSTables
Schreiben Transaction Log + MemTable; asynchrone
SSTable-Erstellung
meh
rere
Kno
ten
Partitionierung Horizontale Bereichspartitionierung (Row Key)
Anfrage-Routing Master Server → Tablet Server
(-ROOT- → .META. → User Tablet)
Konsistenz Strong Consistency

4-29
BigTable vs. RDBMS
• BigTable-Eigenschaften
– Verteilte Punkt- und Scan-Anfragen für Reads/Writes
– Built-In-Replikation
– Skalierbarkeit
– Batch-Verarbeitung (Source/Sink für MapReduce)
– Denormalisierte Daten / breite, spärlich besetzte Tabellen
– kostengünstig
– keine Query-Engine / kein SQL
– Transaktionen und Sekundär-Indices (extern) möglich, jedoch schlechte Performance
• RDBMS
– deklarative Anfragen mit SQL (Joins, Group By, Order By …)
– automatische Parallelisierbarkeit auf verschiedenen PDBS-Architekturen
– Sekundär-Indices
– Referenzielle Integrität
– ACID-Transaktionen, …

4-30
Megastore: Datenmodell
• Hybrider Ansatz zwischen
RDBMS und Data Store
• Ziel: Skalierbarkeit
+ Replikation
+ ACID-Transaktionen
• Relationales Schema
– Tabellen und Properties (Attribute)
– Definition von Indexen
• Data Store
– mehrwertige Properties (repeated)
– Abbildung auf BigTable-Modell
• BigTable-Modell
– Row = Entity, Row key = (konkatenierter) Primary Key
– (row, column, timestamp) value [Megastore]
Bildquelle: Amir Payberah: MegaStore and Spanner. 2015. https://de.slideshare.net/payberah/megastore-and-spanner
http://cse708.blogspot.jp/2011/03/megastore-providing-scalable-highly.html

4-31
Megastore: Partitionierung
• Datenpartitionierung in RDBMS
– horizontal vs. vertikal (oder kombiniert)
– Ziel: Anfragen müssen nur von einem (oder wenigen) Knoten bearbeitet werden
– Auswahl nach Art der Anfragen (Projektion, Selektion)
– Problem: Anfragen über mehrere Relationen
• Megastore: Anwendungsspezifische Partitionierung von Entities zu
Gruppen (Entity groups)
– Definition von Parent-Child-Beziehung zwischen Tabellen (foreign key, 1:N)
– Root-Table = Tabelle ohne Parent
– Entity group = eine Entity in Root-Table + alle seine (Kindes-)Kinder
• Beispiele
– Mail-Programm: (Nutzer+Emails)
– Blogger: (Nutzerprofil), (Blog+Posts)

4-32
Megastore: BeispielCREATE TABLE User {required int64 user_id;required string name;
} PRIMARY KEY(user_id), ENTITY GROUP ROOT;
CREATE TABLE Photo {required int64 user_id;required int32 photo_id;required int64 time;required string full_url;optional string
thumbnail_url;repeated string tag;
} PRIMARY KEY(user_id, photo_id),IN TABLE User, ENTITY GROUP KEY(user_id) REFERENCES User;
user_id name
1 Schmidt
2 Meier
user_id photo_id time tag ...
1 10 19:15 [Dinner,Paris] ...
1 11 19:18 [Dinner,Berlin] ...
2 10 15:34 [Berlin, Mauer] ...
Key user.name photo.time photo.tag photo. ...
1
1.10 ...
1.11 ...
2
2.10 ...
User
Photo
BigTable
EG1
EG2

4-33
MegaStore: Entity Groups
• Transaktionen und konkurrierende Zugriffe
– ACID-Semantik innerhalb einer Entity Group (logischer Einbenutzerbetrieb, strong
consistency)
– keine ACID-Garantie für Transaktionen über mehrere Entity Groups
• Indexes
– lokal: nur innerhalb einer Entity Group
– global: über mehrere Entity Groups
• Replikation
– Entity Groups werden synchron repliziert (auch über verschiedene Data Center)
– unabhängige Synchronisation verschiedener Entity Groups
CREATE LOCAL INDEX PhotosByTimeON Photo(user_id, time);
CREATE GLOBAL INDEX PhotosByTagON Photo(tag) STORING (thumbnail_url);

4-34
Indizes
• Anfragebeantwortung ausschließlich mit Indizes
– Hohe Leseperformanz auf Kosten von Schreibzugriffen
• Index für eine oder mehrere Property inkl. Sortierreihenfolge
Quelle: Dan Sanderson: Programming Google App Engine, O‘Reilly. + Folien Prof. Dr. Scherzinger

4-35
Anfragesprache GQL
• Keine SQL-Mächtigkeit
• Aufbau: Entity-Typ, Filter (WHERE), Sortierung (ORDER BY)
– Einschränkungen (nächste Folie)
• Anfrageverarbeitung
– Verwende den Index, bei dem alle Entities des Anfrageergebnisses hintereinander
(consecutive rows) auftreten (ggf. in ORDER-BY-Reihenfolge)
– Finde erste passende Entity; dann alle folgenden Entities solange wie Filter-
Bedingung erfüllt ist
• Beispiel 1:
SELECT * FROM Book
WHERE Year=1950
• Beispiel 2:
SELECT * FROM Book
WHERE Year>=1950

4-36
Anfragesprache: Einschränkungen (1)
• Unproblematisch: Mehrere Filter (< und >) auf gleicher Property
– Nur AND-Kombination in WHERE-Bedingung möglich!
• Problematisch: Filter auf mehreren Properties
• Verwendung eines Inequality-Filters (<, >) erzwingt geeigneten Index
– Index muss zunächst nach Equality-Property sortiert sein
– Beispiel: SELECT * FROM Player WHERE charclass=„mage“ AND level > 10
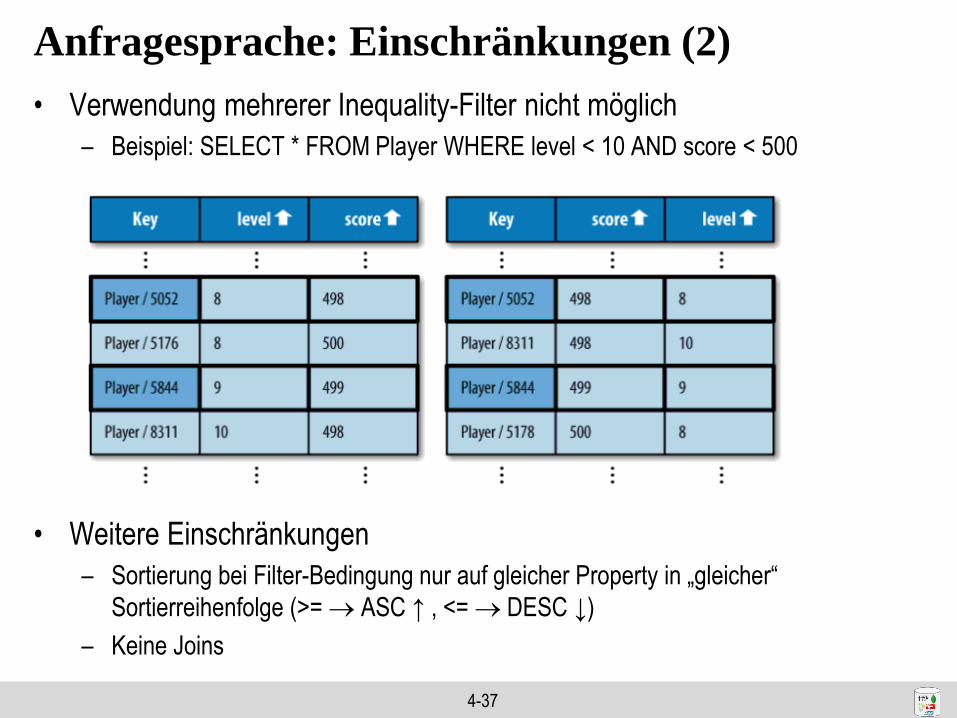
4-37
Anfragesprache: Einschränkungen (2)
• Verwendung mehrerer Inequality-Filter nicht möglich
– Beispiel: SELECT * FROM Player WHERE level < 10 AND score < 500
• Weitere Einschränkungen
– Sortierung bei Filter-Bedingung nur auf gleicher Property in „gleicher“
Sortierreihenfolge (>= ASC ↑ , <= DESC ↓)
– Keine Joins

4-38
Transaktionen
[Megastore]

4-39
Transaktionen innerhalb einer Entity Group
• ACID-Semantik: Änderungen zunächst in WAL (write-ahead log),
erst danach Anwendung der Änderung auf Daten
• Multi-Version Concurrency Control (MVCC)
– Bigtable-Timestamp pro Transaktion zur Unterscheidung
– Read kann konsistente, ältere Versionen während Write lesen
– Write-Operation blockiert Lese-Operation nicht
• Write-Transaktion – Life Cycle
1) Read: Bestimme Timestamp der letzten zugesicherten (commit) Transaktion
+ Logfile Position
2) Anwendungslogik: Lese Daten von Bigtable und erzeuge Logfile-Eintrag
3) Commit: Einigung zwischen Knoten, dass Eintrag in Logfile geschrieben wird (Paxos)
4) Apply: Durchführen der Operationen auf den Daten, Aktualisierung der Indizes
5) Clean-up: Löschen nicht mehr benötigter Daten

4-40
Transaktionen innerhalb einer Entity Group (2)
• Commit vor Apply
– Lese-Operationen die „aktuellste Version anfordern“ müssen ggf. warten
– RDBMS: Commit (Daten sind “durable”) erst, wenn alle Daten “sichtbar”
• Reads
– current: Warten, bis alle zugesicherten (committed) writes durchgeführt, dann lesen
– snapshot: Timestamp der letzten vollständigen durchgeführten Transaktion (ggf.
zugesicherte aber noch nicht durchgeführte Transaktion nicht erfasst)
– inconsistent: lesen letzte Werte, log wird ignoriert (dirty reads)
• Konkurrierende Writes
– gleichzeitiger “Read-Schritt” in Transaktion liefert die gleiche Logfile-Position
– Einigungsprotokoll (Paxos) bestimmt eine Transaktion, die an die Position schreiben
darf (“Winner”)
– andere (“losing”) Transaktionen werden “informiert” und abgebrochen, meist
anschließendes Retry
– keine Serialisierung, aber Konsistenzsicherung

4-41
Transaktionen zwischen Entity Groups
• Queue-Mechanismus
– Transaktions-Nachrichten zwischen Entity Groups
– Gesendet von einer Entity Group während Transaktion (an andere Entity Group)
– Asynchrone Ausführung, keine ACID-Transaktionssemantik
• 2-Phasen-Commit-Protokoll
– Atomare Updates in Transaktionen zwischen Entity Groups möglich
– Möglichst vermeiden, u.a. wegen hoher Latenz

4-42
Replikation
• Unabhängige, synchrone Replikation pro Entity Group
– Anfügen von Logfile-Blöcken nach vorheriger Einigung (Paxos)
[Megastore]

4-43
Replikation: Techniken
• Backup
– Kopie des aktuellen Datenbestands
• Master/Slave
– (meist asynchrone) Weiterleitung der Änderungen von Master an Slaves
– Bsp: MongoDB, Dynamo (einstellbar mit r/w-Quorum), GFS (synchron)
• Master-Master
– unterschiedliche Versionen auf unterschiedlichen Knoten, Konfliktauflösung nötig
– Bsp: CouchDB
• 2-Phasen-Commit (2PC)
– verteiltes Protokoll mit Koordinator-Knoten (Problem: Koordinatorausfall)
– synchron: “Propose, vote, commit/abort”
– Bsp: Verteilte DB

4-45
Replikation: Übersicht
Backup Master-Slave Master-
Master
2PC Paxos
Konsistenz
Transaktionen
Latenz niedrig niedrig niedrig hoch hoch
Durchsatz hoch hoch hoch niedrig mittel
Datenverlust “viel” “etwas” (async) “etwas” nein nein
Verfügbarkeit
bei Ausfall
[Google I/O 2009 - Transactions Across Datacenters]

4-46
Paxos: Verteiltes Einigungsprotokoll
• Mehrere Knoten müssen sich auf einen Wert einigen
– Szenarien: welche Transaktion darf schreiben, Wahl eines Primary Knotens,
Datenreplikation, ...
• Bedingung
– Knoten funktionieren entweder ganz oder gar nicht; Recovery möglich
– Nachrichten werden korrekt (vollständig) gesendet oder gar nicht
– Knoten haben nicht-flüchtigen Speicher
• Vorteile
– fehlertolerant, d.h. geringer Einfluss von Knotenausfällen (im Gegensatz zu 2PC)
– garantierte Korrektheit und Terminierung

4-47
Paxos – Phase 1
• N Prozesse
– jeder Prozess kann Werte vorschlagen (propose), akzeptieren (accept), lernen (learn)
– jeder Proposer hat Wertebereich für Nachrichtennummern, die in aufsteigender
Reihenfolge verwendet werden (i-ter Prozess: i, i+N, i+2N, ...)
• Client “beauftragt” einen Prozess als Proposer
• Phase 1a: Proposer schickt Nachricht an andere Prozesse und sich selbst
– PREPARE (n, v) – Nachricht-Nummer n und Wert v
• Phase 1b: Prozesse reagieren auf PREPARE-Nachricht
– Lesen des letzten Records (n’, v’)
– Wenn es keinen Eintrag gibt
• Speichere (n, v) und sende PROMISE(n): “Ich werde nie eine Nachricht
mit einer Nummer <n beantworten”
– Sonst wenn n > n’
• Speichere (n, v) und sende PROMISE(n, n’, v’): “Ich werde nie…” + “höchste/r zuvor
bearbeitete/r Nachrichtennummer/-wert war n’/v’ ”
– Sonst Ignorieren

4-48
Aktuellster Wert,
dem zugestimmt
wurde
Paxos – Phase 2
• Phase 2a: Wenn Proposer von Mehrheit der Prozesse (>N/2) ein
PROMISE erhalten hat, sendet er ACCEPT
– Sende ACCEPT(n, v’)
– v’ = Wert v’ des Antwort-Triples (n, n’, v’) mit größtem n’
• wenn nur PREPARE(n) Nachrichten, dann v’=v (aus PREPARE-Nachricht)
• Phase 2b: Prozesse reagieren auf ACCEPT-Nachricht
– Lesen der zuletzt gespeicherten Nachricht (n’, v’ )
– Wenn n≥ n’ (oder es kein n’ gibt)
• Speichern von (n, v) und Senden von ACCEPTED(n, v)
– Andernfalls ignorieren
• Wenn Proposer von Mehrheit der Prozesse eine Antwort auf ACCEPT
erhalten hat, ist der Vorschlag angenommen Einigung
• Weiterleiten der Nachrichten an alle Prozesse (Learning)
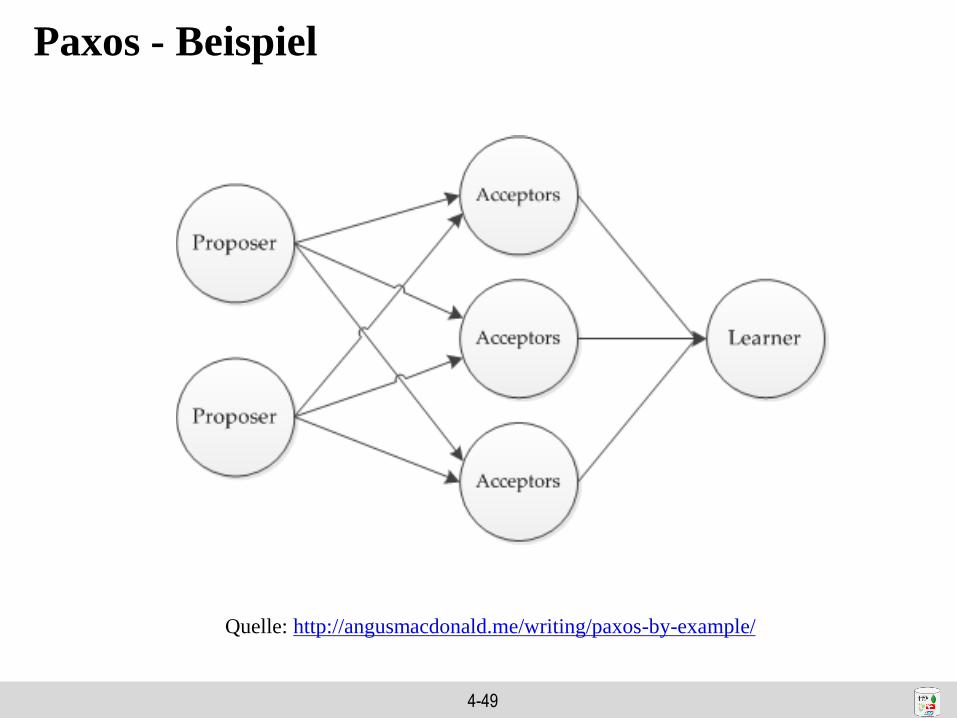
4-49
Paxos - Beispiel
Quelle: http://angusmacdonald.me/writing/paxos-by-example/

4-50
Paxos – Beispiel (2)

4-51
Paxos – Beispiel (3)

4-52
Paxos – Beispiel (4)

4-53
Paxos – Beispiel (5)
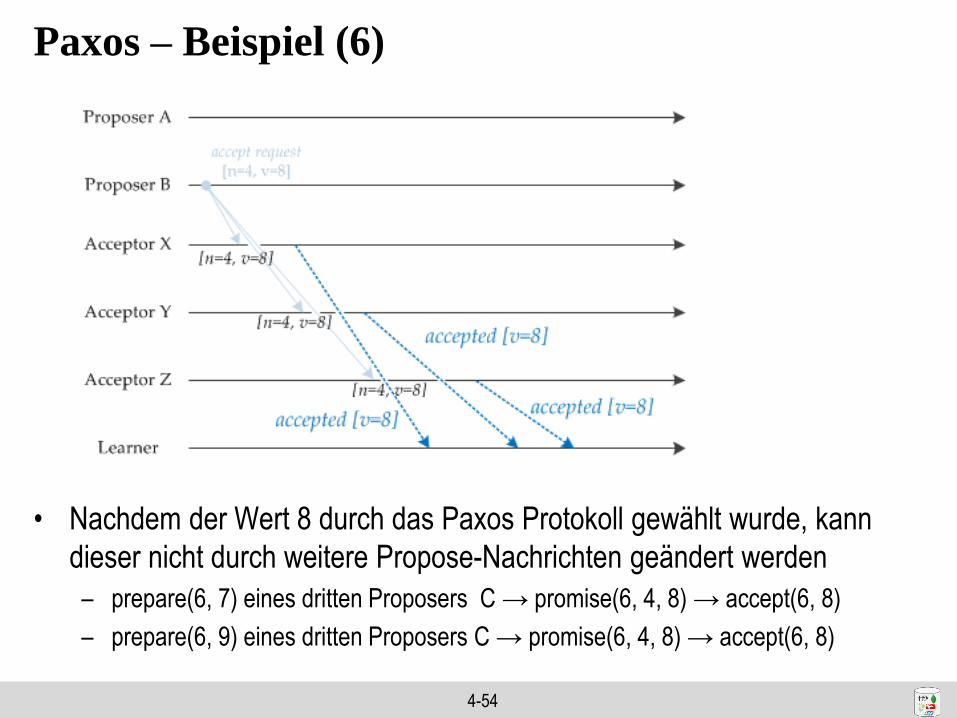
4-54
Paxos – Beispiel (6)
• Nachdem der Wert 8 durch das Paxos Protokoll gewählt wurde, kann
dieser nicht durch weitere Propose-Nachrichten geändert werden
– prepare(6, 7) eines dritten Proposers C → promise(6, 4, 8) → accept(6, 8)
– prepare(6, 9) eines dritten Proposers C → promise(6, 4, 8) → accept(6, 8)

4-55
Paxos: Probleme
• Ausfall eines Acceptors
– kein Problem, solange Quorum (Mehrheit) erreicht wird
• Ausfall eines Learners
– ggf. neu Senden
• Ausfall des Proposers
– Ausfall nach PROPOSE aber vor Einigung
– Lösung durch Bestimmung eines neuen Proposers
• Mehrere Proposer
– Ausfall eines Proposers, Bestimmung eines neuen
– Recovery des ausgefallenen vor Einigung
– Wechselseitige PREPARE-Nachrichten “überstimmen” sich
– Lösung z.B. durch “zufällige Timeouts”, so dass ein Proposer sich durchsetzt
• Allgemein: Fortschritt und Korrektheit kann garantiert werden

4-56
Inhaltsverzeichnis
• Record Stores
– BigTable/HBase, Cassandra
– ACID-Eigenschaften: Megastore
• Relationale Datenbanken in der Cloud
– H-Store/VoltDB
• Transaktionen in der Cloud

4-57
Szenario: RDBMS und das Web
• Web-Anwendung nutzt RDBMS
– irgendwann reicht ein (großer) Datenbankserver nicht mehr aus
– Skalierbarkeit durch verschiedene Techniken
• Verteiltes Caching
– Problem der Aktualisierung, begrenzte Funktionalität
• Replikation der Datenbank
– Lese-Workload kann verteilt werden, dafür Schreibzugriffe auch auf mehreren
Knoten
• Data Sharding
– Partitionierung der Daten über verschiedene Knoten
– Anwendung verwaltet Sharding: Serverausfälle, Anfragen/Transaktionen die über
mehrere Knoten gehen, Re-Sharding, ...
• Ziel: Datenbank/Data Store kümmern sich um
– Verteilung der Daten, Performanz, Behandlung von Ausfällen, ...
http://www.slideshare.net/VoltDB/10-rulesforscalabledatastoreperformance

4-58
Cloud Data Stores
• Kein SQL (NoSQL Data Stores)
– einfacheres Datenmodell, einfache Operationen (Suche mit Schlüssel)
• Einfacheres Modell für konkurrierende Zugriffe
– (meist) keine ACID-Semantik, nächste Folie
• Abgeschwächtes Konsistenzmodell
– Replikation meist asynchron
– Eventual consistency: Clients können zur selben Zeit verschiedene Daten lesen
– konfigurierbarer Tradeoff zwischen Konsistenz und Performanz (read-write-Quorum)
• Erhöhte Anforderung an Client-Applikation, u.a.
– Auflösung von Konflikten
• Bsp: Mischen verschiedener Warenkörbe
– Umgang mit Fehlern auf Grund fehlender Transaktionen
• Bsp: gleichzeitiges Kaufen des letzten Produkts
– Handling von eventual Consistency
• Bsp: verzögerte Aktualisierung des Facebook-Status bei Freunden
http://www.slideshare.net/VoltDB/10-
rulesforscalabledatastoreperformance

4-59
Behandlung konkurrierender Zugriffe
• Einfache Sperren pro Objekt/Dokument
– Nur ein Client kann gleichzeitig auf ein Objekt/Dokument/Record zugreifen
– Bsp: Azure Storage, MongoDB, BigTable
• MVCC – Multi version concurrency control
– Erstellung und Management mehrere Versionen des gleichen
Objekts/Dokuments/Records pro Knoten
– Client leistet Konfliktauflösung
– Bsp: Dynamo, CouchDB, Cassandra
• keine Behandlung
– keine Garantien hinsichtlich resultierender Daten bei konkurrierenden Zugriffen
– Bsp: SimpleDB
• ACID
– logische Serialisierung von Transaktionen (u.a. durch Sperren)
– Bsp: RDBMS, MegaStore (teilweise), VoltDB

4-60
RBDMS-Designprinzipien
• RBDMS wurden für Shared-Memory und (später) Shared-Disk-
Architekturen entwickelt
– Cloud Data Center: Shared Nothing
• RDBMS wurden primär für Speicherung und Verarbeitung von Daten auf
Festplatten entwickelt; Hauptspeicher “nur” für Caching
– zunehmende Größe des Hauptspeichers ermöglicht andere Nutzungsformen
• RDBMS realisieren Recovery durch Logfiles auf Festplatte
– Schnelle Netzwerkstruktur ermöglicht Recovery durch Kopieren von Knoten
• RDBMS realisieren eine strenge Transaktionssemantik (ACID) zur
Sicherung der Datenkonsistenz durch Locking
– Internet-Anwendungen können mit vereinfachten Konsistenzmodellen umgehen
• RDBMS unterstützen Multi-Threading– Gründe: T2 kann bereits ausgeführt werden, wenn T1 auf Daten (von Platte) wartet;
lange Transaktionen sollen kurze nicht blockieren (geringe Latenz)
– Szenario nicht mehr stets relevant (multi core, Hauptspeicherzugriff, OLTP workload)

4-61
Zeitaufteilung für RDBMS
• 13% “sinnvoll”
– Finden relevanter Daten, Aktualisieren der Werte
• 20% Locking
– Setzen, Aufheben und Verwalten von Sperren, Deadlock-Erkennung
– Ziel: Logischer Einbenutzerbetrieb
• 23% Logging
– Schreiben/Lesen von Logfiles
– Ziel: Redo Recovery (Wiederherstellung bei Ausfall), Undo Recovery
(Wiederherstellung des Ursprungszustands bei Transaktionsabbruch)
• 33% Buffer Management
– Abbildung der Tabellen bzw. Datensätze in Seiten (Pages), die dann blockweise auf
Festplatte gespeichert werden
• 11% Latching im Mehrbenutzerbetrieb
– Kurzzeitsperren für interne Datenstrukturen bei Mehrbenutzerbetrieb[OLTP]

4-62
RDBMS-Nutzung für Web-Anwendungen
• Erfolg einfacher Data Stores (KV, Document) zeigt, dass
Datenunabhängigkeit nicht im Fokus steht
– Enge Verzahnung von Web-Anwendung und Data Store
• Viele Web-Anwendungen haben einfache(re) Nutzungsformen
– OLTP mit einfachen Schreib-/Lese-Operationen
– Wenige Datensätze schreiben und lesen pro Transaktion
• Transaktionen sind im Vorfeld bekannt
– Keine ad-hoc Anfragen
• Transaktionen sind meist vergleichsweise einfach
– Keine komplexen Joins, OLAP, etc.

4-63
HStore: Überblick
• Verteilte Datenbank– Mehrere Knoten (Shared-Nothing), pro Knoten ein oder mehrere Sites
– Eine Site pro CPU = single-threaded Datenbank kein Latching
• Hauptspeicher-Datenbank– Zeilen-orientierte Speicherung im Hauptspeicher (B-Tree) kein Buffer Pool
• Transaktionen– Keine ad-hoc SQL-Anfragen, nur Stored Procedures (SP)
– Direkter Zugriff und Datentransfer (kein ODBC)
– Transaktionen (SP) werden a-priori registriert und klassifiziert (z.B. “two phase”)
– Globale Reihenfolge von Transaktionen strenge Konsistenz
– ACID-Eigenschaften
• Recovery– Recovery mittels Replikaten kein Logging
• VoltDB HStore als Open-Source-Produkt (mit Firma für Support)– Verteiltes In-Memory
NewSQL RDBMS
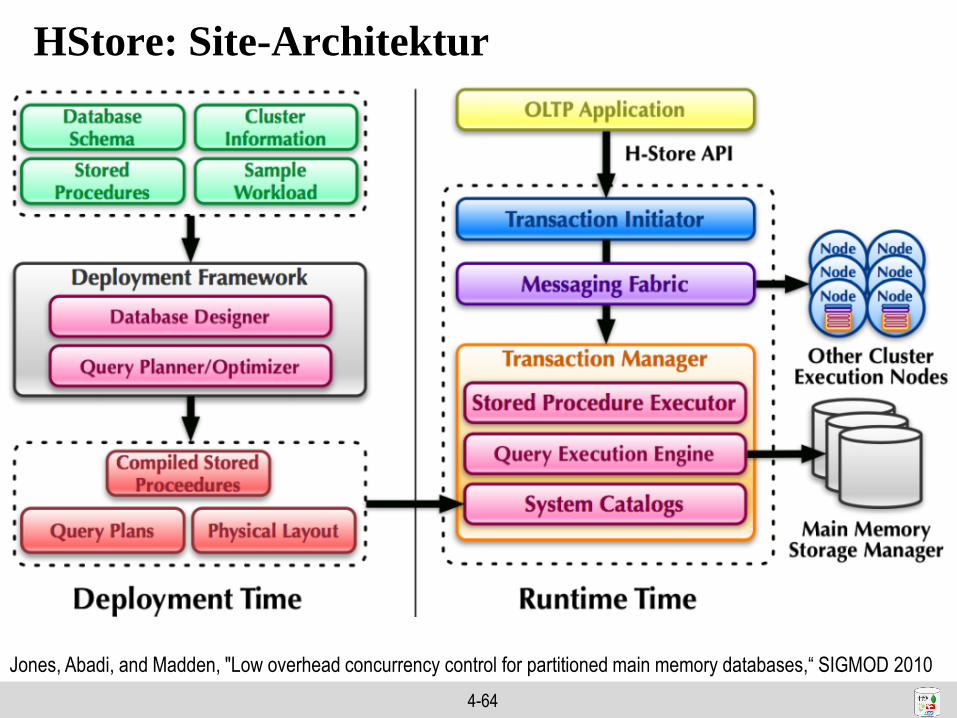
4-64
HStore: Site-Architektur
Jones, Abadi, and Madden, "Low overhead concurrency control for partitioned main memory databases,“ SIGMOD 2010

4-65
Datenpartitionierung und Transaktionen
• Viele Schemas sind “Tree Schemas”
– ein (oder mehrere) Root-Tabellen (z.B. Kunde)
– andere Tabellen haben (mehrfache) 1:N-Beziehung zu Root-Tabelle
• Horizontale Partitionierung der Root-Tabelle
– Horizontale Partitionierung der anderen Tabellen gemäß Root-Tabellen-
Partitionierung
– Alle Informationen zu einem “Root-Datensatz” in gleicher Partition
– vgl. Entity Group in Megastore
• Ziel: Ausnutzen von “Single Site”-Transaktionen
– Alle Operationen einer Transaktion in selber Partition (häufiger Fall)
• Weitere Arten von Transaktionen
– Two-Phase: “erst nur Reads, evtl. Abort, dann alle Writes”
– Commute: beliebige Verschränkung zweier Transkationen führt
stets zum gleichen Ergebnis
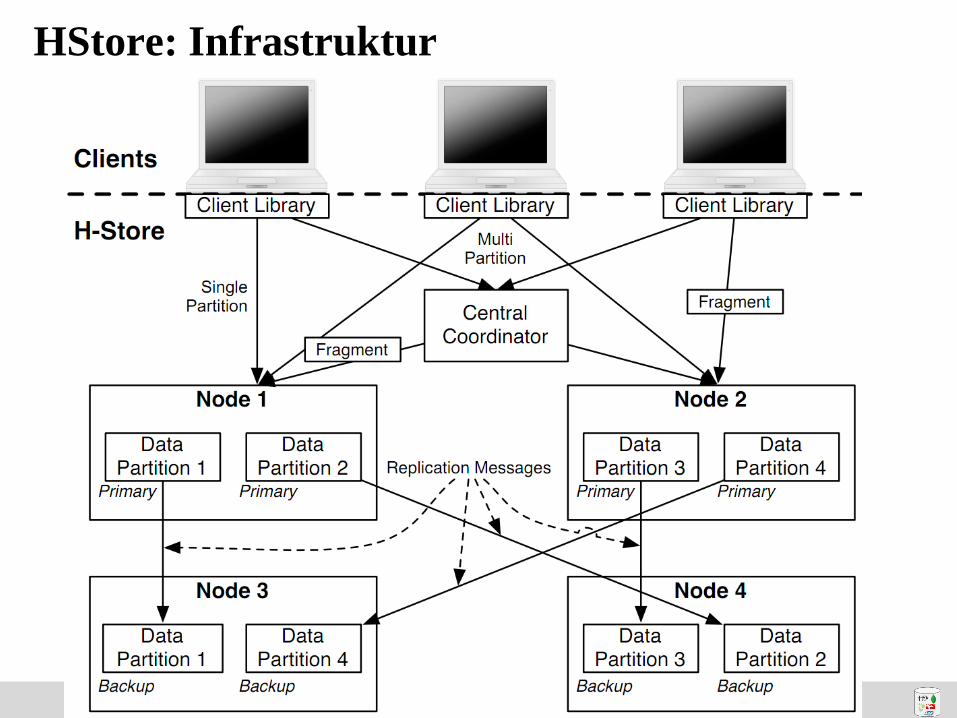
4-66
HStore: Infrastruktur

4-67
Ausführung von Transaktionen
• Transaktionen erhalten eindeutigen Timestamp– (site_id, local_unique_timestamp)
– Alle Sites sind geordnet, Uhrzeiten zwischen Sites (nahezu) synchron
– Globale Ordnung
• Replikation– 2+ Kopien jeder Tabelle
– Reads an beliebige Site, Writes werden an alle Sites gesendet
• Single-Site Transaktionen– Primary Site sendet an Secondary (Backup) Sites weiter
– “etwas warten”, um sicherzustellen, dass keine früheren Transaktionen kommen
– Unabhängige, parallele Ausführung
• Jede Single-Site führt TAs in Timestamp-Reihenfolge aus
• Annahme: Lokales Ergebnis (commit oder abort) = globales Ergebnis
• An Client = Primary Transaktionsergebnis, nachdem alle Secondary ein
“acknowledge” geschickt haben
– Kein ReDo-Log, keine Concurrency Control
– Two-Phase Transaktionen: Zusätzlich kein UnDo-Log

4-68
Multi-Node-Transaktion
• Multi-Node-Transaktion durch zentralen Koordinator
– Globale Reihenfolge der Transaktionen
– Einsatz mehrerer Koordinatoren möglich mit globaler Reihenfolge
• Ausführung
– Zerlegung in mehrere Fragmente, die jeweils an Site geschickt werden
– Undo-Puffer, um bei evtl. Abbruch Ursprungszustand wieder herzustellen
• Abschluss
– Nach Bearbeitung des letzten Fragments sendet Primary alle Fragmente an alle
Secondaries und wartet auf “acknowledge”
– Prüfung auf commit/abort nicht nötig, da gleiches Ergebnis wie Primary

4-69
Inhaltsverzeichnis
• Record Stores
– BigTable/HBase, Cassandra
– ACID-Eigenschaften: Megastore
• Relationale Datenbanken in der Cloud
– H-Store/VoltDB
• Transaktionen in der Cloud

4-70
CloudTPS
• CloudTPS = Cloud Transaction Processing System
• Ziel: ACID-Transaktionen auf mehreren Datensätzen unter Verwendung
existierender Cloud DataStores
• Zwischenschicht zwischen (Web-)Anwendung und Datastore
– Einfaches Key-Value-Datenmodell mit GET/PUT-Anweisungen
• Entkopplung der Datenverantwortung vom jeweiligen Data Store
– Mehrere Transaktionsmanager
• Verteilte Ausführung von Transaktionen
– Zwei-Phasen-Commit-Protokoll (2PC)
• Replikation zwischen Transaktionsmanagern
– Fehlertoleranz
• Periodisches Zurückschreiben der Daten
– Eventual Consistency
Wei, Pierre, Chi: CloudTPS: Scalable Transactions for Web Applications in the Cloud, IEEE Transactions on Services
Computing, Special Issue on Cloud Computing, 2011

4-71
CloudTPS: Architektur
• Virtual Nodes
– Clustering der Datensätze in virtuelle Knoten (vgl. Amazon Dynamo)
– Consistent Hashing für Mapping Node LTM (1:N Mapping)
• Local Transaction Managers (LTMs)
– Verwaltet virtual Nodes
– Transaktionen / Replikationen

4-72
ElasTraS
• Elastic transactional relational Database: Eigenständige Datenbank auf
Basis eines verteilten, fehlertoleranten Speichersystems (DFS)
– „Nachbau“ Kompletter RDBMS Funktionalität (u.a. SQL-Query, ACID)
• Entkopplung der Datenverantwortung vom DFS
– Aufteilung in Partitionen; Zuweisung der Partitionen an Transaktionsmanager (OTM)
• Transaktionen, Lastverteilung, Fehlertoleranz auf Ebene der Partitionen
– Keine partitionsübergreifenden Zugriffe, d.h. keine verteilten Transaktionen
• Änderungen im Hauptspeicher der OTMs
– Hohe Performanz
– Asynchrones Schreiben von SSTables (vgl. BigTable)
Sudipto Das, Shashank Agarwal, Divyakant Agrawal, and Amr El Abbadi. ElasTraS: An elastic, scalable, and self managing
transactional database for the cloud. Journal ACM Transactions on Database Systems (TODS), 38(1), 5, 2013

4-73
ElasTraS: Architektur
• OTM = Owning Transaction Manager
– Verantwortung der ACID-Transaktionen für zugewiesene Partitionen
• TM Master: Mapping Partitionen OTMs
• Metadata Manager: Mapping OTMs DFS
4-74
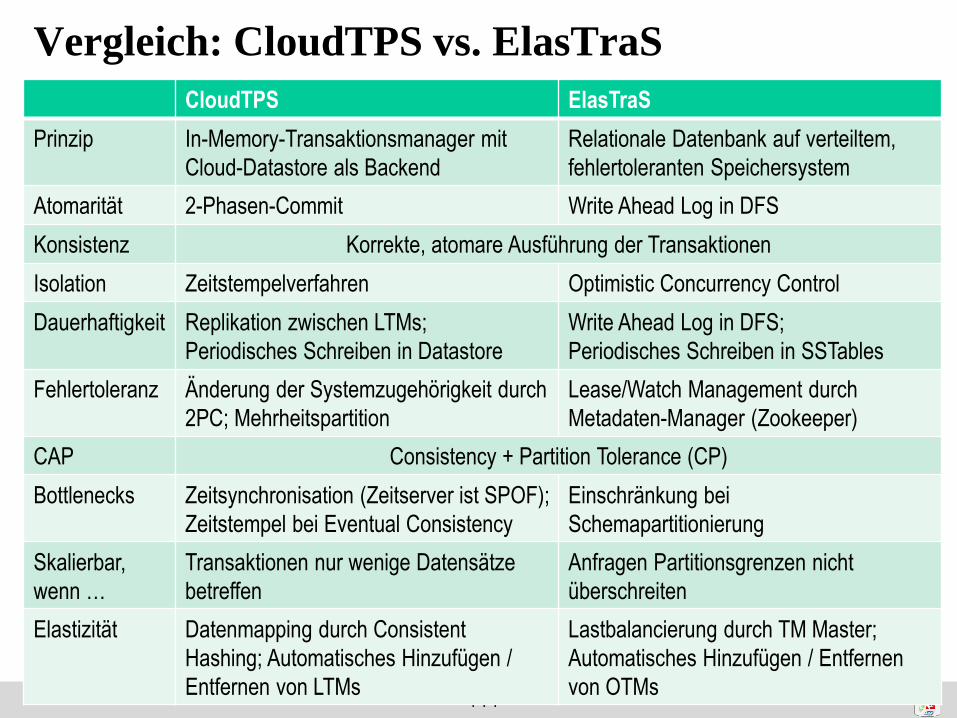
Vergleich: CloudTPS vs. ElasTraS
CloudTPS ElasTraS
Prinzip In-Memory-Transaktionsmanager mit
Cloud-Datastore als Backend
Relationale Datenbank auf verteiltem,
fehlertoleranten Speichersystem
Atomarität 2-Phasen-Commit Write Ahead Log in DFS
Konsistenz Korrekte, atomare Ausführung der Transaktionen
Isolation Zeitstempelverfahren Optimistic Concurrency Control
Dauerhaftigkeit Replikation zwischen LTMs;
Periodisches Schreiben in Datastore
Write Ahead Log in DFS;
Periodisches Schreiben in SSTables
Fehlertoleranz Änderung der Systemzugehörigkeit durch
2PC; Mehrheitspartition
Lease/Watch Management durch
Metadaten-Manager (Zookeeper)
CAP Consistency + Partition Tolerance (CP)
Bottlenecks Zeitsynchronisation (Zeitserver ist SPOF);
Zeitstempel bei Eventual Consistency
Einschränkung bei
Schemapartitionierung
Skalierbar,
wenn …
Transaktionen nur wenige Datensätze
betreffen
Anfragen Partitionsgrenzen nicht
überschreiten
Elastizität Datenmapping durch Consistent
Hashing; Automatisches Hinzufügen /
Entfernen von LTMs
Lastbalancierung durch TM Master;
Automatisches Hinzufügen / Entfernen
von OTMs

4-75
Zusammenfassung
• Relational Data Stores und RDBMS
– Umsetzung von RDBMS-Aspekten in Shared-Nothing-Architekturen
– Erweiterung von einfachen Data Stores um Anfragemächtigkeit und Indexes
• Konsistenzsicherung
– abgeschwächte ACID-Semantik
– MVCC-Prinzip um konsistente Vorversionen während Writes lesen zu können
• Performanz-Aspekte
– Daten in Hauptspeicher
– Möglichst wenige Plattenzugriffe
• Nur “komplette” SSTables einmal schreiben (BigTable)
• Realisierung Logfile-basierter RDBMS-Techniken ohne Plattenzugriffe
– Möglichst wenige Multi-Node-Operationen durch geschickte anwendungs-/schema-
spezifische Datenpartitionierung
– Fokus auf spezielle OLTP-Anwendungen
• Einschränkungen bei verteilten Transaktionen

4-76
Referenzen
• [HBase] http://hadoop.apache.org/hbase/
• [BigTable] Fay Chang, Jeffrey Dean, Sanjay Ghemawat et al. Bigtable: A
Distributed Storage System for Structured Data. OSDI’06
• [Cassandra] Lakshman, Avinash, and Prashant Malik. Cassandra: a
decentralized structured storage system. ACM SIGOPS Operating
Systems Review 44.2 (2010): 35-40.
• [Megastore] Baker et al: Megastore: Providing Scalable, Highly Available
Storage for Interactive Services. CIDR’11
• [OLTP] Harizopoulos et al: OLTP through the looking glass, and what we
found there. SIGMOD, 2008
• [HStore] Stonebraker et al: The end of an architectural era: (it’s time for a
complete rewrite), VLDB 2007