kafka and hadoop at linkedin meetup
TRANSCRIPT

Kafka & Hadoop
Gwen Shapira / Software Engineer

2©2014 Cloudera, Inc. All rights reserved.
• 15 years of moving data around
• Formerly consultant
• Now Cloudera Engineer:– Sqoop Committer
– Kafka
– Flume
About Me

3©2014 Cloudera, Inc. All rights reserved.
There’s a book on that!

4©2014 Cloudera, Inc. All rights reserved.
We are also blogging

6
Getting Data from Kafka to Hadoop
There are only bad options.
It's about finding the best one.
©2014 Cloudera, Inc. All rights reserved.

7
Batch
©2014 Cloudera, Inc. All rights reserved.

8©2014 Cloudera, Inc. All rights reserved.
Camus
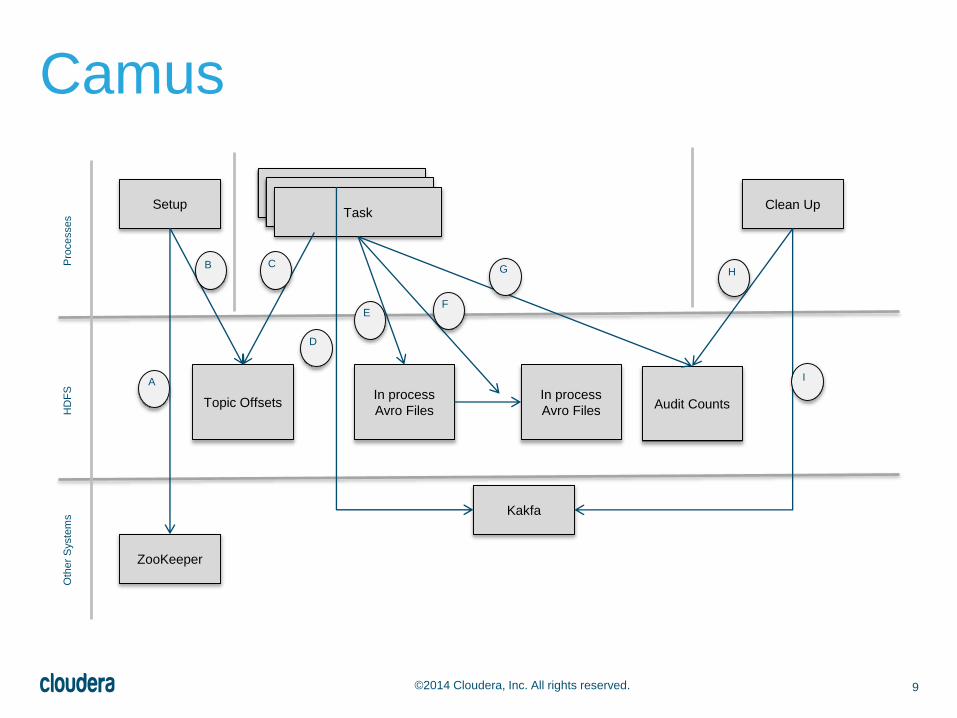
9©2014 Cloudera, Inc. All rights reserved.
Camus
ZooKeeper
Setup
Topic Offsets
Pro
cesses
HD
FS
Oth
er
Syste
ms
TaskTask
Task
In process
Avro Files
In process
Avro FilesAudit Counts
Clean Up
Kakfa
B
A
C
D
F
G H
I
E
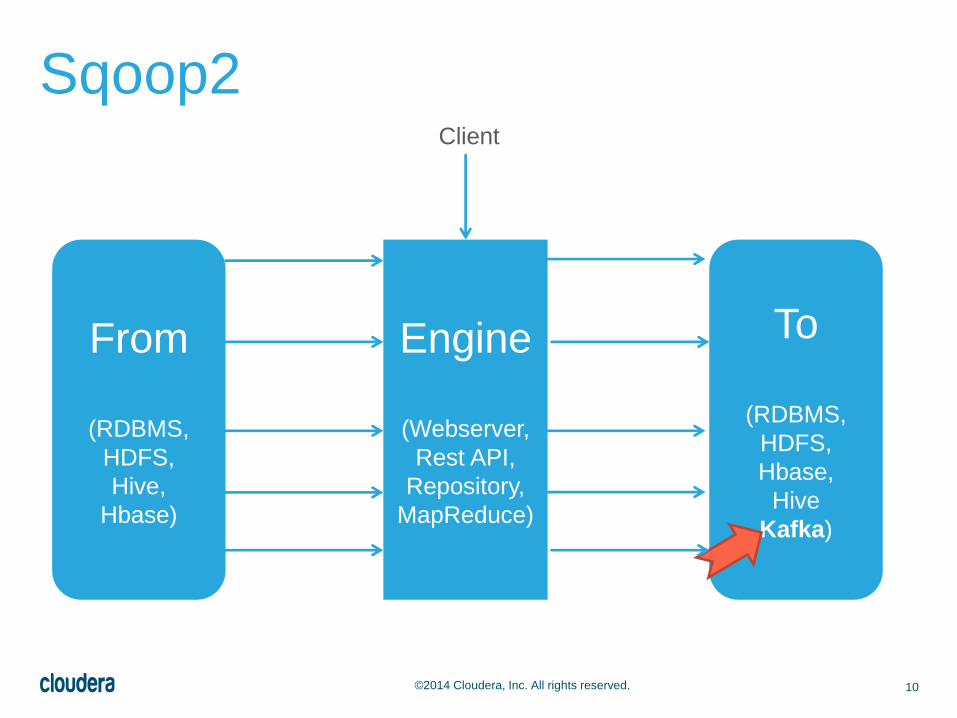
10©2014 Cloudera, Inc. All rights reserved.
Sqoop2
From
(RDBMS,
HDFS,
Hive,
Hbase)
To
(RDBMS,
HDFS,
Hbase,
Hive
Kafka)
Engine
(Webserver,
Rest API,
Repository,
MapReduce)
Client
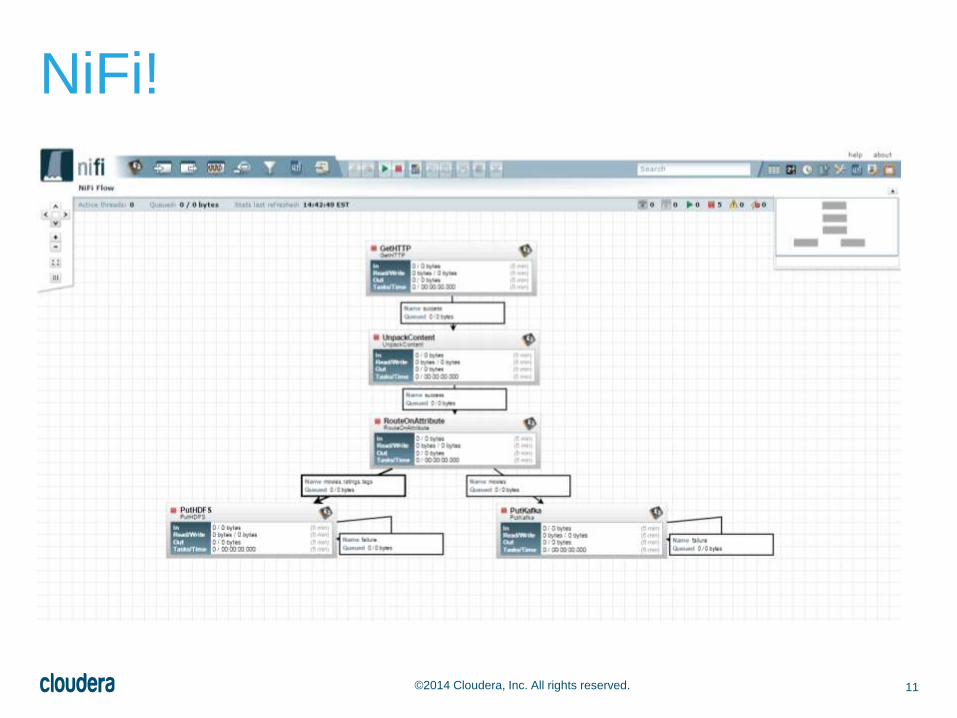
11©2014 Cloudera, Inc. All rights reserved.
NiFi!
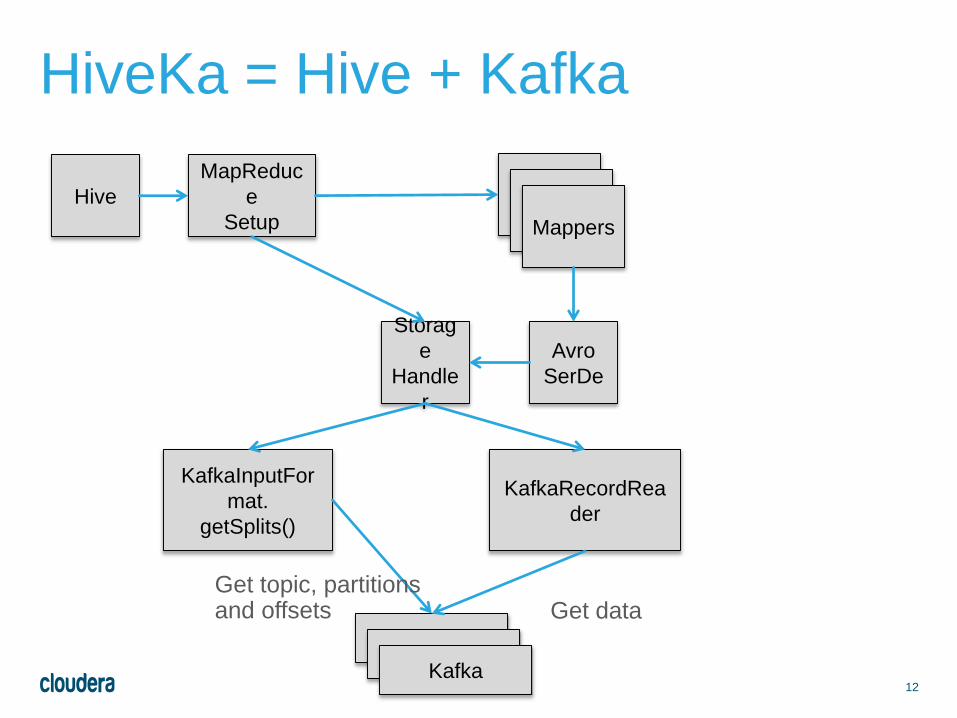
12
Mappers
HiveKa = Hive + Kafka
Hive
Storag
e
Handle
r
KafkaInputFor
mat.
getSplits()
Kafka
Get topic, partitionsand offsets
MapReduc
e
SetupMappers
Mappers
KafkaRecordRea
der
Get data
Avro
SerDe
KafkaKafka
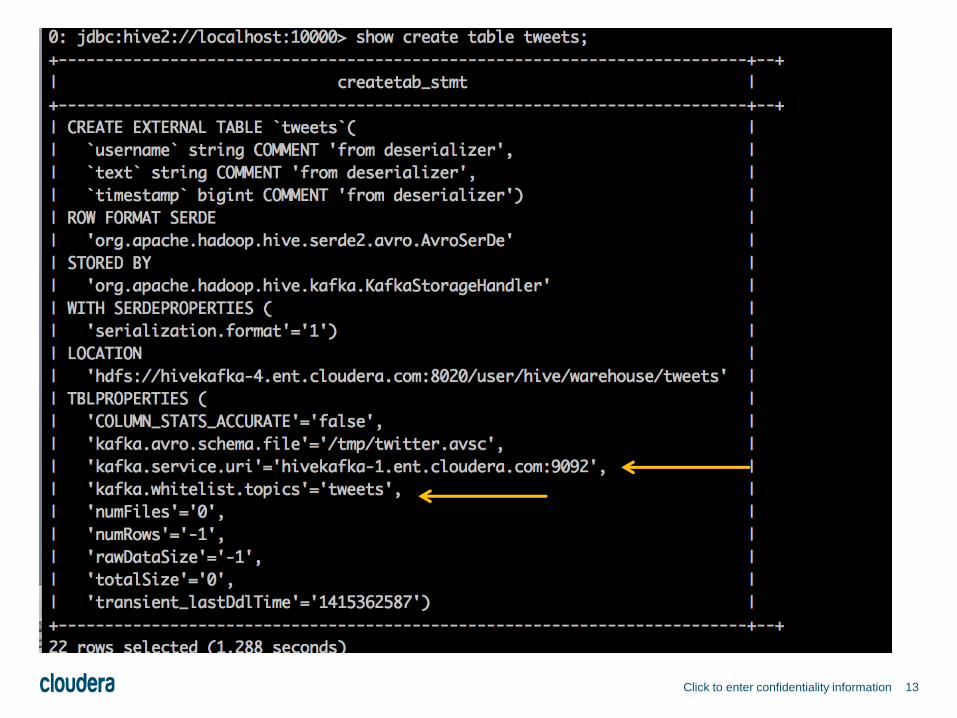
13Click to enter confidentiality information
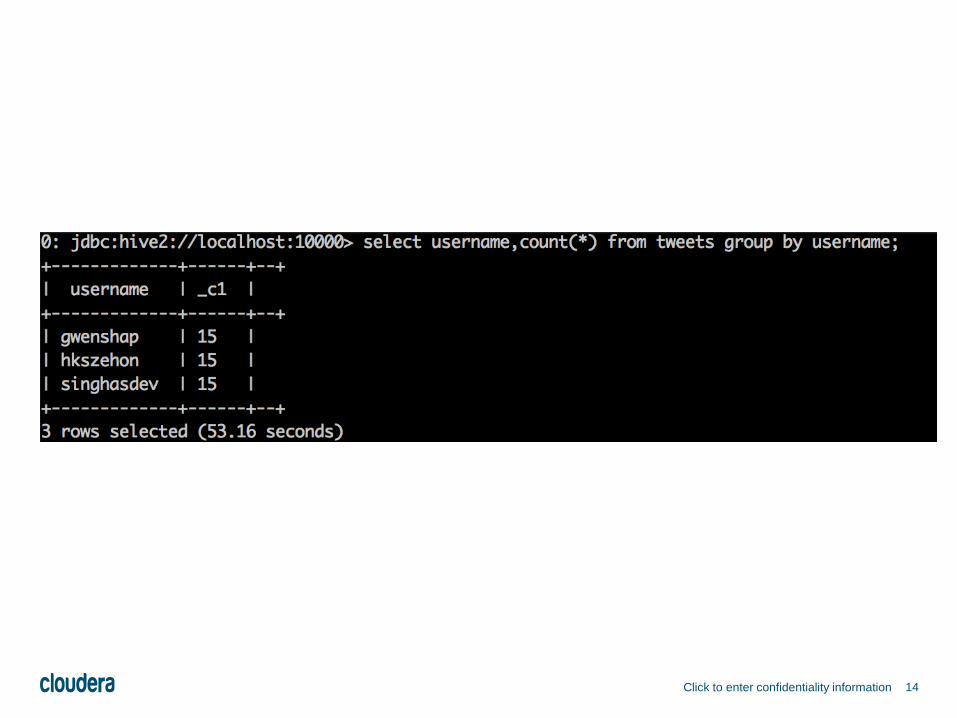
14Click to enter confidentiality information

15
Streaming
©2014 Cloudera, Inc. All rights reserved.

16©2014 Cloudera, Inc. All rights reserved.
Flume + Kafka = Flafka
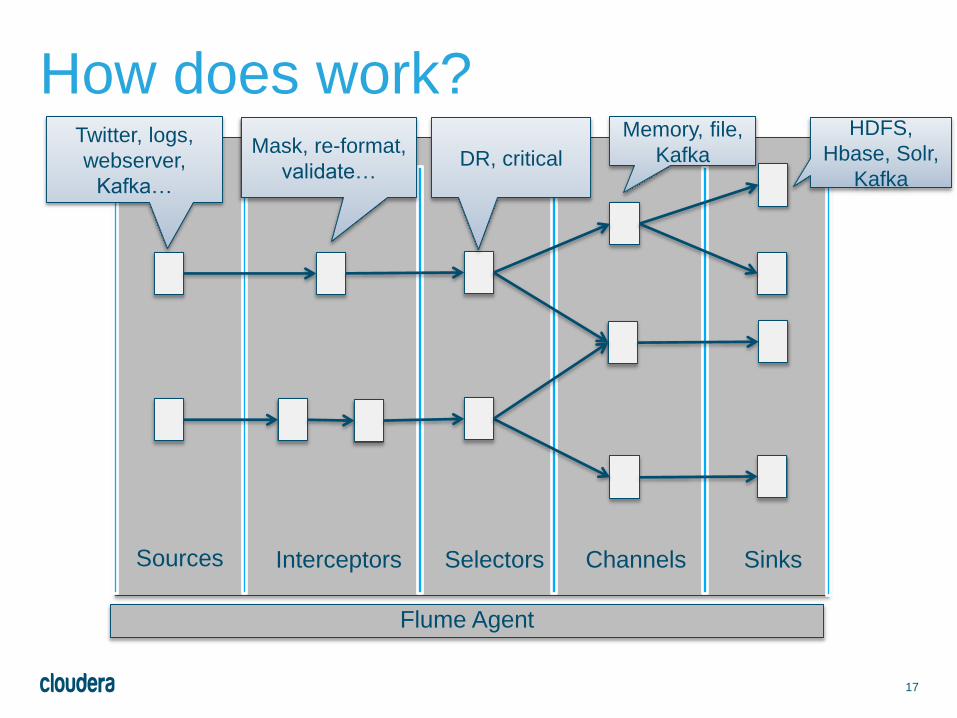
17
Sources Interceptors Selectors Channels Sinks
Flume Agent
How does work?Twitter, logs,
webserver,
Kafka…
Mask, re-format,
validate…DR, critical
Memory, file,
Kafka
HDFS,
Hbase, Solr,
Kafka

18
But I just want to
get data from Kafka
to Hbase / HDFS
©2014 Cloudera, Inc. All rights reserved.
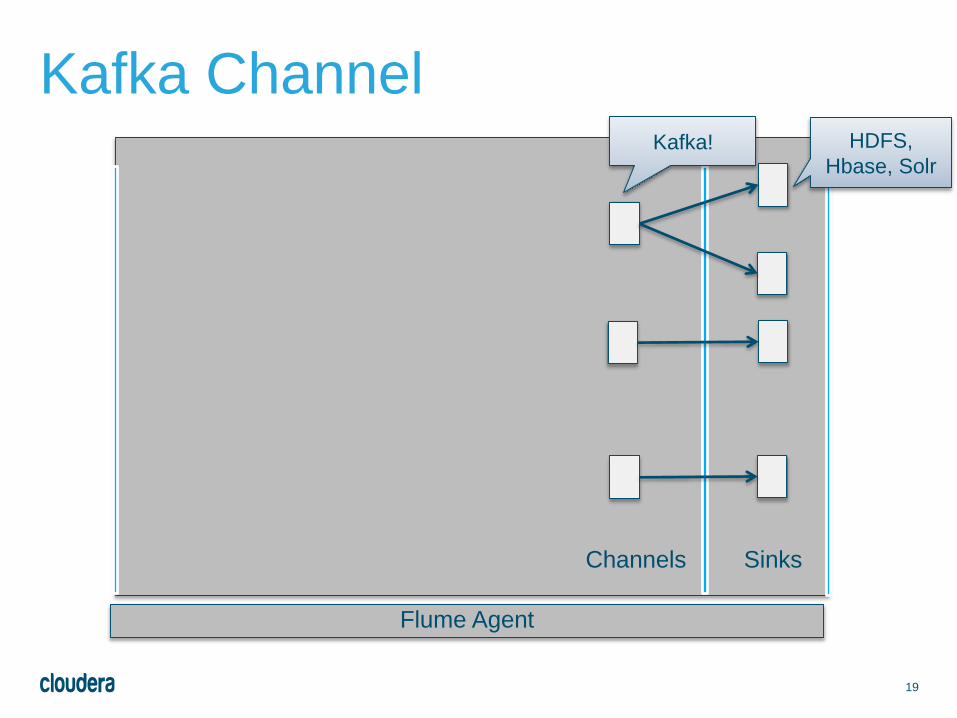
19
Channels Sinks
Flume Agent
Kafka ChannelKafka! HDFS,
Hbase, Solr
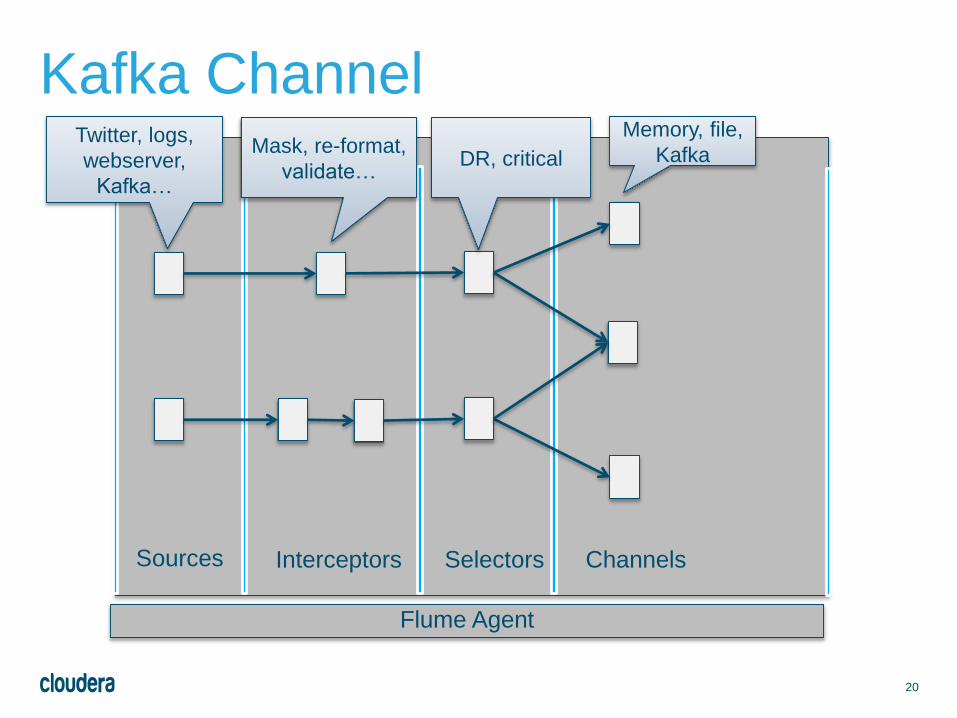
20
Kafka Channel
Sources Interceptors Selectors Channels
Flume Agent
Twitter, logs,
webserver,
Kafka…
Mask, re-format,
validate…DR, critical
Memory, file,
Kafka
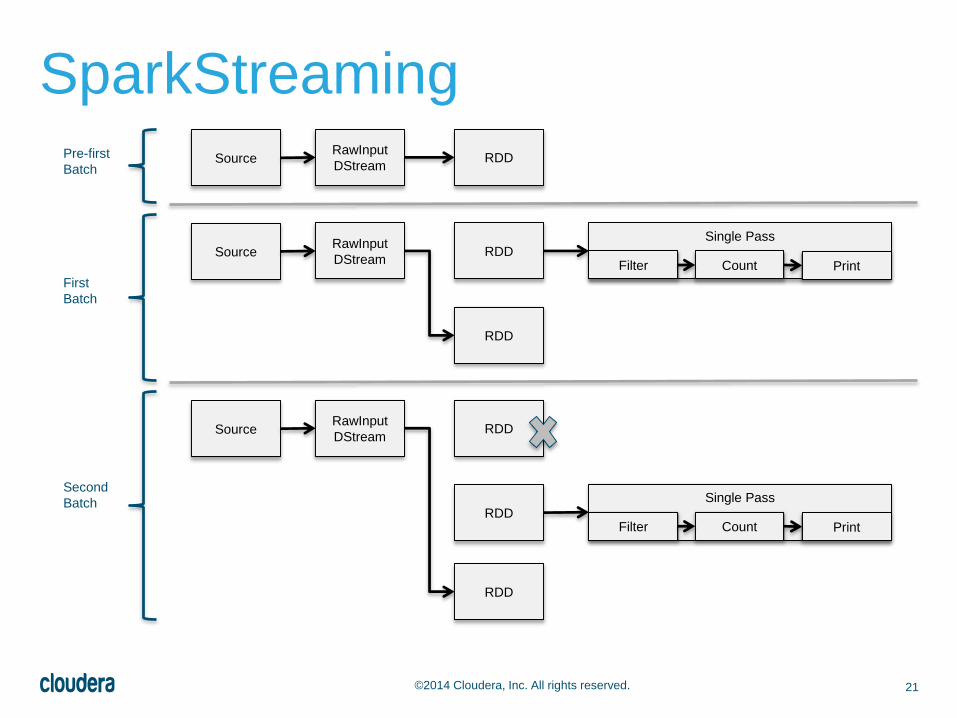
21©2014 Cloudera, Inc. All rights reserved.
SparkStreaming
Single Pass
SourceRawInput
DStreamRDD
SourceRawInput
DStreamRDD
RDD
Filter Count Print
SourceRawInput
DStreamRDD
RDD
RDD
Single Pass
Filter Count Print
Pre-first
Batch
First
Batch
Second
Batch
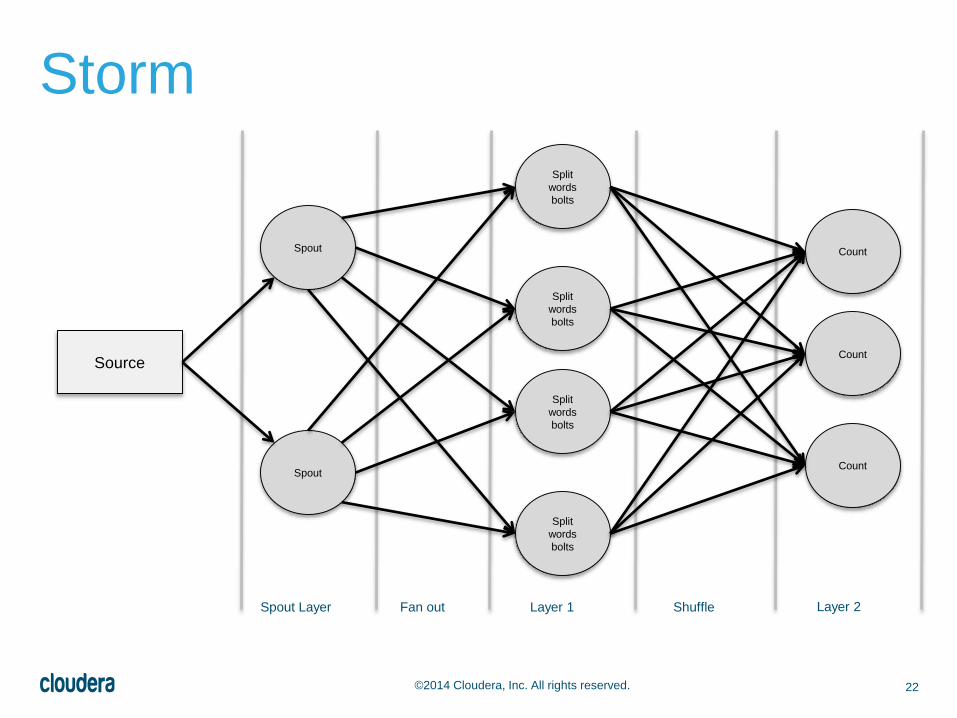
22©2014 Cloudera, Inc. All rights reserved.
Storm
Spout
Source
Split
words
bolts
Split
words
bolts
Spout
Split
words
bolts
Split
words
bolts
Count
Count
Count
Spout Layer Fan out Layer 1 Shuffle Layer 2

23©2014 Cloudera, Inc. All rights reserved.
Retro Thoughts

24©2014 Cloudera, Inc. All rights reserved.
• Data often has schema
• At least it should
• Kafka is unaware – which is good
• Need capability to figure out schema for events
• Without including it in every event
Schema
25©2014 Cloudera, Inc. All rights reserved.
Kafka in Cloudera Manager

Questions?