journal of computing:: efficient method for multiple-level...
TRANSCRIPT

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
722
Efficient Method for Multiple-Level Association Rules in Large Databases
Pratima Gautam K. R. Pardasani
Department of computer Applications Dept. of Mathematics& computer Application MANIT, Bhopal (M.P.) MANIT, Bhopal (M.P.) Email: [email protected] Email: [email protected]
ABSTRACT
The problems of developing models and algorithms for multilevel association mining pose for new challenges for mathematics and computer science. These problems become more challenging when some form of uncertainty in data or relationships in data exists. In this paper, we present a partition technique for the multilevel association rule mining problem. Taking out association rules at multiple levels helps in discovering more specific and applicable knowledge. Even in computing, for the number of occurrence of an item, we require to scan the given database a lot of times. Thus we used partition method and boolean methods for finding frequent itemsets at each concept levels which reduce the number of scans, I/O cost and also reduce CPU overhead. In this paper, a new approach is introduced for solving the abovementioned issues. Therefore, this algorithm above all fit for very large size databases. We also use a top-down progressive deepening method, developed for efficient mining of multiple-level association rules from large transaction databases based on the Apriori principle .
Keywords: association rules, data mining, partition method, multilevel rules
1. INTRODUCTION
Data mining is the process of extracting patterns from data. It is seen as an increasingly important tool by modern business to transform data into business intelligence giving an informational advantage [4]. It is currently used in a wide range of profiling practices, such as marketing, surveillance, fraud detection, and scientific discovery [10]. The related terms data dredging, data fishing and data snooping refer to the use of data mining techniques to sample portions of the larger population data set that are (or may be) too small for reliable statistical inferences to be made about the validity of any patterns discovered[12][8]. Association rules mining is a significant branch of data mining. Association rule knowledge is a popular and healthy researched technique for discovering gorgeous relations between variables in outsized databases [8]. It allows associations among a set of items in huge datasets to be bare and frequently a huge amount of associations are originate [6] [7]. Consequently in order for a user to be able to clench the open rules it is vital to be capable to screen the rules [Interestingness Measures]. For example, the rule {onions, potatoes} = {Burger} originate in the sales data of a supermarket would point out that if a customer buys onions and potatoes jointly, he or she is probable to also buy burger. Such information can be used as the source for decisions concerning advertising activities such as, e.g., promotional pricing or [12] [13]. Some approaches for constructing a concept hierarchy and then trying to discover knowledge in the multi-level abstractions to solve this problem are reported in the
literature [1] like Apriori algorithm [13], [10] etc. These methods work the same minimum support and minimum confidence thresholds. This method is simple, but may lead to some undesirable results. Infect different levels should have different support to extract appropriate patterns [5] [11]. Higher support usually exists at higher levels and if one wants to find interesting rules at lower levels, he/she must define lower minimum support values [21], [3]. This problem over come we use “TreeMap” , a TreeMap can be constructed by scanning the database where each different itemsets is mapped to different locations in the TreeMap, then the entries of the TreeMap gives the genuine calculation of every itemset in the database[16 ]. During that case, we do not have any additional occurrences of each itemset. This method already used by Marganhy and shakour used for single level. . The success of partition approach [16], [17] in single level association rule mining provides the motivation for extending this approach to multilevel association rule mining for four level databases. We also apply this technique for three level databases [22] [15]. In the view of above an algorithm has been developed extending this partition approach and combining it with boolean approach for mining multilevel association rules [14]. 2. RELATED WORK
Marganhy and shakour [17] a prompt and scable algorithm for mining single level association rules using partitioning approach. They partition the database into

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
723
small databases mapped to different locations in the Tree large Map. The database is partitioned in such a way that each partition can be handled in the main memory. This loom makes memory necessities independent from the number of processed transactions which enable truly scable data mining. M.H.Margahny and A.A.Mitwaly[16] build up a method that may avoid or reduce candidate generation and test and exploit some novel data structures to reduce the cost in frequent pattern mining. They were uses the "TreeMap" which is a arrangement in Java language. And also present "Arraylist" technique that greatly reduces the need to cross the database. In this approach, TreeMap store not only candidates, but frequent itemsets as well. Shakil Ahmed, Frans Coenen in paper [19] examined ways of partitioning data for Association Rule Mining. His objective has been to identify methods that will allow capable counting of frequent sets in cases where the data is as well large to be enclosed in main memory, and also where the thickness of the data means that the number of candidates to be measured becomes very large. They have current experimental results that prove the method balance glowing for rising dimensions of data, and perform much better than alternatives, especially when trade with intense data and low support thresholds. Yi-Chung Hu and groups present a new algorithm named fuzzy grids based rules mining algorithm (FGBRMA) for generate fuzzy association rules from a relational database. This algorithm consists of two phases: one to generate the large fuzzy grids, and the other to generate the fuzzy association rules. They also use different partitions methods or the linguistic evade to make the fuzzy association rules exposed from the database more [21] bendable to decision makers. Zaki et.al. Proposed partitions candidate sets into clusters which can be processed separately [9]. The problem with the method is that, particularly when selling with dense data and low support thresholds, expensive pre-processing is required before effective clustering can be identified. They was try to solve this problem.
3. APRIORI ALGORITHM
Apriori is a typical algorithm for learning association rules. Apriori is designed to operate on databases containing transactions (for example, collections of items bought by customers, or details of a website frequentation)[20]. As is common in association rule mining, given a set of itemsets (for instance, sets of retail transactions, each listing individual items purchased), the algorithm attempts to find subsets which are common to at least a minimum number K of the itemsets. [4][18].where k-itemsets are used to explore (k+l)-itemsets. First the set of frequent 1-itemsets is found. This set is denoted L1. L1 is used to find L2, the set of frequent 2-itemsets, which is used to find L3, and so on, until no more frequent k-itemsets can be found. The finding of each Lk requires one
full scan of the database [10]. Once the frequent itemsets from transactions in a database D have been found, it is straightforward to generate strong association rules from them, where strong association rules satisfy both minimum support and minimum confidence [12]. Apriori uses breadth-first search and a tree structure to count candidate item sets efficiently.
4. PROPOSED MODEL FOR FOUR LEVELS MULTI ASSOCIATION RULE
Step-1:
Encode taxonomy using a sequence of numbers and the symbol ‘‘*’’, with the lth number representing the branch number of a certain item at levels.
Step-2:
Set l = 1, where l is used to store the level number being processed whereas l {1, 2, 3, 4} (As we consider up to 4-levels of hierarchies).
Step-3:
Initial j supposes that the unique database size is D bytes. Also the data structure is a Tree Map. And main memory available is G bytes. Following that partition the database into small databases [17].
Step-4:
After that transforming each partition of transaction databases into the Boolean matrix [14].
Step-5:
Set user defines minimum support on current level.
Step-6:
Describe the key value according the occurrences of itemset in the transaction dataset. After that evaluate predefine minimum support threshold.
Step-7:
Execute conjunction proposition rule to generate 2, 3 itemsets and 4-itemsets at level 1.
Step-8:
Generate l+1; (Increment l value by 1; i.e., l = 2, 3) itemset from Lk and go to step-4 (for repeating the intact processing for next level).
VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
724
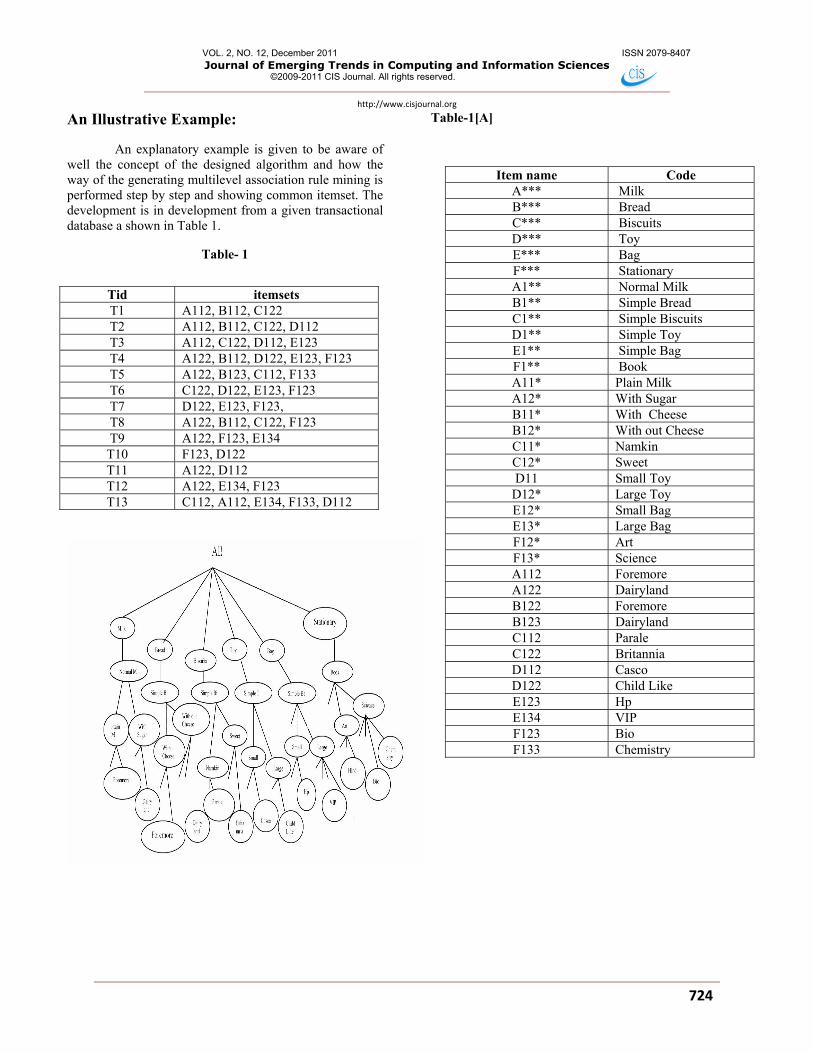
An Illustrative Example:
An explanatory example is given to be aware of well the concept of the designed algorithm and how the way of the generating multilevel association rule mining is performed step by step and showing common itemset. The development is in development from a given transactional database a shown in Table 1.
Table- 1
Table-1[A]
Tid itemsets T1 A112, B112, C122 T2 A112, B112, C122, D112 T3 A112, C122, D112, E123 T4 A122, B112, D122, E123, F123 T5 A122, B123, C112, F133 T6 C122, D122, E123, F123 T7 D122, E123, F123, T8 A122, B112, C122, F123 T9 A122, F123, E134
T10 F123, D122 T11 A122, D112 T12 A122, E134, F123 T13 C112, A112, E134, F133, D112
Item name Code A*** Milk B*** Bread C*** Biscuits D*** Toy E*** Bag F*** Stationary A1** Normal Milk B1** Simple Bread C1** Simple Biscuits D1** Simple Toy E1** Simple Bag F1** Book A11* Plain Milk A12* With Sugar B11* With Cheese B12* With out Cheese C11* Namkin C12* Sweet D11 Small Toy
D12* Large Toy E12* Small Bag E13* Large Bag F12* Art F13* Science A112 Foremore A122 Dairyland B122 Foremore B123 Dairyland C112 Parale C122 Britannia D112 Casco D122 Child Like E123 Hp E134 VIP F123 Bio F133 Chemistry

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
725
Supposed that If D > M after that divided D into
small partitions such that both partition can be handled in
the main memory. Allow the partitions of the database be
D1, D2… Dn. Since each partition can fit in the main
memory; at this time will be no additional disk I/O for
each partition after loading the partition into the main
memory [17]. Later than all small databases are processed;
the Tree Map will be generated and written to disk in
position to depart gap for processing the next frequent
itemsets and so on.
Step-4:
Once partition we transform the both partitions of
transaction data sets into Boolean numbers that means 0
and 1 form. At this time 0 represent the absence of itemset
and 1 represent present of itemset. After that we count the
appearance of itemset in the total transaction dataset and
evaluate predefine minimum support and define key value.
We start our algorithm at first level.
Level-1 Min_support = 40% Frequent 1-itemsets
Table 2 [A]: Filtered Transaction Table
Keys Value
A*** 10%
B*** 50%
C*** 70%
D*** 80%
All itemsets key values are supported minimum support, so
all items makes 2-itemset.
Frequent 2-itemsets
Perform conjunction proposition to generate 2-
itemsets. The conjunction proposition is defined as
follows:
T- T = T, T- F = F, F – F = F, F- T = F
Note that here we assume T = 1 and F = 0

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
726
Table 3 [A]: Filtered Transaction Table
Keys Value
A*** ∧ B*** 50%
A*** ∧ C*** 60%
A*** ∧ D*** 50%
A*** ∧ E*** 50%
A*** ∧ F*** 60%
B*** ∧ C*** 40%
B*** ∧ D*** 20%
B*** ∧ E*** 10%
B*** ∧ F*** 30%
C*** ∧ D*** 40%
C*** ∧ E*** 30%
C*** ∧ F*** 40%
D*** ∧ E*** 50%
D*** ∧ F*** 50%
E*** ∧ F*** 60%
Here B*** ∧ D***, B*** ∧ E***, B*** ∧ F*** and C***
∧ E*** itemsets are not considered for making 3-itemsets.
Frequent 3-itemsets
Table 4 [A]: Filtered Transaction Table
Keys Value
A*** ∧ B*** ∧ C*** 40%
A*** ∧ C***∧ D*** 30%
A*** ∧ C***∧ F*** 30%
A*** ∧ D***∧ E*** 30%
A***∧ D***∧ F*** 20%
A*** ∧ E***∧ F*** 40%
D*** ∧ E***∧ F*** 40%
Now A*** ∧ B*** ∧ C***, A*** ∧ E***∧ F*** and
D*** ∧ E***∧ F*** considered for next levels.

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
727
Level-2 Min_support = 35% Frequent 1-itemsets Tid Keys
A1** B1** C1** D1** E1** F1**
T1 1 1 1 0 0 0
T2 1 1 1 1 0 0
T3 1 0 1 1 1 0
T4 1 1 0 1 1 1
T5 1 1 1 0 0 1
T6 0 0 1 1 1 1
T7 0 0 0 1 1 1
T8 1 1 1 0 0 1
T9 1 0 0 0 1 1
T10 0 0 0 1 0 1
T11 1 0 0 1 0 0
T12 1 0 0 0 1 1
T13 1 0 1 1 1 1
Table 5 [a]: Filtered Transaction Table
Keys Value
A1** 95% B1** 50% C1** 70% D1** 80% E1** 70% F1** 90%
Frequent 2-itemsets
Table 5 [B]: Filtered Transaction Table
Keys Value
A1** ∧ B1** 50%
A1** ∧ C1** 60%
A1** ∧ D1** 50%
A1** ∧ E1** 50%
A1** ∧ F1** 60%
B1** ∧ C1** 40%
C1** ∧ D1** 40%
C1** ∧ F1** 40%
D1** ∧ E1** 50%
D1** ∧ F1** 50%
E1** ∧ F1** 60%
All item making 3-itemsets.

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
728
Table-6
A1** ∧ B1** ∧
C1**
A1** ∧
E1**∧ F1**
D1** ∧ E1**∧
F1**
T1 1 0 0
T2 1 0 0
T3 0 0 0
T4 0 1 1
T5 1 0 0
T6 0 0 1
T7 0 0 1
T8 1 0 0
T9 0 1 0
T10 0 0 0
T11 0 0 0
T12 0 1 0
T13 0 1 1
Table 6 [B]: Filtered Transaction Table
Keys Value
A1** ∧ B1** ∧ C1** 40%
A1** ∧ E1**∧ F1** 40%
D1** ∧ E1**∧ F1** 40%
So following itemset are considered for next levels A1** ∧
B1** ∧ C1**, A1** ∧ E1**∧ F1** and D1** ∧ E1**∧ F1**.
Level-3 Min_support = 30% Frequent 1-itemsets
Table 7 [B]: Filtered Transaction Table
Keys Value A11* 40%
A12* 60% B11* 40% B12* 10% C11* 30% C12* 40% D11* 40% D12* 40% E12* 40% E13* 30% F12* 30% F13* 70%
Frequent 2-itemsets

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
729

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
730
Table 8 [D]: Filtered Transaction Table
Keys Value
A11* ∧ C12* 30%
A11* ∧ D11* 30%
A12* ∧ F12* 40%
D12* ∧ E12*, 40%
D12* ∧ F12** 40%
E12* ∧ F12* 30%
Now A11* ∧ C12*, A11* ∧ D11*, A12* ∧ F12*,
D12* ∧ E12*, D12* ∧ F12* and E12* ∧ F12* Itemsets are frequent, so considered are making 3-itemsets.
Table 9 [A]
A11* ∧ C12* ∧
D11*
D12* ∧ E12*∧ F12*
T1 0 0
T2 1 0
T3 1 0
T4 0 1
T5 0 0
T6 0 1
T7 0 1
T8 0 0
T9 0 0
T10 0 0
T11 0 0
T12 0 0
T13 0 0
Table 9 [B]: Filtered Transaction Table
Keys Value
A11* ∧ C12* ∧ D11* 20%
D12* ∧ E12*∧ F12* 30%
Here only D12, E12, F12 itemsets considered for next level.
Level - 4 Min_support = 20% Frequent 1-itemsets

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
731
Table 10[A] Tid Keys
D122 E123 F123
T1 0 0 0
T2 0 0 0
T3 0 1 0
T4 1 1 1
T5 0 0 0
T6 0 1 1
T7 1 1 1
T8 0 0 1
T9 0 0 1
T10 1 0 1
T11 0 0 0
T12 0 0 1
T13 0 0 0
Table 10[B]: Filtered Transaction Table
Keys Value D122 50% E123 60% F123 50%
The algorithm is terminated because there are maximum frequent itemsets find at lower level (level 4).
5. CONCLUSION
In this paper, we have employed partition and boolean concepts, multiple level taxonomy and different minimum supports to find association rules in a given transaction data set. The models works well with problems involving uncertainty in data relationships, which are represented by boolean concepts. The proposed algorithm can thus generate large itemsets level by level and then derive association rules from transaction dataset. The results shown in the example implies that the proposed algorithm can derive the multiple-level association rules under different supports in a simple and effective way. Also in this paper we examine method of partitioning to limit the total memory requirement, including that required both for the source data and for the candidate sets. Also we
present boolean And operator method to each class that contains itemsets and to the class that contains itemsets which have different support and by the way we reduce the generation of useless candidates. In short, proposed algorithm is efficient and highly scalable for mining very large databases.
REFERENCES
[1] Han, Y. Fu, “Mining Multiple-Level Association Rules in Large Databases,” IEEE TKDE. vol.1, pp. 798-805, 1999.
[2] N.Rajkumar, M.R.Karthik, S.N.Sivana, S.N. Sivanandamndam,"Fast Algorithm for Mining Multilevel Association Rules," IEEE, Vol-2, pp . 688-692, 2003.
[3] R.S Thakur, R.C. Jain, K.R.Pardasani, Fast Algorithm for Mining Multilevel Association Rule Mining," Journal of Computer Science, Vol-1, pp no: 76-81, 2007.
[4] R. Agrawal, T. Imielinski, and A. Swami, "Mining association rules between sets of items in large databases," In Proceeding ACM SIGMOD Conference, pp. 207-216, 1993.
[5] Scott Fortin,Ling Liu,"An object-oriented approach to multi-level association rule mining," Proceedings of the fifth international conference on Information and knowledge management,pp.65-72, 1996.
[6] R. Agrawal and R. Srikant. "Fast algorithms for mining association rules," In Proceedings of the 20th VLDB Conference, pp. 487-499, 1999.
[7] Roberto Bayardo, “Efficiently mining long patterns from databases”, in ACM SIGMOD Conference 1998.
[8] R. Agarwal, C. Aggarwal and V. Prasad, “A tree projection algorithm for generation of frequent itemsets”, Journal of Parallel and Distributed Computing, 2001.
[9] K. Gouda and M.J.Zaki, “Efficiently Mining Maximal Frequent Itemsets”, in Proc. of the IEEE Int. Conference on Data Mining, San Jose, 2001.
[10] R. Agrawal, T. Imielienski and A. Swami, “Mining association rules between sets of items in large databases,” In P. Bunemann and S. Jajodia, editors, Proceedings of the 1993 ACM SIGMOD Conference on Management of Data, Pages 207-216, Newyork, 1993, ACM Press.
[11] Predrag Stanišić, Savo Tomović, "Apriori Multiple Algorithm for Mining Association Rules", Information Technology and Control, vol.37, pp.311-320, 2008.

VOL. 2, NO. 12, December 2011 ISSN 2079-8407 Journal of Emerging Trends in Computing and Information Sciences
©2009-2011 CIS Journal. All rights reserved.
http://www.cisjournal.org
732
[12] J. Han, M. Kamber, "Data Mining: Concepts and Techniques," The Morgan Kaufmann Series, 2001.
[13] Hunbing Liu and Baishen wang, “An association Rule Mining Algorithm Based On a Boolean Matrix,” Data Science Journal, Vol-6, Supplement 9, S559-563, September 2007.
[14] Pratima Gautam, K. R. Pardasani, “A Fast Algorithm for Mining Multilevel Association Rule Based on Boolean Matrix,” International Journal on Computer Science and Engineering, Vol. 02, No. 03, pp. 746-752, 2010.
[15]Yin –Bo Wan, Yong Liang and Li-Ya Ding (2008). “Mining Multilevel Association rules with dynamic concept hierarchy,” IEEE, Vol-1, pp. 287-292. [16] M.H.Margahny , A.A.Mitwaly, “Fast Algorithm for Mining Association Rules” In proc.International Conference on Artificial Intelligence and Machine Learning AIML05(ICGST), pp. 36-40, 2005.
[17] M.H.Margahny, A.A.Shakour, “Scalable Algorithm for Mining Association Rules,” AIML Journal, Vol- 6, Issue 3, pp. 55-60, 2006.
[18] A Raghunathan, K Murugesan, “Optimized Frequent Pattern Mining for Classified Data Sets,” International Journal of Computer Applications, vol- 1, pp. 25-39, 2010.
[19] Shakil Ahmed, Frans Coenen, Paul Leng, “A Tree Partitioning Method for Memory Management in Association Rule Mining,” Lecture Notes in Computer Science, Vol-3181,pp.331-340, 2004.
[20] S.Prakash, R.M.S.Parvathi, “An Enhanced Scaling Apriori for Association Rule Mining Efficiency,” European Journal of Scientific Research, Vol.39, pp.257-264, 2010.
[21] B. Liu, W. Hsu, and Y. Ma, “Mining association rules with multiple minimum supports,” Proceedings of the Fifth ACM SIGKDD International Conference Knowledge Discovery and Data Mining, pp.125-134, 1999. [22] Pratima Gautam and Dr. K. R. Pardasani,” A Fast Algorithm for Multilevel Association Rule Using Hash based Method”, CiiT International Journal of Data Mining Knowledge Engineering, 2010.