jens graupmann ralf schenkel gerhard weikum the spheresearch engine for unified ranked retrieval of...
Post on 21-Dec-2015
215 views
TRANSCRIPT

Jens Graupmann Ralf Schenkel Gerhard Weikum
The SphereSearch Engine for Unified Ranked Retrieval of Heterogeneous XML and Web Documents

Problem
2/38
Web
Intranet
Databases
EnterpriseInformation
Systems
…
Search for… The inventor of the world wide web Gothic and romantic churches that are located in the same place Movies with an actor who is the governor of California

Arising Questions
• What do we know about the structure of the data?• Why do we care what is the structure of the data?
• Can we “structure” data? How?
• Does John Doe also works in Apple?
• How do we interpret links?3/38
<worker> <name> Roy Smith</name> <company>Apple</company></worker>
Roy Smith works in Apple
<person> Roy Smith</person> works in <company>Apple</company>
//worker[company=“Apple”]/name
XPath Query:
<company>Apple</company> employs <person> John Doe</person>

4/38
What are the publications of Max Planck?
Example query #1
Max Planck should be instance of concept person, not of concept institute
Concept Awareness

5/38
Example query #2
Conferences about XML in Norway 2005?
Context Awareness
Information is not present on a single page, but distributed across linked pages
VLDB Conference 2005, Trondheim, Norway
Call for Papers…XML…

6/38
Example query #3Which professors from the Technion do research on Theory of computer science
Different terminology in query and Web pagesAbstraction Awareness
Dr. Amir Shpilka…senior lecturer…

7/38
SphereSearch Concepts
• Unified search for unstructured, semistructured, structured data from heterogeneous sources
• Graph-based model, including links• Annotation engines from NLP to recognize classes
of named entities (persons, locations, dates, …) for concept-aware queries
• Flexible yet simple abstraction-aware query language with context-aware scoring
• Compactness-based scores
Goal: Increase recall & precision for hard queries on linked and heterogeneous data

8/38
Outline
• Challanges in search engines
• SphereSearch Concepts
• Transformation and Annotation
• Query Language and Scoring
• Experimental Evaluation
• Current and Future Work

9/38
Unifying Search on Heterogeneous Data
Web
Intranet
Databases
EnterpriseInformation
Systems
…
XML
Heuristics, type-spec transformations

10/38
Heuristic Transformation of HTML
• Headlines<h1>Experiments</h1><h2>Settings</h2>We evaluated...<h2>Results</h2>Our system...
Goal: Transform layout tagsto semantic annotations
<Experiments><Settings>...</Settings><Results>...</Results>
</Experiments>
• Patterns<b>Topic:</b>XML <Topic>XML</Topic>
• Rules for tables, lists, …

11/38
Basic Data Model<Professor> Gerhard Weikum <Course> IR </Course> Saarbrücken <Research> XML </Research></Professor>
1
docid=1tag=“Professor“content=“Gerhard Weikum Saarbrücken“
32
docid=1tag=“Research“content=“XML“
docid=1tag=“Course“content=“IR“
Automatic annotation of important concepts (persons, locations, dates,
money amounts) with tools from Information Extraction
Tags annotate content with corresponding concept
person
location

12/38
Information Extraction (IE)
The Pelican Hotel in Salvador, operated byRoberto Cardoso, offers comfortable rooms starting at$100 a night, including breakfast. Please check in before 7pm.
The <company> Pelican Hotel </company> in<location> Salvador </location>, operated by<person> Roberto Cardoso </person>, offerscomfortable rooms starting at<price> $100 </price> a night, includingbreakfast. Please check in before <time> 7pm </time>.
• Named Entity Recognition• Based on part-of-speech tagging and large dictionary
containing names of cities, countries, common person names etc.
• Mature (out-of-the-box products, e.g. GATE/ANNIE)• Extensible

13/38
Annotation-Aware Data Model<Professor> Gerhard Weikum <Course>IR</Course> Saarbrücken <Research>XML</Research></Professor>
1docid=1tag=“Professor“content=“Gerhard Weikum Saarbrücken“
32docid=1tag=“Research“content=“XML“
docid=1tag=“Course“content=“IR“
2
1
docid=1tag=„Professor“content=“Gerhard Weikum“
3
docid=1tag=“Research“content=“XML“
docid=1tag=“Course“content=“IR“
4
docid=1tag=“location“content=“Saarbrücken“
Annotation with GATE:„Saarbrücken“ of type „location“
Annotation introduces new tags

14/38
Unifying Search on Heterogeneous Data
Web
Intranet
Databases
EnterpriseInformation
Systems
…
XML
Heuristics, type-spec transformations
AnnotatedXML
Annotation of named entitieswith IE tools (e.g., GATE)

15/38
Outline
• Challanges in search engines
• SphereSearch Concepts
• Transformation and Annotation
• Query Language and Scoring
• Experimental Evaluation
• Current and Future Work

16/38
Data Model• Given a collection of XML documents and links, we define
the element-level graph V is the union of the elements of all documents E contains all parent child edges and links Attributes are considered as if they were elements
• G is undirected for it is easier to phrase queries without thinking about the direction of the edges
• For each element , denotes to the tag name and its content
• Each edge is assigned a nonnegative weight which is 1 for parent-child edge and for links
• takes two elements as input and computes the weight of the shortest path in G between them
e V ( )name e( )content e
,x y
,G V E

17/38
SphereSearch Queries
Extended keyword queries:• similarity conditions ~professor, ~Information retrieval
• concept-based conditions person=Max Planck, location=Paris
• grouping
• join conditions
Ranked results with context-aware scoring

SphereSearch Queries: Examples
R(professor, location=~Jordan)C(course, ~database)R(~seminar, ~XML)
A(gothic, church)B(romantic, church)A.location=B.location
• Supports traditional keyword search18/38
Query group
For each query group, a disjunction of basic conditions
concept(tag)
value(content)
Join condition

Formal Query Language
• A SphereSearch query consists of a set of query groups and a set of join conditions (possibly empty)
• Each consists of (keywords conditions) and (concept value conditions)
• A join has the form for exact match join and for similarity join( are query groups and are tag names)
A result for Query is a list of g-tuples of elements sorted by score
19/38
,S Q J 1, , gQ G G
1, , mJ J J
iG 1 i
i ikt t
1 1 i i
i i i il lc v c v
. .i jG v G w. ~ .i jG v G w
,i jG G ,v w
1 ge eS

20/38
Local Node Score
Query: Course ~XML location=Max Planck
• We compute a node score for each node based on (tf/idf, Okapi BM25 scoring model…) adapted for XML
• How can we use such measure in order to score ~XML or location=Max Planck ?
( , )ns n t

21/38
Similarity Conditions
wizard
intellectual
artist
alchemist
directorprimadonna
lecturer
professor
teacher
educator
scholar
academic,academician,faculty member
scientist
researcher
HYPONYM (0.7)HYPONYM (0.7)
Thesaurus/Ontology:concepts, relationships, glossesfrom WordNet, Gazetteers, Web forms & tables, Wikipedia
relationships quantified bystatistical co-occurence measures
investigator
mentor
Similarity conditions like~professor, ~XML
For ~K similarity we first compute exp(K); a set of all terms similar to K using the ontology
Local score: weighted max over all expansion terms:
Example: δ-exp(K)={w|sim(K,w)>δ}
Abstraction awareness
exp( )
( ,~ )
max , ( , )x K
ns n K
sim K x ns n x

22/38
Concept-based conditions
Concept awareness
Goal: Exploit explicit (tags) and automatic annotations in documents
location=Jordan
concept value n
docid=1tag=„location“content=“Jordan“
concept-specific distance measure like 1970<date<1980
0 ( )( , )
( , )
name n cns n c v
ns n v otherwise
( , ~ ) ( ( ), ) ( , )ns n c v sim name n c ns n v

Spheres
• Most existing retrieval systems consider only the contentcontent of an element itself to asses its relevance for a query
• In SphereSearchSphereSearch this type of score is provided by the Node Score (ns)
• Local score may not be sufficient– In the presence of links– When content is spread over several
elements
23/38

24/38
Score Aggregation: SphereScore
Weighted aggregation of local scores in environment of element (sphere score):
2
1
1
2
0 ':( , ')
( , ) ( ', ), 0 1D
d
d ndist n n d
s n t ns n t
s(1):
research XMLLocal score for each element e (tf/idf, BM25,…)
Context awareness

25/38
Query Groups
SphereScore computed for each group
Group conditions that relate to the same „entity“ professor teaching IR research XML
professor T(teaching IR) R(research XML)
Find compact sets with one result for each group
Goal: Related terms should occur in the same context
1 1
( ) ( , ) , ,i ik l
i ii i j j j
j j
s n s n G s n t s n c v

26/38
Scores for Query Resultsquery result R: one result per query group
( ) ( ) (1 ) ( )i
i ie R
score R s e compactness R
A
X
B
2
1
compactness ~ 1/size of a minimal spanning tree
A
1
X3
11
1( )
3C N
2
A
2
X3
4
B
1
X5
3
B
2
X5
6
1
1
2
21
( )4
C N
31
( )5
C N
41
( )6
C N
Context awareness
27
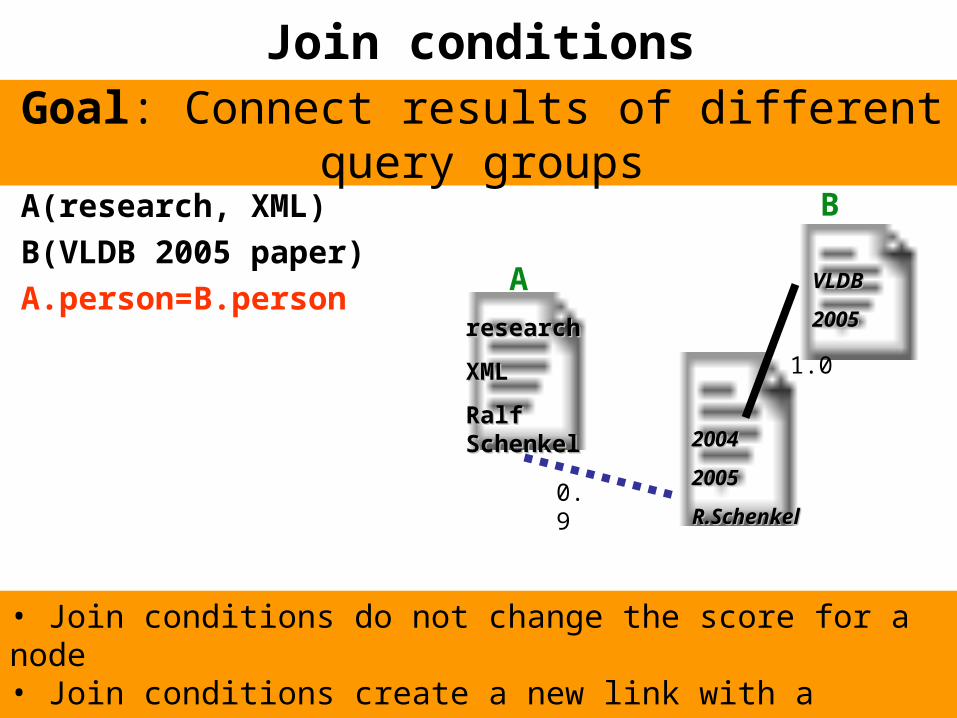
Join conditions
Goal: Connect results of different query groups
A(research, XML)
B(VLDB 2005 paper)
A.person=B.personresearchresearch
XMLXML
Ralf Ralf SchenkelSchenkel 20042004
20052005
R.SchenkelR.Schenkel
VLDBVLDB
20052005
1.0
0.9
• Join conditions do not change the score for a node• Join conditions create a new link with a specific weight
A
B

28/38
Score for Join Conditions
Join condition A.T=B.S:
• For all nodes n1 with type T, n2 with type S, add edge (n1,n2) with weight sim(n1,n2))-1
• sim(n1,n2): content-based similarity
A
X
B
2
1
B
2
X2
3 14
1( )
3C N

Architecture
29/38
Crawler
Ontology Service
Client GUI
Transformer
Annotator Indexer
Query Processor
Index

30/38
Outline
• Challanges in search engines
• SphereSearch Concepts
• Transformation and Annotation
• Query Language and Scoring
• Experimental Evaluation
• Current and Future Work

31/38
Setup for Experiments
Three corpora:• Wikipedia• extended Wikipedia with links to IMDB• extended DBLP corpus with links to homepages
50 Queries like• A(actor birthday 1970<date<1980) western• G(California,governor) M(movie)• A(Madonna,husband) B(director)
A.person=B.director
Opponent: keyword queries with standard TF/IDF-based score „simplified Google“
No existing benchmark (INEX, TREC, …) fits

32/38
SSE-Join(join conditions)
SSE-QG(query groups)
SSE-CV(concept-based conditions)
Incremental Language Levels
SSE-basic(keywords, SphereScores)

33/38
Experimental Results on Wikipdia

34/38
Experimental Results on Wiki++ and DBLP++
• SphereScores better than local scores
• New SSE features improve precision

Qualitative query examples
• Concept-Value: (American, politician, rice) (person=rice, politician)
? (1970<date<1980, actor)
• Query groups:
(California, governor, movie) G(California, governor) M(movie)
• Joins: A(Madonna, husband) B(director) A.person=B.director
35/38
precision@10: 0.60
precision@10: 0.40
precision@10: 0.4
Elements pair: (1) movie directed by Guy Ritchie (2) information that Guy Ritchie is Madonna’s husband

36/38
Conclusion• We introduced SphereSearch for unified ranked retrieval
of heterogenous data– Transformation of heterogenous data into unified format
– Annotation of latent concepts
– Incorporate concept, context and abstraction features
• Query language that is– More expresive then traditional keyword search
– Simpler then full-fledged XML query language / SPARQL
• The Spheres idea seems to be benificial
• Preliminary experiments show improvement in certain queries

37/38
Future Work
• Further Experimentation is needed
• Integration with Semantic-Web– Usage of existing tools (such as SPARQL)
– Ontology based inheritance aware search
– Standartization of annotated tags
– Easier integration with existing RDF data
• More Efficient query evaluation
• Better Similarity measure
• Parameter tuning with relevance feedback
• Deep Web search through automatic queries

38/38
Thank you!