introduction to rbm for written digits recognition
TRANSCRIPT
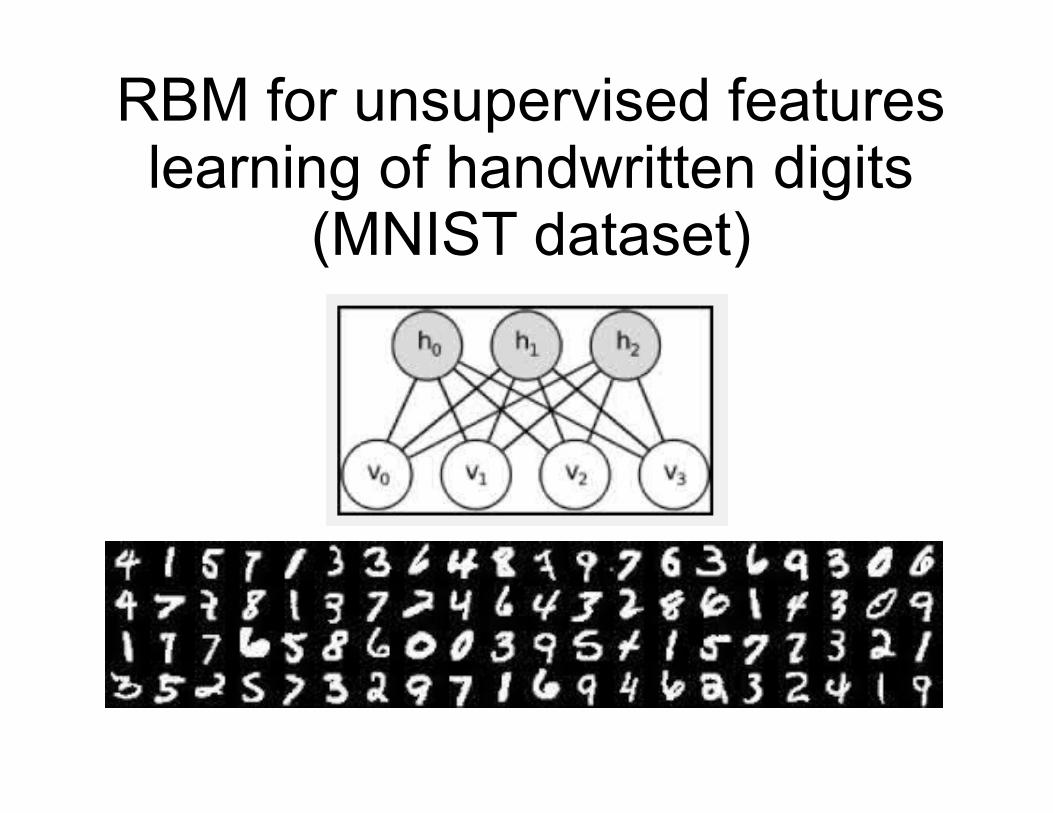
RBM for unsupervised features learning of handwritten digits
(MNIST dataset)
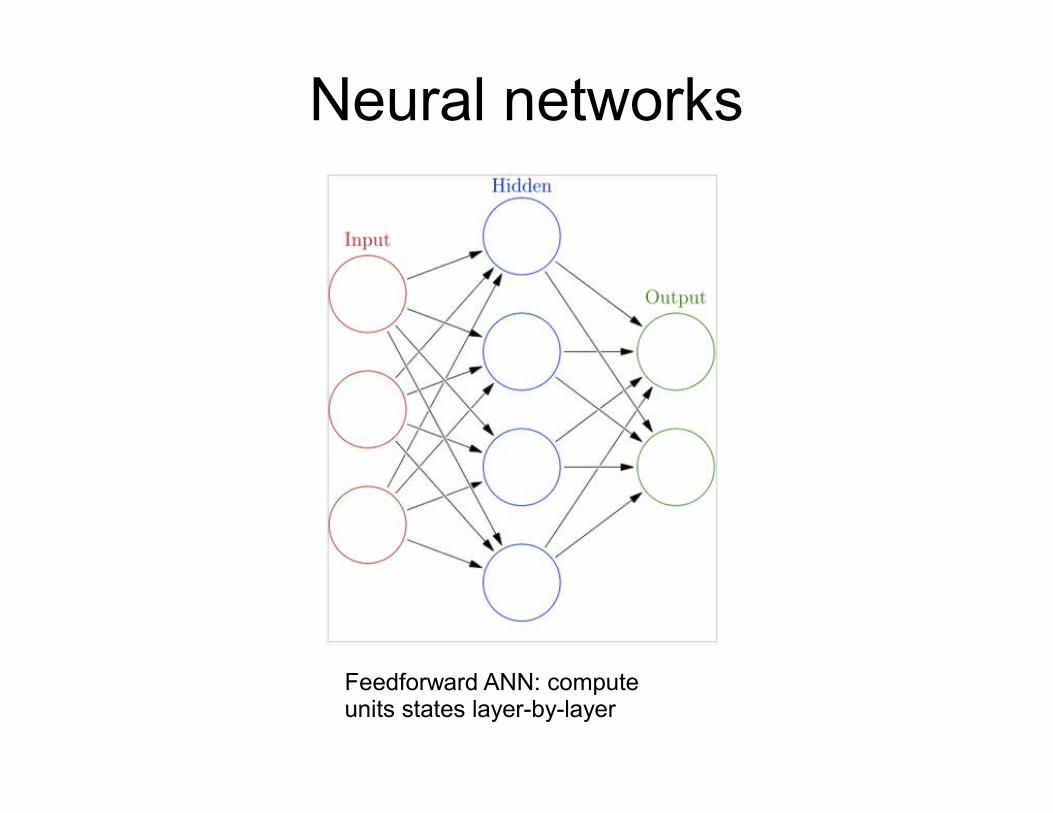
Neural networks
Feedforward ANN: compute units states layer-by-layer
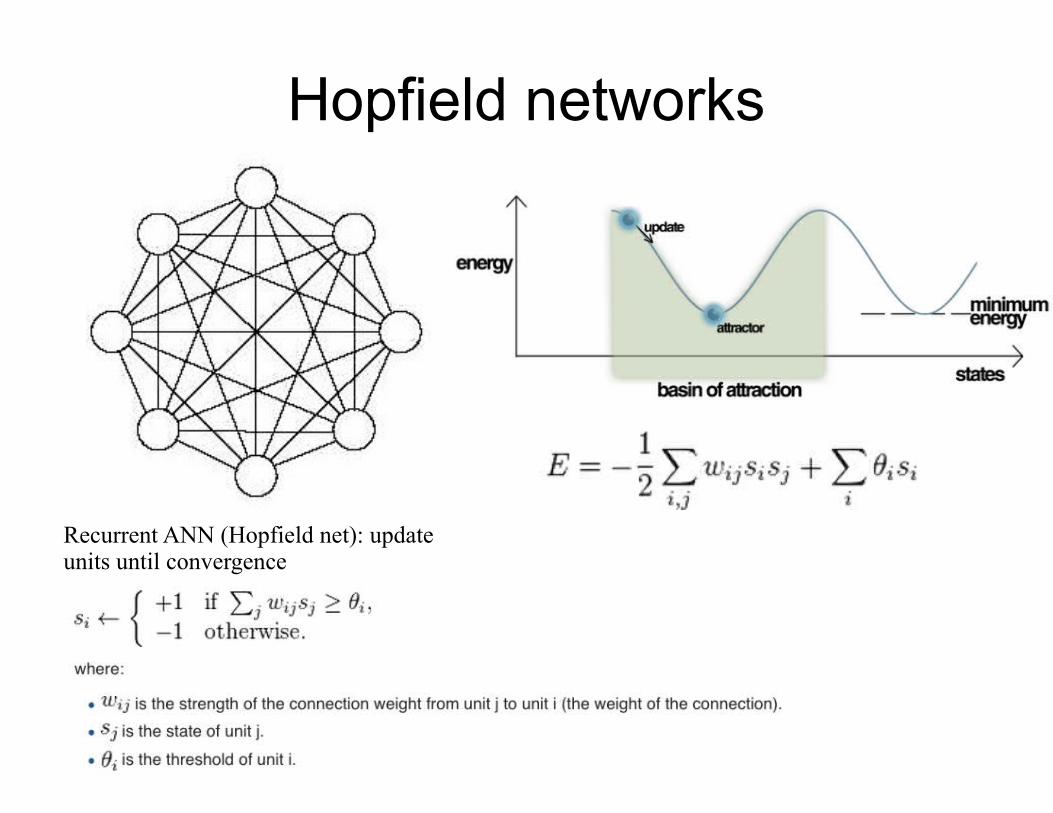
Hopfield networks
Recurrent ANN (Hopfield net): update units until convergence
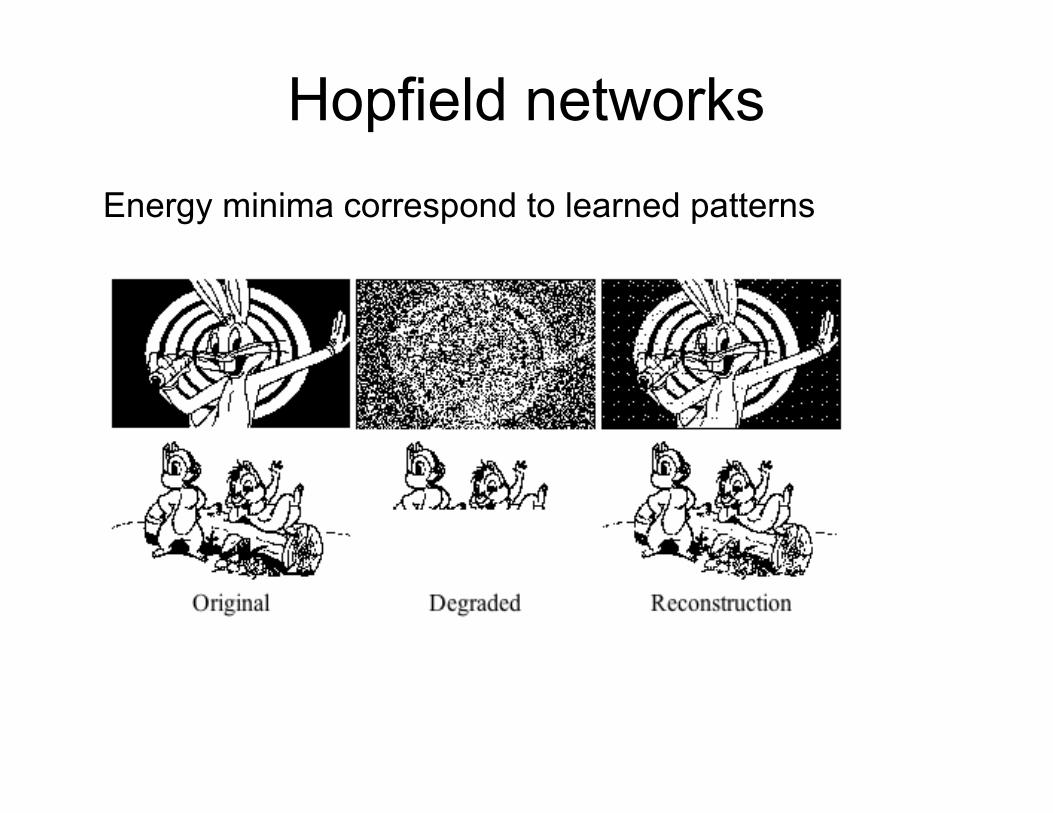
Hopfield networks
Energy minima correspond to learned patterns

Bolzmann machine
Stochastic neural network,Has probability distribution defined:
Low energy states have higher probability
“Partition function”: normalization constant
(Boltzmann distribution is a probability distributionof particles in a system over various possible states)
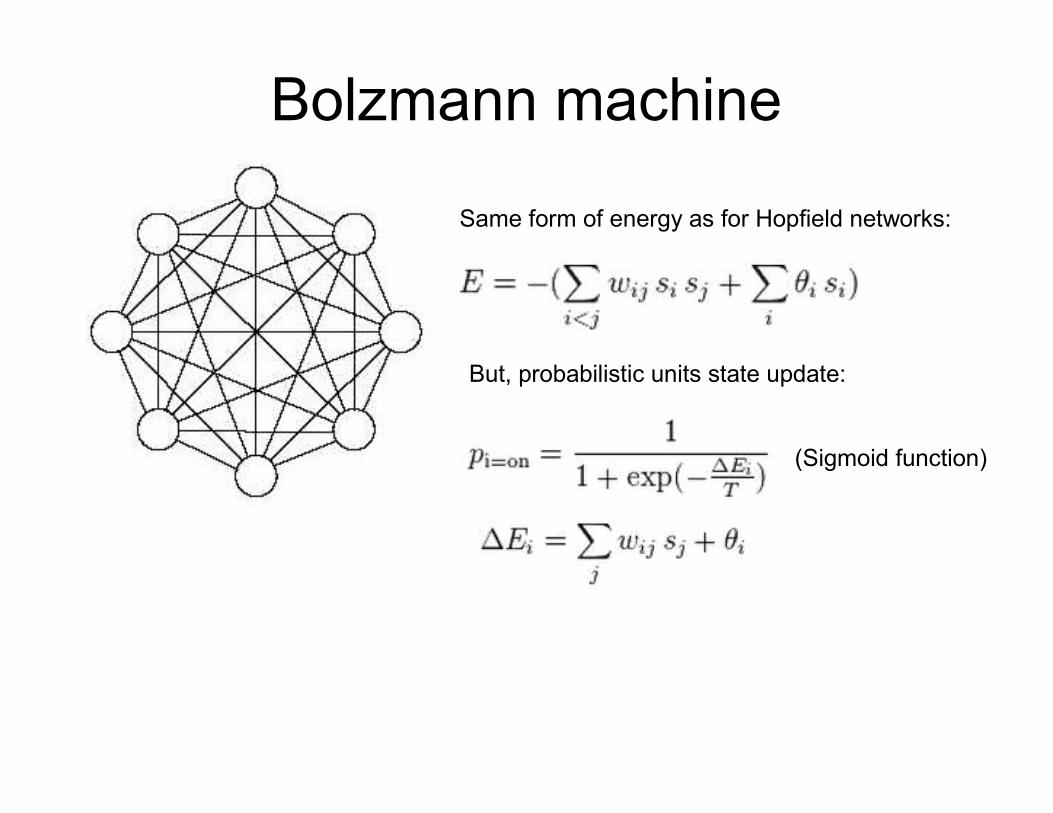
Bolzmann machine
Same form of energy as for Hopfield networks:
But, probabilistic units state update:
(Sigmoid function)
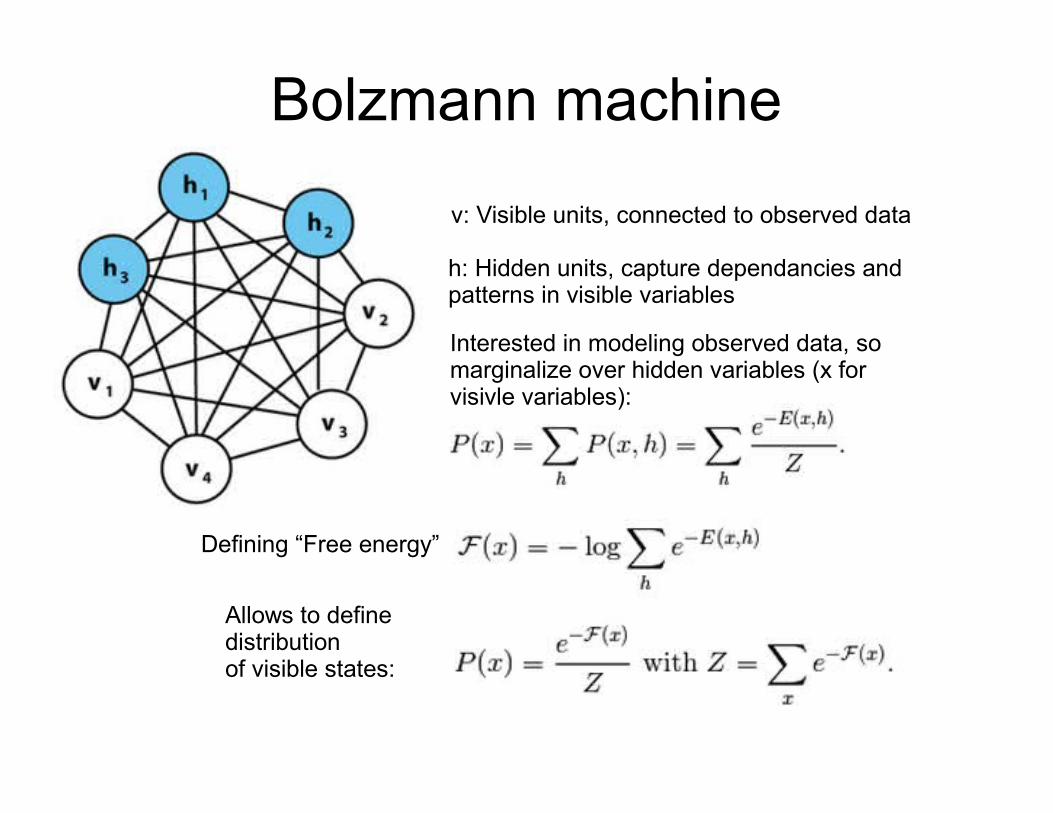
Bolzmann machine
v: Visible units, connected to observed data
h: Hidden units, capture dependancies and patterns in visible variables
Interested in modeling observed data, so marginalize over hidden variables (x for visivle variables):
Defining “Free energy”
Allows to definedistributionof visible states:

Bolzmann machineLog-likelihood given a training sample (v):
Gradient with respect to model parameters:
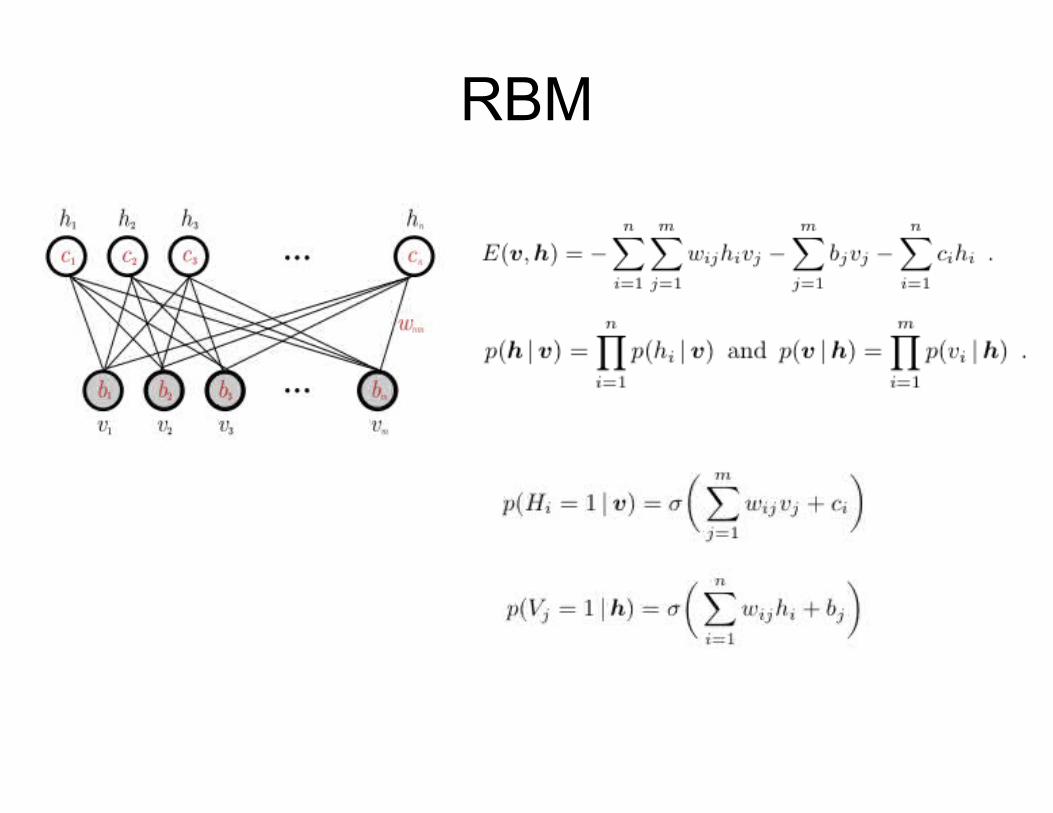
RBM
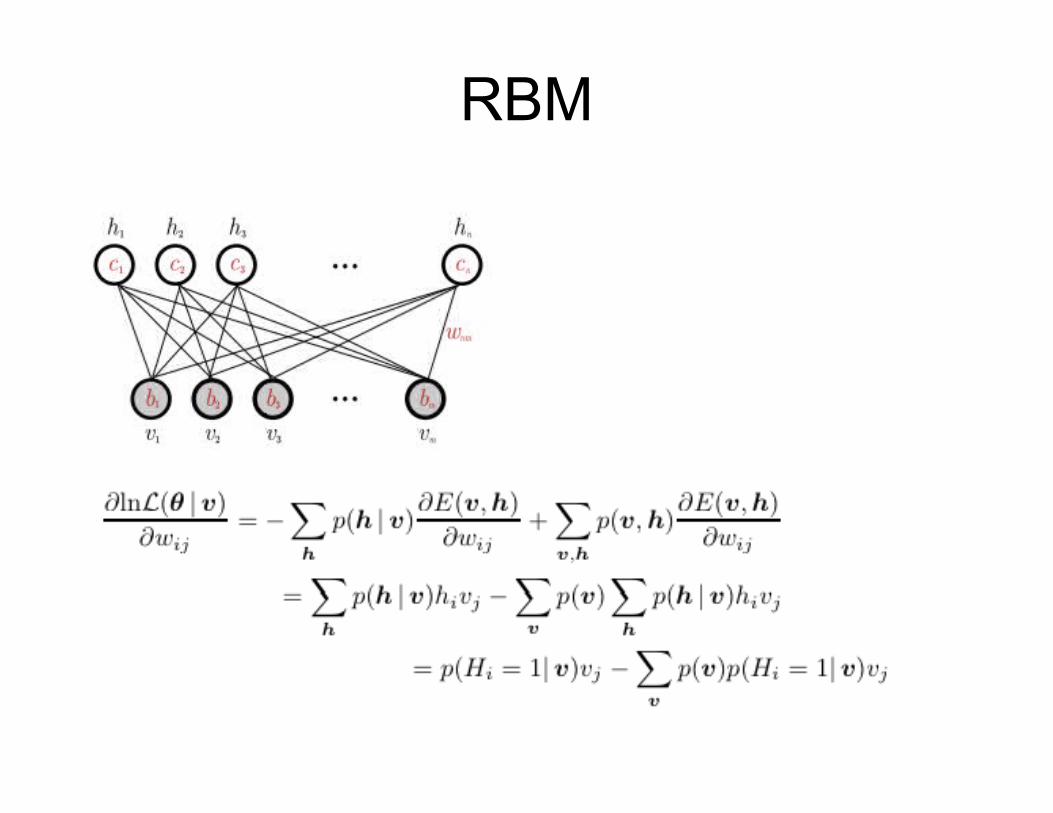
RBM
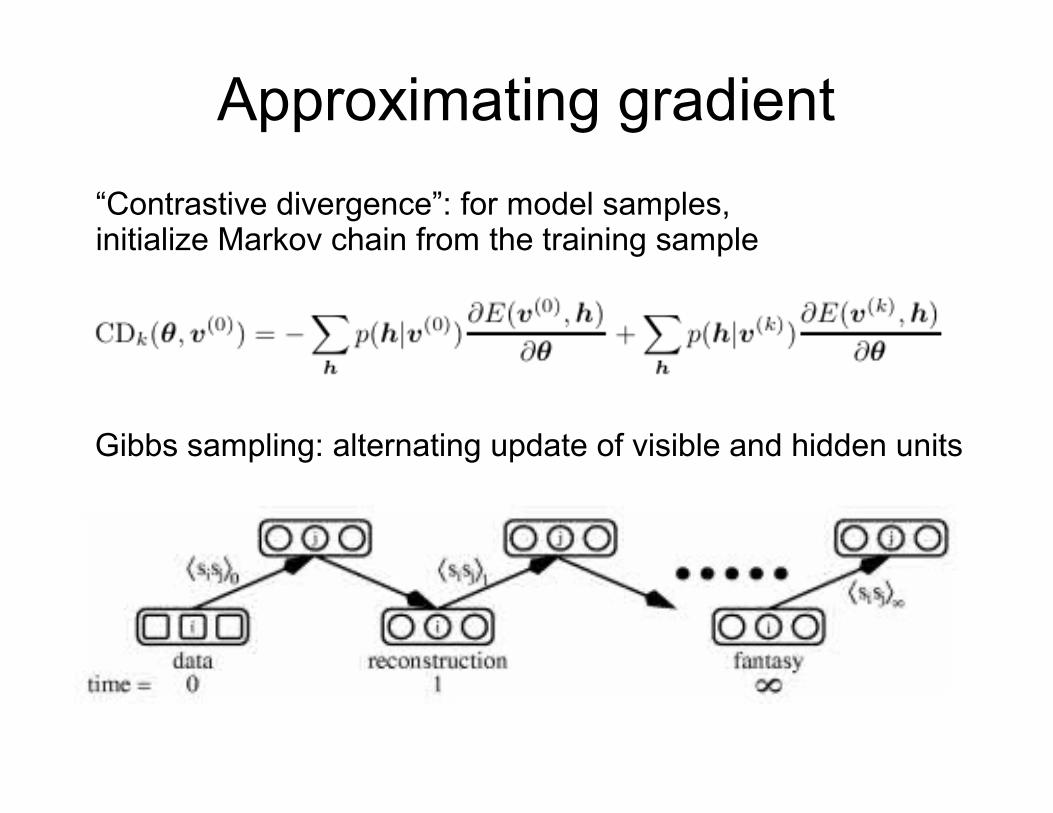
Approximating gradient
“Contrastive divergence”: for model samples,initialize Markov chain from the training sample
Gibbs sampling: alternating update of visible and hidden units

Contrastive divergence

Persistent Contrastive Divergence
Run several sampling chains in parallel
...
For example, one for each training sample
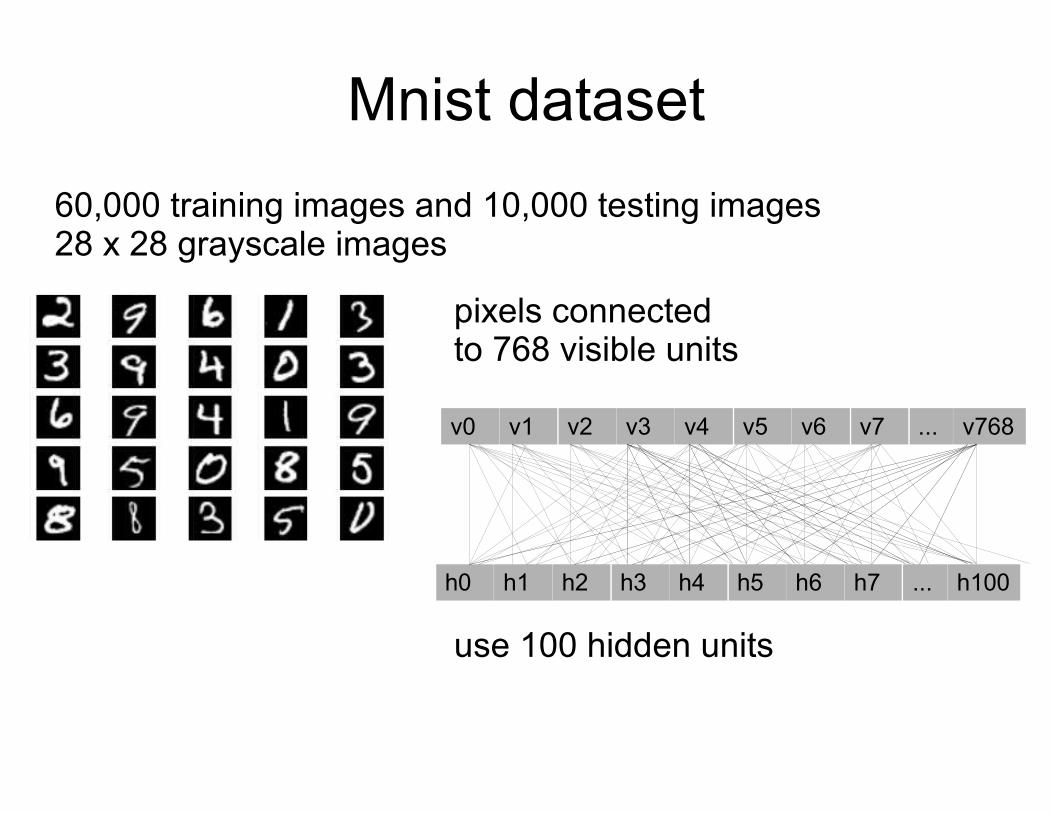
Mnist dataset
60,000 training images and 10,000 testing images28 x 28 grayscale images
pixels connectedto 768 visible units
v0 v1 v2 v3 v4 v5 v6 v7 ... v768
h0 h1 h2 h3 h4 h5 h6 h7 ... h100
use 100 hidden units
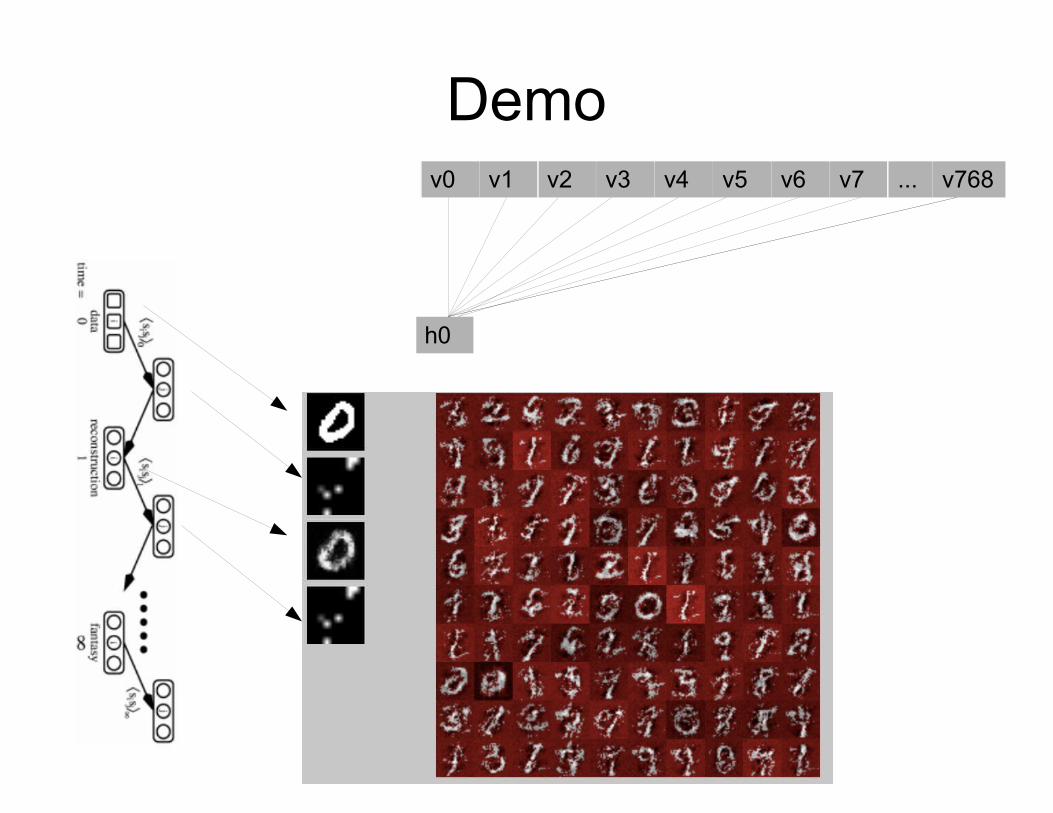
Demov0 v1 v2 v3 v4 v5 v6 v7 ... v768
h0

Training code // (positive phase) // compute hidden nodes activations and probabilities for (int i = 0; i < n_hidden; i++) { h_prob[i] = 0.0f; for (int j = 0; j < n_visible; j++) { h_prob[i] += c[i] + v_data[j] * W[j * n_hidden + i]; } h_prob[i] = sigmoid(h_prob[i]); h[i] = ofRandom(1.0f) > h_prob[i] ? 0.0f : 1.0f; } for (int i = 0; i < n_visible * n_hidden; i++) { pos_weights[i] = v_data[i / n_hidden] * h_prob[i % n_hidden]; }
// (negative phase) // sample visible nodes for (int i = 0; i < n_visible; i++) { v_negative_prob[i] = 0.0f; for (int j = 0; j < n_hidden; j++) { v_negative_prob[i] += b[i] + h[j] * W[i * n_hidden + j]; } v_negative_prob[i] = sigmoid(v_negative_prob[i]); v_negative[i] = ofRandom(1.0f) > v_negative_prob[i] ? 0.0f : 1.0f; }

Training code
// and hidden nodes once again for (int i = 0; i < n_hidden; i++) { h_negative_prob[i] = 0.0f; for (int j = 0; j < n_visible; j++) { h_negative_prob[i] += c[i] + v_negative[j] * W[j * n_hidden + i]; } h_negative_prob[i] = sigmoid(h_negative_prob[i]); h_negative[i] = ofRandom(1.0f) > h_negative_prob[i] ? 0.0f : 1.0f; } for (int i = 0; i < n_visible * n_hidden; i++) { neg_weights[i] = v_negative[i / n_hidden] * h_negative_prob[i % n_hidden]; }
// update weights for (int i = 0; i < n_visible * n_hidden; i++) { W[i] += learning_rate * (pos_weights[i] - neg_weights[i]); }

Training
● Matrix multiplication● Mini-batch training● Regularization● Weights update momentum

Training code // (positive phase) clear(h_data_prob, n_hidden * batch_size); multiply(v_data, W, h_data_prob, batch_size, n_visible, n_hidden); getState(h_data_prob, h_data, n_hidden * batch_size);
transpose(v_data, vt, batch_size, n_visible); multiply(vt, h_data, pos_weights, n_visible, batch_size, n_hidden);
for (int cdk = 0; cdk < k; cdk++) {
// run update for CD1 or persistent chain for PCD clear(v_prob, n_visible * batch_size); transpose(W, Wt, n_visible, n_hidden); multiply(h, Wt, v_prob, batch_size, n_hidden, n_visible); getState(v_prob, v, n_visible * batch_size);
// and hidden nodes clear(h_prob, n_hidden * batch_size); multiply(v, W, h_prob, batch_size, n_visible, n_hidden); getState(h_prob, h, n_hidden * batch_size); }

Training code for (int i = 0; i < n_visible * n_hidden; i++) { W_inc[i] *= momentum; W_inc[i] += learning_rate * (pos_weights[i] - neg_weights[i]) / (float) batch_size - weightcost * W[i]; W[i] += W_inc[i]; }

Sparseness & Selectivity

Sparseness & Selectivity
// increasing selectivity float activity_smoothing = 0.99f; float total_active = 0.0f; for (int i = 0; i < n_hidden; i++) { float activity = pos_weights[i] / (float)batch_size; mean_activity[i] = mean_activity[i] * activity_smoothing + activity * (1.0f - activity_smoothing); W[i] += (0.01f - mean_activity[i]) * 0.01f; total_active += activity; }
// increasing sparseness q = activity_smoothing * q + (1.0f - activity_smoothing) * (total_active / (float) n_hidden); for (int i = 0; i < n_hidden; i++) { W[i] += (0.1f - q) * 0.01f; }
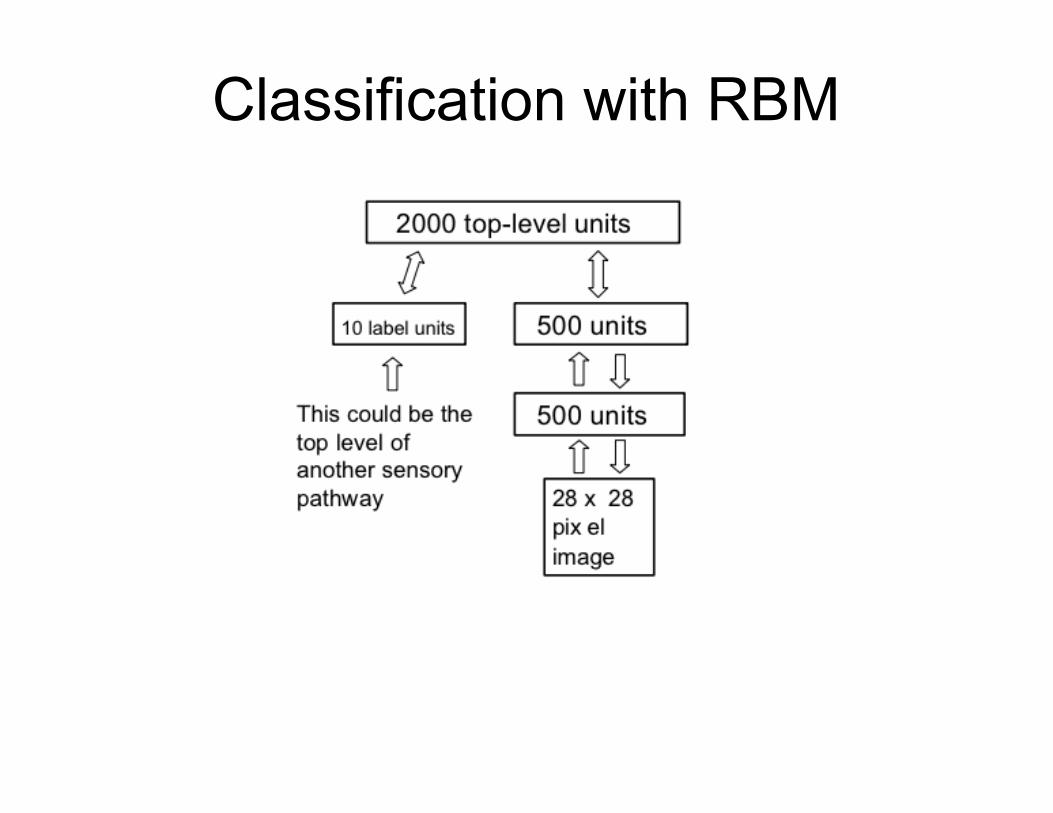
Classification with RBM

Classification with RBM
● inputs for some standard discriminative method (classifier)
● train a separate RBM on each class

Greedy layer-wise training
Higher layers capture more abstract features: