introduction to machine learning 2nd edition
TRANSCRIPT

ETHEM ALPAYDIN© The MIT Press, 2010
[email protected]://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Lecture Slides for


Kernel Machines Discriminant-based: No need to estimate densities first
Define the discriminant in terms of support vectors
The use of kernel functions, application-specific measures of similarity
No need to represent instances as vectors
Convex optimization problems with a unique solution
3Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

4
Optimal Separating Hyperplane
(Cortes and Vapnik, 1995; Vapnik, 1995)
1
11
11
1
1
0
0
0
0
2
1
wr
rw
rw
w
C
Crr
tTt
ttT
ttT
t
tt
ttt
xw
xw
xw
w
x
xx
as rewritten be can which
for
for
that such and find
if
if where,X
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

5
Margin Distance from the discriminant to the closest instances on
either side
Distance of x to the hyperplane is
We require
For a unique sol’n, fix ρ||w||=1, and to max margin
w
xw 0wtT
t
wr tTt
,w
xw 0
twr tTt ,12
10
2xww to subject min
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

Margin
6Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

7
00
0
2
1
12
1
12
1
10
1
11
0
2
1
0
2
0
2
N
t
ttp
N
t
tttp
N
t
tN
t
tTtt
N
t
tTttp
tTt
rw
L
rL
wr
wrL
twr
xww
xww
xww
xww
to subject min ,
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

8
Most αt are 0 and only a small number have αt >0; they are the support vectors
t
and to subject
tr
rr
rwrL
ttt
t
tsTtst
t s
st
t
tT
t t
ttt
t
tttTTd
,00
2
1
2
1
2
10
xx
ww
xwww
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

9
Soft Margin Hyperplane
Not linearly separable
Soft error
New primal is
ttTt wxr 10w
t
t
t
tt
t
ttTtt
t
tp wxrCL 1
2
10
2ww
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

10Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

Hinge Loss
11
otherwise
iftt
tttt
hingery
ryryL
1
10),(
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

n-SVM
12
n
n
t
tttt
N
t s
sTtststd
tttTt
t
t
Nr
xxrrL
wr
N
,,
,,
100
2
1
00
2
1
1
0
2
t
to subject
to subject
1 - min
xw
w
n controls the fraction of support vectors
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

13
t
ttt
t
TtttT
t
ttt
t
ttt
Krg
rg
rr
xxx
xφxφxφwx
xφzw
,
Kernel Trick
Preprocess input x by basis functions
z = φ(x) g(z)=wTz
g(x)=wT φ(x)
The SVM solution
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

14
Vectorial Kernels
Polynomials of degree q:
qtTtK 1 xxxx ,
T
T
xxxxxx
yxyxyyxxyxyx
yxyx
K
2
2
2
12121
2
2
2
2
2
1
2
121212211
2
2211
2
2221
2221
1
1
,,,,,
,
x
yxyx
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

15
Vectorial Kernels
Radial-basis functions:
2
2
2sK
t
txx
xx exp,
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

Defining kernels Kernel “engineering”
Defining good measures of similarity
String kernels, graph kernels, image kernels, ...
Empirical kernel map: Define a set of templates mi and score function s(x,mi)
(xt)=[s(xt,m1), s(xt,m2),..., s(xt,mM)]
and
K(x,xt)= (x)T (xt)
16Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

Fixed kernel combination
Adaptive kernel combination
Localized kernel combination
Multiple Kernel Learning
yxyx
yxyx
yx
yx
,,
,,
,
,
21
21
KK
KK
cK
K
17
i
tii
t
tt
t s i
stii
stst
t
td
i
m
ii
Krg
KrrL
KK
xxx
xx
yxyx
,)(
,
,,
2
1
1
i
tii
t
tt Krg xxxx ,|)(
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

Multiclass Kernel Machines 1-vs-all
Pairwise separation
Error-Correcting Output Codes (section 17.5)
Single multiclass optimization
18
02
2
1
00
1
2
ti
ttii
tT
iz
tT
z
i t
ti
K
ii
ziww
C
tt
to subject
min
,,xwxw
w
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

19
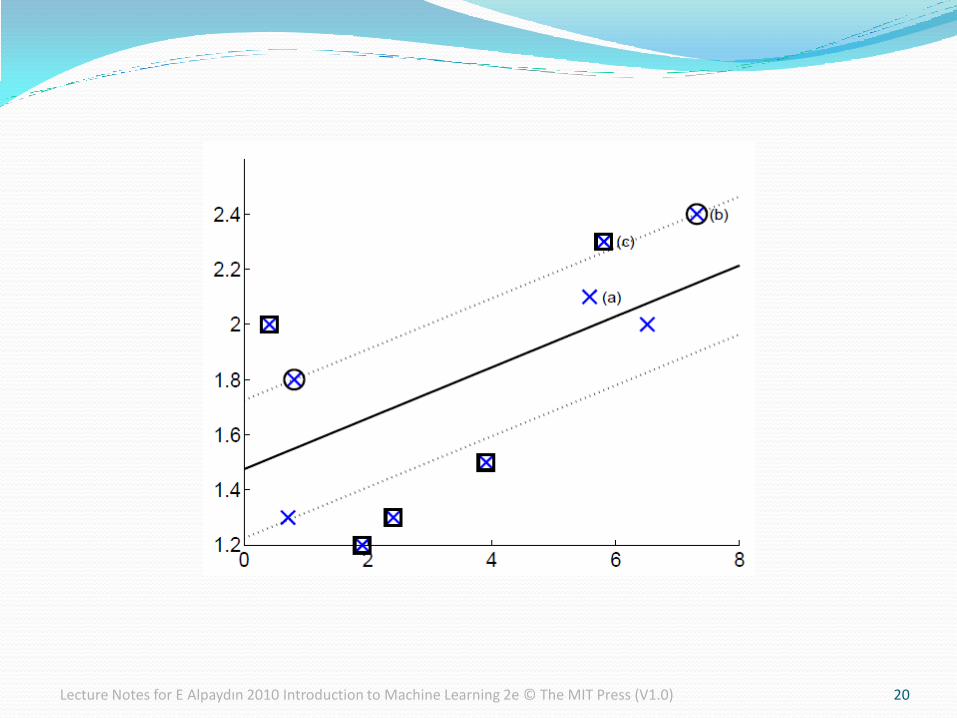
SVM for Regression
Use a linear model (possibly kernelized)
f(x)=wTx+w0
Use the є-sensitive error function
otherwise
if ,
tt
tt
tt
fr
frfre
x
xx
0
0
0
0
tt
ttT
tTt
rw
wr
,
xw
xw
t
ttC 2
2
1wmin
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)
20Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

Kernel Regression
Polynomial kernel Gaussian kernel
21Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

One-Class Kernel Machines Consider a sphere with center a and radius R
22
t
tt
N
t s
sTtstst
t
sTttd
ttt
t
t
C
xxrrxxL
Ra
R
10
0
1
2
2
,
,
to subject
to subject
C min
x
Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

23Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)

Kernel Dimensionality Reduction
Kernel PCA does PCA on the kernel matrix (equal to canonical PCA with a linear kernel)
Kernel LDA
24Lecture Notes for E Alpaydın 2010 Introduction to Machine Learning 2e © The MIT Press (V1.0)