introduction to hd insight
TRANSCRIPT

Christian Coté

ETL (extract, transform and load) architect/developer
ETL development using various ETL tools: DTS / SSIS, Hummungbird Genio, Informatica, Datastage
DW Experience in various domains: Pharmaceutical, finance, insurance and manufacturing
Specialized in Datawarehousing and BI
Microsoft Most Valuable Professional (MVP) – SQL Server
Montreal SQL Pass chapter co-leader
WhoAmI

• Why Big Data?
• Big Data Lambda Architecture
• Getting started with Windows Azure HDInsight
Service
• Introduction to Hive
Agenda


Data complexity: variety and velocity
Petabytes
What is Big Data?

Microsoft Confidential
Distributed, scalable system on commodity hardware composed of:
• HDFS—distributed file system
• MapReduce—programming model
• Others: HBase, R, Pig, Hive, Flume, Mahout, Avro, Zookeeper
HBase (column DB)
Hive Mahout
Oozie
Sqoop
HBase/Cassandra/Couch/
MongoDB
Avro
Zo
okeep
er
Pig FlumeCascadingR
Am
bari
HCatalog
Hadoop = MapReduce + HDFS
What is Hadoop?

Machine
Learning
Graph
Processing
Distributed
Compute
Extract Load
Transform
Predictive
Analysis

Move HDFS into the warehouse before analysis
ETL
Hadoop ecosystem
Learn new skills
SQL
Build
Integrate
Manage
Maintain
Support
Limitations: Analysis with Big Data todaySteep learning curve, slow and inefficient

Data sources Non-Relational Data

• Large amount of logged or archived data –small # of large files
• Loosely structured data – no fixed schema• Data is written once and may only be
appended• Data sets are read frequently and often in
full• Examples
• monitoring supply chains in retail• suspicious trading patterns in finance• air and water quality from arrays of environmental sensors

Traditional
Data Warehouse
ETL

Business Critical
Tomorrows
Data Warehouse
ETL
Sensor Data
Log Data
Automated
Data
Social
Networks
RFID Data
HDInsightSensor Data
Log Data
Automated
Data
Social
Networks
RFID Data

Microsoft Business Intelligence (BI) • Hive ODBC Connectivity
• BI Tools for Big Data
Better on Windows and Azure • Active Directory
• System Center
• .Net Programmability
• Azure Data Factory
Microsoft Data Connectivity• SQL Server / SQL Parallel Data Warehouse
• Azure Storage / Azure Data Market
Collaborate with and Contribute to OSS• Collaborate with HortonWorks
• Provide improvements and Windows support back to OSS

Big Data Lambda Architecture

• Batch layer• Stores master dataset
• Compute arbitrary views
• Speed layer• Fast, incremental algorithms
• Batch layer eventually overrides speed layer
• Serving layer• Random access to batch views
• Updated by batch layer

• Stores master dataset (in append mode)
• Unrestrained computation
• Horizontally scalable
• High latency

• Stream processing of data
• Stores a limited window of data
• Dynamic computation
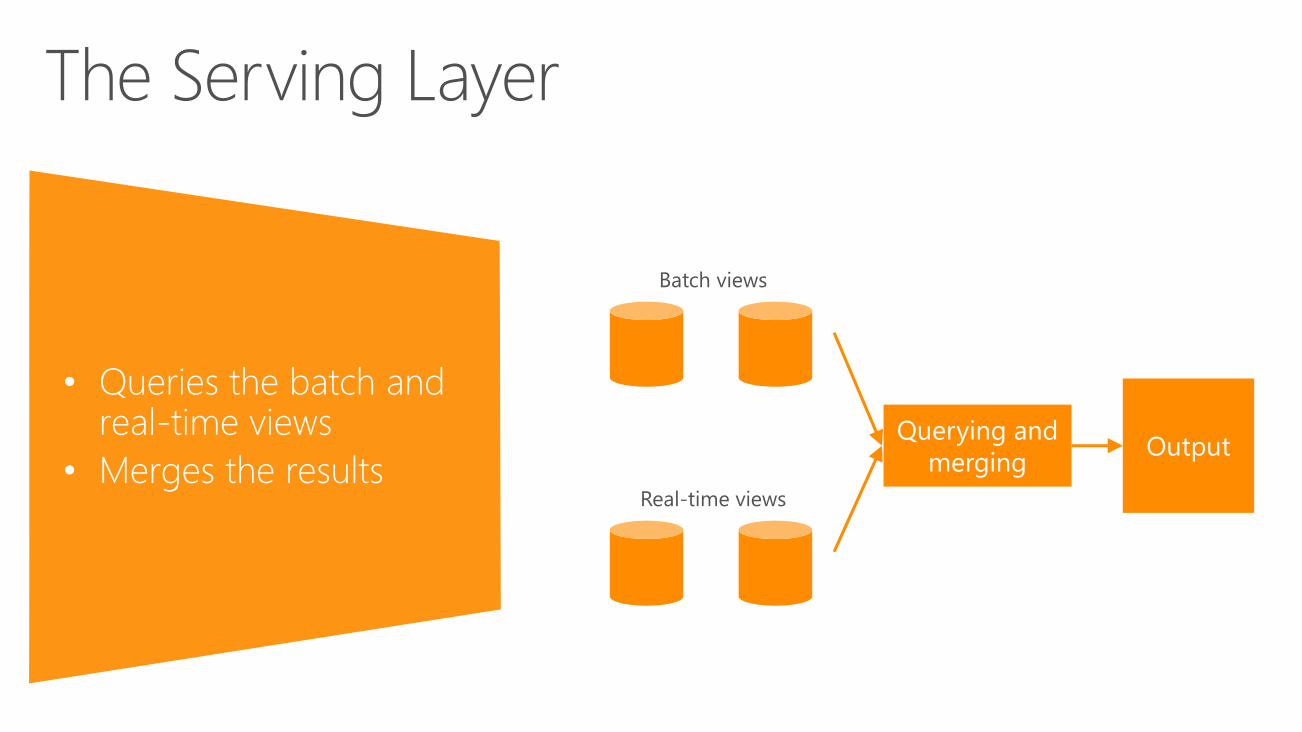
• Queries the batch and real-time views
• Merges the results


Extremely large volume of unstructured web logs
Ad hoc analysis of logs to prototype patterns
Hadoop data cluster feeds large 24TB cube
Business users analyze cube data
E.g. STRUCTURED & UNSTRUCTURED DATA

Apache Hadoop SQL Server Analysis Service (SSAS)
Microsoft Excel and PowerPivot
Other BI Tools and Custom Applications
Hadoop Data
Third Party Database
SQL Server
Analysis Services (SSAS Cube)
+
Custom
Applications
SQL Server Connector (Hadoop Hive ODBC)
Staging Database


Windows Azure HDInsight
Azure Blob storage
HDInsight Console

Windows Azure HDInsight
Azure Blob storage
MapReduce
PowerShell Console

• Programming framework (library and runtime) for analyzing datasets stored in HDFS
• Composed of user-supplied Map and Reduce functions:
• Map() - subdivide and conquer
• Reduce() - combine and reduce cardinality
………
Do work() Do work() Do work()

• Rapidly process vast amounts of data in parallel, on a large cluster of compute nodes
• Framework schedules and monitors tasks, and re-executes failed tasks
• Typically, both input and output are stored in file system
DataNode 1
Mapper
Data is shuffled
across the network
and sorted
Map Phase Shuffle/Sort Reduce Phase
DataNode 2
Mapper
DataNode 3
Mapper
DataNode 1
Reducer
DataNode 2
DataNode 3
Reducer

INPUT
OUTPUT
Pre-Execution
Member 1
Reducer 1
Member 2 Member 3 Member N
Reducer 2 Reducer 3 Reducer m
Data Summary
Reducer 4 Reducer 5
• Client app creates a task
• Task is scheduled in Task Manager
• Task is dispatched at scheduled time
Keyword Content RegionId
Complain OMITTED 10
Service OMITTED 10
Warranty OMITTED 10
Service OMITTED 20
Warranty OMITTED 20
Lawsuit OMITTED 20
Complain OMITTED 30
Tax OMITTED 30
Support OMITTED 30

INPUT
OUTPUT
Pre-Execution
Reducer 1
Mapper 1 Mapper 2 Mapper 3 Mapper NMember 1 Member 2 Member 3 Member N
Reducer 2 Reducer 3 Reducer m
Data Summary
Keyword Content RegionId
Complain OMITTED 10
Service OMITTED 10
Warranty OMITTED 10
Keyword Content RegionId
Service OMITTED 20
Warranty OMITTED 20
Lawsuit OMITTED 20
Keyword Content RegionId
Complain OMITTED 30
Tax OMITTED 30
Support OMITTED 30
Reducer 4 Reducer 5
Keyword Content RegionId
Complain OMITTED 10
Service OMITTED 10
Warranty OMITTED 10
Service OMITTED 20
Warranty OMITTED 20
Lawsuit OMITTED 20
Complain OMITTED 30
Tax OMITTED 30
Support OMITTED 30
• Task is distributed to all member nodes
• Each member node now becomes a Mapper

Reducer 5Reducer 4
INPUT
OUTPUT
Pre-Execution
Mapper 1
Reducer 1
Mapper N
Reducer 2 Reducer 3 Reducer m
Data Summary
Complain 19 10
Service 23 10
Warranty 22 10
Mapper 3Complain 38 30
Support 69 30
Tax 23 30Mapper 2
Lawsuit 7 20
Service 44 20
Warranty 25 20
Keyword Occurrence RegionId
Complain 19 10
Service 23 10
Warranty 22 10
Keyword Occurrence RegionId
Service 44 20
Warranty 25 20
Lawsuit 7 20
Keyword Occurrence RegionId
Complain 38 30
Tax 23 30
Support 69 30
• Mapper function executes over all rows in its partition
• Mappers push results to the Reducers
• Reducers start processing the output from Mappers

INPUT
OUTPUT
Pre-Execution
Mapper 1
Reducer 1
Mapper 2 Mapper 3 Mapper N
Reducer 2 Reducer 3 Reducer m
Data Summary
Reducer 4 Reducer 5Support 69Warranty 47 Lawsuit 7Service 67Complain 57 Tax 23Keyword Occurrence
Support 69
Service 67
Warranty 47
Complain 57
Lawsuit 7
Tax 23
• Reducers carry out their operation in parallel
• Output from each Reducer is summed into one temporary table
• Output results are published into output file

Demo: The “Hello World” of Map Reduce
• Supplied sample on HDInsight
• Written in Java
• Source code at
http://wiki.apache.org/hadoop/WordCount
• Demo
Each mapper takes a line as input and breaks it into words. It then emits a key/value pair of the word and 1. Each reducer sums the counts for each word and emits a single key/value with the word and sum.



• Built on top of Hadoop to provide data management, querying, and analysis
• Access and query data through simple SQL-like statements, called Hive queries
• In short, Hive complies, Hadoop executes

Demo: Hive query on head
node

• HiveQL includes data definition language, data import/export and data manipulation language statements
• See https://cwiki.apache.org/confluence/display/Hive/LanguageManual

http://blogs.msdn.com/b/windowsazure/archive/2013/03/19/getting-started-with-hdinsight.aspx
http://blogs.msdn.com/b/windowsazure/archive/2013/03/21/azure-hdinsight-and-azure-storage.aspx

Questions?
