introduction to deep neural network
TRANSCRIPT

Copyright 2011 Trend Micro Inc. 1
Introduction to Deep Neural Network Liwei Ren, Ph.D
San Jose, California, Nov, 2016

Copyright 2011 Trend Micro Inc.
Agenda
• What a DNN is
• How a DNN works
• Why a DNN works
• Those DNNs in action
• Where the challenges are
• Successful stories
• Security problems
• Summary
• Quiz
• What else
2

Copyright 2011 Trend Micro Inc.
What is a DNN?
• DNN and AI in the secular world
3

Copyright 2011 Trend Micro Inc.
What is a DNN?
• DNN and AI in the secular world
4

Copyright 2011 Trend Micro Inc.
What is a DNN?
• DNN and AI in the secular world
5

Copyright 2011 Trend Micro Inc.
What is a DNN?
• DNN in the technical world
6

Copyright 2011 Trend Micro Inc.
What is a DNN?
• DNN in the technical world
7

Copyright 2011 Trend Micro Inc.
What is a DNN?
• DNN in the technical world
8

Copyright 2011 Trend Micro Inc.
What is a DNN?
• Categorizing the DNNs :
9

Copyright 2011 Trend Micro Inc.
What is a DNN?
• Three technical elements • Architecture: the graph, weights/biases, activation functions
• Activity Rule: weights/biases, activation functions
• Learning Rule: a typical one is backpropagation algorithm
• Three masters in this area:
10

Copyright 2011 Trend Micro Inc.
What is a DNN?
• Given a practical problem , we have two approaches to solve it.
11

Copyright 2011 Trend Micro Inc.
What is a DNN?
• An example: image recognition
12

Copyright 2011 Trend Micro Inc.
What is a DNN?
• An example: image recognition
13

Copyright 2011 Trend Micro Inc.
What is a DNN?
• In the mathematical world – A DNN is a mathematical function f: D S, where D ⊆ Rn and S ⊆ Rm,
which is constructed by a directed graph based architecture.
– A DNN is also a composition of functions from a network of primitive functions.
14

Copyright 2011 Trend Micro Inc.
What is a DNN?
• We denote the a feed-forward DNN function by O= f(I) which is determined by a few parameters G, Φ ,W,B
• Hyper-parameters:
– G is the directed graph which presents the structure
– Φ presents one or multiple activation functions for activating the nodes
• Parameters:
– W is the vector of weights relevant to the edges
– B is the vector of biases relevant to the nodes
15

Copyright 2011 Trend Micro Inc.
What is a DNN?
• Activation at a node:
16

Copyright 2011 Trend Micro Inc.
What is a DNN?
• Activation function:
17

Copyright 2011 Trend Micro Inc.
What is a DNN?
• G=(V,E) is a graph and Φ is a set of activation functions.
• <G,Φ> constructs a family of functions F: – F(G,Φ) = { f | f is a function constructed by <G, Φ ,W> where WϵRN }
• N= total number of weights at all nodes of output layer and hidden layers.
• Each f(I) can be denoted by f(I ,W).
18

Copyright 2011 Trend Micro Inc.
What is a DNN?
• Mathematically, a DNN based supervised machine learning technology can be described as follows : – Given g ϵ { h | h:D S where D ⊆ Rn and S ⊆ Rm} and δ>0 , find f ϵ
F(G,Φ) such that 𝑓 − 𝑔 < δ.
• Essentially, it is to identify a W ϵ RN such that 𝑓(∗,𝑊) − 𝑔 < δ
• However, in practice, g is not explicitly expressed . It usually appears in a sequence of samples:
– { <I(j),T(j)> | T(j) =g(I(j)), j=1, 2, …,M}
• where I(j) is an input vector and T(j) is its corresponding target vector.
19

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• The function g is not explicitly expressed, we are not able to calculate g − f(∗,W)
• Instead, we evaluate the error function E(W)= 1
2𝑀∑||T(j) -
f(I(j),W)||2
• We expect to determine W such that E(W) < δ
• How to identify W ϵ RN so that E(W) < δ ? Lets solve the nonlinear optimization problem min{E(W)| W ϵ RN} , i.e.:
min{1
2𝑀 ∑|| T(j) - f(I(j),W) ||2 | W ϵ RN } (P1)
20

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• (P1) is for batch mode training, however ,it is too expensive.
• In order to reduce the computational cost, a sequential mode is introduced.
• Picking <I,T> ϵ {<I(1),T(1) >, <I(2),T(2)> ,…, <I(M),T(M)>}
sequentially, let the output of the network as O= f(I,W) for any W:
• Error function E(W)= ||T- f(I,W)||2 /2 = ∑(Tj-Oj)2 /2
• Each Oj can be considered as a function of W. We denote it as Oj(W).
• We have the optimization problem for training with sequential mode:
– min{ ∑(Tj-Oj(W) )2 /2 | W ϵ RN} (P2)
21

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• One may ask whether we get the same solution for both batch mode and sequential mode ?
• BTW
– batch mode = offline mode
– sequential mode = online mode
• We focus on online mode in this talk
22

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• How to solve the unconstrained nonlinear optimization problem (P2)?
• The general approach of unconstrained nonlinear optimization is to find local minima of E(W) by using the iterative process of Gradient Descent.
•∂E = (∂E/∂W1, ∂E/∂W2, …, ∂E/∂WT)
• The iterations: – ΔWj = - γ ∂E/∂Wj for j=1, …,T
– Updating W in each step by
• Wj (k+1) = Wj
(k) - γ ∂E(W (k))/∂Wj for j=1, …,T (A1)
• until E(W (k+1)) < δ or E(W (k+1)) can not be reduced anymore
23

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• The algorithm of Gradient Descent:
24

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• From the perspective of mathematics, the process of Gradient Descent is straightforward.
• However, from the perspective of scientific computing, it is quite challenging to calculate the values of all ∂E/∂Wj for j=1, …,N:
– The complexity of presenting each ∂E/∂Wj where j=1, …,N.
– There are (k+1)-layer function compositions for a DNN of k hidden layers.
25

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• For example, we have a very simple network as follows with the activation function φ(v)=1/(1 + 𝑒−𝑣).
• E(W) = [ T - f(I,W) ]2 /2= [T – φ(w1φ(w3I+ w2) + w0)]2 /2, we
have:
– ∂E/∂w0 = -[T – φ(w1φ(w3I + w2) + w0)] φ’(w1φ(w3I+w2) + w0)
– ∂E/∂w1 = -[T – φ(w1φ(w3I + w2) + w0)] φ’(w1φ(w3I+w2) + w0) φ(w3I+w2)
– ∂E/∂w2 = - w1 [T – φ(w1φ(w3I + w2) + w0)] φ’(w1φ(w3I+w2) + w0) φ’(w3I+w2)
– ∂E/∂w3 = - I w1 [T – φ(w1φ(w3I + w2) + w0)] φ’(w1φ(w3I+w2) + w0) φ’(w3I+w2)
26

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• Lets imagine a network of N inputs, M outputs and K hidden layers each of which has L nodes.
– It is a daunting task to express ∂E/∂wj explicitly. Last simple example already shows this.
• The backpropagation (BP) algorithm was proposed as a rescue:
– Main idea : the weights of (k-1)-th hidden layer can be expressed by the k-th layer recursively.
– We can start with the output layer which is considered as (L+1)-layer.
27

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• BP algorithm has the following major steps:
1. Feed-forward computation
2. Back-propagation to the output layer
3. Back-propagation to the hidden layers
4. Weight updates
28

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
29
Copyright 2011 Trend Micro Inc.
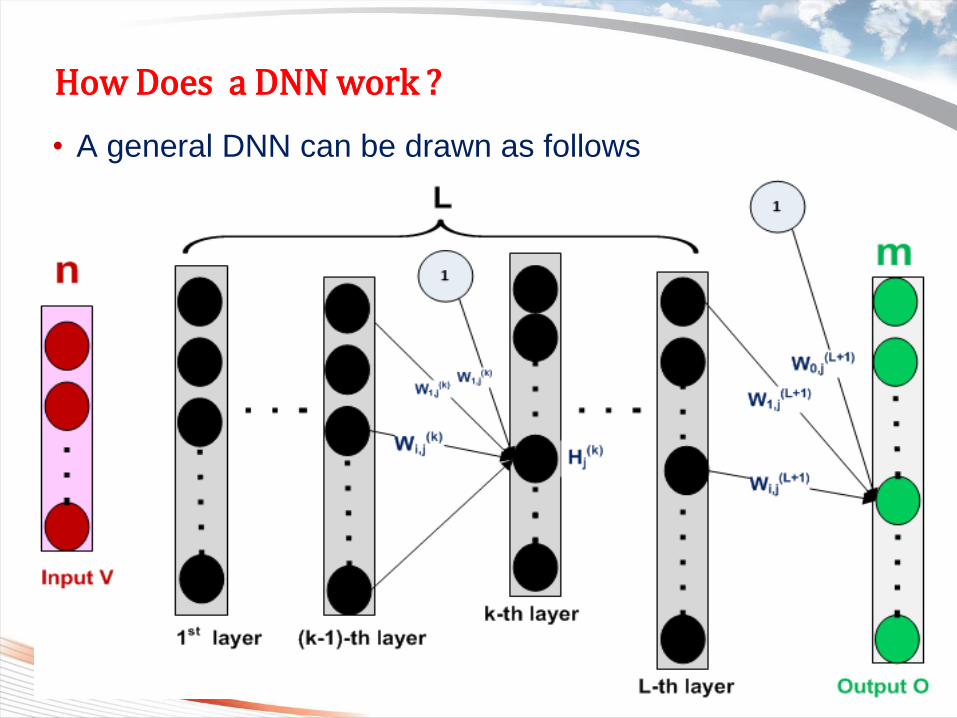
How Does a DNN work ?
• A general DNN can be drawn as follows
30

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• How to express the weights of (k-1)-th hidden layer by the weights of k-th layer recursively?
31

Copyright 2011 Trend Micro Inc.
How Does a DNN work ?
• Let us experience the BP with our small network.
– E(W) = [ T - f(I,W) ]2 /2= [T – φ(w1φ(w3I+ w2) + w0)]2 /2.
• ∂E/∂w0 = - φ’(O) (T – O)
• ∂E/∂w1 = -φ’(O) (T – O) φ(O)
• ∂E/∂w2 = - φ’(O) (T – O) φ’(H) w1 * 1
• ∂E/∂w3 = - φ’(O) (T – O) φ’(H) w1 * I
– Let H0(1)= 1, H1
(1) = H = φ(w3I+ w2), H1(0) = I, we verify the follows:
• δ1(2)= φ’(O) (T – O)
• w0+
= w0 + γ δ1(2) H0
(1) , w1+
= w1 + γ δ1(2) H1
(1)
• δ1(1)= φ’(H1
(1)) δ1(2) w1
• w2+
= w2 + γ δ1(1) H0
(0) , w3+
= w3 + γ δ1(1) H1
(0)
• where w0 = w0,1(2) , w1 = w1,1
(2), w2 = w0,1(1) , w2 = w1,1
(1)
32

Copyright 2011 Trend Micro Inc.
Why Does a DNN Work?
• It is amazing ! However, why does it work?
• For a FNN, it is to ask whether the following approximation problem has a solution: – Given g ϵ { h | h:D S where D ⊆ Rn and S ⊆ Rm} and δ>0 , find a W ϵ
RN such that 𝑓(∗,𝑊) − 𝑔 < δ.
• Universal approximation theorem (S): – Let φ(.) be a bounded and monotonically-increasing continuous function. Let
Im denote the m-dimensional unit hypercube [0,1]m . The space of continuous functions on Im is denoted by C(Im) . Then, given any function f ϵ C(Im) and ε>0 , there exists an integer N , real constants vi, bi ϵ R and real vectors wi ϵ Rm, where i=1, …, N , such that
|F(x)-f(x)| < ε
for all x ϵ Im , where F(x) = vi φ(wi T x + bi) 𝑵
𝒊=𝟏 is an approximation to the function f which is independent of φ .
33
Im

Copyright 2011 Trend Micro Inc.
Why Does a DNN Work?
• Its corresponding network with only one hidden layer – NOTE : this is not even a general case for one hidden layer. It is a
special case. WHY?
– However, it is powerful and encouraging from the mathematical perspective.
34
Im

Copyright 2011 Trend Micro Inc.
Why Does a DNN Work?
The general networks have a general version of Universal Approximation Theorem accordingly:
35
Im

Copyright 2011 Trend Micro Inc.
Why Does a DNN Work?
• Universal approximation theorem (G): – Let φ(.) be a bounded and monotonically-increasing continuous function. Let
S be a compact space in Rm . Let C(S ) = {g | g:S ⊂ Rm Rn is continuous}. Then, given any function f ϵ C(S) and ε>0 , there exists a FNN as shown above which constructs the network function F such that
|| F(x)-f(x) || < ε
where F is an approximation to the function f which is independent of φ .
• It seems both shallow and deep neural networks can construct an approximation to a given function. – Which is better?
– Or which is more efficient in terms of using less nodes ?
36
Im
Rm
Copyright 2011 Trend Micro Inc.
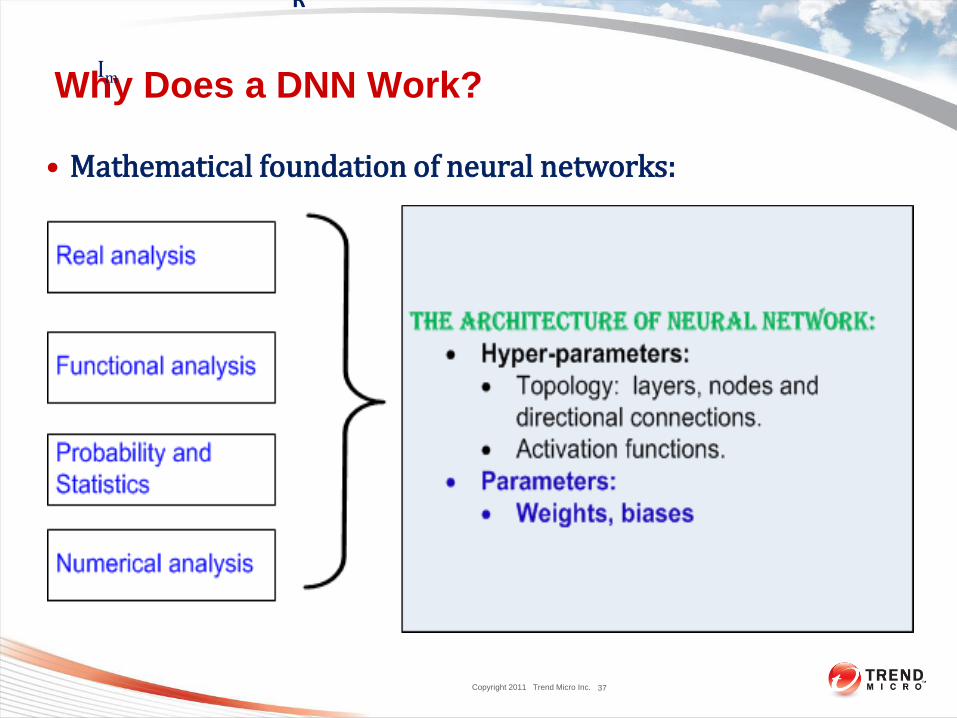
Why Does a DNN Work?
• Mathematical foundation of neural networks:
37
Im
Rm

Copyright 2011 Trend Micro Inc.
Those DNNs in action
• DNN has three elements
• Architecture: the graph , weights/biases, activation functions
• Activity Rule: weights/biases, activation functions
• Learning Rule: a typical one is backpropagation algorithm
• The architecture basically determines the capability of a specific DNN
– Different architectures are suitable for different applications.
– The most general architecture of an ANN is a DAG ( directed acyclic graph).
38

Copyright 2011 Trend Micro Inc.
Those DNNs in action
• There are a few well-known categories of DNNs.
39

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• Given a specific problem, there are a few questions before one starts the journey with DNNs:
– Do you understand the problem that you need to solve?
– Do you really want to solve this problem with DNN, why?
• Do you have an alternative yet effective solution?
– Do you know how to describe the problem in DNN mathematically ?
– Do you know how to implement a DNN , beyond a few APIs and sizzling hype?
– How to collect sufficient data for training?
– How to solve the problem efficiently and cost-effectively?
40

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• 1st Challenge:
– a full mesh network has the curse of dimensionality.
41

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• Many tasks of FNN do not need a full mesh network.
• For example, if we can present the input vector as a grid, the nearest-neighborhood models can be used when constructing an effective FNN which can reduce connections
– Image recognition
– GO (圍棋) : a game that two players play on a 19x19 grid of lines.
42

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• The 2nd challenge is how to describe a technical problem in terms of DNN, i.e., mathematical modeling. There are generally two approaches:
– Applying a well-learned DNN architecture to describe the problem. Deep understanding of the specific network is usually required!
• Two general DNN architectures are well-known
– FNN: feedforward neural network. Its special architecture CNN (convolutional neural network) is widely used in many applications such as image recognition, GO, and etc.
– RNN: recurrent neural network. Its special architecture is LSTM (long short-term memory) which has been applied successfully in speech recognition, language translation, and etc.
• For example, if we want to try a FNN, how to describe the problem in terms of <Input vector, Output vector> with fixed dimension ?
– Creating a novel DNN architecture from ground if none of the existing
models fits your problem. Deep understanding of DNN theory / algorithms is required.
43

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• Handwriting digit recognition: – Modeling this problem is straightforward
44

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• Image Recognition is also straightforward
45

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• However, due to the curse of dimensionality, we can use a special FFN: – Convolutional neural network (CNN)
46

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• How to construct a DNN to describe language translation ?
– They use LSTM networks
• How to construct a DNN to describe the problem of malware classification?
• How to construct a DNN to describe the network traffic for security purpose?
47

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• The 3rd challenge is how to collect sufficient training data. To achieve required accuracy, sufficient training data is necessary. WHY?
48

Copyright 2011 Trend Micro Inc.
What Are the Challenges?
• The 4th challenge is how to identify various talents for providing a DNN solution to solve specific problems.
– Who knows how to use existing DL APIs such as TensorFlow
– Who understands various DNN architectures in depth so that he/she knows how to evaluate and identify a suitable DNN architecture to solve the problem.
– Who understands the theory and algorithms of the DNN in depth so that he/she can create and design a novel DNN from ground.
49

Copyright 2011 Trend Micro Inc.
Successful Stories
• ImageNet : 1M+ images, 1000+ categories, CNN
50

Copyright 2011 Trend Micro Inc.
Successful Stories
• Unsupervised learning neural networks… YouTube and the Cat .
51

Copyright 2011 Trend Micro Inc.
Successful Stories
• AlphaGo, a significant milestone in AI history
– More significant than DeepBlue
• Both Policy Network and Value Network are CNNs.
52

Copyright 2011 Trend Micro Inc.
Successful Stories
• Google Machine Neural Translation… LSTM (Long Short Term Memory) network
53
Copyright 2011 Trend Micro Inc.
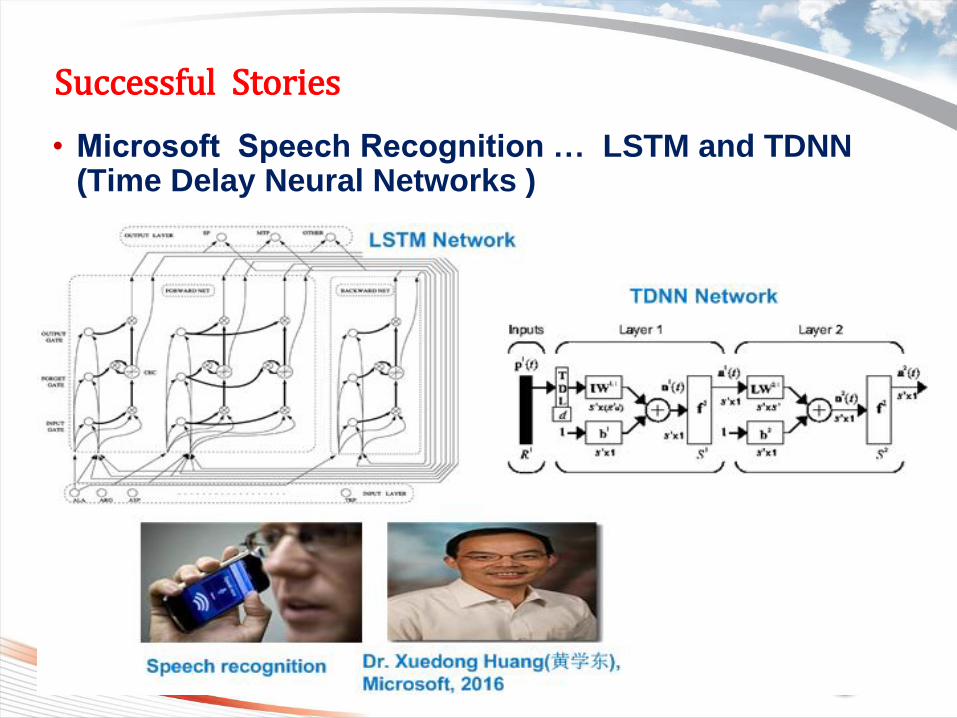
Successful Stories
• Microsoft Speech Recognition … LSTM and TDNN (Time Delay Neural Networks )
54

Copyright 2011 Trend Micro Inc.
Security Problems
• Not disclosed for the public version.
55

Copyright 2011 Trend Micro Inc.
Summary
• What a DNN is
• How a DNN works
• Why a DNN works
• The categories of DNNs
• Some challenges
• Well-known stories
• Security problems
56

Copyright 2011 Trend Micro Inc.
Quiz
• Why do we choose the activation function as a nonlinear function?
• Why Deep? Why deep networks are better than shallow networks?
• What is the difference between online and batch mode training?
• Will online and batch mode training converge to the same solution?
• Why do we need the backpropagation algorithm?
• Why do we apply convolutional neural networks to image recognition?
57

Copyright 2011 Trend Micro Inc.
Quiz
• If we solve a problem with a FNN, – how many deep layers should we go?
– How many nodes are good for each layer?
– How to estimate and optimize the cost?
• Is it guaranteed that the backpropagation algorithm converge to a solution?
• Why do we need sufficient data for training in order to achieve certain accuracy?
• Can a DNN do some tasks more than extending human’s capabilities or automating extensive manual tasks ? – To prove a mathematical theorem ... or to introduce an interesting
concept… or to appreciate a poem… or to love…
58

Copyright 2011 Trend Micro Inc.
Quiz
• AlphaGo is trained for 19x19 lattice. If we play GO game on 20x20 board, can AlphaGo handle it?
• ImageNet is trained for 1000 categories. If we add the 1001-th category, what should we do?
• People do consider a special DNN as a black box. Why?
• More questions from you …
59

Copyright 2011 Trend Micro Inc.
What Else?
• What to share next from me? Why do you care? – Various DNNs: principles, examples, analysis and
experiments…
• ImageNet, AlphaGO, GNMT and etc..
– My Ph.D work and its relevance to DNN
– Little History of AI and Artificial Neural Network
– Various Schools of the AI Discipline
– Strong AI vs. Weak AI
60

Copyright 2011 Trend Micro Inc.
What Else?
• What to share next from me? Why do you care? – Questions when thinking about AI:
• Are we able to understand how we learn?
• Are we going the right directions mathematically and scientifically?
• Are there simple principles for cognition like what Newton and Einstein established for understanding our universe?
• What are we lack between now and the coming of so called Strong AI?
61

Copyright 2011 Trend Micro Inc.
What Else?
• What to share next from me? Why do you care? •Questions about who we are.
– Are we created?
– Are we the AI of the creator?
• My little theory about the Universe
62