introducing perl
DESCRIPTION
Introducing Perl. P ractical E xtraction and R eport L anguage First developed by Larry Wall, a linguist working as a systems administrator for NASA in the late 1980s, as a way to make report processing easier. Since then, it has moved into a large number of roles: - PowerPoint PPT PresentationTRANSCRIPT

04/19/23 1
Introducing Perl
Practical Extraction and Report Language
First developed by Larry Wall, a linguist working as a systems administrator for NASA in the late 1980s, as a way to make report processing easier.
Since then, it has moved into a large number of roles:
automating system administration
acting as glue between different computer systems;
the language of choice for CGI programming on the Web?
Free: Source code, documentation, use Portable: more than 50 operating system platforms

04/19/23 2
Introducing Perl
Perl is often called the Swiss Army chainsaw of languages: versatile, powerful and adaptable - resembles the Swiss Army knife
Perl is an interpreted language optimised for
Scanning arbitrary text files extracting information from those text files Printing reports based on that information
Perl is intended to be practical: easy to use, efficient and complete rather than tiny, elegant and minimal
Perl’s slogan is “There is more than one way to do it” and its philosophy is to “make easy things easy while making difficult things passible”

04/19/23 3
Introducing Perl
A little history: December 1987, release 1.0 Current major release 5.0 in October 1994 July 1998 release 5.005 March 1999 release 5.005_03 March 2000 release 5.6 Latest version ?
Portable Unix: AIX, HSD, HP-UX, IRIX, Linux, Solaris … MS Windows MacOS Others: AmigaOS, OS2, VMS ...

04/19/23 4
Introducing Perl
Programs, Scripts, Compilers, and Interpreters
Perl programs are call “Scripts”. There is no difference. It is just source code
Perl “compiler” is also call “interpreter”.
The source code is compiled into bytecode which is executed in the main memory(rather high level bytecode: “sort a list” is one operation)

04/19/23 5
Introducing Perl
Perl Internet References Resources
Home page of Perl: http://www.pwrl.com Perl user groups: http://www.perl.org CPAN(Comprehensive Perl Archive Network) http://cpan.org
Getting Perl
Unix: www.cpan.org/ports Windows: http://www.activestate.com/ MacOS: http://www.macperl.com/
04/19/23 6
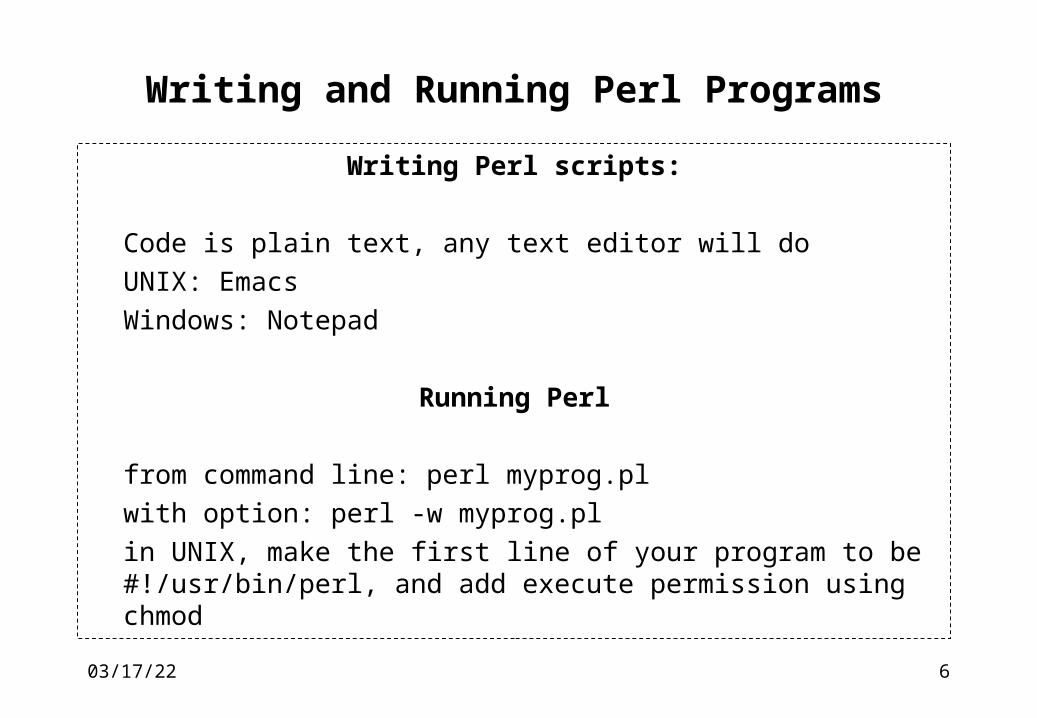
Writing and Running Perl Programs
Writing Perl scripts:
Code is plain text, any text editor will do UNIX: Emacs Windows: Notepad
Running Perl
from command line: perl myprog.pl with option: perl -w myprog.pl in UNIX, make the first line of your program to be #!/usr/bin/perl,
and add execute permission using chmod
04/19/23 7
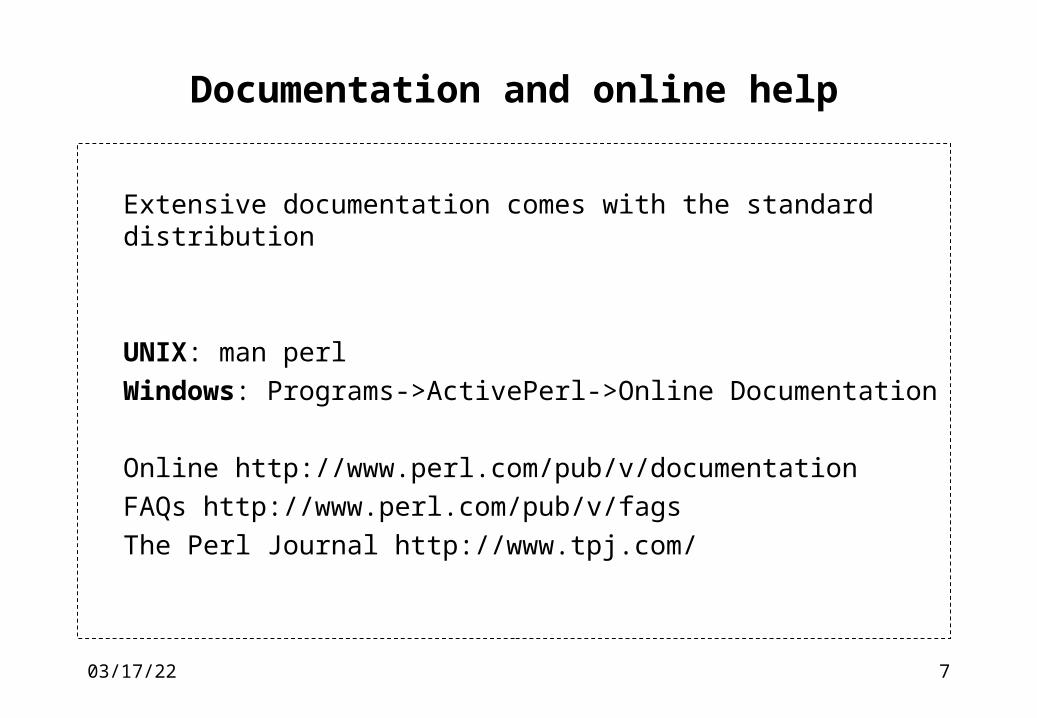
Documentation and online help
Extensive documentation comes with the standard distribution
UNIX: man perl
Windows: Programs->ActivePerl->Online Documentation
Online http://www.perl.com/pub/v/documentation FAQs http://www.perl.com/pub/v/fags The Perl Journal http://www.tpj.com/
04/19/23 8
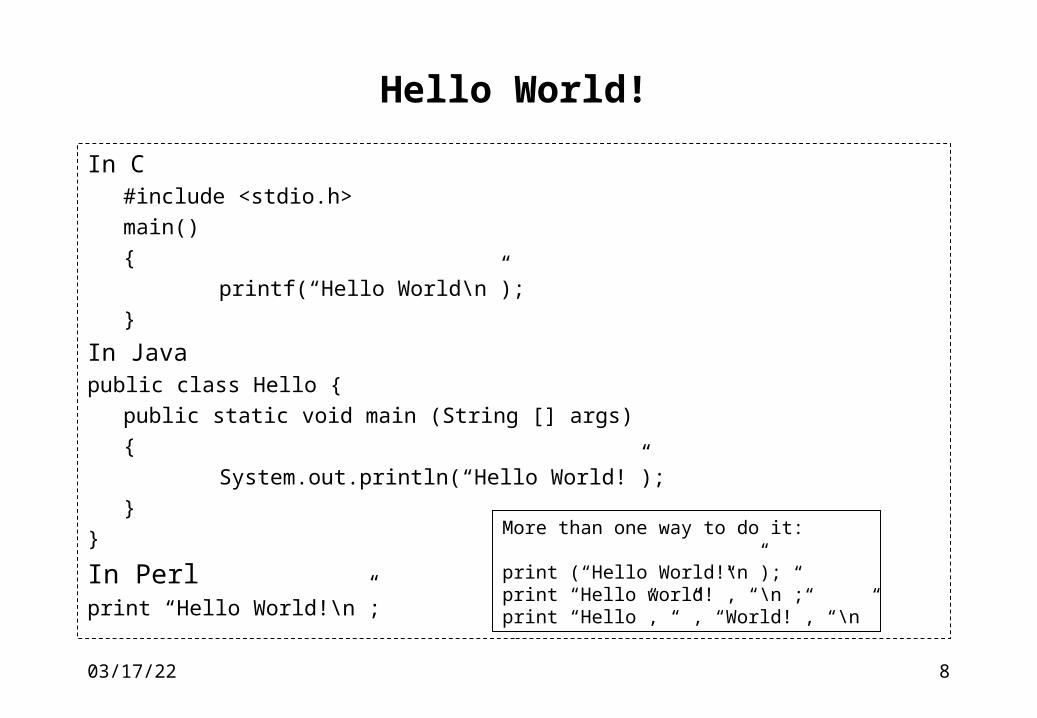
Hello World!
In C#include <stdio.h>
main()
{
printf(“Hello World\n”);
}
In Javapublic class Hello {
public static void main (String [] args)
{
System.out.println(“Hello World!”);
}
}
In Perlprint “Hello World!\n”;
More than one way to do it:
print (“Hello World!\n”);print “Hello world!”, “\n”;print “Hello”, “”, “World!”, “\n”

04/19/23 9
Some Simple Scripts/One-liners
Example 1: Print lines containing the string ‘Shazzam!’
#/usr/bin/perl
while (<STDIN>) {
print if /Shazzam!/
};– #<STDIN> is a bit of Perl magic that delivers the next line of input each time round the loop
Example 2: The same thing the hard way
#/usr/bin/perl
while ($line = <STDIN>) {
print $line if $line =~/Shazzam!/
};

04/19/23 10
Some Simple Scripts/One-liners
Example 3: A script with arguments
#/usr/bin/perl
$word = shift;
while (<>) {print if /$word/};
– If we put the script in a file called match, we can invoke the script
match Shazzam!
Match Shazzam! file1 file 2
– The shift operator returns the first argument from the command, and move others up one position. – Called with one argument, match reads standard input and prints those lines which contains the word
given as the argument.
– Called with two or more arguments, the first argument is the word to be searched for, and second and subsequent arguments are filenames of fles that will be searched in sequence for the target word.

04/19/23 11
Some Simple Scripts/One-liners
Example 4: Error Messages
#/usr/bin/perl
die “Need word to search for\n” if @ARGV ==0;
$word = shift;
while (<>) {print if /$word/};
– @ ARGV is a special array which holds the command line parameters. A program is executed as a result of a system command, which consists of the executable program file, followed by a command tail, e.g. :
C:> program param1 param2 ... paramn
– Then $ARGV[0] = "program", $ARGV[1] = "param1", $ARGV[2] = "param2" ... $ARGV[n] = "paramn".

04/19/23 12
Some Simple Scripts/One-liners
Example 5: Reverse order of lines in a file
#/usr/bin/perl
open IN, $ARGV[0] or die “Cannot open $ARGV[0]\n”;
@file = <IN>;
for ($I = @file-1; $I >= 0; $I--)
{
print $file[$I];
}
Do the same in C, Java ?

04/19/23 13
Variables and Datatypes
– $ Scalar
– @array
– %hash
– The type of a variable is marked by the type prefix ($ @ %), which is always used.
$x = $y +3– Variable names are arbitrary long, which can consist of characters a - z, A-
Z, the underscore _ (and must begin with any of these), and digits from 0 - 9. It is case sensitive: uppercase and lowercase are different.
$No_of_Students, @StudentList, %StudentRecord_01– Special control variables have “punctuation” in their names, e.g., the $^O
variable which tells the name of the current operation system.

04/19/23 14
Variables and Data types (Scalars)
– A $scalar holds a single data item. The data can be
string, numeric, boolean depending on context.
– When scalars are understood as numbers (that is, used as numbers), they are double precision floating point numbers.
– Scalars are given a value by the assignment operator = . For example
– $a = “The University of Nottingham, UK”;– $b = 129867445;– $c = 3.14159; – $d = 03776; #octal– $e = 0x3fff; #hex

04/19/23 15
Variables and Data types (Aggregates)
There are two aggregate datatypes, @array and %hash. Both can hold an unlimited number (as long as there is memory) of scalars, there is no explicit declaration, allocation, deallocation, or any explicit memory management
@array:
– Arrays are ordered and they are indexed by a number (a scalar in numeric context)
%hash:
– Hashes are unordered and they ar indexed by a string (a scalar in string context)

04/19/23 16
Variables and Data types (Arrays)
– An @array is an aggregate for storing scalars and indexed by a number (a scalar) inside square brackets [].
– The indexing is zero-based.
– Also negative indices can be used, they count from the end of the array.
@a = (“one”, “two”, “three”);
print “$a[1] $a[0] $a[-1]\n”;
– will result in
two one three

04/19/23 17
Variables and Data types (Arrays)
– If you enclose the array in double quotes, the scalars of the array are printed separated by space.
@a = (“one”, “two”, “three”);
print “@a\n”;
will give one two three
– Note that while an array has a type prefix of @ and element of the array is a scalar and therefore has a prefix of $:
@a = (“one”, “two”, “three”);
$a[3]= “four”;
print “@a $a[0]\n”;
will give one two three four one

04/19/23 18
Quoting: Basic
– Inside double quotes variables and \-constructs (like \n) are expanded, inside single quotes they are not expanded.
– The difference between single quotes and double quotes is that single quotes mean that their contents should be taken literally, while double quotes mean that their contents should be interpreted.
print "This string\nshows up on two lines.";will show: This string
shows up on two lines
print 'This string \n shows up on only one.';will show: This string \n shows up on two lines
@a = (“one”, “two”, “three”);print “@a\n”, ‘@a’, “\n”;will show one two three
@a

04/19/23 19
Quoting: Basic
– Inside double quotes, the following are the most common \-constructs
\n The logical newline
\t The tabulator
\$ The dollar
\@ The at sign
\xHH Character encoded in hexadecimal
\010 Character encoded in octal
\” The double quotes
\\ The backslash itself

04/19/23 20
Quoting: The qw operator
– There is a special quoting construct for quoting “words”, or strings consisting only of alphanumeric characters.
@a = (“one”, “two”, “three”);
can be written as
@a = qw(one two three);
The qw stands for “quote words”
Note also that all the quoting constructs are operators.

04/19/23 21
Variables and Data types (Arrays, $#)
– The notation $#arrayname returns the index of the farthest array element ever modified.
@a = qw(one two three);
print “The las index of \@a is $#a. \n”;
will show
The last index of @a is 2

04/19/23 22
Variables and Data types (undef)
– What is in the aggregate elements that have not been assigned a value? The undef value (the value of all uninitialized scalars, not just of uninitialized aggregate elements).
– This can be tested using defined, explicitly assigned by using the undef() function, and should be always caught by using -w switch.
@a = qw(one two three);
if (defined $a[1]) {print “Oh, yes\n”};
if (defined $a[9]) {print “Impossible. \n”};
Usin the undef() a scalar can be “returned” to an uninitialized state.
@a=qw(one two three);
undef $a[1];
if (defined $a[1]) {print “Impossible. \n”}

04/19/23 23
Important: -w
– The following script will print The tenth element is . And you would waste your time by wondering what went wrong
@ = qw (one two three);
print “The tenth element is $a[9]. \n”;
But, by adding the -w switch you would have seen this:
Use of uninitialized value ….
Use -w is strongly encouraged.
– The -w catches not only the use of uninialized values but also other mistakes and problems, such as using a variable only once (usually indicative of a typo)

04/19/23 24
Scalar Context: Strings or Numbers
– Numbers in Perl can be manipulated with the usual mathematical operations: addition, multiplication, division and subtraction. (Multiplication and division are indicated in Perl with the * and / symbols, by the way.)
$a = 5; $b = $a + 10; # $b is now equal to 15.
$c = $b * 10; # $c is now equal to 150.
$a = $a - 1; # $a is now 4.
– You can also use special operators like ++, --, +=, -=, /= and *=. These manipulate a scalar's value without needing two elements in an equation.
$a = 5;
$a++; # $a is now 6; we added 1 to it.
$a += 10; # Now it's 16; we added 10.
$a /= 2; # And divided it by 2, so it's 8.

04/19/23 25
Scalar Context: Strings or Numbers
– Strings in Perl don't have quite as much flexibility. About the only basic operator that you can use on strings is concatenation. The concatenation operator is the period . Concatenation and addition are two different things:
$a = "8"; # Note the quotes. $a is a string.
$b = $a + "1"; # "1" is a string too.
$c = $a . "1"; # But $b and $c have different values!
– Remember that Perl converts strings to numbers transparently whenever it's needed, so to get the value of $b, the Perl interpreter converted the two strings "8" and "1" to numbers, then added them. The value of $b is the number 9. However, $c used concatenation, so its value is the string "81".
– Just remember, the plus sign adds numbers and the period puts strings together.

04/19/23 26
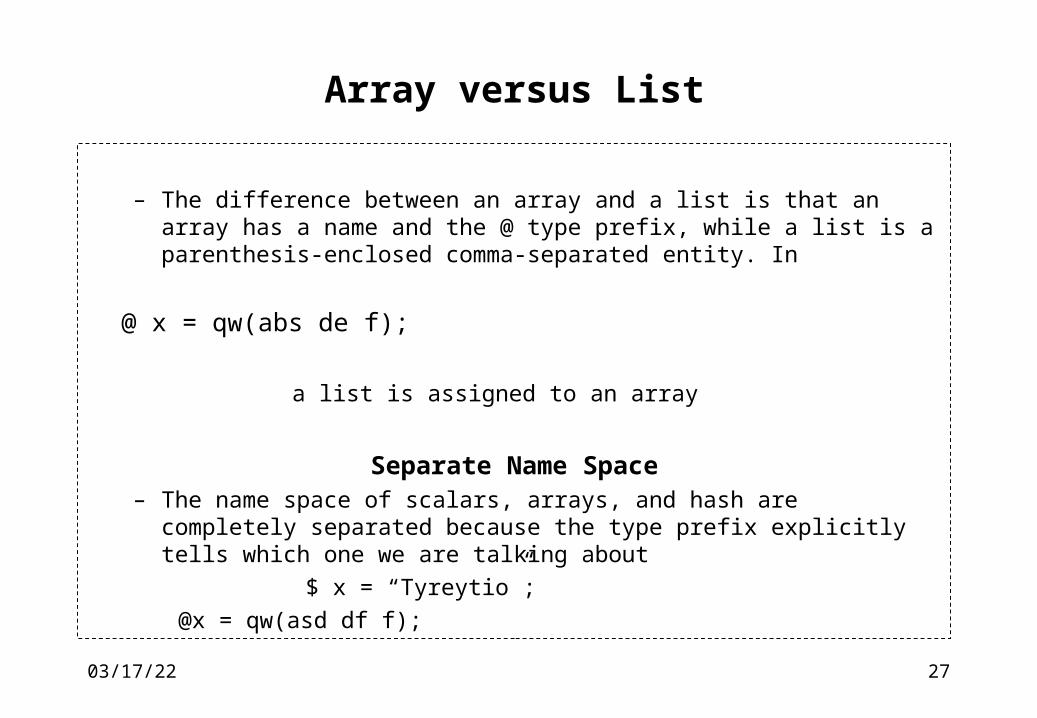
Context: Scalar v.s. List
– A very pervasive concept is different context. Certain constructs and functions behave differently depending on the context they are used. For example, the context of the left side of the assignment operator (=) forces the right side to comply:
@x = qw (adc de f)
@a = @x;
$a = @x;
print “@a: $a \n”;
will print abc de f: 3
– In scalar context the value of an array is the size of the array ($#array plus one)
04/19/23 27
Array versus List
– The difference between an array and a list is that an array has a name and the @ type prefix, while a list is a parenthesis-enclosed comma-separated entity. In
@ x = qw(abs de f);
a list is assigned to an array
Separate Name Space– The name space of scalars, arrays, and hash are completely separated because
the type prefix explicitly tells which one we are talking about
$ x = “Tyreytio”;
@x = qw(asd df f);
04/19/23 28
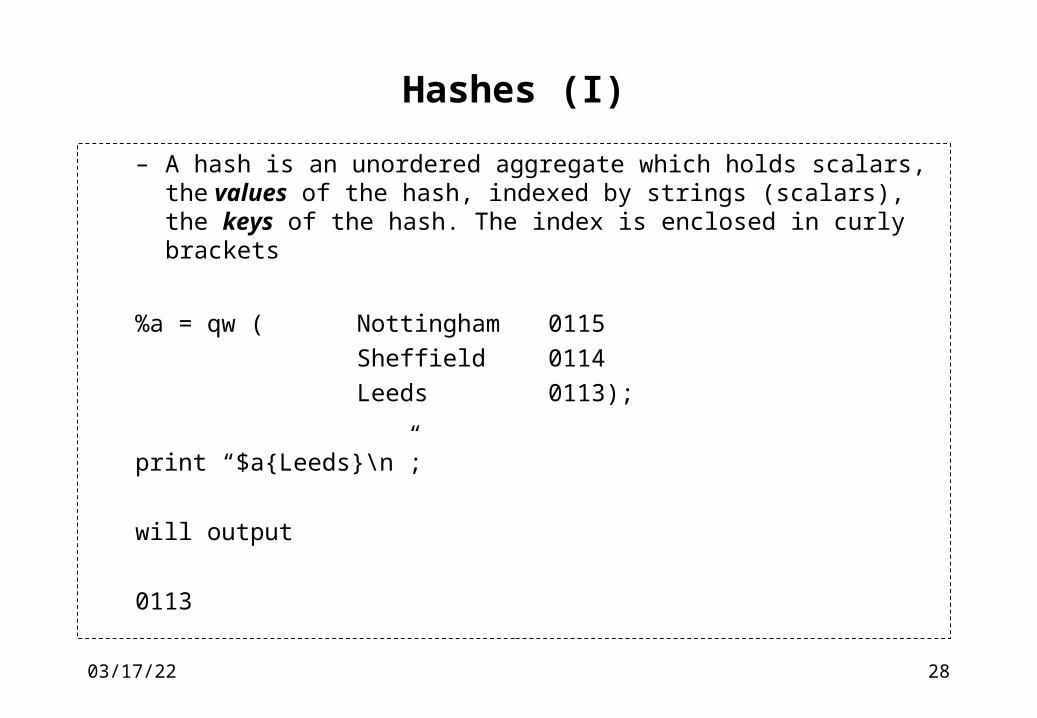
Hashes (I)
– A hash is an unordered aggregate which holds scalars, the values of the hash, indexed by strings (scalars), the keys of the hash. The index is enclosed in curly brackets
%a = qw ( Nottingham 0115
Sheffield 0114
Leeds 0113);
print “$a{Leeds}\n”;
will output
0113
04/19/23 29
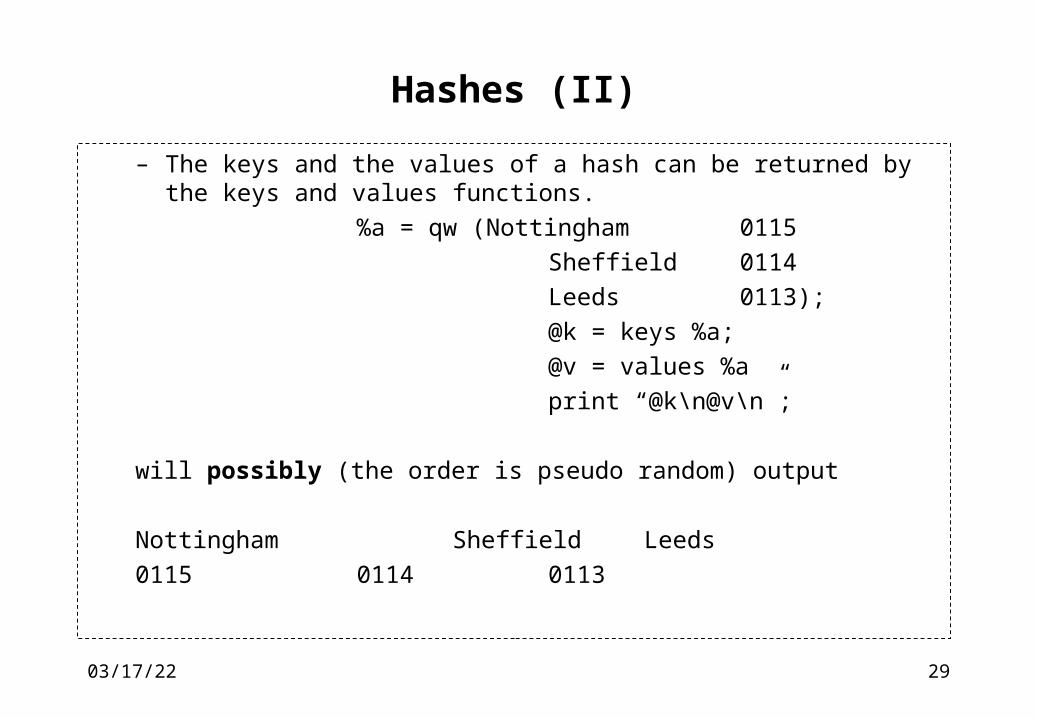
Hashes (II)
– The keys and the values of a hash can be returned by the keys and values functions.
%a = qw (Nottingham 0115
Sheffield 0114
Leeds 0113);
@k = keys %a;
@v = values %a
print “@k\n@v\n”;
will possibly (the order is pseudo random) output
Nottingham Sheffield Leeds
0115 0114 0113

04/19/23 30
Hashes (III)
– The existence of a key-value pair in a hash can be verified using the exists function.
%a = qw( Nottingham 0115
Sheffield 0114
Leeds 0113);
$b = exists $a{Leeds} ? 1:0;
$c = exists $a{Birmingham} ? 1:0;
print “$b $c \n”
will print 1 0
– The exists cares only about the existence of the key: the value is irrelevant.

04/19/23 31
Hashes (IV)
– The key-value pairs of a hash can be returned iteratively (in a loop) by each function
%a = qw(Nottingham 0115
Sheffield 0114
Leeds 0113);
while (($k, $v)= each %a){
print “$k $v\n”;
}– will possibly print (again the order is pseudo random)
Nottingham 0115
Sheffield 0114
Leeds 0113

04/19/23 32
Hashes (V)
The => operator
– The => operator is a variant of the , (comma) operator which as a side effect forces its left operand to be a bare word, effectively a string constant with implicit single quotes around it. This is a convenient notation which is most often used when specifying the key-value pairs for a hash
%b = (‘English’, ‘one’);
%b = (English => ‘one’);
– these are equivalent.

04/19/23 33
Hashes (VI)
– Hash elements or groups of hash elements (slices) can be deleted using the delete function
%a =(English =>”one”, French => “un”,
German => “ein”, Finish => “yksi”
Japanese => “ichi”, Chinese “yi”);
delete $a{German};
delete $a{‘French’, ‘Finish’};
print values %a, “\n”;
will print the values one ichi yi in some order

04/19/23 34
Slices of Aggregates
– In addition to accessing the aggregates either as a whole or per element, it is possible to access them by groups of elements. These groups are called slices. The syntax is @ variable indices, or in other words, @array[number] or @hash{strings}. The slice is the list of scalars at the specified indices.
%a =(English =>”one”, French => “un”,
German => “ein”, Finish => “yksi”
Japanese => “ichi”, Chinese “yi”);
@s = @a{“German”,”English”};
print “@s\n”;
Should result in: ein one– The order of the returned list is well defined because of the order of the indices
is well-defined.

04/19/23 35
Operators
– A fairly standard set of mathematical, logical, and relational operators exists, the only somewhat exceptional one is the power operator **, for example 2**3 is 8.
– Scalars can be either numbers or strings depending on the context they are used in - and this is exactly what operators do: they force a contexr on their operands. For example, while the + forces numeric context on its operands and sums them, the . (dot) operator forces string context on its operand and concatenates them.
(B, $c) = (2, 3);
$a = $b + $c;
$d = $b.$c;
print “$a $d \n”
will print: 5 23

04/19/23 36
Operators: Specialties
Perl has these
– separate sets of comparison operators for string and numeric context
– generalized comparison operators cmp and <=>– low-precedence and, or and not (&&, || and ! Are high precedence)
– string concatenator . (dot) and string/list repeater x– left-quoting pseudo-comma =>, range generator ..– Quoting operators
– file/directory input operator < >– Pattern matching, substitition, and biding operators, m, s, =~, and !~

04/19/23 37
Operators: Boolean
– The && and || are short-circuiting as in C: they stop evaluating their operands as soon as the first decisive value is met (The first false for &&, the first true for||)
– There are also variants of lower precedence: and, or, xor and not

04/19/23 38
Operators: Precedence
– Precedence rules are much like in C, C++, or Java
– Some confusion may stem from the fact that when calling functions (either built-in or user defined), the parentheses are not required. In other words there are equivalent:
$n = length ($header);
$n = length $header;
– This would be easy enough to comprehend, but things gets interesting when the functions have more than one argument, and especially interesting when the number of arguments varies.
– When in doubt, parenthesize

04/19/23 39
Operators: Assignments, Valued and Modifiable
– Assignments have values.
$a += ($b=$c);
This copies the value of $c to $b and then adds that to $a.
– Assignments are modifiable.
($c=$d)+=@e;– This copies the value of $d to $c and then adds the number of elements in @e
to $c.
– Or, in other words, the left side of an assignment can be used in further assignment (this property is often called “lvalue”, left-value).

04/19/23 40
Operators: Assignments, List Context
– Assignment also works in list context.
($a, $b) = ($b, $a);
This swaps the values of $a and $b

04/19/23 41
Operators: Comparing
– For comparing scalars with each other and with literal values all the usual comparison operators exist. The catch is that there are two sets of comparison operators: One for comparing in string context, one for comparing in numeric context.
String Numbereq = =ne !=lt <gt >le <=ge >=
cmp < = >
The cmp and < = > return -1, 0, or 1 depending on whether the comparands fullfil the less-than, equal-to, or greater than relation

04/19/23 42
Operators: Concatenate and Repeat
– Scalars can be concatenated (as string) using the . (dot) operator
$a = “con”;
$b = “nate”;
$c = $a . “cate”. $b;
will result in $c being “concatenate”.
– Scalars and lists can be repeated using the x operator. The repetition count comes after the operator
$a = “yes”; @b = ($a, “No”); $c = $a x 3;@c = @bx2;
print “@c, $c!\n”;
Will print: Yes No Yes No, No No No

04/19/23 43
Operators: Range Generator . .
– The . . Operator can be used to generate ranges of values (as lists) between two scalar endpoints. This works both for numbers and strings. The rules ffor “incrementing strings” to generate ranges are as with the ++ operator.
@a = 0 . . 4;
@b = “aa” . . “zz”;
print “@a @b[0 .. 4] @b[-4 .. -1]\n”;
will result in 0 1 2 3 4 aa ab ac ad ae zv zw zx zz

04/19/23 44
Operators: Quoting
– Single quotes do not extrapolate (do not expand) variables, double quotes do.
– Double quotes have also several special constructs triggered by using the backquotes (\), for eaxmple \n for a logical new line and \U for uppercasing the value of the following variable.
If ($need eq ‘urgent’) { print “\U$task\n”}
else {print “$task\n”}
04/19/23 45
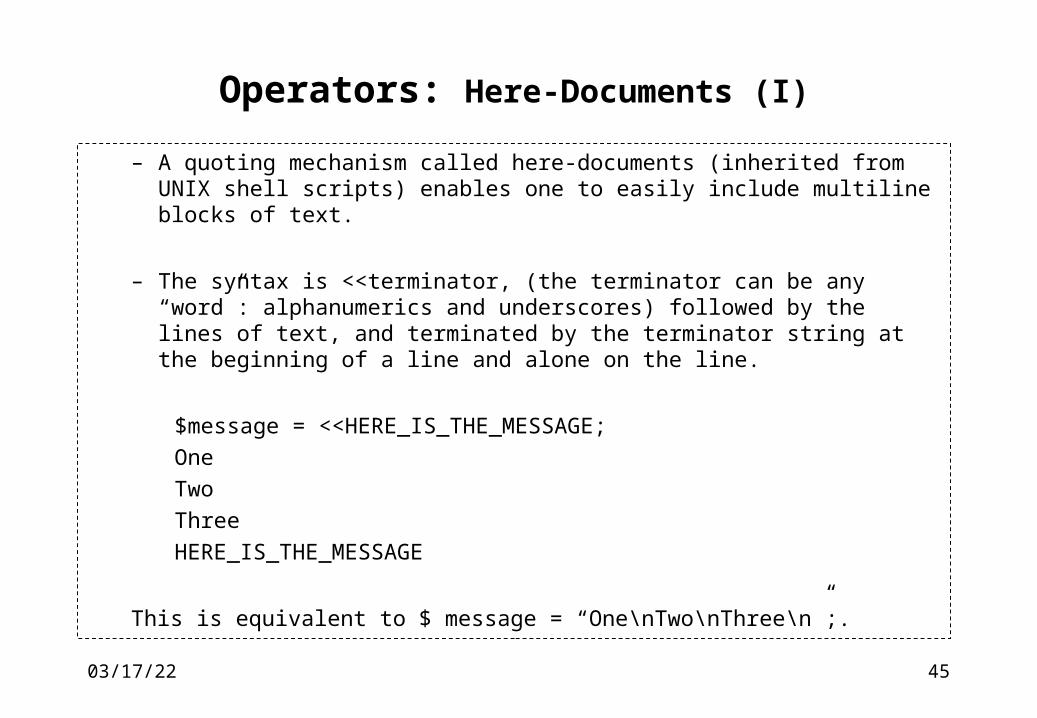
Operators: Here-Documents (I)
– A quoting mechanism called here-documents (inherited from UNIX shell scripts) enables one to easily include multiline blocks of text.
– The syntax is <<terminator, (the terminator can be any “word”: alphanumerics and underscores) followed by the lines of text, and terminated by the terminator string at the beginning of a line and alone on the line.
$message = <<HERE_IS_THE_MESSAGE;
One
Two
Three
HERE_IS_THE_MESSAGE
This is equivalent to $ message = “One\nTwo\nThree\n”;.
04/19/23 46
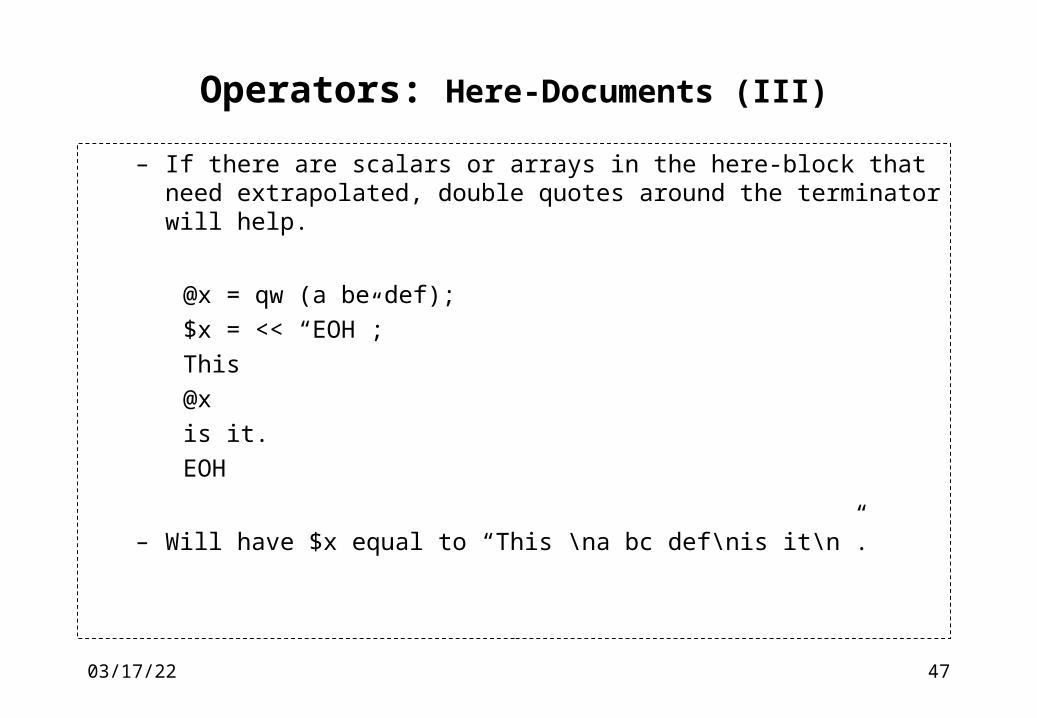
Operators: Here-Documents (II)
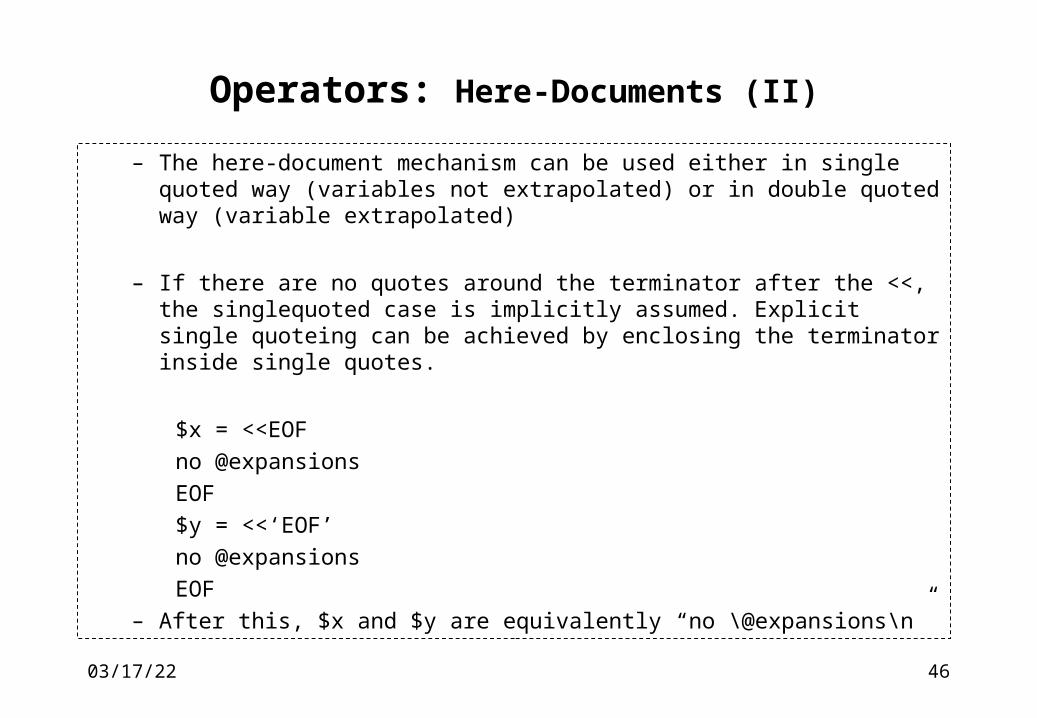
– The here-document mechanism can be used either in single quoted way (variables not extrapolated) or in double quoted way (variable extrapolated)
– If there are no quotes around the terminator after the <<, the singlequoted case is implicitly assumed. Explicit single quoteing can be achieved by enclosing the terminator inside single quotes.
$x = <<EOF
no @expansions
EOF
$y = <<‘EOF’
no @expansions
EOF– After this, $x and $y are equivalently “no \@expansions\n”
04/19/23 47
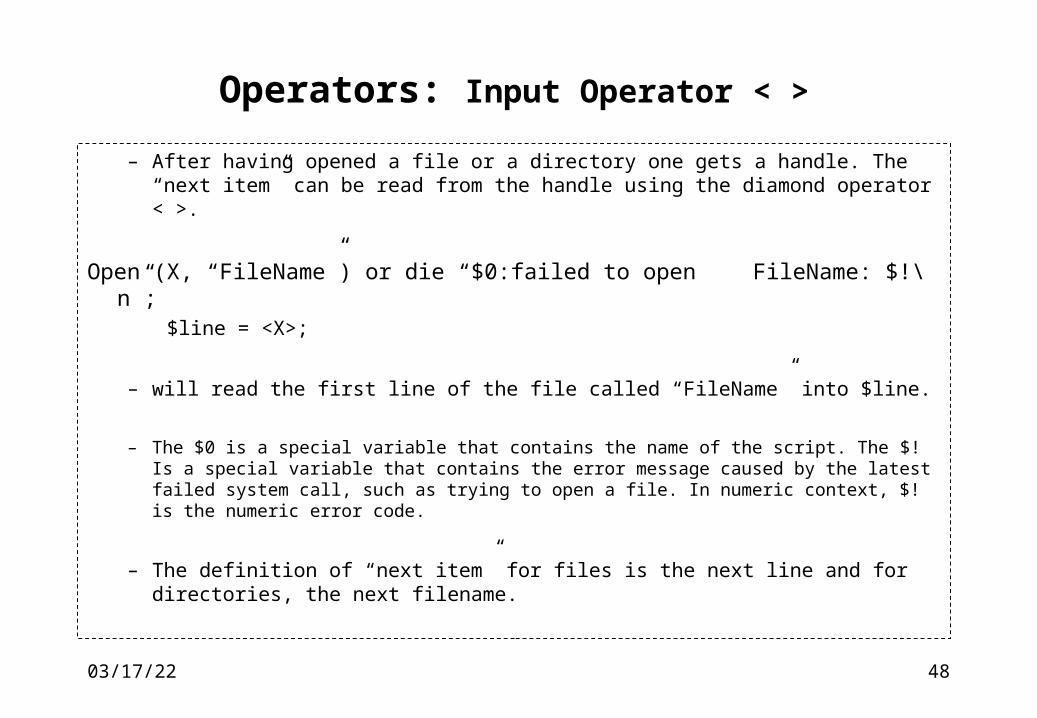
Operators: Here-Documents (III)
– If there are scalars or arrays in the here-block that need extrapolated, double quotes around the terminator will help.
@x = qw (a be def);
$x = << “EOH”;
This
@x
is it.
EOH
– Will have $x equal to “This \na bc def\nis it\n”.
04/19/23 48
Operators: Input Operator < >
– After having opened a file or a directory one gets a handle. The “next item” can be read from the handle using the diamond operator < >.
Open (X, “FileName”) or die “$0:failed to open FileName: $!\n”;
$line = <X>;
– will read the first line of the file called “FileName” into $line.
– The $0 is a special variable that contains the name of the script. The $! Is a special variable that contains the error message caused by the latest failed system call, such as trying to open a file. In numeric context, $! is the numeric error code.
– The definition of “next item” for files is the next line and for directories, the next filename.

04/19/23 49
Control Structures
– A very rich selection of flow control structures is available.
– Control structures control blocks, statements enclosed in { }.
If ($a >= $b +$c) {
$a = 0;
} else {
$a++;
}

04/19/23 50
Control Structures: if, unless, elsif, else
– The if control structure works as might be expected, the following block is executed if the condition is true.
If ($x <=100) { …..}
– The unless is the logical oposite of if: the block follwing it is chosen if the condition is false
unless ($x>100) {……}
if ($x <10) {……)
elsif ($x <20) {…..}
elsif ($x <30) {….}
else {….}

04/19/23 51
Control Structures: Boolean
– If you want to use a “bare” scalar as the condition (in Boolean context), note that there is no need for a separate Boolean type. Any scalar will do as the condition test of the control structures. The rules are as follows:
– Everything is interpreted as a string.
– Numbers are interpreted as strings– undef is interpreted as the empty string “ ”– The strings “0” and “ ” are false
– All other strings are true

04/19/23 52
Control Structures: while, until, do
– The if and unless are one shot; if you want to keep on executing the block of statements, use the while and until
while ($x < 100) {…..}
until ($x >102) { ….}
– If you want to test the condition after at least one round of execution has been completed, use the do
do {…} while ($x <100);
do {…} until ($x >182);

04/19/23 53
Control Structures: for, foreach
– The for can be used as in C to initialize a state, to test for termination of the loop, and do something at the end of each round
for ($i =0; $i <100; $i++) {…..}
– The foreach can be used to iterate over a list of scalars
@a = qw(as we qwe);
foreach (@a) {print $_, “\n”)– what happens here is that the default scalar $_ is aliased in turn to each of the values in the
list
– You can use some other variable
@a = qw(as we qwe);
foreach $b (@a) {print $b, “\n”)

04/19/23 54
Control Structures: foreach Alaising
– The aliasing that takes place in the foreach when iterating over a list is very real: if you change the loop variable, you change the scalar in the list:
@a = qw(abc def ghi);
foreach (@a) {
if ($_ eq “def”){ $_=“xyz”}
print “@a\n”;
– This will output: abc xyz ghi

04/19/23 55
Control Structures: while (<handle>)
– A very common construct is while (<handle>) which means “while there are lines in handle keep reading them into the default scalar, $_”
Open (X, “Input”)
or die “$0:failed to open Input: $!\n”;while (<X>) {
print;
}
close X;
– The print without an explicit argument implicitly outputs the default scalar (to the standard output). The above therefore copies (prints) the contents of the file called “Input” to the standard output, and finally close the file. The above loop is shorthand for
wile($_= <X>){print $_;}

04/19/23 56
Subroutines (I)
– A subrountine is defined with the sub keyword, and adds a new function to your program's capabilities. When you want to use this new function, you call it by name. For instance, here's a short definition of a sub called boo:
sub boo {
print "Boo!\n";
}
boo(); # Eek!

04/19/23 57
Subroutines (II)
– In the same way that Perl's built-in functions can take parameters and can return values, your subs can, too.
– Whenever you call a sub, any parameters you pass to it are placed in the special array @_. You can also return a single value or a list by using the return keyword.
sub multiply{my (@ops) = @_; return $ops[0] * $ops[1];
}
for $i (1 .. 10) {
print "$i squared is ", multiply($i, $i), "\n";}
The my indicates that the variables are private to that sub, so that any existing value for the @ops array we're using elsewhere in our program won't get overwritten.

04/19/23 58
Formats
– If you want to produce text reports that have a certain layout, a feature called formats allows you to create “picture” or templates of the required output formats. The templates contain both the layout and the variables to fill in the layout.
printf, sprintf– The most common formatted printing tool is printf, and its string-producing
twin, sprintf
printf “%5.3f [%-5s] [%5s]\n”, 1/7, ‘abc, ‘def’;
will produce: 0.143 [abc ] [ def].
$s=sprintf“%5.3f [%-5s] [%5s]\n”, 1/7, ‘abc, ‘def’;
print $s;
– The sprintf returns the formatted output string.

04/19/23 59
Formats: Defining (I)
– Formats bare defined using the format keyword.
Format REPORT =
….
..
.
– The REPORT is the name of the filehandle for which the format is to be used. If not specified, STDOUT is assumed.
– The format definition ends with a .(dot) alone at the beginning of a line

04/19/23 60
Formats: Defining (II)
Format REPORT =
….
..
.– The actual format definition, between the format line and the terminating dot,
consists of three kinds of lines:
comment lines, which start begin with # picture lines, which contain format strings argument lines, which the arguments for the formatting strings

04/19/23 61
Formats: Defining (III)
– The picture lines are printed as-is, except for certain special strings that begin with a @ (this is not an array) or ^
• @<<<< to left-align a string• @|||| to center a string• @>>>> to right-aling a string• @#.## to right-align and format a number
– The <<<<, ||||, and >>>> can naturally be as wide as required, not just width of four as shown here. The aligning and centering will be adjusted to match the width of the field.
– The usage of the ^-prefixed field is more complex and explained in more detail in Perl formats, perlform

04/19/23 62
Formats: Defining (IV)
– The argument line contain enough variables, separated with commas, to fill in the picture lines above them
@<<<<<<<<<< @|||||||||| @###.###
$month, $project, $budget_millions

04/19/23 63
Formats: Using
– Using the formats is much easier than defining them. The built-in write function fetches the template and the variables to be used and then outputs the filled-in template.
– The write can be called with or without a filehandle name. With a filehandle name, the format of the said filehandle is used. Without a filehandle, the format of the currently selected default output handle is used. The default output filehandle is STDOUT, but this can be changed using the select() built-in function.

04/19/23 64
Formats: Using
A simple example using formats:
format STDOUT =
[@<<<<<<<<<<<] @#.### [@>>>>>>>>>>>>>>>]
$x, $y, $z
.
($x,$y,$z) = (‘left2, 1/7, ‘right’);
write;
This will produce
[left ] 0.143 [ right]
04/19/23 65
List Processing
– For inspecting and processing lists several useful functions are available.
grep
map
sort
reverse

04/19/23 66
List Processing
– To find elements of a list that satisfy some criterion, use the grep function. It has two slightly different syntax, which work the same way. The two statements below compute the same result.
@b = grep b($_> $max, @a);
@c = grep {$_>$max} @a; #Note: no comma after the block
– Inside the expression or the block the default scalar $_ is aliased to each element of the list (here, an array) in turn. The expression or the expressions in the block are evaluated, and if the last value is true, the element value is returned.
@ = (31,14,15,92,65,35,89,79);
@b = grep {$_ > 50} @a;
print “@b\n”;
This will results in 92 65 89 79

04/19/23 67
Aside: The command Line argument: @ARGV
– This will echo those command line arguments that are greater than the first argument.
my $I = shift;
foreach (@_) {print “$_\n” if $_>$I}
– Outside any subroutine definitions the shift without an explicit array argument array argument will process the @ARGV array, the arguments of the program.

04/19/23 68
List Processing : map-Transform
– To get a copy of a list with the elements transformed through some mapping, use the map function. It has, like grep, two forms, with a block (and no comma) and with an expression (and a comma). The last value will be returned for each element, and from those values a new list can be constructed.
@ = qw(this little piggie went to the market);
@b = map {length} @a;
print “@b\n”;
– This will print 4 6 6 4 2 3 6
– The length without an argument works on the $_. The $_ is again an alias, so if you modify it you’ll modify the elements of the original list.

04/19/23 69
List Processing : foreach Transform
– If you want to modify (distructively) the elements of a list, don’t wast map on it, use foreach
@ = 1 .. 5;
for each (@a) {$_**=$_}
print “@a\n”;
– This will output 1 4 27 256 3125

04/19/23 70
List Processing : sort
– One of the most common tasks in computing is arranging information, sorting. It is so important there is a highly tuned and highly tunable built-in function for it, sort. It has three alternate syntax
@b = sort subname @a
@b = sort { …. } @a;
B= sort @a;
– The first two are equivalent, they carry the comparison as their first argument, either as a name of a subroutine or as an inlined block.
– The third one has an implied sorting order: stringwise comparison.

04/19/23 71
List Processing : sort
– The subroutine or the block get “magically” (meaning that you don’t have to care how they appear in there) passed two arguments called $a and $b. The subroutine or the block must then compare them, and finally returned something less than zero, a zero, or something greater than zero, depending on how the comparands are ordered.
– Examples:
– @b = sort {$a <=> $b} @a; #Sort as numbers.– @c = sort {$b<=>$a} @a ; #sort as descending numbers– @d = sort {lc($a) cmp lc($b)} @a; #Sort case insensiively – #sort keys by numeric values.– @e = sort {$d{$a} <=> $d{$b}} keys %a;
– The $a and $b are passed as aliases, so don’t modify them.

04/19/23 72
List Processing : reverse
– A list can be reversed by the reverse function.
@a = qw(function reverse the by reversed be can list A);
@b = reverse @a;
print “@b.\n”;
– Will print:
A list can be reversed by the reverse function.

04/19/23 73
String Processing: index, rindex
– To find a substring from a string, use the index function. It returns the offset of the substring (more precisely, the offset of the first occurrence). If the substring cannot be found, -1 is returned.
print index(“foobar”, “bar”), “\n”;
print index(“foobar”, “baz”), “\n”;
This will print:
3
-1– The index doesn’t do any pattern matching, just literal strings. To find the last
occurrence of a substring in a string, use the rindex function.

04/19/23 74
String Processing: substr
– To extract and modify substrings by position and length the substr function is available
$a = “I would like to by a camel, please.\n”;
print “I like “, substr($a, 22, 5), “s, of course.\n”;
substr {$a, 22, 5) = “llama”;
print “But $a\n”;
This will output
I like camels, of course.
But I would like to buy a llama, please.
– The offset and length parameter can be negative, which means from the end of the string.

04/19/23 75
String Processing: chomp
– The < > operator leaves the newlines to lines it returns. To remove the newlines use the chop operator:
while (STDIN>) {
chomp; #Operate on $_
print STDERR “[$_]\n”;
}
– This will remove the possible newline, and then print out the reformated lines to the standard error stream.

04/19/23 76
String Processing: split
– With the split you can cut a string into a list. The first argument of split is the separator pattern. The second, optional, argument is the string to be split.
@b = split(/,/,$a);
@c = split /:/;
– Because the first argument is a pattern, full understanding of the split requires understanding of patterns, and therefore we will revisit split later.
There is a commonly used special case, however, using ‘ ‘ as the separator.
@b = split(‘ ‘, @a);– This will split @a by any number of ant whitespace characters and any leading and
tailing empty fields (resulting from leading or tailing whitespace) will be dropped (Not unlike the qw operator).

04/19/23 77
String Processing: join
– You can combine several scalar strings into a single string by using the join function.
$record = join (“, “, @field);
– Note: split and join are NOT symmetrical because the separator of split is a pattern, not a literal string, as the separator of join is.

04/19/23 78
String Processing: reverse
– The reverse function applied on a scalar produces a scalar reversed characterwise.
@b = reverse (“yes or no.”);
print $b, “\n”;
This will print
.on ro sye

04/19/23 79
Pattern Matching
Matching
– Perl has very powerful pattern matching capabilities.
– The basis of pattern matching are the regular expressions.
– Regular expressions are a language of their own within Perl.

04/19/23 80
Matching: The m operator
– The m operator is used to match a pattern against a piece of text, a scalar. It returns true if a match can be found, false if not.
– A strange thing about the m operator is that the m is quite often not written at all, but instead written like this
/pattern/
– That is, the pattern between forward slashes. The pattern can contain even whitespaces, and the whole thing is still understood as a pattern matching operator.
– To better understand how the m operator works and how it can be expressed without the m, we need to take another look at the quoting rules.

04/19/23 81
Aside: Generalized Quoting (I)
– The ‘single quotes’, “double quotes”, and ‘backquotes’, are in fact just “syntactic sugar” for the real quoting operators, q, qq, and qx.
– The syntax of the quoting operators is very flexible. Because which characters should delimit the quote depends on the contents in it (you do not want to use as a delimiter a character that appears in the quote, unless you are fond of using backslashes). The delimiters are selected “dynamically” based on which character follows the quoting operator. Either the delimiters can be of the paired kind (like the parentheses), or they can be the same character (like the usual quotes). Examples:
$a = q(this is a single-quoted);
$b= qq[this is double quoted, @variables expand];
$c = qx ! Echo this goes to the operating system!;
– The qw we have met earlier is another example of the quoting operators, a quoting construct produces a list.

04/19/23 82
Aside: Generalized Quoting (II)
– The matching operator m has one double-quotish argument.
m {pattern}
m /pattern/
– The substitution operator s has two double-quotish arguments
s /pattern/substitute/
s (pattern)(substitute)

04/19/23 83
Matching: Binding
– The string to be matched against is either the default scalar $_ or it can be something else, by using the binding operator =~ or its logical oposite, the !~.
– By using the default scalar and leaving out the m of m, we arriuve at the very common idiom
if (/pattern/) {……}
– written out in full that would be
if ($_ =~ m/pattern/) {……}

04/19/23 84
Matching: The Basic (I)
– The basic set of regular expression matching operators is the triad
. any character
* repeat
| alternative
– With these and the parentheses for grouping, you can already construct perfectly fine regular experessions.
– Alphanumeric characters like a, b, 1, 2, match themselves
– The . Does not really match any character: rather, it matches any non-newline character.

04/19/23 85
Matching: The Basic (II)
– Regular expressions matches sub-strings, not whole strings, unless anchored to do otherwise.
– In other words, the pattern need not match all of the target string. For example, /q/ will match the string “sesquipedalian” just fine.
– Neither do regular expressions care about “words” (unless instruct to), the input string is just a flat string of characters with no implicit tokenization.

04/19/23 86
Matching: The Basic (III)
Some examples:
/apple/ #matches ‘apple’
/bana*/ #matches “ban”, “bana”, “banaa”, “banaaaa”, ….
/ba(na)*/ #matches “ba”, “bana”, “banana”, “bananana”, ….
/(orange|cheery)/ # matches “orange” or “cherry”
/(pear|plum)*/ #matches e.g. “pearpear”, or #“plumpear”, ….
– Beware of further punctuation characters: many of them have special meanings in regular expressions, collectively they are called metacharacters. If you want to match a punctuation character as itself, protect it by prefixing it with a backslash: \* matches the literal *

04/19/23 87
Matching: The Anchors
– If you want to match only at the beginning of the target string, or only at the end, or at both (this is what you might call “match whole words”), use the anchoring meta-characters.
^ beginning
$ end
– For example /^abc/ will match abc only at the beginning of the string. The $ matches either at the end of the string (if there is no newline at the end) or before the last newline, if that is the last character of the string. If you want to match for a new line, use /n.
– Again, if if you need to have these character matched literally, backslash them: \^, \$
– Anchors are the most often used assertions: they do not themselves extend the match but they test for the validity of a (set of) conditions.

04/19/23 88
Matching: Character Classes
– You could use the alternation, |, for single characters, but that would be awefuuly inefficient. If you have a known set of single characters, use character classes.
– Enclose the set of characters inside square brackets, [ ], and you are done. Inside those brackets the metacharacters lose their specialness, for example the dot, ., is just a dot, not any more matche-any-character. For example [ab*] will match any of the a, b, or *.
– If you need to match “any character except these”, you can negate the character class by putting ^ as the first thing after the opening bracket, for example [^abc] will match any character that is not a, b, or c.

04/19/23 89
Matching: Built-In Character Classes
– For certain commonly used character classes and their negations there are shorthands available.
\w any alphanumeric or the underscore
\d any decimal digit
\s any space character
\W any non-\w
\D any non-\d
\S any non-\s
– These can be used either inside or outside the [] character classes.
– Note that the definition of \w(and \W) depend on you locale. If you want, say, to be understood as a \w character, you need to have you locale correctly set up and you must say use locale, at the top of your script. (The locale system is a UNIX only feature)

04/19/23 90
Matching: Further Repetition
– With the basic repetition operator * and alternating (|) with an empty string you can construct repetitions of zero or more, one or more, …, but the expression can get rather ugly. Use instead the following handy postfix notations:
? Not at all or once
+ Once or more
{} {n}, {min,}, {min, max}

04/19/23 91
Matching: Capturing Sub-matches
– Often you will want to save parts of the match to process them further.
– Parentheses let you do that.
– Each sub-match corresponding to a parenthesized sub-pattern is saved a way to a special variable baned $1, $2, and so on.
“thx1138”=~/([a-z]+) - (\d+)/
– After this:
$1 = “thx”, and $2 = “1138”

04/19/23 92
Matching: Word Boundary Assertions
– If you need to match at word boundaries, in other words, at places where a “word”, a string of alphanumeric characters begins or ends, you can use the word boundary assertion \b.
“to be or not to be” = ~/\b(..t)\b/;
– This will save “not” to the $1 because that is the only place where word boundaries are three positions apart and there is an t at the third mid-position.
– If you want to match at a non-boundary, use \B.

04/19/23 93
Matching: Not so fast: Stingy Matching
– The default behaviour of a regular expression is to gobble up as much as possible, that is, as long a match as possible. In other words, each repetition operator extends as far as possible. This is called greedy matching.
– Sometimes this is not what you want. If you want to stop as soon as possible, you can use stingy matching. Changing the repetition operators to stingy is as simple as appending a ? to them: *?, ??, +?.
Example:
“(a,b) (c,d)” = ~ / \((.*?)\) /
– This will set $1 = ‘(a,b)’, not ‘(a,b) (c,d)’. The * will stop at the first ) instead of continuing to match all the way until the last possible ) at the end of the string.

04/19/23 94
Matching: Case (In)Sensitiveness
– Often the case of letters may different from what you would expect. The matching operator can have modifies after the “closing quote” that affect its behaviour. One possible effect is to ignore any case differences. For example so that Perl and perl are considered equal, the modifier for this is i.
– This
/pc/i
– will match
pc, Pc, pC and PC

04/19/23 95
Matching: Non-Capturing Sub-matches
– Sometimes you need to use parentheses just for grouping (to use the | alternation, for example) but you do not want to collect the sub-matches. The (?: …) construct is for this situation: it is exactly like the ordinary parentheses but the sub-matches are not recorded into the $1 etc.
While (<>) {
print if /^(?:de|in|im|un)/;
}
– This is not set $1.
– Note also the special < > structure. Its meaning is: “iterate over all command line arguments (@ARGV), interpret them as filenames, open the files, and iterate over all the lines in those files”.

04/19/23 96
Matching: I want them all: Global Match
– Normally a regular expression matches only once, returning the first successful match.
– However, if you want to keep matching, you can do that using the “global” modifier, /g. The matching remembers the position it was in a scalar which means that you can use the /g match as the control condition of a repetitive control structure such as while
while (/(\d+)/g) {
print $1, “\n”;
}– In addition to the usual Boolean (scalar) beharviour of matching operator, the /g
modifier introduces a new behaviour: in list context all the posiible matches are returned.
@m = /(\d+)/g; – This will return all the numbers of $_ and assign them to @m.

04/19/23 97
Matching: Iterative Matching
– If you need to match exactly where the previous /g (if any) left off, you can use the \G assertion.
while (/ \G(\d+)./g){
print $1, “\n”;
}
– This will match only as long as the numbers are separated by one character. The offset of a match can be returned (and forged!) with the pos function.

04/19/23 98
Matching: Multi-line Matching
– Normally, regular expression match only within one line, but it is possible to match over multiple lines.
– First you need to get a “multi-line” scalar. If you are reading your text to be matched against from file, the easiest way to do that is to set the special variable $/ as necessary. This variable controls what is a “line”. If you set it to ‘’ (an empty string), the whole paragraph (text block separated by empty lines) are read. If you set it to undef, the whole file is read as one big scalar. You will most probably want to use local to localize your change of /$.
– Secondly, you need to decide what do you actually mean by multi-line matching. Do you mean that the dot (.) should match also newlines? Or do you mean that ^ and $ should match at the “internal” new lines, not just at the string beginning and end?
– For these two interpretations of “multi-line”, two different modifiers are available: /s and /m. They can be used simultaneously, as is usual with modifier.: /gims is perfectly fine.
– /m Treat target string containing newline characters a multiple lines. In this case, the anchor ^ and $ are the start and end of a line: \A and \Z anchor to the start and end of string, respectively
– /s Treat a target string containing newline characters as a single string: I.e. dot matches any character including newline.

04/19/23 99
Matching: Multi-Line Assertions
– Because the /m changes definitions of ^ and $ but you might still need the old definitions, they are available via alternative assertions:
\A beginning of the string
\Z end of the string, or before newline at the end
\z end of the string
– The first two are like the old ^ and $, the last one is like (\Z|\n)

04/19/23 100
Matching: split Revisited
– Now we know enough of matching to review split
– The first argument of split is a pattern, like the operand of the m operator. For example:
@f = split (/,\s*/, $s);– will split on a comma, followed by any amount of white space.
– Normally the delimiters corresponding to the pattern are thrown away, but if you want to include the delimiters, surround the pattern with parentheses:
$s = “foo:bar; zap:foo”;
print join (“, “, split(/([:;])/, $s)), “\n”;– This will split on colons and semicolons, but it will also return those delimiters
as list elements: foo, :, bar,;,zap,:,foo.

04/19/23 101
Matching: Limits of regular expressions
– Though regular expressions are powerful, there are some (seemingly) simple tasks they cannot do.
– Most importantly, they cannot match “balanced expressions”. For example ordinary mathematical expressions, which can have arbitrarily nested structures, cannot be matched using regular expressions
– To do that kind of paring, more than just patterns is needed: the context (for example, how deep are we right now, and inside which structure) need to be known, and regular expressions do not give that.

04/19/23 102
Substitution: The s operator
– The substitution operator s operator has two quoted arguments: the pattern and the substitution. The pattern part is exactly as with the m operator, the substitution is a double-quotish string in which you can use sub-matches like $1 from the pattern side.
– At the pattern side you can also use constructs like \1, \2, and so on, that refer to the same sub-matches as $1, $2. The \n refer to the on going match, while the $n would refer to the sub-matches of the previous match. Do not use the \n constructs outside the pattern side of s.
– For example:
s/(gold|silver|platinum)/precious metal/;
– This will replace in $_ the first occurrence of either gold, silver or platinum with precious metal.

04/19/23 103
Substitution: Global Substitution
– For the substitution operator the “global” modifier /g means to substitute all occurrences of the pattern with the substitution, not just the first one.
s/(gold|silver|platinum)/precious metal/g;
– This will replace in $_ all occurrences of either gold, silver, or platinum with precious metal.
– You will probably want to use \b here to avoid false substitutions like precious metalfish and quickprecious metals.

04/19/23 104
Substitution: Evaluating Substitution
– The substitution side of the s operator is already in double-quotish context so all variables are extrapolated, but sometimes you need to evaluate a piece of code. For this you can use the /e modifier
s/(\w+)/reverse($1)/eg;
– This will replace all “words” with their reverses
– The /e even stacks: you can have arbitrarily many of them: /eeee

04/19/23 105
Translation (I)
– If you want to map characters, you can use the tr operator
– Like the s operator, the tr has two quoted arguments, but unlike with the s, both of the arguments of the tr are single-quotish. They also are not regular expressions.
– The first argument is called search list, and the second argument is the replacement list.
– Both can have a range by simply putting a - between two characters.

04/19/23 106
Translation (II)
– To complete the search list, add the /c modifier.
– If the translated character is not found in the replacement list (because the replacement list is too short), and the /d modifier is used, the translated character is deleted from the result. If the /s modifier is used, duplicated translated characters squashed into one.
#A Caesar cipher, a.k.a. rot13, in $_
tr/A-MN-Za-mn-z/N-ZA-Mn-za-m/;
$a=~tr/ //s; #squash multiple spaces into one in $a.
tr/0-9/ /d;#Replace all non-digits with space in $_
– You can count the number of times a character occurs by translating it ito itself, because the tr returns the number of translations made.
$bangs = ($text = ~/tr/!/!/);
04/19/23 107
File I/O (Section 6 of Notes)
To read from or write to a file, you have to open it.
When you open a file, Perl asks the operating system if the file can be accessed - does the file exist if you're trying to read it (or can it be created if you're trying to create a new file),
and do you have the necessary file permissions to do what you want?
If you're allowed to use the file, the operating system will prepare it for you, and Perl will give you a filehandle.
The following statement opens the file log.txtusing the filehandle LOGFILE:
open (LOGFILE, "log.txt");

04/19/23 108
File I/O (Section 6 of Notes)
open (LOGFILE, "log.txt") \or die "I couldn't get at log.txt";
$title = <LOGFILE>; print "Report Title: $title"; for $line (<LOGFILE>) { print $line; } close LOGFILE;

04/19/23 109
File I/O (Section 6 of Notes)
Writing files
You also use open() when you are writing to a file. There are two ways to open a file for writing: overwrite and append.
To indicate that you want a filehandle for writing, you put a single > character before the filename you want to use.
open (OVERWRITE, ">overwrite.txt") \or die "$! error trying to overwrite";# The original contents are gone.
This opens the file in overwrite mode.

04/19/23 110
To open it in append mode, use two > characters. open (APPEND, ">>append.txt") \or die "$! error trying to append";# Original contents still there, #we're adding to the end of the file
Once our filehandle is open, we can use the humble print statement to write to it. Specify the filehandle you want to write to and
a list of values you want to write:
print OVERWRITE "This is the new content.\n";print APPEND "We're adding to the end here.\n”;print APPEND "And here too.\n";
File I/O (Section 6 of Notes)