intro to: “ultra-low power, ultra-high bandwidth density...
TRANSCRIPT

<Insert Picture Here>
Intro to: “Ultra-low power, ultra-high bandwidth density SiP interconnects”
Ashok V. Krishnamoorthy, Ron Ho, John Cunningham, Xuezhe “Fafa” Zheng, Jon LexauOracle Labs
This work was supported in part by DARPA under contract HR0011-08-9-0001 . The views, opinions, and/or findings contained in this article/presentation are those of the author/presenter and should not be interpreted as representing the official views or policies, either expressed or implied, of the Defense Advanced Research Projects Agency or the Department of Defense

Optical link penetration
1
10
100
1000
10000
100000
0.0001 0.001 0.01 0.1 1 10 100
Data Rate (Gb/s)
Dis
tanc
e (m
)
MMF
SMF
Copper
Backplanes
Coax (1970s)
100Gb/s.m
10Gb/s.m
1000Gb/s.m
100Gb/s * m
Companies leading the way QDR/FDR/EDR: Tyco, Finisar, Emcore, FCI (Merge), Avago, Molex, Luxtera …
Krishnamoorthy et al., IEEE JSTQE, Vol. 17 (2),p. 357-376, March/April 2011
Approved for Public Release: Distribution Unlimited

• Compute density (& functionality) improvements> Want higher performance/area (volume) at manageable thermal density
• Power improvements> Want higher BW/Watt to achieve breakthrough performance on key benchmarks
• Productivity (programming) improvements> Want better bisection bandwidth & random memory access for improvements in
development & execution time productivity
• Memory latency improvements> Want reductions in memory-access latency over all-electrical systems
Better Interconnects, Better Systems
Approved for Public Release: Distribution Unlimited

Processor I/O scaling
• Consistent I/O bandwidth growth: ~2x every 2 years– Need >20Tbps I/O soon
• Packaging falling behind historically– Limited high speed pin count pushes for higher data rates
0.01
0.1
1
10
100
1000
2001 2003 2005 2007 2009 2011 2013 2015 2017 2019
Year of Revenue Release (Aprox.)
Tota
l Off-
chip
I/O
Ban
dwid
th[T
bps]
1000
10000
100000
1000000
10000000
100000000
Num
ber o
f pin
s of
f pac
kage
IntelAMDSun/OracleIBMVirtex
Oracle T3
IBM P7
IO Scaling
Data after D. Huang., IEEE HSD Workshop 2011, Santa Fe
Approved for Public Release: Distribution Unlimited

Lots of work trying to solve this problem…
• Integrate vertically with TSVs (build up)– Complex packaging and assembly, but it will be here soon– Thermal issues limit the architectural use cases (memory)
• Integrate horizontally with fine pitch IO (build out)– Complex package, assembly, and test with MCMs
• Known-good die issues
Source: IBM Source: Samsung
Approved for Public Release: Distribution Unlimited

An ideal (?) solutionEnable systems with chips that build both up and out
• Aggregate TSV’ed chip stacks with a fine pitch IO– But without conductive (soldered) attachments, to help yield– Needs a chip-to-chip IO with enormous BW and low energy
6Approved for Public Release: Distribution Unlimited

0.01
0.1
1
10
100
1000
0.001 0.01 0.1 1 10 100 1000
Link
Ene
rgy
Effic
ienc
y (p
J/bi
t/m)
Link Distance (m)
Si Target
System Target: <<1 mW per Gigabit/s per meter
Electrical links today
Improving link energy efficiency
100fJ/bit (Core)500fJ/bit (Core - L3 cache & MM)
2pJ/bit (Core –Distant Memory)
Approved for Public Release: Distribution Unlimited
VCSEL links today
Krishnamoorthy et al., IEEE JSTQE, Vol. 17 (2),p. 357-376, March/April 2011

One possibility: optically-enabled siliconCreate enormously dense IO channels over fast optical media
• Optical channels are an interesting solution– Multiple λs in a single waveguide – more data BW & WDM routing– Better energy/distance, bandwidth/area and bandwidth-distance
• We need an electrical-to-optical interface – Use a “bridge chip” face-bonded to a CPU or mem controller– Optical devices & waveguides on bridge chips can point down– “Optical proximity communication” – w/ face-to-face couplers
Krishnamoorthy et al., Proceedings of the IEEE, 2009Cunningham et al., IEEE Group IV Photonics, 2008
8Approved for Public Release: Distribution Unlimited
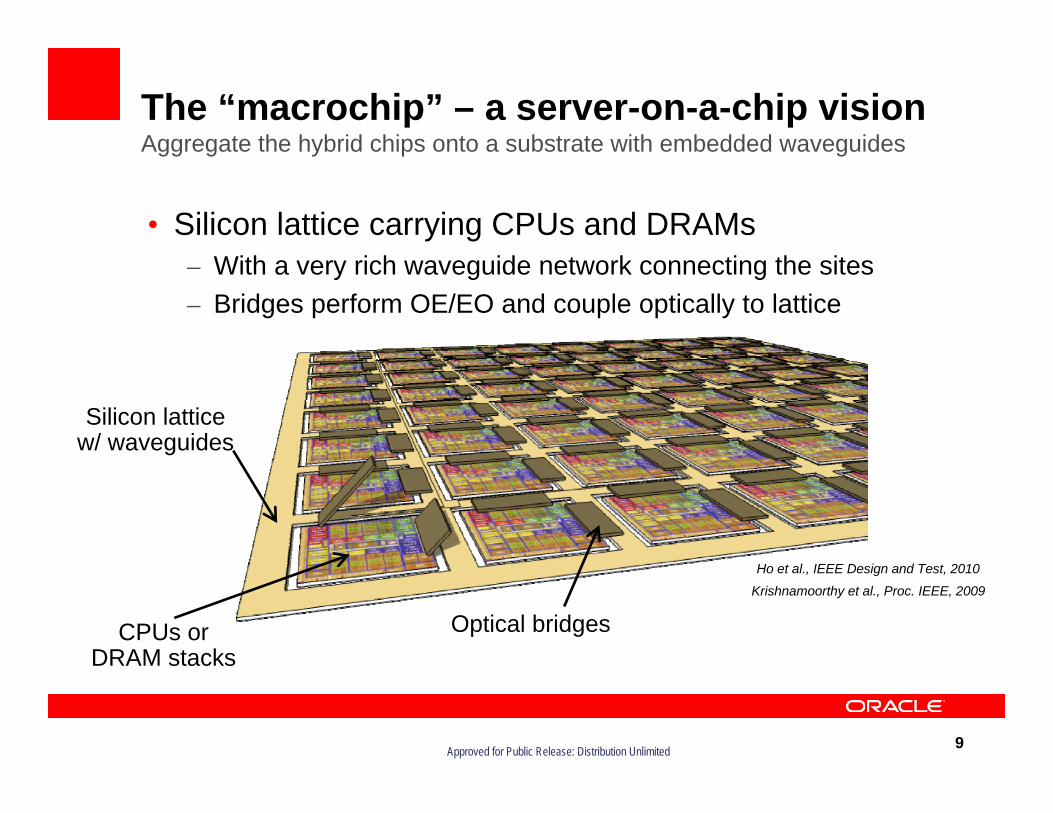
The “macrochip” – a server-on-a-chip visionAggregate the hybrid chips onto a substrate with embedded waveguides
• Silicon lattice carrying CPUs and DRAMs– With a very rich waveguide network connecting the sites– Bridges perform OE/EO and couple optically to lattice
Silicon lattice w/ waveguides
CPUs or DRAM stacks
Optical bridges
Ho et al., IEEE Design and Test, 2010
Krishnamoorthy et al., Proc. IEEE, 2009
9Approved for Public Release: Distribution Unlimited

And the most important part: the link
• The goal is to hit 0.3 pJ/b (on-chip) link energy consumption– Commercial electronic links today around 10-20 pJ/b
• Including laser conversion efficiency, we want to hit <1pJ/bit• We have demonstrated Tx+Rx< 0.35 pJ/b thus far (2011)
• Good start but ”miles to go before we sleep …”Zheng et al., OFC Postdeadline 2011
(JSTQE 2012 accepted)
10Approved for Public Release: Distribution Unlimited