interactions between human–human multi-threaded dialogues and driving
TRANSCRIPT

ORIGINAL ARTICLE
Interactions between human–human multi-threaded dialoguesand driving
Andrew L. Kun • Alexander Shyrokov •
Peter A. Heeman
Received: 14 March 2011 / Accepted: 17 July 2011
� Springer-Verlag London Limited 2012
Abstract In-car devices with speech user interfaces are
proliferating. How can we build these interfaces such that
they allow human–computer interactions with multiple
devices to overlap in time, but without interfering with the
driving task? We suggest that interface design can be
inspired by the way people deal with this problem in
human–human dialogues and propose discovering human
dialogue behaviors of interest through experiments. In this
paper, we discuss how to design an appropriate human–
human dialogue scenario for such experiments. We also
report on one human–human experiment, in terms of the
dialogue behaviors found, and impact on the verbal tasks
and on driving. We also offer design considerations based
on the results of the study.
Keywords Speech user interfaces � Multi-threaded
dialogue � Spoken task � Driving simulator
1 Introduction
While driving, people still want to interact with a computer
to accomplish various tasks such as getting navigation
information, selecting music, or reading email or text
messages. Interacting with a graphical user interface to
accomplish these tasks can be dangerous, as it requires
taking your hands and eyes away from the manual-visual
task of driving. Speech interaction with a computer does
not require the use of the hands and eyes, with the possible
exception of operating a push-to-talk button. Thus, speech
is a viable human–computer interaction mode in a vehicle.
However, using speech as an interaction mode while
driving needs to be done with care. For example, a number
of researchers found that conversing on a mobile phone
degrades driving performance, even when the phone is
used in hands-free mode [1]. In our own work, we found
evidence that certain characteristics of a speech user
interface, for example, low recognition rate [2], can neg-
atively influence driving performance.
Speech interfaces have been used for performing a sin-
gle task at a time, where the user finishes with one task
before moving on to the next one. However, real-time tasks
might require the user’s interactions on different tasks to
overlap in time. For instance, a police officer might need to
be alerted to a nearby accident while accessing a database
during a traffic stop, or a driver might need driving
instructions while reviewing appointments in a calendar.
We refer to the speech interaction about each individual
task as a dialogue thread and say that together they con-
stitute a multi-threaded dialogue [3]. The dialogue threads
can overlap with each other in time. Our long-term goal is
to build a spoken dialogue system that allows the user to
complete task-oriented multi-threaded spoken dialogues
without negatively impacting performance on the driving
task.
To build such a system, we need to know what types of
dialogue behaviors the system should engage in. We pro-
pose that we should identify these behaviors by observing
A. L. Kun (&) � A. Shyrokov
Electrical and Computer Engineering Department, University of
New Hampshire, Kingsbury Hall, Durham, NH 03824, USA
e-mail: [email protected]
A. Shyrokov
e-mail: [email protected]
P. A. Heeman
Biomedical Engineering Department, Center for Spoken
Language Understanding, Oregon Health and Science
University, Beaverton, OR 97006, USA
e-mail: [email protected]
123
Pers Ubiquit Comput
DOI 10.1007/s00779-012-0518-1

the way humans manage dialogues between drivers and
one or more remote or co-present conversants. The
behaviors can be characterized by different utterance types,
pauses, and speaking rates, as well as higher-level dialogue
reasoning. We can also expect to find patterns in how
conversants alter their speech as the driving difficulty
changes. The hypothesis that we can use behaviors
observed in human–human dialogues between a driver and
a co-present conversant is supported by evidence that the
presence of a passenger, and thus very likely conversing
with a passenger, reduces the probability of a collision [4].
In this paper, we focus on laying the groundwork for in-
car speech user interfaces capable of carrying out multi-
threaded spoken dialogues with drivers. After an overview
of related research, we first propose a set of considerations
that researchers should take into account when designing
spoken tasks aimed at exploring human–human dialogue
behaviors. Next, we report on the results of an experiment
exploring human–human behaviors in multi-threaded dia-
logues while one of the conversants is operating a simu-
lated vehicle. We discuss the effects of driving on dialogue
behaviors and the effects of dialogue on driving. Finally,
we discuss design implications for in-car speech systems as
well as future research directions.1
2 Background
In our previous work, we studied how people manage
multi-threaded dialogues. As part of that work, we
explored different verbal tasks to use. In our first experi-
ments, we had participants interact with an actual spoken
dialogue system [6]. Due to the complexity involved in
building a functional system, participants completed simple
tasks with the computer, including addition, circular rota-
tion of number sequences, discovery of short letter
sequences, and category-matching word detection. How-
ever, participants did not find these tasks engaging, and the
resulting dialogues did not seem to capture the complexity
of behaviors we expected to see in more realistic tasks. In
some of the pilot experiments, we tried to motivate par-
ticipants by telling them they were playing a game and
their goal was to solve as many tasks as possible; however,
even this did not seem to help.
To make the tasks more engaging and realistic, we
turned our attention to human–human dialogues. We gave
conversants an ongoing task in which they had to work
together to form a poker hand [3]. Each conversant had
three cards, and they took turns drawing and discarding a
fourth card. Conversants could not see each other, nor
could they see the cards in each other’s hands. They
communicated via headsets and used speech to share what
cards they had and what poker hand to try for. Periodically,
one of the conversants was prompted to solve a real-time
task, that of determining whether the other conversant had
a certain picture displayed on her screen. The urgency of
the real-time task was an experimental variable: conver-
sants were given either 10, 25, or 40 s to complete it. To
make the task engaging, conversants received points for
each completed poker hand and each picture task. We
found that this setup elicited both rich collaboration for the
card game [7] and interesting task management. The
problem is that this setup, with the ongoing task having a
minor manual-visual component, is not representative of
the types of tasks that are of interest to us, in which the
ongoing task is exclusively verbal and where the user is
also engaged in the separate manual-visual task of driving.
For our next study, we used a navigation problem as the
ongoing task [8], inspired by the Map Task experiments
[9]. One conversant (the driver) operated a simulated
vehicle and a second (the dispatcher) helped the driver
navigate city streets. The conversants could not see each
other and communicated via headsets. Unknown to the
dispatcher, some of the city streets were blocked by con-
struction barrels, and so the driver was unable to follow
some of the dispatcher’s instructions. The conversants thus
collaborated to find an alternate route. Periodically, the
driver was prompted to initiate a short real-time task with
the dispatcher. As in the poker-playing task, the prompt
included information about the urgency of the real-time
task. Although this setup elicited rich task management
behavior, participants do not seem to build up discourse
context as they converse. This is because the verbal com-
ponent of the navigation task is more like a series of sep-
arate short real-time tasks. Thus, these verbal tasks might
lack the difficulty that longer verbal tasks might pose.
Villing et al. [10] performed human–human multi-
threaded dialogue experiments in a real car on city roads.
The driver and a passenger were given a navigation task
and a memory task. The participants were not restricted on
how to complete these tasks. Video recordings of the par-
ticipants and the road were taken. The authors found that
drivers and passengers used specific Swedish cue phrases
in only 17 and 12 % of topic shifts, respectively. In further
research, Lindstrom et al. [11] looked at speech disfluency
rates as a function of cognitive load. The authors found that
when the driver is under high cognitive load, the passen-
ger’s disfluency rate decreases. This indicates that the
passenger makes an attempt to be particularly clear and
concise when he perceives that the driver is in a difficult
situation. In subsequent work, Villing [12] found that
passengers do not interrupt or resume dialogue threads
when the driver is subject to high driving-induced
1 Most of this work is derived from the second author’s Ph.D.
dissertation [5].
Pers Ubiquit Comput
123

workload. Their research utilized multiple modalities for
driver-passenger communication and focused on natural
language features. In contrast, our research focuses on a
single modality of interaction between the participants and
has more structured tasks.
Vollrath [13], in work on single-threaded dialogues,
investigated the influence of spoken tasks on driving per-
formance by examining a number of different studies. He
used Wickens’ multiple resource model [14] as the
framework to process the data from the studies. One of his
conclusions was that, to minimize effects of verbal tasks on
driving, the tasks must be simple and short. However, tasks
that are of interest to users are often neither short nor
simple. We are interested in learning how humans manage
complex dialogues and applying the lessons learned to
designing safe in-car human–computer interaction.
3 Designing spoken tasks
Based on our experiences with the studies described in
Sect. 2, we set forth the following requirements [15] for
verbal tasks to be used in human–human experiments in
general and in our experiment in particular:
• Tasks are engaging. Real tasks that users want to
perform will undoubtedly be engaging and will have
the potential to divert users’ attention from driving
[14], [16].
• Tasks are relatively complex, and require both partic-
ipants to participate. Tasks that can be accomplished
with one of the participants speaking little, or not at all,
would provide little data to evaluate different dialogue
behaviors in human–human spoken interaction.
• Tasks allow scoring participant performance. This will
allow us to quantitatively evaluate participant perfor-
mance under different driving task difficulty levels, and
when testing the impact of different dialogue behaviors.
• Tasks have identifiable discourse structure. This will
allow us to easily analyze how the conventions interact
with discourse structure. In particular, tasks should give
rise to adjacency pairs, such as question–answer pairs,
as these are common in human–machine spoken
interaction; therefore, learning more about this partic-
ular type of interaction will be valuable.
Wickens’ multiple resource model [14] indicates that
verbal tasks should not interfere with driving significantly.
However, studies such as Strayer and Johnston’s [16]
clearly show that verbal tasks that are engaging have the
potential to divert the user’s attention from the driving task.
This effect presents a challenge to Wickens’ multiple
resource model. Hence, as a fifth consideration, experi-
menters need to consider the extent of interference between
the driving task and the verbal tasks.
4 Experimental setup
We now describe our study that explored multi-threaded
human–human dialogues. In this study, pairs of participants
(driver and dispatcher) were engaged in two spoken tasks
and one of the participants (the driver) also operated a
simulated vehicle. One spoken task was the ongoing task,
and it was periodically interrupted by another spoken task.
The interruptions forced participants to switch between
different dialogue threads. The two spoken tasks follow the
requirements from the previous section.
The driver operated a high-fidelity driving simulator
(DriveSafety DS-600c), with a 1808 field of view, realistic
sounds, and vibrations, a full-width car cab, and a tilting
motion platform that simulates acceleration and braking
effects. We recorded driving performance measures such as
lane position and steering wheel angle. We also recorded
the drivers’ eye gaze direction and pupil diameter using a
Seeing Machines faceLab 4.6 stereoscopic eye tracker
mounted on the dashboard.
As shown in Fig. 1, the participants could not see each
other and communicated solely through headsets and we
recorded their dialogues. The dialogues were supervised by
the experimenter to enforce time limits on the verbal tasks.
The experiment was completed by 16 pairs of partici-
pants (32 participants). Each pair was formed by two
people who had never met each other before. Participants
Fig. 1 Driver and dispatcher
Pers Ubiquit Comput
123

were between 18 and 38 years of age (average age was
24 years) and 28 % were female.
4.1 Driving task
The primary task of the drivers was to follow a vehicle
while driving responsibly. They drove on two-lane, 7.2 m-
wide roads in daylight. The lead vehicle travelled at 89 km/
h (55 mph), and it was positioned 20 m in front of the
participant. There was also a vehicle 20 m behind the
participant’s car. No other traffic was present on the road.
The difficulty of the driving task is influenced by factors
such as road type, traffic volume, visual demand of route
following, etc. In this research, we only manipulated visual
demand of route following. This can be accomplished by
controlling the radius of curves [17]. Sharper curves cor-
respond to increased visual demand. We created routes
with six straight and six curvy road segments with straight
and curvy segments alternating. Each segment was long
enough for participants to complete an ongoing and an
interrupting task, allowing us to evaluate task-switching
behavior for the given visual demand level.
4.2 Ongoing spoken task
Our ongoing spoken task was a parallel version of twenty
questions (TQ). In TQ, the questioner tries to guess a word
the answerer has in mind. The questioner can only ask yes/
no questions, until she is ready to guess the word. In our
version, the two conversants switch roles after each ques-
tion–answer pair is completed. The commonality between
their roles allows us to contrast their behaviors. Words to
guess were limited to a list of household items (hair dryer,
TV, etc.). In order to minimize learning effects and to make
the dialogue pace more realistic, we trained participants to
use a question tree to guess the objects. For example, each
item was in one of three rooms, thus the first fact to be
established was the room where the object was located.
In parallel twenty questions (PTQ), when a participant in
one TQ game ventured a guess (right or wrong), that game
stopped, but the other TQ game continued until the other
participant also ventured a guess. Furthermore, a PTQ game
stopped if the time limit was exceeded. Thus, a PTQ game can
result in (a) both participants guessing their word correctly,
(b) one participant guessing correctly and the other guessing
wrong, (c) one participant guessing correctly and the other
running out of time, (d) one participant guessing wrong and
the other running out of time, (e) both participants guessing
wrong, or (f) both participants running out of time. These
scores can be translated into scores for the individual TQ
games of (1) guess correctly, (2) guess wrong, or (3) timeout.
Also, as we wanted to focus on task switches and not
negotiations on which conversant should start, the PTQ game
was always started with the dispatcher asking a question first.
The words to be guessed were presented to the participants
visually. We showed words to the driver just above the
dashboard, which minimizes interference with driving.
4.3 Interrupting spoken task
Our interrupting task was a version of the last letter word
game (LL). In our version of this game, a participant utters
a word that starts with the last vowel or consonant of the
word uttered by the other participant. For example, the first
participant might say ‘‘page’’ and the second says ‘‘earn’’
or ‘‘gear.’’ Interruptions were cued by displaying a letter to
one of the participants, along with a progress bar indicating
time remaining to complete the task. The participant who
receives the cue then tells the other participant to begin the
LL game and with what letter. Participants had 30 s to
name three words each. After completing this task, par-
ticipants resumed the PTQ game.
4.4 Interruption timing
Each pair of conversants drove on 12 road segments,
playing one PTQ game with one LL game interrupting it
during each segment. We manipulated interruption timing,
as this might impact dialogue behaviors, driving, and per-
formance on the spoken tasks. Using a set protocol, the
experimenter initiated an interruption during the PTQ game
after one, two, or three question–answer pairs for the driver
(and dispatcher who went first). Each participant was
interrupted six times, twice for each of the three interrup-
tion timings. There was a random delay of 0–10 s before
the initiated interruption was displayed on the participant’s
screen. This ensured that the experimenter did not intro-
duce a bias into the procedure. The delay range was based
on pilot experiments that indicated that it takes about 10 s
to complete a question–answer pair.
5 Results
The participants played a total of 384 twenty questions
games (16 participant pairs 9 12 segments/participant
pair 9 2 parallel games/segment = 384 games). Ideally,
they would have switched to 192 last letter games (16
participants 9 12 segments/participant 9 1 game/seg-
ment = 192 games). However, 15 interruptions were
introduced after the targeted participant completed the
ongoing task (three such cases for drivers, 12 for dis-
patchers). Overall, we recorded 9.3 h of speech interactions
with synchronized simulator and eye-tracker data. The
driving and eye-tracker data were collected over 800 km
travelled.
Pers Ubiquit Comput
123

5.1 Eliciting rich dialogue behavior
The verbal interactions were engaging, as demonstrated by
the example in Table 1. In this example, the two conversants
successfully completed both TQ games and the interrupting
LL game. As can be seen, the PTQ game runs from utterance
1 through utterance 10. During the third pair of question–
answer pairs, at utterance 11, the dispatcher introduces the
last letter game and tells the driver to say a word that begins
with B. The LL game finishes in utterance 17, after which the
driver signals it is over with the word ‘‘Okay.’’ The dis-
patcher then helps resume the PTQ by saying ‘‘Your turn to
ask.’’ In utterance 28, the driver guesses correctly finishing
one of the TQ games, and in utterance 30, the dispatcher also
guesses correctly and ends the second TQ game.2
Figure 2 shows how the TQ games ended. We see that
the driver and dispatcher were usually able to correctly
guess the object. TQ games were clearly challenging to
both participants, but not unreasonably so.
5.2 Managing multi-threaded dialogues
Next, we explored how people manage switches between
dialogue threads. In our study, participants switched from
the ongoing task to the interrupting task and back. Switches
to the interrupting task were cued by a letter displayed for
one of the participants. Thus, we investigated the rela-
tionship between when interruptions are cued and when
participants act on the cue. We also investigated how they
signal the beginning and the end of the interrupting task
and how they resume the ongoing task.
5.2.1 Responding to interrupting task cue
We tabulated all of the interruptions in terms of when they
were cued to the participant and when the participant
actually interrupted. We examined the cues and switches in
terms of whether they were during a question, between the
question and the answer, during the answer, or after the
answer and before the next question. The results are shown
in Fig. 3. First, the number of cued interruptions is not the
same for each region. This is because the cues were semi-
randomly distributed, and so the number of cues in each
region reflects the amount of time that participants spent in
the region. In fact, we see that the region during the answer
is the smallest, which is due to the short length of answers
in TQ, usually ‘‘yes’’ and ‘‘no.’’ Second, and more
importantly, we see that participants did not make the same
number of interruptions in each region as the number cued.
If participants tended to wait a fixed amount of time to
interrupt, the interruptions should also be randomly dis-
tributed between the regions based on the lengths of the
regions and so would result in approximately the same
number of switches as there are cues. This is definitely not
the case. In fact, we see that relative to the number of cues,
Table 1 Example ongoing and interrupting tasks
Utterance # Speaker Utterance Task
1 Disp. Is it in the kitchen? TQ
2 Driver No. TQ
3 Driver Does it have sharp edges? TQ
4 Disp. No. TQ
5 Disp. Is it in the bathroom? TQ
6 Driver No. TQ
7 Driver Does it produce heat? TQ
8 Disp. No. TQ
9 Disp. Is it on the ceiling? TQ
10 Driver No. TQ
11 Disp. Letter, word beginning with B. LL
12 Driver Ball. LL
13 Disp. Like. LL
14 Driver Kite. LL
15 Disp. Time. LL
16 Driver Move. LL
17 Disp. Voice. LL
18 Driver Okay. End LL
19 Disp. Your turn to ask. Resume TQ
20 Driver Does it have a door? TQ
21 Disp. Yes. TQ
… TQ
28 Driver Is it the refrigerator? TQ
29 Disp. Yes. TQ
30 Disp. Is it the TV? TQ
31 Driver Yes. TQ
Fig. 2 Game outcomes
2 Some subject pairs, including the ones from the dialogue excerpt in
Table 1, decided that the dispatcher’s first utterance would also reveal
the location of the dispatcher’s object. Thus, utterance 1 in Table 1 is
also communicating that the dispatcher’s object is in the kitchen. In
our study, three of the 16 participant pairs negotiated during the
training period.
Pers Ubiquit Comput
123
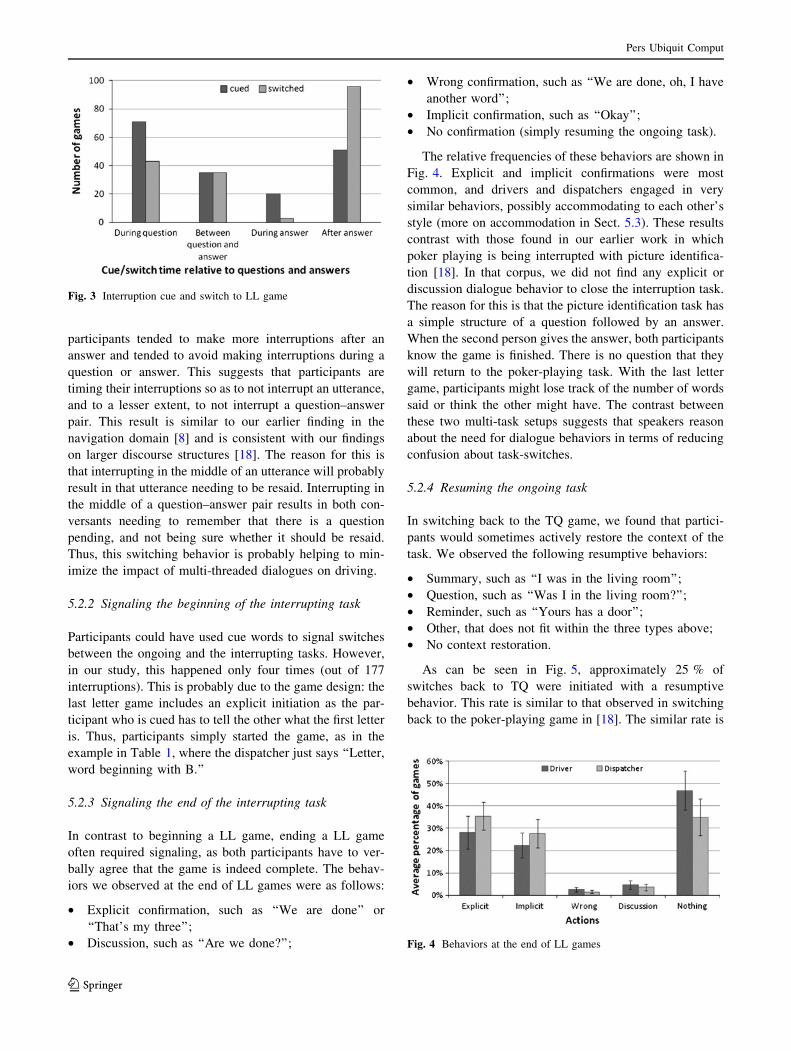
participants tended to make more interruptions after an
answer and tended to avoid making interruptions during a
question or answer. This suggests that participants are
timing their interruptions so as to not interrupt an utterance,
and to a lesser extent, to not interrupt a question–answer
pair. This result is similar to our earlier finding in the
navigation domain [8] and is consistent with our findings
on larger discourse structures [18]. The reason for this is
that interrupting in the middle of an utterance will probably
result in that utterance needing to be resaid. Interrupting in
the middle of a question–answer pair results in both con-
versants needing to remember that there is a question
pending, and not being sure whether it should be resaid.
Thus, this switching behavior is probably helping to min-
imize the impact of multi-threaded dialogues on driving.
5.2.2 Signaling the beginning of the interrupting task
Participants could have used cue words to signal switches
between the ongoing and the interrupting tasks. However,
in our study, this happened only four times (out of 177
interruptions). This is probably due to the game design: the
last letter game includes an explicit initiation as the par-
ticipant who is cued has to tell the other what the first letter
is. Thus, participants simply started the game, as in the
example in Table 1, where the dispatcher just says ‘‘Letter,
word beginning with B.’’
5.2.3 Signaling the end of the interrupting task
In contrast to beginning a LL game, ending a LL game
often required signaling, as both participants have to ver-
bally agree that the game is indeed complete. The behav-
iors we observed at the end of LL games were as follows:
• Explicit confirmation, such as ‘‘We are done’’ or
‘‘That’s my three’’;
• Discussion, such as ‘‘Are we done?’’;
• Wrong confirmation, such as ‘‘We are done, oh, I have
another word’’;
• Implicit confirmation, such as ‘‘Okay’’;
• No confirmation (simply resuming the ongoing task).
The relative frequencies of these behaviors are shown in
Fig. 4. Explicit and implicit confirmations were most
common, and drivers and dispatchers engaged in very
similar behaviors, possibly accommodating to each other’s
style (more on accommodation in Sect. 5.3). These results
contrast with those found in our earlier work in which
poker playing is being interrupted with picture identifica-
tion [18]. In that corpus, we did not find any explicit or
discussion dialogue behavior to close the interruption task.
The reason for this is that the picture identification task has
a simple structure of a question followed by an answer.
When the second person gives the answer, both participants
know the game is finished. There is no question that they
will return to the poker-playing task. With the last letter
game, participants might lose track of the number of words
said or think the other might have. The contrast between
these two multi-task setups suggests that speakers reason
about the need for dialogue behaviors in terms of reducing
confusion about task-switches.
5.2.4 Resuming the ongoing task
In switching back to the TQ game, we found that partici-
pants would sometimes actively restore the context of the
task. We observed the following resumptive behaviors:
• Summary, such as ‘‘I was in the living room’’;
• Question, such as ‘‘Was I in the living room?’’;
• Reminder, such as ‘‘Yours has a door’’;
• Other, that does not fit within the three types above;
• No context restoration.
As can be seen in Fig. 5, approximately 25 % of
switches back to TQ were initiated with a resumptive
behavior. This rate is similar to that observed in switching
back to the poker-playing game in [18]. The similar rate is
Fig. 3 Interruption cue and switch to LL game
Fig. 4 Behaviors at the end of LL games
Pers Ubiquit Comput
123
probably a coincidence, as the rate of resumptive behavior
probably depends on the length and complexity of the
interruption, and the amount of context of the task that is
being restored. These two aspects differ dramatically
between the two multi-task setups, with the poker playing
having a large context, but a simple interruption, which is
somewhat the opposite for the PTQ and LL games.
It is interesting to note that we did not see any signifi-
cant difference in task-switching behavior depending on
the road conditions, on how far into the ongoing task the
interruption was cued, or between the driver and the dis-
patcher. This might be due to insufficient data, or because
the verbal tasks were not difficult enough, or simply
because human speakers are not capable of adjusting these
task-switching behaviors to take into account differences in
cognitive load.
5.3 Accommodation in dialogue behavior
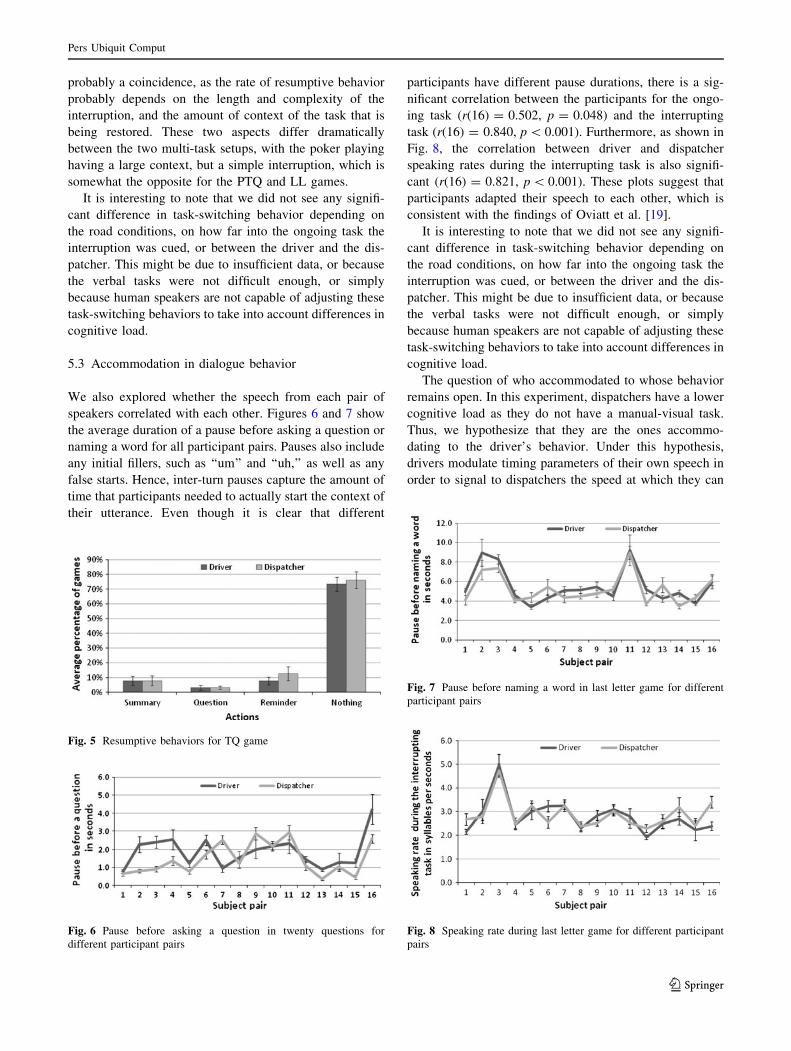
We also explored whether the speech from each pair of
speakers correlated with each other. Figures 6 and 7 show
the average duration of a pause before asking a question or
naming a word for all participant pairs. Pauses also include
any initial fillers, such as ‘‘um’’ and ‘‘uh,’’ as well as any
false starts. Hence, inter-turn pauses capture the amount of
time that participants needed to actually start the context of
their utterance. Even though it is clear that different
participants have different pause durations, there is a sig-
nificant correlation between the participants for the ongo-
ing task (r(16) = 0.502, p = 0.048) and the interrupting
task (r(16) = 0.840, p \ 0.001). Furthermore, as shown in
Fig. 8, the correlation between driver and dispatcher
speaking rates during the interrupting task is also signifi-
cant (r(16) = 0.821, p \ 0.001). These plots suggest that
participants adapted their speech to each other, which is
consistent with the findings of Oviatt et al. [19].
It is interesting to note that we did not see any signifi-
cant difference in task-switching behavior depending on
the road conditions, on how far into the ongoing task the
interruption was cued, or between the driver and the dis-
patcher. This might be due to insufficient data, or because
the verbal tasks were not difficult enough, or simply
because human speakers are not capable of adjusting these
task-switching behaviors to take into account differences in
cognitive load.
The question of who accommodated to whose behavior
remains open. In this experiment, dispatchers have a lower
cognitive load as they do not have a manual-visual task.
Thus, we hypothesize that they are the ones accommo-
dating to the driver’s behavior. Under this hypothesis,
drivers modulate timing parameters of their own speech in
order to signal to dispatchers the speed at which they can
Fig. 5 Resumptive behaviors for TQ game
Fig. 6 Pause before asking a question in twenty questions for
different participant pairs
Fig. 7 Pause before naming a word in last letter game for different
participant pairs
Fig. 8 Speaking rate during last letter game for different participant
pairs
Pers Ubiquit Comput
123
comfortably play a game. Dispatchers recognize the mod-
ulation and use similar timings in their own speech.
5.4 Effects of interruption timing
We next evaluated how the timing of the interruption
influenced the twenty questions game outcome. We
focused on games with correct guesses and timeouts, since
dialogue behaviors in these games might be different from
the ones observed in games that resulted in wrong guesses.
We also focused on games in which the interruption hap-
pened after two, three, and four question–answer pairs for a
given participant. We designate these interruptions Early,
Middle, and Late, respectively.
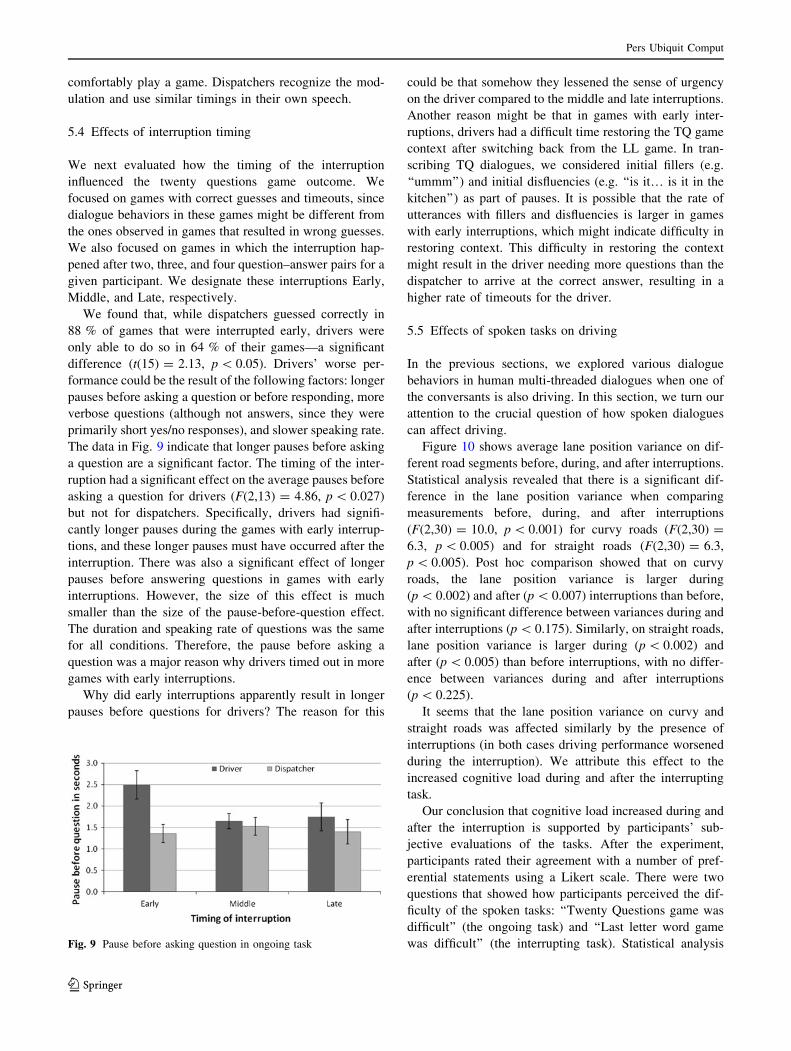
We found that, while dispatchers guessed correctly in
88 % of games that were interrupted early, drivers were
only able to do so in 64 % of their games—a significant
difference (t(15) = 2.13, p \ 0.05). Drivers’ worse per-
formance could be the result of the following factors: longer
pauses before asking a question or before responding, more
verbose questions (although not answers, since they were
primarily short yes/no responses), and slower speaking rate.
The data in Fig. 9 indicate that longer pauses before asking
a question are a significant factor. The timing of the inter-
ruption had a significant effect on the average pauses before
asking a question for drivers (F(2,13) = 4.86, p \ 0.027)
but not for dispatchers. Specifically, drivers had signifi-
cantly longer pauses during the games with early interrup-
tions, and these longer pauses must have occurred after the
interruption. There was also a significant effect of longer
pauses before answering questions in games with early
interruptions. However, the size of this effect is much
smaller than the size of the pause-before-question effect.
The duration and speaking rate of questions was the same
for all conditions. Therefore, the pause before asking a
question was a major reason why drivers timed out in more
games with early interruptions.
Why did early interruptions apparently result in longer
pauses before questions for drivers? The reason for this
could be that somehow they lessened the sense of urgency
on the driver compared to the middle and late interruptions.
Another reason might be that in games with early inter-
ruptions, drivers had a difficult time restoring the TQ game
context after switching back from the LL game. In tran-
scribing TQ dialogues, we considered initial fillers (e.g.
‘‘ummm’’) and initial disfluencies (e.g. ‘‘is it… is it in the
kitchen’’) as part of pauses. It is possible that the rate of
utterances with fillers and disfluencies is larger in games
with early interruptions, which might indicate difficulty in
restoring context. This difficulty in restoring the context
might result in the driver needing more questions than the
dispatcher to arrive at the correct answer, resulting in a
higher rate of timeouts for the driver.
5.5 Effects of spoken tasks on driving
In the previous sections, we explored various dialogue
behaviors in human multi-threaded dialogues when one of
the conversants is also driving. In this section, we turn our
attention to the crucial question of how spoken dialogues
can affect driving.
Figure 10 shows average lane position variance on dif-
ferent road segments before, during, and after interruptions.
Statistical analysis revealed that there is a significant dif-
ference in the lane position variance when comparing
measurements before, during, and after interruptions
(F(2,30) = 10.0, p \ 0.001) for curvy roads (F(2,30) =
6.3, p \ 0.005) and for straight roads (F(2,30) = 6.3,
p \ 0.005). Post hoc comparison showed that on curvy
roads, the lane position variance is larger during
(p \ 0.002) and after (p \ 0.007) interruptions than before,
with no significant difference between variances during and
after interruptions (p \ 0.175). Similarly, on straight roads,
lane position variance is larger during (p \ 0.002) and
after (p \ 0.005) than before interruptions, with no differ-
ence between variances during and after interruptions
(p \ 0.225).
It seems that the lane position variance on curvy and
straight roads was affected similarly by the presence of
interruptions (in both cases driving performance worsened
during the interruption). We attribute this effect to the
increased cognitive load during and after the interrupting
task.
Our conclusion that cognitive load increased during and
after the interruption is supported by participants’ sub-
jective evaluations of the tasks. After the experiment,
participants rated their agreement with a number of pref-
erential statements using a Likert scale. There were two
questions that showed how participants perceived the dif-
ficulty of the spoken tasks: ‘‘Twenty Questions game was
difficult’’ (the ongoing task) and ‘‘Last letter word game
was difficult’’ (the interrupting task). Statistical analysisFig. 9 Pause before asking question in ongoing task
Pers Ubiquit Comput
123

showed that the drivers and the dispatchers rated the
interrupting task as significantly more difficult than the
ongoing task (F(1,15)=6.25, p \ 0.002). Physiological
estimates of cognitive load lend further support to this
conclusion. Specifically, in other work on the same data
[20], we demonstrated that on curvy segments, physio-
logical measures based on the task-evoked pupillary
response [21] track the performance measure of lane
position variance shown in Fig. 10. Clearly, our partici-
pants felt that the tasks were of different difficulty levels,
and this is consistent with the performance and physio-
logical measures. It could be that the participants expected
the interrupting task to be more difficult and paid more
attention to it. For drivers, this might have come at the cost
of somewhat neglecting the driving task. Due to the design
of our study, we cannot determine whether this is due to the
LL game itself or to the fact that the LL game interrupts the
PTQ game. We feel that at least some of the difficulty
stems from introducing an interruption and requiring par-
ticipants to switch between tasks.
6 Design implications
In the introduction, we stated that using speech as a mode
of interaction while driving has to be done with care. The
results of our human–human study indicate that this gen-
eral statement will hold for the case of multi-threaded
human–computer dialogues. Our results offer clear evi-
dence that these dialogues can negatively impact cognitive
load in general, and driving performance (a measure of
cognitive load) in particular. Specifically, we found that
switching from an ongoing to an interrupting verbal task is
associated with increased cognitive load. Furthermore, the
cognitive load might not return to lower levels immediately
after switching back to the ongoing task. Designers should
carefully evaluate if, under various driving conditions,
switching from one verbal task to another (and back) might
lead to increased driver cognitive load and decreased
driving performance.
In exploring multi-threaded dialogue behaviors, we
found evidence that humans plan task-switches between
verbal tasks such as to reduce cognitive load. When
switching back to a task, they might also restore the context
of that task. However, the type and frequency of the
utterances in these switches are task dependent. Without
these utterances, the cognitive load of completing the
verbal tasks might be too high. Consequently, drivers
might abandon the verbal tasks or their driving perfor-
mance might suffer. Designers should explore ways in
which to endow computers with behaviors to support dia-
logue switches. Our results provide a starting point for
exploring appropriate computer behaviors.
Our results also indicate that humans use accommoda-
tion in multi-threaded dialogues between a driver and a
remote conversant. It is likely that the remote conversant
(our dispatcher) is accommodating to the driver. Designers
should explore ways in which a computer can detect dif-
ferent driver behaviors, such as pauses in speech, and
mimic them in order to help reduce the driver’s cognitive
load. It is also possible that the computer can trigger
accommodation behavior in the driver in order to reduce
his/her cognitive load. If, for example, the computer
detects high driver cognitive load using physiological or
driving performance measures, it can modulate timing
parameters of its own speech and expect the driver to
match them. This can result in slowing down the pace of
the verbal tasks, with a result of reduced overall driver
cognitive load.
7 Conclusions
With the number of in-car devices growing rapidly, it is
clear that designers will want to allow interactions between
drivers and these devices to overlap in time, resulting in
multi-threaded dialogues. In this paper, we aimed to lay the
groundwork for developing in-car speech interfaces capa-
ble of handling such dialogues while allowing the driver to
maintain adequate driving performance. We hypothesize
that such an interface can be built by learning from the way
humans (safely) handle in-car dialogues.
Thus, we proceeded to design a human–human study
exploring dialogue behaviors while one conversant is
operating a simulated vehicle. To this end, we first proposed
requirements that the design of the verbal tasks for such a
study should follow. We created two tasks that satisfy these
requirements and found that they can be used to elicit a
variety of dialogue behaviors between the conversants.
Evidence from driving performance measures, sub-
jective measures, and pupil-diameter-based physiological
measures indicates that engaging in multi-threaded dia-
logues can increase driver cognitive load. This supports theFig. 10 Lane position variance
Pers Ubiquit Comput
123

results of Vergauwe et al. [22] indicating that verbal and
manual-visual processes compete for some shared resour-
ces. On the other hand, we found evidence that the driver
and the remote conversant (the dispatcher) engaged in
dialogue behavior (accommodation) that might allow them
to collaboratively reduce the driver’s cognitive load.
While we observed a variety of dialogue behaviors, we
expect that in real-world dialogues in vehicles, human
conversants employ a much wider array of behaviors in
order to adapt to the ever-changing requirements of the
road. We believe that the reason these behaviors were not
observed in our study is that the options at the conversants’
disposal were limited by the relative simplicity of the
dialogue structures. After all, there is only so much one can
do to change the flow of the last letter game! As indicated
by Drews et al. [23], many other studies have a similar
limitation. For future studies, this observation points to the
need to employ a wider range of tasks in terms of their
complexity.
Acknowledgments This work was funded by the NSF under grant
IIS-0326496 and by the US Department of Justice under grants
2006DDBXK099, 2008DNBXK221, 2009D1BXK021, and
2010DDBXK226.
References
1. Horrey WJ, Wickens CD (2006) Examining the impact of cell
phone conversations on driving using meta-analytic techniques.
Hum Factors 48(1):196–205
2. Kun AL, Paek T, Medenica Z (2007) The effect of speech
interface accuracy on driving performance. In: Proceedings of
Interspeech, Antwerp, Belgium
3. Heeman PA, Yang F, Kun AL, Shyrokov A (2005) Conventions
in human–human multi-threaded dialogues: a preliminary study.
In: Proceedings of the international conference on intelligent user
interfaces, San Diego, CA
4. Reuda-Domingo T, Lardelli-Claret P, de Luna-del-Castillo JD,
Jimenez-Moleon JJ, Garcia-Martin M, Bueno-Cavanillas A
(2004) The influence of passengers on the risk of the driver
causing a car collision in Spain: analysis of collisions from 1990
to 1999. Accident Anal Prevent 36:481–489
5. Shyrokov A (2010) Human-human multi-threaded spoken dialogs
in the presence of driving. Doctoral dissertation, University of
New Hampshire
6. Shyrokov A (2006) Setting up experiments to test a multi-
threaded speech user interface. Technical report ECE.P54.2006.1,
University of New Hampshire
7. Toh SL, Yang F, Heeman PA (2006) An annotation scheme for
agreement analysis. In: Proceedings of the 9th international
conference on spoken language processing (ICSLP-06), Pitts-
burgh PA
8. Shyrokov A, Kun A, Heeman P (2007) Experimental modeling of
human–human multi-threaded dialogues in the presence of a
manual-visual task. In: Proceedings of the 8th SIGdial workshop
on discourse and dialogue, Antwerp, Belgium
9. Anderson AH, Bader M, Bard EC, Boyle E, Doherty G, Garrod S,
Isard S, Kowtko J, McAllister J, Miller J, Sotillo C, Thompson H,
Weinert R (1991) The HCRC map task corpus. Lang Speech
34(4):351–366
10. Villing J, Holtelius C, Larsson S, Lindstrom A, Seward A, Aberg
N (2008) Interruption, resumption and domain switching in in-
vehicle dialogue. In: Proceedings of GoTAL, 6th international
conference on natural language processing, Gothenburg, Sweden
11. Lindstrom A, Villing J, Larsson S (2008) The effect of cognitive
load on disfluencies during in-vehicle spoken dialogue. In: Pro-
ceedings of Interspeech, Brisbane, Australia
12. Villing J (2010) Now, Where Was I? Resumption strategies for
an in-vehicle dialogue system. In: Proceedings of the 48th annual
meeting of the association for computational linguistics, Uppsala,
Sweden
13. Vollrath M (2007) Speech and driving-solution or problem? Intell
Transp Syst 1:89–94
14. Wickens CD (2002) Multiple resources and performance pre-
diction. Theor Issues Ergonom Sci 3(2):159–177
15. Kun AL, Shyrokov A, Heeman PA (2010) Spoken tasks for
human–human experiments: towards in-car speech user interfaces
for multi-threaded dialogue. In: Proceedings of 2nd international
conference on automotive user interfaces and interactive vehic-
ular applications (AutomotiveUI ’10), Pittsburgh, PA
16. Strayer DL, Johnston WA (2001) Driven to distraction: dual-task
studies of simulated driving and conversing on a cellular phone.
Psychol Sci 12(6):462–466
17. Tsimhoni O, Green P (1999) Visual demand of driving curves
determined by visual occlusion. In: Proceedings of the vision in
vehicles 8 conference, Boston, MA
18. Yang F, Heeman PA, Kun AL (2011) An investigation of inter-
ruptions and resumptions in multi-tasking dialogues. Comput
Linguist 37:1
19. Oviatt S, Darves C, Coulston R (2004) Toward adaptive con-
versational interfaces: modeling speech convergence with ani-
mated personas. Trans Comput Hum Interact 11:300–328
20. Palinko O, Kun AL, Shyrokov A, Heeman P (2010) Estimating
cognitive load using remote eye tracking in a driving simulator.
In: Proceedings of the eye tracking research and applications
conference, Austin, TX
21. Beatty J (1982) Task evoked pupillary responses, processing load
and structure of processing resources. Psychol Bull 91(2):
276–292
22. Vergauwe E, Barrouillet P, Camos V (2010) Do mental processes
share a domain-general resource? Psychol Sci 21(3):384–390
23. Drews FA, Pasupathi M, Strayer DL (2008) Passenger and cell
phone conversations in simulated driving. J Exp Psychol Appl
14(4):392–400
Pers Ubiquit Comput
123