inter-processor parallel architecture
DESCRIPTION
Inter-Processor Parallel Architecture. Course No Lecture No Term. Outline. Parallel Architectures Symmetric multiprocessor architecture (SMP) Distributed-memory multiprocessor architecture Clusters The Grid The Cloud Multicore architecture Simultaneous Multithreaded architecture - PowerPoint PPT PresentationTRANSCRIPT

This module created with support form NSF under grant # DUE 1141022
Module developed Spring 2013by Apan Qasem
Some slides adopted from Patterson and Hennessy 4th Edition with permission
Inter-Processor Parallel Architecture
Course NoLecture No
Term

TXST TUES Module : C2
Outline
Parallel Architectures• Symmetric multiprocessor architecture (SMP)• Distributed-memory multiprocessor
architecture • Clusters• The Grid• The Cloud
• Multicore architecture • Simultaneous Multithreaded architecture • Vector Processors• GPUs
2

TXST TUES Module : C2
Outline
• Types of parallelism• Data-level parallelism (DLP)• Task-level parallelism (TLP)• Pipelined parallelism
• Issues in Parallelism• Amdahl’s Law• Load balancing • Scalability
3

TXST TUES Module : C2
What’s a Parallel Computer?
• Any system with more than one processing unit• Many names
• Multiprocessor Systems• Clusters• Supercomputers• Distributed Systems• SMPs• Multicore
• May refer to different types of architectures
• Not under the realm of parallel computers• OS running multiple processes on a single processor
4
Terms widely misused!

TXST TUES Module : C2
The 50s and 60s
5
IBM
360 UNIVAC1
time-share machinesmainframes
image : Wikipedia

TXST TUES Module : C2
Mainframes today
6
IBM still selling mainframe today
Banks appear to be the biggest client
New line of mainframes code
named “T-Rex
IBM Z-enterpriseBillion dollars in revenue
image : The Economist. 2012

TXST TUES Module : C2
The 70s
7
shared-memory processors (SMP)
vector machines pipelined architecture
CDC 7600 CRAY 1
Seymour Cray
image : Wikipedia

TXST TUES Module : C2
The 80s and 90s
8
IBM Power5-based ClusterIntel-based Beowulf
Cluster ComputingDistributed Computing
VaxCluster
image : Wikipedia

TXST TUES Module : C2
The 90s and 00s
9
The Grid

TXST TUES Module : C2
Grid Computing
• Separate computers interconnected by long-haul networks• e.g., Internet connections• work units farmed out, results sent back
• Can make use of idle time on PCs• e.g.,
• seti@home • folding@home
• Don’t need any additional hardware• Writing good software is difficult
10
TXST TUES Module : C2
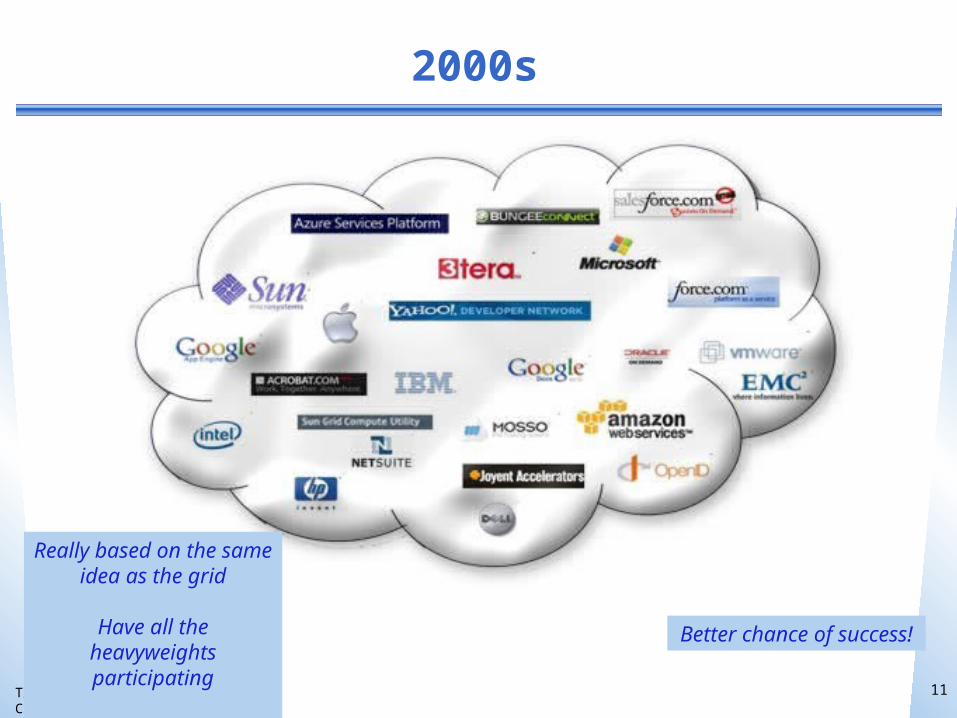
2000s
11
Really based on the same idea as the grid
Have all the heavyweights participating
Better chance of success!

TXST TUES Module : C2
Parallel Architecture Design Issues
• Architectural design choices driven by challenges in writing parallel programs
• Three main challenges in writing parallel programs are • Safety
• Can’t change the semantics• Account for race conditions
• Efficiency• Exploit resources, keep processors busy
• Scalability• Ensure that performance grows as you add more nodes.
• Some problems are inherently sequential• Can still extract some parallelism from it
12
Key characteristics for parallel architectures
Communication MechanismMemory Access
Scalability

TXST TUES Module : C2
Shared-Memory Multiprocessor (SMP)
• Single address space shared by all processors • akin to a multi-threaded program
• Processors communicate through shared variables in memory• Architecture must provide features to co-ordinate access to shared
data • synchronization primitives
13
until ~2006 most servers were set up as SMPs

TXST TUES Module : C2
Process Synchronization in SMP Architecture
int foo = 17;
void *thread_func(void *arg) { ... foo = foo + 1; ... }
14
Assume 2 threads in the program are executing the function in parallel
Also assume work performed in each thread is independent
But the threads operate on the same data set (e.g., foo)
In the assembly level the increment statement involves at least
one load, one store one add
Need to coordinate threads working on the same data

TXST TUES Module : C2
Process Synchronization in SMP Architecture
Problem with concurrent access to shared data
15
Assume the following order of access
T0 loads fooT1 loads fooT0 adds to fooT1 adds to fooT0 stores fooT1 stores foo
What is the final value of foo?
int foo = 17;
void *thread_func(void *arg) { ... foo = foo + 1; ... }

TXST TUES Module : C2
Process Synchronization in SMP Architecture
Problem with concurrent access to shared data
16
Assume the following order of access
T0 loads fooT0 adds to fooT1 loads fooT1 adds to fooT0 stores fooT1 stores foo
What is the final value of foo?
int foo = 17;
void *thread_func(void *arg) { ... foo = foo + 1; ... }

TXST TUES Module : C2
Using a mutex for synchronization
pthread_mutex_lock(mutex);/ * code that modifies foo */
foo = foo + 1;
pthread_mutex_unlock(mutex);
• Any thread executing the critical section will perform the load, add and store without any intervening operations on foo
• To provide support for locking mechanism need atomic operations
17
at any point only one thread is going toexecute this code
critical section

TXST TUES Module : C2
Process Synchronization in SMP Architecture
• Need to be able to coordinate processes working on the same data
• At the program-level can use semaphores or mutexes to synchronize processes and implement critical sections
• Need architectural support to lock shared variables• atomic swap operation on MIPS (ll and sc)and SPARC (swp)
• Need architectural support to determine which processor gets access to the lock variable• single bus provides arbitration mechanism since the bus
is the only path to memory• the processor that gets the bus wins 18

TXST TUES Module : C2
Shared-Memory Multiprocessor (SMP)
• Single address space shared by all processors • akin to a multi-threaded program
• Processors communicate through shared variables in memory
• Architecture must provide features to co-ordinate access to shared data
19
What’s a big disadvantage?

TXST TUES Module : C2
Types of SMP
• SMPs come in two styles• Uniform memory access (UMA)
multiprocessors• Any memory access takes the same amount of time
• Non-uniform memory access (NUMA) multiprocessors• Memory is divided into banks• Memory latency depends on where the data is located
• Programming NUMAs are harder but design is easier
• NUMAs can scale to larger sizes and have lower latency to local memory leading to overall improved performance
• Most SMPs in use today are NUMA20

TXST TUES Module : C2
Distributed Memory Systems
• Multiple processors, each with its own address space connected via I/O bus
• Processors share data by explicitly sending and receiving information (message passing)
• Coordination is built into message-passing primitives (message send and message receive)
21

TXST TUES Module : C2
Specialized Interconnection Networks
• For distributed memory systems speed of communication between processors is critical
• I/O bus or Ethernet, although viable solutions don’t provide the necessary necessary performance• latency is important • high throughput is important
• Most distributed systems today are implemented with specialized interconnect networks• Infiniband• Myrinet• Quadrics
22
infiniband
myrinet

TXST TUES Module : C2
Clusters
• Clusters are a type of distributed memory systems• They are off-the-shelf, whole computers with multiple
private address spaces connected using the I/O bus and network switches• lower bandwidth than multiprocessor that use the processor-
memory (front side) bus• lower speed network links• more conflicts with I/O traffic
• Each node has its own OS, limiting the memory available for applications
• Improved system availability and expandability• easier to replace a machine without bringing down the whole
system• allows rapid, incremental expansion
• Economies-of-scale advantages with respect to costs23

TXST TUES Module : C2
Interconnection Networks
• On distributed systems processors can be arranged in a variety of ways
• Typically the more connections you have the better the performance and higher the cost
24
Bus Ring
2D Mesh
N-cube (N = 3)
Fully connected

TXST TUES Module : C2
SMPs vs. Distributed Systems
SMP
Communication happens through
shared memory
Harder to design and program
Not scalable
Need special OS
Programming API : OpenMP
Administration cost low
Distributed
Need explicit communication
Easier to design and program
Scalable
Can use regular OS
Programming API : MPI
Administration cost high
25

TXST TUES Module : C2
Power Density
Chart courtesy : Pat Gelsinger, Intel Developer Forum, 2004
Heat becoming an unmanageable problem

TXST TUES Module : C2
The Power Wall
• Moore’s law still holds but does not seem to be economically feasible• Power dissipation (and associated costs) too
high
• Solution• Put multiple simplified cores in the same chip area• Less power dissipation => Less heat => Lower cost
27
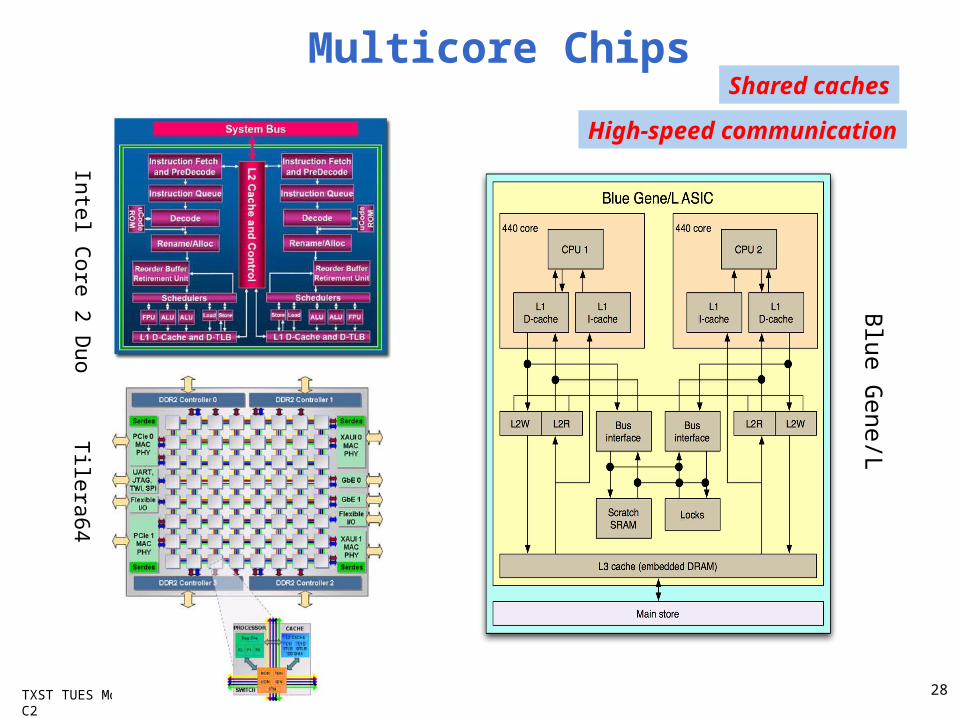
TXST TUES Module : C2
Multicore ChipsBlue G
ene/L
Tilera64Intel Core 2 D
uo
Shared caches
High-speed communication
28

TXST TUES Module : C2
Intel - Nehalem
29

TXST TUES Module : C2
AMD - Shanghai
30

TXST TUES Module : C2
CMP Architectural Considerations
In a way, each multicore chip is an SMP• memory => cache• processor => core
Architectural considerations are same as for SMPs• Scalability
• how many cores can we hook up to an L2 cache?• Sharing
• how do concurrent threads share data?• through LLC or memory
• Communication• how do threads communicate?• semaphores and locks, use cache if possible
31
cache coherence protocols

TXST TUES Module : C2
Simultaneous Multithreading (SMT)
• Many architectures today support multiple HW threads• SMTs use the resources of superscalar to exploit both ILP
and thread-level parallelism• Having more instructions to play with gives the scheduler
more opportunities in scheduling • No dependence between threads from different programs
• Need to rename registers
• Intel calls it’s SMT technology hyperthreading• On most machines today, you have SMT on every core
• Theoretically, a quad-core machine gives you 8 processors with hyperthreading
• Logical cores
32
TXST TUES Module : C2
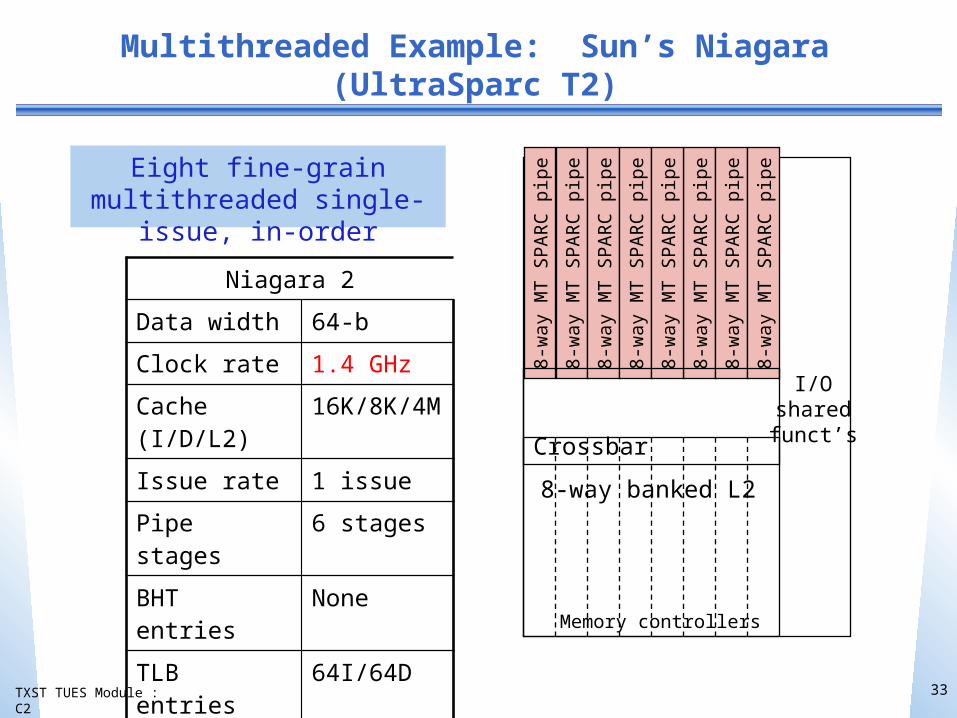
Multithreaded Example: Sun’s Niagara (UltraSparc T2)
33
Eight fine-grain multithreaded single-issue, in-order
Niagara 2Data width 64-bClock rate 1.4 GHzCache (I/D/L2) 16K/8K/4MIssue rate 1 issuePipe stages 6 stagesBHT entries NoneTLB entries 64I/64D
Memory BW 60+ GB/s
Power (max) <95 W8-
way
MT
SPAR
C pi
pe
8-w
ay M
T SP
ARC
pipe
8-w
ay M
T SP
ARC
pipe
8-w
ay M
T SP
ARC
pipe
8-w
ay M
T SP
ARC
pipe
8-w
ay M
T SP
ARC
pipe
8-w
ay M
T SP
ARC
pipe
8-w
ay M
T SP
ARC
pipe
Crossbar
8-way banked L2
Memory controllers
I/Osharedfunct’s
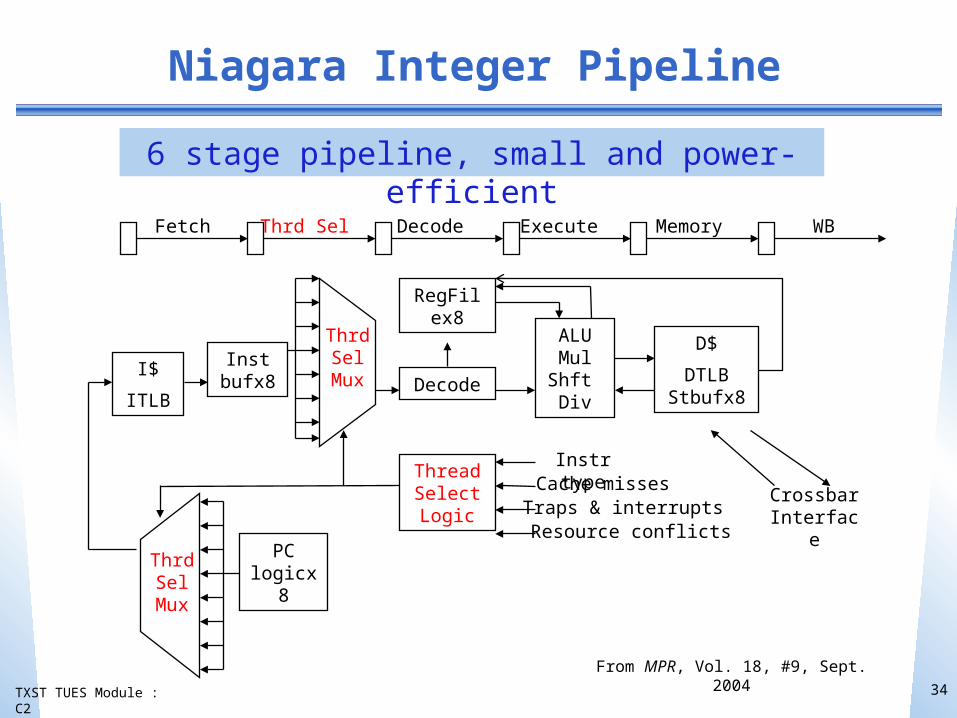
TXST TUES Module : C2
Niagara Integer Pipeline
6 stage pipeline, small and power-efficient
34
From MPR, Vol. 18, #9, Sept. 2004
Fetch Thrd Sel Decode Execute Memory WB
I$
ITLB
Inst bufx8
PC logicx8
Decode
RegFilex8
Thread Select Logic
ALU Mul Shft Div
D$
DTLB Stbufx8
Thrd Sel
Mux
Thrd Sel
Mux
Crossbar Interface
Instr typeCache missesTraps & interruptsResource conflicts

TXST TUES Module : C2
SMT Issues
• Processor must duplicate the state hardware for each thread• a separate register file, PC, instruction buffer, store
buffer for each thread
• The caches, TLBs, BHT can be shared• although the miss rates may increase if they are not
sized accordingly
• The memory can be shared through virtual memory mechanisms
• Hardware must support efficient thread context switching
35

TXST TUES Module : C2
Vector Processors
• A vector processor operates on vector registers• Vector registers can hold multiple data items of the same
type• Usually 64, 128 words
• Need hardware to support operations on these vector registers
• Need at least one regular CPU• Vector ALUs usually pipelined
• high pay-off on scientific applications
• formed the basis of supercomputers in the 1970’s and early 80’s
36
TXST TUES Module : C2
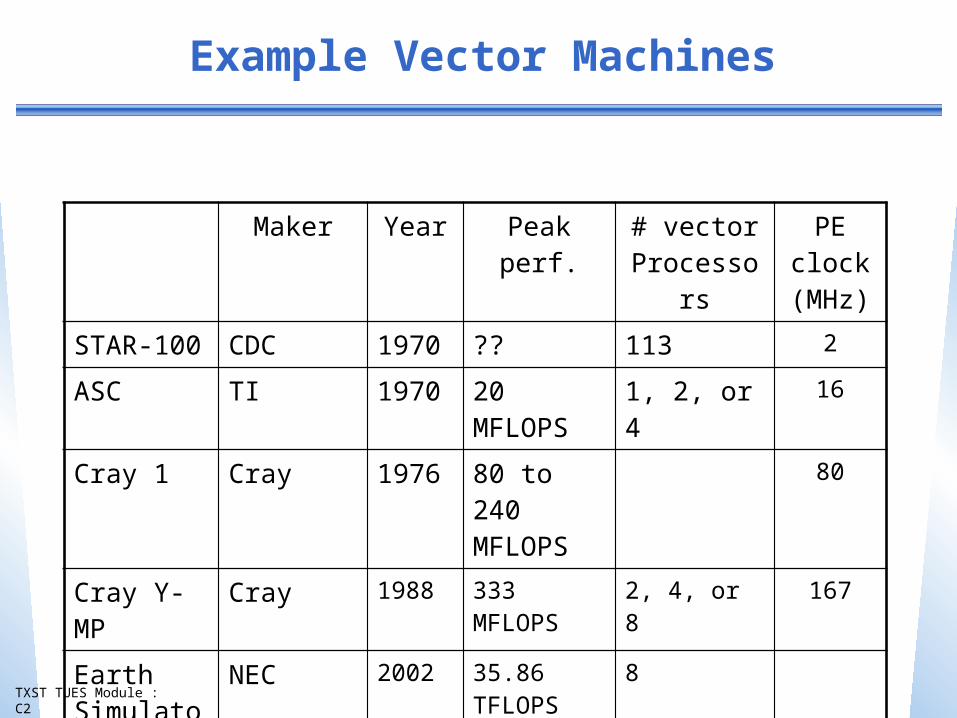
Example Vector Machines
Maker Year Peak perf. # vector Processors
PE clock (MHz)
STAR-100 CDC 1970 ?? 113 2
ASC TI 1970 20 MFLOPS 1, 2, or 4 16
Cray 1 Cray 1976 80 to 240 MFLOPS
80
Cray Y-MP Cray 1988 333 MFLOPS 2, 4, or 8 167
Earth Simulator
NEC 2002 35.86 TFLOPS 8

TXST TUES Module : C2
Multimedia SIMD Extensions
• Most processors today come with vector extensions
• The compiler needs to be able generate code for these
• Examples• Intel : MMX, SSE• AMD : 3DNow!• IBM, Apple : Altivec (does floating-point as well)
38

TXST TUES Module : C2
GPUs
• Graphics cards have come a long way since the early days of 8-bit graphics
• Most machines today come with graphics processing unit that is highly powerful and capable of doing general purpose computation as well
• Nvidia is leading the market (GTX, Tesla)
• AMD’s competing (ATI)• Intel’s kind of behind
• May change with MICs
39
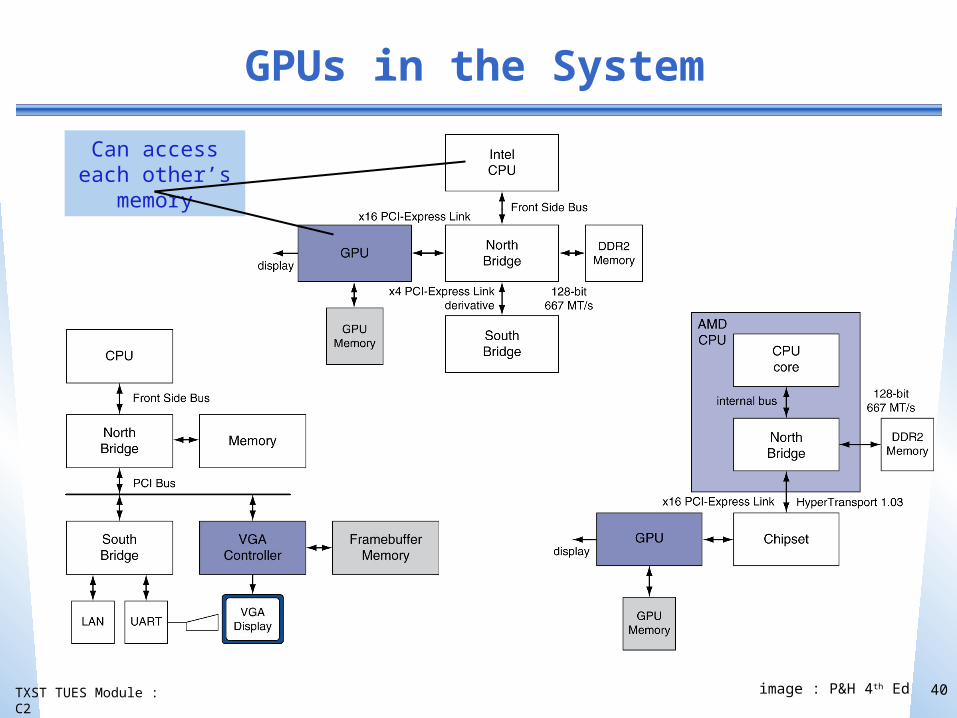
TXST TUES Module : C2
GPUs in the System
40
Can access each other’s memory
image : P&H 4th Ed
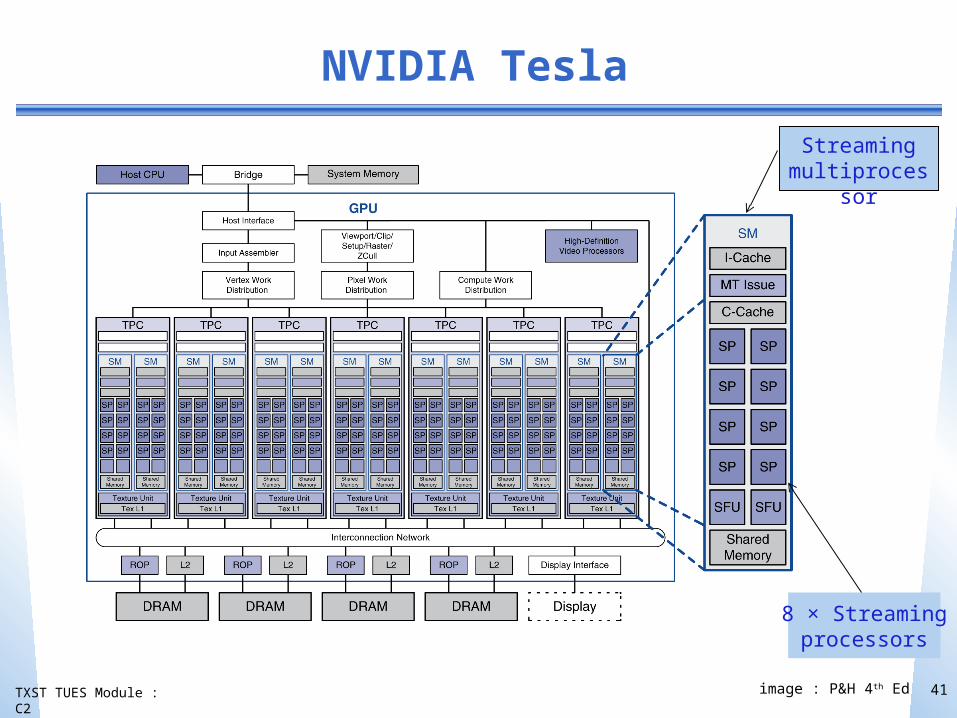
TXST TUES Module : C2
NVIDIA Tesla
41
Streaming multiprocessor
8 × Streamingprocessors
image : P&H 4th Ed

TXST TUES Module : C2
GPU Architectures
• Many processing cores• Cores not as powerful as CPU
• Processing is highly data-parallel• Use thread switching to hide memory latency
• Less reliance on multi-level caches• Graphics memory is wide and high-bandwidth
• Trend toward heterogeneous CPU/GPU systems in HPC• Top 500
• Programming languages/APIs• Compute Unified Device Architecture (CUDA) from NVidia• OpenCL for ATI
42

TXST TUES Module : C2
The Cell Processor Architecture
43
IBM’s CELL used in PS3 and HPC
image : ibm.com

TXST TUES Module : C2
Types of Parallelism
• Models of parallelism• Message Passing • Shared-memory
• Classification based on decomposition• Data parallelism• Task parallelism• Pipelined parallelism
• Classification based on • TLP // thread-level parallelism• ILP // instruction-level parallelism
• Other related terms• Massively Parallel• Petascale, Exascale computing• Embarrassingly Parallel
44

TXST TUES Module : C2
Flynn’s Taxonomy
• SISD – single instruction, single data stream• aka uniprocessor
• SIMD – single instruction, multiple data streams• single control unit broadcasting operations to multiple
datapaths
• MISD – multiple instruction, single data• no such machine
• MIMD – multiple instructions, multiple data streams• aka multiprocessors (SMPs, clusters)
45

TXST TUES Module : C2
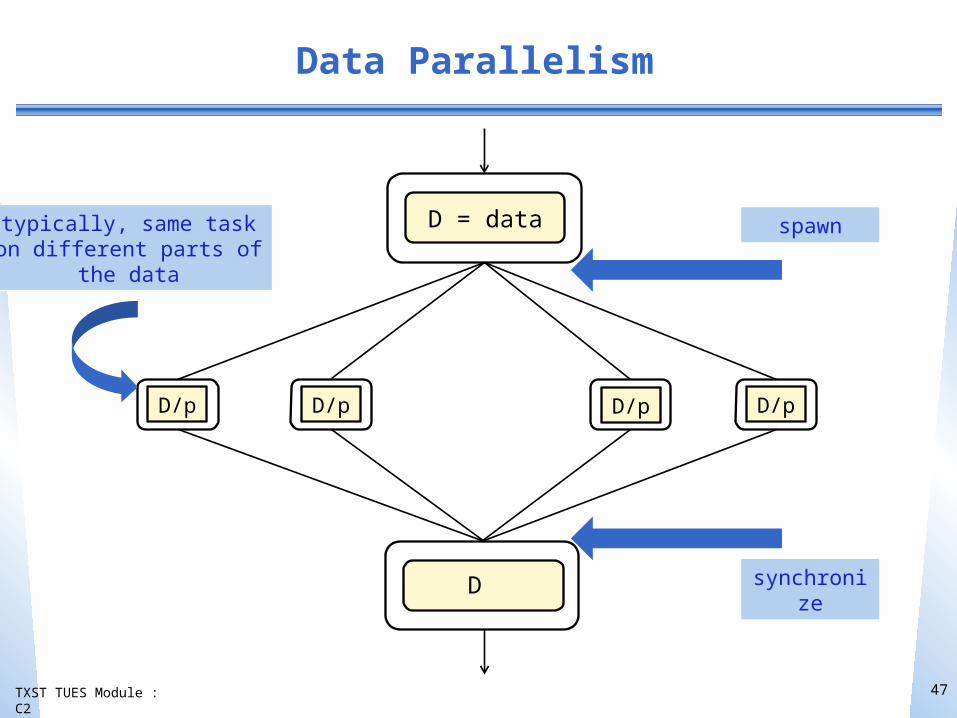
Data Parallelism
46
D/pD/p D/p D/p
D = data
D
TXST TUES Module : C2
Data Parallelism
47
D/pD/p D/p D/p
D = data
D
typically, same taskon different parts of
the data
spawn
synchronize

TXST TUES Module : C2
Data Distribution Schemes
48Figure courtesy : Blaise Barney, LLNL

TXST TUES Module : C2
Example : Data Parallel Code in OpenMP
!$omp parallel do private(i,j)do j = 1, N do i = 1, M a(i,j) = 17 enddo b(j) = 17 c(j) = 17 d(j) = 17enddo!$omp end parallel do
49

TXST TUES Module : C2
Example : Data Parallel Code in OpenMP
do jj = 1, N, 16!$omp parallel do private(i,j) do j = jj, min(jj+16-1,N)!) do i = 1, M a(i,j) = 17 enddo b(j) = 17 c(j) = 17 d(j) = 17enddo!$omp end parallel do
50
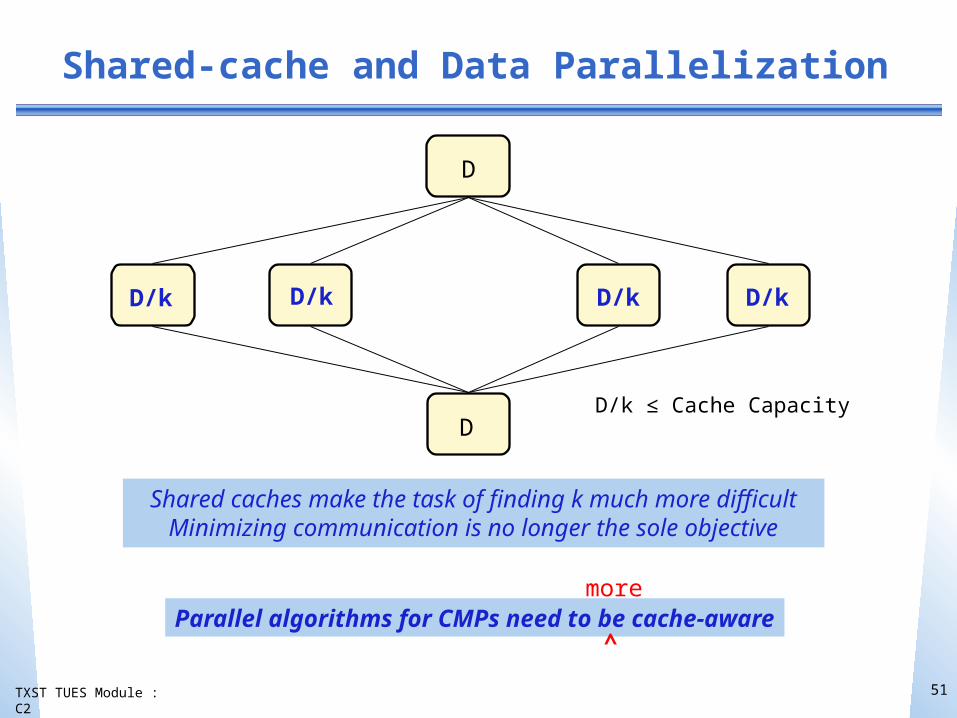
TXST TUES Module : C2
D/k
D
DD/k ≤ Cache Capacity
D/k D/kD/k
Parallel algorithms for CMPs need to be cache-aware^
more
Shared-cache and Data Parallelization
Shared caches make the task of finding k much more difficultMinimizing communication is no longer the sole objective
51

TXST TUES Module : C2
Data Parallelism
• This type of parallelism is sometimes referred to as loop-level parallelism
• Quite common in scientific computation
• Also, sorting. Which ones?
52
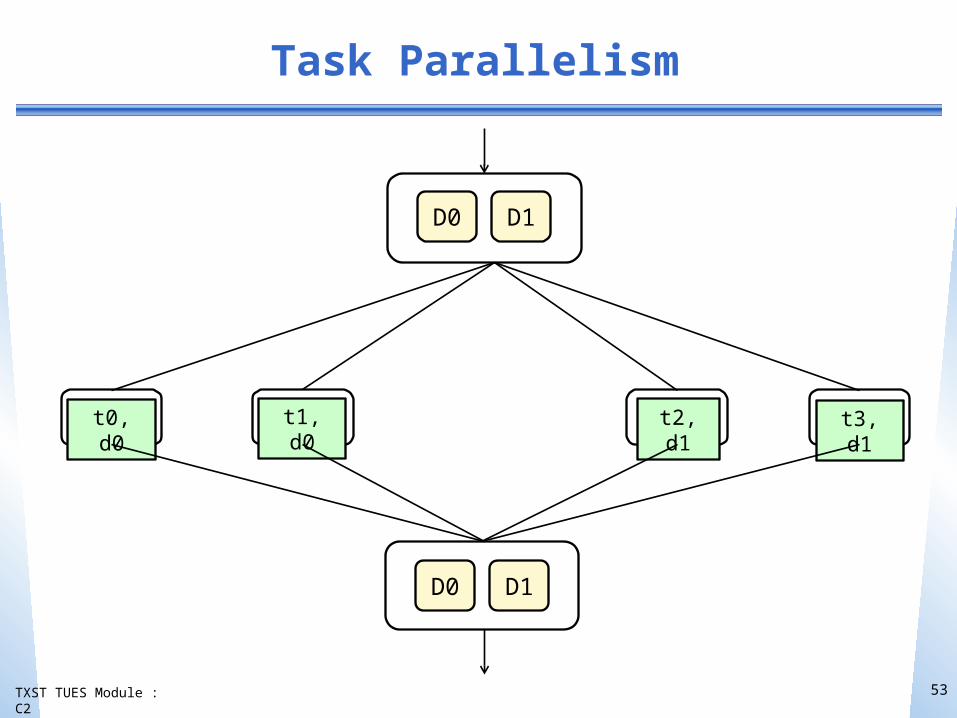
TXST TUES Module : C2
Task Parallelism
53
t2, d1t0, d0 t1, d0 t3, d1
D0 D1
D1D0
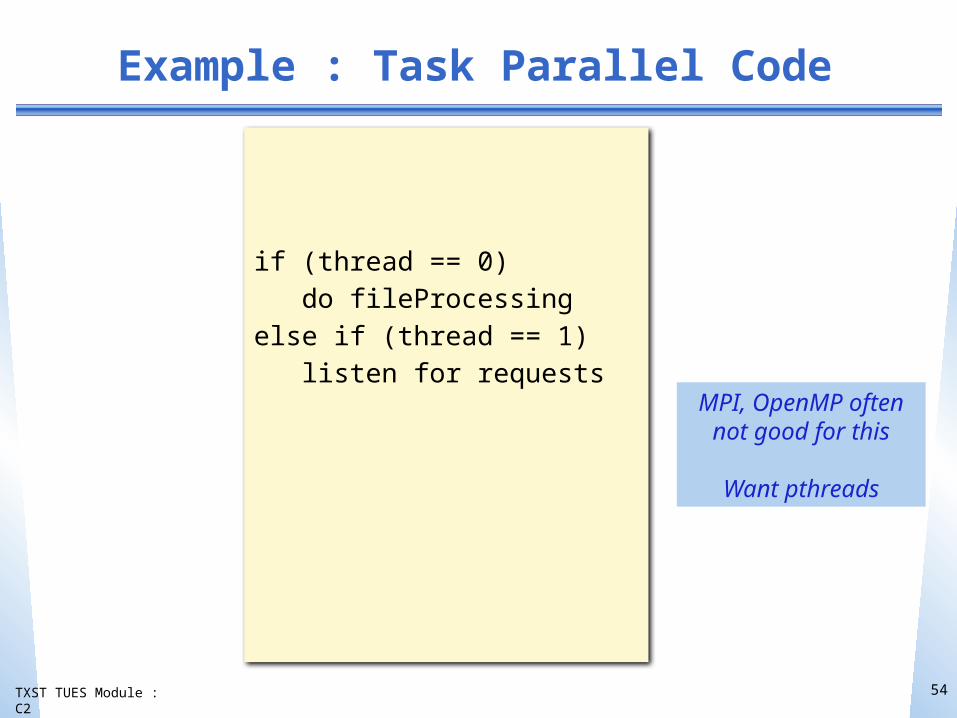
TXST TUES Module : C2
Example : Task Parallel Code
if (thread == 0) do fileProcessingelse if (thread == 1) listen for requests
54
MPI, OpenMP often not good for this
Want pthreads

TXST TUES Module : C2
Pipelined Parallelism
55
CP
Shared Data Set
P
C
Synchronization window
time

TXST TUES Module : C2
Synchronization Window in Pipelined Parallelism
56
Bad
Not asbad
Better?

TXST TUES Module : C2
ExTime w/ E = ExTime w/o E ((1-F) + F/P)
Amdahl’s Law and Parallelism
Speedup due to enhancement E is
57
Speedup w/ E = -------------------------- Exec time w/o E
Exec time w/ E
Suppose,
Fraction F can be parallelized into P processing cores
Speedup w/ E = 1 / ((1-F) + F/P)
Gene Amdahl

TXST TUES Module : C2
Amdahl’s Law and Parallelism
• Assume we can parallelize 25% of the program and we have 20 processing cores
Speedup w/ E = 1/(.75 + .25/20) = 1.31
• If only 15% is parallelized Speedup w/ E = 1/(.85 + .15/20) = 1.17
• Amdahl’s Law tells us that to achieve linear speedup with n processors, none of the original computation can be scalar!
• To get a speedup of 90 from 100 processors, the percentage of the original program that could be scalar would have to be 0.1% or less
Speedup w/ E = 1/(.001 + .999/100) = 90.99
58
Speedup with parallelism = 1 / ((1-F) + F/P)
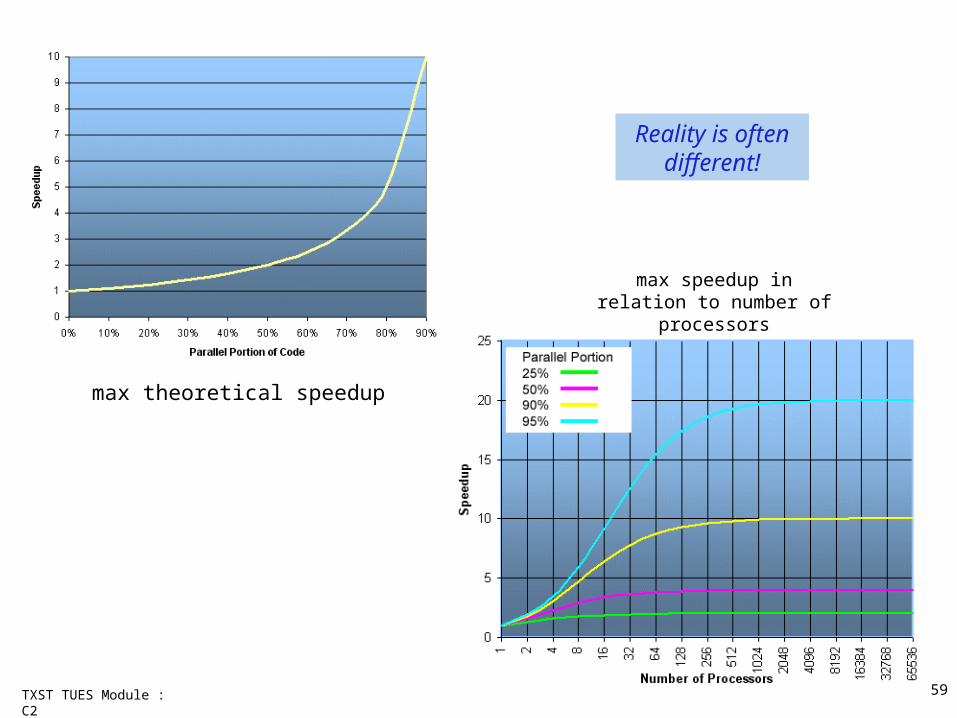
TXST TUES Module : C2
max theoretical speedup
max speedup in relation to number of processors
Reality is often different!
59

TXST TUES Module : C2
Scaling
• Getting good speedup on a multiprocessor while keeping the problem size fixed is harder than getting good speedup by increasing the size of the problem
• Strong scaling• when speedup can be achieved on a multiprocessor
without increasing the size of the problem
• Weak scaling• when speedup is achieved on a multiprocessor by
increasing the size of the problem proportionally to the increase in the number of processors
60

TXST TUES Module : C2
Load Balancing
• Load balancing is another important factor in parallel computing
• Just a single processor with twice the load of the others cuts the speedup almost in half
• If the complexity of the parallel threads vary, then the complexity of the overall algorithm is dominated by the thread with the worst complexity
• Granularity of parallel task is important• Adapt granularity based on architectural characteristics
61

TXST TUES Module : C2
Load Balancing
62
This one dominates! What are the architectural implications?