integrating qradar with hadoop - ibm · integrating!qradarwith!hadoop!–!awhite!paper! 3!...
TRANSCRIPT

Integrating QRadar with Hadoop A White Paper
Ben Wuest Research & Integration Architect
Security Intelligence Security Systems
IBM
April 16th, 2014

Integrating QRadar with Hadoop – A White Paper
2
OVERVIEW __________________________________________________________________________________________ 3 BACKGROUND READING ____________________________________________________________________________ 4 PRE-‐REQUISITE SOFTWARE _________________________________________________________________________ 4
DATA FORMAT _____________________________________________________________________________________ 4 CUSTOM PROPERTIES _______________________________________________________________________________ 5
CONFIGURING THE DATA LINK __________________________________________________________________ 5 QRADAR TO HADOOP DATA FLOW CONFIGURATION _________________________________________________ 5 JSON Enablement on for QRadar _____________________________________________________________ 5 QRadar Routing Rules and Forwarding Destinations _______________________________________ 6
Routing Rules ____________________________________________________________________________________________________ 6 Forwarding Destinations ________________________________________________________________________________________ 6
Flume Receiver/Agent Configuration ________________________________________________________ 7 Agent Definition _________________________________________________________________________________________________ 7 Source Definition ________________________________________________________________________________________________ 8 Channel Definition _______________________________________________________________________________________________ 8 Sink Definition ___________________________________________________________________________________________________ 9
HADOOP TO QRADAR DATA FLOW CONFIGURATION _________________________________________________ 9 API Services Role Configuration ______________________________________________________________ 9 Authorized Service Configuration ___________________________________________________________ 10
DEPLOYMENT CONSIDERATIONS _____________________________________________________________ 11 DATA STORAGE CONFIGURATION _________________________________________________________________ 11 Deployment Example _________________________________________________________________________ 11
MULTI-‐AGENT FLUME CONFIGURATIONS __________________________________________________________ 11 FORWARDING PROFILES _______________________________________________________________________ 12 TECHNICAL DETAILS ______________________________________________________________________________ 12 EDITING THE FORWARDING PROFILE _____________________________________________________________ 12 Header Attributes ____________________________________________________________________________ 13
Name and Custom Property Configuration __________________________________________________________________ 13 Pre-‐amble ______________________________________________________________________________________________________ 13 ISO Time Formatting __________________________________________________________________________________________ 13
Field Properties _______________________________________________________________________________ 14 WORKING WITH INSIGHTS IN QRADAR CORRELATION ENGINE _________________________ 14 BIG INSIGHTS DATA ACCESS ___________________________________________________________________ 16 JAQL AND QRADAR DATA ________________________________________________________________________ 16 BIG SHEETS AND QRADAR DATA __________________________________________________________________ 16
USE CASES ________________________________________________________________________________________ 18 ESTABLISHING BASELINE _________________________________________________________________________ 18 ADVANCED PERSISTENT THREAT DETECTION _____________________________________________________ 18 Beaconing _____________________________________________________________________________________ 18 Data Leakage _________________________________________________________________________________ 19
DOMAIN ATTRIBUTION ___________________________________________________________________________ 19 QRADAR – BIG INSIGHTS RPM _________________________________________________________________ 20 APPENDIX ________________________________________________________________________________________ 21 JSON DATA FIELDS _______________________________________________________________________________ 21

Integrating QRadar with Hadoop – A White Paper
3
Overview The world of Security Intelligence is evolving. In today’s security picture organizations are looking to identify linkages and patterns in their organizational data. This data includes more than just cyber data. This type of deep analysis requires the offline processing and data-‐flows that are enabled by a Hadoop environment. The integration of the QRadar Security Information Event Management System (SIEM) with a Hadoop environment provides a framework for performing these types of analyses. This integration (outlined in Fig 1.0) includes simple connectors to allow normalized and enriched data to flow from QRadar to a Hadoop based platform and for insights to flow back. These insights can then be considered in the advanced real-‐time correlation engine of the QRadar SIEM.
Fig 1.0: Integration Overview
In this integration, analytics are performed on the Big Data platform. These are analytics that combine traditional cyber data sources with non-‐traditional feeds, such as social media, external threat feeds, domain registration data, web site feeds etc. In this paper you will find details on the interoperable data format, data link configuration, deployment considerations, advanced profile manipulation and details on some example use cases to consider when integrating the QRadar SIEM with a Hadoop Environment.

Integrating QRadar with Hadoop – A White Paper
4
Background Reading A good understanding of QRadar and Hadoop is important to the information provided in this document. Please refer to IBM documentation on QRadar and to your Hadoop specific implementation documentation. The open source sites are great sources of information for this.
Pre-‐requisite Software The software pre-‐requisites for this document include:
a. IBM QRadar SIEM v7.2 Maintenance Release 1 patched to v7.2 Maintenance Release 1 Patch 3 (With Interim Fix 1); and
b. IBM InfoSphere Big Insights 2.1.0.0 (for any Big Insights specific applications); and
c. Apache Flume 1.3 or higher (1.4 is preferred but some Hadoop Flavors do not currently support this version)
Data Format Central to the integration is a JSON Data format; which is the data format exported from QRadar on the data link (over TCP Syslog). This format is a simple JSON key-‐value pair format. It contains all the normalized and enriched fields that are extracted by QRadar. An example even data record is shown below: {"category": "Misc POST Request ", "credibility": "5", "devTimeEpoch": "1391648638000", "devTimeISO": "2014-02-05T21:03:58.000-04:00", "dst": "192.168.18.13", "dstIPLoc": "other", "dstNetName": "Net-10-172-192.Net_192_168_0_0", "dstPort": "80", "dstPostNATPort": "0", "dstPreNATPort": "0", "eventDescription": "An HTTP POST request was issued but there is no available s-action information.", "eventName": "Misc POST Request","hasIdentity": "false", "hasOffense": "false", "highLevelCategory": "Access", "isoTimeFormat": "yyyy-MM-dd\'T\'HH:mm:ss.SSSZ", "logSource": "BlueCoat", "logSourceGroup": "Other", "logSourceType": "Bluecoat SG Appliance", "lowLevelCategory": "Misc Network Communication Event", "name": "json_default_profile", "payload": "<182>Feb 05 21:03:58 10.1.1.2 \"[05/Feb/2014 21:03:58 -0500]\" 1 bluecoat.proxysg.test.com REYESA - - OBSERVED \"none\" - 0 - POST - http 216.155.194.147 80 / - - \"Mozilla/5.0\" 192.168.18.13 0 687 -\n", "protocolID": "255", "relevance": "6", "sev": "3", "src": "10.1.1.2", "srcIPLoc": "other", "srcNetName": "Net-10-172-192.Net_10_0_0_0", "srcPort": "0", "srcPostNATPort": "0", "srcPreNATPort": "0", "startTimeEpoch": "1391630555106", "startTimeISO": "2014-02-05T16:02:35.106-04:00", "storageTimeEpoch": "1391630555106", "storageTimeISO": "2014-02-05T16:02:35.106-04:00", "type": "Event", "usrName": "REYESA", "version": "1.0" }
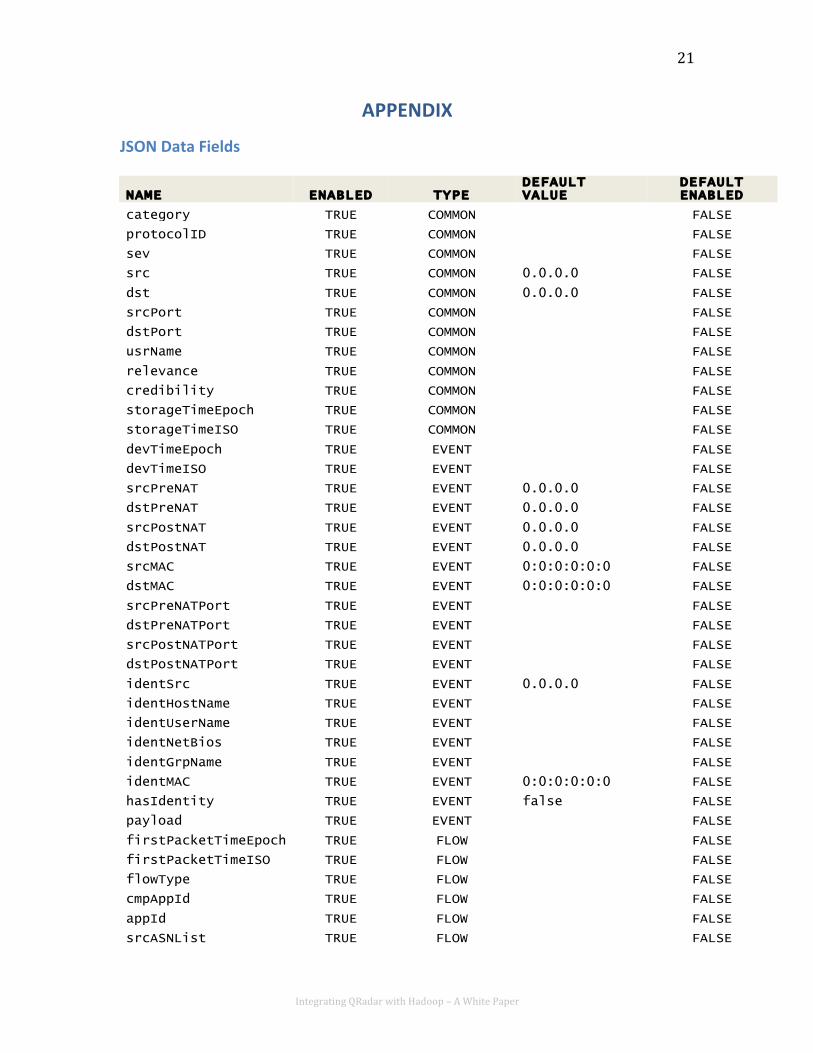
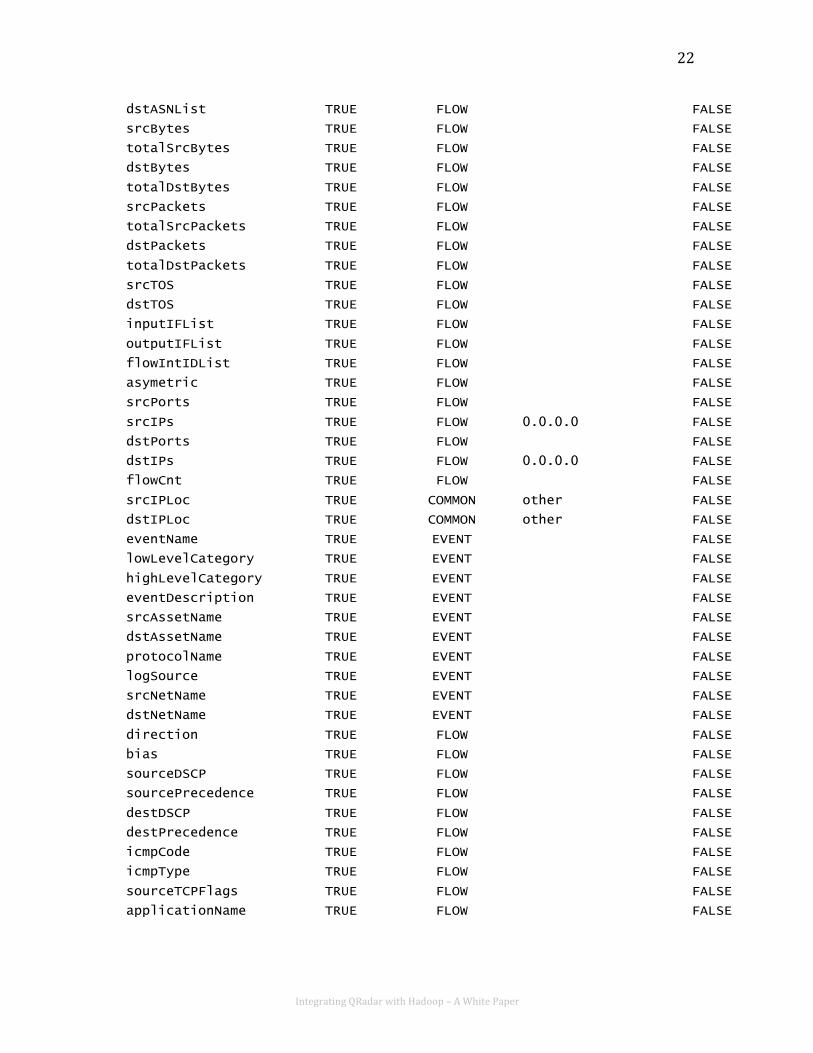
For a complete record of all the values available in this format see Appendix A.

Integrating QRadar with Hadoop – A White Paper
5
Custom Properties In addition to the values defined in Appendix A, the data format supports Custom Properties defined in QRadar. Only Custom Properties that are have the option: “optimize parsing for rules, reports, and searches” will be included in the data that is sent to Hadoop. For more information on defining Custom Properties, please refer to the QRadar documentation. When designing analytics it is important to decide whether or not to use a Custom Property. It may be more valuable to perform the further parsing and analytics in the offline processing of the Hadoop Cluster. Each field must be looked at on a case-‐by-‐case basis.
Configuring the Data Link The data link between QRadar and a Hadoop environment is established through some configuration on both sides. One configuration dictates how to send the data from QRadar to Hadoop and the other configuration is for the QRadar Platform API to consume insights back from the big data platform.
QRadar to Hadoop Data Flow Configuration Configuring the data flow between QRadar to Hadoop involves the configuration of the following components:
a. JSON Forwarding Enablement; and b. QRadar Routing Rules and Destinations c. Flume Receiver Configuration (Hadoop Cluster).
JSON Enablement on for QRadar By default, QRadar v7.2 mr1 p3 does not expose the JSON option. In order to enable the following option (see below) must be added to the following files on the QRadar Console of the given deployment:
1. /opt/qradar/conf/nva.conf 2. /store/configservices/staging/globalconfig/nva.conf
Line to add: FORWARDING_DESTINATION_JSON_FORMAT_ENABLE=true
No deployment is necessary after this activity is complete. The system will pick up this change. However, if you have browser windows open to the Routing Rules and Destinations; you must close them and re-‐open them for the system to pick up the changes.

Integrating QRadar with Hadoop – A White Paper
6
QRadar Routing Rules and Forwarding Destinations Routing Rules and Forwarding Destinations allow data to flow out QRadar. This section will go over the basics for defining routing rules and destinations. Routing Rules and Destinations can be found in the QRadar Admin Tab (see Fig 1.0).
Fig 2.0 Admin Panel
Routing Rules Routing Rules allow the user to filter data from the QRadar system and direct it to a given destination. Routing Rules developed for forwarding to a Hadoop Environment must have the following properties:
a. They must have a mode of offline. b. In the routing forward options they should be directed to a forwarding
destination that has been setup for your Big Data Cluster.
Forwarding Destinations Forwarding Destinations in QRadar allow the user to specify a destination for data along with a format, port and protocol. Forwarding Destinations for a Hadoop Based Cluster require the following properties:
a. The Event Format must be set to JSON; and b. The Protocol must be TCP; and c. The Destination Address and Port must be that of the corresponding
Flume Receiver on the Hadoop Cluster; and d. The check for prefixing a syslog header if it is missing or invalid should be
checked.

Integrating QRadar with Hadoop – A White Paper
7
Flume Receiver/Agent Configuration Apache Flume (http://flume.apache.org) is currently the recommended approach for receiving data from QRadar into a Hadoop Big Data Cluster. The general approach is to develop a series of sources, channels and sinks that write data to HDFS in the Hadoop Cluster. For larger deployments, a complex network of Flume Agents is generally required on a set of dedicated hardware outside the Big Data Cluster. This configuration is dependent upon how the data is being stored into HDFS and how much data is being forwarded. We will touch upon this in the Example Deployment Section (later in this document). This section will show how a single Flume Receiver is configured. For more in-‐depth details on how Flume Receivers can be configured and their accompanying options please refer to the Flume Documentation. As indicated at the beginning of the paper, Flume 1.4 is recommended for the following descriptions. A basic flume receiver/agent consists of sources, channels and sinks. The Flume Users Guide (http://flume.apache.org/FlumeUserGuide.html) documents more complex configurations. Flume Agents are defined in a configuration file and are started through the following command: flume-ng agent -n $agent_name -c conf -f $agent.conf In the above command $agent_name is name of the Flume Agent and $agent.conf is the full path to the configuration file that specifies the configuration of the receiver. A full configuration file is quite large so we will dissect the components of a sample agent configuration file here:
a. Agent Definition b. Source Definition c. Channel Definition d. Sink Definition
The following sections will go into basic detail of these definitions, for a more in-‐depth understanding of these definitions, please consult the flume documentation.
Agent Definition Below is the agent definition excerpt from a basic flume configuration. It defines that the agent “QRadarAgent” will have:
a. A source “qradar”; and b. A channel “FileChannel”; and c. A sink “HDFS”; and d. The qradar source and the HDFS Sink will both use the channel File Channel.

Integrating QRadar with Hadoop – A White Paper
8
This is the basic architecture of our flume agent. #Syslog TCP Source from QRadar # QRadar Source Channel and Sink QRadarAgent.sources = qradar QRadarAgent.channels = FileChannel QRadarAgent.sinks = HDFS # QRadar File Channel QRadarAgent.sources.qradar.channels = FileChannel QRadarAgent.sinks.HDFS.channel = FileChannel
Source Definition The source for this example receiver defines a syslogtcp receiver listening on port 5555 on bigdatahost.com. If we recall back to the section on the forwarding destination configuration in QRadar, this host and port will be the same as what is specified in the Forwarding Destination. The event size is important or there will be truncated data. If the QRadar Cluster is collecting events with larger payloads, it is recommended that the event Size be adjusted accordingly. # Configuration for the QRadar Single Port Source QRadarAgent.sources.qradar.type = syslogtcp QRadarAgent.sources.qradar.port = 5555 QRadarAgent.sources.qradar.portHeader = port QRadarAgent.sources.qradar.host = bigdatahost.com QRadarAgent.sources.qradar.eventSize = 25000 # Flume File Stamp Interceptor QRadarAgent.sources.qradar.interceptors = i3 QRadarAgent.sources.qradar.interceptors.i3.type = TIMESTAMP
Channel Definition A channel can be on disk or in memory. It is recommended that for configuring data from QRadar to a Hadoop based cluster that a file channel be deployed. Below is a sample file based channel in our agent configuration file. It specifies the type “file” and a checkpoint and data directory. It is recommended for the best performance that these directories be on different disks. # Each channel's type is defined. QRadarAgent.channels.FileChannel.type = file QRadarAgent.channels.FileChannel.checkpointDir = $CheckPointDir QRadarAgent.channels.FileChannel.dataDirs=$DataDir QRadarAgent.channels.FileChannel.transactionCapacity = 500000

Integrating QRadar with Hadoop – A White Paper
9
Sink Definition The below sink definition defines a HDFS sink that is stored in compressed form. The path and the roll Size allow the data to be stored in different directories in HDFS. This document will touch upon the various ways to land data in HDFS in the Example Deployment section. It is recommended because of the ‘heaviness’ (size) of the JSON format that some sort of compression be deployed when landing data on the QRadar cluster. ## sink properties ## hdfs sinks properties QRadarAgent.sinks.HDFS.type = hdfs QRadarAgent.sinks.HDFS.hdfs.writeFormat = Text QRadarAgent.sinks.HDFS.hdfs.codeC = cmx QRadarAgent.sinks.HDFS.hdfs.fileType = CompressedStream QRadarAgent.sinks.HDFS.hdfs.rollInterval = 0 QRadarAgent.sinks.HDFS.hdfs.idleTimeout = 120 QRadarAgent.sinks.HDFS.hdfs.batchSize = 50000 QRadarAgent.sinks.HDFS.hdfs.txnEventMax = 50000 # not roll based on file size QRadarAgent.sinks.HDFS.hdfs.rollSize = 4194304000 # not roll based on number of events QRadarAgent.sinks.HDFS.hdfs.rollCount = 0 QRadarAgent.sinks.HDFS.hdfs.filePrefix = host-%Y%m%d%H00 QRadarAgent.sinks.HDFS.hdfs.fileSuffix=.cmx QRadarAgent.sinks.HDFS.hdfs.path = hdfs://host:9000/%Y-%m-%d/%H00
Hadoop to QRadar Data Flow Configuration The QRadar platform accepts data from Hadoop through its Platform Reference Set API; which provides and interface to manipulating the reference data stored in the QRadar Cluster. Documentation for the reference data API can be found by logging into the QRadar Cluster as admin and accessing: https://<consoleip>/restapi/doc. The data returned to QRadar, from a Big Security point of view ,is information gleaned from the Offline Batch Analytics performed on the Hadoop Platform. In order to use the API a role and an authorized service must be configured on the QRadar Platform.
API Services Role Configuration To configure an API Role, access the Users icon in the User Management section of the admin panel. Create a new role: “APIRole” that has the API and Reference Data API Options Checked (see Figure 3.0). Perform a deploy after this.
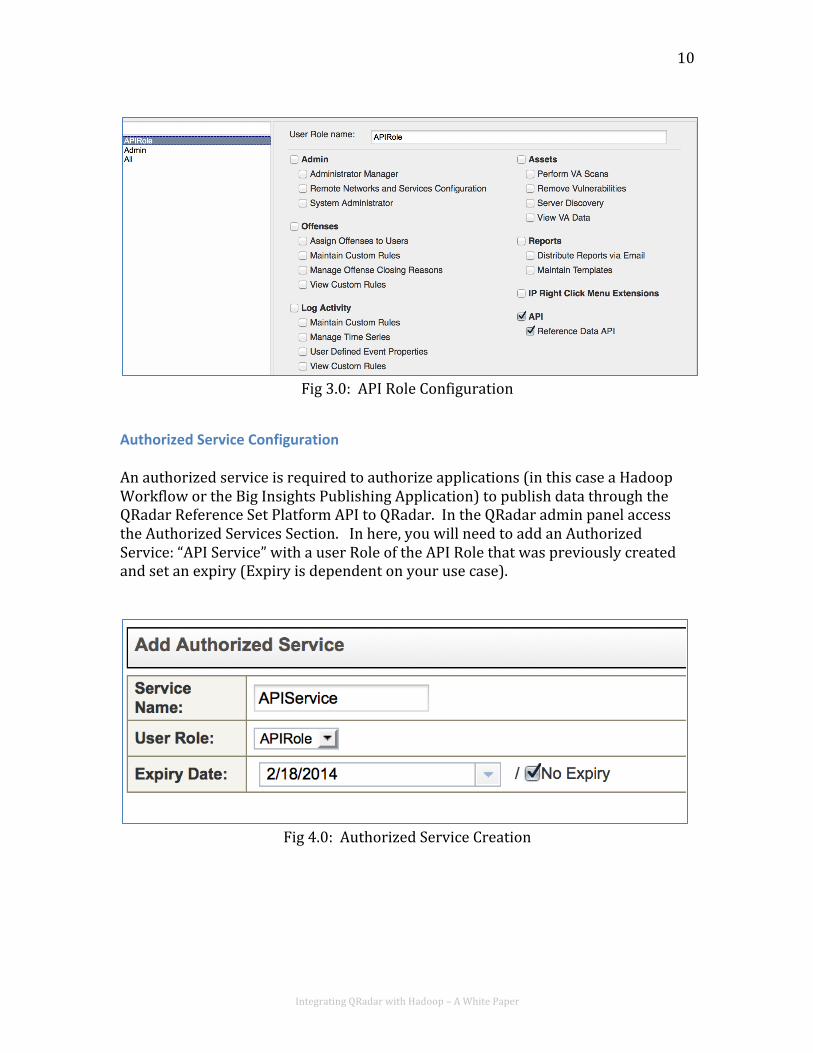
Integrating QRadar with Hadoop – A White Paper
10
Fig 3.0: API Role Configuration
Authorized Service Configuration An authorized service is required to authorize applications (in this case a Hadoop Workflow or the Big Insights Publishing Application) to publish data through the QRadar Reference Set Platform API to QRadar. In the QRadar admin panel access the Authorized Services Section. In here, you will need to add an Authorized Service: “API Service” with a user Role of the API Role that was previously created and set an expiry (Expiry is dependent on your use case).
Fig 4.0: Authorized Service Creation

Integrating QRadar with Hadoop – A White Paper
11
Deployment Considerations In this section, we will talk about a number of deployment considerations when configuring a QRadar Cluster with a Hadoop Based Cluster. Things to consider:
a. Data Storage in HDFS b. Multi-‐Agent Flume Configuration
Data Storage Configuration As this document has shown, a Flume Sink Guides how data is “landed” in the Big Data Cluster. There are a number of parameters on a Flume Sink that guide:
a. The maximum size of data files in HDFS; and b. How the directory structure is formed (Date Parameters).
To make sense of this configuration, one has to develop a custom architecture of flume agents, routing rules and forwarding destinations. The routing rules will define what data from which event processors are sent and the flume agents define how the data is landed in HDFS. The best way to describe this is through an example.
Deployment Example In this example we will use QRadar deployment consisting of a console and three (3) Event Processors. In this fictitious scenario the three EPs are all collecting Windows and Bluecoat logs. In this example, the data will be stored in HDFS separated by device group type. This will entail:
a. Defining Two (2) Flume Agents for each of the group types (Windows and Blue Coat for this particular example); and
b. Defining Two (2) Forwarding Destinations for each group type to route data to the corresponding flume agent; and
c. Defining two (2) routing rules for each group on each Event Processor (EP) (a total of 6 routing rules) to route the data to the appropriate destination.
Multi-‐Agent Flume Configurations For large QRadar deployments, the sheer amount of data to be transferred from a QRadar cluster to a Hadoop environment requires a series of “flume relay” machines to route the data to HDFS. Some QRadar deployments can consume over 100,000 events per second (eps) and the feasibility of having all the Event Processors in the QRadar cluster send all their data to the Hadoop Clusters console is simply not practical. In these situations, a series of flume agents need to be

Integrating QRadar with Hadoop – A White Paper
12
deployed on dedicated hardware outside the Big Data Cluster to collect and relay the sink the data appropriately to the cluster.
Forwarding Profiles As was shown earlier, in configuring the data link, the Forwarding Destinations contain the directions for the type of data to send, where to send it and the protocol to use. Behind the scenes, every forwarding destination has a forwarding profile. These profiles direct what data is sent from the overall subset of available attributes (see Appendix A) and some properties regarding how it is sent. This allows for some highly configurable data feeds from QRadar. Currently the configuration of this profile is something that has to be done with shell access to the QRadar Cluster console.
Technical Details In QRadar v7.2 mr1 p3, a forwarding profile for each destination is initialized in the /opt/qradar/conf/ directory. These files are will appear named as “forwardingprofile_json.xml.1”, “forwardingprofile_json.xml.2”, etc. The number at the end of the file (in /opt/qradar/conf) corresponds to the internal id of the destination in the corresponding postgres table: selectivefwd_destination. In order to find out the corresponding file for a given destination this table has to be queried by name. For example, if the destination is named ‘mydestination’, the corresponding database query would be: select id from selectivefwd_destination where name = ‘mydestination’;
If the above query returned 2 as the respective id then the forwarding profile for that destination would reside in /opt/qradar/conf/forwardingprofile_json.xml.2. Because this is a backend modification, you must first disable the corresponding destination before editing it’s forwarding profiles. Once you are finished, enable the destination and the forwarding profile changes should be picked up.
Editing the Forwarding Profile The XML Forwarding Profile allows you to configure:
a. The name of the forwarding profile; and b. Whether custom properties are sent (currently all or none); and c. A pre-‐amble for each event (this is provided for syslog receivers that are
particular about the format of the syslog header); and d. The time format for any ISO time field; and

Integrating QRadar with Hadoop – A White Paper
13
e. Properties for any of the available fields to send.
Header Attributes The Header Attributes include (a-‐d above) and are all the attributes on a profile that apply to the profile as a whole.
Name and Custom Property Configuration Below is an excerpt from a forwarding profile that shows how the profile name and the custom properties settings can be controlled. <profile name="myprofile" enabled="true" version="1.0" includeAllCustomProperties="true"> </profile>
Pre-‐amble The preamble is controlled by it’s own xml element (see below). By default the preamble is set to a priority code 01 and the string “hostname” which simulates a host name. The pre-‐amble is static and is here to support syslog receivers, which may require additional formatting. <preamble data="<01>- hostname "></preamble>
ISO Time Formatting There are a number of fields, which are formatted in ISO time. The profile allows for a change to global formatting of time (see below). This should be only changed when absolutely necessary. This is because the system is optimized to send the time formats in the default form. Another important point is that if the ISO format data time fields are not required, it is recommended that these fields are disabled to improve the overall performance of the data link.
<attribute tag="isoTimeFormat" enabled="true" name="isoTimeFormat"
defaultValue="yyyy-MM-dd'T'HH:mm:ss.SSSZ" enableDefaultValue="false">
</attribute>

Integrating QRadar with Hadoop – A White Paper
14
Field Properties For each field there are the following configurable options in the forwarding profile (see sample field element below):
a. Enabled / Disabled (send or don’t send); and b. The name of the field to use in the JSON feed (tag will correspond to the
available attributes) but the name field controls how it is names; and c. Default Value (the default value to use for the field if is null or not); and d. Whether the Default Value is enabled (enableDefaultValue). This
controls whether to send a default value if one is not present.
<attribute tag="category" enabled="true" name="category" defaultValue="" enableDefaultValue="false">
</attribute>
Working with Insights in QRadar Correlation Engine The data that is returned to QRadar is in some form of reference data. Reference data can data can be used with in the correlation engine in QRadar to identify new alerts based off these insights. This section will go through a small demonstration of this. In this example, the Hadoop Environment has already published a set of user names into a reference set in the QRadar system. This data can be made useful by writing a correlation rule that looks for events containing those user names. This response for these rules can be to adjust the severity of these events or to actually report an incident depending on the actual severity level considered for the users in this list. To create an event rule based on a reference set you can use built in tests in the Rule Wizard that apply to reference data. You can access these in Test Group: “Event Property Tests”. The below example (Fig 5.0) shows adding the Event Property Test: “when any of these event properties are contained in any of these reference set(s)”.
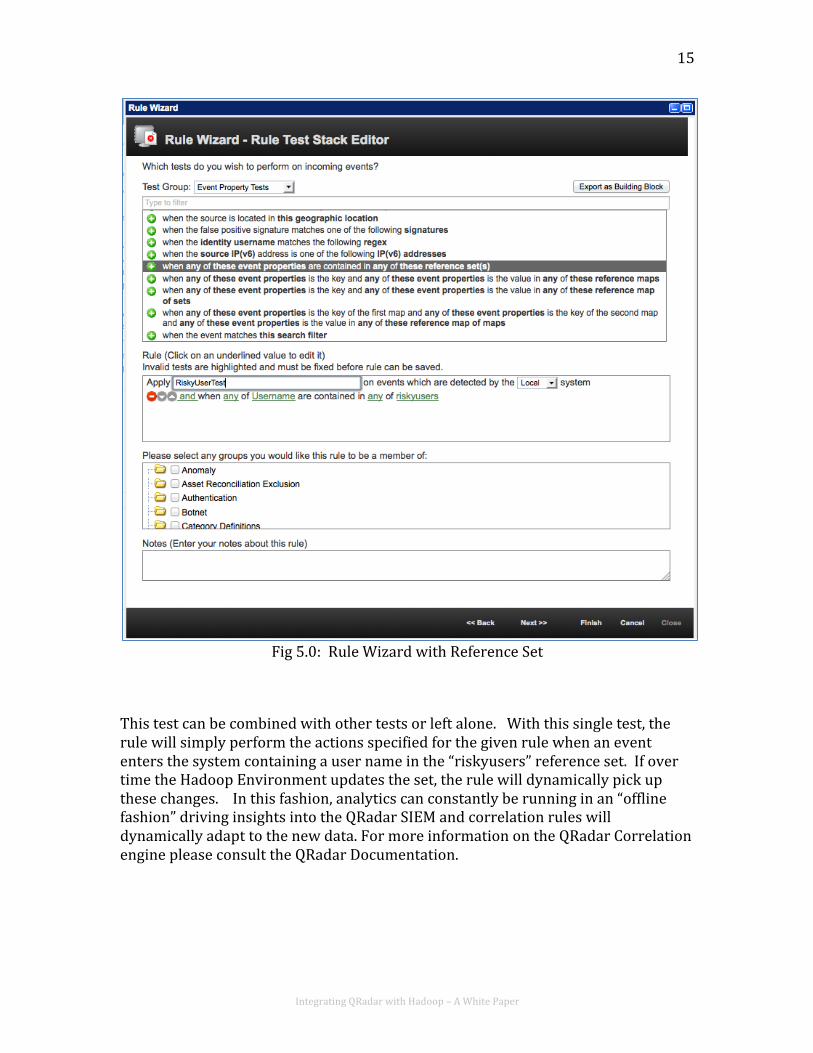
Integrating QRadar with Hadoop – A White Paper
15
Fig 5.0: Rule Wizard with Reference Set
This test can be combined with other tests or left alone. With this single test, the rule will simply perform the actions specified for the given rule when an event enters the system containing a user name in the “riskyusers” reference set. If over time the Hadoop Environment updates the set, the rule will dynamically pick up these changes. In this fashion, analytics can constantly be running in an “offline fashion” driving insights into the QRadar SIEM and correlation rules will dynamically adapt to the new data. For more information on the QRadar Correlation engine please consult the QRadar Documentation.

Integrating QRadar with Hadoop – A White Paper
16
Big Insights Data Access For Big Insights Hadoop environments there are a couple of easy ways to access the data that has been received from QRadar. This section will look at a couple of simple methods using Jaql and Big Sheets. More information on these Big Insights Features can be found in the Big Insights Documentation.
JAQL and QRadar Data JAQL is primarily a query language for JavaScript Object Notation (JSON), but it supports more than just JSON. This makes it a nice fit for the data coming from a QRadar System. The below script is a very simple example of how you can open a QRadar Data File in Big Insights. jsonLines = fn(location) lines (location, inoptions = { converter: " com.ibm.jaql.io.hadoop.converter.FromJsonTextConverter"}); events = read(jsonLines("<FULL HDFS FILE PATH>")); events -> top 1; quit; The above script can be executed using the following command from the prompt (logged in as biadmin): /opt/ibm/biginsights/jaql/bin/jaqlshell -b sample.jaql This should output the first event in the file you have specified.
Big Sheets and QRadar Data Big Sheets within Big Insights can also be used to access data received from the QRadar System. To view any file in Big Sheets click on the file in the file browser. On the right click on “Sheets” radio button (See Fig 6.0 below)
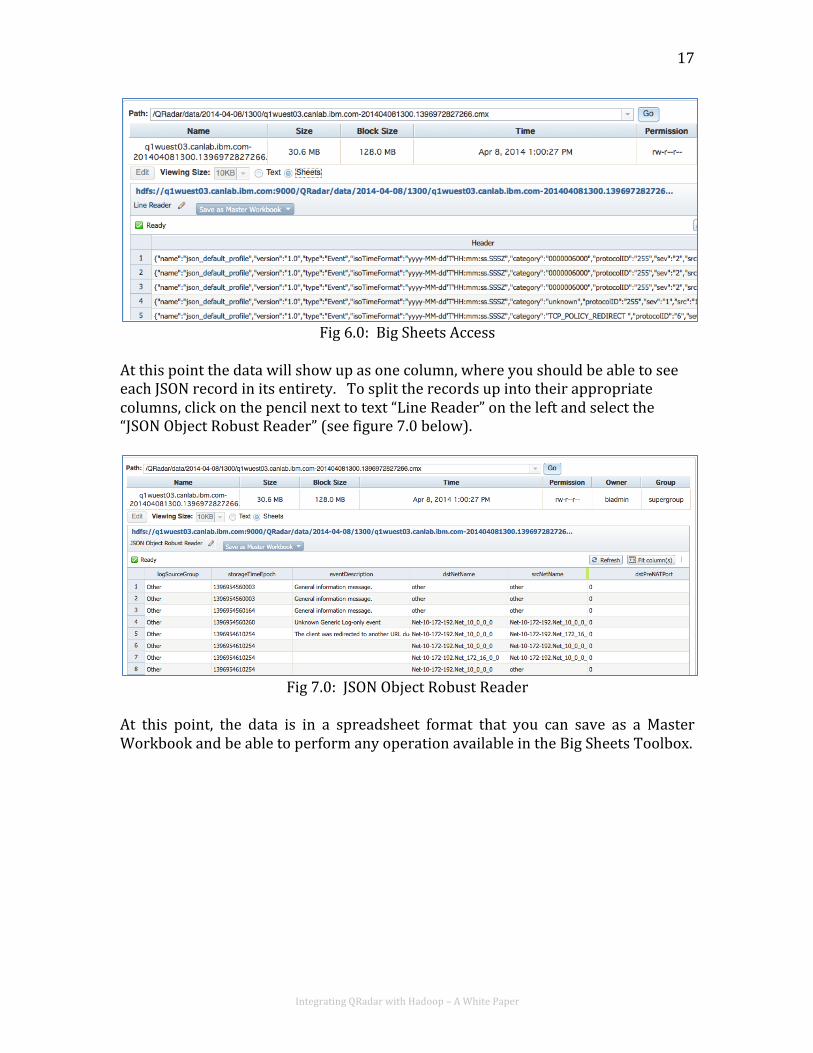
Integrating QRadar with Hadoop – A White Paper
17
Fig 6.0: Big Sheets Access
At this point the data will show up as one column, where you should be able to see each JSON record in its entirety. To split the records up into their appropriate columns, click on the pencil next to text “Line Reader” on the left and select the “JSON Object Robust Reader” (see figure 7.0 below).
Fig 7.0: JSON Object Robust Reader
At this point, the data is in a spreadsheet format that you can save as a Master Workbook and be able to perform any operation available in the Big Sheets Toolbox.

Integrating QRadar with Hadoop – A White Paper
18
Use Cases To this point, this paper has talked technically about integrating QRadar with a Hadoop Environment. There are a number of use cases surrounding this. They all boil down to the need to consider non-‐traditional (with respect to cyber) information into the Security Picture. This section talks about example use cases for:
a. Establishing Baseline b. Advanced Persistent Threat Detection (Beaconing, Leakage) c. Domain Attribution
These use cases are meant to serve as examples of what can be accomplished in Hadoop. Central to these examples are whether they provide value or not to the Security Picture of given enterprise. There is a considerable amount of planning involved to identify the data sources and analytics to support identified security use cases. In addition, every use case will have an accompanied data workflow and model.
Establishing Baseline A classic use case for working with QRadar data in Hadoop involves base lining behavior. The Hadoop cluster provides a container for long-‐term information storage and with that trends can be detected over long periods. These trends can be established using long running map reduce jobs to understand things like:
a. User Behavior; and b. Network Activity on Identified Assets; and c. Domain Attribution.
These are just a list of a few examples. Because of the diverse programming capabilities of a Hadoop Based platform, the data scientist has the ability to incorporate various clustering / machine learning capabilities on the normalized cyber data received from QRadar.
Advanced Persistent Threat Detection Advanced Persistent Threats (APTs) are complicated to detect. There isn’t a single formula for detecting every APT out there but the Hadoop platform provides a vehicle for analyzing data points over long periods of time to understand patterns in behavior. A couple of classic examples of this are Beaconing and Data Leakage.
Beaconing The classic example of beaconing is analyzing the traffic over time to identify local sources that are talking remotely periodically (hourly, daily etc.) with a very small
Integrating QRadar with Hadoop – A White Paper
19
amount of bytes (less than 512 bytes). These attributes are common in command and control domains. The malware is calling home periodically. These small communications can be missed in a real-‐time system but using offline batch analytics they can be identified.
Data Leakage Another case similar to beaconing is data leakage. Instead of transferring data out of the organization, data is trickled consistently from one local source. This can be identified by looking for consistent transmissions on a local source to remote destination over time.
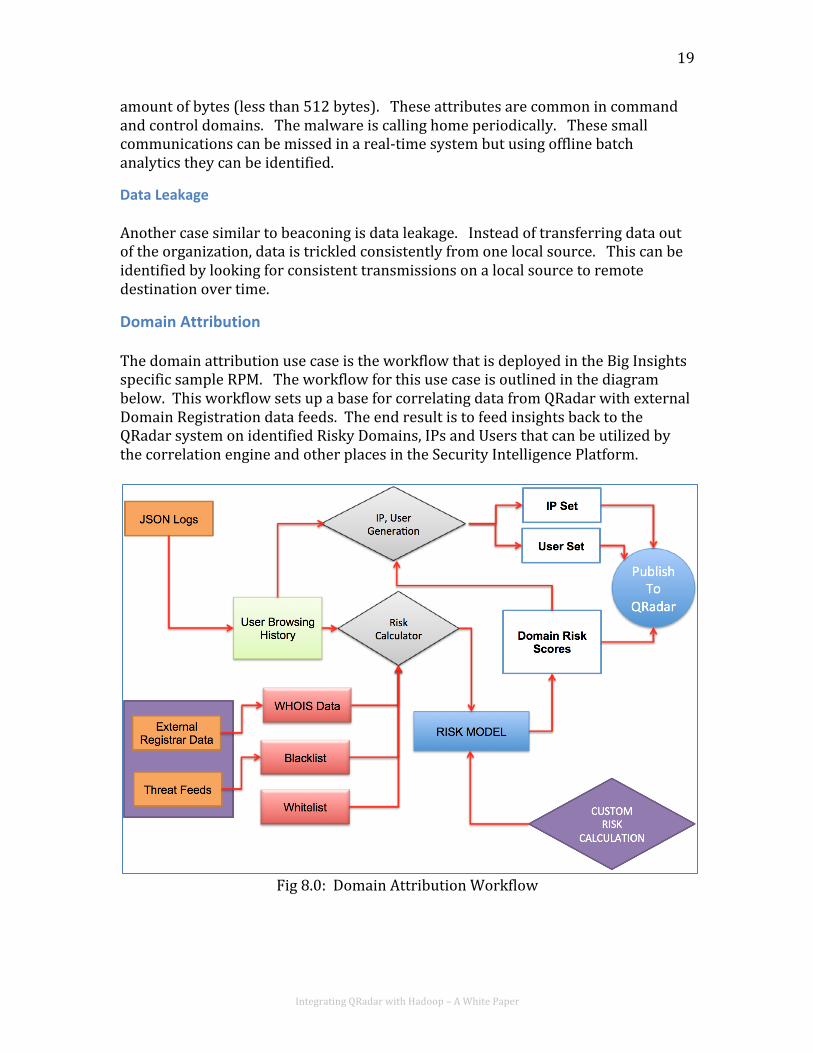
Domain Attribution The domain attribution use case is the workflow that is deployed in the Big Insights specific sample RPM. The workflow for this use case is outlined in the diagram below. This workflow sets up a base for correlating data from QRadar with external Domain Registration data feeds. The end result is to feed insights back to the QRadar system on identified Risky Domains, IPs and Users that can be utilized by the correlation engine and other places in the Security Intelligence Platform.
Fig 8.0: Domain Attribution Workflow

Integrating QRadar with Hadoop – A White Paper
20
In this use-‐case domain data is extracted from various sources. Domain registration data for these domains is looked up using an external service. Risk Models can be developed on this data. These risk models can look at attributes like:
a. Domain Age; and b. Correlation between Domain Data with known black lists; and c. How often data on this domain is changing.
Once risky domains are identified from the traffic flow, they are cross-‐referenced with the immediate browsing history to extract a set of Risky Users and IPs. The Insights Data Publisher (installed with the Big Insights RPM) is then called upon to publish this data back to QRadar.
QRadar – Big Insights RPM This document has detailed all the manual steps for setting up the communication channel between QRadar and a Hadoop based system. There is an RPM available for Big Insights Clusters that will automatically perform the following actions:
a. Setup one Flume Channel between QRadar Cluster and Big Insights (For complex clusters it is recommended that this step is skipped and architecture be followed in this document); and
b. Setup and install the Big Insights Publishing Application with all the required credentials; and
c. Install a sample workflow for Domain Registry Analysis (see readme on the RPM for more details).
Please see the accompanying documentation with QRadar – Big Insights RPM for details on installation and configuration.
Integrating QRadar with Hadoop – A White Paper
21
APPENDIX
JSON Data Fields
NAME ENABLED TYPE DEFAULT VALUE
DEFAULT ENABLED
category TRUE COMMON
FALSE
protocolID TRUE COMMON
FALSE
sev TRUE COMMON
FALSE
src TRUE COMMON 0.0.0.0 FALSE
dst TRUE COMMON 0.0.0.0 FALSE
srcPort TRUE COMMON
FALSE
dstPort TRUE COMMON
FALSE
usrName TRUE COMMON
FALSE
relevance TRUE COMMON
FALSE
credibility TRUE COMMON
FALSE
storageTimeEpoch TRUE COMMON
FALSE
storageTimeISO TRUE COMMON
FALSE
devTimeEpoch TRUE EVENT
FALSE
devTimeISO TRUE EVENT
FALSE
srcPreNAT TRUE EVENT 0.0.0.0 FALSE
dstPreNAT TRUE EVENT 0.0.0.0 FALSE
srcPostNAT TRUE EVENT 0.0.0.0 FALSE
dstPostNAT TRUE EVENT 0.0.0.0 FALSE
srcMAC TRUE EVENT 0:0:0:0:0:0 FALSE
dstMAC TRUE EVENT 0:0:0:0:0:0 FALSE
srcPreNATPort TRUE EVENT
FALSE
dstPreNATPort TRUE EVENT
FALSE
srcPostNATPort TRUE EVENT
FALSE
dstPostNATPort TRUE EVENT
FALSE
identSrc TRUE EVENT 0.0.0.0 FALSE
identHostName TRUE EVENT
FALSE
identUserName TRUE EVENT
FALSE
identNetBios TRUE EVENT
FALSE
identGrpName TRUE EVENT
FALSE
identMAC TRUE EVENT 0:0:0:0:0:0 FALSE
hasIdentity TRUE EVENT false FALSE
payload TRUE EVENT
FALSE
firstPacketTimeEpoch TRUE FLOW
FALSE
firstPacketTimeISO TRUE FLOW
FALSE
flowType TRUE FLOW
FALSE
cmpAppId TRUE FLOW
FALSE
appId TRUE FLOW
FALSE
srcASNList TRUE FLOW
FALSE
Integrating QRadar with Hadoop – A White Paper
22
dstASNList TRUE FLOW
FALSE
srcBytes TRUE FLOW
FALSE
totalSrcBytes TRUE FLOW
FALSE
dstBytes TRUE FLOW
FALSE
totalDstBytes TRUE FLOW
FALSE
srcPackets TRUE FLOW
FALSE
totalSrcPackets TRUE FLOW
FALSE
dstPackets TRUE FLOW
FALSE
totalDstPackets TRUE FLOW
FALSE
srcTOS TRUE FLOW
FALSE
dstTOS TRUE FLOW
FALSE
inputIFList TRUE FLOW
FALSE
outputIFList TRUE FLOW
FALSE
flowIntIDList TRUE FLOW
FALSE
asymetric TRUE FLOW
FALSE
srcPorts TRUE FLOW
FALSE
srcIPs TRUE FLOW 0.0.0.0 FALSE
dstPorts TRUE FLOW
FALSE
dstIPs TRUE FLOW 0.0.0.0 FALSE
flowCnt TRUE FLOW
FALSE
srcIPLoc TRUE COMMON other FALSE
dstIPLoc TRUE COMMON other FALSE
eventName TRUE EVENT
FALSE
lowLevelCategory TRUE EVENT
FALSE
highLevelCategory TRUE EVENT
FALSE
eventDescription TRUE EVENT
FALSE
srcAssetName TRUE EVENT
FALSE
dstAssetName TRUE EVENT
FALSE
protocolName TRUE EVENT
FALSE
logSource TRUE EVENT
FALSE
srcNetName TRUE EVENT
FALSE
dstNetName TRUE EVENT
FALSE
direction TRUE FLOW
FALSE
bias TRUE FLOW
FALSE
sourceDSCP TRUE FLOW
FALSE
sourcePrecedence TRUE FLOW
FALSE
destDSCP TRUE FLOW
FALSE
destPrecedence TRUE FLOW FALSE
icmpCode TRUE FLOW
FALSE
icmpType TRUE FLOW
FALSE
sourceTCPFlags TRUE FLOW
FALSE
applicationName TRUE FLOW
FALSE