indexing data relationships
DESCRIPTION
Indexing Data Relationships. Michael J. Franklin University of California, Berkeley & RightOrder Inc. Overview. Data relationships can be complex. Hierarchical views: XML, LDAP, … Semistructure & dynamic schema Approach:Encode paths as tagged strings “raw” paths encode structure - PowerPoint PPT PresentationTRANSCRIPT

Indexing Data Relationships
Michael J. FranklinUniversity of California, Berkeley
& RightOrder Inc.

2
Overview Data relationships can be complex.
Hierarchical views: XML, LDAP, … Semistructure & dynamic schema
Approach:Encode paths as tagged strings “raw” paths encode structure “refined” paths accelerate lookups Index strings in a highly-compact structure. Live on top of, next to or inside DBMS.
Benefits Performance, Scalability + Adaptivity Leverages mature DBMS technology

3
Raw paths w/Designators
ABC Corp.
123 ABC Way
17 Main St.
Goods Inc.
widget
thingy
jobber
Invoice as a tree
Invoice
Buyer Seller Itemlist
Name Address Item
ABC Corp. 123 ABC Way Goods Inc. 17 Main St.
widget thingy jobber
Name Address Item Item

4
Refined paths Optimize specific access paths
“Find invoices where X sold to Y ”
“Find invoices where X bought Y and Z”
“Find invoices where a buyer bought X, Y and Z ”
X Y ABC Corp. Goods Inc.
XYZ Corp. Acme Inc.
ABC Corp. jobber widget
XYZ Corp. drill hammer X Y Z
X Y Z jobber thingy widget drill hammer nail

5
Index Fabric An index structure for long strings.
Provides fast lookups Handles long strings Ideal substrate for designated keys
Based on Patricia tries Highly compressed string representation Cost in index independent of string
length But, need to balance.

6
Patricia tries
Indexes first point of difference between keys
greenbeans
greentea
g c
r w
0
22
corn cow
a
2grass
5
e
b t
greenbeans greentea
D. R. Morrison. “PATRICIA – Practical algorithm to retrieve information coded in alphanumeric.” J. ACM, 15 (1968) pp. 514-534

7
Multiple Hierarchical Views Can store multiple permulations of
relationships Find animals and the plants they eat Find plants and the animals that eat them
Represent as a new set of keys
Store data once using “permutation records”
corn cow
corn cow

8
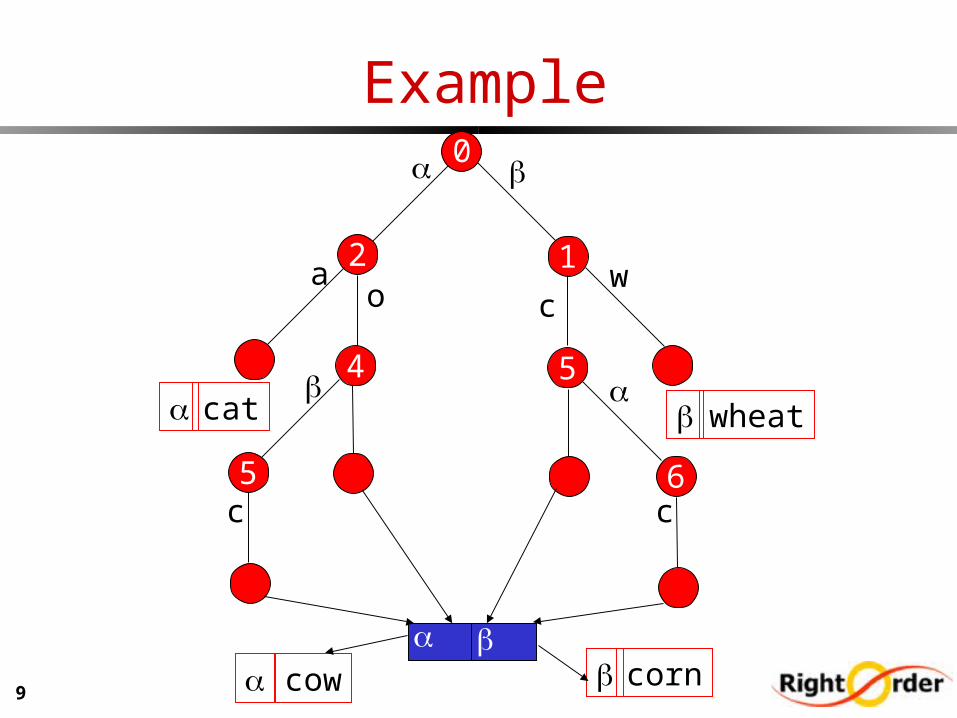
Example 0
2o
a
cat4
5c cow
corn
1
w
5
c
wheat
corn
6
c
cow
9
Example 0
2o
a
cat4
5
corn
1
w
5
c
wheat
6
cow
c c

10
Balancing Patricia tries
g c
r w
0
22
corn cow
a
2grass
5
e
b t
greenbeans greentea

11
Balancing Patricia tries
Step 1: divide trie into blocks
g c
r w
0
22
corn cow
a
2grass
5
e
b t
greenbeans greentea

12
Balancing Patricia tries
Step 2: build another layer
g0
2
Layer 1 Layer 0
e
g c
r w
0
22
corn cow
a
2grass
5
e
b t
greenbeans greentea

13
Balancing Patricia tries
Search for “cash”
g0
2
Layer 1 Layer 0
e
greenbeans
g c
r w
0
22
corn cow
a
2grass
5
e
b t
greenbeans greentea

14
Balancing Patricia tries
Search for “cash”
g0
2
Layer 1 Layer 0
e
greenbeans
g c
r w
0
22
corn cow
a
2grass
5
e
b t
greenbeans greentea

15
Balancing Patricia tries
Search for “cash”
g0
2
Layer 1 Layer 0
e greenbeans
g c
r w
0
22
corn cow
a
2grass
5
e
b t
greenbeans greentea

16
Balancing Patricia tries
Layer
0
Data
Search
Layer
0
Layer
1La
yer
1
Layer
2La
yer
2
Layer
3

17
Performance Number of layers is small
Fixed (small) space per key High branching factor per block Bushy, shallow tree
Example: 8 KB blocks 32 bit pointers + 2 bytes for keys/structure = 1000+ pointers per block = 3 layers for 1 billion pointers to data (10003) Upper layers are tiny (10 megabytes), in RAM Only layer 0 on disk Usually one index I/O per key lookup
Data

18
Find publications by co-authors
0
1000
2000
3000
4000
5000
6000
IndexFabric:Refined
IndexFabric:Raw
RDBMSonly: Smart
RDBMSonly: Naïve
seco
nd
s
RDBMS STORED
2.5 : 1
Index Fabric Raw Paths
5 : 1
Index Fabric Refined Paths
25 : 1
RDBMS Edge mapping
10,000 queries

19
Find publications by co-authors
050000
100000150000200000250000300000350000400000
Index Fabric
Refined Paths
Index Fabric
Raw Paths
RDBMS
STORED
RDBMS Edge
mapping
I/O
s
index I/O data I/O index I/O - edge data I/O - edge
RDBMS STORED
Index Fabric Raw Paths
Index Fabric Refined Paths
RDBMS Edge mapping
2.1 : 1
4 : 1
20 : 1
10,000 queries

20
Conclusion Index arbitrary relationships
Encode as designated strings Relationships and structures can be
complex Index many data access paths No need for DTD or pre-defined schema
Index Fabric Special data structure for long keys High performance key lookups Supports designator encoding
